Nextcloud – это бесплатное облачное хранилище с открытым исходным кодом. Nextcloud позволяет организовать легкий доступ к своим файлам, фотографиям и документам для работы и совместного использования с членами команды, клиентами и партнерами. В хранилище также есть дополнительные функции, такие как Календарь, Контакты, Планировщик задач, потоковое воспроизведение мультимедиа с помощью Ampache и т. д.
Для синхронизации файлов между рабочим столом и вашим собственным сервером, Nextcloud предоставляет приложения для рабочих столов Windows, Linux и Mac, а также мобильное приложение для Android и iOS.
Что потребуется для установки?
Мы будем устанавливать Nextcloud на сервер Ubuntu 20.04. Необходимым условием являются внешний ip-адрес и открытые порты 80 и 443.
1. Установка web-сервера Nginx
Первым делом подключимся к нашему серверу и установим веб-сервер Nginx
sudo apt update
sudo apt install nginx -y
После завершения установки запустим службу Nginx и включим ее старт при загрузке системы с помощью systemctl.
systemctl start nginx
systemctl enable nginx
Проверим, что все запустилось
systemctl status nginx

Установка и настройка PHP 7.4 – FPM
Установим пакеты PHP и PHP-FPM, используя команду ниже:
sudo apt install php-fpm php-curl php-cli php-mysql php-gd php-common php-xml php-json php-intl php-pear php-imagick php-dev php-common php-mbstring php-zip php-soap php-bz2 -y
После завершения установки нужно немного отредактировать файлы php.ini для php-fpm и php-cli. Данные изменения необходимо произвести в обоих файлах.
cd /etc/php/7.4/
sudo nano fpm/php.ini
sudo nano cli/php.ini
Раскоментируйте строку date.timezone и измените значение на свой часовой пояс.
date.timezone = Europe/Moscow
Раскоментируйте строку ‘cgi.fix_pathinfo’ и измените значение на ‘0’.
cgi.fix_pathinfo=0
Сохраняем изменения и выходим.
Теперь отредактируем файл www.conf
sudo nano fpm/pool.d/www.conf
Найдем и раскоментируем следующие строки:
env [HOSTNAME] = $HOSTNAME
env [PATH] = /usr/local/bin:/usr/bin:/bin
env [TMP] = /tmp
env [TMPDIR] = /tmp
env [TEMP] = /tmp
Сохраняем файл и выходим.
Следующим шагом нужно перезапустить службу PHP7.4-FPM и включить ее автозагрузку.
systemctl restart php7.4-fpm
systemctl enable php7.4-fpm
Проверим что сервис работает с помощью следующей команды:
ss -xa | grep php
systemctl status php7.4-fpm

Вы увидите, что php-fpm запущен и работает под файлом sock ‘/run/php/php7.4-fpm.sock’.
3. Установка и настройка сервера MariaDB
Следующий шаг – установка базы данных. Установите последнюю версию сервера MariaDB, используя команду:
sudo apt install mariadb-server -y
После завершения установки запустим службу MariaDB и включим ее запуск при каждом старте системы.
systemctl start mariadb
systemctl enable mariadb
Проверяем:
systemctl status mariadb

