Веб-браузеры всегда были важной частью доступа и работы в Интернете. Google Chrome — один из самых популярных и широко используемых браузеров, и его пользовательская база продолжает расширяться. До его выпуска в основном использовались такие браузеры, как Internet Explorer и Firefox, и у них было много поклонников. У них было несколько отличных функций, которые в то время были чрезвычайно полезны.
Однако по мере развития технологий текущие функции не могли удовлетворить потребности людей. С выходом Chrome в 2008 году это полностью изменило динамику системы платформы веб-браузера, поскольку благодаря своей высокоскоростной производительности и стабильному характеру он быстро привлек внимание людей и обогнал своих предшественников.
Chrome сам по себе не безупречен и, как правило, имеет свои собственные проблемы.Одна конкретная проблема, которая постоянно растет, — это ошибка тайм-аута, которая также будет темой нашего обсуждения в этой статье, где мы рассмотрим различные решения относительно того, как можно исправить ошибку тайм-аута в Chrome.
Решения ошибки
Ошибка истечения времени ожидания обычно возникает из-за отсутствия связи между вашим браузером и веб-сайтом, к которому вы пытаетесь получить доступ. Это связано с тем, что либо ваш браузер не может получить данные, либо время, которое потребовалось, пересекло время ожидания сеанса и не смог установить соединение.
Часто бывает достаточно приобрести прокси-сервер proxy-sale.com и указать его в настройках браузера.
А вообще, есть несколько способов решить эту проблему. Давайте теперь исследуем их все.
1) Очистка данных просмотра из Chrome
Часто причина, по которой ваше соединение может истекать, заключается в том, что файлы cookie или кеши повреждены и создают проблемы при установлении соединения между вашим браузером и сервером веб-сайта. Поэтому хороший вариант — удалить данные о просмотре из вашего Google Chrome. Для этого откройте свой Google Chrome, затем нажмите на три вертикальные точки , перейдите к параметру «Дополнительные инструменты» и, наконец, выберите параметр «Очистить данные просмотра». Вы также можете открыть это с помощью сочетания клавиш Ctrl + Shift + Delete .
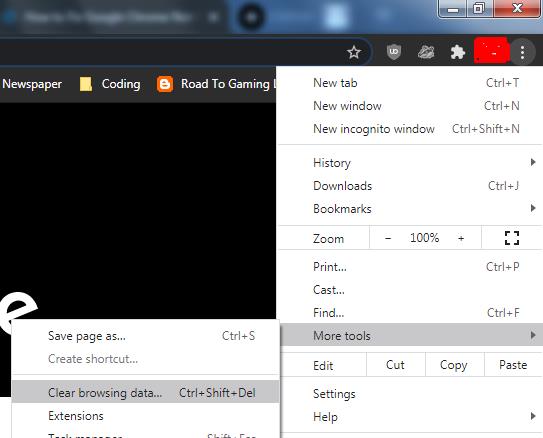
Затем откроется окно, в котором будет несколько вариантов для выбора, в частности, период времени, с которого вы хотите начать удаление данных просмотра. Раздела «Базовый» будет достаточно, чтобы устранить эту ошибку; однако, если есть какие-то особые настройки сайта, которые, по вашему мнению, создают проблемы, вы можете выбрать их в разделе «Дополнительно».
Очистить данные просмотров:
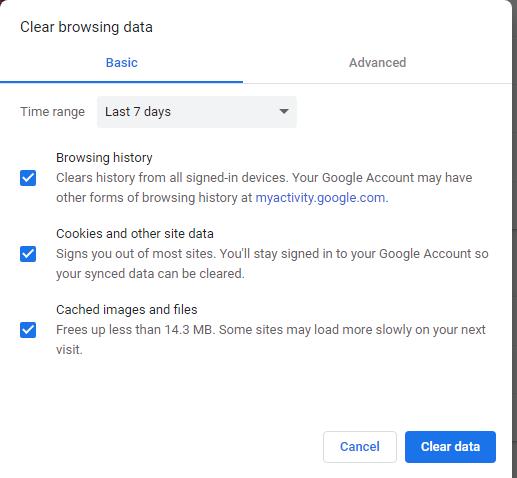
Настройки сайта на вкладке «Дополнительно»:
Перезапустите веб-браузер Chrome и проверьте, загружается ли веб-страница.
2) Отключение брандмауэра
Другая причина, по которой вы можете получить ошибку тайм-аута в Chrome, может быть связана с тем, что ваш брандмауэр пытается заблокировать соединение между вашим браузером и сервером. Брандмауэры — это функции безопасности, установленные для защиты ваших систем и блокировки подозрительных веб-страниц. Однако иногда это приводит к блокировке безопасных страниц. В Windows вы должны проверить это через брандмауэр Windows. Сначала найдите Брандмауэр в меню поиска и откройте его.
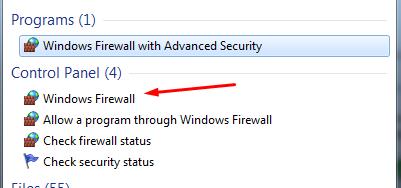
Затем нажмите Включить или выключить брандмауэр Windows.
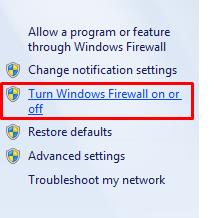
Вам нужно нажать на опцию Отключить брандмауэр Windows в настройках расположения частной сети здесь.
