Отправка длинных сообщений ушла в прошлое. Тем более с появлением голосовых сообщений. Однако, если вы хотите разыграть своих друзей, вы можете отправить им сообщение без сообщения. Для этого отправьте им пустое сообщение в WhatsApp.
На момент написания этой статьи не было прямого способа отправить пустое сообщение в WhatsApp. Во всяком случае, WhatsApp не делает доступной опцию отправки, если вы нажимаете пробел на клавиатуре, чтобы создать пустое сообщение. Однако нижеперечисленные 4 способа могут помочь вам добиться этого. Продолжайте читать, чтобы узнать больше.
1. Использование метода скобок
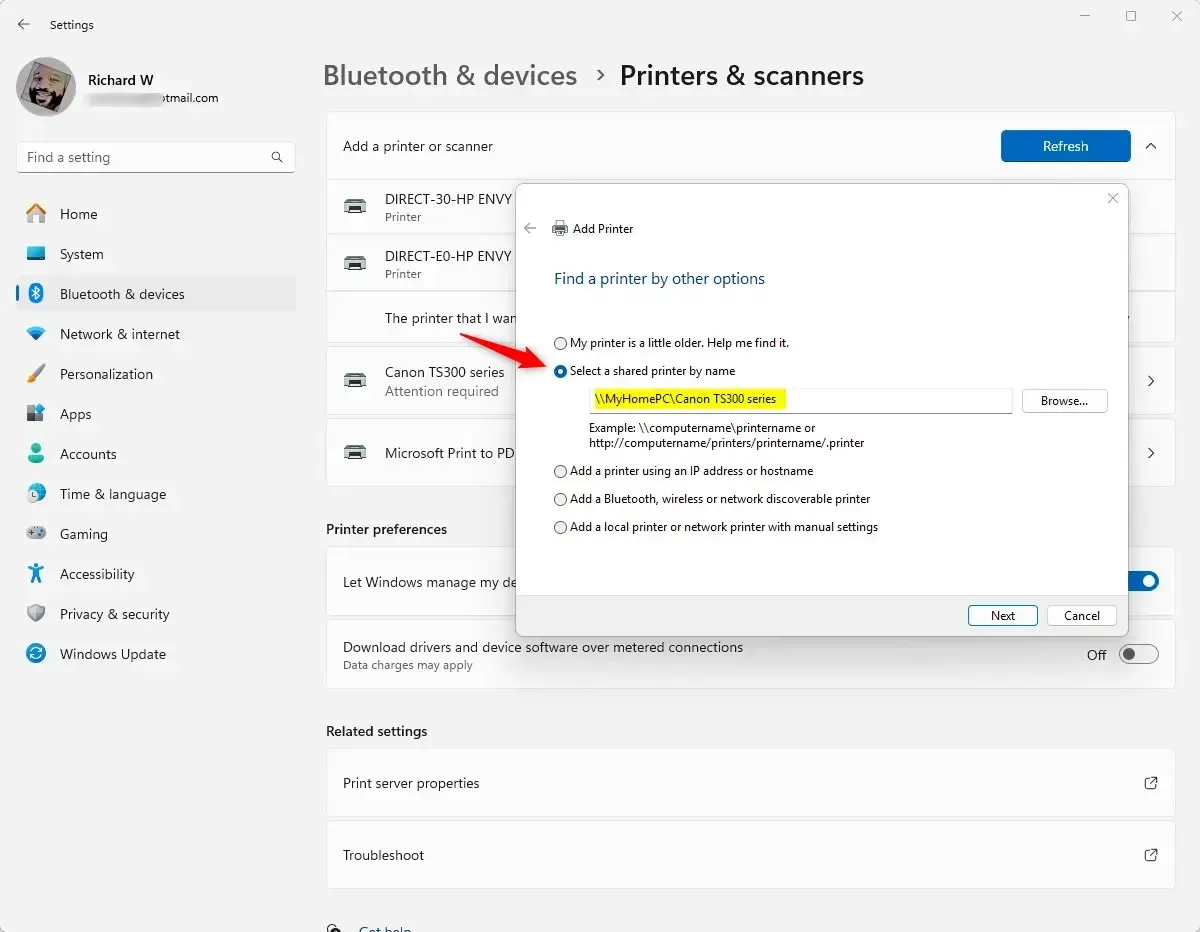
Одним из самых популярных способов отправки пустого сообщения в WhatsApp без каких-либо сторонних инструментов является метод скобок. Здесь создайте пробел между двумя скобками в веб-браузере. Затем вырежьте пространство и оставьте скобки. После этого вставьте пробел в окно сообщения и отправьте его как пустое сообщение. Вот пошаговый обзор для большей ясности.
