В Windows 10 вы можете вернуться к предыдущей версии Microsoft Edge по мере необходимости, и вы можете выполнить эту задачу двумя разными способами, и в этом руководстве вы узнаете, как это сделать. В отличие от устаревшей версии, версия Microsoft Edge для Chromium периодически получает обновления от операционной системы на неопределенный срок, чтобы предоставлять исправления, улучшения и новые функции так же своевременно, как и другие современные браузеры (например, Firefox и Chrome).
Единственная проблема с этим подходом заключается в том, что иногда новые версии Microsoft Edge могут развертываться с ошибками или вызывать неожиданные проблемы. Хотя простого способа удалить браузер в Windows 10 больше нет, есть возможность вернуться к предыдущей версии, которая позволяет устранить проблемы или вернуться к более ранней версии, когда все работало правильно, с использованием файла .msi или групповой политики.
Эта функция предназначена для организаций, но любой может использовать ее для отката к предыдущей версии Microsoft Edge.
В этом руководстве вы узнаете о двух поддерживаемых методах перехода на более старую версию Microsoft Edge в Windows 10.
Откат к предыдущей версии Edge вручную
Начиная с версии 86, вы можете понизить версию Microsoft Edge для Chromium, загрузив и установив файл .msi, но сначала вы должны отключить обновления для браузера, что требует установки дополнительных шаблонов групповой политики для управления настройками браузера.
Шаг 1. Установите шаблоны групповой политики Microsoft Edge
Чтобы установить шаблоны групповой политики для управления Microsoft Edge, выполните следующие действия:
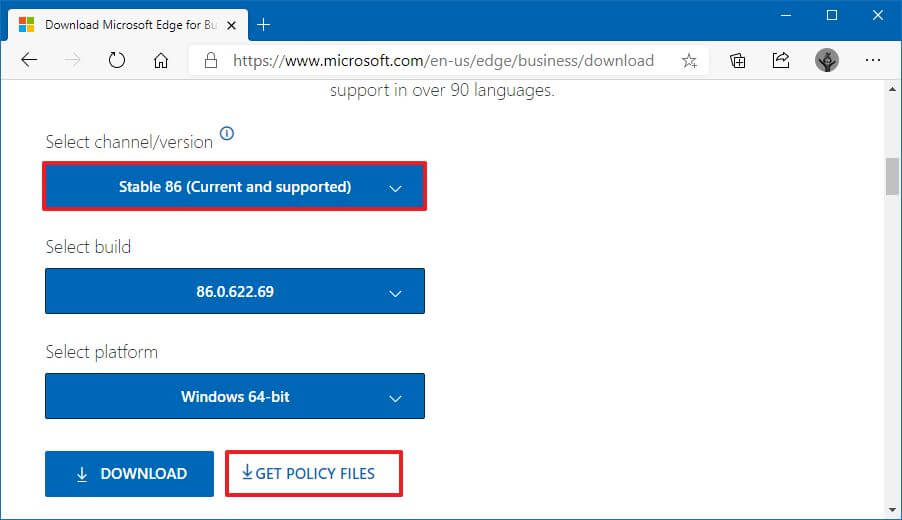
- Откройте веб-сайт Microsoft Edge для бизнеса.
- В разделе «Файл политики» нажмите кнопку «Загрузить».
- Выберите версию Microsoft Edge. (Обычно вы хотите использовать последнюю доступную стабильную версию.)
- Выберите сборку (доступна последняя версия).
- Выберите платформу. Например, Windows 64-битная.
- Щелкните параметр Получить файлы политики.

- Нажмите кнопку «Принять и загрузить».
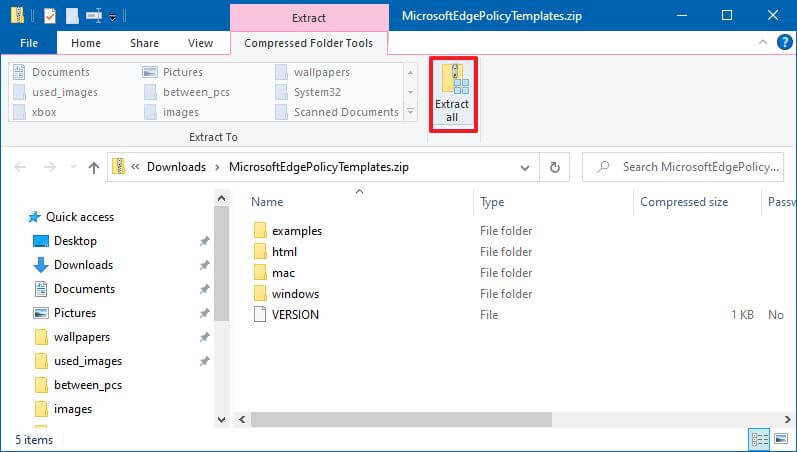
- Дважды щелкните, чтобы открыть файл MicrosoftEdgePolicyTemplates.zip.
