Запуск сайта WordPress — непростая задача. Одна из проблем WordPress — медленная работа панели администратора. Это повлияет на вашу продуктивность, так как вам придется регулярно работать в админ-панели для публикации контента. Если вы боретесь с медленной панелью администратора, вот несколько причин и советов, как ускорить работу. Если вы новичок в панели администратора, ознакомьтесь с нашим руководством для начинающих по панели администратора WordPress, чтобы узнать больше.
Бэкэнд и Фронтенд WordPress
Помните, мы говорим об оптимизации панели администратора, которая является серверной частью вашего сайта. Если вы хотите оптимизировать время загрузки страницы, прочтите нашу статью о вещах, которые могут снизить скорость вашего интерфейса. Серверная часть WordPress использует стили и скрипты из папки wp-admin для загрузки функций администратора. Вы можете проверить содержимое папки wp-admin, загрузив пакет WordPress с официального сайта или зайдя на свой сервер по FTP.
Помимо основных компонентов, время загрузки страницы администратора также зависит от конкретной темы и плагинов, установленных на вашем сайте.
1. Заблокированное или медленное соединение.
Первое, что вам нужно проверить, заметив медленную работу панели администратора WordPress, — это проверить подключение к Интернету. Медленное подключение к Интернету повлияет на загрузку сценариев администратора, и их загрузка займет много времени. Убедитесь, что вы используете надежную сеть Wi-Fi или используете кабель для подключения компьютера к Интернету.
2. Плохой хостинг
Многие из нас думают, что хостинг, плагины и темы будут влиять на время загрузки интерфейса сайта WordPress. Однако правда в том, что такие факторы, как плохой хостинг, будут сильно влиять на серверную часть по сравнению с внешним интерфейсом.
В отличие от страниц внешнего интерфейса, серверная часть WordPress не кэшируется. Это означает, что каждая страница загружается путем получения данных из базы данных. Таким образом, скорость серверной части сильно зависит от мощности хостинга, который позволяет быстро получать и загружать данные. Использование плохого хостинга повлияет на скорость, что особенно актуально для крупных веб-сайтов, использующих виртуальный хостинг.
Если вы получаете хороший трафик, рассмотрите возможность перехода в облако или выделенный сервер. Это поможет пользователям быстрее загружать страницы интерфейса, и вы также сможете без проблем использовать панель администратора.
3. Отключите виджет информационной панели.
По умолчанию вы увидите раздел панели управления при входе в административную панель WordPress. Многие плагины и коммерческие темы добавляют виджеты на панель управления. Это резко снизит скорость во время запуска. Например, популярный плагин WooCommerce добавит виджет отслеживания на панель инструментов. Аналогично, плагин Yoast SEO добавит виджет быстрого статуса. Эти виджеты будут динамически получать данные при входе в систему и замедлять работу панели администратора.
- Нажмите кнопку «Параметры экрана», расположенную в верхнем правом углу.
- Снимите флажки с ненужных опций, чтобы эти виджеты не загружались при запуске.
 Отключить виджеты в панели управления
Отключить виджеты в панели управления
Теперь вы почувствуете, что вход в систему происходит быстрее без ненужных виджетов на приборной панели.
4. Отключите ненужные параметры экрана.
Подобно разделу панели управления, каждый экран имеет множество опций в панели администратора WordPress. Например, в разделе «Все сообщения» будет показан список сообщений с несколькими столбцами, такими как избранное изображение, категории, теги, дата публикации и т. д. Вы можете использовать параметры экрана, чтобы отключить ненужные параметры, чтобы ускорить загрузку страницы.
 Параметры экрана на странице «Все сообщения»
Параметры экрана на странице «Все сообщения»
Вы также можете отключить меню быстрого доступа, добавленные плагинами и темами на верхней панели.