Примечание. В ходе тестирования мы обнаружили, что этот метод периодически оказывается успешным при использовании последней версии WhatsApp. Если это также произойдет с вами, перейдите к любому из других методов, упомянутых ниже.
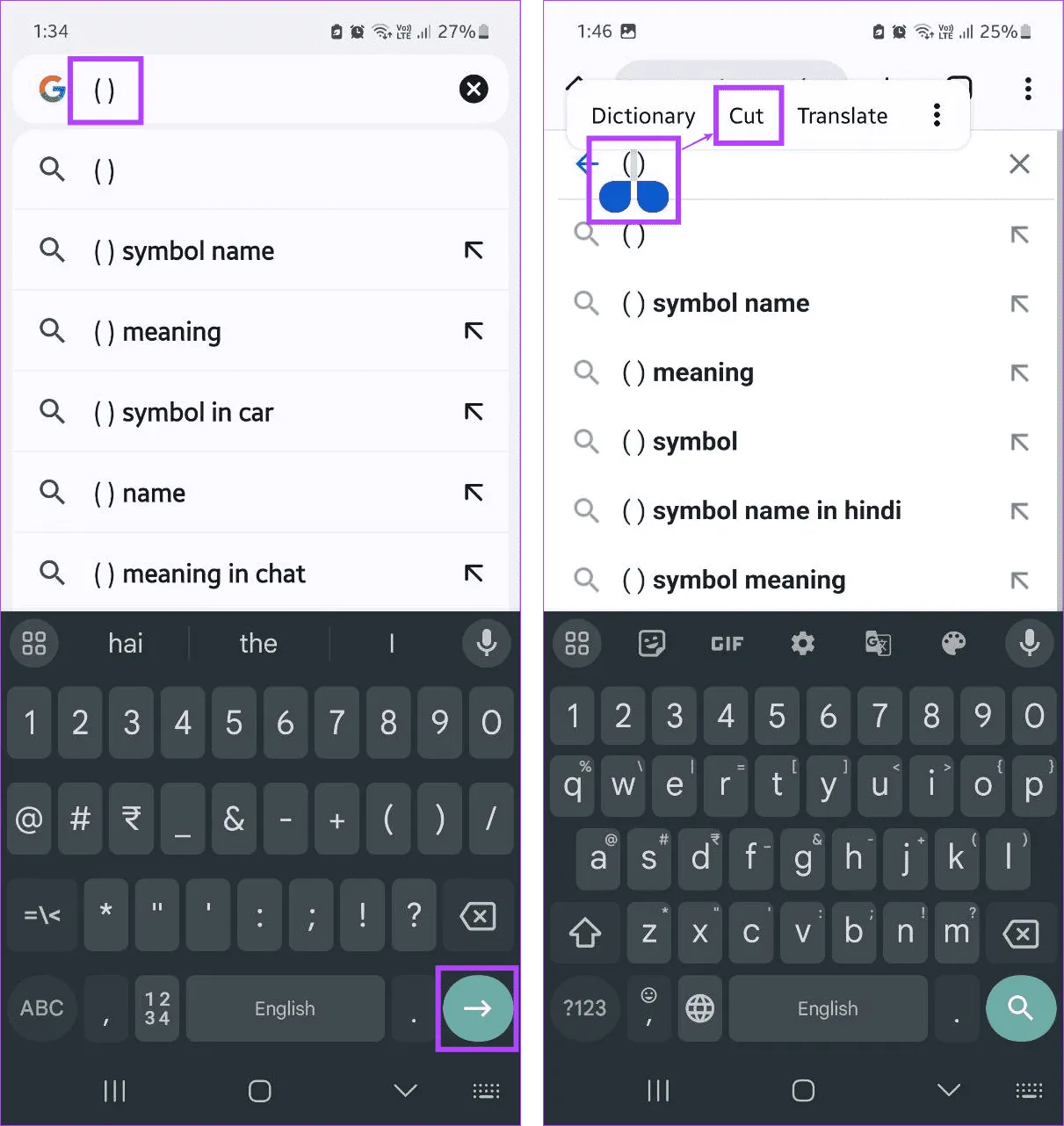
Шаг 1. Откройте любой веб-браузер на своем мобильном телефоне. Здесь введите (). Убедитесь, что вы используете пробел, чтобы создать пространство между двумя скобками.
Шаг 2: Затем нажмите «Готово».
Шаг 3: Теперь нажмите и выберите пространство между двумя скобками.
Шаг 4: Когда появятся параметры, нажмите «Вырезать».

