ePayments – что это такое и как с этим работать.
ePayments – как оформить
Чтобы завести электронный epayments кошелек, необходимо пройти регистрацию на epayments.com . Выбрав оптимальную языковую версию сайта, переходим к созданию личного аккаунта в системе.
- На главной странице нажимаем Открыть счет;

- Указываем, какой епейментс аккаунт хотим открыть: частный или бизнес → Продолжить;

- Открывается форма регистрации для внесения персональных данных: имя, фамилия, дата рождения, страна проживания, электронная почта, пароль. Можно также зарегистрироваться через Telegram канал;
- Принимаем правила работы сервиса, по желанию подписываемся на email-рассылку платформы и жмем Регистрация;

- Для подтверждения регистрации вводим код, который система отправили на указанный email, или просто активируем ссылку из письма;
- Регистрация аккаунта завершена, можно осуществлять вход в личный кабинет.



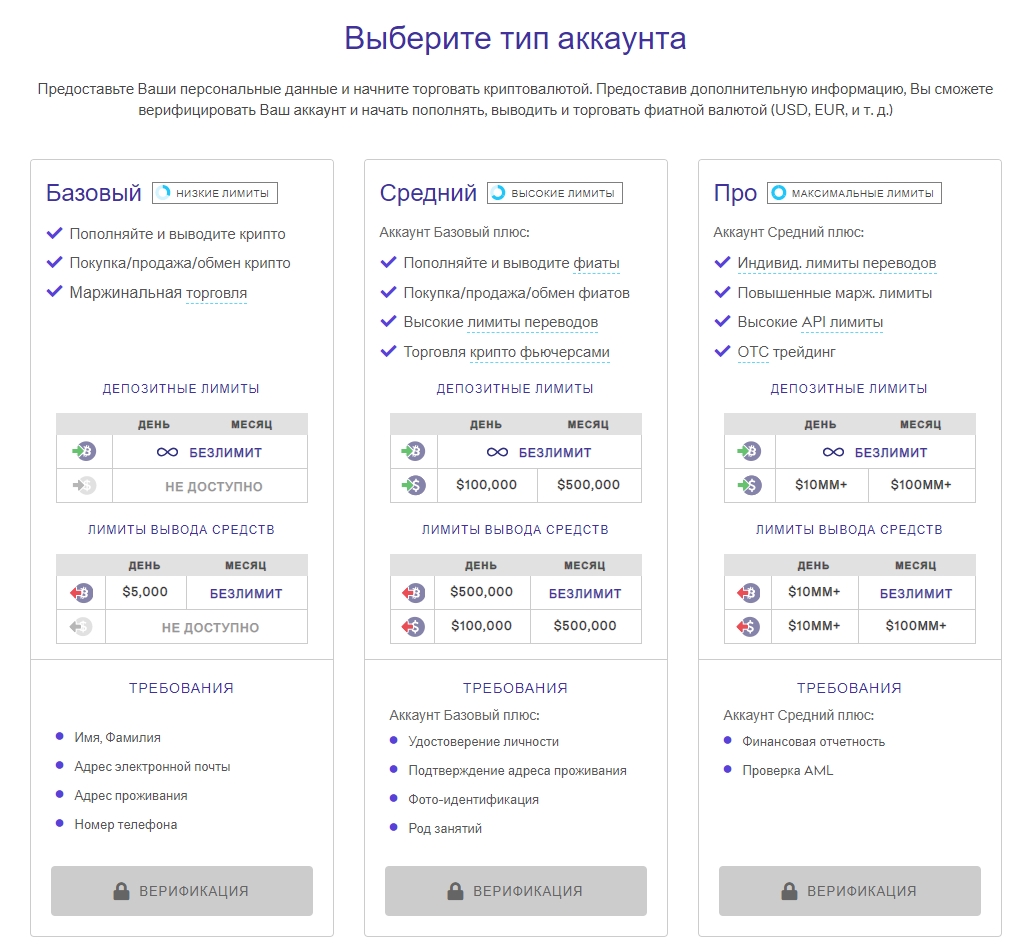
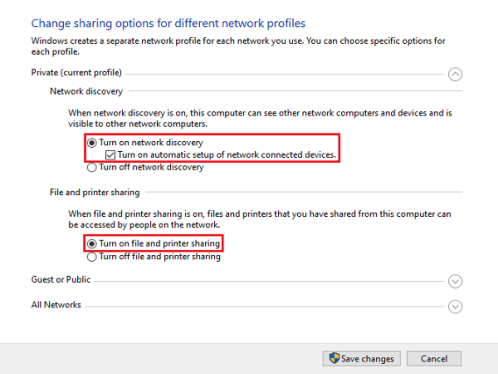
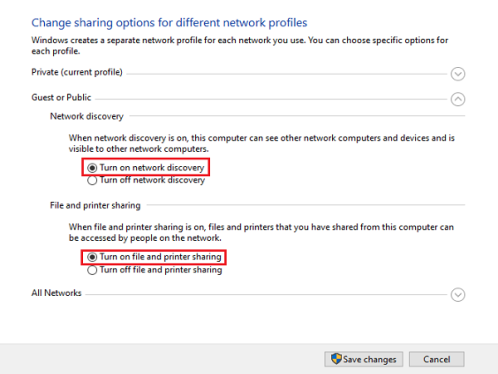
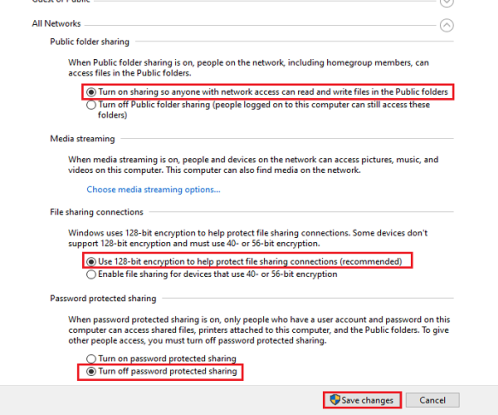
После регистрации каждому аккаунту предоставляется частичный доступ к финансовым операциям. В личном кабинете на сайте можно создать rub, usd или eur кошелек, переводить и получать средства, ознакомиться с лимитами и тарифами, посмотреть сводную статистику, а также обратиться в службу поддержки.
На ePayments есть Справочный центр, где содержится подробная информация о работе системы: как верифицировать свой аккаунт, как зайти в личный кабинет, как узнать лимиты кошелька и платежный пароль, бизнес аккаунт – что это такое и как им пользоваться и другие ответы на популярные вопросы.
Для повышения лимитов и получения доступа к полному функционалу платформы необходимо пройти верификацию аккаунта.
Настройка безопасности ePayments
После входа в личный кабинет система сразу предлагает верифицировать аккаунт, что позволит работать с неограниченными лимитами. Для этого на главной странице личного кабинета жмем Верифицировать аккаунт.

