Поддерживать связь с друзьями и семьей стало проще благодаря приложениям для обмена сообщениями, таким как Telegram. Однако могут быть случаи, когда вы через некоторое время хотите написать кому-то, но его контактная информация изменилась. Есть ли способ искать людей в Telegram?
Хотя вы можете искать людей в Telegram, вы можете не видеть их контактные данные, например номера мобильных телефонов. Кроме того, они могут не увидеть, что вы их ищете. В этом случае, как только вы найдете пользователя, представьтесь при отправке сообщения, чтобы вас по ошибке не заблокировали. С этим покончено, давайте начнем.
1. Использование номера телефона
Найти человека по номеру телефона – один из самых простых способов поиска людей. Это касается любого приложения, включая Telegram. Обратите внимание, что некоторые международные телефонные номера могут не отображаться, если вы не введете перед ними полный код страны. Чтобы сделать это, выполните следующие шаги.
Примечание. Вы также можете использовать эти шаги в настольном приложении Telegram. Нажмите на строку поиска, чтобы начать.
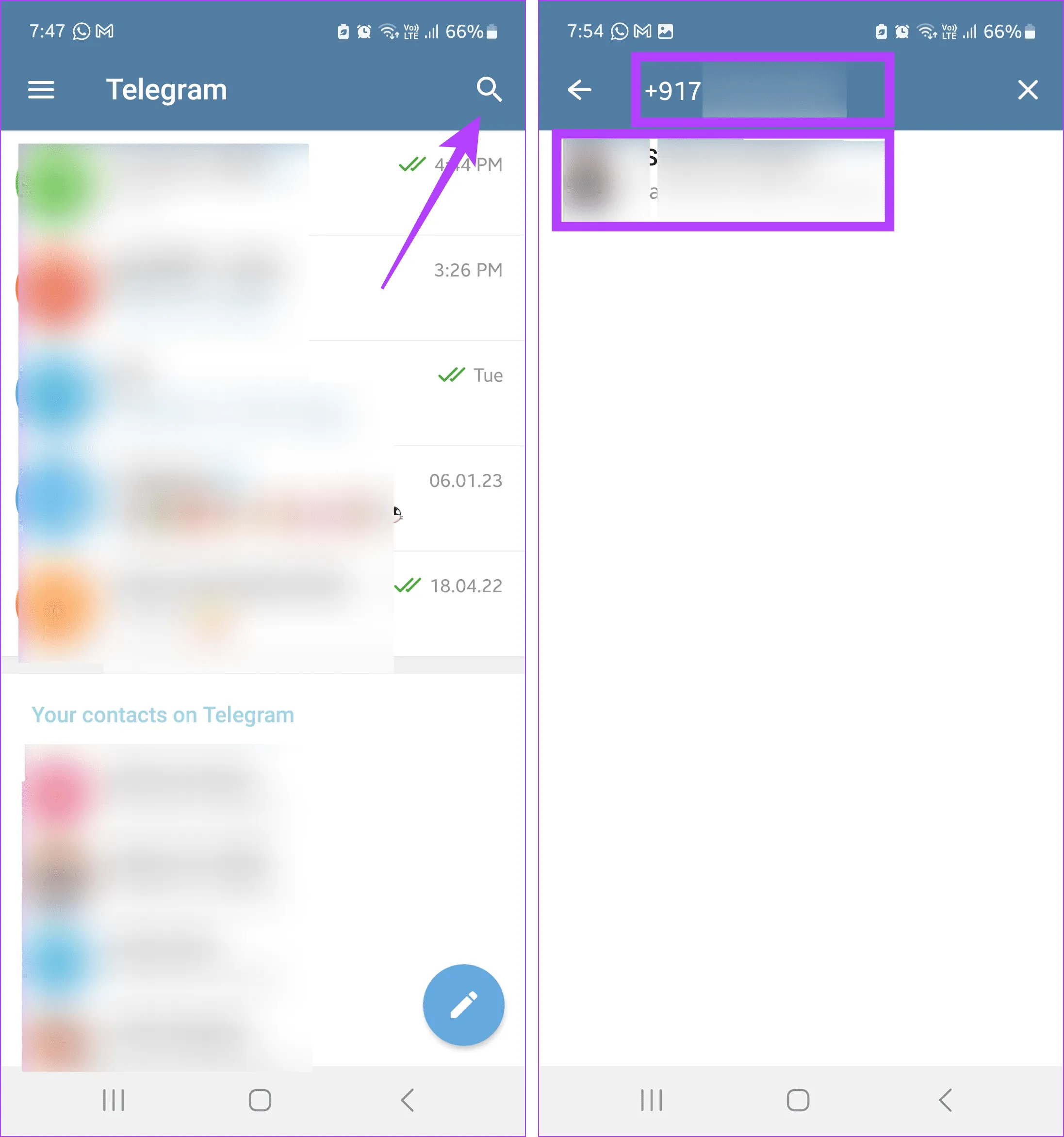
Шаг 1. Откройте приложение Telegram для Android и нажмите значок лупы в правом верхнем углу. Подождите, пока появится панель поиска.
