Когда дело доходит до мощного и универсального программного обеспечения, ничто не может сравниться с веб-браузером. Будь то машина Intel с архитектурой x86 или смартфон, использующий микрокод ARM; веб-браузеры предлагают феноменальную производительность на любом используемом вами оборудовании. Они настолько мощны, что могут заменить полноценную операционную систему, и Chrome OS — яркий тому пример.
Браузеры — это произведение искусства, но задумывались ли вы, что происходит за кулисами; весь процесс ввода запроса и возврата результата браузером? Что ж, в этой статье мы рассмотрим, как работает браузер и как он отображает веб-страницы за считанные секунды.
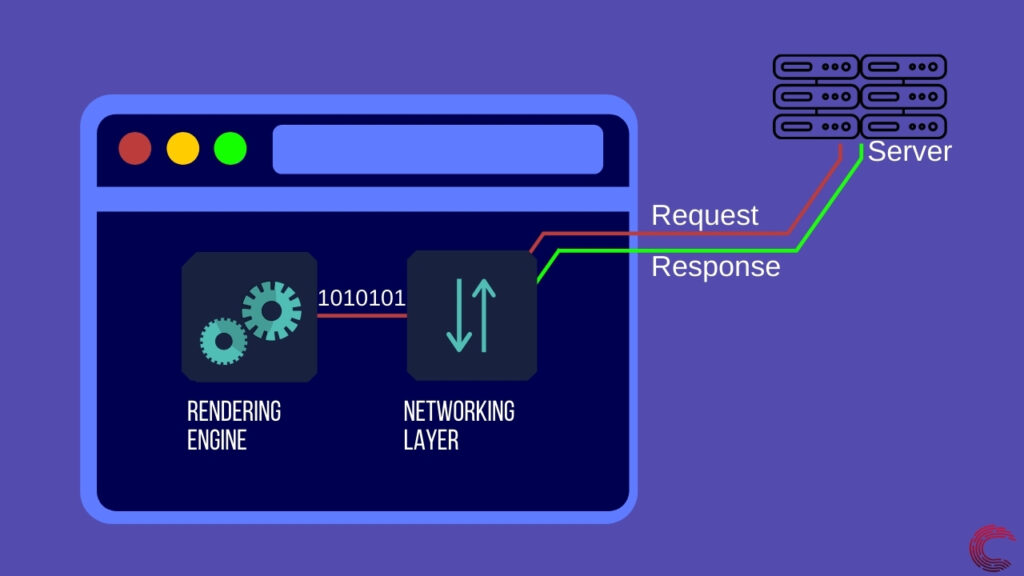
Все начинается с запросов и сетевого уровня.
Когда вы посещаете веб-сайт в Интернете, ваш браузер только подключается к удаленному компьютеру (веб-серверу) и запрашивает ресурсы для раскраски страницы. Это может показаться тривиальным, но под капотом ваш браузер обрабатывает миллионы чисел, чтобы найти и отобразить веб-сайт на вашем экране.
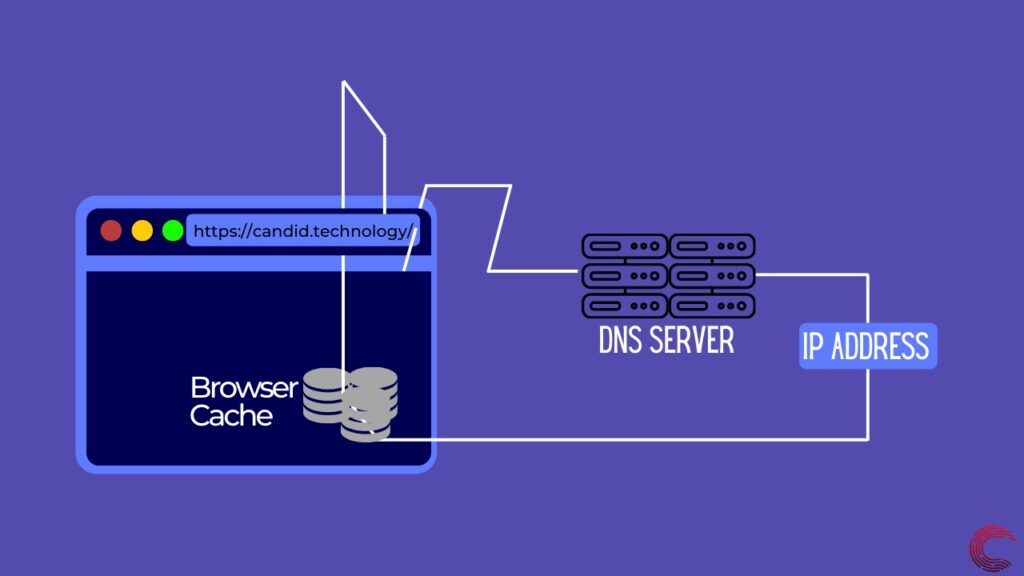
Чтобы отобразить веб-страницу, первое, что нужно сделать вашему браузеру, — это найти удаленный сервер, на котором размещен веб-сайт. Для этого он пытается найти IP-адрес URL-адреса, введенного вами в адресной строке. Этот IP-адрес может однозначно идентифицировать веб-сервер, и как только браузер получит этот адрес, он сможет отправлять запросы на сервер для получения данных.