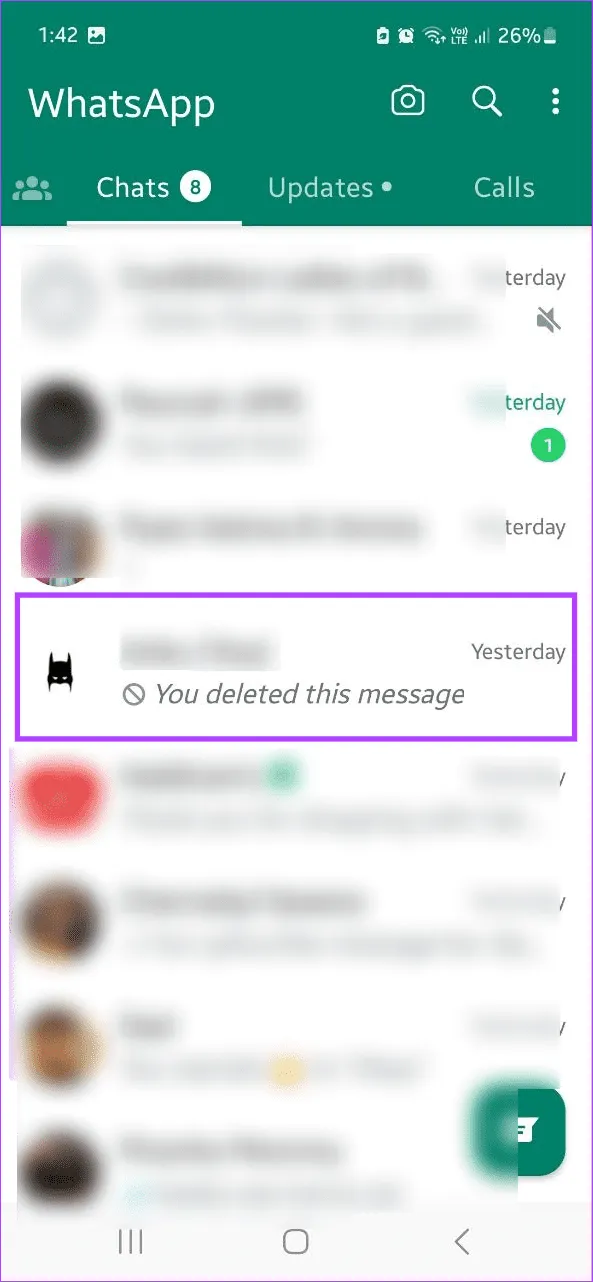
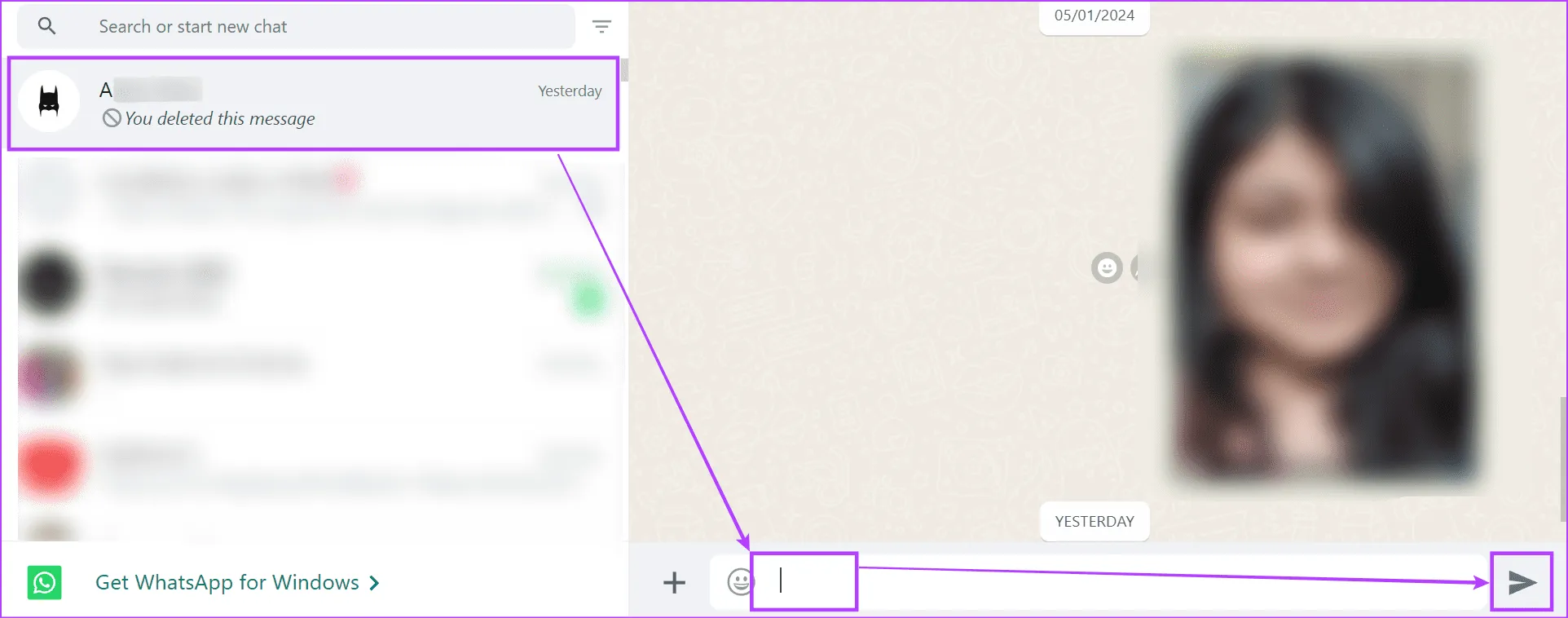
Шаг 5: Откройте WhatsApp и нажмите на соответствующий контакт.