- Нажмите кнопку «Извлечь все» на вкладке «Инструменты для сжатых папок».

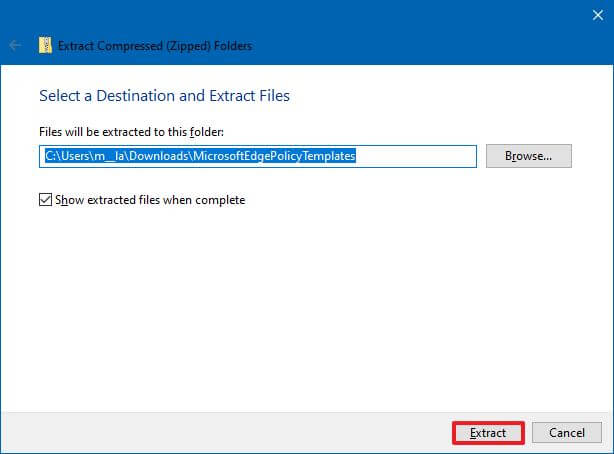
- (Необязательно) Выберите место для извлечения файлов.
- Установите флажок Показывать извлеченные файлы по завершении.
- Щелкните кнопку Извлечь.

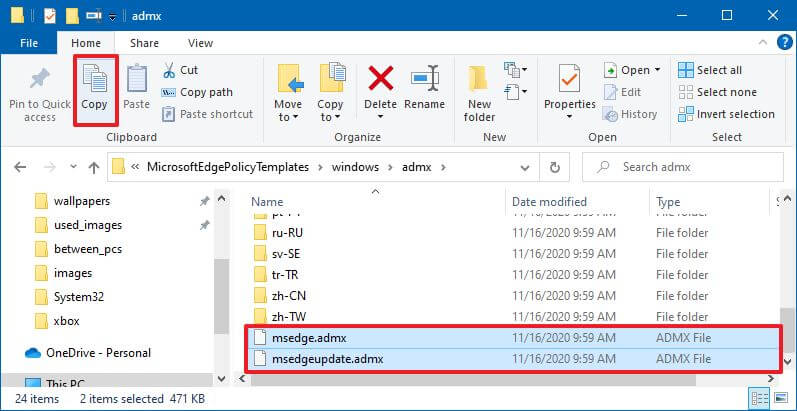
- Просмотрите следующий путь внутри (извлеченной) папки «MicrosoftEdgePolicyTemplates»:
windowsadmx
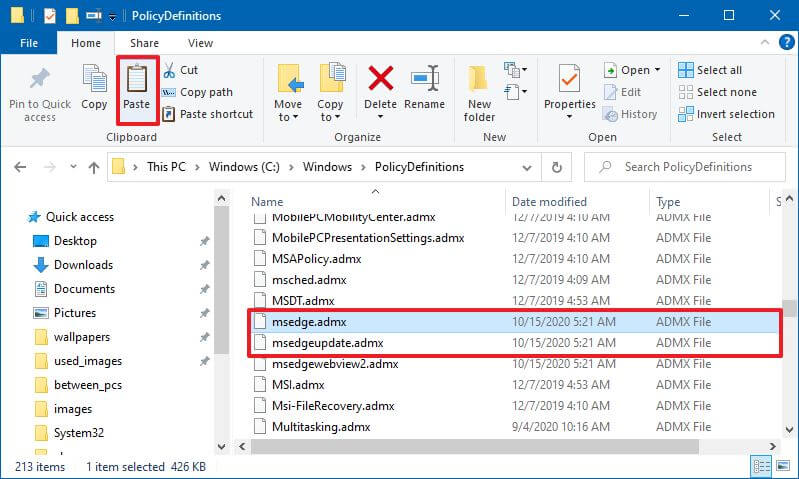
- Выберите файлы msedge.admx и msedgeupdate.admx и нажмите кнопку « Копировать » на вкладке «Главная».