Если вы используете приложение Telegram для iOS, нажмите значок «Написать» в правом верхнем углу. Затем нажмите на строку поиска.
Шаг 2: Здесь введите соответствующий номер телефона. Если он не появляется, введите номер телефона еще раз с кодом страны.
Шаг 3. Если пользователь есть в вашем списке контактов, нажмите на него. Если нет, нажмите на опцию «Добавить».

Как только пользователь будет добавлен в ваши контакты, используйте окно чата в Telegram, чтобы представиться другому пользователю.
2. По имени пользователя
Telegram позволяет создавать имена пользователей, которые можно использовать вместо контактных номеров. Это может не только помочь вашему профилю Telegram выделиться, но и сохранить анонимность при присоединении к группам и каналам. Также удобно найти конкретного человека без его номера телефона.
Кроме того, при поиске по имени пользователя используйте опцию глобального поиска, чтобы увидеть все связанные имена пользователей в Telegram, особенно если у вас есть сомнения. Вот как это сделать.
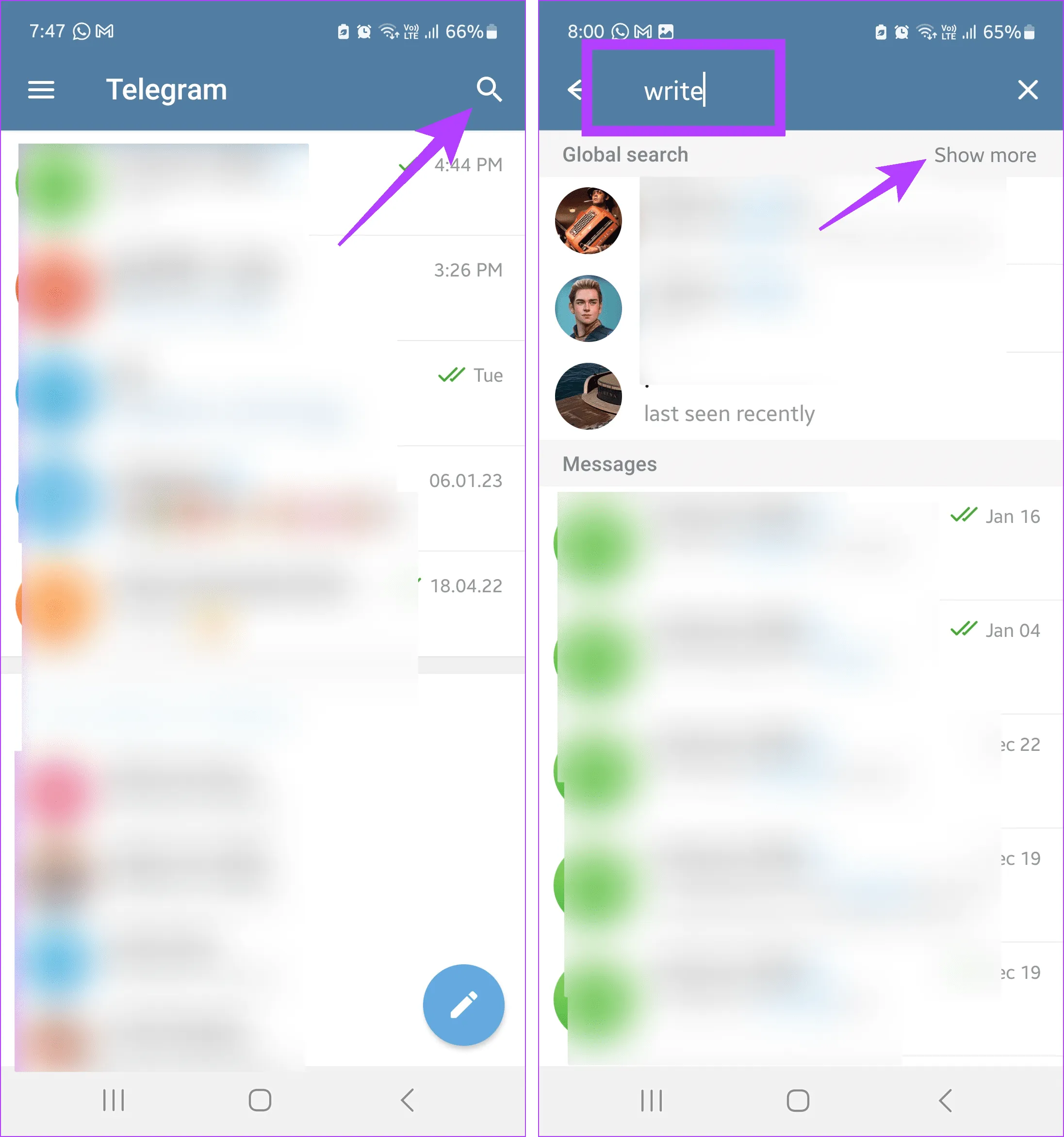
Шаг 1. Откройте приложение Telegram для Android и коснитесь значка лупы.
В приложении Telegram для iOS нажмите значок «Написать». Затем нажмите на строку поиска.
Шаг 2: Теперь введите соответствующее имя пользователя в строке поиска.
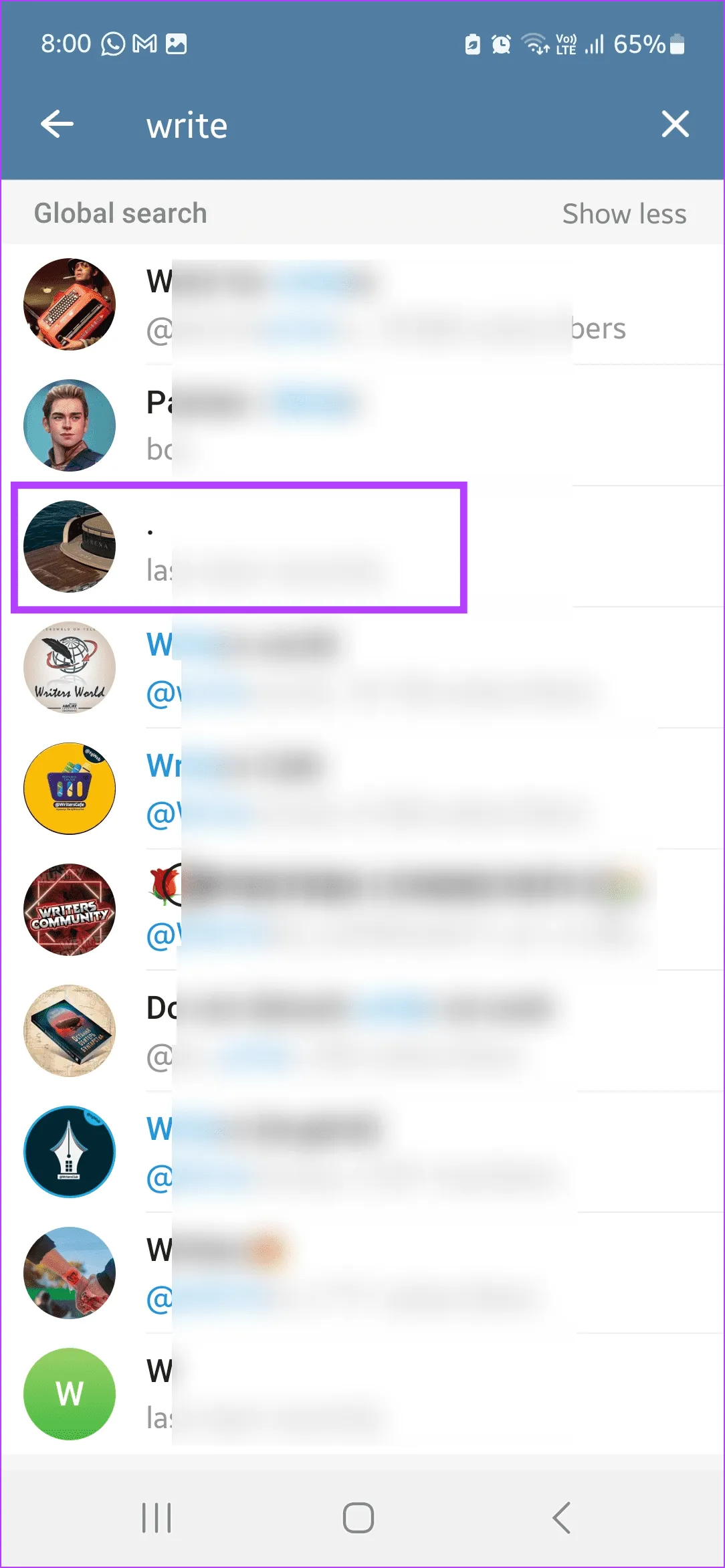
Шаг 3: Если вы нашли пользователя, нажмите на его имя пользователя. В противном случае перейдите в панель глобального поиска и нажмите «Показать больше».
Шаг 4: Просмотрите результаты и нажмите на соответствующее имя пользователя. Должно открыться окно чата в Telegram.
Совет: Группы, которые появляются в результатах поиска, помечаются знаком @ и показывают количество подписчиков. Их можно пропустить при поиске пользователя.

