Американская биржа Kraken появилась на криптовалютном рынке в 2011 году. Штаб-квартира биржи находится в Калифорнии, Сан-Франциско.
Основателем и CEO является Джесси Пауэлл, который признавал важность Биткоина и Блокчейна с самого зарождения криптовалютной экосистемы и видел в ней большой потенциал и возможность для достижения финансовой независимости. Он видел смысл в том, чтобы развивать то, что в 2009 году изобрел Сатоши Накамото, и создавать новые эффективные решения, положившие начало новой цифровой экономике.
Первые годы работы биржа находилась в тени конкурентов, но с середины 2014 года ее популярность стала расти. Это во многом связано с банкротством биржи MtGox, которая в то время имела влияние на расстановку сил на рынке. Многие трейдеры и инвесторы, которые ранее работали с MtGox, перешли на Kraken, которая предлагала выгодные торговые условия.
Получите бесплатный видео-курс по трейдингуEmail*Смотреть курс Изначально в листинге были только евро, биткоины и лайткоины. Постепенно список активов расширялся, добавлялись другие фиатные и цифровые валюты, увеличивались торговые обороты. В 2014 году биржа Kraken стала крупнейшей в мире платформой по объему торгов EUR/BTC.
Из неприятных моментов, связанных с историей биржи, можно вспомнить успешные DDoS-атаки в 2017 году, вследствие которых платформа не работала несколько дней.
Kraken признан лучшей и самой безопасной криптовалютной биржей.
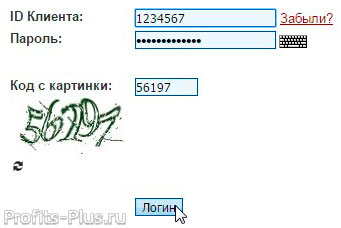
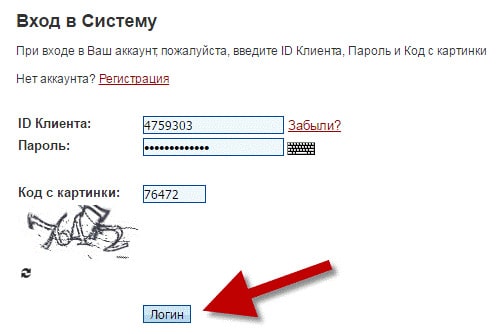
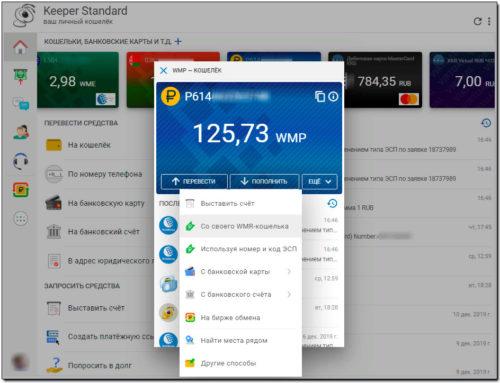
Личный кабинет
Интерфейс биржи доступен на 10 языках: американском и британском английском, французском, испанском, итальянском, португальском, русском, турецком, японском и китайском.
Поэтому платформой пользуются трейдеры со всего мира, работая с биржей на родном языке, что гораздо упрощает процесс обмена и торговли.
Для смены языковой версии, спуститесь вниз сайта и в закладке Language выберете один из 10 предложенных языков.
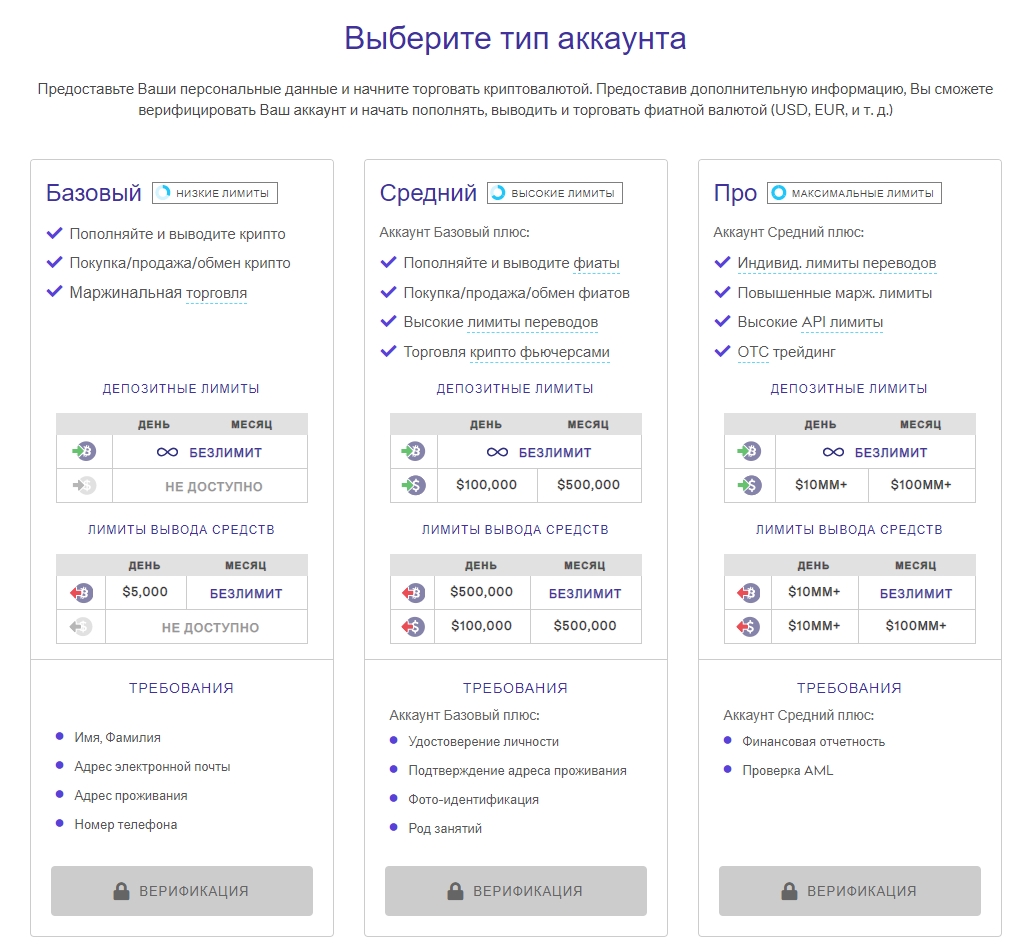
Типы Kraken аккаунтов: Базовый, Средний и Про.
Базовый Kraken аккаунт
Безлимитный депозит;
Пополнение и вывод в криптовалюте (фиат недоступен);
Покупка/продажа/обмен криптовалюты;
Маржинальная торговля;
Средний Kraken аккаунт
Все в Базовый, плюс:
Пополнение и вывод в фиате
Покупка/продажа/обмен фиатных валют;
Высокие лимиты переводов;
Торговля крипто фьючерсами.
Про Kraken аккаунт
Все в Средний, плюс:
Индивидуальные лимиты переводов;
Повышенные марж. Лимиты;
Высокие API лимиты;
ОТС трейдинг.
Каждый пользователь может выбрать тип аккаунта, соответствующий его потребностям в обмене и торговле криптовалютой.
В личном кабинете доступны следующие разделы:
Настройки: аккаунта, уведомления, API, документы;
Безопасность;
История;
Верификация;
Выход.
На странице торговли пользователь увидит следующие вкладки:
Новый ордер;
Ордера: Новые и Открытые ордера, Закрытые ордера;
Позиции: Открытые позиции, Закрытые позиции;
Сделки.
На Kraken можно создавать Простые, Средние и Сложные ордера.
В личном кабинете отображаются также торговые балансы пользователя и его текущая и следующая комиссия (зависит от общего торгового объема).
Верификация на Kraken
Как и многие популярные криптовалютные биржи, Kraken соответствует правилам KYC/AML.
Биржа разделяет аккаунты пользователей на 4 разных уровня, каждый из которых предлагает дополнительные функции, более высокие лимиты и больше возможностей пополнения и вывода. Доступны следующие уровни:
Нулевой уровень. Начальный уровень для всех аккаунтов Kraken, которые имеют подтвержденный адрес электронной почты. Пользователи с нулевым уровнем могут просматривать платформу, но не могут вводить/выводить средства или совершать сделки.
Базовый. Для достижения первого уровня вам необходимо указать свое полное имя, дату рождения, адрес проживания и номер телефона. Это позволит торговать криптовалютами, даст доступ к маржинальной торговле, но не разрешает вводить, выводить или торговать фиатными валютами. Аккаунты первого уровня не имеют максимальных лимитов на депозит криптовалют, но ограничены $5000 в день на вывод криптовалют.
Средний. Второй уровень требует загрузки удостоверения личности, документов, которые подтверждают адрес проживания, прохождения фото-идентификацию и предоставления информации о роде занятий. Аккаунты второго уровня могут вводить до $100 000 в день или $500 000 в месяц. Помимо этого, аккаунты второго уровня позволяют торговать фиатными парами, имеют увеличенный лимит на вывод криптовалют – $500 000 в день. Лимит вывода фиатных валют – $100 000 в день и $500 000 в месяц.
Про. Подтверждение третьего уровня требует предоставления финансовой отчетности и прохождения проверки в в рамках AML (борьбы с отмыванием денег). После проверки будут установлены индивидуальные лимиты, повышены лимиты маржинальной торговли, а также открыт доступ к OTC (внебиржевой) площадке Kraken.
Kraken – самая надежная криптовалютная биржа на рынке.
Активы на бирже Kraken
Kraken тщательно подходит к выбору цифровых активов, поэтому трейдерам, которые имеют опыт торговли, к примеру, на Binance, листинг на этой бирже может показаться довольно скудным.
В настоящее время Kraken предлагает маржинальную торговлю для восьми криптовалют. Доступное кредитное плечо для них составляет как минимум 2x. Максимальное плечо (5x) доступно только для биткоина, эфира и XRP.
В целом Kraken ориентируется на трейдеров, которые торгуют топовыми криптовалютными активами и не подойдет тем, кто “ищет иксы” среди токенов и малоизвестных проектов.
Биржа стабильно входит топ-50 бирж по объему торгов на CoinMarketCap. Подавляющее большинство объемов составляют сделки BTC/USD, BTC/EUR, ETH/ USD и ETH/EUR (около 75% суточного объема торгов Kraken). Суточный объем на бирже составляет около $100 млн. Менее популярные торговые пары имеют проблемы с ликвидностью, поэтому, опять же, это не лучший вариант для тех, кто работает с малоизвестными цифровыми активами.
Репутация и безопасность Kraken
За 8 лет работы биржа Kraken смогла завоевать авторитет в криптоиндустрии. Биржа регулярно проводит внутренний аудит и старается демонстрировать прозрачность даже в условиях недобросовестной конкуренции. Например, большое количество менее авторитетных бирж занимаются wash-трейдингом, чтобы искусственно увеличить свои объемы торгов. Последний отчет Blockchain Transparency Institute показал, что на Kraken не было обнаружено никаких признаков wash-трейдинга, а биржа (вместе с Coinbase) предоставляет самые точные торговые данные.
Однако, несмотря на высокую репутацию Kraken, в интернете можно найти достаточно много негативных комментариев о работе платформы. В большинстве жалоб упоминаются проблемы с верификацией и медленная работа службы поддержки. Также в 2017 году на бирже не раз наблюдались сбои на фоне рекордных объёмов торгов.
Тем не менее, когда дело доходит до безопасности, мало кто может конкурировать с Kraken. На сегодняшний день Kraken является одной из немногих крупных криптовалютных бирж, которая никогда не была взломана.
Глава биржи Джесси Пауэлл говорит, что он и все сотрудники биржи — это «хронические параноики». Биржа уделяет особое внимание персоналу. Если кто-либо в компании делает что-то подозрительное, например, просматривает чей-то аккаунт, на который не было соответствующего запроса в службу поддержки, — будет начато внутреннее расследование. Из-за сложностей, связанных с личной жизнью сотрудников, Kraken рекомендует всем, кто работает в компании, никому не рассказывать об этом (особенно в социальных сетях).
Для достижения максимально возможного уровня безопасности компания Kraken хранит большую часть средств пользователей на холодных кошельках, географически распределенных по нескольким странам. Серверы Kraken контролируются круглосуточно и находятся под защитой вооруженных охранников, а группа экспертов по кибербезопасности регулярно проверяет наличие потенциальных уязвимостей.
Пользователям Kraken предлагает множество дополнительных опций для защиты аккаунта. Они включают в себя дополнительную двухфакторную аутентификацию, а также блокировку настроек аккаунта.
Kraken – самая надежная криптовалютная биржа на рынке.
Торгуйте с уверенностью!
Получение доверия наших клиентов всегда было главным приоритетом. Мы заслужили это доверие благодаря лучшей безопасности в этой отрасле — большинство наших цифровых активов надежно хранятся в «холодных кошельках» следовательно, злоумышленники не могут справиться с ними.
Наша платформа обеспечивает финансовую стабильность мирового класса, поддерживая полные резервы, здоровые банковские отношения и высочайшие стандарты соблюдения правовых норм.
Наша платформа полна различных возможностей.
Наш простой интерфейс, способы быстрых переводов и большой выбор цифровых валют позволяет без особых усилий реализовывать как долгосрочные, так и краткосрочные инвестиционные стратегии. Мы также предлагаем дополнительные возможности, такие как маржинальная торговля и торговля фьючерсами. Таким образом Вы можете получить больше с меньшими затратами, используя все возможности Вашего портфеля.
Забудьте об ограничениях и скрытых комиссиях!
В отличие от традиционных торговых платформ, у нас нет фиксированной комиссии за каждую совершенную сделку, следовательно, у Вас нет скрытых затрат.
The more you trade, the lower your rate. Чем больше Вы торгуете, тем ниже ставка комиссий. Наши комиссии основаны на объеме торгов, поэтому Вы можете совершать больше сделок за меньшие деньги.
Наш список активов все время увеличивается!
Криптовалютная платформа Kraken предоставляет доступ к одному из самых больших наборов монет для торговли с более чем 20 криптоактивами, и этот перечень увеличивается.
У нас множество активов.
Мы предлагаем более 70 валютных пар – пожалуй, самый широкий выбор монет для покупки, продажи и торговли; часто добавляются новые.
Заключение
Пройдя испытание временем, Kraken остается одним из лидеров среди криптовалютных бирж в вопросе безопасности.
Биржа лучше всего подходит европейским трейдерам, которые хотят торговать популярными цифровыми активами (биткоин и эфир) в паре к евро. Платформа по-прежнему довольно популярна среди трейдеров из США и Канады.
Ограниченный выбор цифровых активов и необходимость прохождения верификации может оттолкнуть некоторых трейдеров. Также нуждается в доработке русская локализация биржи, хотя само её наличие можно считать плюсом.
По мнению генерального директора криптобиржи Kraken Джесси Пауэлла, в течение ближайших двух лет биткоин взлетит в цене до $100 000. Такую точку зрения он высказал в ходе онлайн-беседы, организованной инвесткомпанией Pantera Capital. Пауэлл сказал: Большинство людей слышало о биткоине, но у них нет никакого биткоина. Они ничего не знают о будущем биткоина. Я думаю, что
02.06.2020 1552 2 мин Биржи VIP-прогноз Kraken: Биткоин готов прервать многолетний нисходящий тренд или вернуться к $6000
Американская криптобиржа Kraken 7 мая опубликовала свой ежемесячный отчет о состоянии рынка криптовалют. В отчете, который первоначально рассылался VIP-клиентам биржи, говорится о том, что хешрейт биткоина и распространение коронавируса являются двумя ключевыми факторами, на которые следует обратить внимание перед грядущим сокращением вознаграждения за блок (халвингом). Если хешрейт поднимется, а заражение COVID-19 замедлится, то цена биткоина
08.05.2020 5899 2 мин Аналитика Kraken: В ходе «великой передачи богатства» в биткоин может быть инвестировано около $1 трлн
В ближайшие десятилетия произойдет самая крупная передача богатства в истории — поколение X и миллениалы в одних только США унаследуют почти $70 триллионов от поколения беби-бумеров. Об этом говорится в новом отчете Kraken Intelligence, аналитического подразделения американской криптовалютной биржи Kraken. Ожидается, что эта передача богатства приведет к значительным изменениям в инвестиционных трендах, и биткоин намерен
Moon Bitcoin — один из самых проверенных биткоин-кранов, которому доверяют сотни тысяч человек со всего мира. Простота в использовании, высокий уровень надежности, удобные способы вывода накопленных сбережений — достоинств у этого ресурса очень много. Одним единственным недостатком можно считать отсутствие перевода на русский язык. Сервис представлен только на английском языке, что немного затрудняет процесс пользования для русскоязычных посетителей, которые не понимают английский. Но здесь не все так сложно: несколько раз воспользоваться переводчиком — и все станет понятно.
Пользователи Мун Биткоин зарабатывают сатоши — самые маленькие неделимые части биткоина. Так вот эти монетки «капают» на ваш счет постоянно. Даже когда компьютер выключен. Со временем количество сатоши, которые выдаются в минуту, уменьшается.
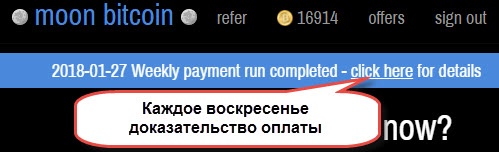
Выводить заработанные деньги можно каждые пять минут. Опытные пользователи Moon Bitcoin советуют выводить накопленные деньги через 15-30 минут. Если у вас нет на это времени, старайтесь снимать крипту хотя бы раз в сутки. Это поможет зарабатывать больше. Кстати, кран умеет осуществлять автовыплаты. Они производятся на кошельки каждую субботу или воскресенье, когда на счету находится минимум 5500 сатоши.
Кран «Луна» предлагает своим пользователям различные способы дополнительного заработка, бонусы, которые принесут доход. Реферальная программа — один из вариантов. Участие в ней поможет увеличить заработок на 50 процентов с каждого зарегистрировавшегося пользователя по вашей рекомендации.
Чтобы привлечь под свое крыло как можно больше майнеров, опытные пользователи рекомендуют тщательно поработать над рекламной кампанией — разместить рекламные баннеры на форумах или других тематических сайтах или хотя бы дать объявление со своей реферальной ссылкой в социальных сетях.
Moon Bitcoin регистрация.
На moon bitcoin регистрация занимает всего пару нажатий и возможна двумя способами (от этого в дальнейшем зависит выплата), рекомендую пользоваться через КоинПот (поверьте это очень упрощает снятие, конвертацию).
Что такое Moonbitcoin
MoonBitcoin – это первый кран из Moon-семейства, который был выпущен компанией. Сервис служит верой и правдой уже почти 5 лет.
Основной доход начисляется просто за клики.
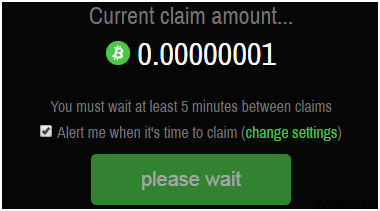
☝️ Средний заработок на сервисе составляет около 10 сатоши. Интервал между запросами на сайте составляет 5 минут.
При этом, если вы не используете вашу попытку, то ставка дохода увеличивается. Таким образом, вы можете собирать мелкие суммы каждые 5 минут или посещать сайт один-два раза в день и получать сразу более существенную прибыль.
Создание аккаунта Moon Bitcoin
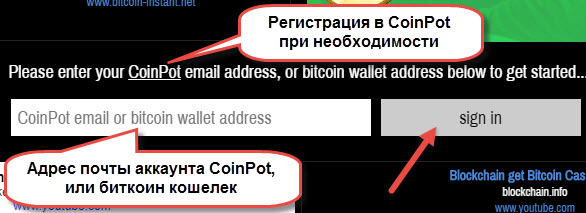
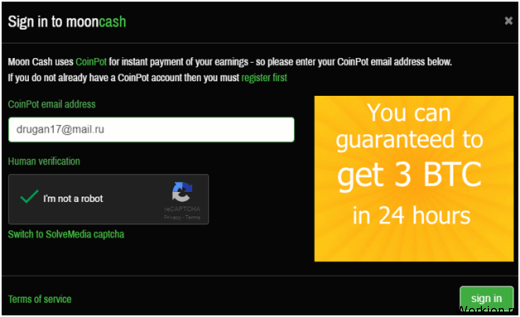
Для начала потребуется создать учетную запись в системе Moon. Если у нового участника нет аккаунта в кошельке для микроплатежей, его необходимо предварительно открыть. Заходят на официальный портал coinpot.co. Для регистрации аккаунта нужно:
ввести адрес электронной почты + подтвердить его;
придумать пароль;
пройти капчу;
поставить галочку согласия с Условиями сервиса.
Процедура простая:
Ввод адреса электронной почты, к которому прикреплен CoinPot, или биткоин-кошелька.
Клик по кнопке Sigh In.
Прохождение капчи и нажатие кнопки Submit.
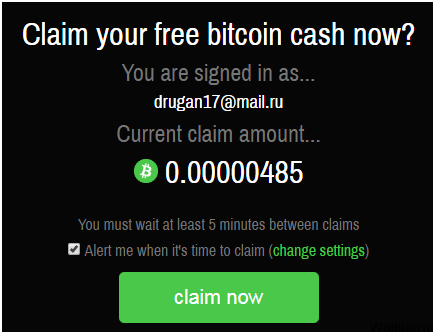
Если пользователь не создал предварительно аккаунт в системе CoinPot, при регистации на Мун Биткоин аккаунт в кошельке откроется автоматически. После регистрации в личном кабинете пользователя сразу начинается сбор монеток.
Подтверждения электронной почты не требуется, поэтому процедура регистрации занимает не более 1 минуты. После авторизации на сайте можно сразу претендовать на получение вознаграждения.
Moon Bitcoin (Moonbit.co.in) инструкция.
Дело в том, что все сервисы коллекции «moon — луна» содержат свои балансы на CoinPot (более детальное описание и полный список) объединяя таким образом в единый общий – это на подобии FaucetHub (кто разбирается). Небольшая инструкция о moonbit для сравнения как лучше зарегистрироваться? Рассмотрим оба варианта.
Через почту от Coin-Pot, (ДА) дает преимущество пользователю собирать со всех поддерживающих краников средства в одно место, там же обменять между собой крипту по курсу на какой-то определенный счет, и вывести при достижении минимума в 10 000 сатошиков.
Используя биткоин-кошелек, (НЕТ) тут денежки собираются и хранятся на аккаунте moon bitcoin, при наборе минимального порога в 25000 они автоматически поступают в обработку на перечисление в кошелек каждые субботу, воскресенье.
По оплате постоянно публикуется еженедельно новость вверху страницы.
Moon bitcoin как зарабатывать?
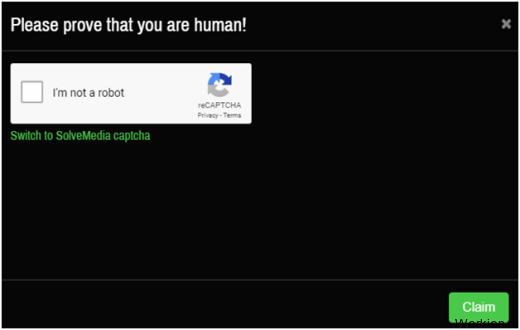
Зарабатывать на moon bitcoin не сложно, все что требуется так это нажать «claim» и отгадать капчу.
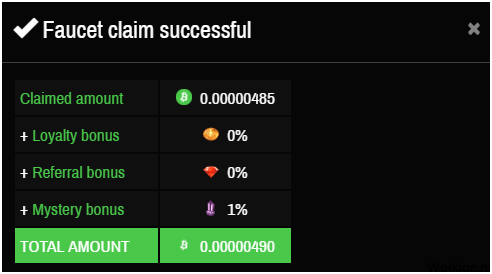
При зачислении появится таблица с Вашим уровнем бонусной доходности, которую при желании можно увеличить от 100% и т. д.
Что такое краны: краткий экскурс
Прежде, чем рассказывать об особенностях Moon Bitcoin, нужно понять, что такое краны и как они вообще устроены.