Чтобы найти IP-адрес, браузер выполняет разрешение DNS, которое можно сделать только двумя способами. Он может либо заглянуть в кеш-память вашего браузера, которая может содержать IP-адрес URL-адреса, если вы посещали сайт в прошлом. Если это не так, он запрашивает у вашего интернет-провайдера, Google или Cloudflare IP-адрес определенного веб-сайта, используя их DNS-серверы.
Как только ваш браузер получит IP-адрес веб-сайта, который вы ищете, сетевой уровень вашего браузера начнет работать. Он пытается установить соединение между вашим устройством и сервером, чтобы данные могли передаваться между двумя устройствами. Для создания этого соединения сетевой уровень использует сокеты, которые представляют собой способ соединения двух устройств в сети с использованием их IP-адреса и назначенного порта на каждом устройстве.
Теперь, когда сетевой уровень соединил два устройства и пакеты данных могут передаваться между ними, сетевой уровень начинает выполнять следующую по важности задачу в любой коммуникации в Интернете — шифрование.
Чтобы зашифровать данные, сетевой уровень выполняет рукопожатие TLS между двумя взаимодействующими устройствами. После завершения рукопожатия все данные, передаваемые между устройствами, зашифровываются и не могут быть прочитаны третьими лицами.
Рукопожатие TLS выполняется только тогда, когда данные передаются с использованием протокола HTTPS, а в случае HTTP выполняется только рукопожатие TCP. Это не шифрует данные; поэтому вы никогда не должны отправлять конфиденциальные данные через HTTP-соединение, поскольку любой злонамеренный объект может видеть ваши данные
После настройки канала связи между двумя устройствами сетевой уровень отправляет запрос на сервер для ресурсов. В случае веб-страницы это HTTPS/HTTP-запрос, который просит веб-сервер отправить HTML-файл, содержащий всю информацию, необходимую браузеру для отображения веб-страницы. Как только сервер получает запрос, он отправляет HTML-документ браузеру в виде единиц и нулей по каналу связи, установленному сетевым уровнем.
Наконец, в браузере есть ресурсы, необходимые для отображения веб-страницы, но они представлены в виде байтов и должны быть преобразованы в формат, который выглядит как веб-страница. Для этого браузер использует свой механизм рендеринга.
Получение смысла из битов с помощью механизма рендеринга
Теперь, когда сетевой уровень сделал запросы к веб-серверу и получил все данные, необходимые браузеру, на сцену выходит механизм визуализации.
Основная задача механизма рендеринга — преобразовать биты данных в форму, которая может быть использована браузером для создания веб-страницы. Чтобы понять, как работает механизм рендеринга, важно понимать все части, из которых состоит веб-сайт.
- HTML (язык гипертекстовой разметки) используется для определения структуры веб-страницы.
- CSS (каскадные таблицы стилей) используются для указания браузеру, как должен выглядеть каждый элемент на веб-сайте.
- Javascript используется для добавления интерактивности сайту и используется для обработки пользовательского ввода, кликов или любой другой обработки, которая может понадобиться сайту.
Механизм визуализации использует синтаксические анализаторы для преобразования битов данных в значимую информацию, которая может использоваться браузером для визуализации веб-страницы. Механизм рендеринга имеет два разных парсера: один для HTML и один для CSS. Давайте посмотрим, как работает анализатор HTML, чтобы получить представление о процессе синтаксического анализа.