Три этапа epayments верификации:
- подтверждение email и номера телефона;
- подтверждение личности;
- подтверждение адреса.
Подтверждение e-mail и номера телефона
Поскольку адрес электронной почты и номер телефона были указаны при регистрации аккаунта, то данный этап отображается как выполненный.

Зарегистрироваться в Epayments
Подтверждение личности
Указываем гражданство и в зависимости от выбранной страны отобразятся документы, которые подойдут для подтверждения данных. Для России – общегражданский паспорт, заграничный паспорт или водительское удостоверение.

Указываем номер документа, дату окончания действия документа и загружаем его в систему.
Документ должен подтверждать личные данные, которые мы вводили при создании аккаунта. На этапе верификации их нельзя редактировать, но при необходимости можно направить запрос в службу поддержки.

Подтверждение адреса
Указываем адрес проживания и загружаем подтверждающие документы. Для каждого типа документов отображаются пример и требования. Жители Российской Федерации указывают адрес кириллицей, все остальные – латиницей.

Жмем Отправить заявку. Система принимает заявку, результаты проверки будут известны не позднее, чем через 5 дней.

В случае одобрения заявки статус аккаунта поменяется на Верифицирован, и пользователь получает полный доступ к функционалу сервиса.
Верифицировать аккаунт на epayments.com можно также через Telegram.
Помимо прочего, каждый пользователь может скачать приложение для Android или iOS , чтобы пользоваться ePayments когда и где угодно. В мобильной версии доступны все функции веб-интерфейса. Клиенты платежной системы довольны приложением и подтверждают это положительными оценками и отзывами.
Проблемы у ePayments: блокировка счетов клиентов
Сейчас наблюдается небольшая паника в отношении ePayments у её клиентов, вызванная тем, что некоторые из партнёрских программ отказались делать выплаты на ePayments без объяснения причин.На официальном сайте появился такой текст уведомления (перевод на русский язык):
«11 февраля 2020 года ePayment Systems Limited (ePayments) договорилась с Управлением по финансовому поведению (FCA) приостановить все финансовые операции на счетах своих клиентов. Это решение было принято после пересмотра FCA систем и средств контроля за отмыванием денег ePayments, которые выявили недостатки, требующие исправления. Мы знаем, что нашим клиентам очень не понравится эта новость. Мы приносим свои извинения за любые причиненные неудобства и сейчас взаимодействуем с FCA, чтобы обеспечить решение текущих проблем и в скорейшем времени разблокировать учетные записи клиентов ePayments. В рамках этого процесса мы уведомляем клиентов, что их деньги будут надёжно защищены как и раньше«.
На текущий момент все платежи с ePayments не проводятся. Биржа DSX тоже отказывается выводить средства в «Епейментс». Как долго продлится временная блокировка пока неизвестно. Судя по информации, что имеем на сегодня, ePayments не прекратит работу в России или где-либо ещё, ограничения временные. Лицензия не отобрана!
Предписания от FCA представители компании ePayments получили и сейчас работают над устранениями нарушений в рамках финансового оздоровления компании (усиления направления комплаенс компании). На их устранение, по некоторым данным, может потребоваться до двух недель.
Альтернативы ePayments
Вполне резонный вопрос в сложившихся ситуациях. Если вам деньги нужны сейчас или организовать процесс выплат, то рекомендуем посмотреть в сторону следующих платёжных систем:
- Payoneer (карты не присылают карты в Россию, но деньги со счёта (доллары и евро) можно выводить в банк),
- AdvCash (выдают карты, номинированные в рублях, бесплатный кошелёк, вывод денег на многие источники, поддержка крипты),
- Skrill (карты не присылают, но бесплатный кошелёк и множество возможностей ввода и вывода денег, есть поддержка крипты).
Почему ePayments востребована в России, Украине и других странах СНГ?
Характерная особенность системы — это возможность использовать ePayments как обычный электронный кошелёк, на который можно получать выплаты от сторонних лиц (в том числе и бесплатно, если транзакция осуществляется внутри системы). Кроме этого, доступно пополнение кошелька с банковских карт, а также предоплаченной карты «Епейментс» при помощи российской платёжной системы Webmoney, с которой заключено партнёрское соглашение. Аналогично и с выводом денежек из кошелька (при этом при зачислении на карту ePayments Prepaid Card комиссия не взимается!).

