Бесплатная среда выполнения Java (JRE) предоставляет необходимые элементы для выполнения Java-приложений Windows 11. Он включает в себя виртуальную машину Java (JVM), основные библиотеки и классы. Если среда выполнения Java отсутствует в Windows 11, зависимые программы перестают работать должным образом.
Вы можете столкнуться с этой проблемой, если Java установлена неправильно, зависимые приложения повреждены или на компьютере установлено несколько версий Java. Мы рассмотрели наиболее практичные решения и в этом руководстве проведем вас через все их основные шаги. Пойдем.
Предварительное условие: правильно установить Java
Если вы не установили Java или установили его неправильно, все приложения, использующие его, вернут сообщение об ошибке: «Среда выполнения Java не найдена». Прежде чем перейти к приведенным ниже решениям, вам следует проверить состояние Java на компьютере. Вот как.
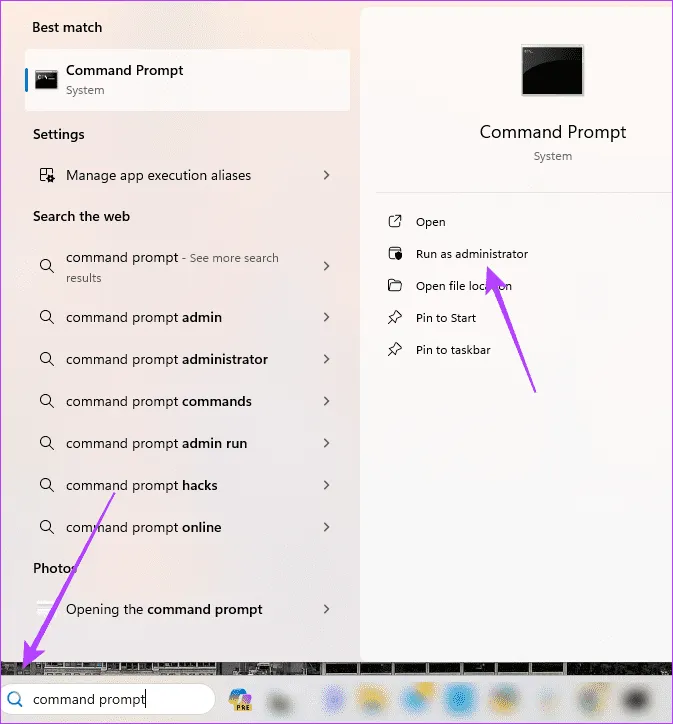
Шаг 1. Нажмите увеличительную линзу на панели задач, введите «Командная строка» и выберите «Запуск от имени администратора».

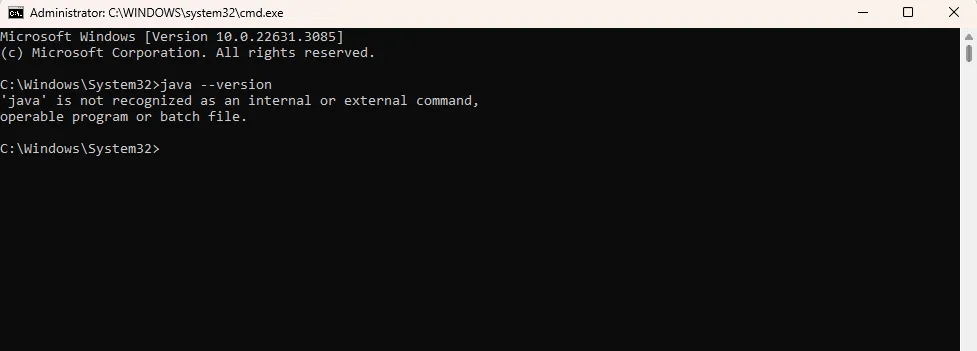
Шаг 2. Введите команду ниже и нажмите Enter, чтобы проверить статус Java.
Java-версия