Разбор HTML
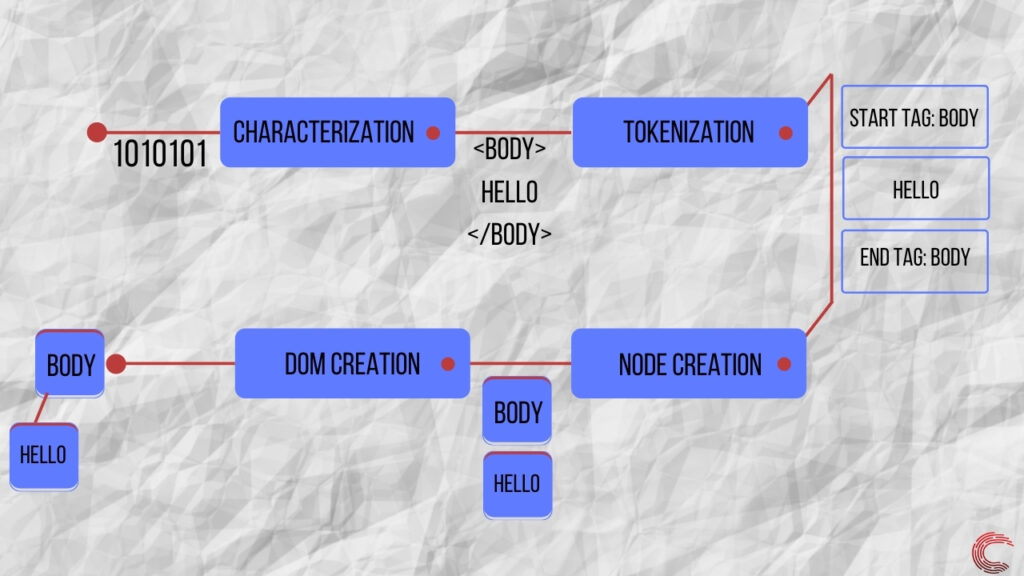
Анализатор HTML принимает биты данных в качестве входных данных и создает логическое представление документа HTML в памяти устройства. Это логическое представление данных известно как структура DOM и представляет данные HTML в иерархическом порядке.
Чтобы создать структуру DOM, парсер HTML выполняет несколько шагов, которые можно описать следующим образом.
- Характеризация извлекает символы из байтов информации, которую анализатор HTML получает с сетевого уровня.
- Токенизация находит токены в потоке символов, который помогает браузеру определять структуру данных.
- Создание узла После идентификации токенов и содержащейся в них информации браузер создает узлы памяти для хранения этих данных.
- Создание DOM парсер иерархически связывает узлы памяти для создания DOM-представления полученных байтов данных.
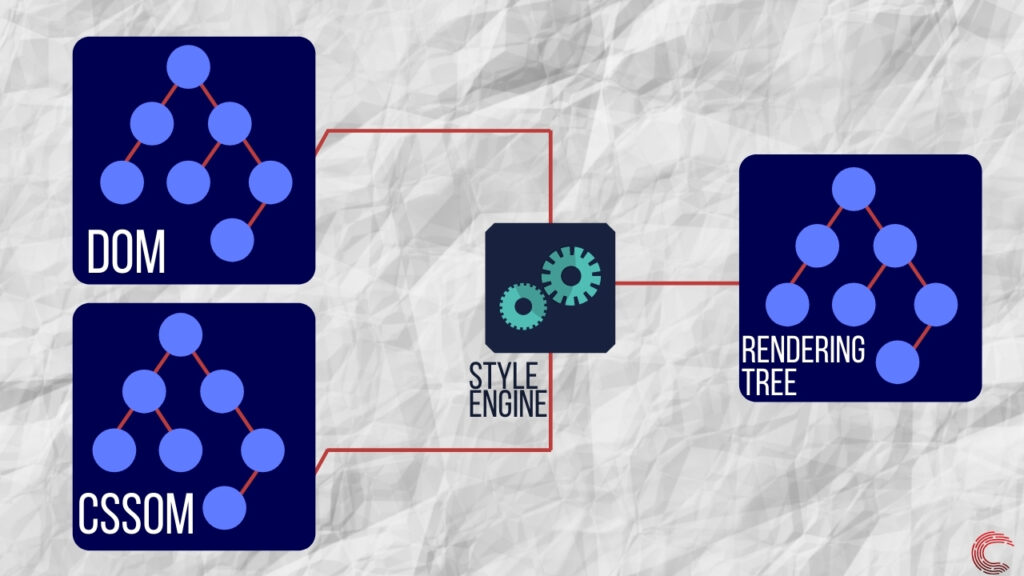
HTML-документ, который получает браузер, содержит ссылки на файлы CSS. Эти ссылки обрабатываются сетевым уровнем и отправляются синтаксическому анализатору CSS. Этот синтаксический анализатор создает вывод CSSOM (объектная модель CSS), который определяет, как должен быть стилизован каждый элемент в DOM.