Логотип системы ePayments Card.
Создатели системы утверждают, что у обладателя личного счёта не возникнет проблем с выводом денег из любой зарубежной партнёрской программы. Для удобства взаиморасчётов есть возможность принимать платежи напрямую (передачей идентификатора ePID) или же банковским переводом. Реквизиты счёта можно найти в личном кабинете. Таким образом, перед нами реальный конкурент карты от Payoneer.
Все транзакции можно контролировать при помощи одноимённого приложения, которое можно скачать как с Google Play, так и Apple AppStore. Безопасность системы также на высоте: служба поддержки работает круглосуточно, в том числе и на русском языке.
Сегодня ePayments предоставила не просто систему получения вознаграждений за труд фрилансеров. Это ещё и удобный способ пополнения баланса на различных зарубежных сайтах (к примеру, на брокерском счёте, партнёрских программах и так далее). Лимиты станут не ограничены после того, как вы пройдёте процедуру верификации аккаунта (то есть предоставите свои данные: фотографии паспорта, заполните анкету, а также информацию о вашем месте жительства). В противном случае вы сможете получить и вывести не более 2500$ в год!

23 мая 2020 года системе ePayments исполнится 10 лет.
Поскольку ассоциация EPA работает в британской юрисдикции, то можно быть уверенным в том, что сохранность ваших средств обеспечивается надёжным государственным контролем со стороны Соединённого Королевства. А это означает, что все деньги на счетах подпадают под программу обязательного страхования.
Это очень важно при взаимодействии в режиме онлайн между контрагентами, которые могут находиться физически друг от друга на огромных расстояниях.

Сегодня это один из самых простых способов быстро и недорого получить денежные средства от иностранных компаний, на которые вы работаете. Для этого целесообразно заказать пластиковую предоплаченную карту ePayments Prepaid Card, которой впоследствии можно расплачиваться в торговых точках и выгодно снимать наличность в банкоматах, выдающих валюту (доллары США или Евро).
В чём главные отличия от Payoneer?
- Наличие бесплатного электронного кошелька ePID с беспроцентными переводами между пользователями внутри ePayments
(в Пионере очень ограничены возможности для «бескарточных» операций (только вывод средств в банк РФ), бесплатных переводов между пользователями внутри системы нет). - Доступны сразу несколько валют: USD (доллары США), EUR (Евро) и с марта 2016 года RUR (Рубли РФ).
- Значимое нововведение: в 2018 году стало возможно получать платежи в евро по банковским реквизитам на своё время. Но пока есть ограничение: деньги можно получить только в евро и только от резидентов (частных лиц или компаний) Евросоюза! То есть если нужно получить деньги не из ЕС банковским платежом, то используем реквизиты консолидированного счёта ePayments.
- С электронного кошелька ePayments можно выводить деньги через обменники. На Payoneer такое невозможно.
Например, находить выгодные варианты через сервис BestChange и менять через третьих лиц. - Бесплатные переводы на крипту и пополнения кошелька с них, а также между пользователями ePayments. Подробнее читайте ниже.
- Есть собственная криптовалютная биржа DSX (у биржи есть британская лицензия): примечательно, что ввод и вывод с кошелька ePayments на биржу и обратно (USD / EUR) без комиссии; у биржи есть русский интерфейс + русскоязычная служба поддержки.
- Полноценное бесплатное смс-информирование по карте (можно смело совершать покупки, где требуется 3D Secure и получать уведомление о покупке); В Payoneer нет 3D Secure.
- Бесплатные покупки по карте безналичным способом (% только за конвертацию USD/EUR в рубли), в Payoneer за обычные покупки в магазине и Интернете сдерут до 3,5%.
- Вывод на счёт в банке РФ выгоднее в Payoneer (он идёт по межбанковским реквизитам РФ в рублях; комиссия 2% + ещё примерно 2% за конвертацию валют).
В ePayments можно вывести деньги в банк РФ только по SWIFT (комиссия 0.5%, минимально $ 15 / евро или 900 рублей). От 100 до 100 000 долларов. Деньги приходят из Rietumu Bankа (Латвия).
Приятная новость: снижены комиссии за банковские переводы с кошелька ePayments. SWIFT в долларах, евро и рублях: 0,5% (но не менее 15 долларов/евро или 900 рублей);
Ну и не очень приятная: к сожалению, временно переводы в долларах пока не возможны (на пополнение и на вывод средств) по SWIFT. - ePayments поддерживает прямой вывод на карту по номеру карты российского банка (по Moneysend) в рублях, Payoneer — нет.
- Деньги с рублёвого кошелька ePayments можно вывести напрямую на счёт в «Яндекс.Деньгах» и на Qiwi (верифицированный) и Webmoney (на любой кошелёк, больше не нужна привязка к пластиковой карте ePayments, обратите внимание: это касается только вывода денежных средств, ввод с «Вебмани» до сих пор возможен только на карту ePayments);
(2% комиссия вне зависимости от суммы, минимально 1 рубль, максимально 60 000 рублей за операцию (и их не более 5 в сутки!), в день 300 000 рублей, в месяц 600 000 рублей). - Снимать деньги с карты ePayments в банкоматах дешевле, чем в Payoneer. Комиссия: 2,6$ (если снимаете в рублях, то ещё 2,6% за конвертацию валюты). Нет комиссии за трансграничные операции.
В Payoneer: 3,5$ + 1,8% за трансграничную операцию (если снимаете в рублях, то ещё за конвертацию дополнительно примерно 2%). - Дешёвый выпуск карты: всего 5,95$ или 4,95 евро и бесплатные первые 2 месяца обслуживания ($29.95 в «Пионере» за год обслуживания). К сожалению, пока их платёжная карта ePayments пока не выпускается новым клиентам, старые обслуживаются как и прежде. Администрация ePayments не сообщает сроки возобновления выпуска карт.
В Payoneer также за счёт реферальной программы можно тоже сделать практически бесплатный первый год обслуживания, при этом выпуск карты бесплатный, включая доставку. - Официальная поддержка системы «Вебмани» (ввод денежных средств на предоплаченную карту Epayments, а вывод денежных средств на любые кошельки без привязки к банковской карте ePayments).
ePayments и налоги в РФ
Ещё одно ключевое преимущество — это отсутствие необходимости отчитываться перед государством о счёте, открытом за рубежом. По сути, вы владеете только картой, которую можно использовать для платежей и обналички, и электронным кошельком, а банковского счёта у вас нет.
Компания ePayments (в народе именуемая «Епейментс») не является налоговым агентом, а потому не предоставляет информацию о ваших доходах (в том числе и в Великобританию)! Владелец счёта обязан самостоятельно уплачивать налоги по своим доходам в установленный срок.
Компания функционирует на основании Data Protection Act 1998, в основе которого лежит неразглашение персональных данных своих клиентов без специального запроса государственных органов Великобритании. Он может быть только в рамках в британской юрисдикции, однако его не так просто получить, и компания фильтрует их (например, если они были поданы с нарушением формальных требований).
Комиссии, сборы и ограничения ePayments
Согласно условиям договора ePayments, каждому пользователю рекомендуется пройти верификацию, т. е. подтвердить свою личность. Результатом этого процесса будет отсутствие лимитов по количеству и сумме денежных средств при покупке товаров и услуги в Интернете и обычных торговых точках.