Шаг 3. Выполнение команды отобразит версию Java на вашем компьютере, если она установлена правильно. В противном случае вы можете получить сообщение об ошибке.
2. Восстановите зависимое от Java приложение.
Вам также следует изучить возможность повреждения Java-зависимого приложения. Некоторые программы имеют возможность восстановления. Хотя этапы восстановления могут различаться в зависимости от программы, обычно большинство приложений следуют процессу, описанному ниже.
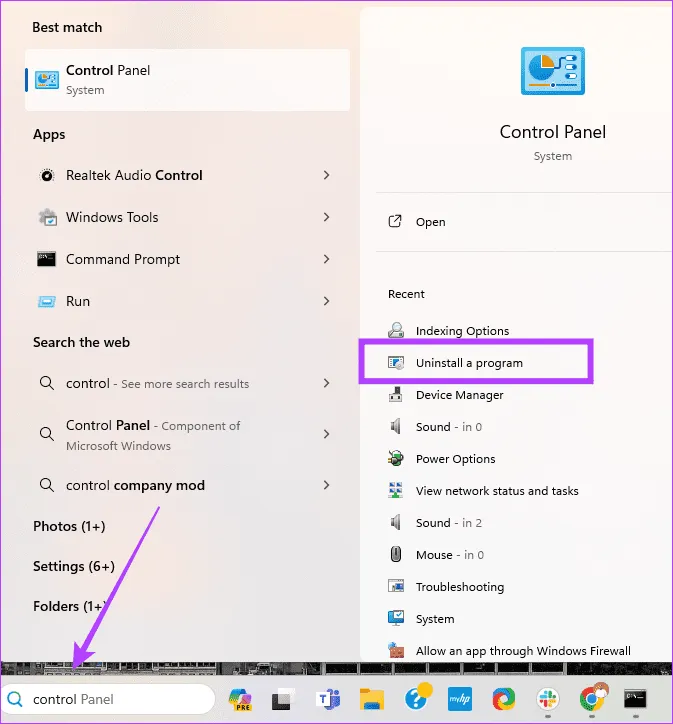
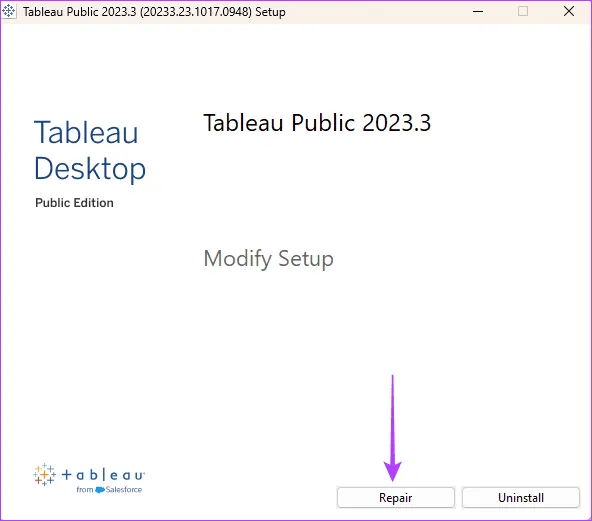
Шаг 1. Перейдите в окно поиска на панели задач, введите control и выберите опцию «Удалить программу».
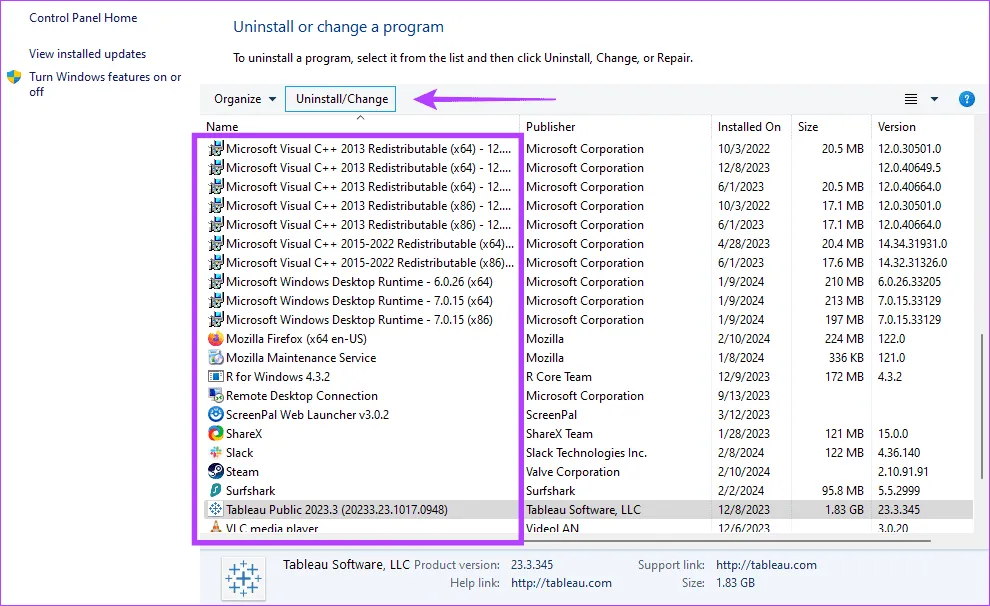
Шаг 2. Выберите приложение в столбце «Имя», затем выберите любой из доступных вариантов: «Изменить», «Удалить/Изменить».