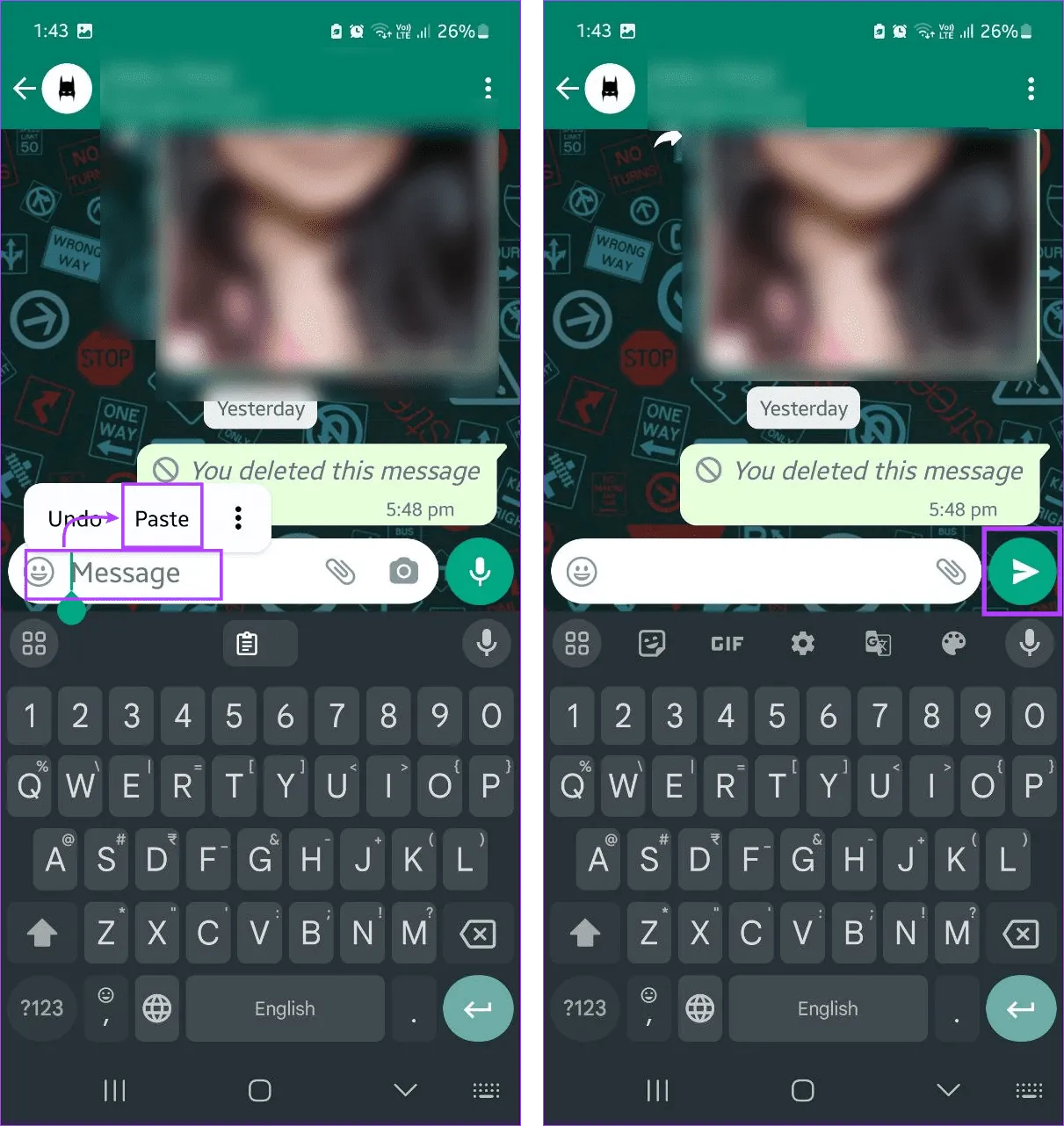
Шаг 6: Нажмите и удерживайте панель сообщений и нажмите «Вставить».