Так выглядит новая карта ePayments. Произошла смена дизайна. Система получила статус принципального члена Mastercard, а это означает, что им больше не нужен посредник при выпуске карт.
Рекомендуем сразу же после открытия счёта верифицировать аккаунт, в противном случае вам будет недоступна большая часть операций в системе и существенно заниженные лимиты. Это достаточно быстрая процедура: необходимо лишь предоставить сканы ваших документов и заполнить анкету пользователя.
Для верификации адреса проживания можно предоставить выписку с банковского счёта (принимаются в том числе и PDF-выписки). Для верификации личности можно предоставить заграничный паспорт или водительские права. На ваш выбор
Верификация аккаунта занимает обычно 4 рабочих дня. Например, после верификации аккаунта, вы будете иметь возможность снимать по 3 000$ (2 333€) в день. Исходя из текущей политической ситуации, карта не доступна для получения жителям Крыма и города Севастополь. Новые клиенты (клиенты из РФ) пока тоже заказать её не могут. Доступен только перевыпуск уже имеющихся карт. Использование этой карты на территории полуострова запрещено.
Карта ePayments, тарифы 2020 года:
С 2017 года обслуживание карты ePayments стало немного более выгодным, благодаря новым тарифам. Если вкратце, отменили единовременный сбор за годовое обслуживание. Была снижена стоимость изготовления и доставки карты (почти в 6 раз дешевле!), появились льготы, которые могут сделать обслуживание карты вообще бесплатным.
Увы, с 2018 года в ePayments решили приостановить выдачу новых карт. Старые обслуживаются как и прежде. Администрация платёжной системы не сообщает сроки возобновления выпуска, также не комментируется и причина, по которой выпуск новых карт приостановлен.
В личном кабинете ePayments опубликована новость: «Уважаемые клиенты! Нами выполняется пересмотр условий выпуска карт ePayments. В рамках этого процесса, начиная с 15:00 GMT 11.04.2018, выпуск всех новых карт временно приостановлен». Если вы резидент Европейского союза, то можете попробовать заказать пластиковую карту. Появилась информация, что для таких клиентов новые карты всё-таки можно выпустить. Россиянам и жителям СНГ новые карточные продукты по-прежнему не доступны.
Если вы хотите получить именно зарубежную пластиковую карту, то советуем обратить внимание на Payoneer (они карты жителям РФ выдают).
- Заказ и изготовление, а также перевыпуск — 5,95$ (4,95€).
- Комиссия за годовое обслуживание с апреля 2017 года не взимается единоразово, но списывается ежемесячно, при этом
- первые 2 месяца обслуживания с момента выпуска бесплатны в любом случае;
- с 3 месяца и далее $2.9 (€2.4);
- если картой не пользуетесь, и на кошельке ePayments нет достаточного количества средств, то деньги за обслуживание пластиковой карты списываться не будут; как только средства поступят на карту или кошелёк, будет оплачен следующий месяц пользования карты (за предыдущие месяцы, когда на счёте кошелька был 0, платить не нужно!);
- выгода по карте ePayments: если в течение месяца вы совершили общее количество покупок в магазине или интернете на сумму от 300 евро или долларов, то следующий месяц обслуживания для вас будет бесплатным!
Например, если в мае мы активно покупали при помощи карты ePayments в магазинах или на интернет-сайтах товары и услуги, и общая сумма покупок превышает 300 долларов, то в июне не платим $2.9 (€2.4) за обслуживание!
Такие покупки можно начинать со второго месяца, чтобы не платить за третий и так далее. Ограничений нет, то есть вы можете вообще пользоваться платёжной картой «Епейментс» бесплатно, если будете совершать ежемесячно покупки на сумму от 300 долларов или евро!
- Покупки в магазинах и Интернете (POS-транзакции) — бесплатно, нет комиссии за трансграничные платежи
(конвертация в местную валюту по курсу платёжной системы + 2,6% при оплате не в долларах или евро). - Снятие денег в банкомате (ATM-операции) — фиксированная 2.60$ (2.40€)
(+2,6% если будете снимать в местной валюте). - При отсутствии операций в течение полугода начинает ежемесячно списываться по 10$ (8€) до достижения нулевой отметки.
- Смена пин-кода платная и стоит 1$ (0.80€).
- Доставка обычной почтой бесплатная, экспресс-доставка курьером сейчас 45$ (вместо 89.95).
- Лимиты: 200 операций покупок (на сумму до 40 000$) / 100 операций снятия наличных в день (3 000$ за раз и в сутки).
Пополнение предоплаченного пластика бесплатное (именно зачисление на счёт кошелька по SWIFT (в долларах, евро или рублях), за сам перевод нужно будет заплатить выбранному вами банку по его тарифам) банковским переводом, с Webmoney 1% (но минимум 5$).
Вы также можете пополнить карту ePayments с персональных карт VISA, Mastercard или Maestro с поддержкой 3D Secure (смс-подтверждения) — комиссия 2,6%.
При этом минимальная сумма для зачисления на счёт 10$ (10€), а при одноразовом пополнении важно не превысить — 10 000$ (7 778€). На счёте можно хранить не более 20 000$ (15 556€).
Условия и особенности карты ePayments:
- Эмбоссированная (с выпуклыми символами), именная, статус по BINBASE — Prepaid, на лицевой стороне имеется EMV-чип,