Создание дерева отрисовки и макета для веб-страницы
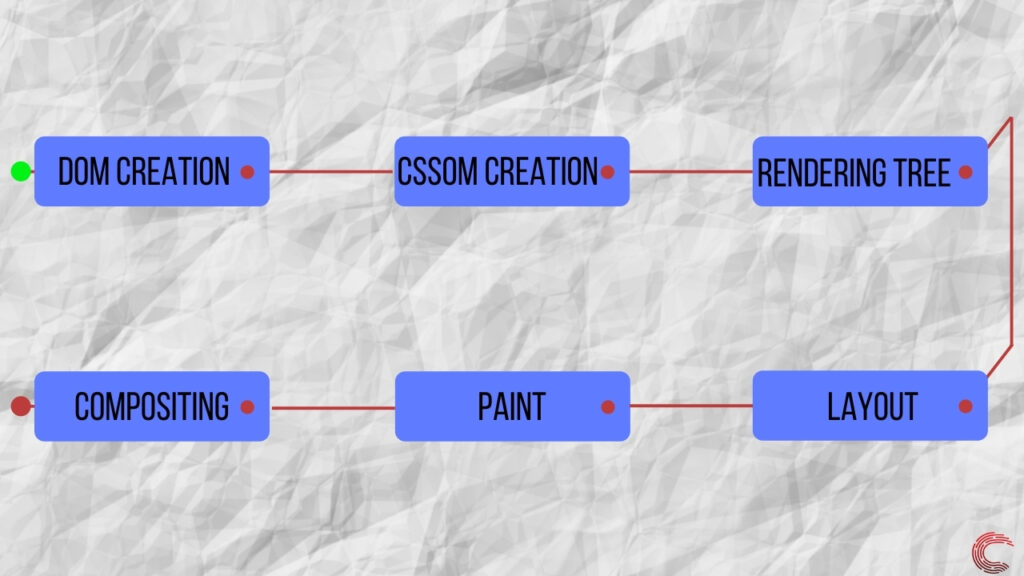
После создания модели DOM и завершения синтаксического анализа CSS-файла механизм визуализации использует механизм стилей для объединения как CSSOM, так и DOM. Это создает дерево визуализации, которое содержит информацию о структуре и стиле веб-страницы, которая должна отображаться. Дерево рендеринга состоит только из видимых узлов и не имеет узлов, невидимых для пользователя на экране.
После создания дерева рендеринга механизм рендеринга запускает процесс компоновки. Этот процесс учитывает разрешение экрана и то, как каждый элемент должен быть размещен на устройстве. Он также вычисляет размер каждого элемента, который будет отображаться на экране, и его относительное положение по отношению к другим элементам.
Теперь, когда движок рендеринга имеет всю информацию о веб-странице в формате, понятном нашей системе, мы можем начать рендеринг страницы в браузере.
Рисование холста и компоновка веб-страницы на экране
После того, как механизм рендеринга завершил процесс макета, ему необходимо нарисовать каждый пиксель на экране в соответствии с макетом, который был создан с использованием дерева рендеринга. Этот процесс известен как растеризация , то есть процесс рисования экрана. Большинство браузеров используют ЦП для выполнения этой задачи, но, поскольку это процесс, который включает в себя повторяющуюся обработку, для получения лучших результатов его можно передать на ГП.
Операция рисования происходит в многоуровневом формате, и механизм визуализации создает несколько слоев элементов для создания веб-страницы. Эта многоуровневая структура помогает браузеру быстрее вносить изменения, когда пользователь взаимодействует с веб-страницей.
После того, как все слои созданы, механизм визуализации отправляет эту информацию в пользовательский интерфейс, отображая веб-страницу на экране. Этот процесс известен как создание веб-страницы и является последним шагом, выполняемым механизмом рендеринга.
Этот процесс создания веб-страницы из битов данных известен как критический путь отрисовки и является основным фактором, определяющим производительность любой веб-страницы, которую вы посещаете в Интернете.
Теперь, когда механизм рендеринга отрисовал веб-сайт в браузере, вам может быть интересно, что мы нигде не использовали Javascript. Это связано с тем, что Javascript является независимым объектом, который отвечает за внесение изменений в структуру DOM, которая добавляет интерактивности веб-сайту.