- Перейдите по следующему пути:
C:WindowsPolicyDefinitions
- Нажмите кнопку «Вставить» на вкладке «Главная».

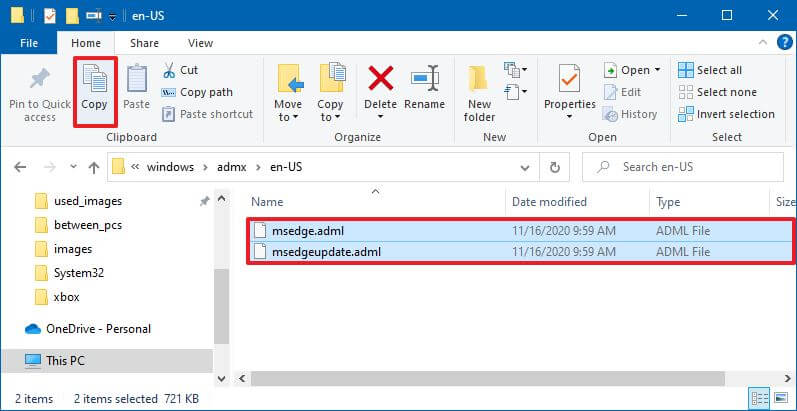
- В папке «admx» внутри папки «MicrosoftEdgePolicyTemplates» откройте языковую папку, которая представляет ваш язык. Например, en-US.
- Выберите файлы msedge.adml и msedgeupdate.adml и нажмите кнопку «Копировать» на вкладке «Главная».
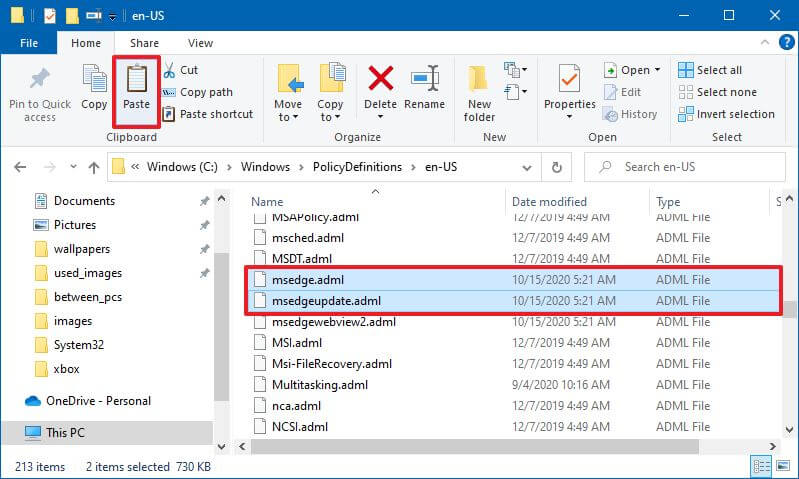
- Перейдите по следующему пути, соответствующему вашему языку:
C:WindowsPolicyDefinitionsen-US
В приведенной выше команде обязательно измените en-US для папки, соответствующей вашему языку.
- Нажмите кнопку «Вставить» на вкладке «Главная».
Выполнив эти шаги, вы можете продолжить отключение обновлений для Microsoft Edge.
Шаг 2. Отключите обновления Microsoft Edge
Чтобы отключить обновления для Microsoft Edge, выполните следующие действия:
- Откройте Пуск.
- Найдите
gpedit и щелкните верхний результат, чтобы открыть редактор групповой политики.