ePayments создала условия для бесплатного обслуживания карты, есть полноценная поддержка sms-информирования и 3D Secure.есть PayPass. Эмитент с 2016 года PSI-Pay Ltd (UK) — Великобритания (до этого была WaveCrest Holdings LTD).
- Срок действия 3 года.
- С 8 февраля 2017 года карта стала поддерживать 3D Secure (оплату на сайтах с смс-подтверждением платежей).
- Доставляется бесплатно заказным письмом с трек-номером отслеживания через «Почту России» (в течение двух недель по РФ), но есть возможность заказа курьерской службой DHL (стоимость под 88$).
- Валюта — доллар США ($) и Евро (€), скоро прикрутят GBR (P — британский фунт стерлингов).
- СМС-информирование об операциях по карте поддерживается, полностью бесплатное. Работает и полноценный 3D Secure (смс-подтверждение операций при покупках онлайн).
- По операциям с кошельком ePayements можно получать Push-уведомления в телефон (через официальное приложение), а также по электронной почте.
- Есть поддержка бесконтактных платежей PayPass.

Электронный кошелёк ePayments eWallet

Его пополнение локальным платежом, банковским переводом (по SWIFT, комиссия со стороны «Ипейментс» не взимается, но может быть удержана отправителем) или с криптовалют абсолютно бесплатное. Исключение составляет Webmoney (1%, минимально 5 баксов), другие платёжные карты Visa / MasterCard — 2.6%. При этом лимиты не ограничены, если вы заранее верифицировали свой аккаунт.
Также важно отметить, что не поддерживается PayPal (по ней можно оплатить только заказ карты, если на кошельке нет средств)!
Вывод денег с кошелька ePayments
Реализована и возможность прямой отправки денег в банк по международным платежам SWIFT/SEPA (0.8%, но не меньше 85$ и не больше 135$, минимум 100$ максимум в 100 000$).
Временно действуют ограничения на операции трат денег и их вывода со счёта ePayments в рамках ограничений от FCA. Подробнее об этом писали в начале статьи.
При этом вы можете выводить в трёх валютах: доллары США, евро и рубли. Платёж всё равно идёт по международным реквизитам SWIFT (комиссии по переводам в рублях: 0.8%, но не менее 4 500 и не более 7 500 рублей): минимальная сумма для перевода 6000 рублей, максимальная 6 000 000 рублей. В долларах и евро: не менее 90 и не более 90 000 долларов или евро (комиссия 0,8%, min 75, max 125 в долларах или евро). К сожалению, в 2018 году переводы в SWIFT в долларах в ePayments пока приостановлены. Как на приём денежных средств, так и на вывод.
С 18 февраля 2018 снижены комиссии за SWIFT: 0,5% (минимально 15 долларов / евро или 900 рублей — в зависимости от того, в какой валюте выводите). До этого было 0,8% (минимально 85 долларов). То есть с февраля теперь можно выгодно отправлять банковским платежом и небольшие суммы тоже.
Однако тут есть и сложности. Минимальная комиссия обязывает отправлять крупные деньги на свой счёт в российском банке, однако регулярные поступления из-за границы в крупных объёмах могут вызвать вопросы у кредитных организаций России, что можете привести к блокировке счёта в российском банке.
Казалось бы, найди себе обменник для вывода ePayments на BestChange и радуйся жизни, но не тут-то было. Найти реальных дельных предложений от независимых обменных пунктов практически нереально. Зато есть сервис Capitalist , который может стать промежуточным звеном цепи (принять у вас по SWIFT денежки и перекинуть дальше их куда пожелаете). Пусть это и дороже, зато более безопасно.
Также деньги с ePayments можно напрямую вывести на другую платёжную карту по Moneysend (2.9%, минимум 3,5$ — перевод только в рублях, обмен USD и EUR автоматически рассчитывается по невыгодному курсу — меньше на 2-3 рубля от официального ЦБ РФ).
Деньги можно также выводить на Qiwi (с любой валюты, 2%) и на «Яндекс.Деньги«, но только с рублёвого кошелька (2% за операцию, нет фиксированного значения; сумма от 1 рубля до 60 000 за операцию / 300 000 в сутки / 600 000 в месяц, в сутки не более 5 операций). С 19 апреля 2017 года появилась возможность выводить на любой кошелёк Qiwi в долларах, рублях или евро. Комиссия тоже 2%. Можно выводить и на «Вебмани» (2%), при этом карту «Ипейментс» оформлять не обязательно.
Как пополнить кошелек?
После того, как аккаунт создан и верифицирован, пополняем его деньгами. На епейментс можно создать кошелек в USD, EUR и RUB.
3 способа, как пополнить счет в платежной системе epayments:
- через банковский перевод в любом банке – без комиссии;
- с карты Visa/Mastercard/Maestro – комиссия 2,6%;
- криптовалютой (BTC, BCC, ETH, LTC) – без комиссии.