5. Тяжелые темы и плагины
Коммерческие темы предлагают настраиваемую панель для настройки вашего сайта. Первым требованием для использования такой пользовательской панели является увеличение выполнения PHP и ограничение памяти на вашем сервере. Без пояснений можно понять, что эти темы грузят тяжелые скрипты в админ-панели. Мы настоятельно рекомендуем использовать настройщик WordPress по умолчанию вместо тем, предлагающих дополнительные настраиваемые панели.
Как уже упоминалось, все популярные плагины загружают скрипты на страницах администратора. Вы можете просмотреть исходный код вашей страницы администратора, щелкнув правой кнопкой мыши и выбрав опцию «Проверить» или «Проверить элемент». Вы будете удивлены, увидев, что все плагины из папки wp-content загружают какие-то CSS/скрипты на ваши страницы администратора.
 Посмотреть исходный код на странице администратора
Посмотреть исходный код на странице администратора
Поэтому используйте простые плагины и темы, особенно если вы используете сервер общего хостинга.
6. Отключите API Heartbeat.
Плагины используют Heartbeat API в WordPress для получения обновлений виджетов панели управления в режиме реального времени. Хорошим примером является плагин WooCommerce, который будет отображать цифры продаж в реальном времени в виджете информационной панели. Проверьте, нужны ли вам оперативные данные, в противном случае отключите API Heartbeat, чтобы снизить нагрузку на ваш сервер. Это также поможет улучшить время загрузки ваших страниц администрирования.
7. Очистка базы данных
Как упоминалось ранее, страницы администрирования будут загружаться динамически путем запроса к базе данных. Большая база данных с ненужными записями увеличит время выполнения запроса и, следовательно, задержит загрузку страниц администрирования. Yoast, WooCommerce и многие другие плагины добавляют таблицы базы данных и записи в таблицу wp_options для загрузки ресурсов на всех страницах. Это раздражает, поскольку вам не обязательно иметь эти плагины на многих страницах администратора.
Лучшее решение — регулярно очищать базу данных, чтобы удалять просроченные записи, такие как временные файлы. Кроме того, удаление плагинов не приведет к удалению таблицы и записей базы данных. Поэтому проверьте, не висит ли в вашей базе данных неиспользуемый контент, и удалите его, чтобы повысить производительность.
8. PHP-штуки
WordPress — это не что иное, как PHP-скрипты, которые помогают собирать контент из внутренней базы данных. PHP как язык сценариев имеет жизненный цикл и постоянно обновляется. Следовательно, убедитесь, что ваши версии WordPress и PHP обновлены, чтобы избежать медленной работы страниц администрирования. Помните, что PHP 8 или более поздняя версия в несколько раз быстрее, чем более старые версии, такие как 5.6, с точки зрения времени выполнения запросов к базе данных. Таким образом, использование старой версии PHP может стать потенциальной причиной замедления работы вашей панели управления.
Примечание: Для обновления сайта вам необходимо обновить ядро WordPress, версию PHP на вашем сервере, тему и плагины, используемые на вашем сайте. Вы можете использовать функцию «Инструменты > Состояние сайта», чтобы проверить, есть ли какие-либо проблемы несовместимости, мешающие работе вашего сайта. Проконсультируйтесь с вашим хостером, если вам нужно изменить параметры PHP, такие как MAX_INPUT_VARS, ограничение памяти или установить любые другие недостающие расширения PHP.
9. Проверьте настройки кэширования.
Страницы администрирования по умолчанию не кэшируются. Однако такие плагины, как W3TC, позволяют настроить кэширование объектов и БД, при котором будут кэшироваться все отдельные объекты. Это предназначено для сокращения времени выполнения запроса, однако увеличивает нагрузку на ваш сервер. В большинстве сценариев общего хостинга это потенциально может замедлить работу сайта и панели администратора. Отключите эти параметры и проверьте, помогает ли это быстрее загружать страницы администратора.
Кроме того, если вы используете плагин кеширования, мы рекомендуем отключить кеширование страниц для администратора, чтобы избежать проблем при редактировании и просмотре измененного контента.
10. Переустановите администратор WordPress.
Как уже упоминалось, WordPress использует содержимое папки wp-admin для сборки страниц администрирования. Поэтому простая перезапись папки wp-admin может помочь устранить поврежденные файлы и быстро загрузить страницы.
