Хотя исправление ошибки «Windows не удалось завершить форматирование» может оказаться утомительной задачей, вы можете решить эту проблему, следуя систематическому подходу. Эта ошибка часто возникает при попытке отформатировать устройство хранения данных, например SD-карту или USB-накопитель. Чтобы решить эту проблему, вы можете использовать сторонние инструменты форматирования, проверить наличие ошибок диска или проверить защиту от записи. Применяя методы устранения неполадок в зависимости от конкретной ситуации, вы можете успешно устранить эту ошибку и отформатировать устройство хранения данных в системе Windows.
Что означает «Windows не удалось завершить ошибку формата»?
Когда появляется ошибка «Windows не удалось завершить форматирование», это обычно означает, что в операционной системе возникли проблемы с форматированием устройства хранения данных, например внешнего жесткого диска, SD-карты или USB-накопителя. Защита от записи, повреждение файловой системы, поврежденные сектора на устройстве хранения и проблемы совместимости — вот некоторые из причин этой проблемы. Проверка механизмов защиты от записи, сканирование на наличие ошибок диска или успешное форматирование соответствующего устройства хранения с помощью альтернативных инструментов форматирования — вот некоторые возможные способы устранения ошибки.
Причины возникновения ошибки «Windows не удалось завершить форматирование»
Существует ряд причин ошибки «Windows не удалось завершить форматирование», в том числе:
- Защита от записи: на устройстве хранения может быть активирован физический переключатель защиты от записи, предотвращающий любые изменения его содержимого.
- Проблемы с файловой системой. Проблемы с форматированием могут возникнуть из-за повреждения структуры файловой системы устройства хранения.
- Плохие сектора: ошибка может возникнуть из-за поврежденных секторов носителя, препятствующих процессу форматирования.
- Несовместимая файловая система. Эта ошибка может возникнуть при попытке отформатировать диск, файловая система которого несовместима с предполагаемым использованием.
- Сломанный USB-кабель или порт. Сломанный USB-порт или порт может помешать процессу форматирования.
- Заражение вирусом или вредоносным ПО. Угрозы безопасности могут препятствовать операциям форматирования, что может привести к ошибке.
- Неисправное устройство хранения. Успешному форматированию может помешать физическое повреждение или неисправное устройство хранения.
Устранение ошибки «Windows не удалось завершить форматирование» может включать принятие соответствующих мер для решения этих возможных проблем.
Исправьте ошибку «Windows не удалось завершить форматирование».
1. Извлеките и снова подключите диск к другому USB-порту вашего компьютера.
Извлечение поврежденного диска и повторное подключение его к другому USB-порту вашего компьютера — это один из простых способов исправить ошибку «Windows не удалось завершить форматирование». Иногда причиной ошибки может быть неправильный USB-порт или плохое соединение. Сделав этот простой шаг, вы потенциально сможете решить проблему форматирования и приступить к форматированию устройства хранения данных в желаемом формате. Это также может помочь установить стабильное соединение.
2. Подключите накопитель к другой ОС (Mac).
Подключение поврежденного диска к другой операционной системе, например Mac, может помочь устранить ошибку «Windows не удалось завершить форматирование». Вы можете обойти ограничения Windows, используя инструменты и механизмы форматирования, уникальные для разных операционных систем. После подключения диска к Mac откройте Дисковую утилиту и попробуйте отформатировать диск там. Этот кросс-платформенный метод может помочь решить проблемы форматирования, уникальные для Windows, и обеспечить правильную работу форматирования в Mac OS.
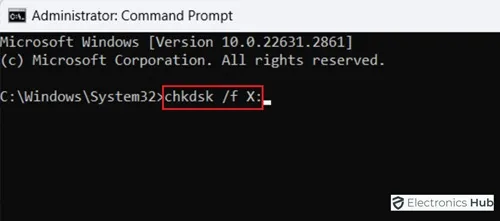
3. Запустите команду CHKDSK.
Используйте команду CHKDSK, чтобы исправить ошибку «Windows не удалось завершить форматирование». Нажмите Enter после открытия командной строки от имени администратора и ввода «chkdsk /f X:» (вставляя X в качестве буквы диска затронутого устройства). Ошибки диска проверяются и исправляются с помощью этой команды. После завершения попробуйте отформатировать устройство еще раз. Проблемы файловой системы можно устранить с помощью CHKDSK, который также может исправить ошибки форматирования и обеспечить успешное завершение процесса форматирования.