Чтобы положить деньги на свой кошелек, в личном кабинете в меню слева жмем Получить, выбираем метод оплаты и вносим данные для осуществления транзакции.
При этом лимиты на пополнение для верифицированных аккаунтов не ограничены. Детальная информация о комиссии и лимитах на прием платежей доступны по ссылке.
Epayments и криптовалюта
По состоянию на январь 2020 года кошелёк ePayments поддерживает вывод и вывод средств на криптовалют. Это, кстати, одна из немногих систем, где выбор вывода средств настолько разнообразен и удобен (в AdvCash, например, поддерживается пока только одна валюта и лишь некоторые биржи)! Вы можете самостоятельно решить, в какую криптовалюту выводить средства и чем пополнять кошелёк, соответственно. Такая универсальность позволяет использовать «Ипейментс» не только для долгосрочной покупки, но и для краткосрочных сделок, например, на биржах криптовалют. Хотя лучше всего заниматься пассивным заработком на криптовалюте и выводить заработанное сразу с биржи.
ePayments и криптовалюта: лимиты
- Минимальная сумма вывода 50$ в эквиваленте любой валюты;
- Максимальная сумма транзакции (в том числе в день) 20 000$; недельная 100 000$ и месячная 200 000$;
- Обмен криптовалюты по курсу системы ePayments;
- Комиссии со стороны «Епейментс» нет, только рекомендуемые комиссии самих криптовалют за транзакцию на день проведения операции (зависят от загруженности сетей);
- При пополнении ePayments-кошелька криптовалютой с биржи или криптокошелька зайдите в раздел «Пополнить» — «Криптовалютой«, укажите объём имеющейся у вас криптовалюты для перевода, ознакомьтесь с рекомендуемой комиссией сети и совершите перевод в установленный срок. После перевода ожидайте подтверждения.
Выберите в меню пункт «Пополнить«, а затем «Криптовалютой«
Система ePayments позволяет эффективно решить вопрос вывода и вывода прибыли, поскольку с кошелька можно перевести деньги на карту ePayments и выводить средства в долларах в любой точке мира когда и где захотите! В банкоматах и даже кассах банков без комиссии!
Внимание: обязательно учитывайте необходимые условия для ввода и вывода средств в криптовалюте через кошелёк ePayments: рекомендуемый размер комиссии за операцию, необходимую сумму перевода и объём реализуемой криптовалюты! Оплату нужно провести в установленный срок! В противном случае платёж не пройдёт и вернётся обратно!
Биржа DSX

Интеграция с кошельком ePayments (комиссия 0% за ввод и вывод). Зарегистрируйтесь и получите месяц скидки 50% на комиссию за сделки.
Немногие знают, что платёжная система ePayments обзавелась собственной электронной площадкой для ведения торгов популярными криптовалютами.
Примечательным и вселяющим доверие фактом является то, что данная биржа подпадает под ту же лицензию, которой владеет и сама компания, а именно Financial Conduct Authority (FCA), предполагающую строгий контроль властей Великобритании за деятельностью электронных кошельков. Таким образом, мы уже законодательно защищены от проблем, которые случаются с частными биржами, как авторитетом самой ePayments, так и британским законодательством.
Биржа DSX (Digital Securities Exchange Limited) в настоящее время предлагает торговлю 5 криптовалютами как между собой, так и деньгами (британским фунтом, евро, долларом США и рублями). Можно менять и валюты между собой. На текущий момент из биржи нельзя временно деньги вывести на ePayments в рамках ограничений от FCA.
Характерная особенность системы — поддержка русского языка как в интерфейсе, так и в службе поддержки. Тесная связь с ePayments значительно упрощает работу: вы можете входить через логин и пароль в ePayments, более того, если прошли верификацию в электронном кошельке, то на бирже её проходить не придётся. Хорошая экономия времени! Поддерживается и двухфакторная авторизация (по смс или через Google Identificator).

Ввод и вывод с торгового счёта на кошелёк ePayments без комиссии!
Ещё одна крутая возможность — отсутствие комиссий при пополнении и выводе на кошелёк ePayments. Но, конечно же, можно выводить и саму криптовалюту, а также деньги по SWIFT, но уже за денежку
Таким образом, биржа DSX позволяет деньгам работать и приумножаться, а не просто лежать на счетах кошелька.
Комиссия за сделки стандартная — 0,2% от оборота, но её можно снизить даже в два раза, если будете часто торговать и хорошими объёмами.
А ещё комиссию можно снизить в 2 раза на 30 дней, если зарегистрируетесь по нашей ссылке на бирже DSX и совершите торговый оборот от 100$.
Условия более чем лояльные. Эту биржу многие ждали и уже оценили по достоинству, ведь теперь деньги можно выгодно приумножить в рамках всё той же ePayments
Как максимально выгодно снять деньги с ePayments в банкоматах России?
П 
ервым делом необходимо найти в вашем городе банкомат, который выдаёт валюту (доллары или евро) без комиссии. Это ключевой момент, поскольку многие банки либо вообще не позволяют получить её, либо эта услуга только для своих клиентов. Сегодня список банков России, готовых предоставить льготные условия по выдаче наличных денег, довольно скуден:
Снятие денег и финансовые операции по картам ePayments временно ограничены, согласно требованиям FCA. Проблема решается представителями компании.
- Unicredit, Citibank ( только долларовые банкоматы, появилась дополнительная комиссия 2$ за операцию), «Росбанк» — до 400$ за одну транзакцию;
- «Райффайзен» — до 300$/операция (появилась комиссия владельца банкомата до 3$ с транзакции);
- ВТБ (взимает свою комиссию 1,5%, если снимаете меньше 500$, мало валютных банкоматов, в основном Санкт-Петербург, Москва) — до 500$ за подход, но можно найти и больше, всё зависит от банкомата;
- «Бинбанк» — в связи с объединением с «Открытием» валюты банкоматы практически не выдают. Лучше снимать в кассе банка крупные суммы. Тем более что это без комиссии со стороны банка.
- «Альфа-Банк» — только 100 долларов за операцию (говорят, есть комиссия 5$ за операцию);
- «Европа Кредит Банк» — до 300$ за одну операцию.
- Тинькофф — лимит не более 5000 USD, часто валюты нет, особенно в регионах (банкомат Tinkoff взимает свою комиссию 5% от суммы снятия в долларах!), не предупреждая заранее. Только в чеке отражается информация постфактум.
Немного, но хотя бы что-то. Таким образом, если нам необходимо снять 400$, то затраты будут следующие:
400$ + 2.60$ = 402.6$. Таким образом, спишут фиксированную комиссию, на руки получите 400$ хрустящих купюр, а по счёту реально получится 402,6$.
Общие лимиты ePayments на выдачу наличных в банкоматах по всему миру и в кассах банков: 3000$ в день и не более 100 подходов. К сожалению, в российских банкоматах такие лимиты выдачи налички — мечта.
Снимаем деньги с ePayments за рубежом