Добавление интерактивности на веб-сайты с помощью Javascript
После того, как механизм рендеринга завершил рендеринг веб-сайта в пользовательском интерфейсе, пользователь может видеть веб-сайт, но он еще не является интерактивным. Это означает, что если на веб-странице есть кнопка, которая показывает пользователю подсказку, она не будет работать, а Javascript появится на картинке.
Javascript также может вносить изменения в структуру DOM, созданную механизмом рендеринга, и даже создавать новые узлы DOM и подключать их к структуре DOM. Этот код Javascript запускается виртуальной машиной в браузере, известной как механизм Javascript.
Механизм Javascript и структура DOM не используют одну и ту же память и являются независимыми объектами. Тем не менее, движок Javascript может взаимодействовать со структурой DOM и запускаться, когда на странице происходит определенное событие. Это различие между двумя пробелами помогает браузеру отображать страницы с помощью механизма Javascript и отображать их при возникновении события.
Javascript лежит в основе каждого используемого вами веб-сайта и отвечает за обработку вводимых пользователем данных и их отправку на удаленный сервер, на котором работает веб-сайт. Скриптовый характер Javascript — это то, что делает браузеры чрезвычайно универсальными, позволяя веб-сайтам работать одинаково как на смартфоне, так и на настольных компьютерах, поскольку браузер может интерпретировать код Javascript в механизме Javascript.
В те дни, когда был изобретен Интернет, все браузеры отображали веб-страницы, и при этом не было задействовано много Javascript. Удаленный сервер выполнял большую часть обработки, а движок Javascript мало что делал на веб-странице. Из-за этого большой объем информации должен был передаваться между сервером и браузером, и такая архитектура подходила для Интернета, когда страницы не были такими сложными и интерактивными.
Тем не менее, современный Интернет не может работать на той же архитектуре, поскольку это сильно замедляет работу веб-сайтов. Следовательно, и браузер, и удаленный сервер должны работать симбиотически, чтобы обеспечить лучший пользовательский интерфейс. Это означает, что браузер больше не отвечает только за отображение веб-страниц, но также за обработку большого количества данных, и все это делает движок Javascript.
Расшифровка движка Javascript
Javascript дебютировал в 1996 году и был создан Бренданом Эйхом всего за 10 дней. Он был частью Netscape Navigator версии 3 и был создан как язык сценариев, который можно было интерпретировать в самом браузере.
Поскольку Javascript был создан как язык, который мог обрабатываться интерпретатором в веб-браузере, он не создавал машинный код для работы на ЦП, что делало язык чрезвычайно универсальным.
Тем не менее, эта универсальная природа Javascript имела компромисс; низкая производительность. Чтобы решить эту проблему, JIT-компиляторы пришли к Javascript, что сделало их очень быстрыми. Использование JIT-компиляторов сделало Javascript настолько быстрым, что он работает на сервере, на котором размещены ваши веб-сайты.
Теперь, когда мы знакомы с ролью Javascript в работе веб-сайта, мы можем подробно разобраться в том, как работает механизм Javascript.
Как работает движок Javascript?
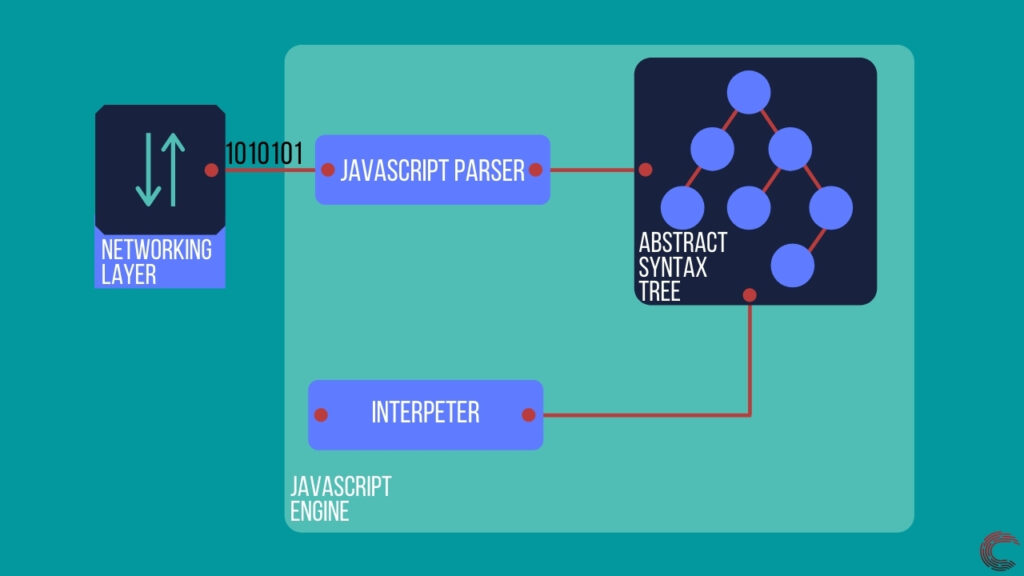
Точно так же, как сетевой уровень извлекает HTML и CSS в виде байтов для механизма рендеринга, он также извлекает код Javascript и передает его механизму Javascript.