Криптовалютные краны — это полноценные сайты, которые обычно состоят из одной или двух страниц и позволяют посетителям получать небольшое количество виртуальной валюты за совершение определенных действий. В первое время, основной целью этих ресурсов было привлечь внимание пользователей к электронным деньгам. Они позволяли заработать свои первые коины без материальных вложений.
Сегодня большинство кранов — коммерческие проекты, которые вознаграждают посетителей за просмотр рекламы или введение капчи, клики по баннерам или участие в играх.
Сразу опустим вас с небес на землю: заработать на кранах миллионы нереально. Чаще всего заработок на таких ресурсах мизерный. Так что основным источником дохода такая деятельность точно не может стать.
Капля с крана
Когда-либо вы могли себе представить, что при слове «кран» ассоциация будет не только с сантехникой? Это одно из подтверждений тому, что криптовалюты меняют многое в нашем мире: от способов проведения платежей до понимания многих слов.
Сегодня, если вы находитесь в окружении пользователей криптовалют, то под словом «кран» также стоит понимать проект, который совершенно бесплатно раздает монеты. Награда совсем мизерная, но зато нет никаких вложений.
Это можно сравнить с каплей из обычного крана. Награда в монетах совершенно небольшая и получить ее можно раз в пять минут, а то и реже. Если кран протекает, то через определенные промежутки времени из него падает маленькая капля. Возможно именно так они и получили свое название.
Как выбрать
Поскольку речь идет о кранах для Биткоин Кэш, то простой анализ просторов Интернета дает понять, что для него создано очень много подобных площадок. Это связано с тем, что данная монета стала очень успешным хард форком лучшей криптовалюты мира, да еще и умудрилась превзойти ее по некоторым показателям. Кроме того, многие известные бренды признали BCH еще до его фактического появления.
Это сразу дало многим понять, что на данную криптовалюту будет спрос. А как стало понятно после хард форка, все, кто имел на своем счету любое количество Bitcoin, смогли получить столько же Bitcoin Cash. Но ведь не каждый рядовой пользователь захотел с ним работать. Как извлечь из этого выгоду? Кто-то просто обналичил, а кто-то явно решил создать кран и раздать свои монеты, заработав на рекламе.
Таким образом появилось даже больше площадок, чем вы сможете найти для BTC. Но кроме честных добродетелей появились также те, кто решил обмануть наивных пользователей. Потому стоит очень осторожно подходить к выбору крана.
Особо важных или ключевых показателей вы не встретите, поскольку такая площадка — это куча рекламы и кнопка для получения награды. Но есть несколько моментов, которыми мошенники себя часто выдают.
Первое — предлагают большое вознаграждение. Оно бывает действительно нелепым. Любой пользователь понимает, что бесплатный сыр лишь в мышеловке, и за простой клик никто так просто не отдаст много денег. Как только видите, что кран предлагает десятки Биткоин Кэш, можете смело покидать сайт и больше не возвращаться.
Второе — маленький период ожидания. Механика кранов такова, что награду можно получать не чаще, чем каждые 5 минут, а то и намного реже (к примеру, раз в день). Если же какой-то кран предлагает бесконечные награды ежесекундно, то также в этом верить не стоит. Иначе владелец подобной площадки быстро опустошил бы свои карманы, не успев заработать.
Третье, уже для многих привычное — это отзывы. Очень часто бывает лень зайти на какой-то форум и найти мнение пользователей о конкретном проекте. Но отзывы играют очень большую роль при выборе крана для криптовалют.
Выбор есть
Среди всего потока предложений есть категория кранов, которые платят честно из безоговорочно, предоставляя при этом довольно комфортные условия использования. Для таких криптовалют, как Litecoin, Bitcoin или Dogecoin, вы могли видеть Moon краны. Ни по одной из монет они еще не подводили.
Естественно, существует и Moon Bitcoin Cash. Он ничем не отличается от площадок под другие криптовалюты, кроме как самой монетой.
Первое, что примечательно и сильно выделяет его среди остальных проектов — вы вольны выбирать момент для получения награды. Пока некоторые площадки устанавливают периоды в полчаса, час или даже сутки, здесь вы можете получить награду когда-угодно. Единственное, что стоит учесть — минимальный период ожидания для одного адреса — 5 минут.
Вы тут же скажете, что есть много площадок с таким периодом. Однако на них награда не растет пропорционально времени отсутствия активности. А вот на мун кранах вы сможете получить больше, если заберете монеты не через 5 минут, а через час. Таким образом, если у вас нет возможности заходить на площадку слишком часто, вы все равно ничего не потеряете.
В среднем, начальная награда составляет 50–100 сатоши BCH. Однако вы можете увеличить ее благодаря системе бонусов. Первый — ежедневный бонус. Все очень просто: если вы хотя бы раз в день заберете награду, на следующий к ней добавится 1%. Максимально можно увеличить на 100%. Таким образом, через 100 дней вы будете получать минимум 100–200 сатоши. Естественно, если какой-то день будет пропущен, то бонус аннулируется.
Второе — реферальная программа. Во-первых, от каждого приглашенного пользователя вы будете пожизненно получать 25% с его награды. Во-вторых, за каждого активного реферала вам будет начисляться 1% к вознаграждению. Таковыми считаются те пользователи, которые получили прибыль в последние 72 часа.
Третье — это секретный бонус. Он не подкрепляется ничем. Конечно, есть какой-то алгоритм, по которому он начисляется, однако просчитать его пока что не удалось. К сожалению, он также может принести лишь до 100% от вашей награды. Скорее всего, его дают как премию за активность или же количество привлеченных пользователей. Так или иначе, в любой момент вы можете быть приятно удивлены.
Куда зачисляется награда
Каждое вознаграждение от мун Биткоин Кэш присылается на ваш кошелек в CoinPot. Потому, прежде нужно зарегистрироваться на этом сайте. Она займет у вас несколько секунд: нужен лишь адрес электронной почты и пароль.
При первом использовании Moon Bitcoin Cash нужно будет ввести адрес почты, который вы использовали для создания кошелька. Не нужно пробовать вводить сам адрес кошелька, поскольку в таком случае кран просто не распознает его и соответственно не предоставит возможности получать монеты.
Не стоит играться
Многие хотят просто обмануть платформу и пробуют создать фейковых рефералов путем создания новых адресов CoinPot. Но стоит учитывать, что каждый пользователь учитывается не только через почту кошелька, но и по IP-адресу. Если вы переусердствуете, то все рефералы и основной аккаунт будут просто заблокированы.
Проблемы с получением
Существует несколько случаев, из-за которых пользователи могли не получить награду или даже не увидеть кнопки для этого. Первая, самая распространенная — это наличие блокиратора рекламы. Краны живут за счет нее. Если пользователь имеет блокировку, то владельцу площадки не будет смысла ее держать. Потому перед получением награды нужно выключать Adblock.
Второе — это несовместимость с браузером. На самом деле, она встречается очень редко, поскольку большинство пользователей сидят в Интернете через Chrome, Opera, Mozilla или Safari, которые известны по всему миру и поддерживаются всеми сайтами. Но если же у вас какой-то иной браузер, тогда попробуйте скачать один из вышеназванных, дабы использовать Moon Bitcoin Cash.
Если данная статья показалась вам полезна, уважаемый читатель, подписывайтесь на группы в соцсетях и делитесь полезной информацией с друзьями — вдруг они как раз сейчас ищут порядочные краны для заработка криптовалюты.
Как работает MoonBitcoin Cash?
Кран стандартный, сайт напичкан рекламой, за счет которой и привлекаются деньги.
Рекламодатели переводят их администрации, а она часть этих средств раскидывает между посетителями. Всё, что потребуется делать, это вводить капчу (она здесь от Google, самая простая).
Бесплатно вы можете собирать и Биткоины на лучшем кране с лотерей FreeBitcoin.
Выплаты мгновенные на кошельки CoinPot. Если вы ещё не зарегистрированы в данной системе, сделайте это прямо сейчас. Мультивалютный кошелек под криптовалюты пригодится вам для работы с другими сервисами. Собранные монеты можно будет потом вывести на другой счет:
Чтобы подать заявку на вывод, нужно собрать минимум 0,0001BCH. Обрабатываются они в течение 48 часов, комиссии нет. Если переводить деньги на FaucetHub, то комиссия составит 1.5%.
С использованием этого кошелька не должно быть проблем, потому что в нём не так много функций.
Как получить бонус MoonBitcoin Cash Faucet?
В отличие от многих кранов, здесь разрешается собирать бонусы каждые 5 минут. Да, суммы небольшие, зато они моментально переводятся на кошелек. Также есть дополнительные поощрения, но о них расскажем отдельно.
Чтобы никто из новичков точно не запутался, покажем подробную инструкцию по получению бесплатных Биткоин Кэш:
Когда зайдете на сайт, в центре главной страницы увидите кнопку для перехода к сбору бонуса:
Для авторизации нужно указать Email, который использовался при регистрации на CoinPot и ввести капчу:
После этого вы попадаете в личный кабинет, где по центру размещена кнопка сбора бонуса и показан его размер:
Чтобы забрать эту небольшую сумму, просят пройти проверку на бота:
Дальше появляется уведомление о начислении бонуса. Вся сумма мгновенно переводится на кошелек CoinPot:
Теперь нужно ждать 5 минут, когда будет доступен следующий бонус. В это время кнопка становится не активной. Ставьте галочку над ней, чтобы получать уведомления о доступности бонуса:
Не обязательно посещать сайт так часто, можно заходить в него и раз в сутки, но тогда прибыльность будет вообще незаметной.
По приблизительным расчетам, за 24 часа удается насобирать бонусов на сумму в районе 10 центов. Но ведь курс BCH может вырасти и это не единственный способ получить криптовалюту.
Сколько можно заработать с Moon Cash
Сервис Moon Bitcoin Cash пользуется огромной популярностью среди криптоэнтузиастов. Но что касается заработков, то ничем выдающимся портал похвастаться не может. Как и все краны в текущей ситуации, этот кран криптовалют платит мало.
На сайте выставлена официальная информация, где указаны текущие возможности заработка на портале.
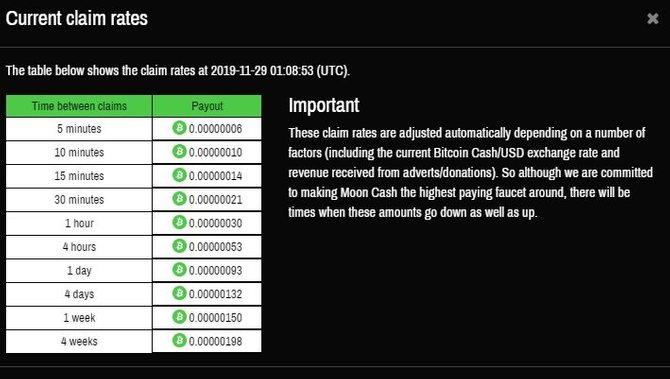
Текущие ставки на Moon Cash
Как видите, начисления сейчас совсем небольшие. За месяц даже до минималки для вывода не дотянем. Но, как уточняют собственники крана, ставки регулярно корректируются в зависимости от курса биткоина и доходов компании, поэтому можно ожидать, что заработать на кране через какое-то время можно будет больше.
При этом не стоит забывать, что существенно увеличить свой доход можно за счет реферальной программы. Опытные игроки постоянно продвигают свою ссылку на тематических форумах и в соцсетях и за счёт этого имеют стабильный пассивный доход.
Дополнительные бонусы
Есть на сайте два дополнительных бонуса. Первый «Таинственный», о нём ничего конкретного на сайте не написано, но он может увеличивать размер бонуса. Второй «Ежедневный» — прибавляет по 1% к бонусу, за каждодневный вход в аккаунт.
Максимум можно увеличить сумму на 100%, но для этого придется 100 дней подряд посещать профиль. Если хотя бы один день будет пропущен, придется начинать всё сначала.
Учтите, все ваши бонусы могут сгореть, если администрация обнаружит, что у вас установлены программы, блокирующие показ рекламы.
Кроме этого, в основном меню крана пользователям предлагают «Задания». Но там нет каких-то поручений, просто предлагают воспользоваться другими сервисами, где тоже раздаются криптовалюты:
Если есть время на это, обязательно используйте несколько кранов одновременно. Это не только позволит собирать больше бонусов, но и сделать несколько источников дохода, ведь на всех этих проектах есть реферальные системы.
Партнерская программа MoonBitcoin Cash
В меню профиля (пример выше) есть также раздел Referrals. Нажав на эту ссылку открывается окно с промо материалами и кнопками, чтобы поделиться постами в социальных сетях.
Приглашайте новых участников и получайте 25% от собранных ими бонусов. Разрешены любые методы привлечения рефералов.
Все отчисления по партнерской программе также мгновенно переводятся на CoinPot счет.
Кроме этого, за каждого активного реферала в сутки дается по 1% к основному бонусу (который сам собираешь).
Т.е. если 100 приглашенных человек сегодня посещали свои профили, получаешь на 100% большую сумму. Эти данные отображаются в оповещении о начислении средств:
Первый – ежедневный бонус, второй реферальный, третий случайный. В общей сложности бонус может быть увеличен на 300%. Начинайте распространять свою ссылку, можно даже через буксы создавать задания.
MoonBitcoin Cash не работает, что делать?
Технические проблемы бывают у всех, поэтому стоит немного подождать, когда сайт не открывается.
При переезде на новый домен пользователи часто жаловались, что MoonBitcoin Cash не работает, но всё восстановили и оставили пропущенные дни не учтенными, ведь клиенты не виноваты.
Также в FAQ сайта указано, что проблемы с доступом могут быть связаны с используемым устройством или браузером. Поэтому первым делом попробуйте зайти на сайт с другого браузера.
При написании этой статьи площадка тестировалась, выплаты на кошелек реально приходили, всё работает.
Отзывы о MoonBitcoin Cash
После смены домена у проекта началась новая волна популярности. Отзывы только положительные, репутация безупречная, а новости о кране выходят прямо на CoinPot.
Даже если кран быстро закроется, ничего не потеряешь, ведь все твои монеты сразу переводятся на отдельный кошелек.
Сейчас MoonBitcoin Cash платит, жирный кран с моментальными выплатами – это именно то, что все ищут.
Пользоваться им не сложно, рефералов вы точно найдете, потому что Биткоин Кэш сейчас популярен и за активность будете поощряться 100% бонусом. Однако, самый большой профит может приносить только партнерская программа.
Параллельно собирайте Сатоши каждые 15 минут Bonusbitcoin co. Это ещё один кран с выплатами на КоинПот.
Кран Биткоин Кэш MoonBitcoin Cash – лучший среди аналогов. Бонусы незначительные, только за счет бонусных программ их удается увеличить. Поэтому активные пользователи зарабатывают тут больше. Пользуйтесь партнёркой, заходите каждый день, собирай свои бесплатные BCH.
Как вывести деньги c Moonbitcoin
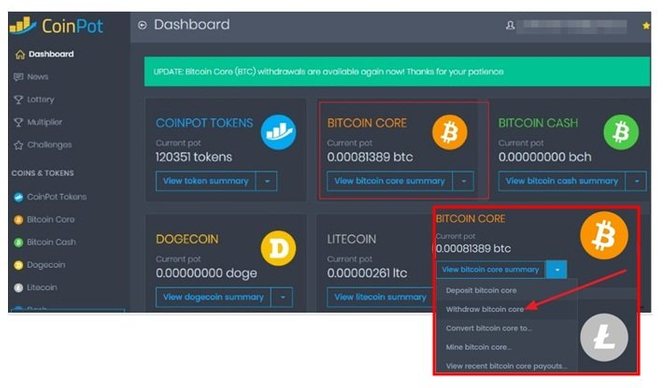
Чтобы вывести заработанные сатоши, зайдите в меню баланса, которое расположено на верхней панели и кликните по ссылке перехода в кошелек CoinPot.
Вывод монет с Moonbitcoin
На главной странице будут выведены балансы по всем криптовалютам. Находим блок с балансом Bitcoin и в выпадающем меню выбираем кнопку вывода монет как показано на скрине ниже.
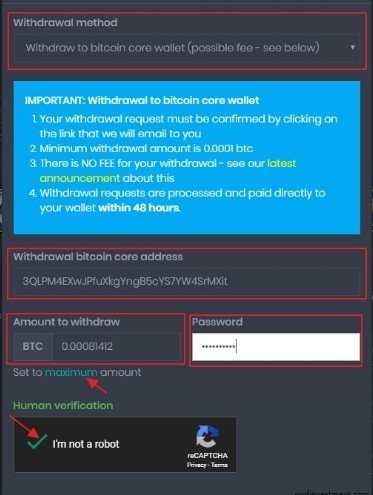
Вывод Bitcoin с кошелька CoinPot☝️ Минимальный лимит снятия составляет 0,0001 BTC (10000 сатоши). Вывод происходит без комиссии.
Чтобы вывести заработанные монеты, необходимо заполнить форму, где требуется указать адрес биткоин-кошелька, сумму, вводим пароль, проходим капчу и нажимаем «Withdraw».
Вывод Bitcoin с кошелька CoinPot
Каждая заявка на вывод подтверждается пользователем через email. Перечисление средств занимает до 48 часов.
Преимущества и недостатки
Основным минус Мун Биткоин — отсутствие русскоязычной версии сайта, но интуитивно понятный интерфейс позволяет зарабатывать без знания английского. В крайнем случае можно использовать онлайн-переводчики. В некоторые браузеры (Google и Яндекс) встроены переводчики, и страницу можно переводить автоматически.
Достоинства Мун Биткоин:
Многолетний опыт работы, что говорит о надежности и стабильности сервиса по заработку Биткоина.
Удобный, простой интерфейс.
Простота заработка (не требуются специальные навыки и знания).
Возможность получать пассивный доход в Биткоинах. В отличие от большинства других сервисов, на Moon монеты копятся постоянно. Можно заходить раз в день или в неделю и снимать прибыль.
Дополнительный доход в виде BTC на опросах и мини-задачах.
Бонусы + выгодная реферальная программа.
Отсутствие минимального порога для вывода.
Моментальные автоматические выплаты Bitcoin.
Онлайн-сервис Moon Bitcoin — один из наиболее прибыльных и выгодных кранов по сбору BTC. Большие деньги на сайте получить не выйдет, но использовать ресурс в качестве дополнительного заработка или для накопления стартового капитала для вложений в криптовалютную индустрию можно. Хотя сайт существует давно, портал остается прибыльным и соответствует последним тенденциям индустрии.
Что такое Moon Litecoin
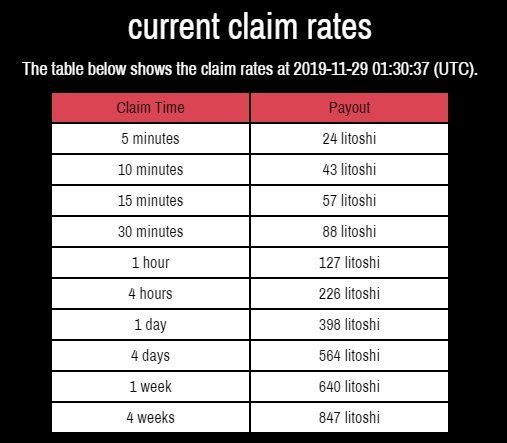
Moon Litecoin – это один из крупнейших кранов, который бесплатно генерирует Litecoin. Единица измерения на сайте – литоши.
Текущие ставки Moon Litecoin☝️ Официальный сайт Moon Litecoin
Как получить Лайткоин
Как и на других сервисах Moon-семейства, чтобы заработать на Moon Litecoin, необходимо выполнить 3 простых действия:
Шаг 1. Зарегистрироваться на CoinPot (если не сделали этого ранее).
Шаг 2. Зарегистрироваться на Moon Litecoin.
Шаг 3. Нажать кнопку «Claim now».
Если вы хотите детальнее разобраться с особенностями заработка монет на Moon Litecoin, читайте наш подробный обзор далее.
Помним, что аккаунт на CoinPot и Moon Litecoin должны быть связаны. Поэтому регистрацию на обоих сервисах проводим используя один и тот же email.
Создание аккаунта на CoinPot описано в предыдущих разделах обзора, потому рассмотрим регистрацию на Moon Litecoin.
Переходим на официальный сайт Moon Litecoin и регистрируемся по email.
Регистрация на Moon Litecoin
Чтобы заработать первые литоши, жмем кнопку «Claim now» и проходим капчу.
Заработок монет на Moon Litecoin
Заработанные деньги падают на баланс с учетом бонусов.
Заработок монет на Moon Litecoin
Следующая попылка собрать бесплатные монеты будет доступна через 5 минут.
Как вывести литоши с Moon Litecoin
Вывод монет происходит через меню баланса. Кликаем «Go To CoinPot» чтобы перейти в свой профиль микрокошелька.
Вывод монет с Moon Litecoin
Находим блок Litecoin, переходим в заполнение формы для вывода. Тут указываем все необходимую информацию и нажимаем «Withdraw».
Вывод монет с Moon Litecoin☝️ Минимальная сумма для вывода 0,002 LTC (200000 литоши). Комиссия отсутствует.
Moon Dogecoin
Заработок на Moon Dogecoin
На очереди еще один представитель мун-семейства – криптокран Moon Dogecoin. Рассмотрим его детальнее.
Что такое Moon Dogecoin
Moon Dogecoin – кран для бесплатного сбора криптовалюты Dogecoin (DOGE).
Точно также как и другие Мун краны, этот сервис имеет хорошую репутацию и пользуется большой популярностью за счет стабильных выплат.
Условия работы с сайтом не отличаются от других кранов семейства. Сервис платит за прохождение капчи. Максимальная частота сбора монет – каждые 5 минут. Минимальная – неограничена.
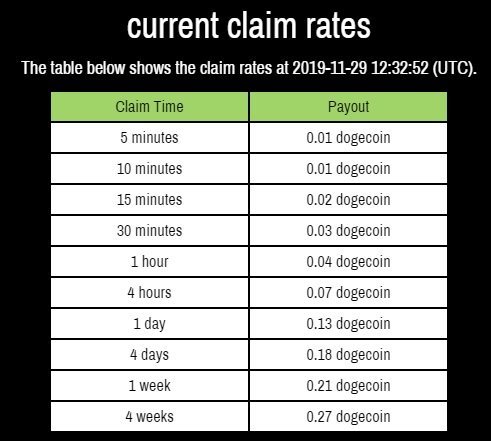
Текущие ставки Moon Dogecoin☝️ Официальный сайт Moon Dogecoin
Как получить Догикоин
Чтобы начать получать бесплатные Доги на Moon Dogecoin, вам необходимо выполнить 3 простых действия:
Шаг 1. Зарегистрироваться на CoinPot (если не сделали этого ранее).
Шаг 2. Зарегистрироваться на Moon Dogecoin.
Шаг 3. Нажать кнопку «Claim now».
Чтобы узнать больше о заработке на Moon Dogecoin, читайте далее более подробный обзор.
Помним, что аккаунт на CoinPot и Moon Dogecoin должны быть связаны. Поэтому регистрацию на обоих сервисах проводим используя один и тот же email.
Регистрация на Moon Dogecoin
За сбор монет отвечает кнопка «Claim now».
Заработок монет на Moon Dogecoin
Как и другие краны, сервис начисляет дополнительные бонусы за активность.
Система бонусов на Moon Dogecoin
Как вывести монеты с Moon Dogecoin
Через меню баланса переходим по ссылке в кошелек CoinPot. Находим блок с Dogecoin и переходим на экран вывода.
Вывод с Moon Dogecoin
Заполняем форму для вывода и нажимаем «Withdraw». Минимальная сумма вывода 100 DOGE. Комиссии нет.
Накопительные краны Dogecoin
Кроме крана Moon Dogecoin, можно использовать другие сервисы, позволяющие собирать монеты, накапливать их на счету, а после — выводить на адрес бумажника.