Например, это реально осуществить в Турции. И даже не будет комиссии.
Garanti выдаёт до $4800 (купюры по 50 долларов).
Максимальный лимит в Deniz Bank — $4000 за каждое снятие,
TEB — $2000 за операцию. В последних двух купюры 100 долларов
Лайфхак:
если у вас на руках карта «Епейментс» в евро и живёте в Санкт-Петербурге или в любом другом городе, находящимся недалеко от стран, где официальная валюта — евро, то у вас есть возможность обналичивать деньги в банкоматах Финляндии, Эстонии, Латвии, Литвы. Или, например, летите в Европу из Москвы, то отдых или деловую поездку можно провести с пользой, и снимать деньги в других странах. При этом лимиты будут значительно выше. Не забудьте захватить с собой евровую карту ePayments.
Если знаете, как обналичивать «Епейментс» в других странах, и у вас есть опыт (какие конкретно банкоматы, где и какие лимиты), пишите в отзывах. Это очень ценные сведения!
Вывод долларов и евро с ePayments через кассу банка

В банке «Авангард» можно попробовать снять деньги в кассе.
Низкие лимиты выдачи иностранной валюты в банкоматах РФ — это настоящая головная боль, т. к. если нужно банально снять что-то больше стандартных лимитов (в районе 400$ за операцию, по евро лимиты ещё хуже), то выйдет дорого. Тем не менее есть вариант — попробуйте обналичить иностранную валюту с ePayments через кассу банка. Только заранее уточните там, сколько это будет стоить, есть ли вообще возможность получить доллары или евро, и принимает ли их POS-терминал в кассе карты сторонних банков.

С карты в долларах можно снять деньги в кассе банка «Ак Барс». Банк свою комиссию не взимает.
Появилась также информация о кассах «Ак Барса». Можно попробовать снять доллары или евро с карты ePayments в кассе этого банка. Деньги списывает только ePayments по своим тарифам. Для получения наличных нужен паспорт РФ. Свою комиссию «Ак Барс» за снятие через свою кассу не берёт. Помните также о том, что не во всех банках может в кассе быть в наличии большая сумма валютной наличности. Уточняйте заранее. Зато можно снять вплоть до суточного лимита по карте.
Есть отзывы о том, что неплохие условия предлагает «Банк Авангард«. У них обналичка выйдет по тарифу 2% + стандартные комиссии системы ePayments (2,6$/евро). Это может быть выгодно снятия сумм, превышающих лимиты банкоматов РФ по выдаче валюты (от 500$).
Для справки: в «Сбербанке» комиссия 40$ при снятии 1000$ с карты ePayments. «Газпромбанк» — 25$. Примерно сопоставимые комиссии в «Открытие».
Как сделать перевод?
Существует множество способов, как перевести деньги на кошелек epayments. Можно делать переводы как между своими кошельками, так и отправлять деньги другим клиентам ePayments. Обратите внимание, что функция Переводы доступна только для верифицированных пользователей.
- Перевод между своими счетами: пополнение и возврат средств c карты ePayment на кошелек – без комиссии;
- Мгновенный платеж любому пользователю ePayment по номеру его кошелька, телефона или email – без комиссии;
- Перевод на банковскую карту VISA/Mastercard/Maestro/МИР – комиссия 2,9%;
- Перевод средств на банковский счет:
-локальный перевод в валюте BDT, BRL, CAD, GBP, HKD, IDR, INR, JPY, PHP, RUB, SEK, THB, VND – комиссия $3;
-SEPA-перевод в EUR – комиссия $0.6 (актуально до 31.10.2018);
-международный перевод – комиссия 0.5%. - Перевод средств на криптовалютный кошелек в BTC, BCC, ETH, LTC – без комиссии;
- Перевод на WebMoney в валюте WMZ, WME – комиссия 2%;
- Перевод денег на кошельки Яндекс.Деньги – комиссия 2%;
- Перевод на кошелек VISA QIWI Wallet – комиссия 2%;
- Перевод средств на мобильный телефон – комиссия 2%.
Более того, система позволяет сделать массовые переводы и отправлять средства неограниченному числу людей по номеру кошелька, телефона или email.
Чтобы положить деньги на свой кошелек, в личном кабинете в меню выбираем Перевести, указываем способ перевода и вводим необходимые данные.
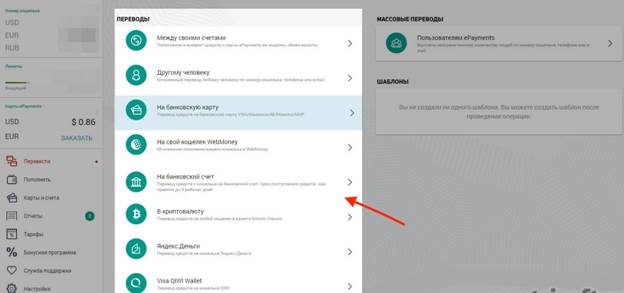
Информация о минимальной и максимальной сумме переводов для каждого из способов доступна по ссылке.
Как обменять деньги?
Если нужно пополнить карту ePayments, а деньги на кошельке отличаются от валюты карты, или перевести деньги другому человеку в конкретной валюте, можно воспользоваться epayments обменником.
Обмен валюты доступен даже для не верифицированного пользователя.
Но переводить средства с кошелька можно лишь после процедуры идентификации личности.
Обменять деньги можно между любыми секциями ePayments кошелька, то есть между RUB, USD и EUR. Конвертация валюты в происходит мгновенно.
Чтобы произвести обмен в личном кабинете нажимаем Перевести → Между своими счетами и заполняем поля заявки на обмен. В поле Со счета выбираем валюту, которую отдаем; На счет – ту, которую хотим получить. Ниже указываем сумму обмена. Проверяем данные и завершаем операцию, нажав Подтвердить.
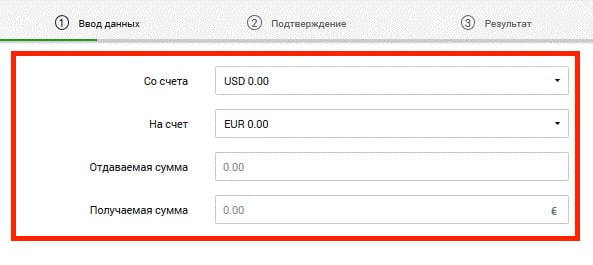
Система рассчитывает получаемую сумму на основании среднерыночного курса текущего дня.
Обмен валюты доступен и в мобильной версии платежной системы на iOS и Android.
Как вывести рубли?
С карты ePayments