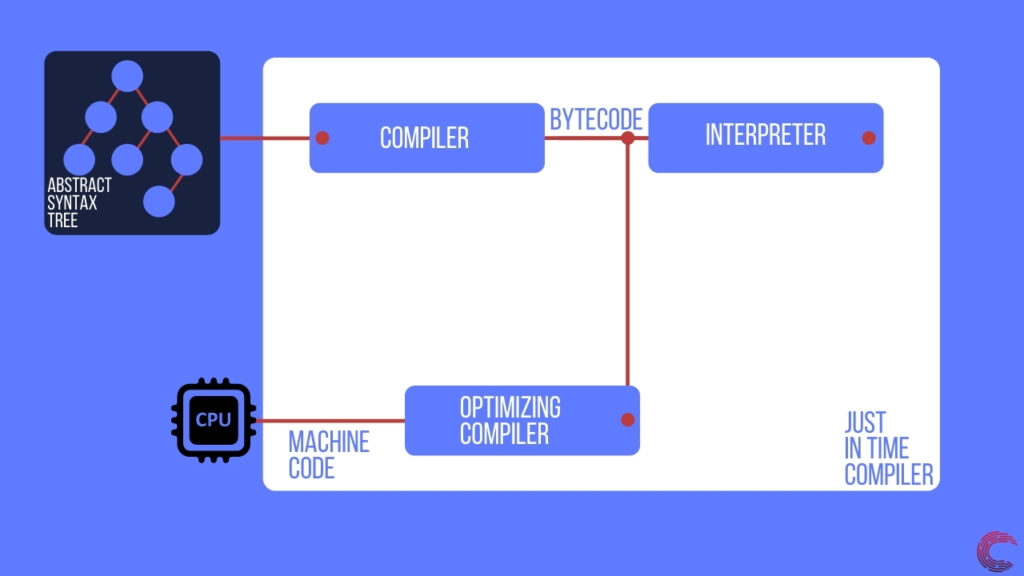
Как только движок получает код Javascript, он отправляет его синтаксическому анализатору, который создает абстрактное синтаксическое дерево (AST). Это дерево является логическим представлением кода Javascript, который может быть запущен компилятором. Компилятор преобразует дерево в промежуточный язык (байт-код), который может выполняться интерпретатором построчно.
Это выполнение Javascript используется, когда код в скрипте не выполняет повторяющиеся задачи (например, цикл). Если в коде Javascript есть обширные циклы, то движок пытается оптимизировать этот код и запускать его на ЦП устройства. Поскольку код выполняется на ЦП машины, он работает намного быстрее по сравнению с интерпретируемой версией.
Для создания машинного кода механизм Javascript использует оптимизирующий компилятор. Этот компилятор принимает байт-код, сгенерированный компилятором, и преобразует его в машинный код для конкретного устройства.
Как только у движка есть оптимизированный машинный код, он может запускать скрипт на невероятно высокой скорости, используя как процессор, так и интерпретатор Javascript.
Заглядывая в будущее
Хотя браузеры сейчас супер мощные, постоянно появляются инновации, которые еще больше ускоряют просмотр. Одним из таких нововведений является веб-сборка, которая используется с Javascript, чтобы сделать выполнение кода еще быстрее за счет использования кода уровня сборки.
Мало того, браузеры догоняют достижения в области машинного обучения и искусственного интеллекта. С такими библиотеками, как Tensorflow, переход на Javascript означает только то, что браузеры обязательно станут умнее в будущем; дальнейшее улучшение пользовательского опыта, который они предлагают.
2020-11-20T09:55:13
Вопросы читателей