Лучшие накопительные сайты для получения Догикоина:
Freedoge.co.in — площадка для сбора Dogecoin с периодичностью один раз в час. Аналогичный ресурс имеется для криптовалюты Bitcoin. Размер выигрыша составляет от 0,09 до 17,6 тысячи коинов в зависимости от выпавшего числа, но показатель периодически пересматривается. Для начала работы требуется ввести адрес email, придумать пароль и указать адрес кошелька, куда будут переводиться собранные монеты. Максимальный размер выигрыша (по заявлению разработчиков) составляет до 150 долларов в криптовалюте. Предусмотрена возможность для получения бонуса в размере одного миллиона Догикоинов. Работает партнерка, позволяющая получать 50 % от дохода реферала. На 15 января 2019 года на сайте зарегистрировано около 3,9 миллиона человек и сыграно больше 23 миллиардов игр.
Dogecoins4free.com — кран с возможностью сбора Догикоинов раз в 10–15 минут. Для увеличения дохода рекомендуется поиграть в кости. После очередного броска доход пользователя может увеличиться или уменьшиться в зависимости от выпавшего числа. Пользователям, желающим сыграть по-крупному, доступна специальная лотерея. Для повышения статуса доступна возможность обновления профиля до Голд. В этом случае можно требовать монеты раз в 45 минут. Открывается возможность для участия в пожизненной партнерской программе, позволяющей рассчитывать на 30 % от заработка (в обычном режиме платится 25 %). Дается ссылка в размере 20 % на размещение рекламы, а нижний порог вывода коинов уменьшается до 43 000 (вместо 100 000). Увеличивается число лотерейных билетов до трех.
Speedup—faucet.com/doge — кран с зачислением Догикоинов с периодичностью раз в десять минут. Максимальное число переводимых средств — 1,76 монеты. Комиссия за привлеченных рефералов составляет 20 %. Для начала работы требуется ввести адрес DOGE, после чего авторизоваться на сайте. Во время работы запрещено использовать VPN, запрашивать криптовалюту с нескольких адресов или включать блокировщик рекламы.
Среди накопительных кранов наиболее популярный Moon Dogecoin, имеющий лучшую репутацию и отзывы пользователей. Накопительные сервисы немного потеряли популярность, и их место занимают краны с мгновенной выплатой.
Краны Dogecoin с мгновенным перечислением средств
Краны с моментальной выплатой коинов подразумевают оплату работы пользователя мгновенно, без проволочек по времени. Лучшие краны Dogecoin, функционирующие по принципу мгновенной выплаты заработка:
Queenfaucet.website/doge/ — кран, обеспечивающий заработок в размере 0,4635 коина (около 0,001 доллара) раз в две минуты. Особенность сервиса в мультивалютности, мгновенном выводе денег на FaucetHub и легкости заработка (достаточно ввести адрес криптовалюты). Для роста заработка можно привлекать рефералов, которые приносят 10 % от полученной прибыли.
Claimfreedoge.win — мультивалютный кран с мгновенным выводом на FaucetHub. На 15 января 2019 года величина выплат на сервисе достигает одного Догикоина с периодичностью сбора раз в пять минут. Для сбора коинов требуется ввести адрес бумажника и указать капчу. В отличие от прошлого сервиса, предусмотрена улучшенная реферальная программа — до 50 % за привлеченного партнера.
8raa.com/dogecoin/ — сервис, известный любителям бесплатного сбора криптовалюты. Периодичность входа и сбора токенов равна раз в пять минут. За один вход предлагают хороший доход в виде 0,3357 коина. Заработанные деньги мгновенно зачисляются на FaucetHub. Партнерка рассчитана на получение 10 % от заработанных рефералом средств. Ссылка для привлечения пользователей приведена на сайте.
Заработок на сайте Moon Dogecoin и других кранах — начальный этап для участников криптосети, планирующих пополнить криптовалютный кошелек, но не желающих вкладывать большие суммы в майнинг. Рассматривать этот вид заработка серьезно не стоит, ведь даже при активной деятельности месячный доход вряд ли перешагнет через отметку в 20–50 долларов.
LocalBitcoins – популярный сервис, который позволяет торговать биткоинами в 248 странах и 7685 городах мира.
Официальный сайт торговой площадки локал биткоин — Localbitcoins.net. Он является официальным зеркалом LocalBitcoins, которое было создано осенью 2016 года, когда основной сайт LocalBitcoins.com был заблокирован Роскомнадзором.
Поэтому, если ваш провайдер блокирует основной сайт и вы не знаете, как зайти на localbitcoins, смело используйте русскоязычное официальное зеркало сервиса, доступное из любой точки мира.
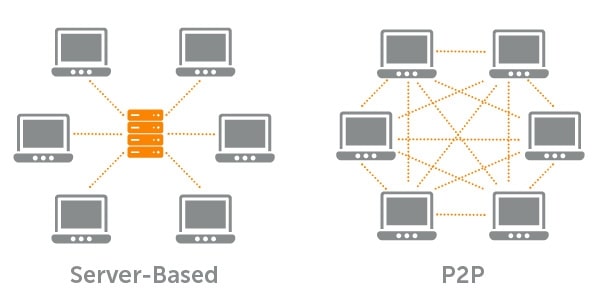
LocalBitcoins работает по принципу P2P, и по сути это аналог привычной нам доски объявлений, когда обмен происходит напрямую между пользователями. Вся логистика осуществляется специальным ПО, которое автоматически соединяет пользователей с одинаковыми условиями купли-продажи валют. Поэтому участие третьих лиц и, соответственно, выплата им вознаграждения не требуется.
P2P развивает философию децентрализации, которой руководствовались создатели биткоина.
Преимуществом личной сделки является то, что продавец может установить свою стоимость монет, которая превышает рыночную. Сделка совершается тогда, когда находится покупатель, принявший эти условия. Таким образом, заработать получится больше, чем осуществляя торговлю через обменник или биржу, а отсутствие стороннего сервиса освобождает от затрат на комиссию.
Обратная сторона медали — высокий риск наткнуться на недобросовестных контрагентов и понести финансовые потери.
Мы сделали большой обзор на один из крупнейших P2P обменников — LocalBitcoins , популярность которого только растет, как и желание пользователей зарабатывать больше на сделках с криптовалютой.
История LocalBitcoins
История LocalBitcoins началась в 2012 году в Финляндии (Хельсинки). Здесь компания была зарегистрирована, здесь же находится ее головной офис. Изучая тот или иной сервис для работы с криптовалютой, всегда интересно узнать, кто его создал. Личность создателя играет важную роль при запуске подобныых проектов. И чем больше авторитет и опыт человека, создавшего новый криптопродукт, тем выше степень доверия к нему с самого старта.
Что касается LocalBitcoins, ее основателем является Николаус Кангас, который запустил сервис вместе с братом. Все начиналось с инвестиций всего в несколько тысяч долларов.
По словам Кангаса, когда он задумался о создании LocalBitcoins, вариантов покупки и продажи биткоина на рынке практически не было. Он поставил своей целью расширить возможности работы с криптовалютой там, где не может быть применена традиционная банковская система.
“Наша цель – улучшить торговые возможности и обслуживать людей, которые имеют ограниченный доступ к финансовым услугам”.
Таким образом, ему удалось создать глобальную платформу, которая гарантирует пользователям то, что их криптовалютные активы находятся за рамками контроля государства. Например, налоговая никогда не узнает о продаже биткоинов за наличные. Такой подход обеспечивает анонимность и минимизирует риски потери капитала.
Получите бесплатный видео-курс по трейдингуEmail*Смотреть курс Даже с появлением многочисленных специализированных сервисов и открытию новых возможностей, LocalBitcoins продолжает набирать популярность. На фоне крупных криптовалютных бирж, суточные торговые объемы которых превышают сотни миллионов или даже миллиарды долларов, показатели работы на LocalBitcoins значительно скромнее.
Однако, о значимости ресурса говорит то, что к его услугам часто обращаются жители стран, чья экономика находится в глубоком кризисе (например, Венесуэла). Или значительный всплеск активности в Канаде в следствие того, что Bank of Montreal стал блокировать криптовалютные транзакции клиентов.
“Если сравнивать нас с большими биржами, которые делают $100 млн в день, то мы, конечно, покажемся мелким игроком. Но, как я думаю, мы решаем базовую проблему покупки и продажи биткоина за фиат”, — говорит Кангас.
Эта проблема была еще более очевидной в 2011 году, когда у братьев Кангас впервые возникла идея такого сервиса. Сейчас LocalBitcoins продолжает развиваться и процветать, даже когда идет сильная конкуренция со стороны поднявшихся на венчурном финансировании криптовалютных бирж.
Инструкция по работе с LocalBitcoins
Для прохождения регистрации на бирже ЛокалБиткоинс, вам необходимо перейти на официальный сайт и нажать на кнопку «зарегистрироваться бесплатно», находящеюся в самом центре страницы. Дальше вы перейдете на страницу регистрации.
Личный кабинет
Создание счета
Шаг 1: Нажмите здесь, чтобы зарегистрировать счёт на LocalBitcoins. Нажмите «Создать счёт бесплатно.»
Шаг 2: введите свою информацию и нажмите «Зарегистрироваться.»
Шаг 3: Подтвердите вашу электронную почту и войдите на сайта.
Покупка биткоинов
Теперь пришло время купить биткоины за рубли, доллары или любую другую фиатную валюту. Идеальным вариантом будет передача наличных денег из рук в руки, поскольку это самый трудно отслеживаемый путь для обмена денег.
Вы можете также выбрать создание собственного ордера с ценой, которую предпочитаете или выбрать ту цену, которая уже была размещена кем-то. Помните, что так как пользователи предоставляют вам услугу продажи биткоинов, они могут назначать свою наценку к рыночной цене.
Наценка меняется в зависимости от типа платежа, репутации пользователя и качества обслуживания. В идеале, вам нужно найти лучший баланс между предложениями продавцов и ценой.
Никогда не пытайтесь торговаться с продавцом, чтобы изменить условия. Этого, скорее всего, не произойдёт, и продавец не будет ценить вас как клиента.
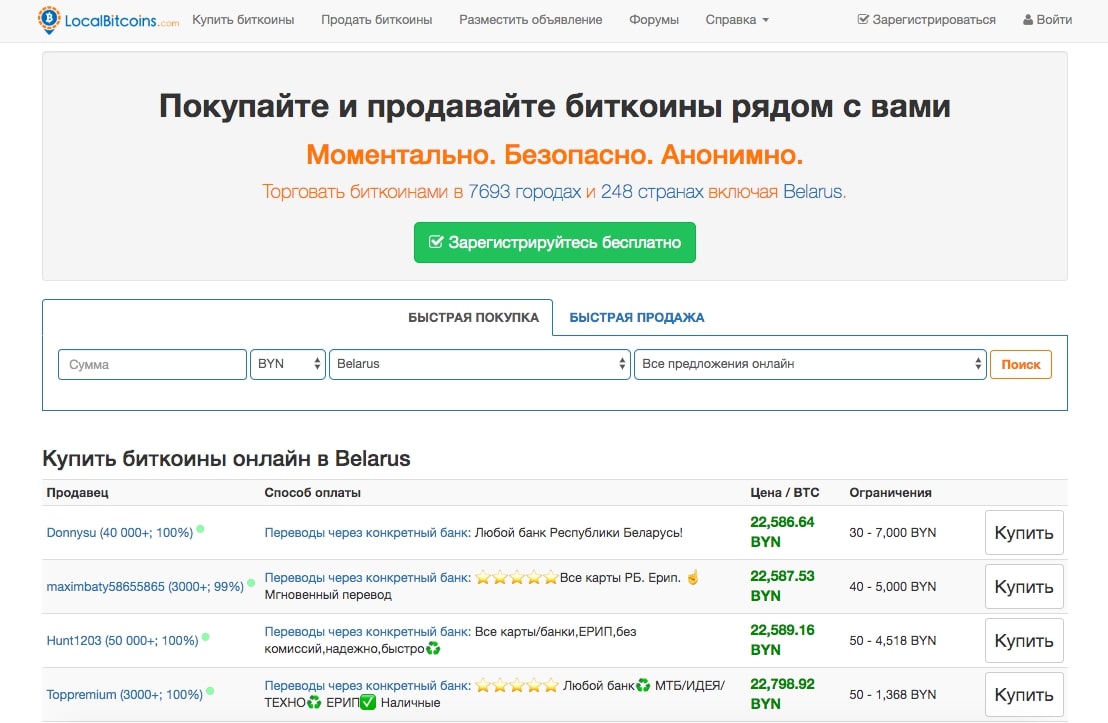
Шаг 1: введите количество (1) и валюту, за которую хотите купить биткоины (2), ваше месторасположение (3), и тип платёжного метода (4). Мы собираемся выбрать наличные из рук в руки.
Шаг 2: нажмите «поиск.»
Шаг 3: выберите предложение, которое наилучшим образом отвечает вашим потребностям, учитывая расстояние до продавца, цену и репутацию продавца. Затем нажмите «купить.»
Репутация продавца находится возле его имени. Первое число это количество сделок и второе это % позитивных отзывов. (В этом примере, у продавца более 100 сделок и 100% позитивных отзывов).
Шаг 4: убедитесь, что вы прочитали условия сделки (1) и согласились с ними перед тем, как продолжить. Затем выберите количество биткоинов, которые вы хотите купить (2) и нажмите «послать запрос на сделку» (3).
Вам нужно начать чат с продавцом. Следуйте инструкциям продавца, чтобы заключить с ним сделку. Его биткоины останутся на условном депонировании до тех пор, пока сделка не завершится, и затем вы сможете вывести их на свой личный кошелёк.
Как самостоятельно создать ордер на Localbitcoins?
Если вас не устроил ни один из доступных ордеров, вы всегда можете создать свой собственный ордер. Если он кого-либо заинтересует, то человек откроет ордер и будет следовать вашим условиям. Помните, что для исполнения вашего ордера может понадобиться очень долгое время, в зависимости от цены, вашего месторасположения и количества.
Шаг 1: нажмите «Разместить сделку»:
Шаг 2: Заполните настройки, которые предпочитаете и нажмите «опубликовать рекламу» внизу страницы:
Шаг 3: Ждите, пока кого-нибудь устроит ваш ордер и начните чат с этим человеком, чтобы согласовать место и время.
Это немного сложнее — создать ордер вместо того, чтобы воспользоваться уже готовым, так что убедитесь, что вы готовы провести своего «клиента» через этот процесс. Если же нет, вы всегда можете воспользоваться уже готовым ордером, что будет проще. Более того, сделки бесплатны для тех, кто выполняет ордер, в то время как тот, кто разместил ордер, платит 1% комиссию.Читайте так же: “Лучшие криптобиржи”
Насколько безопасен LocalBitcoins?
Сервис устроен по децентрализованному принципу, поэтому пользователи должны соблюдать определенные правила, чтобы защититься от злоумышленников. Сайт заслуженно считается безопасной и надежной площадкой, где можно купить или продать биткоины, однако всегда существует риск обмана. Чтобы избежать мошенников и нечестных продавцов, воспользуйтесь следующими советами:
Проверьте профиль продавца и убедитесь, что он отвечает вашим требованиям. Выбирайте поставщиков, которые работают на сайте не менее года, имеют высокий рейтинг и провели сделки хотя бы на 100 BTC. Кроме того, многие проверенные продавцы указывают свои реквизиты, номер телефона и адрес электронной почты.
Свяжитесь с продавцом и запросите обмен через платформу. Избегайте сделок за пределами платформы, поскольку в этом случае вы не сможете воспользоваться сервисом доверительного хранения. Также рекомендуем общаться с продавцом исключительно через форму на сайте LocalBitcoins, минуя текстовые и электронные сообщения.
Изложите продавцу свои требования максимально подробно и выделите любые нюансы. LocalBitcoins позволяет клиентам устанавливать цены и способы оплаты, а также способ поставки биткоинов, поэтому важно заранее обсудить все наиболее важные аспекты сделки.
В случае возникновения проблем или сомнений в отношении продавца свяжитесь со службой поддержки или воспользуйтесь форумом. Сайт довольно прост в использовании, однако могут возникнуть неожиданные проблемы, поэтому не забывайте о поддержке.
История основания и статус ЛокалБиткоинс
Биржа LocalBitcoins – это финская криптовалютная биржа, которая была зарегистрирована в 2012 году. Штаб квартира LocalBitcoins находится в Финляндии в городе Хельсинки.
Официальный сайт – localbitcoins.com, который доступен на 7 языках, среди которых есть русский. Главным отличием биржи localbitcoins является то, что сделки купли продажи осуществляются между людьми, без вмешательства биржи. Данная процедура позволяет сделать процесс купли продажи намного быстрее и прозрачнее.
Основная информация о бирже LocalBitcoins.com:
Официальный сайт биржи: LocalBitcoins.com, зеркало LocalBitcoins.net.
Список криптовалют: Биржа торгует только биткоинами.
Особенности сервиса Localbitcoins
Этот сервис весьма прост в обращении. Достаточно зарегистрироваться и подтвердить номер Вашего телефона. Дополнительно, безопасность обеспечивается двухфакторной аутентификацией на ввод, вывод и внутренние операции. Для активации такой защиты, нужно будет установить на телефон специальное приложение Google Authenticator. После установки и активации приложения для LocalBitcoins, в нем будут периодически появляться одноразовые шестизначные коды, запрашиваемые сервисом при работе в нем.
Интерфейс LocalBitcoins хорошо руссифицирован и интуитивно удобен. Две основных закладки — БЫСТРАЯ ПОКУПКА и БЫСТРАЯ ПРОДАЖА не дадут вам заблудиться на сайте. Основной валютой сервиса является биткоин. Относительно него осуществляется обмен на другие валюты, которых на выбор предлагается аж 75.
Также есть возможность выбора страны контрагента и удобной для вас платежной системы из 30 возможных. Для удобства пользователей сервис предлагает два способа проведения сделки обмена ОНЛАЙН и ОФФЛАЙН.
Если вы не очень доверяете интернету, сервис предоставит вам геоданные контрагентов в зон вашей локации и вы увидите на карте места расположения потенциальных продавцов или покупателей для проведения сделки в живую с физическим контактом. Если с интернетом проблем нет — любая сделка доступна вам в онлайн режиме.
Покупки
Покупки можно осуществлять сразу после регистрации, надо лишь выбрать подходящее торговое предложение и отправить продавцу текст с запросом ваших потребностей. Купленные монеты биткоин поступят на ваш внутренний счет в сервисе.
При выборе контрагента для обмена, вам будет предложен расширенный фильтр, по странам, валютам, и платежным системам, но при необходимости можно просматривать и все предложения сразу.
Продажи
Продажи становятся доступны после размещения на сервисе небольшого депозита в размере 0,002 BTC и несложной верификации вашей личности. Это требуется для обеспечения безопасности сделок и повышения уровня доверия между контрагентами.
Также при проведении сделки система LocalBitcoins блокирует средства продавца до завершения, что, в свою очередь, гарантирует покупателю комфортное проведение обмена.
Достоинства и недостатки LocalBitcoins
Среди главных преимуществ биржи LocalBitcoins, является ее опыт работы на рынке, напомним ЛокалБиткоинс работает с 2012 года. Неоспоримым плюсом в работе с локалбиткоинс является то, что они принимают большое количество вариантов для оплаты, об этом мы писали выше. Ну и конечно объемы торгов — биржей пользуется огромное количество пользователей по всему миру.
Одним из главных преимуществ является возможность выбора наиболее удобного способа оплаты для заключения сделки. Благодаря LocalBitcoins покупать и продавать криптовалюту следующими способами:
Moneygram;
Банковский перевод внутри страны;
OKpay;
QIWI;
WebMoney;
Яндекс.Деньги;
Western Union;
Advcash;
Ethereum;
наличные (при личной встрече);
CashU;
PayPal и так далее.
Также пользователям доступны классические онлайн переводы через конкретный банк в качестве которых выступают практически все крупные банки России:
Сбербанк;
Тинькоф;
Альфа-банк;
ВТБ24;
Авангард;
Райффайзен;
Открытие.
Кроме этого для удобства пользователей есть множество других способ, таки как:
Внесение наличных на счет
Код подарочной карты
Международный перевод (SWIFT)
Наличные в банкомате
Недостатки:
Поддержка только биткоина. На этой платформе торгуют только BTC. Поэтому если вы хотите купить другую монету, то вам придется искать другой сервис в интернете. Предлагаем воспользоваться нашим рейтингом бирж криптовалют.
Риски. На бирже могут работать мошенники, поэтому нужно внимательно выбирать трейдеров. В противном случае можно остаться без заветных биткоинов.
Недоверие к новичкам. Система работает по принципу доверия. Больше преимущества при работе с площадкой будет у тех пользователей, которые ужа давно работают на LocalBitcoins. Новичкам же придется ограничиться сделками на небольшую сумму, чтобы сначала заработать хорошую репутацию.
Рекомендации по работе с сервисом
Начиная свои операции в сервисе LocalBitcoins не пренебрегайте следующими простыми советами:
После регистрации, выполните рекомендации системы по настройке безопасности
Фильтруйте предложения покупки продажи по региону
Тщательно изучите репутацию продавца и отзывы
Посмотрите на количество проведенных продавцом сделок
Посмотрите раскрыл ли он информацию о своей личности
Выбирайте платежную систему удобную для вас
Не торопитесь с выбором и вы обязательно найдете лучшие предложения по курсу и условиям сделки. А высокие показатели вашего контрагента обеспечат вам успешную и комфортную транзакцию в сети биткоин.
При покупке или продаже Bitcoin на площадке LocalBitcoins лучше все отдавать предпочтение трейдерам, которые отмечены «зеленым пальцем». Это значит что они:
совершили большое количество сделок;
имеют большое количество положительных отзывов;
используют популярные способы оплаты;
давно работают на сайте LocalBitcoins;
имеют большие объемы торгов.
Доверие и безопасность в LocalBitcoins
Для повышения уровня доверия к пользователям сервиса и ограждения добропорядочных граждан от мошенников, в системе LocalBitcoins предусмотрены различные рейтинги контрагентов. Эти индикаторы безопасности отображают например, насколько участник обмена раскрыл данные о своей личности, каково количество проведенных им сделок, сколько у него позитивных и негативных отзывов.
Наряду с рейтингами пользователей, система расширенных режимов двухфакторной авторизации и блокировок депозитов при сделках, позволяет сервису LocalBitcoins вести многолетнюю бесконфликтную работу на валютно обменном рынке. А наличие в качестве базовой — криптовалюты биткоин, делает сервис поистине уникальным и чрезвычайно удобным.
Личные сообщения и практические советы по сделкам
На сайте LocalBitcoins изначально нет ЛС в классической реализации, только сообщения в поле чата в окне сделки, и вы сможете пообщаться с одним из пользователей только после того, как откроете с ним первую сделку.
Для того, чтобы открывать сделки, нужно иметь некий минимум средств на балансе (10 USD будет достаточно, чтобы успешно найти как минимум пару контрагентов, согласных на обмен столь мелкой суммы).
Можно переключить на вкладку QUICK SELL (Быстрая продажа), нажать на SEARCH и получить соотв. результаты. Обратите внимание, как у одних и тех же продавцов различается комиссия на покупку и продажу монет.
или
Если вы хотите создать своё объявление о покупке или продаже, то потребуется уже 0.1 BTC на балансе, и 0.2 BTC нужно хранить на сайте если хотите, чтобы ваше объявление светилось в ТОП-е на главной (менее 0.2 BTC — и не светится, но активно и имеет на себя ссылку, которую можно размещать на тех же форумах…).
Эти деньги не списываются с вашего счёта, они принадлежат вам и просто должны находится там постоянно (если вы хотите раскрутить свою торговую точку на Локале, без объявления на главной у вас это вряд ли получится).
Выбрав валюту, вы можете установить процент на сделки. Устанавливать можно как в плюс так и в минус (доплачиваете своим клиентам), процент будет касаться только сделок по данному объявлению.
В поле «Terms of trade» укажите условия сделки, для связи также запишите туда свой Telegram если у вас достаточная для «прямых обменов» репутация. Прямой обмен не страхуется эскроу системой Локала. Свои первые сделки лучше проводите исключительно в рамках LB.
Стоит ознакомиться с опциями безопасности: можно сделать так, чтобы ваши объявления видели только люди с подтверждёнными документами, номером телефона а также только те, кто находится в «Доверенных» (TRUSTED).