Лимиты по ВТБ (100 000 рублей), «Альфа Банк» (до 250 000 рублей) по обналичиванию с карт ePayments рублей.
Рекомендуем искать банкоматы с логотипом ВТБ, которые позволяют снимать до 100 000 рублей с «чужих карт» за одну транзакцию. Также есть информация, что банкоматы «Альфа Банка» по чужим картам могут выдать рублями до 250 000 (не все и не везде, уточняйте заранее). Повышенные лимиты есть и в банкоматах «Тинькофф» (при снятии рублей).
Есть также информация о том, что в банкоматах «Райффайзен» банка можно снять до 150 000 рублей, в «Открытие», а также в «Промсвязьбанке» до 200 000 рублей.
Для сравнения (лимиты получения денег с «чужих карт» в банкоматах других банков):
- «Тинькофф Банк» — до 200 000 рублей (если снимать в рублях, то комиссии нет). Банкомат взимает комиссию только при снятии с карты ePayments долларов или евро.
- «Почта банк» — до 50 000 рублей за операцию;
- «Русский стандарт» — до 40 000 рублей за операцию;
- «Сбербанк» — до 5 000 рублей за один раз.
Комиссии: 2,6$/евро за снятие в банкомате + 2,6% за конвертацию долларов или евро в рубли.
Банки в России и за рубежом могут взимать дополнительную комиссию за снятие долларов или евро (так называемый ATM fee) в своих банкоматах по чужим картам. Например, это в России это делает ВТБ. За снятие рублей пока комиссии нет.
Epayments и снятие денег в банкоматах с карт иностранных банков
Вывод денег с кошелька «Епейментс»
Напрямую с кошелька можно вывести на банковские карты России. Учтите, пожалуйста, что перевод на карту банка РФ будет в рублях. Причём на карты банков РФ можно получить только рубли! Поэтому не используйте долларовые карты банков в РФ, чтобы не попасть на двойную конвертацию валют при получении перевода с кошелька «Ипейментс».
Система ePayments возьмёт комиссию за вывод 2.9% (минимум $ 3.50) + если выводятся доллары или евро с кошелька, то производится дополнительная внутренняя комиссия кошелька за конвертацию (примерно 3%).
В вопросах выбора удобного способа приёма платежей для себя трудно искать советчика, но на сегодняшний момент система ePayments дарит значительную свободу для действий людям, которые работают в Интернете. Гибкость и подстройка под нужды пользователей — это то, что так ценится миллионной армией юзеров по всему миру. Наверное, поэтому о ней так много положительных отзывов. Особенно от людей, живущих в Украине. Там это незаменимое средство для вывода денег, в том числе и из российской Webmoney, которую не очень-то жалуют современные украинские власти.
В качестве альтернативы ePayments вы можете попробовать систему и платёжную карту Skrill. У нас на сайте есть подробный обзор возможностей системы «Скрилл». В сравнении с ePayments её обслуживание обходится дешевле, однако распространена она меньше: не все партнёры принимают такой вариант для выплат. Ну или Payoneer (здесь доступны счета в долларах или в евро и вывод на банковский счёт). В качестве альтернативного электронного кошелька (и банковской карты в рублях) можно рассмотреть систему Advanced Cash . Они ещё и карты выдают.
Источники:
- https://cryptonisation.ru/obzor-platezhnoj-sistemy-epayments-vozmozhnosti-i-preimushhestva/
- https://dataworld.info/epayments-card-prepaid-russia.php