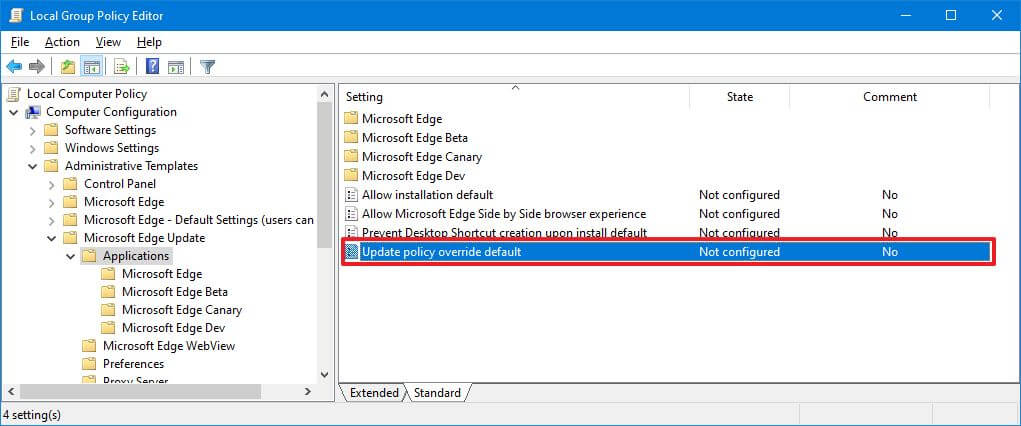
- Просмотрите следующий путь:
Конфигурация компьютера> Административные шаблоны> Обновление Microsoft Edge> Приложения> Microsoft Edge
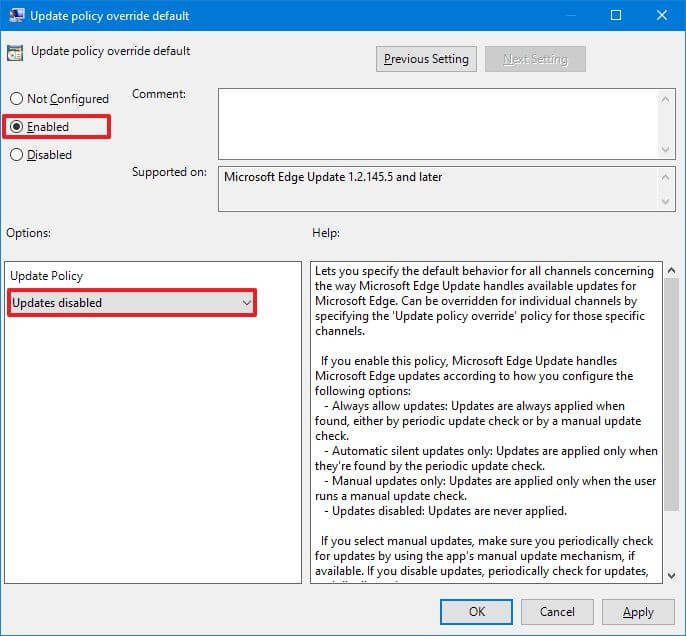
- Дважды щелкните политику переопределения политики обновления .Обновить политику переопределения по умолчанию.
 Совет: если вы хотите отключить обновления для всех каналов (стабильный, бета-версия, для разработчиков и Canary) браузера, вы можете настроить политику переопределения политики обновления Computer Configuration > Administrative Templates > Microsoft Edge Update.
Совет: если вы хотите отключить обновления для всех каналов (стабильный, бета-версия, для разработчиков и Canary) браузера, вы можете настроить политику переопределения политики обновления Computer Configuration > Administrative Templates > Microsoft Edge Update.
- Выберите вариант Включено.
- В разделе «Параметры» используйте раскрывающееся меню и выберите параметр «Обновление отключено».

После выполнения этих шагов вы можете продолжить загрузку установщика для более старой версии Microsoft Edge, которую вы планируете понизить.
Шаг 3. Загрузите старую версию Microsoft Edge
Чтобы загрузить более старую версию Microsoft Edge, выполните следующие действия:
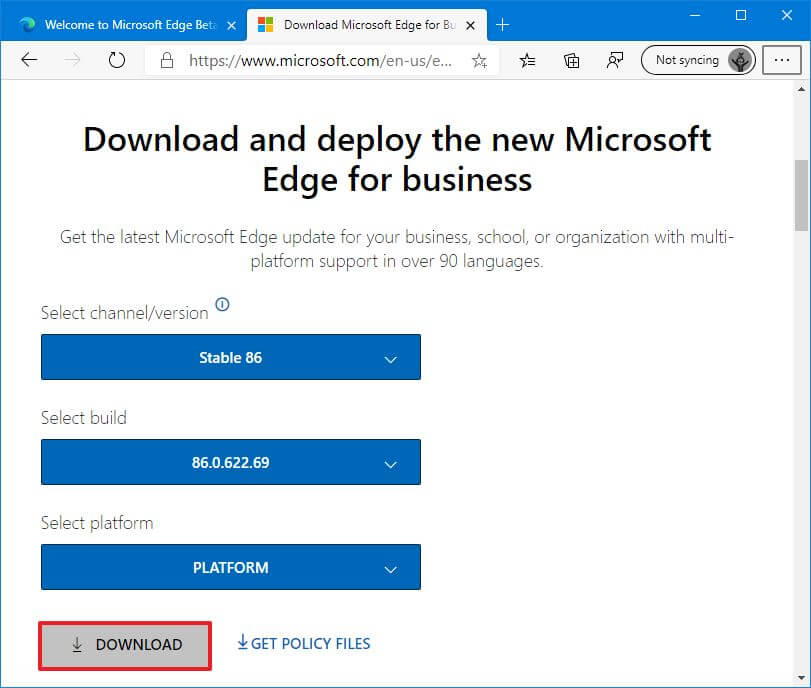
- Откройте веб-сайт загрузки Microsoft Edge.