Вы также можете использовать вышеупомянутые шаги, чтобы найти пользователя по его имени с помощью настольного приложения Telegram. Чтобы начать, сразу нажмите на строку поиска.
3. Найдите конкретного человека через общие группы.
Если вы и другой пользователь являетесь частью ваших текущих групп Telegram, вы можете использовать их для поиска этого пользователя. Для этого откройте соответствующую группу и просмотрите участников. Чтобы сделать это, выполните следующие шаги.
Примечание. Ваша группа должна позволять вам просматривать ее участников в Telegram. В противном случае вы не сможете видеть участников группы.
Шаг 1: Откройте Telegram и нажмите на соответствующую группу.
Шаг 2: Здесь нажмите на название группы.

Шаг 3: Затем нажмите на соответствующего участника.
Шаг 4: Здесь нажмите на значок чата.
Откроется окно сообщения. Теперь вы можете отправить пользователю сообщение, представившись, и даже запросить его контактную информацию, поскольку она будет недоступна, пока другой пользователь не одобрит это.
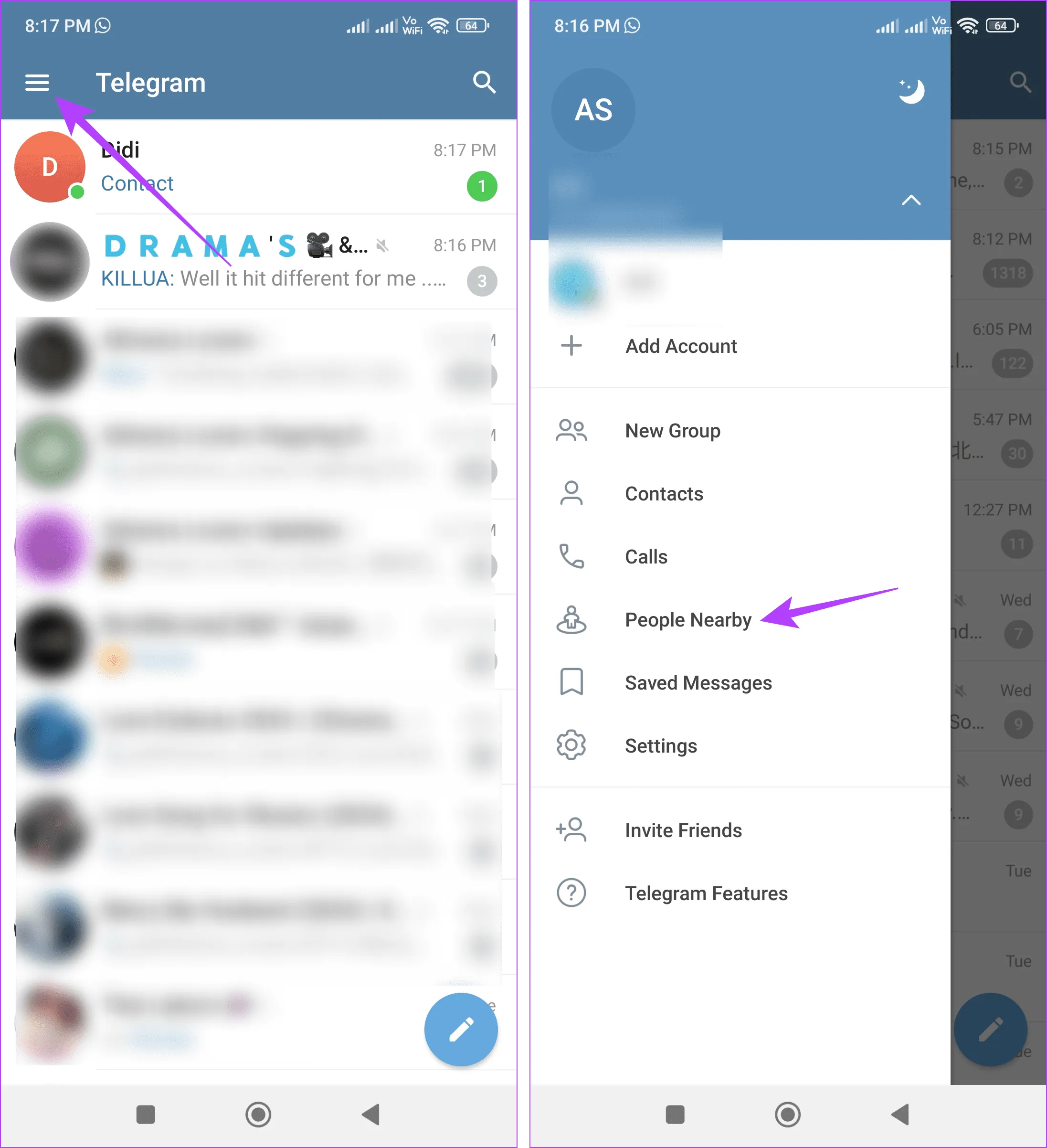
4. Использование людей поблизости
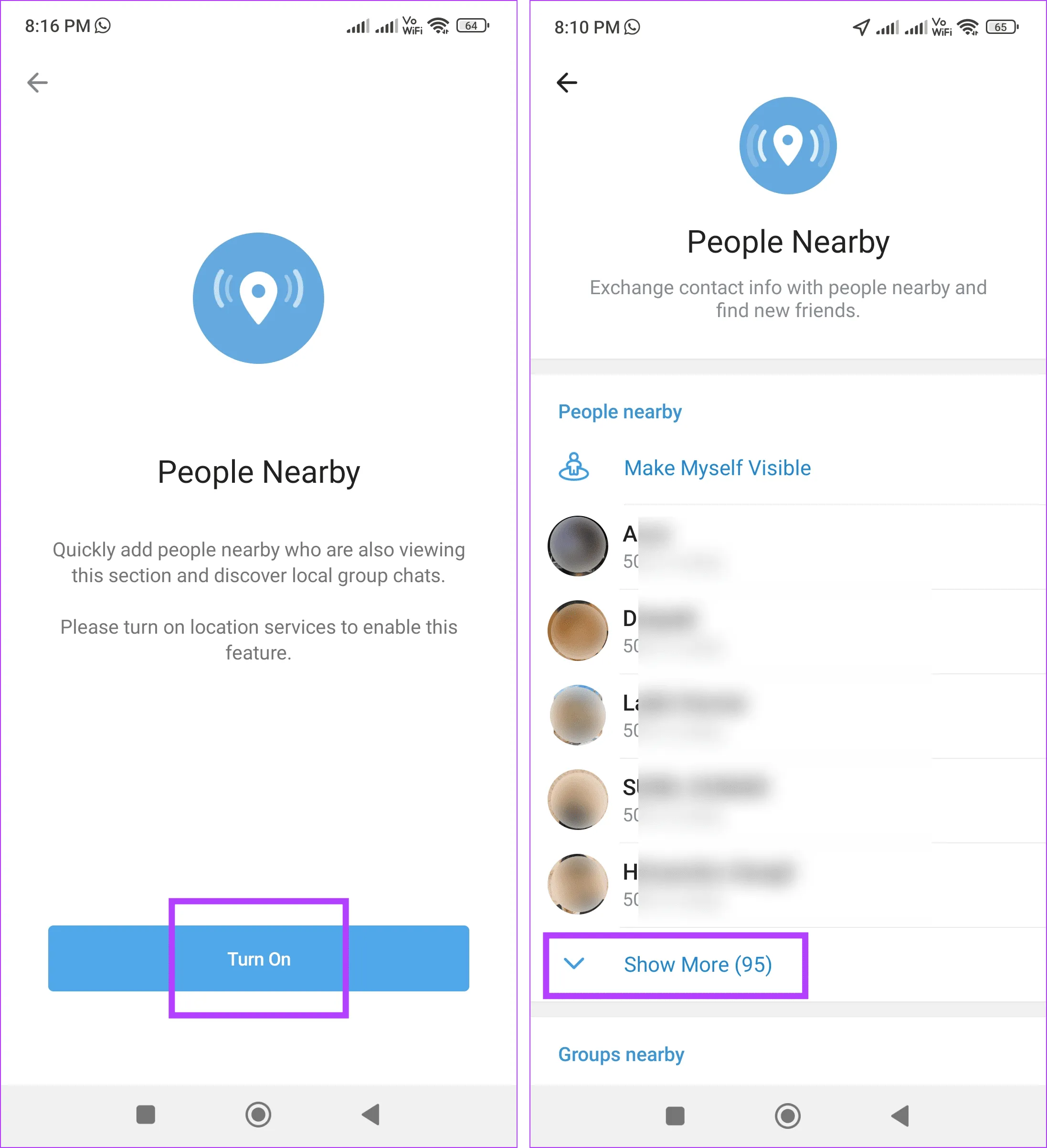
Telegram позволяет вам находить других пользователей Telegram рядом с вашим текущим местоположением. Хотя это отличный способ связаться с другими, он также может быть рискованным. Вот почему эта функция отключена по умолчанию. Однако, если вы пытаетесь найти кого-то поблизости, этот метод может оказаться полезным. Вы можете увидеть их имя, расстояние от вас и изображение профиля.
Обратите внимание, что эта функция будет работать только в том случае, если другой пользователь сделал себя видимым для другого пользователя Telegram поблизости. Кроме того, прежде чем продолжить, вам необходимо включить службы определения местоположения на вашем iPhone или устройстве Android. После этого выполните следующие шаги.
Шаг 1. В приложении Telegram для Android нажмите значок гамбургера в верхнем левом углу.
Или, если вы используете приложение Telegram для iOS, нажмите «Контакты» в левом нижнем углу.
Шаг 2. Здесь, в зависимости от вашего устройства, нажмите «Люди рядом» или «Найти людей поблизости».
Шаг 3: При появлении запроса нажмите «Включить».
Шаг 4. Здесь нажмите «Показать больше», чтобы увидеть всех ближайших пользователей.
Шаг 5: Нажмите на соответствующее имя пользователя из списка.
Шаг 6: Затем нажмите значок чата, чтобы начать разговор.
5. Через карточку контакта
Если кто-то другой отправил вам контактные данные соответствующего пользователя, используйте эту карточку контакта, чтобы добавить его в окно чата в Telegram. Это позволит вам не только увидеть их контактные данные, но и пообщаться с ними в Telegram. Вот как это сделать.