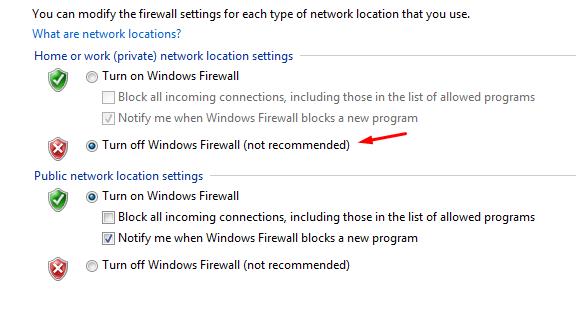
Затем нажмите OK, и теперь вы увидите следующее на главной странице вашего брандмауэра.
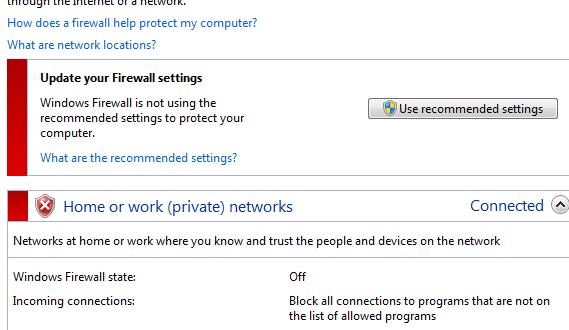
Теперь еще раз проверьте, загружает ли ваш Chrome веб-сайт или нет.
3) Редактирование файла хостов Windows
Другой альтернативой исправлению ошибки превышения времени ожидания является проверка файла хостов Windows на предмет отсутствия доступа к именам веб-сайтов. Возможно, они были заблокированы файлом хостов. Для редактирования хост — файл, откройте Мой компьютер, а затем перейти к следующему каталогу: C:WindowsSystem32DriversEtc. Здесь вы увидите файл с именем hosts. Откройте файл, щелкнув его правой кнопкой мыши и используя блокнот или аналогичное программное обеспечение, чтобы открыть его. Теперь убедитесь, что имена веб-сайтов не упоминаются после раздела localhost.
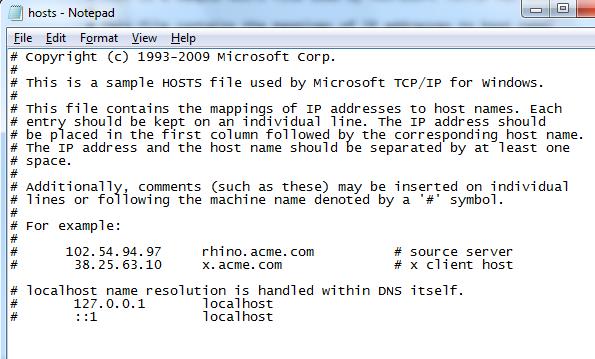
Если вы видите имена, удалите их, сохраните файл хоста и еще раз откройте Chrome и проверьте, загружает ли он вашу веб-страницу.
4) Сброс и очистка DNS
Подобно удалению данных о просмотре, вы также можете попробовать очистить кеш DNS, поскольку веб-сайт, к которому вы, возможно, пытаетесь получить доступ, может не разрешать соединение с вашим IP-адресом. Для этого откройте терминал, написав командную строку в строке поиска и открыв программу командной строки.
Затем введите следующие команды, чтобы очистить кеш DNS и обновить свой IP-адрес:
$ ipconfig /flushdns $ ipconfig /registerdns $ ipconfig /release $ ipconfig /renew
После этого выполните следующую команду, чтобы сбросить его:
$ netsh winsock reset
Перезагрузите компьютер и попробуйте еще раз загрузить веб-страницу в Chrome.
5) Настройка параметров локальной сети
Еще одна альтернатива — заглянуть в настройки вашей локальной сети и настроить несколько параметров. Для этого откройте панель управления , нажмите «Сеть и Интернет», а затем выберите «Свойства обозревателя» .
После выбора этого откроется окно, в котором щелкните вкладку подключений, чтобы открыть его.
Затем нажмите кнопку настроек LAN, расположенную в разделе LAN.
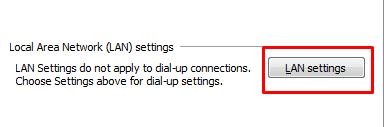
Здесь снимите флажок «Использовать прокси-сервер» в разделе «Прокси-сервер» и нажмите «ОК».
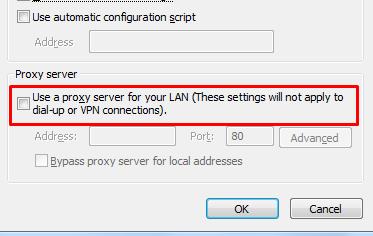
После настройки параметров локальной сети перезагрузите систему, а после перезапуска откройте Chrome и убедитесь, что он загружает вашу веб-страницу.
Вывод?
Chrome — отличный веб-браузер, который значительно упростил процесс доступа в Интернет. Но, как и все изобретения, он не лишен недостатков и может иметь некоторые ошибки. Поэтому важно знать, как можно своевременно устранять эти ошибки.
https://www.youtube.com/watch?v=FHWI1qAObdU