Следующий шаг – настройка безопасности SQL-сервера. У вас спросят о некоторых настройках сервера MariaDB. После ответа на вопрос Set root password? введите новый пароль root для SQL-сервера MariaDB
mysql_secure_installation
Enter current password for root (enter for none): Press Enter
Set root password? [Y/n] Y
Remove anonymous users? [Y/n] Y
Disallow root login remotely? [Y/n] Y
Remove test database and access to it? [Y/n] Y
Reload privilege tables now? [Y/n] Y
Теперь создадим новую базу данных для установки nextcloud. Назовем базу данных «nextcloud_db» с пользователем «nextclouduser» и паролем «PaSsW0rD@».
Войдите в оболочку MySQL от имени пользователя root с помощью команды mysql.
mysql -u root -p
Введите пароль root SQL-сервера MariaDB.
Создадим базу данных и пользователя:
create database nextcloud_db;
create user nextclouduser@localhost identified by 'PaSsW0rD@';
grant all privileges on nextcloud_db.* to nextclouduser@localhost identified by 'PaSsW0rD@';
flush privileges;
exit;
Установка и настройка MariaDB для Nextcloud завершена.
4. Генерация SSL-сертификата Letsencrypt
Установите инструмент letsencrypt, используя команду apt ниже:
sudo apt install certbot -y
После завершения установки остановите службу nginx.
systemctl stop nginx
Сгенерируем SSL-сертификаты для доменного имени ‘cloud.admin812.ru’, используя командную строку cerbot.
certbot certonly --standalone -d cloud.admin812.ru
Вам будет предложено ввести адрес электронной почты на который будет приходить уведомление о необходимости продления сертификата.
Следующим шагом будет вывод на экран оглашения об обслуживании. Нажимаем “А” (Agree) и после этого запускается процесс генерации сертификата. По окончании появится надпись об успешном завершении процесса и можно приступать непосредственно к установке Nextcloud.
5. Скачиваем Nextcloud
Перед загрузкой исходного кода nextcloud убедитесь, что в системе установлен пакет unzip. Если у вас его нет пакета, установите его:
sudo apt install wget unzip zip -y
Теперь перейдем в каталог /var/www и скачаем последнюю версию Nextcloud:
cd /var/www/
wget -q https://download.nextcloud.com/server/releases/latest.zip
Распакуем архив и изменим владельца каталога nextcloud на пользователя ‘www-data’:
unzip -qq latest.zip
sudo chown -R www-data:www-data /var/www/nextcloud
6. Настраиваем виртуальный хост Nginx для Nextcloud
В каталоге /etc/nginx/sites-available создадим новый файл виртуального хоста nextcloud.
cd /etc/nginx/sites-available/
sudo nano nextcloud
Вставим следующую конфигурацию виртуального хоста nextcloud.
upstream php-handler {
#server 127.0.0.1:9000;
server unix:/var/run/php/php7.4-fpm.sock;
}
server {
listen 80;
listen [::]:80;
server_name cloud.admin812.ru;
# enforce https
return 301 https://$server_name:443$request_uri;
}
#
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
server_name cloud.admin812.ru;
#
# Use Mozilla's guidelines for SSL/TLS settings
# https://mozilla.github.io/server-side-tls/ssl-config-generator/
# NOTE: some settings below might be redundant
ssl_certificate /etc/letsencrypt/live/cloud.admin812.ru/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/cloud.admin812.ru/privkey.pem;
#
# Add headers to serve security related headers
# Before enabling Strict-Transport-Security headers please read into this
# topic first.
#add_header Strict-Transport-Security "max-age=15768000; includeSubDomains; preload;" always;
#
# WARNING: Only add the preload option once you read about
# the consequences in https://hstspreload.org/. This option
# will add the domain to a hardcoded list that is shipped
# in all major browsers and getting removed from this list
# could take several months.
add_header Referrer-Policy "no-referrer" always;
add_header X-Content-Type-Options "nosniff" always;
add_header X-Download-Options "noopen" always;
add_header X-Frame-Options "SAMEORIGIN" always;
add_header X-Permitted-Cross-Domain-Policies "none" always;
add_header X-Robots-Tag "none" always;
add_header X-XSS-Protection "1; mode=block" always;
#
# Remove X-Powered-By, which is an information leak
fastcgi_hide_header X-Powered-By;
#
# Path to the root of your installation
root /var/www/nextcloud;
#
location = /robots.txt {
allow all;
log_not_found off;
access_log off;
}
#
# The following 2 rules are only needed for the user_webfinger app.
# Uncomment it if you're planning to use this app.
#rewrite ^/.well-known/host-meta /public.php?service=host-meta last;