Жмите «Publish advertisement», если всё готово.
Нажав на кнопку «forums» вы попадаете на внутреннюю доску сайта, где люди создают тикеты с комментариями и свободно общаются на разные темы. Вот например человек жалуется, что отправил деньги на Blockchain.info и не получил их.
В то же время «саппорт» отморозился, спихнув отсутствие входящей транзакции (видной в других блок-эксплорерах) на отправителя (то есть на LB). Ясное дело, что проблема кроется скорее в самом биткоин кошельке blockchain.info, нежели на сайте Localbitcoins, но люди почему-то не склонны учиться на ошибках других и продолжают заливать на blockchain.info свои деньги.
Надеемся, что вы уже придумали, куда вывести биткоины с этого сервиса, если используете его для хранения основных средств в криптовалюте? Например — в кошелек Electrum или Jaxx.
Если вы хотите изменить ваш профиль или посмотреть текущие настройки безопасности, смело используйте меню вверху справа.
По нажатии на Dashboard вы сможете быстро оказаться на экране ваших текущих объявлений (перманентных онлайн-сделок) а также просмотреть историю предыдущих сделок и установить письменный контакт с любым из ваших прошлых коллег по обмену, если это необходимо.
Не всегда у вас есть возможность проводить обмен прямо на сайте, поэтому имеет смысл взять контакт у одного из давно проверенных вами трейдеров и обмениваться напрямую в Telegram, минуя 1% комиссию LB (за поддержку изначальной идеологии Биткойна это — небольшая цена).
Как правило, сделки совершаются в окошке с мини чатом и кнопкой «Release bitcoins» или «Mark payment complete». Соответственно, если вы продаёте биткойн, то отправляете его не сразу трейдеру, а сначала в холодный депозит.
Когда вам перевели деньги на карту банка (или когда вы встретились с человеком в реальной жизни и он передал вам купюры) вы нажимаете «Release bitcoins» и биткойны, тогда уже окончательно, отправляются вашему контрагенту. Если же вы купили у кого-либо биткойны, то после совершения вами фиатного платежа нажмите «Mark payment complete» и ждите, пока сделка завершится.
В настройках профиля вам доступны такие возможности:
Рекомендуем вам выставить следующие параметры:
А также, сразу настройте безопасность, например включите двухфакторную аутентификацию с помощью мобильного приложения или заранее сгенерированных на сайте паролей.
Первая опция весьма удобна и для большинства пользователей её хватит.
Вторая опция более интересная — вам даётся заранее целая куча паролей, каждый раз придется при входе на сайт вводить новый, и бумажку с этими паролями (или файл с ними) вы не имеете права потерять.
Первая опция — ваш вариант. Используйте вторую только если вы не доверяете «двухфакторке» из-за вашего оператора.
При выборе второго варианта нужно кликнуть сначала на «Click here to reveal», и ваш браузер в новом маленьком окошке откроет секретный список кодов аутентификации. Его нужно распечатать на принтере или переписать вручную на бумагу, смотрите не ошибитесь!
Затем, когда все коды сохранены, жмёте на «Proceed to activation».
Отзывы о криптовалютной бирже-сервисе LocalBitcoins
Русский интерфейс, а также работа со всеми действующими формами оплаты сделали биржу ЛокалБиткоинс довольно популярной в России и странах СНГ. В отзывах часто проскакивает, что это биржа с самым дружественным интерфейсом.
Также иногда проскакивают просьбы помочь советом как вернуть деньги, потерянные в результате мошеннических операций. В этом и есть отрицательная сторона децентрализации биржи.
Вы уже торговали криптовалютой на бирже LocalBitcoins? Оставьте свой отзыв, он поможет остальным читателям при выборе платформы для торговли Bitcoin.
Заключение
LocalBitcoins — одна из самых доступных платформ для покупки биткоинов. Сайт связывает покупателей и продавцов по всему миру, позволяет оплачивать биткоины несколькими способами и не ограничивает объемы сделок.
Тем не менее пользователи должны помнить о том, что на сайте встречаются нечестные продавцы, а надежные поставщики могут накладывать определенные ограничения на сделки. Например, для крупных сделок они могут потребовать документ, подтверждающий личность; отказать покупателю в случае, если тот решит оплатить с помощью сервиса, поддерживающего возврат платежей, такого как PayPal.
Цены также могут быть немного выше, поскольку поставщики вынуждены компенсировать комиссию площадки.
LocalBitcoins — проверенный и надежный способ покупки биткоинов, востребованный в криптовалютном сообществе. Сервис старается поддерживать децентрализованные принципы криптовалют и занимает важную нишу в экосистеме цифровых валют. Сайт прекрасно подходит как для новичков, так и для опытных трейдеров.
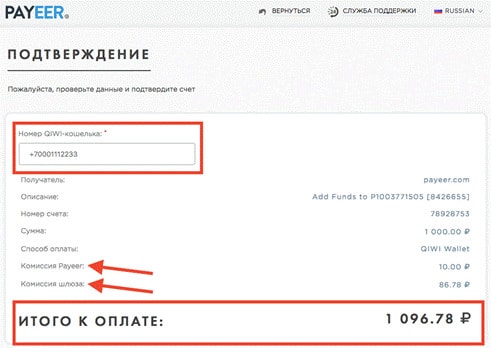
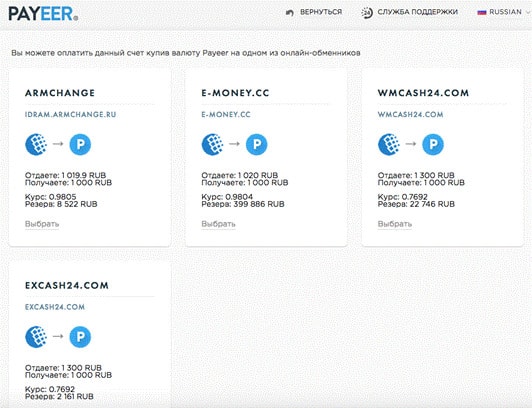
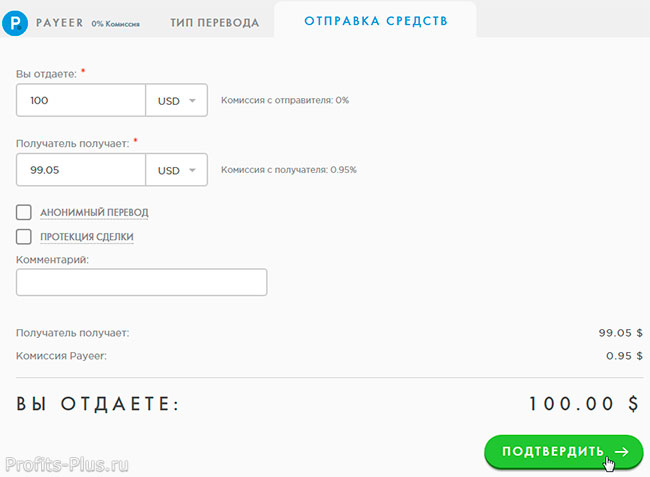
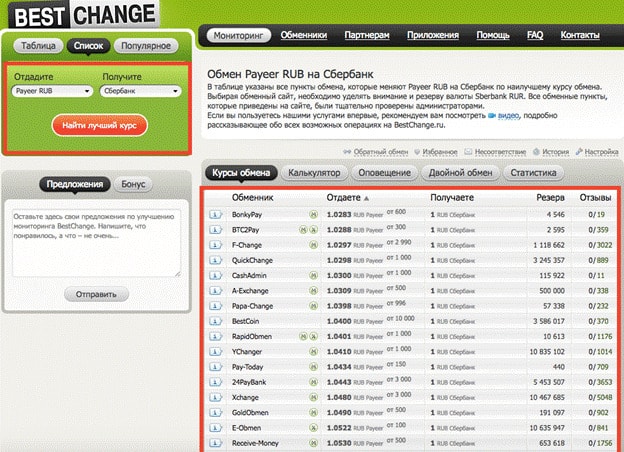
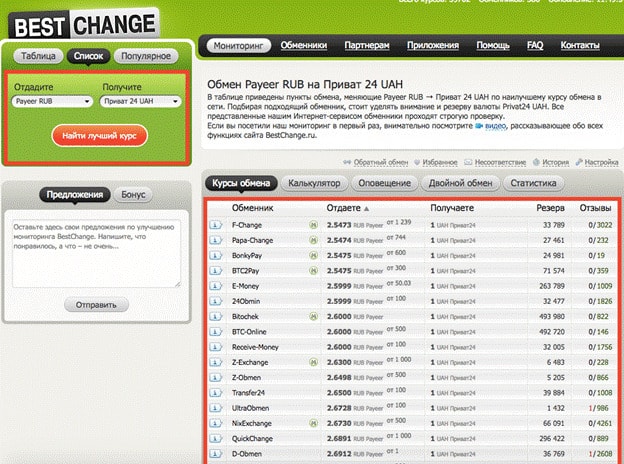
Payeer — онлайн-платформа, с помощью которой пользователи могут отправлять и получать деньги. Услуги сервиса доступны пользователям в более чем 200 странах. Расчеты осуществляются в 3-х фиатных валютах: доллары США, евро, рубли и криптовалютах: Bitcoin, Ethereum, Bitcoin Cash, Litecoin, Dash, Ripple и стейблкоине от компании Tether (USDT).
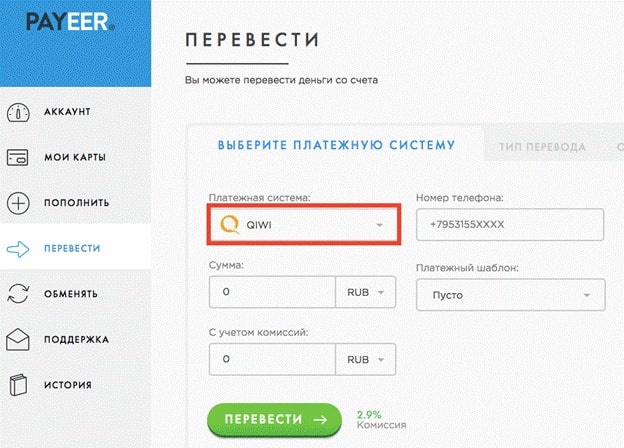
Одной из сильных сторон сайта является гибкость системы в области взаимодействия с другими платежными сервисами. Клиенты Пайер могут осуществлять переводы на счета Qiwi, Яндекс.Деньги и AdvCash. Отметим, что комиссии по данным направлениям не из низких.
Payeer — одна из любимых платежных систем многих пользователей, которые предпочитают онлайн-заработок (постинг на форумах, участие в хайпах, играх и т.д.).
Особо привлекательна 6-уровневая реферальная программа с возможностью получения пассивного заработка.
Payeer предлагает следующие инструменты для защиты аккаунта: «IP-безопасность», «SMS-уведомление» и «Восстановление пароля», однако по степени надежности, она уступает другим платежным системам, например, Skrill.
Система продолжает развиваться, о чем свидетельствуют усилия компании в направлении соответствия необходимым нормативным требованиям. Так, в 2019 году система получила 3 лицензии для ведения законной деятельности:
Официальный сайт Payeer — общая информация
Пайер ( официальный сайт ) — это электронная платежная система, с помощью которой можно осуществлять различные денежные операции в интернете.
Свою деятельность начал относительно недавно — в 2012 году. Но благодаря своей простоте в регистрации, использовании, а также полной анонимности, он быстро завоевал популярность и прочно закрепился на позициях лидера наряду с остальными популярными ЭПС, такими как Perfect Money и Advanced Cash .
Официально зарегистрирована платежная система в Тбилиси (Грузия). Международную лицензию PSP на осуществление финансовой деятельности выдал Национальный банк Грузии. Также компанией на сегодняшний день открыты офисы в Москве (Россия) и Абердине (Великобритания). Сайт переведен на 6 языков, в том числе русский и английский. Поддерживает 3 основных валюты: USD, EUR, RUB. А также несколько популярных криптовалют, в том числе Bitcoin и Ethereum.
Короткий видеоролик рассказывающий об особенностях электронного кошелька.
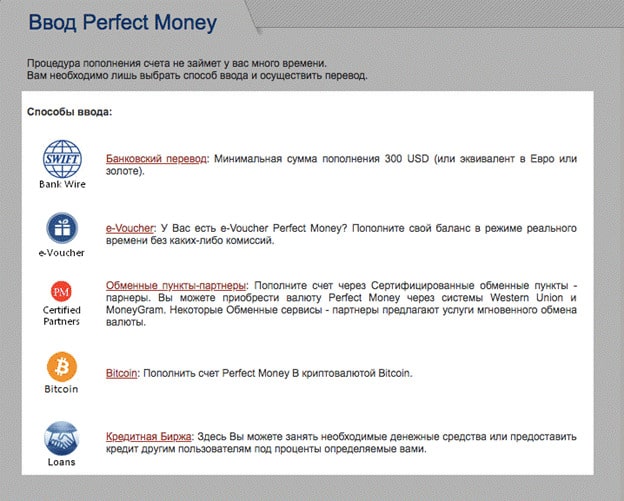
Часто система используется при работе с высокодоходными (хайп) проектами . Ведь пополнить/вывести с него деньги очень легко. Осуществить это возможно практически любым доступным и удобным для пользователя способом:
Банковская карта VISA/MasterCard;
SWIFT переводы;
Электронные деньги (Яндекс.Деньги, Qiwi, Perfect Money, Advanced Cash и пр.);
Криптовалюта;
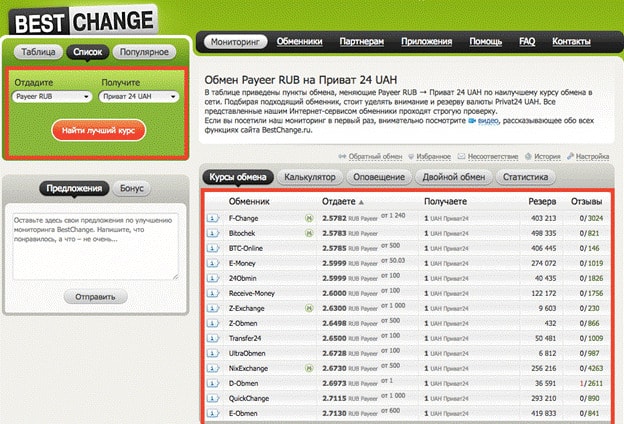
Наличные деньги на кассах в салонах Евросеть и через терминалы оплаты в салонах Связной;
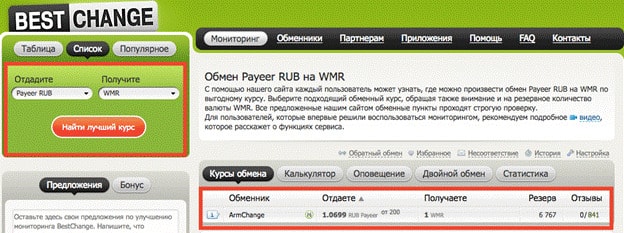
Обменные сервисы(BestChange или Курс Эксперт ).
При этом пользоваться платежной системой можно совершенно анонимно, не проходя верификацию, при соблюдении лимитов.
Описание платежного сервиса Payeer
Данный платежный сервис начал функционировать с 2012 года. На сегодняшний день он является одной из наиболее востребованных и надежных платформ для проведения множества финансовых операций. Сейчас здесь зарегистрировано более 11 миллионов пользователей с разных уголков планеты. Сервис доступен для регистрации жителям более 200 стран мира.
Интерфейс сайта разработан на нескольких языках, среди которых русский, французский, испанский, английский и китайский. Это делает пользование данным сервисом максимально удобным для широчайшего круга пользователей. Главный офис данной компании территориально расположен в Грузии, в городе Тбилиси. Однако во многих других городах (в частности, в Москве) есть официальные представительства.
Среди основных возможностей, которые получают зарегистрированные на этом сайте пользователи, стоит отметить следующие:
отправка платежей другим пользователям и их принятие;
обмен валют без необходимости использовать сторонние обменники;
перевод средств пользователям других платежных систем с минимальной комиссией;
оплата различных услуг (коммунальных счетов, телефонии, интернета и пр.);
подключение кошелька к своему сайту для получения платежей от посетителей или клиентов и пр.
В целом, данный ресурс успел хорошо себя зарекомендовать и войти в ТОП самых популярных платежных систем.
Почему платежная система Payeer лучше остальных?
Давайте разберем преимущества платежной системы Payeer, чтобы понять, чем она лучше остальных платежных систем интернета. И для начала поговорим о том, какие услуги предоставляются всем пользователям зарегистрировавшимся в Payeer:
Можно осуществлять денежные переводы по всему миру. Перевести деньги можно даже пользователям, которые не зарегистрированы в системе! Перевод денег в Payeer осуществляется мгновенно.
Вы сможете оплачивать коммунальные услуги, интернет, пополнять счет мобильного и многое другое не выходя из дома.
С помощью платежной системы Payeer можно осуществлять покупки в большинстве интернет-магазинов.
В платежной системе Payeer можно проводить обмен различных видов валют по выгодным курсам.
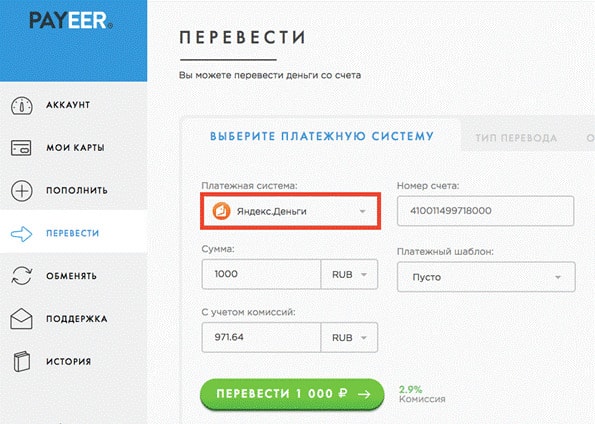
Есть масса способов, чтобы обналичить деньги с кошельков Payeer. Можно перевести деньги в другую платежную (к примеру перевести деньги с Payeer на ндекс ДеньгиЯ ). Также можно перевести средства с кошельков Payeer на свой счет в банке.
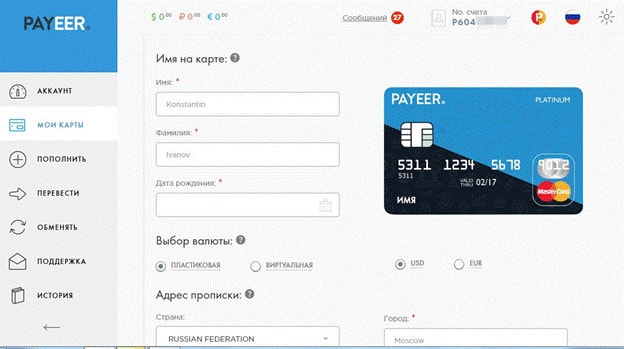
Платежная система предоставляет возможность получить карту Payeer MasterCard. С ее помощью Вы сможете снимать деньги во всех банкоматах мира и осуществлять покупки без комиссии!
Для владельцев сайтов предоставляется возможность подключить Payeer Merchant и осуществлять прием платежей. Предоставляет более 60 способов приема оплаты на сайте.
Чтобы понять насколько хороша данная платежная система, давайте рассмотрим основные ее функции подробнее.
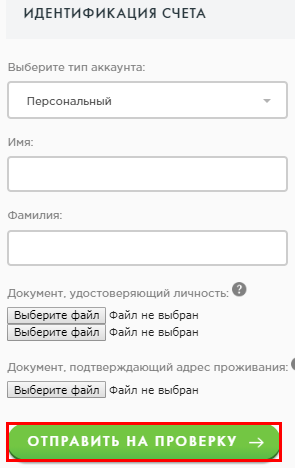
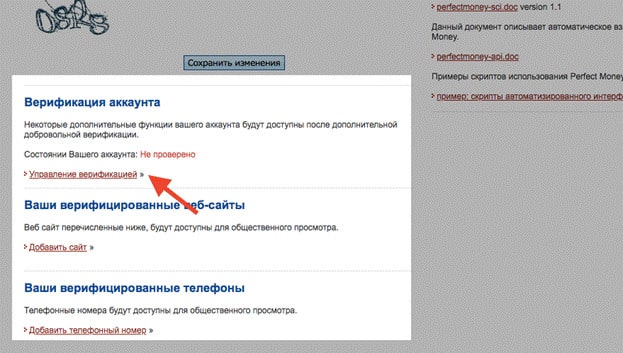
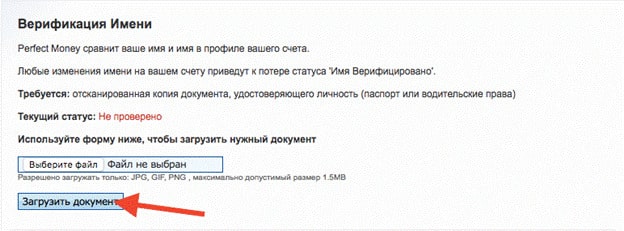
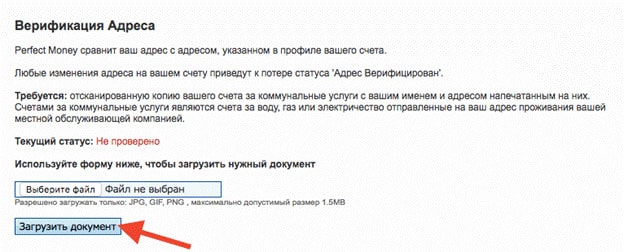
Как пройти верификацию
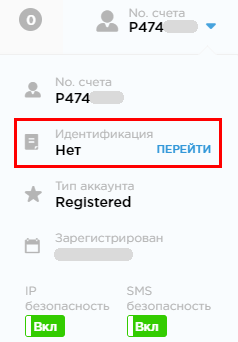
После регистрации необходимо пройти процедуру верификации учетной записи с проверкой ваших документов и прописки. Для начала верификации необходимо навести на номер вашего счета Payeer в верхнем правом углу экрана (он выглядит примерно так:P3718954) и кликнуть на иконку “Перейти”, которая расположена в строке “Идентификация ”.
Далее необходимо ввести ваше имя и фамилию, а также загрузить любые документы, подтверждающие вашу личность и прописку. После процедуры верификации подтверждение личности займет около 24 часов
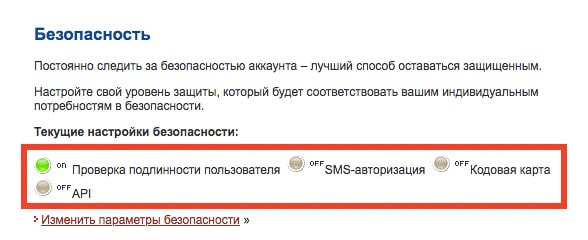
Настройки безопасности для пользователей
Еще одна процедура, которую нужно выполнить сразу после того, как вы создадите кошелек в системе Payeer, – это настройка безопасности. Эта процедура обязательна для всех, кто планирует получать или отправлять через свой счет большие суммы денег. Это дополнительная защита вашего аккаунта и ваших денег, которой не стоит пренебрегать.
Для этого нажмите на значок шестеренки, расположенный в правом верхнем углу в вашем личном кабинете. Затем кликните на «Настройки». В появившемся окне выберите вкладку «Безопасность».
Далее система предложит вам ввести номер своего мобильного телефона и привязать его к своему аккаунту на сайте Пайер. Это значит, что вы сможете получать код подтверждения по СМС, а не по почте, что является более надежным.
Еще один способ получения проверочных кодов – использование приложения Телеграм. В специально отведенное поле введите свой ник, который вы указали в данном мессенджере.
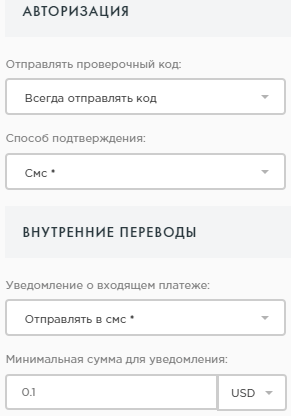
Далее вы можете выбрать, в каких случаях сервис Payeer может отправлять вам проверочный код. Рекомендуется выбрать пункт «Отправлять всегда». Также выберите оптимальный способ получения кода. Наименее надежным является емейл, поскольку почтовые ящики также часто взламывают. Самым надежным является СМС или через приложение Телеграм.