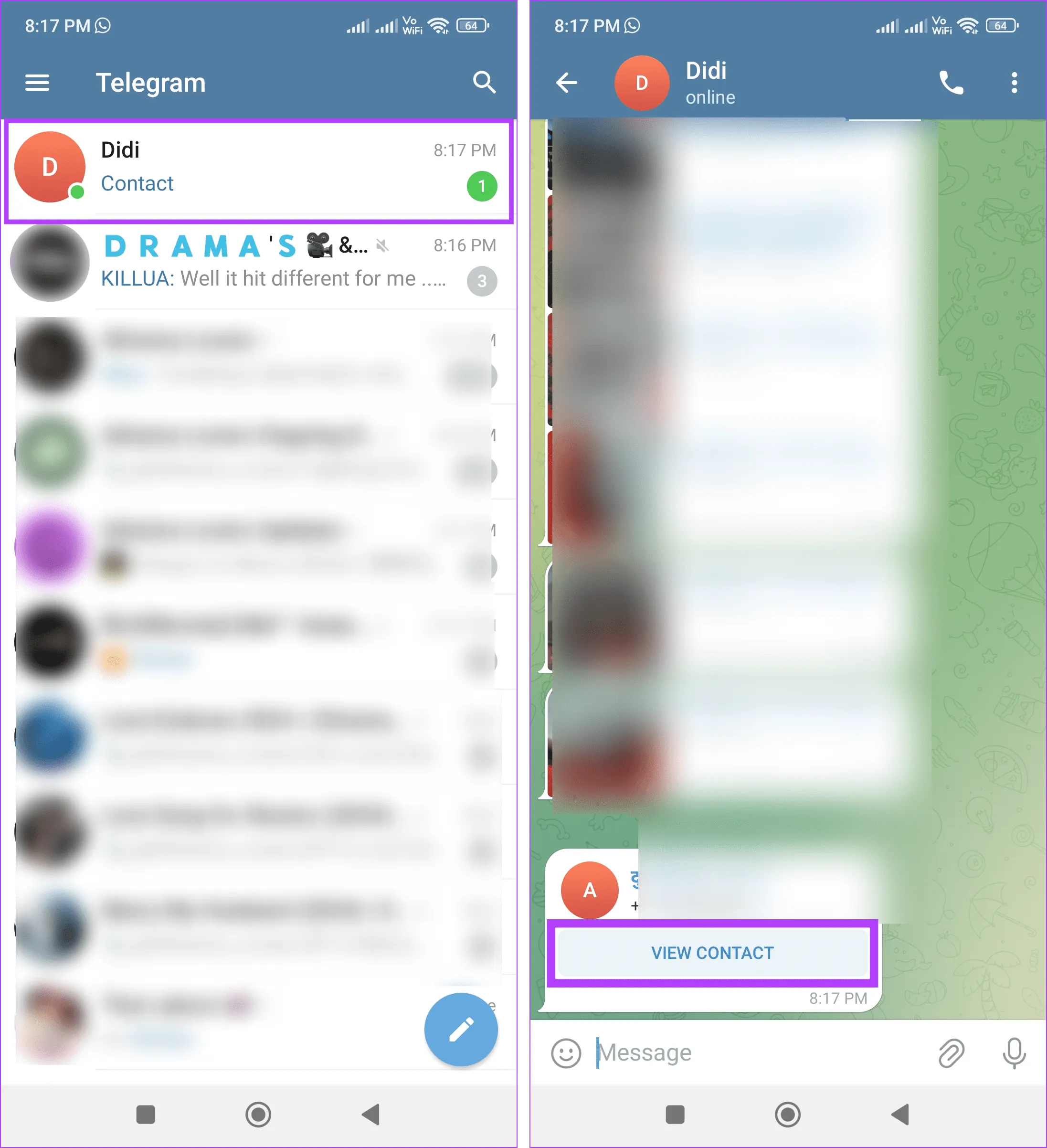
Шаг 1: Откройте Telegram и нажмите на соответствующий чат.
Шаг 2: Здесь нажмите «Просмотреть контакт».
Шаг 3. Как только откроется контактная информация, нажмите значок чата, чтобы отправить им сообщение.

6. Спрашивая другого человека
Пользователь может быть доступен на других платформах, таких как Twitter, Instagram, Facebook и т. д. Поэтому, если вы не можете найти кого-то в Telegram, отправьте ему личное сообщение через эту платформу и попросите его имя пользователя Telegram или связанный с ним номер телефона. После получения используйте его, чтобы пообщаться с ними в Telegram.
Найдите кого-нибудь в Telegram
Хотя Telegram — отличный способ встретиться с друзьями, отсутствие их контактной информации может нарушить эти планы. Итак, мы надеемся, что эта статья помогла вам искать людей в Telegram.
2024-02-22T23:17:47
Вопросы читателей