Вам нужно знать, как печатать в Windows 10 или Windows 7 из любого приложения, которое вы можете использовать? Хотя печать не так проста, как должна быть, но и не слишком сложна. Все зависит от версии Windows, которую вы используете, от того, используете ли вы приложения, предназначенные для сенсорных экранов или рабочего стола, и так далее. Чтобы упростить задачу, вот наше руководство, в котором рассказывается обо всех способах печати из Windows с помощью сенсорного экрана или мыши и клавиатуры.
ПРИМЕЧАНИЕ. Это руководство применимо к Windows 10 и Windows 7. Мы предполагаем, что на вашем ПК уже установлен и настроен принтер.
1. Как печатать в Windows с помощью клавиатуры: CTRL + P
Этот метод работает как в настольных программах, так и в приложениях из Microsoft Store. В приложении, которое вы хотите использовать, откройте то, что вы хотите распечатать, и нажмите CTRL + P на клавиатуре. Это сочетание клавиш для печати вызывает диалоговое окно « Печать», в котором вы можете указать способ печати. Этот метод особенно полезен при работе с приложениями, в которых нет легкодоступных меню для параметров печати.

ПРИМЕЧАНИЕ. CTRL + P отображает диалоговое окно «Печать» только в приложениях, поддерживающих печать. В приложениях, которые этого не делают, эта команда не действует.
2. Как печатать в Windows из настольных приложений, в которых есть меню «Файл».
Многие настольные приложения имеют меню «Файл». Обычно он включает параметр «Печать», если приложение, которое вы используете, предназначено для печати. Если вы хотите распечатать из такого приложения, щелкните или коснитесь «Файл», а затем выберите «Печать». На следующем снимке экрана вы можете увидеть пример того, как это меню выглядит в Adobe Reader:
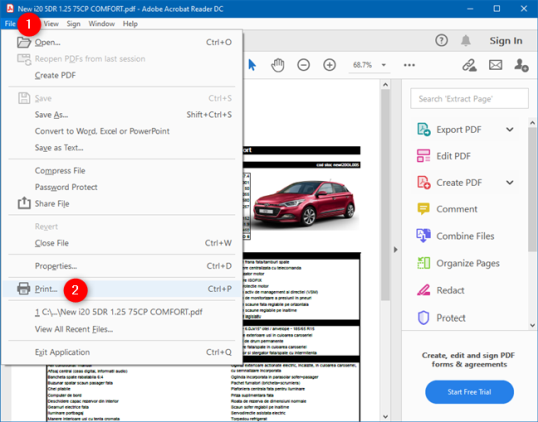
Как и при нажатии Ctrl + P, вам обычно показывают предварительный просмотр печати вместе с несколькими вариантами печати. Настройте вещи по своему усмотрению, а затем щелкните или коснитесь Печать.
3. Как печатать в Windows из настольных приложений с лентой (Microsoft Office)
Некоторые настольные приложения имеют пользовательский интерфейс с лентой вместо стандартных меню. Известными примерами таких приложений являются пакет Microsoft Office, WordPad и Paint. Если в используемом вами настольном приложении есть лента, щелкните вкладку Файл на ленте.

Откроется список параметров, которые должны включать печать.
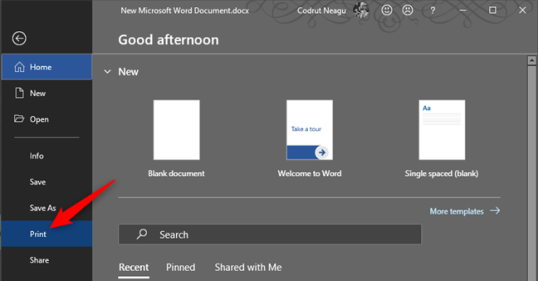
Настройте способ печати файла, а затем щелкните или коснитесь «Печать».
4. Как печатать в Windows 10 из приложений из Microsoft Store.
Приложения из Microsoft Store в Windows 10 обычно включают кнопку «Настройки и многое другое» (…) или кнопку «гамбургер» (☰). Его часто помещают в верхнем левом или правом углу. Если вы щелкните или коснитесь его, откроется меню с параметрами, которые должны включать Печать. Ниже вы можете увидеть снимок экрана из приложения OneNote для Windows 10.