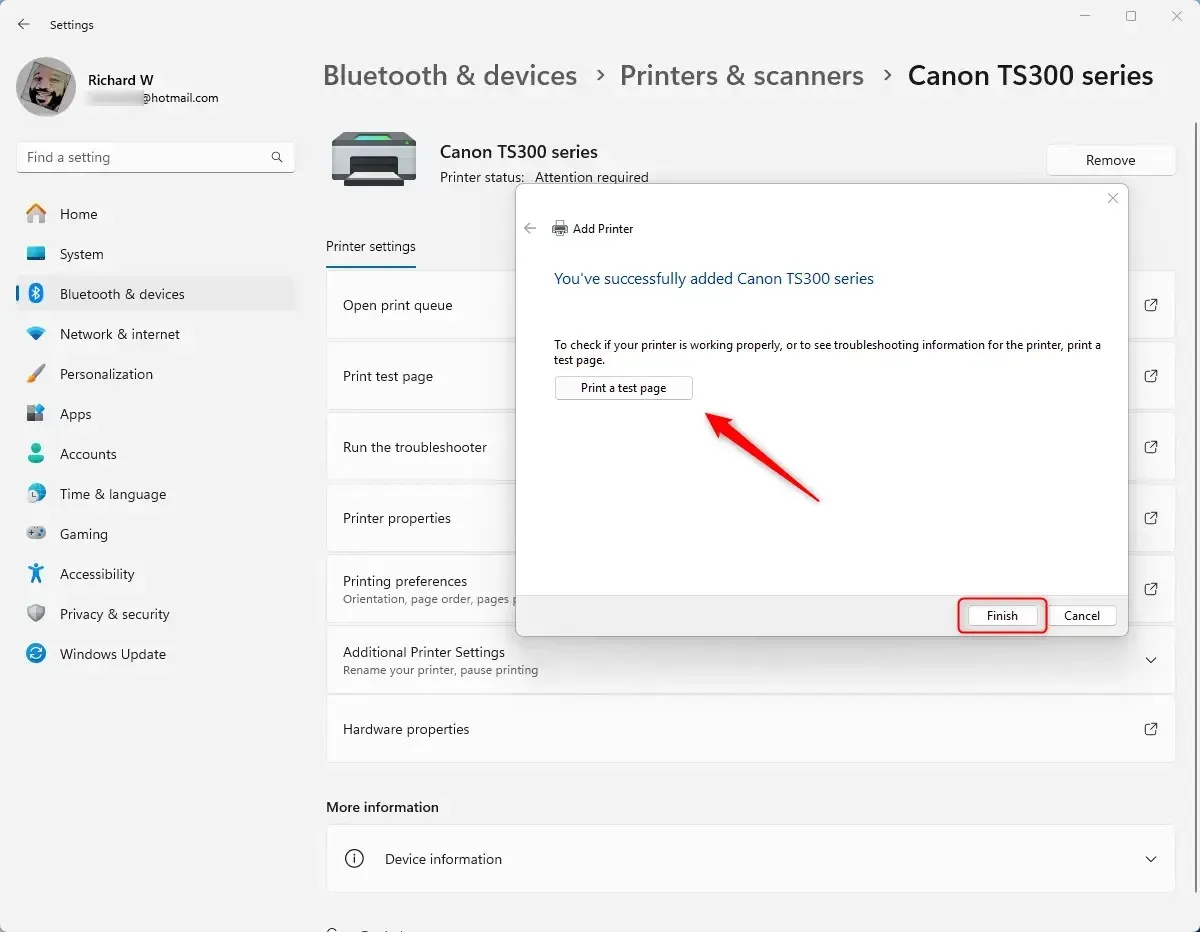
Шаг 7: Как только опция станет доступной, нажмите «Отправить».
Выбранному контакту будет отправлено пустое сообщение. Пока мы используем мобильное устройство в демонстрационных целях, вы можете повторить описанные выше шаги и отправить пустое сообщение с помощью веб-браузера и веб-приложения WhatsApp или настольного приложения.