В поле, расположенном ниже, вы сможете указать, куда должны приходить уведомления о входящих платежах, а также установить минимальную сумму, о зачислении которой стоит вас информировать.
Также вы сможете выбрать способ отправки кода в случае восстановления пароля. Рекомендуется выбрать вариант «по СМС», однако стоит учитывать, что стоимость отправки одного сообщения обойдется вам в 0,05 доллара.
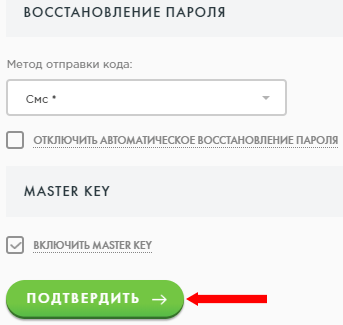
Последним пунктом является включение или отключение Master Key (специального кода, который вы будете вводить при подтверждении каждого платежа). Чтобы исключить риск мошеннических операций, рекомендуется включить данную опцию. Этот код вы придумаете сами после того, как нажмете на кнопку «Подтвердить».
Как видите, настройка безопасности на сервисе Payeer достаточно простая и отнимет у вас буквально несколько минут. Займитесь этим как можно быстрее, чтобы обезопасить свой счет и исключить всякие риски.
Инструкция по регистрации на сайте Payeer
Зарегистрироваться на данном ресурсе может любой желающий. Для этого достаточно перейти на официальный сайт сервиса и кликнуть на кнопку «Создать аккаунт», расположенную в центре экрана.
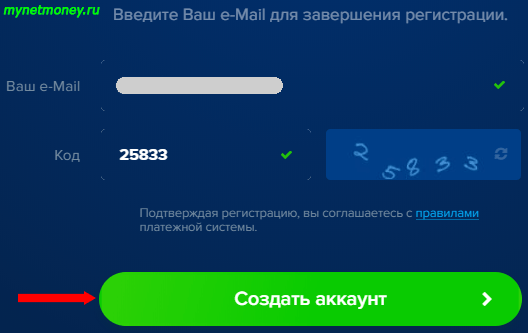
Перед вами появится небольшая форма, в которую нужно ввести свою электронную почту. Указывайте тот почтовый ящик, к которому у вас есть постоянный доступ. Ниже будет поле для ввода несложной капчи. Еще ниже вы увидите ссылку, перейдя по которой, можно будет ознакомиться с основными правилами данного ресурса. Рекомендую прочитать все условия, прежде чем регистрироваться. Выполнив эти действия, жмите на «Создать аккаунт».
На указанный вами емейл система отправит код для подтверждения процедуры регистрации. Перейдите в свою почту, откройте письмо от сервиса Payeer, скопируйте код. Затем вернитесь на сайт, вставьте в поле код и кликните на кнопку «Создать аккаунт».
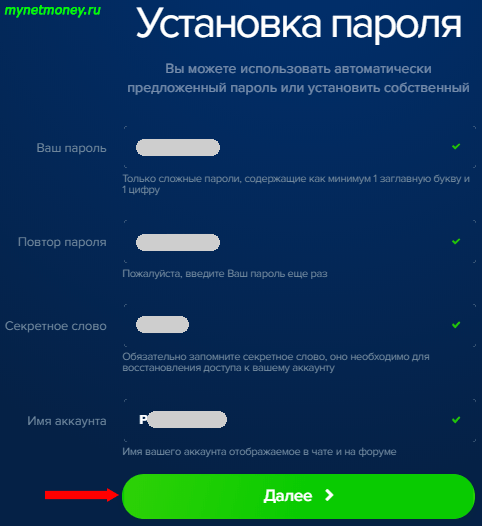
После этого вы увидите окно, в котором уже автоматически сгенерированы пароль для входа в систему, номер кошелька, а также секретное слово, необходимое для восстановления доступа к аккаунту.
Для удобства стоит сразу сменить пароль на тот, который вам будет проще запомнить. Учитывайте, что пароль должен состоять как минимум из одной цифры и одной большой буквы.
Секретное слово вам обязательно нужно записать куда-то. В случае, если вы забудете свой пароль и потеряете доступ к почтовому ящику, вы сможете войти в свой аккаунт, введя это секретное слово. Поменяв пароль и записав другие данные, жмите на кнопку «Далее».
Вы создали аккаунт! На вашу почту поступит письмо с уведомлением о том, что регистрация завершена.
Вас перенаправит в ваш личный кабинет, а на экране появится окно с рекомендацией записать пароль, секретное слово и номер кошелька.
Первым делом после прохождения регистрации стоит пройти идентификацию, чтобы иметь возможность пользоваться всем функционалом сайта. Кроме того, данная процедура позволит вам обезопасить себя, а администрации системы Payeer – исключить риск проведения мошеннических операций.
Для прохождения идентификации найдите номер своего счета в правом верхнем углу сайта и наведите на него курсором мышки.
Напротив строки «Идентификация» вы увидите кнопку «Перейти». Нажмите на нее. Затем перед вами откроется окно, в котором потребуется:
выбрать тип аккаунта (персональный или бизнес);
ввести свое реальное имя и фамилию;
загрузить фотографии первых страниц паспорта, а также страницы с пропиской;
нажать на кнопку «Отправить на проверку».
Когда администрация проверит ваши данные, вы получите уведомление на свой почтовый ящик о том, что успешно прошли идентификацию. После этого вы получите возможность получать и отправлять деньги, используя для этого SWIFT-реквизиты, а также увеличите лимиты на снятие средств и на пополнение счета. Поэтому рекомендуется сразу идентифицировать свою личность, если вы планируете пользоваться данным сервисом и не желаете испытывать каких-либо трудностей.
Какие кошельки есть в Payeer?
В платежной системе Payeer присутствует 3 типа кошельков:
Для хранения и проведения денежных операций в рублях РФ.
Для хранения и проведения денежных операций в долларах США.
Для хранения и проведения денежных операций в евро.
Payeer кошелек: виды счетов
Кошелек дает возможность хранить свои денежные средства на разных счетах, в том числе и криптовалютных. Давайте перечислим счета, которые доступны в данный момент:
USD (доллары);
EUR (евро);
RUB (рубли);
Bitcoin (BTC);
Ethereum (ETH);
Bitcoin Cash (BCH);
Litecoin (LTC);
Dash.
Как видите, на Payeer кошельке можно хранить также и довольно большое количество криптовалюты. Причем хранение ее осуществляется без конвертации в доллары. Т.е. Пэйер одновременно и фиатный кошелек и мультикриптовалютный. Сравним его с тем же AdvCash, который не позволяет хранить на счетах криптовалюту. Таким образом, пользуясь ЭПС Пэйер, можно не утруждать себя поиском хороших кошельков для каждой имеющейся у Вас криптовалюты. Тут можно хранить самые популярные монеты, и этот список постоянно растет.
Как можно использовать систему?
Кошелек Payeer можно использовать как универсальную платежную систему для принятия и отправки платежей, хранения своих средств и т.д. Давайте более подробно разберемся, какие возможность дает кошелек Пэйер:
пополнение счета / вывод денежных средств + хранение;
использование кошелька для хранения криптовалюты ;
прием и совершение платежей (с помощью ЭПС можно расплачиваться за покупки в интернет-магазинах, оплачивать коммуналку и совершать другие платежи);
совершение переводов денежных средств в любую точку земного шара (международных);
совершение внутренних переводов между пользователями системы;
использование для получения заработка с буксов и других сайтов для заработка, а также для инвестиций в хайпы и другие инвестиционные проекты.
Какие лимиты и ограничения есть в системе?
Ограничений или лимитов на количество денежных средств на кошельках в Payeer нет. И не имеет значения, верифицирован у вас счет или нет. Вы можете хранить любое количество денег на любом кошельке.
Также в Payeer нет лимитов на перевод средств внутри платежной системы. Можно перевести за один раз любую доступную сумму для кошелька. К тому же при переводе внутри системы отсутствует комиссия.
При выводе денег из Payeer некоторыми способами есть ограничения на минимальную и максимальную сумму. Подробнее об этом Вы узнаете дальше в статье.
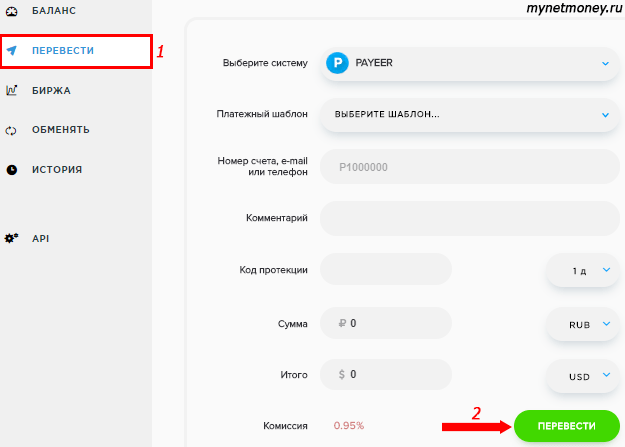
Проведение основных денежных операций
Предлагаю вам изучить особенности пополнения кошелька в данной платежной системе, а также перевода и вывода средств. Здесь у вас будет три фиатных счета – в рублях, долларах и евро. Все остальные валюты вы можете обменять через встроенный обменник.
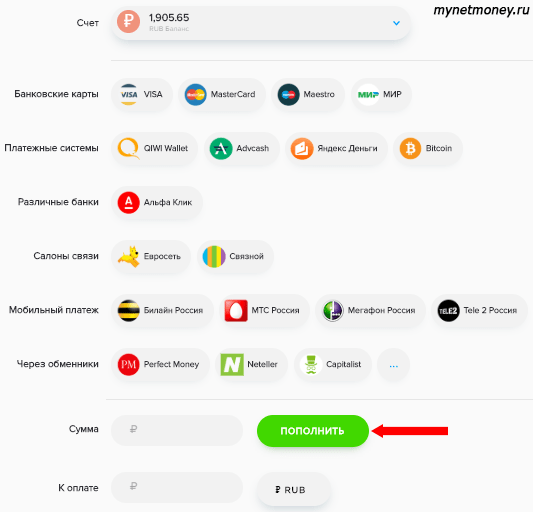
Так, чтобы пополнить свой счет, вам нужно будет в левом меню сайта найти кнопку «Баланс» и кликнуть по ней. Перед вами откроется перечень валют. Вам достаточно выбрать подходящий вариант и нажать на кнопку «Пополнить». Если вы выбрали рубли, то увидите такие способы пополнения:
с банковской карты (Visa, MasterCard, Maestro, Мир);
используя другие платежные системы (такие как Яндекс Деньги, Киви, AdvCash, Bitcoin);
через салоны связи «Евросеть» и «Связной»;
со счета мобильного телефона таких операторов: Билайн, МТС, Мегафон, Теле2;
через различные обменники, такие как Перфект Мани, Капиталист и пр.
Еще ниже будет расположено поле для ввода требуемой суммы. Указав ее, жмите на кнопку «Пополнить» и следуйте дальнейшим инструкциям.
Для других валют способы пополнения могут немного отличаться.
Чтобы отправить деньги на любой счет в платежной системе Payeer или какой-либо другой, нажмите на кнопку «Перевести», расположенную в левом меню сайта. Перед вами откроется небольшая форма, где вам нужно будет:
выбрать систему, на которую вы планируете осуществить перевод (это могут быть платежные системы, банковские карты, криптовалюта, номера мобильных телефонов и международные переводы);
выбрать платежный шаблон (эта опция будет доступна вам только после совершения первой денежной операции; все платежные данные, которые вы вводите, будут сохраняться, чтобы в следующий раз вы могли просто выбрать их, а не указывать заново);
указать номер счета;
ввести сумму перевода и выбрать валюту.
Ниже под суммой перевода будет указано, сколько денег будет снято с вашего счета с учетом комиссий. После этого перепроверьте указанные данные и жмите на «Перевести».
Комиссия за вывод рассчитывается в зависимости от того, какой способ перевода вы выбрали. Так, например, комиссия за отправку средств на другой кошелек в системе Пайер составляет 0,95% от суммы. А за перевод на Яндекс Деньги с вас дополнительно снимут 2,9% от суммы. Кроме того, перевод на другие кошельки данной платежной системы производится мгновенно, а вывод на другие сервисы может занимать от 1 рабочего дня.
Перейдя в раздел «Биржа», вы сможете посмотреть основные изменения на валютном рынке, а также купить или продать какую-то валюту.
В разделе «Обменять» вы сможете мгновенно провести обмен средств между своими фиатными и криптовалютными счетами. Текущий курс вы увидите там же.
Payeer — как пополнить кошелек
Способов пополнить Payeer, как писал уже выше, существует большое разнообразие:
Наличными (USD, RUB, EUR) c минимальной комиссией (до 1%) через официальные обменные пункты;
ЭПС (AdvCash, Perfect Money, Qiwi, Яндекс.Деньги и др.);
Банковские карты VISA/MasterCard/Maestro/Мир;
SWIFT переводы;
Через обменники;
Мобильный платеж (Теле2, МТС, Билайн, Мегафон);
Наличными в салонах Связной и Евросеть.
С актуальным перечнем можно ознакомиться на официальном сайте платежной системы Пайер.
В Личном кабинете, в разделе “Баланс“, представлены все кошельки (фиатные и криптовалютные). На каждом из них указанна сумма средств на текущий момент и немного ниже есть две кнопки “Пополнить” и “Вывести”. Сейчас остановимся более подробно на пункте “Пополнить“. Далее выбираем счет для зачисления денег, способ оплаты, указываем сумму и нужную валюту пополнения. И сразу же рядом система указывает сумму к оплате, с учетом комиссии за осуществляемую операцию. Всегда обращайте на это внимание, так как размер комиссии может значительно отличаться. Она зависит от выбранного способа пополнения кошелька.
Можете покликать на способы оплаты и посмотреть как от этого будет изменяться сумма к оплате, таким образом, выбрав для себя более удобный и выгодный.
Затем жмете на зеленую кнопку “Пополнить” и система перенаправит Вас для осуществления платежа на новую страничку. Далее следуете инструкциям, все предельно просто.
Как пополнить Payeer через Qiwi?
Чтобы пополнить пайер через киви, заходим в личный кабинет Payeer, вкладка Пополнить → выбираем валютный счет → указываем сумму депозита → жмем Пополнить. Среди предлагаемых методов оплаты выбираем платежную систему Qiwi.
Пополнение Payeer через Qiwi
Перейти в Payeer
Выбрав QIWI WALLET, на странице подтверждения указываем номер QIWI-кошелька, с которого будут сняты средства. Итоговая сумма перевода отображается с учетом комиссии Payeer и комиссии шлюза. Жмем Подтвердить.
Как пополнить Payeer через Webmoney?
Чтобы пополнить payeer кошелек через Webmoney, заходим в личный кабинет Payeer, вкладка Пополнить → выбираем валютный счет → указываем сумму депозита → жмем Пополнить. Среди предлагаемых методов оплаты выбираем Webmoney.
Для перевода денег с вебмани на пайер система предлагает на выбор несколько онлайн-обменников. Выбираете наиболее выгодный курс и на странице обменника вводите данные для перевода с Paymer WMR на Payeer.
Как перевести деньги на Payeer кошелек?
В платежной системе Payeer нет каких-либо ограничений и лимитов на внутренние операции и переводы. Внутри системы можно осуществлять перевод в размере от 2 центов, а максимальная сумма не ограничена. Все переводы осуществляются мгновенно.
Чтобы перевести деньги на кошелек Payeer другому пользователю системы зайдите в раздел в личном кабинете «Перевести». Затем выберите из списка платежную систему Payeer и нажмите на кнопку «Перевод».
Далее выберите один из 3 вариантов указания получателя денег: указать его E-Mail, мобильный номер или номер счета. Затем нажмите на кнопку «Продолжить».
Далее в открывшемся окне следует указать сумму и валюту перевода на другой кошелек Payeer. Затем снова нажать на кнопку «Продолжить».
Как видите, процедура перевода средств внутри платежной системы Payeer очень проста. А что делать, если получатель перевода не зарегистрирован в системе? Конечно, проще всего будет ему зарегистрироваться в Payeer, но а если такой возможности нет? На этот случай данная платежная система предоставляет выход.
Payeer предоставляет возможность осуществить перевод даже не зарегистрированным пользователям! После осуществления перевода платежная система автоматически создает аккаунт и высылает все данные (пароль, секретное слово и так далее) на указанный E-Mail или телефон отправителем.
После этого получателю денег достаточно будет зайти в созданный счет Payeer и вывести деньги с кошельков, к примеру на счет в банке или карту.
Как обменять с webmoney на Payeer?
Выгодный обмен webmoney на payeer совершаем с помощью Bestchange .
Для этого копируем свой номер кошелька на пайер, заходим на сайт https://www.bestchange.ru/ и в поле Отдадите выбираем Webmoney, а в Получите указываем Payeer USD.
Выбираем обменник с лучшим курсом, обращаем внимание на резерв нужной валюты и отзывы, переходим на сайт обменного пункта и завершаем транзакцию.
Обмен Webmoney на Payeer USD
Как обменять Биткоин на Payeer?
Чтобы обменять payeer на btc также пользуемся услугами бесплатного мониторинга обменников Bestchange.Копируем свой номер кошелька на пайер, на сайте https://www.bestchange.ru/ и в поле Отдадите выбираем Bitcoin (BTC), а в Получите
указываем Payeer USD.
Система выдает список всех пунктов, поддерживающих направление обмена payeer на биткоин, выбираем лучший курс и совершаем обмен.
Выбираем вкладку Перевести, указываем номер счета Яндекс.Деньги, сумму перевода, и система рассчитывает итоговую цифру сделки с учетом комиссии.
При переводе средств с Payeer на Яндекс.Деньги:
Комиссия: 2,9%
Min сумма: 10 RUB
Max сумма: 15 000 RUB за одну транзакцию
Срок исполнения: мгновенно
Обмен Payeer на Яндекс.Деньги
Как обменять Payeer на Сбербанк?
Выгодный курс обмена payeer на сбербанк ищем на Bestchange. Копируем номер кошелька на пайер, на сайте https://www.bestchange.ru/ и в поле Отдадите выбираем Payeer RUB, в поле Получите – Сбербанк. Выбираем лучшее предложение и совершаем обмен.
Обмен Payeer на Сбербанк
Как обменять Payeer на Приват24?
Выгодные варианты обмена payeer на приват24 подскажет Bestchange. Копируем номер кошелька на пайер, на сайте мониторинга в поле Отдадите выбираем Payeer USD, в поле Получите – Приват 24 UAH. Переходим на сайт обменника с лучшим предложением и завершаем процедуру обмена.
Обмен Payeer на Приват 24
Как обменять Payeer на Qiwi?
Обмен payeer на qiwi осуществляем в личном кабинете Payeer. Выбираем вкладку Перевести, указываем номер кошелька QIWI, сумму перевода, и система рассчитывает итоговую цифру сделки с учетом комиссии.
Обменять киви на payeer можно на следующих условиях:
Комиссия: 2,9%
Min сумма: 1 USD/EUR / 10 RUB
Max сумма: 200 USD/EUR / 15 000 RUB
Срок исполнения: мгновенно
Обмен Payeer на Qiwi
Как вывести деньги
Для вывода средств также есть большое количество способов:
Забрать наличными (USD, RUB, EUR) в официальных обменных пунктах (комиссия 1.99%);
ЭПС (AdvCash, Qiwi, Яндекс.Деньги, Bitcoin и др.);
В Личном кабинете в меню слева кликните на пункт “Перевести” либо выбираете эту же кнопку в разделе “Баланс”, на кошельке. Затем нужно выбрать удобный для вас способ вывода и указать необходимую сумму, а также номер кошелька. Еще возможен перевод средств между счетами пользователей Пайер, для этого необходимо просто знать номер счета.
Также Payeer оснащен собственной валютной биржей, то есть непосредственно в самой платежной системе можно спокойно обменять деньги между счетами пользователей по курсу, который возможно установить самостоятельно в заявке. Процесс конечно не очень быстрый, однако комиссия отсутствует. К тому же заявку можно отменить в любой момент и средства вернутся на счет.
Кроме того платежная система сотрудничает с большим количеством обменников. А самый выгодный курс по интересующему направлению всегда можно узнать на сервисах BestChange и Kurs Expert .
Вывод средств произойдет мгновенно. Все совершенные ранее операции можно посмотреть выбрав пункт меню “История».
Как сделать перевод с Payeer на Qiwi?
Чтобы перевести деньги с payeer на qiwi, в личном кабинете на Payeer выбираем Перевести, указываем номер кошелька QIWI, сумму перевода, и система рассчитывает итоговую цифру сделки с учетом комиссии 2,9%.
Пополнить киви кошелек с payeer можно как минимум 1 USD/EUR / или 10 RUB,
максимум 200 USD/EUR / или 15 000 RUB.
Перевод Payeer на Qiwi
Как вывести с Payeer на карту сбербанка?
Вывод денег с payeer кошелька на карту Сбербанка также выгоднее осуществлять с помощью стороннего онлайн-обменника. Копируем номер кошелька на пайер, на сайте https://www.bestchange.ru/ в поле Отдадите выбираем Payeer RUB, в поле Получите – Сбербанк. Выбираем лучший курс и на сайте обменного пункта совершаем операцию по выводу денег на Сбербанк-счет.
Вывод с Payeer на Сбербанк
Как вывести с Payeer на webmoney?
Посредством какого онлайн-обменника лучше всего вывести средства c payeer на webmoney подскажет Bestchange. На сайте мониторинга в поле Отдадите выбираем Payeer RUB, а в Получите указываем Webmoney. Переходим на сайт обменника и выводим деньги на счет на вебмани.
Вывод с Payeer на Webmoney
Как вывести с Payeer на Приват24?
Чтобы вывести средства с payeer на приват24, копируем номер кошелька на пайер и идем на сайт уже хорошо нам известного мониторинга Bestchange. Здесь в поле Отдадите выбираем Payeer USD, а в поле Получите – Приват 24 UAH. Система выдает список предложений, из них выбираем обменник с наиболее привлекательным курсом, который позволит максимально выгодно пополнить свой счет на Приват24.
Вывод с Payeer на Приват24
Как вывести с Payeer на EXMO?
При необходимости вывода с payeer на exmo снова прибегает к услугам мониторинга Bestchange и с его помощью совершаем валютную операцию с минимальными комиссиями. В графах Отдаете/Получите задаем нужное направление перевода, из предлагаемого системой списка выбираем наиболее привлекательное предложение и на сайте обменника завершаем процесс вывода денег с платежной системы пайер на эксмо.
Вывод с Payeer на Exmo
Карта Payeer Mastercard
С 1 октября 2015 года под покровительством банка Великобритании стали выпускаться фирменные пластиковые карты Payeer Platinum MasterCard, оформить которую можно в личном кабинете на сайте платежной системы в разделе Мои карты → Добавить карту.
Payeer карта это бесплатная именная банковская карта. За саму пластиковую карту платить не надо, оплачивается только доставка. Виртуальная пайер карта стоит $0,5.
Доставка обычной почтой обойдется вам в $9 и 3-4 недели ожидания.
Экспресс-доставка курьерской службой DHL стоит $35, но при этом вы получите карту на руки в течение нескольких дней. При получении карту нужно сразу активировать в личном кабинете посредством ввода последних 4-х цифр номера карты.
Payeer Platinum MasterCard работает в 200+ странах мира. Выдается на 3 года, и на протяжении всего периода обслуживается бесплатно. С ее помощью можно без комиссий оплачивать покупки в USD или EUR, но при оплате в валюте, отличающейся от валюты счета карты, комиссия составляет 2.5%. Держателям этой карты не нужно подавать налоговые декларации.
Благодаря автоматической конвертации карта позволяет обналичивать деньги в банкоматах по всему миру и снимать ту валюту, которая вам необходима в конкретный период времени.