Шаг 3. Нажмите кнопку «Восстановить» и следуйте инструкциям для завершения процесса.

3. Переустановите зависимое от Java приложение.
Если восстановление зависимого приложения не помогло, вам следует рассмотреть возможность переустановки приложения. Однако перед переустановкой необходимо полностью удалить приложение и убедиться, что вы переустановили его из только что загруженной копии.
Таким образом, вам гарантировано, что любое повреждение, затронувшее старую установку, не повлияет на новую.
4. Загрузите и установите среду выполнения Java.
Если после запуска команды Java -version вы обнаружите, что Java отсутствует на вашем компьютере, вам необходимо загрузить и установить ее. Для этого потребуется посетить официальный сайт Java. Приведенные ниже шаги проведут вас через этот процесс.
Шаг 1: Посетите официальный сайт и нажмите зеленую кнопку «Загрузить».

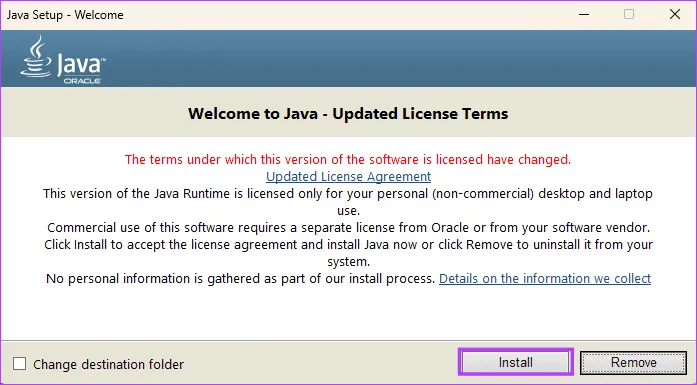
Шаг 3: Дважды щелкните загруженный файл, чтобы начать установку.
Шаг 4: Нажмите кнопку «Установить».

Шаг 5. Закройте программу установки и убедитесь, что проблема устранена.
5. Удалите конфликтующие версии Java.
Вы по-прежнему сталкиваетесь с ошибкой приложения, хотя Java уже установлена? Если это так, это может указывать на повреждение среды выполнения Java или конфликтующие версии Java. В этом случае вы можете разрешить конфликты, полностью удалив старые версии Java и оставив только самую последнюю.
6. Разрешите Java через брандмауэр
Брандмауэр Windows 11 помогает защитить ваш компьютер, блокируя угрозы, нежелательные программы и другое вредоносное программное обеспечение. При этом некоторые программы могут запрашивать разрешение на проход через брандмауэр. Если брандмауэр блокирует Java, вы получите сообщение об ошибке «Среда выполнения Java не найдена». Вот как вы можете это исправить.
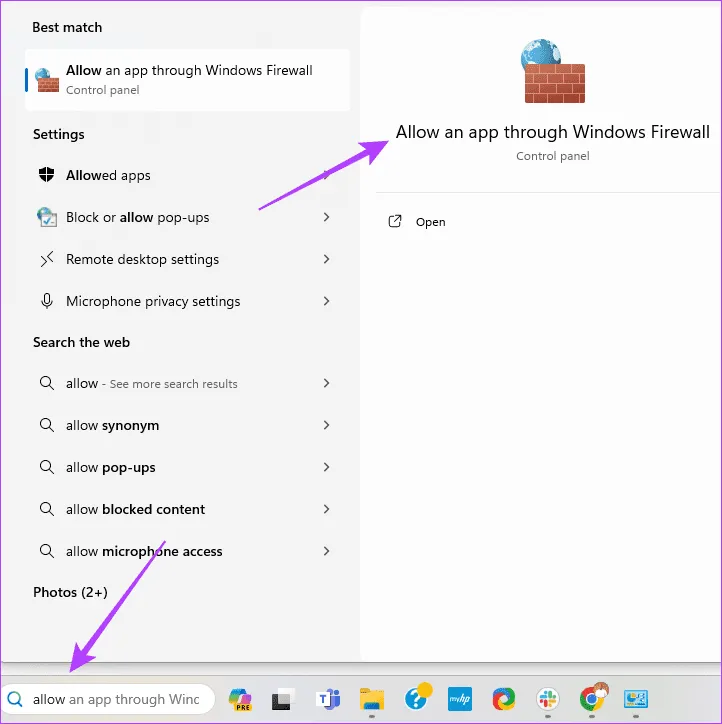
Шаг 1. Нажмите увеличительную линзу на панели задач, введите «Разрешить» и нажмите «Разрешить приложение через брандмауэр Windows».