#rewrite ^/.well-known/host-meta.json /public.php?service=host-meta-json last;
#
# The following rule is only needed for the Social app.
# Uncomment it if you're planning to use this app.
#rewrite ^/.well-known/webfinger /public.php?service=webfinger last;
#
location = /.well-known/carddav {
return 301 $scheme://$host:$server_port/remote.php/dav;
}
location = /.well-known/caldav {
return 301 $scheme://$host:$server_port/remote.php/dav;
}
#
# set max upload size
client_max_body_size 512M;
fastcgi_buffers 64 4K;
#
# Enable gzip but do not remove ETag headers
gzip on;
gzip_vary on;
gzip_comp_level 4;
gzip_min_length 256;
gzip_proxied expired no-cache no-store private no_last_modified no_etag auth;
gzip_types application/atom+xml application/javascript application/json application/ld+json application/manifest+json application/rss+xml application/vnd.geo+json application/vnd.ms-fontobject application/x-font-ttf application/x-web-app-manifest+json application/xhtml+xml application/xml font/opentype image/bmp image/svg+xml image/x-icon text/cache-manifest text/css text/plain text/vcard text/vnd.rim.location.xloc text/vtt text/x-component text/x-cross-domain-policy;
#
# Uncomment if your server is build with the ngx_pagespeed module
# This module is currently not supported.
#pagespeed off;
#
location / {
rewrite ^ /index.php;
}
#
location ~ ^/(?:build|tests|config|lib|3rdparty|templates|data)/ {
deny all;
}
location ~ ^/(?:.|autotest|occ|issue|indie|db_|console) {
deny all;
}
#
location ~ ^/(?:index|remote|public|cron|core/ajax/update|status|ocs/v[12]|updater/.+|oc[ms]-provider/.+).php(?:$|/) {
fastcgi_split_path_info ^(.+?.php)(/.*|)$;
set $path_info $fastcgi_path_info;
try_files $fastcgi_script_name =404;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param PATH_INFO $path_info;
fastcgi_param HTTPS on;
# Avoid sending the security headers twice
fastcgi_param modHeadersAvailable true;
# Enable pretty urls
fastcgi_param front_controller_active true;
fastcgi_pass php-handler;
fastcgi_intercept_errors on;
fastcgi_request_buffering off;
}
#
location ~ ^/(?:updater|oc[ms]-provider)(?:$|/) {
try_files $uri/ =404;
index index.php;
}
#
# Adding the cache control header for js, css and map files
# Make sure it is BELOW the PHP block
location ~ .(?:css|js|woff2?|svg|gif|map)$ {
try_files $uri /index.php$request_uri;
add_header Cache-Control "public, max-age=15778463";
# Add headers to serve security related headers (It is intended to
# have those duplicated to the ones above)
# Before enabling Strict-Transport-Security headers please read into
# this topic first.
#add_header Strict-Transport-Security "max-age=15768000; includeSubDomains; preload;" always;
#
# WARNING: Only add the preload option once you read about
# the consequences in https://hstspreload.org/. This option
# will add the domain to a hardcoded list that is shipped
# in all major browsers and getting removed from this list
# could take several months.
add_header Referrer-Policy "no-referrer" always;
add_header X-Content-Type-Options "nosniff" always;
add_header X-Download-Options "noopen" always;
add_header X-Frame-Options "SAMEORIGIN" always;
add_header X-Permitted-Cross-Domain-Policies "none" always;
add_header X-Robots-Tag "none" always;
add_header X-XSS-Protection "1; mode=block" always;
# Optional: Don't log access to assets
access_log off;
}
location ~ .(?:png|html|ttf|ico|jpg|jpeg|bcmap)$ {
try_files $uri /index.php$request_uri;
# Optional: Don't log access to other assets
access_log off;
}
}
Замените выделенное красным на свое доменное имя.
Включите виртуальный хост, протестируйте конфигурацию и убедитесь, что нетv ошибок.
ln -s /etc/nginx/sites-available/nextcloud /etc/nginx/sites-enabled/
nginx -t
Если ошибок нет, перезапустите сервис PHP7.4-FPM и nginx.
systemctl restart nginx
systemctl restart php7.4-fpm
Конфигурация виртуального хоста Nginx для nextcloud создана.
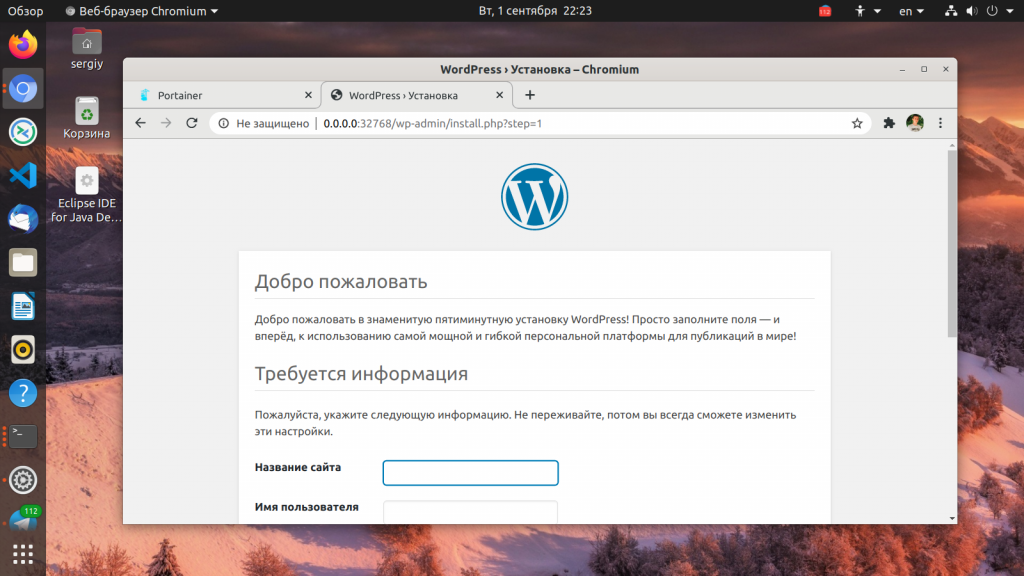
7. Подключение к Nextcloud
Откройте веб-браузер и введите URL-адрес nextcloud. Вы будете автоматически перенаправлены на соединение https.
Нам нужно создать пользователя-администратора для Nextcloud и ввести пароль.
Также нужно настроить соединение с базой данных. Для этого введите название базы данных, имя пользователя и пароль которые мы создали на шаге 3, а затем нажмите кнопку «Finish».
И после завершения установки вы получите панель Nextcloud, как показано ниже.

Источник: https://admin812.ru/ustanovka-oblachnogo-hranilishha-nextcloud.html


{kind=link}