2. Копируя пустые символы Юникода
Некоторые кодовые элементы Юникода, такие как шаблон Брайля U+2800, могут быть прочитаны веб-сайтами и приложениями как пробелы. Это означает, что как только вы скопируете и вставите символ, он появится в WhatsApp как пустое место. Однако, поскольку изначально это был образец Брайля, его следует распознать как сообщение в окне чата. Вот как это сделать.
Шаг 1. Откройте любой веб-браузер и воспользуйтесь ссылкой ниже, чтобы открыть символ Юникода U+2800.
Шаг 2: Теперь выберите и скопируйте пустое место.

Шаг 3. Затем перейдите в веб-приложение или приложение WhatsApp для ПК и нажмите на соответствующий контакт.
Шаг 4. На панели сообщений вставьте скопированное пустое сообщение.
Шаг 5: Когда появится опция, нажмите «Отправить».

Это отправит пустое сообщение в WhatsApp. Вы также можете использовать веб-браузер на своем мобильном телефоне, чтобы открыть вышеупомянутую ссылку. Затем скопируйте и вставьте символ Юникода в окно сообщения мобильного приложения WhatsApp и отправьте его как пустое сообщение.
3. Использование сайта-генератора пустого пространства
Как и символы Юникода, вы также можете использовать веб-сайты-генераторы пустого текста для отправки пустых сообщений в WhatsApp без установки какого-либо приложения. Для этого зайдите на любой сайт-генератор пустого текста и скопируйте и вставьте текст в окно сообщения WhatsApp.
Это также может помочь, поскольку некоторые символы Юникода могут не распознаваться WhatsApp как пустой текст. Кроме того, вы можете создать больше строк пустого текста, чем предыдущий метод. Чтобы сделать это, выполните следующие шаги.
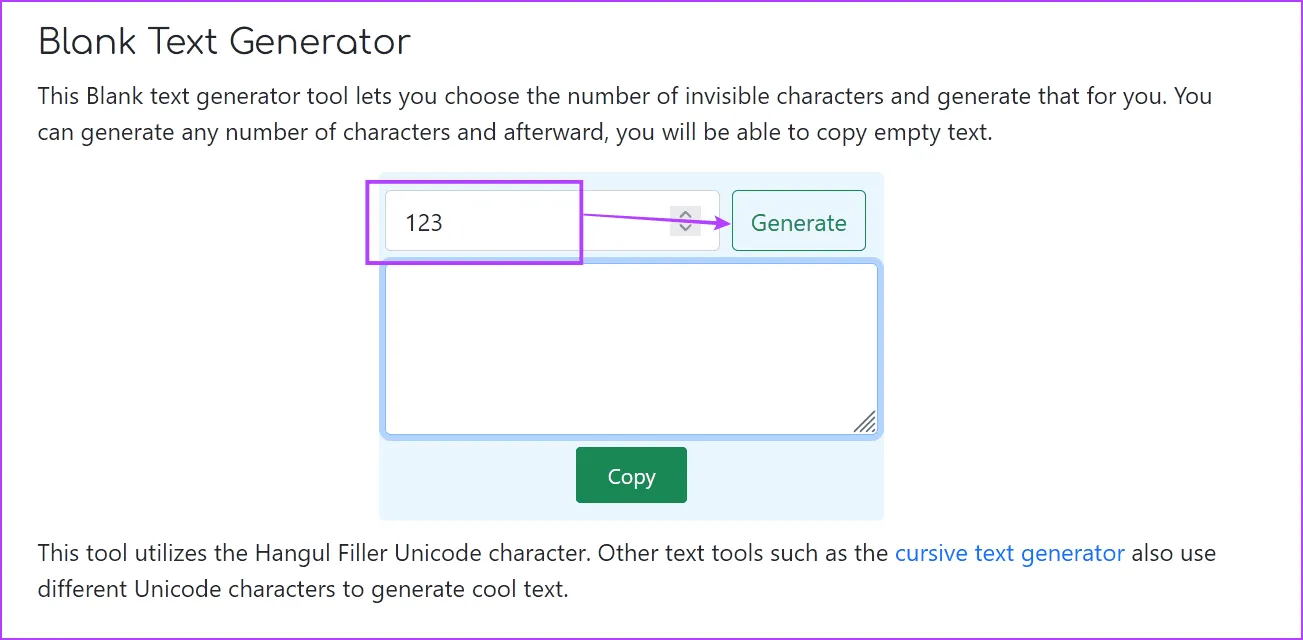
Шаг 1. Откройте веб-сайт генератора пустого текста в любом веб-браузере.
Открыть пустой текстовый сайт
Шаг 2. Здесь введите слова или символы, которые вы хотите преобразовать в пустой текст, и нажмите «Создать».