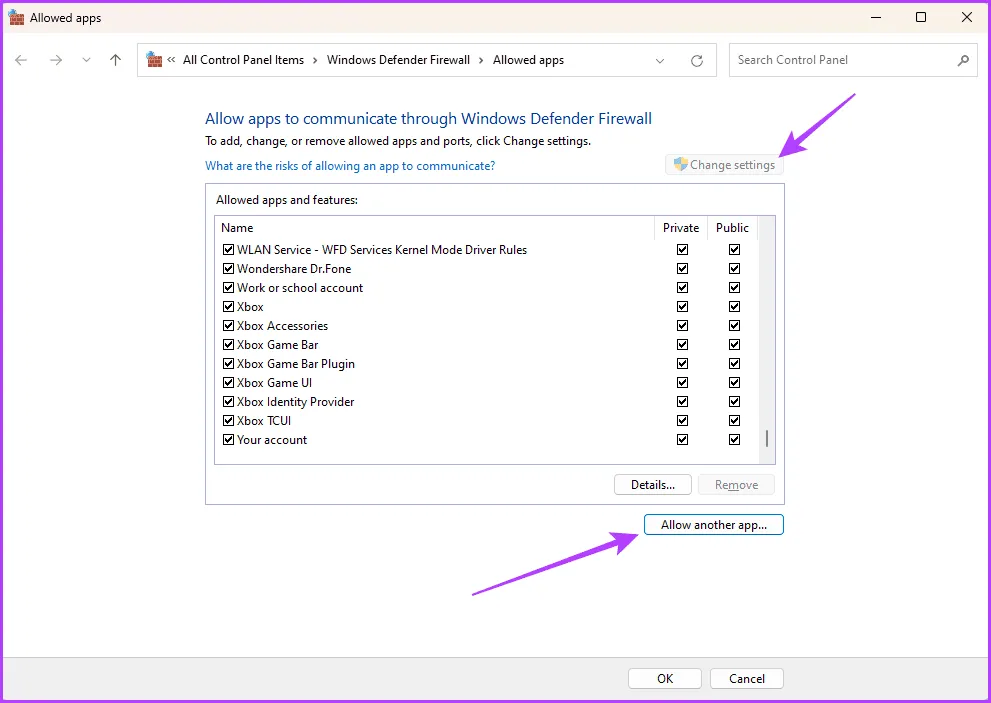
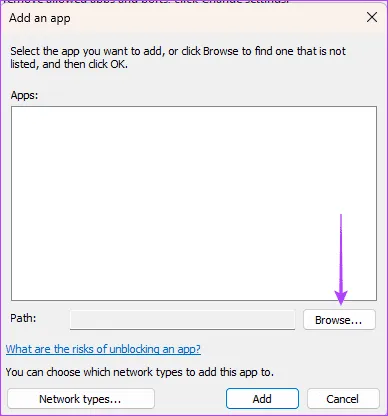
Шаг 2. Нажмите кнопку «Изменить настройки» и «Разрешить другое приложение».

Шаг 3. Нажмите «Обзор», перейдите по указанному ниже пути и добавьте установку Java.
C:ProgramDataMicrosoftWindowsМеню ПускПрограммыJava

Шаг 4: Нажмите кнопку «ОК», и ошибка Java должна быть устранена.
Устранение ошибки приложения Java
Некоторые люди могут столкнуться с проблемами, когда они не могут найти или загрузить среду выполнения Java. Эта проблема часто связана с определенным повреждением в приложении или JRE. Вы бы успешно решили эту проблему, пройдя путь к решениям, которые мы изучили.
Какое из решений показалось вам наиболее эффективным? Пожалуйста, сообщите нам в разделе комментариев ниже.
2024-02-16T16:44:22
Вопросы читателей