- Выберите старую версию, сборку и платформу.
- Щелкните кнопку Загрузить.

- Нажмите кнопку «Принять и загрузить».
После выполнения этих шагов вы можете использовать файлы с приведенными ниже инструкциями для отката к предыдущей версии Microsoft Edge.
Шаг 4. Откат к предыдущей версии Microsoft Edge
Чтобы вернуться к более ранней версии Microsoft Edge, выполните следующие действия:
- Откройте Пуск .
- Найдите командную строку , щелкните правой кнопкой мыши верхний результат и выберите параметр « Запуск от имени администратора» .
- Введите следующую команду, чтобы изменить местоположение папки, в которой находится установщик, и нажмите Enter:
cd C:PATHTOMSI-INSTALLER
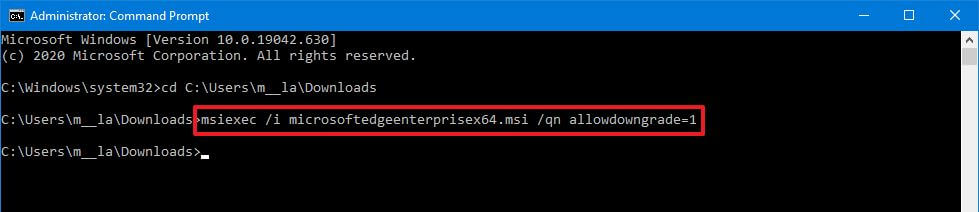
- Введите следующую команду, чтобы понизить версию Edge, и нажмите Enter :
C:PATHTOMSI-INSTALLER>msiexec /I FileName.msi /qn ALLOWDOWNGRADE=1
В команде обязательно обновите C: PATH TO MSI-INSTALLER, указав путь к месту установки. Также замените FileName.msi фактическим именем установщика.
Например, эта команда переводит Edge на более раннюю версию MicrosoftEdgeEnterpriseX64.msi версии 84, расположенной в папке загрузок:
C:Usersm__laDownloads>msiexec /I MicrosoftEdgeEnterpriseX64.msi /qn ALLOWDOWNGRADE=1

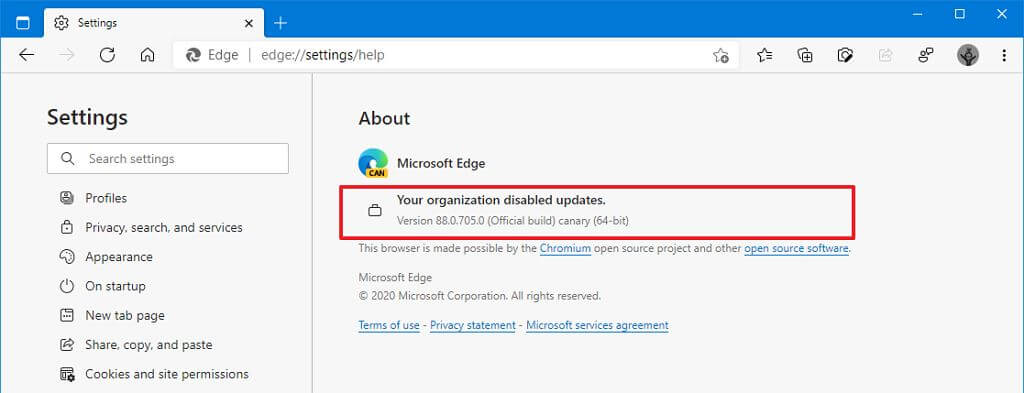
- Снова откройте Microsoft Edge.