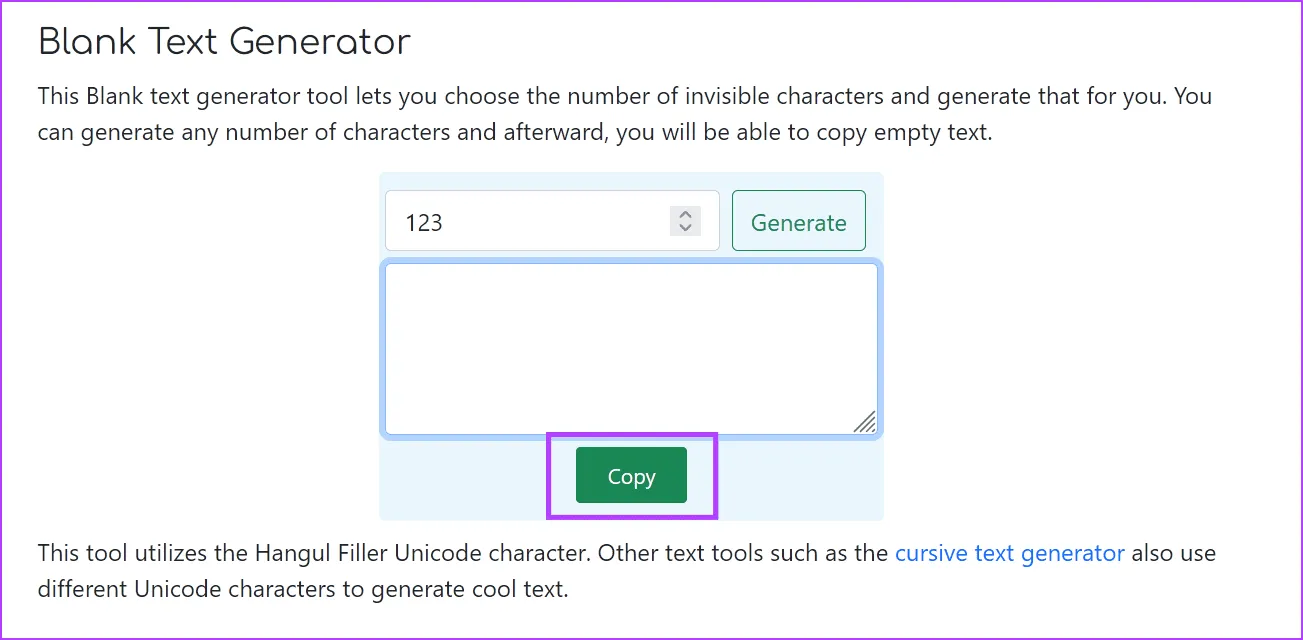
Шаг 3: После создания пустого текста нажмите «Копировать».
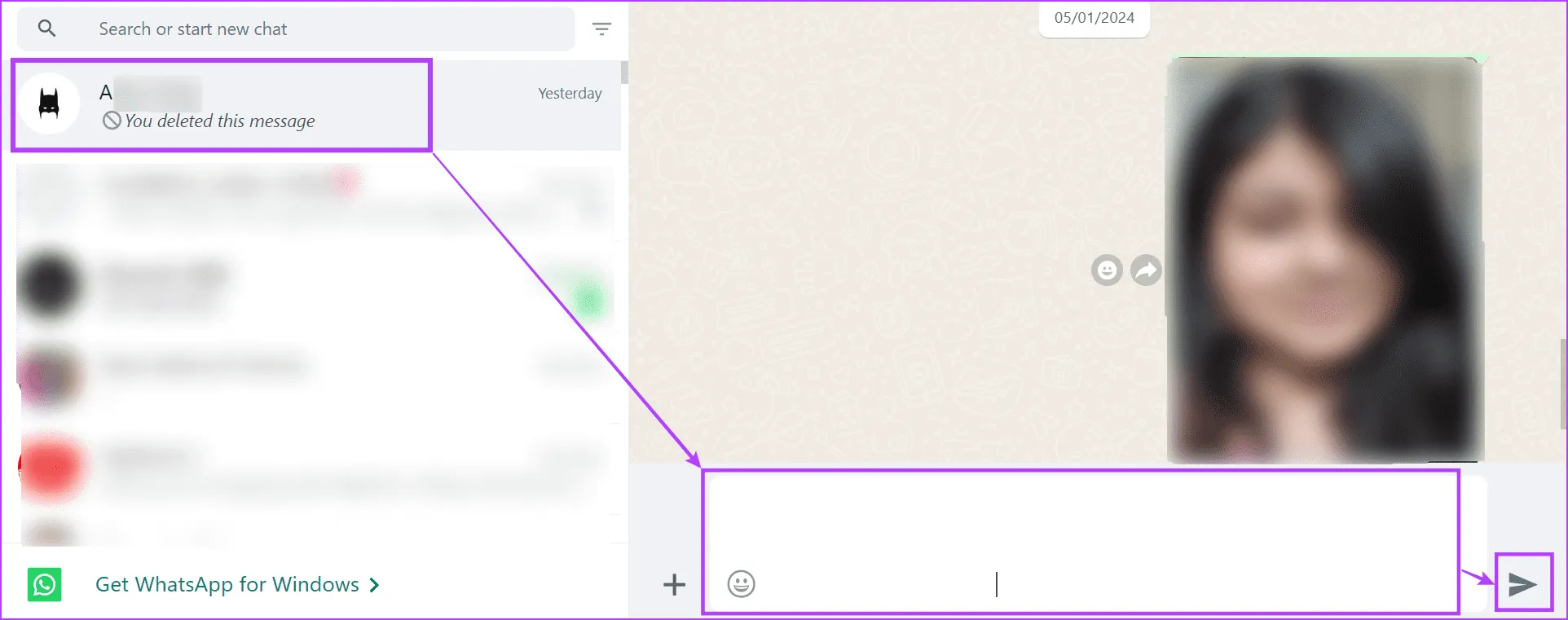
Шаг 4: Теперь перейдите в WhatsApp и нажмите на соответствующий контакт.
Шаг 5: В поле сообщения вставьте ранее скопированный пустой текст.
Шаг 6: Когда опция станет доступной, нажмите «Отправить».

Это приведет к отправке пустого текста. Если вы используете мобильное устройство, откройте ссылку выше в любом веб-браузере и скопируйте и вставьте соответствующий текст в мобильное приложение WhatsApp, чтобы отправить пустой текст.
4. Использование сторонних приложений
Если вы предпочитаете использовать WhatsApp на своем мобильном телефоне и не можете вводить пустой текст, вы можете использовать сторонние приложения, такие как «Пустое сообщение для WhatsApp». После подключения к приложению WhatsApp вы можете легко отправлять пустые сообщения. Также доступны некоторые другие приложения с той же функциональностью. Однако мы не рекомендуем использовать такие приложения по соображениям защиты данных.
Часто задаваемые вопросы по отправке пустых сообщений в WhatsApp
1. Можно ли удалить пустые сообщения в WhatsApp?
Пустые или пустые сообщения отправляются в WhatsApp как обычные сообщения. Это означает, что вы также можете удалить их, как обычное сообщение в WhatsApp. В зависимости от того, когда было отправлено сообщение, вы можете удалить сообщение только для себя или для всех.
Отправить пустое сообщение в WhatsApp