ВАЖНО! С октября 2017 года карты Payeer Mastercard в России не выпускаются. Все активные карты, держателями которых были нерезиденты ЕС, были заблокированы 1 января 2018 года. Ограничение связано с политикой Mastercard в отношении партнера Payeer — эмитента Wave Crest Holdings.
Карта Payeer— как заказать
Payeer выпускает собственную пластиковую карту от MasterCard. Эмитент — холдинг West Crest. Ей можно пользоваться практически в любой стране и расплачиваться в любых магазинах, где принимают MasterCard, а также снимать деньги в банкоматах.
К главным преимуществам можно отнести достаточно небольшую стоимость карты, отсутствие платы за обслуживание и самый главный плюс — полная конфиденциальность, т.е. о совершаемых вами операциях ни налоговая ни какие-либо другие лица не смогут узнать. Карта выпускается и активизируется совершенно бесплатно, потребуется оплатить только доставку — 9,55$.
При обналичивании денег через банкоматы, комиссия со стороны платежной системы Payeer отсутствует, возьмет ее только банк — 1,99$ за операцию. Во время снятия рублей с валютной карты, комиссия за конвертацию будет 2,5% от суммы и еще плюс 3,5$ за транзакцию. При безналичной оплате в валюте — комиссия отсутствует, но если будете платить в рублях, а сама карта в долларах, то уже сам MasterCard возьмет какой-то процент за обмен.
Заказать карту можно через соответствующую форму на официальном сайте. Можно только одну и только на физическое лицо. Лимит — 2500 EUR, увеличение возможно после верификации. Подробнее обо всем можно прочитать непосредственно на сайте кошелька.
После получения карты, необходимо на обратной стороне поставить свою подпись. Далее активизировать ее в личном кабинете, для этого укажите её номер, CVV и дату рождения. После вы получите PIN-код (его можно изменить, обратившись в службу поддержки или в банкомате MasterCard).
Важно знать! С начала 2018 года карты Пайер, которые были выпущены для не резидентов Евросоюза были заблокированы. В настоящий момент вопрос об их выпуске за пределами Европейского Союза решается, поэтому получение может возобновиться в ближайшее время.
Бонусная программа Payeer
Payeer бонусы представляют собой раздачу денег на пайер кошелек наподобие сбора сатошей с криптовалютных кранов.
Как получить? После ввода номера кошелька и капчи нужно нажать на рекламу, чтобы появилась ссылка Получить бонус.Определенная сумма денег начисляется уже сразу после активации данной ссылки. На каждом кране с бесплатной раздачей payeer имеется определенная сумма к выводу. Чтобы ее набрать, нужно проделать описанную выше процедуру 4-5 раз.
Можно попробовать серфинг за деньги на Payeer. В этом случае бонусы начисляются за выполнение разных заданий: просмотр сайтов, рекламы, видео и тд.
Но раздача пайер бонусов на этом не заканчивается. Существуют удвоители payeer и payeer утроители, которые по сути являются хайпами, позволяющими быстро заработать на вложениях.
Схема простая: вкладываете деньги и спустя короткое время забираете в разы больше.
Классические удвоители живут 12-14 часа. За это время пользователь регистрируется на сайте, вкладывает деньги и получает выплаты с процентами. Таким образом, пайер позволяет бесплатно удвоить или утроить свой капитал, поскольку деньги работают на вас каждую минуту.
Для дополнительного заработка Payeer предлагает также:
Многоуровневую реферальную программу. Привлекаете на платформу новых пользователей, получаете до 40% от комиссий рефералов и до 5% комиссий рефералов ваших рефералов.
Открытие собственного обменника. Бесплатно используя API платежной системы, открываете свой обменный пункт. Это может быть обменник с нуля или подключенный к уже существующему сайту, что сразу позволит монетизировать трафик. Еще один полезный bonus при открытии своего обменника: скидка Payeer от 20% до 40% в зависимости от объема.
В отличие от других платформ электронных платежей, Payeer обеспечивает неограниченный денежный поток внутри системы, а переводы на Visa и MasterCard не могут превышать 5 000 долларов США за один раз. Предприниматели могут использовать систему для настройки онлайн-платежей на своих сайтах. Чтобы включить эту функцию, вам нужно просто зарегистрировать кошелек в сервисе и создать учетную запись Merchant. Payeer может помочь IT-специалистам, предоставляя API, который может быть полезен для создания приложений и веб-сайтов. Благодаря относительно низким тарифам, недорогому управлению валютой, криптовалюте и интуитивно понятному личному кабинету кошелька Payeer, компания постепенно создает прочную репутацию и становится действительно отличной онлайн-службой управления деньгами.
Преимущества системы Payeer
К основным достоинствам системы Payeer можно отнести:
Payeer принимает заказы на выпуск офшорных пластиковых карт MasterCard USD/EUR;
Работает с тремя валютами: RUB, USD, EUR;
Система не затрагивает анонимность своих клиентов — здесь полностью отсутствует процедура верификации;
С Payeer пользователь имеет возможность пополнить кошелек множеством способов: как через карту, так и через другие платежки, что позволяет использовать сервис как обменник, например, BestChange.ru;
Система крайне редко блокирует аккаунты своих клиентов;
Платежная система Рayeer предлагает двухфакторную систему безопасности, когда при входе пользователю необходимо ввести пароль и секретный код, который приходит на электронную почту. Тем же, кому недостаточно такой защиты аккаунта, предоставляется возможность за отдельную плату подключить смс-уведомление (0,05$) и абсолютно бесплатно установить IP-безопасность.
Отзыв о платежной системе Payeer
Прочитав данную статью полностью, думаю, будет понятно, что отзыв о платежной системе Payeer может быть только положительным. Все преимущества и удобства Payeer обеспечат комфорт при работе через интернет, ведении бизнеса в сети, а также просто при осуществлении платежей.
Perfect Money ( официальный сайт ) — оффшорная электронная платежная система, которая начала свою работу еще в далеком 2007 году. И с того времени является лидером на рынке среди всех существующих ЭПС. Компания зарегистрирована в Панаме. Сайт предлагает на выбор пользователям более 20 различных языков, в том числе Русский и Украинский. Поддерживает 4 основных валюты на сегодняшний день: доллар (USD), евро (EUR), золото, биткоин (BTC).
Кошелек Перфект Мани пользуется большим успехом в различных финансовых сферах. К услугам РМ прибегают как крупные международные компании, так и частные лица, владельцы интернет-бизнеса. Но чаще всего данную платежную систему используют для ввода/вывода денежных средств в высокодоходных (хайп) проектах . А все из-за анонимности и абузоустойчивости, т.е. никто никогда не сможет узнать о совершаемых пользователем операциях. Читайте так же: “Платежная система Payeer“.
Общая информация про кошелек Perfect Money
Сервис Perfect Money работает на протяжении 13 лет — первая транзакция была проведена в 2007 году. Популярность начала резко расти начиная с 2013 года: именно тогда закрылась площадка Liberty Reserve, один из основных конкурентов.
Перфект Мани управляется из Цюриха, а материнская компания платежного сервиса, Perfect Money Finance Corp., зарегистрирована на территории Панамы. Однако это не должно смущать пользователей из стран СНГ — главная страница адаптирована для русскоязычных клиентов:
Помимо русского, здесь поддерживается еще 22 языка. Но они менее популярны: основная часть пользователей проживает в странах СНГ.
Как зарегистрироваться в Perfect Money?
Давайте подробно рассмотрим, как зарегистрироваться в Perfect Money. Регистрация в данной платежной системе у Вас займет всего несколько минут. Для начала перейдите на официальный сайт платежной системы: Perfect Money.
Перейдя по указанной выше ссылке Вы попадете сразу на страницу с формой регистрации. Заполните ее достоверными личными данными. Форму регистрации в Perfect Money Вы можете увидеть ниже на картинке. После того, как Вы заполнили данную форму, нажмите на кнопку «Зарегистрироваться».
На этом регистрация в Perfect Money завершена. Теперь нужно осуществить первый вход в свой аккаунт.
Как войти в Perfect Money?
Для того, чтобы войти в Perfect Money, нажмите на главной странице платежной системы на ссылку «Вход». Далее проверьте почту электронного адреса, который Вы указали при регистрации в Perfect Money. На него должны прийти два письма, в одном из них будет Ваш идентификационный номер.
После этого, на странице авторизации укажите свой ID и пароль, далее введите капчу и нажмите на кнопку «Логин».
После этого Вы можете пользоваться всеми функциями платежной системы Perfect Money.
Верификация и настройка безопасности аккаунта
После регистрации система предложит верифицировать аккаунт, что позволит получить доступ к расширенному функционалу и иметь более выгодные финансовые условия для денежных транзакций.
Для идентификации личности системе нужно предоставить:
скан паспорта / водительского удостоверения;
скан счета за коммунальные услуги с актуальным адресом;
номер телефона;
Пройти верификацию система предлагает при входе в личный кабинет:
Заходим в свой аккаунт, введя ID, пароль и код с картинки → Логин;
Выбираем вкладку Настройки
Внизу страницы будет блок с информацией о верификации, нам нужна Верификация аккаунта → ссылка Управление верификацией;
Первый из трех этапов – Верификация Имени:→ Выберите файл → добавляем скан-копию паспорта или водительских прав → Загрузить документ.
Второй этап – Верификация Адреса: → Выберите файл → добавляем скан-копию счета за коммунальные услуги с отчетливыми именем и адресом → Загрузить документ.
К третьему этапу – Верификация Телефона – переходим лишь после того, как система подтвердит 1 и 2 этап (обычно занимает 3-5 дней).
Perfectmoney верификация не обязательна: системой можно пользоваться полностью в анонимном режиме. Из недостатков для не верифицированных пользователей: недоступны некоторые функции и более высокие комиссии.
Чтобы защитить свой аккаунт от взлома, в системе Perfect Money предусмотрено три уровня безопасности, которые можно активировать/дезактивировать по своему усмотрению:
Проверка подлинности пользователя включена по умолчанию. При входе в систему с неизвестного IP-адреса на электронный адрес приходит код подтверждения, который нужен для возобновления доступа к аккаунту.
SMS-авторизация платная: 0.1 usd за каждое sms сообщение с кодом, которое приходит на мобильный телефон.
Кодовая карта содержит цифры, которые нужно будет вводить каждый раз при вводе/выводе/переводе средств. Кодовую карту можно хранить на любом цифровом носителе.
Включить или выключить тот или иной тип проверки – ссылка Изменить параметры безопасности.
В личном кабинете, кликнув на панели меню по кнопке Отзывы, можно напрямую обратиться в службу поддержки, используя уникальную защищенную Систему Безопасных тикетов.
Perfect Money позиционируется как клиентоориентированный сервис, поэтому ценит честную обратную связь от клиентов. Открытый диалог с пользователями и прозрачность работы повышают лояльность к платформе, устанавливая доверительные партнерские отношения между сервисом и его клиентами.
СОбратившись к специалистам, вы можете оперативно получить любую интересующую вас информацию: условия и тарифы на ввод/вывод/перевод/обмен, как создать кошелек в rub, как узнать номер ID-кошелька в случае его утери или платежный пароль для осуществления операций в системе и тд.
Статусы пользователя кошелька
В Perfect Money предусмотрено 3 статуса пользователя. В целом большой разницы между ними нет, но есть возможность получить комиссионные вычеты, если выполнить определенные условия.
Normal. Статус присваивается всем новым аккаунтам без каких-либо ограничений.
Premium. Данный статус присваивается после 1 года пользования кошельком или после достижения определенного оборота средств баланса. В этом статусе меньше комиссии на операции по отношению к Normal.
Partner. Присваивается администрацией Перфект Мани в одностороннем порядке бизнес аккаунтам и дает им дополнительные преимущества.
Безопасность платежной системы
В платежной системе предусмотрено несколько степеней защиты, которые помогут защитить ваши деньги от мошенников:
1. Проверка подлинности пользователя. Этот инструмент проверяет устройство, с которого происходит попытка входа в аккаунт. Если система заметит, что вход осуществляется с другого IP, то на e-mail будет отправлен дополнительный код безопасности.
2. СМС-авторизация. В этом случае при попытке входа высылается код подтверждения на мобильный телефон владельца счета. Это самый защищенный способ, так как для входа в аккаунт требуется доступ к номеру телефона.
3. Кодовая карта. На почту пользователя высылается графическая карта с кодами подтверждения. Для подтверждения операций система будет каждый раз запрашивать в случайном порядке определенный код.
Какие из этих функций активировать, а какие нет — решать вам. Я же рекомендую использовать от 2 степеней защиты, например, кодовую карту и проверку подлинности пользователя.
Perfect Money — как ввести и вывести деньги
Есть 2 способа как ввести на кошелек и вывести деньги.
1. Первый способ это перейти во вкладки “Ввод” или “Вывод” из личного кабинета.
На ввод доступны такие варианты:
Банковский перевод. Минимальная сумма — 300$ или эквивалент в золоте или евро;
e-Voucher;
Через сертифицированные обменные пункты партнеры;
Bitcoin;
Через кредитную биржу.
На вывод:
Банковский перевод;
e-Voucher;
Электронные деньги;
Сертифицированные обменные пункты партнеры;
Bitcoin;
Кредитная биржа.
2. Второй способ, который я рекомендую — это воспользоваться мониторингами обменных пунктов — BestChange или Kurs.Expert . По сравнению с первым способом, на них можно легко найти самый выгодный курс нужной валюты. С минимальными комиссиями перевести деньги с одной платежной системы в другую или сразу на банковскую карту. В общем направлений обменов множество. Ну, а каким из способов пользоваться вам — решаете вы.
Какие кошельки и аккаунты есть в Perfect Money?
В Perfect Money есть несколько видов кошельков, которые отличаются друг от друга по валюте. Также есть градация аккаунтов — по типу пользователя (персональный/бизнес) и по его статусу.
Как пополнить кошелек?
Есть 2 способа, как пополнить свой счет Perfectmoney:
Способ 1. Встроенные способы ввода на сайте Perfect Money.
Положить деньги на перфект мани кошелек можно через:
Банковский перевод (минимальная сумма пополнения $300);
e-Voucher (без комиссии);
Обменные пункты-партнеры PM;
Криптовалюту Bitcoin (комиссия 0%);
Кредитную биржу .
Способ 2. Через независимые сертифицированные онлайн-обменники.
Как лучше завести деньги на Perfect Money и сэкономить на комиссии подскажет популярный мониторинг обменников BestChange.ru .
На сайте сервиса указывает откуда и куда переводим деньги и получаем список сертифицированных надежных обменных пунктов, поддерживающих заданное направление.
Как пополнить Perfectmoney через Qiwi?
Покажем, как пополнить перфект мани через киви воспользовавшись вторым способом, то есть через сторонние сервисы по обмену валют. Лучшее предложение ищем на BestChange.ru.
На сайте бестчендж в левом сайдбаре в графе Отдадите выбираем QIWI, Получите – Perfect Money.
По заданным параметрам система выдает список обменных пунктов, ранжируя их на основании курса: самые выгодные предложения находятся вверху списка;
Помимо курса обмена обращаем внимание на имеющийся в обменнике резерв нужной нам валюты и отзывы;
Выбираем лучшее предложение, переходим на сайт обменника и совершаем процедуру обмена с киви на перфект мани.
Как сделать перевод?
После пополнения кошелька можно осуществлять мгновенные внутренние переводы с минимальной суммой 0.01 USD/EUR или 10 USD золотом.
Как перевести деньги на другой кошелек Perfectmoney:
Заходим в личный кабинет и в меню выбираем Внутренний перевод;
Система предлагает 4 варианта перевода: единый платеж, платеж на e-mail, платеж на мобильный телефон, платеж по расписанию;
Единый платеж позволяет перевести деньги другому пользователю по ID кошелька (самый распространенный способ);
Выбираем Единый платеж, вводим сумму, которую будем переводить, кошелек получателя, описание платежа (опционально) → Предпросмотр платежа;
Проверяем данные и, если все введено корректно, подтверждаем перевод.
Также для любой транзакции в системе можно установить код протекции, без которого пользователь не сможет получить ваш перевод. Его можно придумать самостоятельно или использовать код, сгенерированный системой. Период действия кода от 1 до 365 дней (выставляется по желанию пользователя).
Как сделать перевод с Perfectmoney на Яндекс Деньги?
Показываем, как с помощью Bestchange перевести деньги с Perfectmoney на Яндекс Деньги.
На сайте мониторинга в графе Отдадите выбираем Perfect Money, в Получите – Яндекс.Деньги.
Выбираем обменник с лучшим курсом, обращая внимание на резерв и отзывы, переходим на сайт обменного пункта, где и завершаем операцию перевода с кошелька Перфект Мани на Яндекс Деньги.
Как сделать перевод с Perfectmoney на Qiwi?
Чтобы перевести деньги с Perfectmoney на qiwi, на сайте бестчендж в графе Отдадите выбираем Perfect Money, в графе Получите отмечаем QIWI. Система предложит варианты обмена между данными кошельками, отсортированные по лучшему курсу.
Выбираем выгодный и надежный обменный пункт и производим обмен.
Если нужно наоборот пополнить Perfectmoney с киви кошелька, то задаем обратное направление перевода QIWI → Perfect Money и выбираем из предложенных системой сервисов.
Как сделать перевод с Perfectmoney на карту Сбербанка?
Если вас интересует перевод на Сбербанк, то процедура будет аналогичной. Прибегая к услугам хорошо нам известного bestchange.ru с целью перевести средства с Perfectmoney на карту Сбербанка, задаем соответствующие параметры: Отдаете Perfect Money USD, ПолучитеСбербанк.
Как обменять деньги?
Как и в случае перевода, найти лучший обменник Perfectmoney на другую валюту поможет популярный мониторинг обменников Bestchange.ru. Механика поиска лучшего предложения обмена средств с кошелька перфект мани на кошелек в другой платежной системе вам хорошо известна.
Как обменять Perfectmoney на Qiwi?
На примере обмена Perfectmoney на qiwi закрепим порядок действий.
в таблице с валютами в графе Отдадите выбираем Perfect Money, а в графе Получите – платежную систему QIWI, на счет которой переведем средства с PM;
в списке с обменниками, который подобрал мониторинг, выбираем лучший курс по обмену PM на QIWI, кликаем по обменнику и переводим средства с платежной системы Perfect Money, которые зачислятся на qiwi-счет.
Таким же самым образом можно обменять киви на Perfectmoney.
Как вывести средства?
Для вывода средств со счета Perfect Money, как и в случае пополнения баланса, предусмотрены 2 опции:
Через встроенные способы вывода в системе PM: банковский перевод (от 2.5% + комиссия банка); e-Voucher (без комиссии); криптовалюта Bitcoin (экспресс-вывод, комиссия 0.5%); обменники-партнеры Perfect Money; кредитная биржа.
При выборе того или иного способа, на сайте отображаются полные условия сделки и лимиты на ввод и вывод средств.
Через независимые сертифицированные онлайн-обменники.
Если вы ищете способ, как вывести деньги с Perfectmoney c наименьшими не только денежными, но и временными затратами, то удобнее всего воспользоваться сторонними сервисами по поиску наиболее оптимальных решений.
Бесплатный мониторинг BestChange.ru отслеживает самые выгодные курсы обмена валют по всему рунету, что сводит к минимуму время, потраченное на поиски.
Как вывести средства на карту сбербанка?
Чтобы осуществить вывод денег с Perfectmoney кошелька на карту сбербанка, переходим на сайт мониторинга Bestchange.ru и слева в таблице в колонке Отдадите отмечаем валюту, которую отдаем (Perfect Money), Получите – валюту которую получаете (Сбербанк).
По заданным параметрам система подбирает список обменных пунктов и сразу сортирует их на основании предлагаемого курса. Осталось выбрать, как именно вывести деньги.
Для завершения операцию нужно определиться с обменником, кликнуть по нему и уже на сайте обменного сервиса перевести средства, в нашем случае с кошелька перфект мани на карту Сбербанка. В среднем время перевода занимает до 15 мин, а в некоторых случаях зачисление происходит мгновенно.
Перфект Мани — партнерская программа и как заработать
Каждый пользователь Перфект Мани может зарабатывать просто держа денежные средства на своем счете. Каждый месяц на остаток средств на балансе будет начисляться по 0.33%, за 1 год это 4%. Ничего не делаете и получаете за это проценты в USD, EUR или BTC, как при банковском депозите. Вот только в банках депозиты в рублях, а у рубля высокая инфляция, которая съедает весь доход (а также девальвация).
В платежной системе есть возможность увеличить свой заработок при помощи партнёрской программы. Привлекаете пользователей и получаете 1% годовых с остатка средств своих рефералов.
Свою партнерскую ссылку вы можете найти во вкладке история и нажав на ссылку как показано на картинке.
Недостатки Перфект Мани
Что касается минусов платежки, то их гораздо меньше, чем преимуществ и в целом эти недостатки можно считать относительными. Это значит, что они не являются критическими и для многих пользователей не играют роли.
В первую очередь стоит сказать, что далеко не все клиенты Perfect Money готовы предоставлять свои документы и проходить верификацию. В этом случае работа с платежкой для них будет невыгодной, так как размер комиссии будет составлять 1.99%, что считается достаточно большим процентом.
Кроме относительно высокой комиссии для не верифицированных пользователей, стоит отметить минусом и то, что напрямую пополнить счет и вывести деньги из системы невозможно. Перфект предлагает это делать через обменники, кредитную биржу, E-Voucher или биткоины. Зачастую придется прибегать к помощи посредников в виде обменных сервисов.
Преимущества кошелька Perfect Money
Платежка Perfect Money широко известна в узком кругу хайп-инвесторов и пользуется спросом не зря. Она имеет много плюсов, которые и делают ее оптимальным инструментов для платежей:
Низкая комиссия для верифицированных пользователей в размере 0.5% (для тех, кто не прошел верификацию, комиссия составит 1.99%).
Регистрация платежки в офшорной Панаме позволяет ей работать вне контроля налоговых органов и прочих регуляторов.
Сайт Перфект Мани переведен на 23 языковые версии, в том числе он предоставляется и на русском.
Есть возможность отправлять деньги через e-Voucher. В этом случае получатель не видит реквизитов отправителя.
Есть API для обменных пунктов, магазинов и других коммерческих ресурсов.
Удобные настройки аккаунта позволяют выбрать оптимальный уровень безопасности.
Есть несколько счетов в разной валюте – Dollar, Gold (troy oz.), Bitcoin, Euro. Также пользователь может открывать дополнительные кошельки в одной и той же валюте.
На остаток начисляются дивиденды в размере 4% в год.
Есть партнерская программа, которая позволит зарабатывать 1% годовых с минимального месячного остатка на счету партнера.
С 2010 года в Перфект Мани есть своя кредитная биржа, через которую можно выдавать деньги в кредит и брать займы у других пользователей.
Есть функция «Платеж по расписанию», которая позволит осуществить транзакцию в заданный день и время.
Есть внутренний обменник, позволяющий зарабатывать на скачках курса разных валют.
Имеются приложения для устройств на iOS и Android.
Perfect Money — отзыв и заключение
Регулярно пользуюсь Perfect Money и могу рекомендовать вам. Конечно есть некоторые недостатки, но их значительно перевешивают преимущества. Считаю, что у тех, кто зарабатывает в интернете или только собирается, должен быть в арсенале данный кошелек. Платежная система работает практически с каждым инвестиционным проектом , к тому же она популярна и проста в использовании.
WM-кошелек в системе WebMoney (Вебмани) — инструмент хранения виртуальной валюты. Платформа располагает несколькими видами кошельков, каждый из которых хранит валюту с соответствующими титулами. Рассмотрим WMZ кошелек что это, а также что такое WME, WMU кошельки и другие. Внутри системы пользователями совершается оборот не реальных денег (рублей, долларов или других), а специальных титульных знаков, привязанных к конкретным валютам и золоту. По состоянию на май 2020 г. система предлагает 13 видов кошельков, являющихся эквивалентом той или иной валюты:
Каждый из представленных кошельков идентифицируется уникальным 12-значным номером, а сам тип валюты обозначается префиксом — латинской буквой. Благодаря этому легко различать счета, на которые другие пользователи запрашивают перевод. Например, понять, что это Webmoney WMZ, предназначенный для долларов, можно по латинской букве Z, стоящей в самом начале номера. Буква B перед номером значит, что на счету можно хранить белорусские рубли.