- Нажмите кнопку меню «Настройки и прочее» (многоточие) и выберите «Настройки».
- Щелкните О Microsoft Edge.
- Убедитесь, что установлена более старая версия.

После того, как вы выполните эти шаги, текущая версия браузера будет удалена, а более старая версия будет установлена в Windows 10.
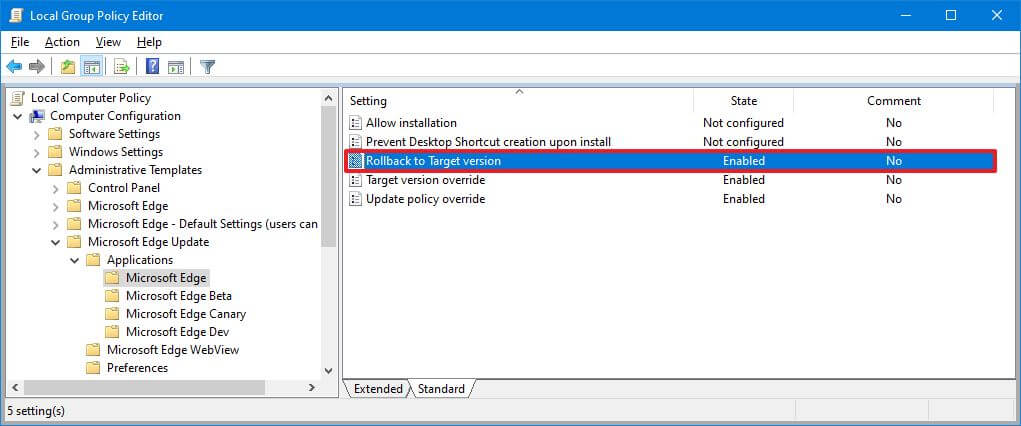
Откат к предыдущей версии Edge с групповой политикой
Вы также можете выполнить постепенный переход на более раннюю версию, настроив три конкретных объекта групповой политики. Этот метод также требует установки шаблонов политики для управления браузером с помощью редактора групповой политики. Если у вас не установлены шаблоны, обратитесь к предыдущим шагам, чтобы загрузить и установить шаблоны политик Microsoft Edge в Windows 10.
Чтобы откатить Microsoft Edge к предыдущей версии с помощью групповой политики, выполните следующие действия:
- Откройте Пуск.
- Найдите gpedit и щелкните верхний результат, чтобы открыть редактор групповой политики.
- Просмотрите следующий путь:
Конфигурация компьютера> Административные шаблоны> Обновление Microsoft Edge> Приложения> Microsoft Edge
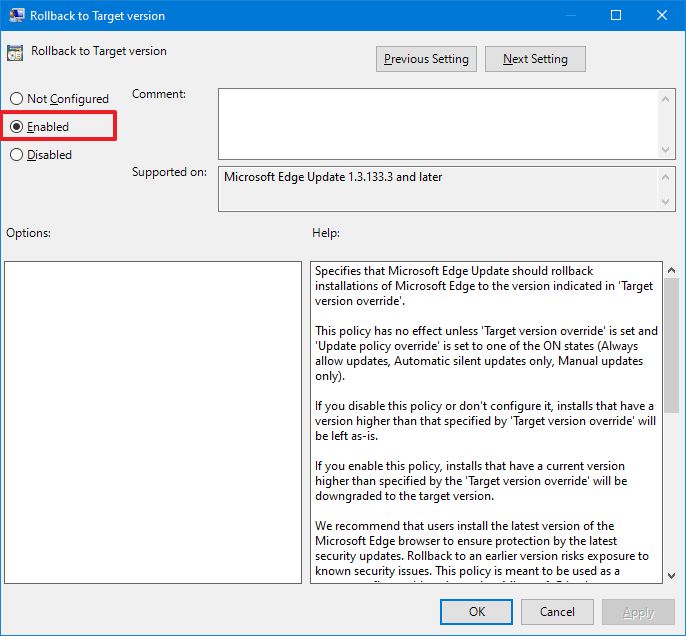
- Дважды щелкните политику отката к целевой версии.
- Выберите вариант Включено.
- Нажмите кнопку Применить.
- Щелкните кнопку ОК.