Будучи предпочтительным средством связи для многих, отправка и получение сообщений WhatsApp стали обычным делом. Однако вы можете нарушить этот монотонный шаблон, отправив вместо этого своим друзьям пустое сообщение в WhatsApp. Мы надеемся, что наша статья помогла вам добиться этого. Не забудьте поделиться реакцией друга на пустое сообщение в комментариях ниже.
2024-01-22T22:18:04
Вопросы читателей
 Это многолетнее листопадное дерево. Листья на тонких длинных черешках, очередные, широкояйцевидные или округлые, с выемчатым или усеченным основанием, зубчатые, реже цельнокрайные, иногда лопастные или даже (у садовых форм) перистонадрезанные, сверху темно-зеленые, снизу — сизовато-зеленые. Липа замечательное декоративное растение, широко используемое при закладке парков и скверов, и прекрасный медонос — главный медонос лесов и парков. У нее мягкая, легко обрабатываемая древесина, идущая на производство мебели, кадок, фанеры, музыкальных инструментов. Ее луб используют на мочало, а кору молодых деревьев — на лыко -для плетения корзин, обуви, веревок.
Это многолетнее листопадное дерево. Листья на тонких длинных черешках, очередные, широкояйцевидные или округлые, с выемчатым или усеченным основанием, зубчатые, реже цельнокрайные, иногда лопастные или даже (у садовых форм) перистонадрезанные, сверху темно-зеленые, снизу — сизовато-зеленые. Липа замечательное декоративное растение, широко используемое при закладке парков и скверов, и прекрасный медонос — главный медонос лесов и парков. У нее мягкая, легко обрабатываемая древесина, идущая на производство мебели, кадок, фанеры, музыкальных инструментов. Ее луб используют на мочало, а кору молодых деревьев — на лыко -для плетения корзин, обуви, веревок.