Пользователь вправе самостоятельно определять тип кошелька, который ему необходим. У каждого титульного знака есть собственный гарант, поэтому они не зависят друг от друга. Однако все счета объединяются под одним идентифицирующим номером — WMID.
Помимо основных кошельков, существуют 2 специальных вида:
WMD — тип D — обозначает сумму выданных кредитов другим пользователям;
WMC — тип С — учетных кредитных обязательств перед другими участниками.
Счета D и C являются уникальными, поэтому на 1 аккаунте допускается открытие не более 1 счета.
Для остальных видов титульных знаков разрешается создание дополнительных кошельков. Но для этого нужно привязать и скачать профессиональную версию Кипера, поскольку WM Keeper Standart (личный кабинет на сайте) не обладает таким функционалом.
Особенности WMX
Рассмотрим WMX счет в Webmoney: что это, для чего нужен и какие особенности имеет.
WMX — это один из титульных знаков, являющийся аналогом криптовалюты, а именно 0,001 BTC. За основу взята глобальная публичная база данных сети bitcoin.org.
Прием/хранение и возврат с хранения BTC производится на основании заключенного договора хранения имущественных прав WMX.
За совершение любых операций с WMX, в том числе на внутренней бирже, система взимает 0,8 % от суммы в качестве комиссии. При этом максимальный размер сбора не может превышать 5 WMX.
Для получения доступа к операциям ввода и вывода WMX необходим формальный аттестат, прошедший проверку личных данных.
Чем WMP отличается от WMR
WMP — это основной вебмани-счет, на котором хранятся титульные знаки, являющиеся эквивалентом российского рубля. R-счет также предназначен для рублей, но при этом они различаются.
В 2020 г. WMR кошелек в первую очередь рассчитан на нерезидентов РФ. Его легко открыть, для этого не требуются какие-либо документы, но при этом недоступно значительное количество операций, а также существенно ограничены лимиты. Участники из России могут пользоваться данным типом счета, но с такими же ограничениями.
Для создания WMP кошелька пользователю необходимо пройти предварительную упрощенную или полную идентификацию. Упрощенная процедура доступна только гражданам РФ, она подразумевает загрузку в личный кабинет своего ИНН и СНИЛС, а также проверку документов администрацией. Участники из других стран должны закончить полную идентификацию.
До октября 2019 года был открыт беспроцентный переход на WMP с WMR с последующим закрытием последнего. В 2020 г. данная операция облагается стандартной комиссией 0,8 %. При этом отправить деньги в обратную сторону напрямую нельзя, для этого нужно пользоваться специальными обменниками.
WMP кошелек может быть использован для совершения любых операций в системе, а также для оплаты товаров и услуг в интернете. На него распространяются только общие ограничения.
Что такое бумажник WebMoney
Платежная система обеспечивает возможность распоряжаться титулами в ее пределах или обналичивать их путем вывода на счета прочих платежных систем и карт банков. Каждый кошелек обозначен соответствующей аббревиатурой, например, WMR — что это такое среди всех остальных кошельков и какое он имеет назначение. WMR-кошелек обеспечивает работу с титульным знаком, который эквивалентен рублю РФ. К аббревиатуре WM присоединена буква R для обозначения рублей.
Изучая, что за кошелек WMR, следует учитывать, что холдер хранит только рубли, а при оплате с его счета долларового товара или услуги произойдет конвертация валюты согласно внутреннему курсу, о чем система предупредит участника перед выполнением операции. Что такое применение кошелька — это переводы и платежи в любой валюте, начиная от долларов и заканчивая евро или украинскими гривнами.
По номеру кошелька можно узнать WMID — идентификатор пользователя. Например, намечается оплата через Интернет в электронной валюте определенного товара. Продавец дает номер бумажника и больше ничего. Покупатель хочет получить гарантии, что после оплаты получит товар: нужно получить хоть какую-то информацию о продавце.
Так как сделка происходит за пределами системы, информацию можно получить следующим способом:
Пройти по ссылке https://passport.webmoney.ru/asp/VerifyWMID.asp.
В специальном окне указать номер WM-кошелька и нажать «Найти».
Всплывает окно, в котором отобразятся данные о держателе кошелька, в том числе и номер идентификатора.
Узнать информацию можно о любом участнике, зная цифры номера портмоне.
Как завести электронный кошелек WebMoney
Регистрация электронного кошелька не отличается от регистрации на любом сайте. Достаточно придумать логин, пароль и указать мобильный телефон. Зарегистрироваться можно двумя способами: через компьютер и через мобильное приложение на смартфоне. Рассмотрим подробнее оба этих способа.
Webmoney кошелек – вход в личный кабинет
Как и любой кошелек или интернет-банк Webmoney имеет защиту для входа, которая может осуществляться через:
Электронную почту. Пользователю отправляется письмо с кодом, который нужно будет ввести в платежной системе;
На номер телефона. Предпочтительный способ, который стоит по умолчанию.
Также для удобства использования платежной системы имеется удобное мобильное приложение, позволяющее быстро оплатить услугу или воспользоваться QR-кодом для оплаты.
Важно, что при установке мобильного приложения вся проверка при входе будет вестись через него, но данную функцию можно переключить на другие способы аутентификациии.
Например, при стандартном входе производиться проверка через электронную почту или мобильный телефон, а в случае с приложением потребуется сканировать код с приложения и отправить его на сайт или ввести вручную.
Лишь только после выполнения этих требований будет доступен вход в личный кабинет. Таким образом можно защитить свою учетную запись от злоумышленников и взлома, а также сохранить свои деньги.
Также система оповещает на почту всех пользователей если осуществляется вход в личный кабинет. Например, при входе в личный кабинет в режиме инкогнито, то сразу же приходит уведомление на почту. Аналогично будет приходить уведомление в телефоне в виде PUSH.
Аттестаты Вебмани
Аттестатов Вебмани идентификаторов – огромное множество. Среди них самые распространённые:
псевдонима,
формальный,
начальный,
персональный,
продавца.
Система WebMoney Transfer требует от каждого пользователя оформления аттестата:
Аттестат псевдонима подразумевает подачу информации по данным владельца, и не проверяется системой.
Формальный аттестат выдаётся на основании подачи паспортных данных (открывает большинство возможностей системы).
Начальный аттестат оформляется после проверки поданных персональных данных (сведений паспорта). Он оформляется только при отсутствии ранее оформления персонального либо начального аттестата.
Региональные Персонализаторы имеют право выдачи начальных и персональных аттестатов.
Внимание: есть возможность автоматического получения аттестата начального уровня после зачисления на R-кошелек средств денежным переводом по РФ, через системы Юнистрим, Анелик, Contact, либо с банковского счёта.
Необходимо совпадение указанных данных для WMID и при переводе.
Выдаются также:
Аттестат продавца – для ведения деятельности через мерчант-интерфейс.
Capitaller – тип аттестата дл бюджетных автоматов.
Аттестат расчетного автомата (для юрлиц, для интеграции системы расчётов с wm).
Аттестат разработчика для создателей ПО WebMoney Transfer.
Аттестат регистратора (наивысший, требуется собеседование с представителями центра аттестации).
Существуют также аттестат сервиса, гаранта и оператора.
Какие есть виды бумажников
На сегодня система WebMoney Transfer предлагает клиентам несколько видов кошельков:
Z — доллар;
E — европейская валюта;
R — обозначение для WMR-деньги;
U — гривна (валюта Украины);
B — рубль, но белорусский;
K — для казахской электронной валюты;
X — для криптовалюты BTC;
G — для золота.
Каждый кошелек имеет разные имущественные права, а титул в качестве WM считается единицей измерения. Правами обладает только Гарант. Система WebMoney Transfer не ограничивает пользователя в количестве кошельков, например, WMR-валюты и несколько других, в выборе Гаранта.
Единым хранилищем для портмоне считается Keeper, а его WMID выступает индивидуальным регистрационным номером для пользователя.
Какой кошелек Webmoney выбрать
Пользователям разрешено самостоятельно выбирать тип кошелька для использования. При его создании следует исходить из основных целей. Если задача оплата товаров и услуг в российских интернет-магазинах и отправка денег другим пользователям, вероятно, хватит и одного WMP, особого смысла открывать WMR нет, поскольку он ничем не лучше, а наоборот, имеет ограничения.
В дальнейшем также легко зарегистрировать счета и под другие валюты — доллары, евро, гривны, никаких ограничений по этому поводу нет.
Что делать, если создал кошелек не той валюты
Если была допущена ошибка при выборе валюты, всегда можно оформить новый кошелек, система это не запрещает. Ненужный счет можно удалить, а потом при желании восстановить — и так хоть до бесконечности.
Можно ли перевести деньги с WMR на свой кошелек другой валюты
В 2020 году напрямую перевести WMR можно только на WMP счет, другие валюты для этого недоступны. Однако уже WMP обмениваются на любые титульные знаки через личный кабинет либо специальные биржи.
Чтобы совершить перевод, необходимо зайти в WM Keeper Standard, нажать на карточку WMR кошелька и выбрать пункт перевода на WMP:
Также можно открыть панель управления WMP и произвести пополнение «Со своего WMR кошелька»:
Выбрать желаемую сумму и продолжить оформление:
Далее происходят стандартные подтверждения операции, затем деньги моментально перечисляются. После этого можно сразу же начинать ими пользоваться.
В обратном порядке выполнить процедуру невозможно, и перевести деньги с WMP на WMR кошелек напрямую не разрешается, однако и особого смысла в этом нет. В случае необходимости придется пользоваться внутренней или сторонней биржей и приобретать WMR через нее.
Особенности перевода средств со своего WMX кошелька на WMR кошелек
Совершить прямой перевод с WMX на WMR нельзя, для этого придется пользоваться системным обменником WM exchanger https://wm.exchanger.money/asp/wmlist.asp, либо любым другим сторонним сервисом.
После перехода на сайт биржи следует выбрать обе валюты обмена. Здесь же можно отсортировать все заявки по предлагаемому курсу:
Чтобы произвести обмен, нужно нажать на подходящую строку и подтвердить операцию. После этого деньги зачислятся на указанный WM кошелек. Если ни одна из заявок не может покрыть всю сумму перевода за 1 раз, можно скупить сразу несколько позиций. Также пользователи вправе самостоятельно создавать заявки, указывая любые желаемые условия.
Обмен через внутреннюю биржу абсолютно безопасен для обоих участников. До момента окончательного зачисления средств на счета пользователей они замораживаются системой, поэтому обман одним пользователем другого невозможен. При возникновении любых проблем каждая сторона имеет право обратиться к администратору для разрешения спора.
Какие сложности могут возникнуть при входе в Вебмани
Чтобы воспользоваться услугами Вебмани, необходимо зарегистрироваться и создать аккаунт. Для этого необходимо зайти на официальный сайт системы или скачать приложение и пройти несложную процедуру регистрации. На первом этапе проходить идентификацию или подтверждать паспортные данные по упрощенной схеме – не обязательно. Часть возможностей системы будет доступна сразу же – понадобятся лишь адрес электронной почты, номер телефона и пароль.
С последним чаще всего и возникают сложности. Неверный ввод хотя бы одной цифры лишает возможности входа в Вебмани. А чаще всего пользователи банально его забывают – поскольку нигде не записывают или из-за того, что теряют бумажку с записанным паролем.
Полезный совет! Для хранения паролей лучше всего использовать специальных менеджеры паролей – такие как 1password.
Существует несколько способов входа в Вебмани:
стандартный вход;
авторизация без мобильного телефона (без смс-кода);
подключение E-NUM.
Последний способ – самый удобный, так как E-NUM все равно потребуется в процессе работы с системой, ведь подтверждение платежей и переводов SMS-кодом для владельцев WebMoney-кошельков – услуга платная. Через E-NUM все бесплатно, но для работы с ней нужен будет смартфон с установленным приложением платежной системы.
Стандартный вход в Вебмани
Классическим методом входа в электронный кошелек WebMoney может воспользоваться каждый пользователь, имеющий телефон и помнящий пароль. Действия в данном случае будут заключаться в следующем:
открыть сайт Вебмани и выбрать пункт «Вход» (открывается окно для авторизации);
заполнить строку «Логин», в которую надо ввести номер телефона, e-mail или WMID (определяется пользователем);
ввести пароль, придуманный при регистрации;
разгадать «капчу» – цифры и буквы с появившейся картинки (при нечитаемости картинки «капчу» можно обновлять).
Система затребует подтверждение номера телефона, поэтому следует ожидать SMS с кодом.
Существуют два варианта, которые необходимы для защиты от взломов. В ряде случаев проще воспользоваться СМС-авторизацией, так как телефон всегда под рукой (WebMoney постоянно требует подтверждения действий пользователя). Подтверждение через SMS удобно в тех случаях, когда у пользователя не смартфон, а обычный телефон или когда он находится в зоне с неустойчивым интернет-соединением. Роботом через несколько секунд будет отправлено автоматическое сообщение, в котором указан код. Его необходимо ввести в соответствующее поле. Больше препятствий нет, вход в систему WebMoney открыт, и можно приступать к работе с кошельками.
Важно! Если смс-ка задерживается или код не поступил, – необходима перезагрузка телефона. Если запросов направлено несколько, вводятся цифры кода последнего сообщения. При введении неверной комбинации кодовых цифр несколько раз подряд, следующее смс-сообщение приходит на телефон по истечении 20 минут.
Вход с помощью разных версий WM Keeper
С учетом существования нескольких браузерных версий Webmoney следует учесть следующее:
При наличии WM Keeper Standart используется классическая система входа.
Keeper WinPro требует скачивания и установки на ПК, для входа потребуется персональный аттестат.
Keeper WebPro Light/Mobile используются для авторизации на планшетах и мобильных телефонах.
Версия Keeper упрощена, но логин и пароль вводятся обязательно. Безопасность обеспечивается подтверждением кода с помощью смс.
Вход в систему при отсутствии телефона
Если возможность получить смс-код отсутствует и нет возможности зайти в WebMoney, можно воспользоваться другим вариантом входа. Причем, имеются два способа входа при отсутствии телефона.
В первом случае пользование телефоном исключается полностью. Время будет сэкономлено, но защищенность учетной записи окажется под угрозой. Прежде, чем принимать решение, следует осознать, что риск достаточно большой – особенно если вы храните в своем кошельке мало-мальски заметные суммы. Отключение смс-верификации может привести к непредсказуемым последствиям. Если же все-таки решение принято, действия следующие:
открыть меню «Настройки»;
выбрать графу «Безопасность»;
выбрать строку «Подтверждение»;
выбрать вариант «Отключить двухфакторную авторизацию по SMS»;
кликнуть на «Сохранить параметры».
SMS-подтверждения будут отключены. Теперь для входа в систему будут необходимы только логин и пароль.
Данные для входа в кошелек
Чтобы войти в Webmoney кошелек, понадобится несколько личных данных и вспомогательных средств:
логин;
пароль;
код с картинки;
телефон;
смс или E-num программа.
Логином для входа в Вебмани служит ваш номер телефона, указанный при регистрации. Он указывается в формате 7xxxxxxxxxx – без знака “+” и пробелов.
С паролем для электронных кошельков часто возникают сложности. Особенно это касается сервиса WebMoney, ведь у него крайне высокий уровень защиты и высокие требования к паролю. Чтобы войти в систему, пароль может состоять из:
заглавных букв латинского алфавита;
строчных букв латинского алфавита;
арабских цифр;
знаков верхнего регистра(!»№;%:?*).
Код с картинки всегда отображается с правой стороны. Обычно, эти числа легко читаются. Но, если вы не понимаете, что за цифры указаны на табличке, нажмите на меню «обновить картинку».
Если поставить галочку рядом с надписью «запомнить меня на этом устройстве», то система запомнит ваши данные и вам не придется постоянно вводить логин и пароль, чтобы попасть в кошелек.
Вход в Keeper Standard (Mini)
Чтобы попасть в личный кабинет Вебмани, необходимо выполнить вход в кошелек. Какой бы Keeper вы не использовали, вам потребуется оказаться на сайте www.webmoney.ru, чтобы войти в систему.
Оказавшись на сайте Webmoney, нажмите «вход» в правом верхнем углу страницы.
Если вы используете для работы версию Standard (Mini), то вы окажетесь на странице, где потребуется указать:
логин;
пароль.
Ввести код с картинки – без ошибок, и нажать «войти». После этого вы попадете в окно для подтверждения входа. Подтвердить свои действия можно двумя способами: паролем из смс и кодом в E-num. Если вы используете пароль, то просто введите код, высланный вам на телефон, и нажмите «войти».
Если вы хотите использовать для подтверждения систему E-num, то нажмите «назад» на странице подтверждения. В новом окне выберете «получить число вопрос» и введите число-ответ, который вы получите на телефон, в соответствующем поле и нажмите «войти».
После этого, система проверит ваши данные, и вы окажетесь в личном кабинете, чтобы начать работу.
Вход в Keeper WebPro (Light)
Если вы не знаете, как войти в систему Вебмани и попасть в свой кошелек через Keeper WebPro (Light), то вам понадобится следующая инструкция:
Зайдите на адрес light.webmoney.ru/v3/Login.
Введите ваш WMID.
Введите пароль.
Выберите один из вариантов авторизации: без подтверждения, смс или E-num.
Нажмите «войти».
В новом окне, отсканируйте код через программу на своем телефоне и введите число-результат в соответствующем поле.
Помните, что число-результат действует лишь несколько секунд. Если вы не успеете ввести правильное число, то вам придется снова сканировать картинку.
После того, как вы нажмете «далее», система завершит проверку данных, и вы сможете завершить вход в свой личный кабинет.
Вход через социальные сети
Для активных пользователей социальных сетей, можно попасть в кошелек Webmoney через вход в личный кабинет с использованием своего профиля. Как это сделать? Алгоритм действий выглядит так:
Зайдите в свою социальную сеть, например ВК, и введите в строке поиска «Webmoney».
Перейдите в группу Вебмани – она первая в списке поиска.
С правой стороны вы увидите приложение, через которое можно зайти в свой электронный кошелек в системе ВК.
Нажмите «запустить».
После проверки данных, вы окажетесь в своем личном кабинете. Повторное вхождение не потребует таких усилий, ведь приложение для входа в Webmoney сохранится в разделе «игры».
Вход через мобильную версию
Чтобы использовать transfer Webmoney с телефона, необходимо скачать на свой мобильный системное приложение. Для этого можно использовать интернет магазин, поддерживаемый вашей системой.
Введите в поиске WebMoney Keeper и перейдите в меню для скачивания.
После того, как приложение установится на телефон, нажмите «открыть».
Вы окажетесь в новом окне, где необходимо ввести свой номер телефона и нажать «далее».
Вы окажетесь в меню, где потребуется ввести код с картинки. Введите его и нажмите «далее».
Теперь, по номеру телефона указанного вначале регистрации, будет отправлено сообщение с кодом подтверждения.
Введите код подтверждения вручную или позвольте системе сделать это за вас. Нажмите «далее».
В новом окне выберите вариант подтверждения и продолжите вход в систему.
Дождитесь сообщения с паролем и введите код, чтобы продолжить трансфер.
Готово. Теперь вы можете использовать WMR с мобильного телефона.
Использовать мобильный кипер для входа в кошелек – удобно и практично. Особенно, если ваш телефон может работать с бесконтактными платежами.
Вход через Keeper WinPro
Данный Keeper предназначен для работы с компьютера. На практике, его используют только те пользователи Webmoney, которые постоянно и много работают с этим электронным кошельком.
Если вы относитесь к таким пользователям, то для входа в Keeper WinPro со своего компьютера, вам понадобится скачать программу. После того, как установка завершиться, нажмите на иконку запуска, чтобы войти в систему.
Для входа в систему вам понадобится:
Ввести WMID.
Ввести пароль.
Нажать «ок».
В новом окне выберите подходящий вариант и нажмите «готово».
Все, что вам останется – это указать путь для ключей, хранящихся на вашем компьютере, и вы окажетесь в личном кабинете. Компьютерная версия дает самые максимальные возможности пользователям Вебмани и рассчитана на продвинутых юзеров.
Если у вас возникли проблемы с доступом, и у вас нет файла с ключами, то обратитесь в техподдержку.
Как создать WMZ кошелек на WebMoney
WMZ кошелек предназначен для работы с титульными знаками типа Z, которые являются эквивалентом доллару США (USD). Кошелек также является одним из международных сервисов, которые могут использоваться в любой стране, где работает система Webmoney.
Кошелек WMZ доступен для всех участников системы, включая обладателей аттестатов псевдонима. Граждане РФ, наряду с кошельком WMR, могут создать один кошелек WMZ, без предъявления требований к аттестату.
Создание кошелька
После регистрации на сервисе вебмани пользователю будет присвоен уникальный идентификационный номер – WMID. Это аналог паспорта человека для входа в систему и совершения платежных или иных операций.
Сервис предлагает пользователям создавать неограниченное количество кошельков выбранного типа. При решении открыть очередное хранилище следует помнить, что созданный счет невозможно удалить. Чтобы не запутаться, в будущем рекомендуется подключать только необходимые кошельки.
Первоначально пользователю доступен WebMoney Keeper Standard. Это браузерная версия программного обеспечения. Она позволяет открывать кошельки в валюте и в рублях, имеет простой интерфейс без некоторых дополнительных функций.
Для увеличения лимитов на проводимые денежные операции необходимо получение формального аттестата. Это подразумевает подтверждение собственной личности путем отправки в Центр Аттестации скана паспорта.
После повышения уровня сертификата можно полноценно пользоваться WMZ кошельком.
Пошаговая инструкция
Для удобства пользователя разработано отдельное приложение для компьютера WM Keeper Classic, которое имеет расширенные функции. Для того чтобы зарегистрировать кошелек через программу:
Первым делом необходимо её скачать и установить. После установки в личном профиле на сайте Вебмани появляется возможность управлять версией «кипера» через ПК.
Следующим шагом станет открытие вкладки «Кошельки» на главном экране программы. С левой стороны будет находиться кнопка «создать», позволяющая открыть новый кошелек.
Далее, в выпадающем списке пользователю будет предложено выбрать титульный знак необходимой валюты. Это будет обозначать, что при выборе WMZ создается долларовый кошелек, при выборе иного вида создается соответствующее хранилище.
Завершающим шагом создания станет принятие лицензионного соглашения по правилам использования валютных сертификатов. Поставив галочку в окошко «Я принимаю», следует нажать кнопку «Далее».
Кошелек создан. Можно начинать работать.
Процедура создания WMZ счета посредством браузерных версий — аналогична. На главном экране WM Keeper Light или WM Keeper Standard необходимо выбрать пункт «Кошельки», «Создать» и кликнуть на необходимую валюту счета.
Какие операции доступны
Имея WMZ кошелек, пользователь может совершать с ним различные операции:
конвертация;
вывод средств;
пополнение.
Конвертация
Система предлагает возможность обмена валюты. Сразу следует отметить, что курс не самый выгодный. Это плата за скорость совершения операции и повышенный уровень безопасности сервиса.
Для конвертации валюты потребуется зайти в меню «Кошельки». Выбрать тот счет, средства с которого требуется конвертировать, и нажать на иконку «Перевести средства». Далее, в выпадающем меню будет предложен выбор, куда нужно переводить деньги. После нажатия на пункт «На кошелек» откроется экран с действующими курсами. Конвертация валют происходит по туристическому курсу, который значительно отличается от банковского.
Как пополнить кошелёк Вебмани
Пополнение кошелька Вебмани возможно несколькими способами: это
Пополнение с помощью wm-карты подходящего типа.
Обмен WM в любом обменном пункте (список находится на официальном сайте системы), у дилеров wmr.
Обмен наличных средств (либо безналичных) в специальном разделе биржи обмена Exchanger.
Путём обмена электронных денег других систем или обменом с другого кошелька на Exchanger или в обменных пунктах онлайн.