- Вы можете скачать пакет WordPress с официального сайта и распаковать папку wp-admin.
- Войдите на свой сервер с помощью FTP и переименуйте папку wp-admin во что-то вроде old-wp-admin.
- Теперь загрузите папку wp-admin из пакета на свой сервер.
- Снова войдите в свою панель управления и проверьте, загружаются ли страницы быстрее.
- Если что-то не работает, переименуйте папку wp-admin в new-wp-admin и измените папку old-wp-admin на wp-admin.
Мы не рекомендуем этого делать, поскольку основной причиной замедления в большинстве случаев будет PHP, база данных, хостинг, плагины и темы. Таким образом, переустановка папки wp-admin не поможет, если проблема в другом месте.
2024-02-25T20:37:52
Сайтостроение
 Одно из самых прекрасных качеств человека и большинства живых организмов – это восприятие звуков.
Одно из самых прекрасных качеств человека и большинства живых организмов – это восприятие звуков.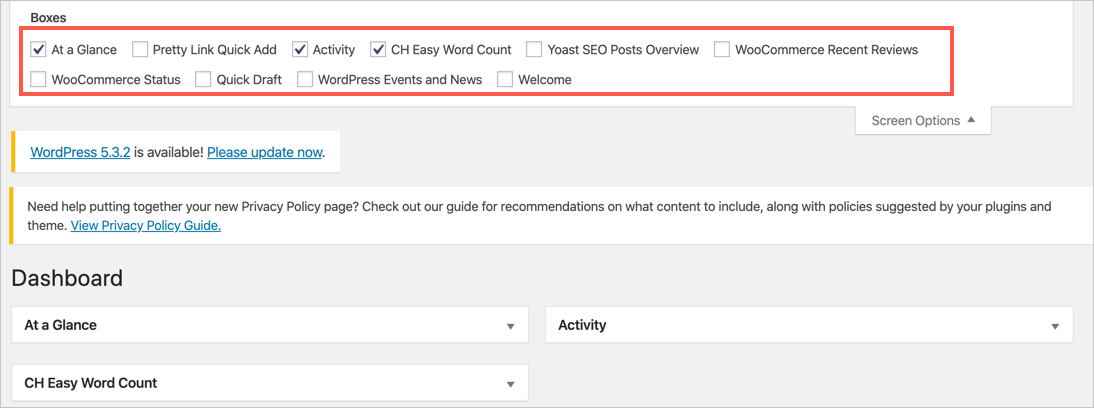 Отключить виджеты в панели управления
Отключить виджеты в панели управления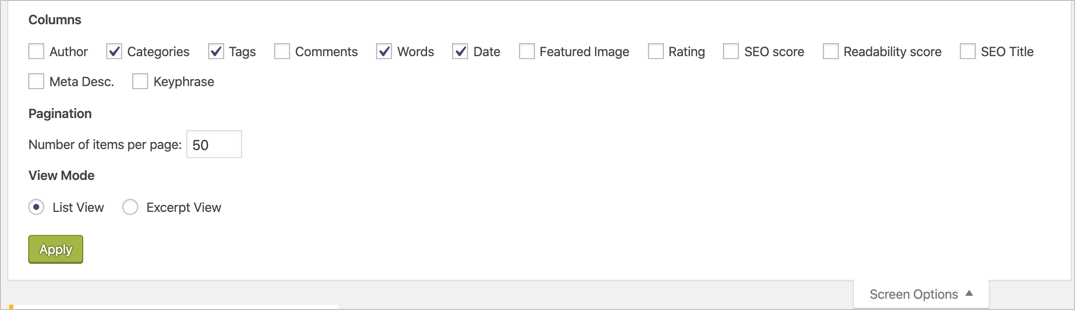 Параметры экрана на странице «Все сообщения»
Параметры экрана на странице «Все сообщения» Посмотреть исходный код на странице администратора
Посмотреть исходный код на странице администратора