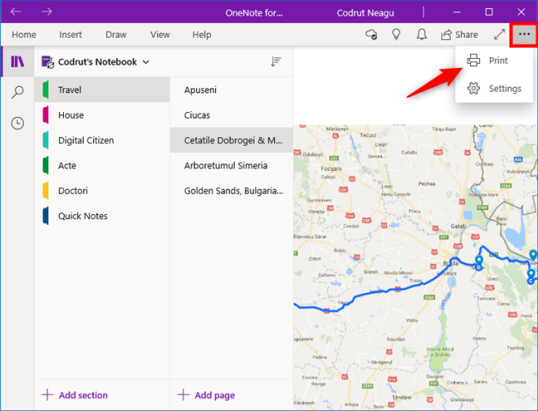
Щелкните или коснитесь «Печать», измените параметры печати и нажмите «Печать».
5. Как печатать в Windows 10 из приложения «Фото»
Вам интересно, как печатать из приложения «Фото» на ПК или устройстве с Windows 10? В приложении «Фото» откройте изображение, которое хотите распечатать. Затем нажмите или коснитесь кнопки принтера, показанной в верхней правой части окна. Если вы его не видите, либо увеличьте окно, чтобы появилась кнопка принтера, либо нажмите/коснитесь кнопки «Настройки и другое» (☰), а затем выберите «Печать».
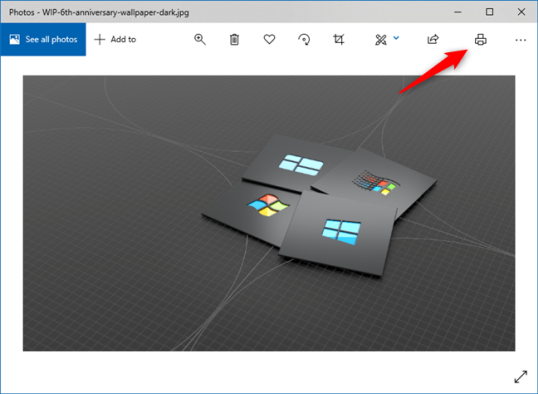
Выберите предпочтительные параметры печати в диалоговом окне печати и затем нажмите «Печать», чтобы отправить фотографию на принтер. Это оно!
6. Как печатать в Windows 10 прямо из проводника (документы и изображения)
Если вы установили и настроили принтер по умолчанию, вы можете печатать документы и изображения прямо из проводника . В Windows 10 откройте проводник и перейдите к файлу, который хотите распечатать. Выберите его и перейдите на вкладку «Поделиться» на ленте. В группе «Отправить» нажмите или коснитесь кнопки «Печать».
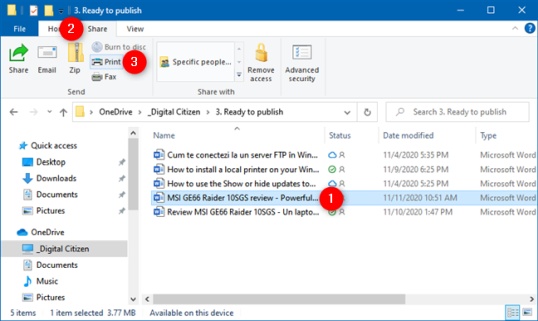
Файл отправляется прямо на принтер, где он распечатывается с использованием настроек печати по умолчанию.
7. Как печатать из Windows 7 прямо из проводника Windows (документы и изображения)
Точно так же, если вы настроили принтер по умолчанию на своем компьютере с Windows 7, вы можете распечатать любой документ или изображение прямо из проводника Windows. Вот как это происходит:
Откройте проводник Windows и найдите файл, который вы собираетесь распечатать. Выберите его и нажмите кнопку «Печать» на панели инструментов в верхней части окна.
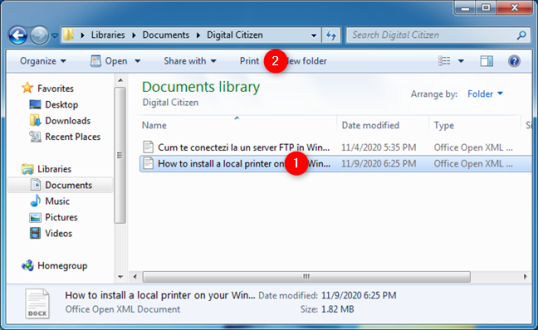
Затем Windows 7 отправляет выбранный файл непосредственно на принтер, где он распечатывается с использованием настроек печати по умолчанию.
Вы знаете другие способы печати из Windows?
Теперь вы знаете, как печатать в Windows. Это наиболее распространенные методы, которые вы можете использовать для печати документов, изображений и любого контента из приложений. Если вы знаете других, не стесняйтесь сообщить нам об этом в комментариях ниже.