Для многих типов кошельков существуют и свои, специфические способы пополнения:
для WMZ – в платёжном терминале, с банковской карты, банковским переводом, предоплаченной карточкой, наличными в банке,
для WMR – с помощью WM-карт, в платёжных терминалах, в системах интернет-банкинга, наличными (вплоть до касс розничных сетей), почтовым переводом и даже с мобильного телефона,
для WMB – с помощью скретч-карт, в отделениях почты (временно не работает до перехода на другую систему расчёта), с расчётного счёта в банке.
Как узнать свой номер
Начинающие пользователи часто путают идентификатор в системе (WMID) и номер кошелька. Это не одно и то же. Идентификатор требуется для входа в систему и служит удостоверением личности пользователя.Номер кошелька – это номер счета, который необходимо указывать при осуществлении транзакции.
Узнать номер кошелька несложно. Он состоит из 12 цифр и буквы, которая означает вид хранилища. Для WMZ этой буквой будет Z.
Способы узнать номер в различных вариантах хранилища:
Webmoney Keeper WinPro (Classic). После входа в программу пользователь должен выбрать вкладку «Кошельки» и в списке имеющихся хранилищ посмотреть номер кошелька, начинающегося с буквы Z.
Webmoney Standart. Авторизировавшись на сайте, необходимо выбрать меню со стилизованным изображением кошелька. На открывшейся странице пользователь увидит не только номера кошельков, но также все последние операции.
Мобильное приложение. Чтобы узнать номер WMZ кошелька, в мобильном приложении необходимо «тапнуть» на прямоугольнике, изображающем кошелек, на котором нарисована Пентаграмма или выровненная пирамида. Подобный рисунок изображен на долларах США. Картинка увеличится на весь экран, и пользователю будет доступен номер.
Фотогалерея «Создание кошелька и работа в WebMoney»
Конвертация при помощи сервиса WebMoney
Номер кошелька в Keeper Stansard
Сервис SDP Exchanger для вывода средств
Создание кошелька с помощью Keeper Classic
Вход в WebMoney c различных клиентов и платформ
У кошелька вебмани вход в личный кабинет производится в зависимости от его версии. Владельцы кошельков mini, light, check, classic,…
Какие существуют ограничения, связанные с WMR и WMP кошельками
Вебмани устанавливает несколько видов ограничений на операции пользователей. Они распространяются сразу на все титульные знаки и валюты и зависят от нескольких факторов:
уровень пройденной идентификации (полученный аттестата);
используемый Keeper для работы (официальный сайт или стороннее приложение);
подключенные способы подтверждения операций.
Минимальными лимитами по всем операциям обладают пользователи со статусом псевдонима, использующие WM Keeper Standart (личный кабинет на официальном сайте) без указанного и подтвержденного мобильного телефона. В таком случае не разрешается вообще тратить деньги из кошелька, можно только пополнять его. Для снятия данного ограничения потребуется подтвердить свой номер телефона.
Поскольку большинство пользователей работает с системой через сайт либо мобильное приложение, а не через стороннюю программу на компьютере, приведем лимиты для WM Keeper Standart без подключенного WM Keeper WinPro или WM Keeper WebPro, но с подтвержденным номером телефона:
Независимо от уровня пройденной верификации и полученного аттестата, с WMR кошелька можно тратить не более 15 000 руб. в месяц. Для WMP лимит существенно больше — 60 000 руб.
Однако необходимо учитывать, что WMID с аттестатом псевдонима не могут открывать WMP кошельки. Буква «Н», используемая в таблице, означает отсутствие лимитов на совершение операций.
Операции по WebMoney WMR и WMP облагаются стандартной комиссией системы за совершение любых операций — 0,8 %, но не менее чем 0,1 WM. Исключение — перевод между своими однотипными кошельками, привязанными к одному WMID. Максимальный размер комиссии также одинаковый — 1500 WMR и WMP соответственно.
WMP может использоваться для выполнения любых операций в системе, в то время как WMR существенно ограничен в этом. Также некоторые магазины перестали принимать к оплате WMR, и расплатиться данной валютой в них невозможно.
Совокупность перечисленных обстоятельств делает использование WMR счета для большинства пользователей системы нецелесообразным.
Таким образом, WMR и WMP кошельки предназначены для хранения титульных знаков, выступающих в качестве эквивалента российского рубля. В 2020 г. основным является именно WMP счет, в то время как WMR практически не используется и предназначен в основном для нерезидентов РФ. На старые рублевые кошельки системой наложено множество ограничений по выводу, переводу, а также по доступным лимитам, что делает их использование нецелесообразным.
Вывод Webmoney на «Яндекс.Деньги» и бесплатное снятие в банкоматах
Оформите бесплатную карту по нашей ссылке (создайте новый аккаунт, закажите и активируйте карту) и получите от «Яндекса» подарок: 100 бонусных рублей. Выпуск карты сейчас стоит всего 199 рублей. И это конечная стоимость: больше никаких поборов за обслуживание в течение 5 лет действия карты!
«Яндекс.Деньги» полностью обнулили комиссию за снятие денег в банкоматах по своим именным картам «Яндекс.Деньги Mastercard». В календарный месяц можно снимать в любом банкомате наличные до 10 000 рублей. Минимальная сумма операции, как и количество подходов не ограничены. Важный момент: ваш «Яндекс.Кошелёк» должен быть полностью идентифицирован (по третьей колонке).
Всё, что превышает 10 000 рублей, будет идти со стандартной комиссией снятия денег с пластиковых карт «Яндекс.Деньги» — 3%, минимум 100 рублей. Максимальная сумма одного снятия по полностью верифицированным картам — 100 000 рублей в день и 1 300 000 рублей в месяц.
Карта «Яндекс.Денег» бесплатно обслуживается в течение всего срока своей жизни. Вы платите только за доставку в любую страну именной карты всего 199 рублей. Это единственная плата. Далее карта будет бесплатной всегда.
Яндекс.Деньги» также появился кэшбэк: выплачивается бонусными рублями (1 рубль = 1 бонусный рубль). Кэшбэк мгновенный. Каждый месяц сервис определяет категории повышенного кэшбэка, за которые вы получаете 5% от суммы покупки баллами + 5% за каждый пятый чек в других категориях или 1% на все покупки в небонусных категориях, в том числе и в Интернете. Накопленные баллы можно обменять у партнёров, которые принимают к оплате Яндекс.Деньги, а таких много. Например, их можно потратить в магазинах, которые принимают к оплате «Яндекс Деньги». Например, тот же магазин «Озон«.
Сама схема перевода WMR на «Яндекс.Кошелёк» очень простая: находим на BestChange лучший обменник с Webmoney на «Яндекс.Деньги», меняем (получаем деньги на «Яндекс.Кошелёк»), а дальше просто идём в любой банкомат с картой «Яндекс Денег» и снимаем наличными без комиссии.
Кстати, если у вас ещё нет «Яндекс.Кошелька» и их пластиковой карты, то по нашей ссылке его можно создать даже с выгодой для вас. Просто перейдите по ссылке, зарегистрируйтесь (создайте новый аккаунт в «Яндексе»), закажите, а потом активируйте бесплатную пластиковую карту «Яндекс.Деньги», и получите за это 100 бонусных рублей от Yandex. Потратить эти деньги можно в любой точке, где принимаются к оплате Яндекс Деньги. Например, на Озон. Мелочь, а приятно, можно потом потратить их на будущие покупки Сама карта полностью бесплатная в обслуживании и выдаётся на 3 года.
Кроме того, обменники позволяют получить ряд возможностей, не предусмотренных даже при стандартных методах обналички. Например, вывод на иностранные кошельки и платёжные карты.
Как перевести с Вебмани на Киви
Для перевода средств на Qiwi-кошелёк вам придётся пройти процедуру взаимной привязки счетов в Вебмани и в системе Киви. Код для привязки высылается вначале системой Вебмани. Пройдите все шаги по инструкции.
После этого вы получите
Оповещение в панели Qiwi-кошелька: откроются пункты взаимного перевода средств.
Пункт меню в Qiwi-кошельке, где вы сможете в любой момент деактивировать привязку на время.
В WM Keeper – строчку со счётом в Qiwi-кошельке, который привязан к WM-кошельку, где баланс будет указываться с учетом имеющегося лимита на списание.
Привязка позволит легко переводить WebMoney на ваш Qiwi-кошелёк – напрямую либо с помощью сервисов онлайн-обмена валют.
Как перевести деньги на кошелек Вебмани
Перевод средств на известный вам wm-идентификатор (wmid) невозможен. Перевести деньги можно только зная конкретный номер кошелька. Кроме того, с помощью внутреннего функционала системы можно не только перевести деньги, но и выставить счёт – поэтому если вы хотите не ошибиться при переводе средств, попросите вашего получателя средств оформить перевод таким образом. Выставленный счёт – гарантия того, что вы точно отправите средства!
Деньги переводятся одним из способов – непосредственно либо с кодом протекции, гарантирующим, что только вы и получатель будете задействованы в конкретном переводе. Код выставляется на любой срок от 1 до 365 дней, а по истечении этого периода, если правильный код не введён, средства возвращаются отправителю.
Это интересно: при желании вы сможете сколько угодно раз сменить автоматически генерируемый код перед переводом денег – это удобно, если вы хотите найти необычную, но легко запоминаемую комбинацию.
Вывод «Вебмани» через «Мегафон»
(наиболее экономная и безопасная схема для «карманных расходов»)
Пополнение счёта мобильного телефона с Webmoney с последующим выводом денег с него. Подходит этот вариант для лиц с формальным аттестатом и выше и для небольших сумм (до 15 000 рублей в месяц). Однако деньги на всех этапах принадлежат вам. Сегодня это самый дешёвый вариант вывода WMR. И вообще единственный «официальный». К тому же он автоматический. Деньги уже на счёте вашей карты в течение 5 минут после совершения транзакции. Без посредников в виде бирж или обменных пунктов.
Банковская карта «Мегафон Мастеркард»: особенности
Платёжная карта Мегафона может стать эффективным инструментом по выводу WMR, вы можете прямо сейчас открыть бесплатно виртуальную карту на сайте, с виртуальной карты можно снимать деньги в банкоматах с NFC и платить в любых магазинах при помощи Google Pay / Apple Pay
Особой популярностью для обналички Webmoney стала пользоваться виртуальная карта MasterCard Standard моментальной выдачи от «Мегафона«.
Её фишка в том, что она привязана напрямую к счёту телефона (для абонентов «Мегафона») и оформить её могут даже иностранцы, купив предварительно сим-карту (не граждане РФ). То есть те деньги, что есть на мобильном счёте, можно использовать для привычной оплаты товаров и услуг в магазинах и Интернете. Сегодня это единственный такой на рынке продукт. Прикольно, не правда ли?
Карта выдаётся на три года. Эмитентом её является ООО «Банк Раунд», однако личный кабинет работает под вывеской «Мегафон Банк»
Вы можете выпустить виртуальную карту «Мегафон», и это тоже будет бесплатно. А по симке можно выбрать тариф, где нет абонентской платы. Виртуалку можно легко привязать к Google Pay / Apple Pay и пользоваться ей вместо пластиковой при покупках в любых магазинах или снимая деньги в банкоматах. Выпуск виртуальной карты моментальный. Это самая обычная карта платёжной системы Mastercard, но только без физического носителя.
С такой виртуальной карты тоже можно снимать деньги в банкоматах. Вам нужно просто найти банкомат, который поддерживает считывание по NFC. Например, это все банкоматы «Тинькофф Банка», многие банкоматы «Сбербанка».
Карта может обслуживаться бесплатно при выполнении условий.Стоимость обслуживания карты: на тарифе «Лайт» (49 рублей в месяц или бесплатно при тратах от 3000 рублей), «Стандарт» (149 рублей в месяц или бесплатно при тратах от 10000 рублей) и «Максимум» (199 рублей в месяц или бесплатно при тратах от 30000 рублей в месяц).
На ежедневный остаток по счёту телефона свыше 500 рублей начисляется процент на остаток: 6% годовых на тарифе «Лайт», 8% годовых на «Стандарт» и 10% на «Максимум».
Кэшбэк по картам «Мегафона»
Если вы абонент «Мегафона», то прямо сейчас можете бесплатно получить себе виртуальную карту на сайте оператора, привязать её к Google Pay / Samsung Pay / Apple Pay и использовать как обычную карту, получая кэшбэк деньгами 1/1,5% за все покупки и повышенный в категориях, по акциям + мегабайтами на связь и процент на остаток до 10% годовых.
По платёжной карте «Мегафона» полагается даже кэшбэк за покупки в магазинах в виде мегабайтов на мобильный Интернет. Они идут пакетами по 10 МБ за каждые потраченные 100 рублей. Если покупка меньше 100 рублей, то кэшбека не будет, а если, к примеру, 189 рублей, то получите только 10 мегабайт. Вот такое округление, зато мегабайты можно тратить в течение года. Мелочь, а приятно!
Есть также и кэшбэк деньгами на тарифах «Стандарт» и «Максимум«: 1% на все покупки и 1,5% от суммы всех покупок соответственно. За покупки по этим MCC-кодам кэшбэк от «Мегафона» не начисляется: 4813, 4814, 6012, 6532, 6533, 8999.
Пополнить карту просто: достаточно лишь оплатить номер телефона, к которому привязана карта. Комиссия за операцию будет всего 0,8% (стандартный сбор Webmoney).
ЛИМИТЫ ПО КОШЕЛЬКУ WEBMONEY:
есть серьёзное ограничение Telepay на пополнение телефона (не более 15 000 рублей в месяц);
обязателен минимум формальный аттестат (псевдоним не подойдёт ни под каким соусом).
ЛИМИТЫ ПО КАРТЕ «МЕГАФОНА»:
100 000 рублей в сутки (300 000 в месяц) суммарно на пополнение, снятие в банкоматах и переводы (на покупки 600 000 в месяц) — для граждан РФ, можно открыть до 5 карт на один номер телефона и с общим лимитом;
лимит для граждан других стран 60 000 в сутки и 100 000 рублей в месяц;
обналичивание баланса телефона картой в любых банкоматах РФ до 10 000 рублей в месяц бесплатно (но для этого нужно совершить покупки по данной карте на общую сумму от 3 000 рублей в месяц), далее — 2,5% от суммы операции, 3,5% для сумм до 100 000 рублей и 4% на всё, что свыше. Соответственно, вывод средств по комиссиям суммарно выходит от 0,8% до 4,8% в зависимости от суммы;
перевод на другие карты (по MoneySend) — 1,99%. Например, вытягиванием на «Кукурузу», «Билайн Mastercard», «Тинькофф Блэк» и другие, поддерживающие C2C. Суммарно (включая изначальную комиссию Webmoney): 1,99% + 0,8% = 2,79%;
если будете пополнять электронные кошелька (например, «Яндекс.Деньги» или Qiwi), то карта «Мегафона» сдерёт 8% от суммы операции;
ещё одна прикольная фишка: бесплатные переводы «Мегафон — МТС» и обратно. Для этого нужно, либо зайти в личный кабинет «Мегафон.Банка». Может, кому и пригодится такая фишка.
Лимиты: в сутки 30 000 рублей и в месяц не более 40 000. Минимальная сумма платежа — 10 рублей.
покупки по карте без комиссии, покупки в иностранной валюте по курсу конвертации (ЦБ РФ + 3%).
По сути, вы можете пополнять с Webmoney номер телефона оператора «Мегафон» со стандартной комиссией 0,8%, выпустить себе платёжную карту к номеру телефона без комиссии и пользоваться ей бесплатно в течение всего срока действия: покупать товары, снимать деньги, переводить их на другие карты.
Будьте осторожны: не увлекайтесь обналичкой по данной карте. Банку не нравится, когда эту карту используют только для снятия наличности. Используйте карту полноценно: совершайте покупки и снимайте наличность без фанатизма, и тогда всё будет хорошо
для некрупных покупок в Интернете и магазинах (лимит на одну операцию 15 000 рублей в день и 40 000 рублей в месяц)
Оформить карту можно на сайте Webmoney Cards: https://cards.web.money/
В компании «Вебмани», видимо, решили восстановить выпуск виртуальных карт для тех, кто имеет кошелёк в этой системе. После того, как с проверкой в ККБ нагрянул сам ЦБ РФ, эту карту, как и многие другие банка выдавать перестали, но теперь всё потихоньку возвращается на круги своя. И вот перед нами старая добрая виртуалочка от Webmoney, местами улучшенная, местами ухудшенная.
Комиссия за выпуск карты 50 рублей, обслуживание бесплатное. Сама карта выдаётся на 1 год. По смс присылаются реквизиты карты, туда же приходят смс с подтверждениями операций при покупках онлайн (наконец-то реализован механизм 3D Secure, в старом такого не было).
Получить карту может любое физическое лицо РФ с гражданством этой страны. Карта Webmoney доступна для оформления лицам с формальным аттестатом и выше.
ВАЖНОЕ ОБНОВЛЕНИЕ:
пополнить виртуальную карту Webmoney вы можете только с кошелька WMP.
Лимиты виртуальной карты Webmoney:
максимальный лимит одной операции (покупка, пополнение) — 15 000 рублей;
дневной лимит тоже 15 000 рублей;
месячный лимит на операции — 40 000 рублей;
на один кошелёк можно выпустить до 5 таких карт.
Пополнить карту «Вебмани» можно напрямую с кошелька. Комиссия — 1% от суммы платежа. Вернуть деньги с карты обратно в кошелёк можно без комиссии. Карта поддерживает оплату через системы Google Pay и Apple Pay (то есть можно использовать как физическую для оплаты товаров и услуг в обычных магазинах), но по карте не генерируется PIN-код, а это значит, что операции от 1000 рублей в обычных магазинах могут и не пройти (проверьте в магазине, так ли это).
Исходя из лимитов, максимальная сумма покупки по этой виртуальной карте Webmoney ограничена суммой 15 000 рублей. Естественно, никакого кэшбэка за покупки здесь нет И да, карта не поддерживает C2C (то есть с этой карты нельзя стянуть деньги на другую карту!). Мы пробовали — не получилось. Может быть, получится у вас? Напишите о результате в отзывах к статье
Webmoney и криптовалюта в 2020 году
Спрос на криптовалюту значительно увеличился. Систему Webmoney можно вполне эффективно использовать для спекуляций на цене криптовалют (напомним, в системе существует специальный кошелёк WMX, привязанный к стоимости биткоин). WMX можно купить с любого доступного кошелька Webmoney (WMZ, WMR и других) как внутри системе, так и на внутренней бирже wmx.wmtransfer.com (наиболее выгодный вариант) между участниками системы. Отдельно отметим, что 1 BTC равен 1000 WMX. Именно по такой схеме и нужно считать, когда вы будете осуществлять сделки. Если что, то сама биржа вам подскажет, не ошибётесь.
Основные плюсы WMX: моментальные транзакции и комиссия всего 0,8% (то есть стандартная от Webmoney).
Ввод крипты в Webmoney
В Криптонаторе можно хранить много криптовалют. Ключ доступа хранится у вас.
Помимо чисто спекулятивных целей вы можете в Webmoney вводить и выводить криптовалюту извне. Если хотим добавить биткоин в «Вебмани», то, опять же, идём на wmx.wmtransfer.com и кликаем «Ввести Bitcoin«. На следующей странице получаем адрес (публичный ключ), на который будем пересылать деньги из нашего криптокошелька (например, «Криптонатора» — в нём можно хранить сразу много криптовалют и менять их между собой при надобности, есть удобное мобильное приложение, кошелёк русскоязычный).
Во избежание недоразумений рекомендуем отправлять суммы кратные 0.00001 BTC (0.01 WMX). Деньги появляются на счёте WMX после 6 подтверждений.
Вывод из Webmoney в крипту
Если нужно вывести деньги с Webmoney в криптовалюту, то там же кликаем «Вывести Bitcoin» и далее делаем обратную процедуру: указываем в адресе для получения публичный ключ биржи или кошелька и отправляем наши WMX, которые будут автоматически сконвертированы в Биткоин и отправлены в нужном направлении (подтверждение операции обычно происходит в течение суток).
Каждый раз выбирайте нужное вам действие на странице wmx.wmtransfer.com или на wmh.wmtransfer.com
Поддерживается ли Bitcoin Cash и Litecoin в «Вебмани»?
Да, с осени 2017 года вы можете вводить и выводить свои средства не только сам Bitcoin, но и в его младшего коллегу Bitcoin Cash, а с декабря 2017 года — и Litecoin. В ряде случаев это бывает оправданно, т. к. и операции быстрее проходят и банально стоимость транзакции ниже.
Для хранения Bitcoin Cash в системе был создан специальный кошелёк WMH, а для Litecoin — WML. Аналогичное соотношение: 1 BCH равен 1000 WMH и 1 LTC = 1000 WML.
Собственно, те же манипуляции с покупкой и продажей BCH и LTC можно провести на сайте https://wmh.wmtransfer.com/ и https://wml.wmtransfer.com/ Включая торговлю на этих биржах, так и внешний ввод и вывод средств на криптокошельки.
Что делать с аттестатом псевдонима?
Например, купить билет на поезд, товар в магазине и забронировать отель за Webmoney
Альтернативный способ вывода с Webmoney — купить за «Вебмани» билет на самолёт, поезд или номер в отеле! Часто это востребовано даже несмотря на возможные наценки сервисов!
Почему бы и нет? Хороший вариант с учётом того, что официальный сайт РЖД не принимает к оплате «Вебмани» и уж тем более так не делает популярный сервис Booking.com при варианте с отелями.
Webmoney можно потратить также в таких крупных магазинах, как Aliexpress или Wildberries. А также вывести на телефон (правда, очень мизерные лимиты).
И даже вернуть часть средств от покупки (кэшбэк)!
С 2017 года запущена бонусная система Webmoney Bonus, которая позволяет вернуть часть средств от покупки и тем самым нивелировать величину комиссии 0,8%. По сути, это кэшбэк-сервис, но от системы «Вебмани» (что такое кэшбэк-сервис?). Деньги выплачиваются на кошелёк Webmoney. Например, по «Алиэкспресс» ставка у них 6%.
В поездку за Webmoney
Купить билет и забронировать проживание в отеле можно прямо на официальном сервисе Webmoney Travel. Либо обратиться к сторонним компаниям: Aviasales, Tutu.ru и Pososhok.ru (здесь, правда, только поездка и авиабилеты). Уверены — найти приемлемое предложение в этом разнообразии возможно. Сравнивайте цены на обозначенных сайтах и покупайте там, где удобно и выгодно. Не нужно тратиться на вывод средств с кошелька, ведь билет можно получить, просто оплатив билет или проживание в отеле / хостеле за Webmoney
Можно попробовать также оплатить другие товары или услуги, где можно произвести оплату за Webmoney. Например, некоторых провайдеров услуг Интернета. Если вы работаете в ИТ сфере, то найти способ сбыть свои WMR и WMZ значительно проще — больше предложений!
Выводить деньги стало дороже. Но, увы, в текущей ситуации выбирать фактически не из чего. Надеемся на лучшее, но готовимся к худшему! Универсальная рекомендация — не держите деньги в кошельке, выводите как можно скорее. Пока это ещё возможно!
Сравнение систем электронных денег: WebMoney и Яндекс.Деньги
На рынке в РФ действует несколько электронных платежных систем. Самые распространенные — QIWI, WebMoney и Яндекс.Деньги. В последнее время хорошие…
О мошенничестве в WebMoney
Пожалуй, WebMoney – один из самых безопасных кошельков. Но, и с ним следует работать осторожно, ведь виртуальный мошенник не дремлет. Первый, и самый распространенный вариант мошенничества – это фишинг, целью которого является получение доступа к вашим личным данным. Чтобы этого избежать:
Никогда не скачивайте программы Вебмани с посторонних сервисов.
Нигде не вводите данные от своего личного кабинета, кроме официального сайта.
Внимательно следите за ссылками в сообщениях, перекидывающих вас на сайт WebMoney – это распространенный способ мошенничества.
Никуда не высылайте ваши пароли, даже если того просит система – это не безопасно.
Второй вариант мошенничества в системе – это выманивание самих денег, а не только личных данных. Это может быть недобросовестный работодатель, который просит вас завести кошелек, а потом прислать ему личные данные для оплаты.
Могут встречаться и обычные мошенники, требующие перевести деньги, за какую-то услугу или в качестве залога. Но, такие люди работают и на других кошельках, а не только на Webmoney.