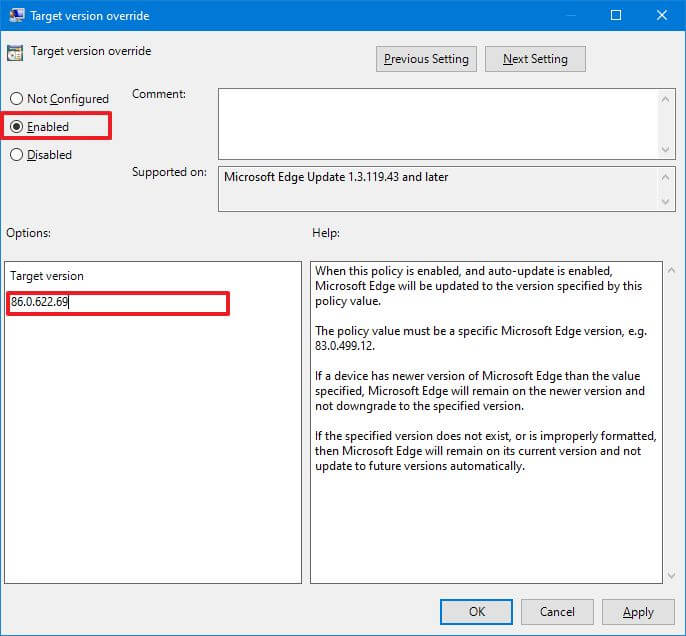
- Дважды щелкните политику переопределения целевой версии.
- Выберите вариант Включено.
- В разделе «Параметры» в поле Целевая версия укажите точную версию Microsoft Edge, которую вы хотите откатить. Например, 86.0.622.69.
- Нажмите кнопку Применить.
- Щелкните кнопку ОК.
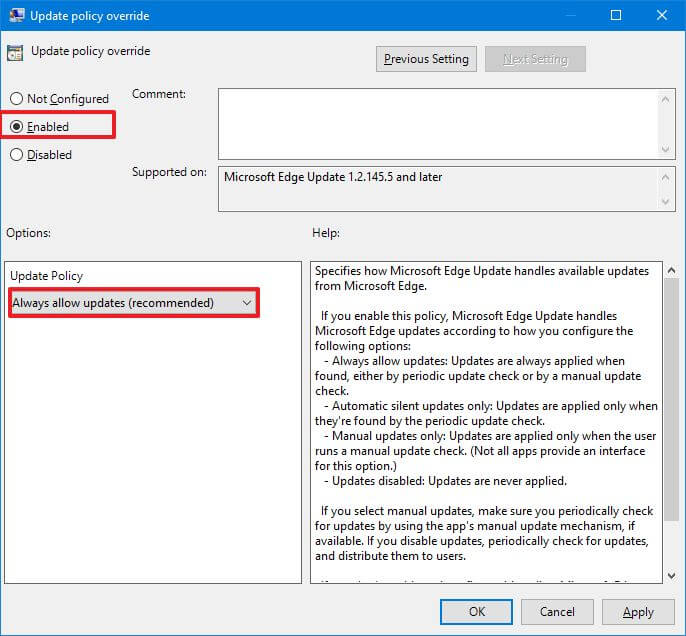
- Дважды щелкните политику переопределения политики обновления.
- Выберите вариант Включено.
- В разделе «Параметры» используйте раскрывающееся меню и выберите параметр «Всегда разрешать обновления».
- Нажмите кнопку Применить.
- Щелкните кнопку ОК.
После выполнения этих шагов, в следующий раз, когда Microsoft Edge автоматически проверяет наличие обновлений (обычно каждые десять часов), он должен загрузить и установить старую версию браузера.
Хотя существуют поддерживаемые способы перехода на более раннюю версию Microsoft Edge, эти параметры предназначены только для устранения проблем или временного решения конкретной проблемы. Всегда рекомендуется использовать браузер с последними обновлениями, чтобы убедиться, что вы используете наиболее безопасную доступную версию.
2020-11-24T10:05:45
Вопросы читателей


 Совет: если вы хотите отключить обновления для всех каналов (стабильный, бета-версия, для разработчиков и Canary) браузера, вы можете настроить политику переопределения политики обновления Computer Configuration > Administrative Templates > Microsoft Edge Update.
Совет: если вы хотите отключить обновления для всех каналов (стабильный, бета-версия, для разработчиков и Canary) браузера, вы можете настроить политику переопределения политики обновления Computer Configuration > Administrative Templates > Microsoft Edge Update.