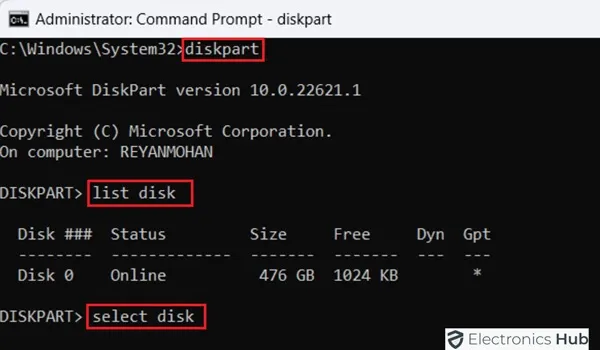
4. Использование командной строки
Попробуйте выполнить следующие действия, чтобы устранить ошибку «Windows не удалось завершить форматирование» с помощью командной строки. Начните с запуска командной строки в режиме администратора. После этого введите «diskpart» и нажмите Enter. После этого введите «list disk», чтобы просмотреть доступные диски, затем используйте «select disk [number]», чтобы выбрать нужный диск. Наконец, используйте команду «create partition primary» после ввода «clean», чтобы стереть все данные и разделы. Затем введите «format fs=ntfs» (или файловую систему по вашему выбору) и нажмите Enter, чтобы отформатировать диск.

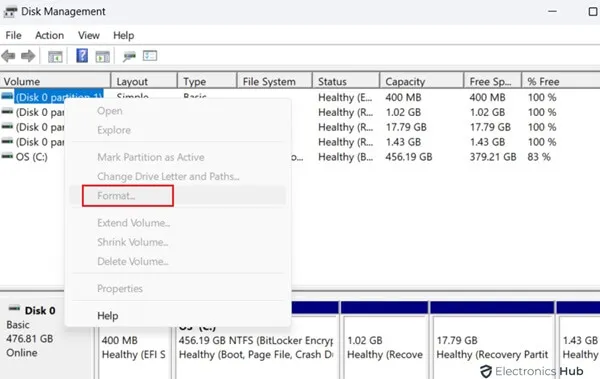
5. Использование управления дисками
Используйте «Управление дисками», чтобы исправить ошибку «Windows не удалось завершить форматирование». Вы можете добраться до него, найдя целевой диск, выбрав «Управление дисками», а затем щелкнув правой кнопкой мыши кнопку «Пуск». Чтобы изменить файловую систему, щелкните диск правой кнопкой мыши, выберите «Форматировать» и затем настройте. Убедитесь, что выбрано «Выполнить быстрое форматирование». Чтобы начать процесс форматирования, нажмите «ОК». Мощные функции управления дисками часто преодолевают препятствия форматирования, устраняя проблему и позволяя успешно отформатировать устройство хранения.

6. Проверьте и исправьте ошибки диска
Ошибки диска необходимо проверить и исправить, чтобы устранить ошибку «Windows не удалось завершить форматирование». Устройство хранения данных необходимо сначала вставить, прежде чем вы сможете щелкнуть его правой кнопкой мыши и выбрать «Свойства». Выберите «Проверить» в разделе «Проверка ошибок» на вкладке «Инструменты». Для сканирования и исправления ошибок диска следуйте инструкциям, отображаемым на экране. Устранив любые возможные проблемы с файловой системой, эта процедура увеличивает шансы на успешное форматирование и позволяет избавиться от ошибки.
7. Снимите защиту от записи
Прежде чем пытаться исправить ошибку «Windows не удалось завершить форматирование», вызванную защитой от записи, убедитесь, что на запоминающем устройстве нет физического переключателя защиты от записи. Переведите его в выключенное положение, если оно есть. Альтернативно вы можете отключить защиту от записи, изменив реестр или используя команды diskpart. После внесения этих изменений попробуйте отформатировать устройство еще раз. Устранив барьер защиты от записи, эта процедура позволяет успешно выполнить форматирование Windows без ранее упомянутой ошибки.
8. Проверьте наличие переключателя физической защиты от записи.
Первый шаг в исправлении ошибки «Windows не удалось завершить форматирование» — убедиться, что устройство хранения имеет физический переключатель защиты от записи. Если этот переключатель включен, операции записи прекращаются. Убедитесь, что переключатель разблокирован, найдя его на устройстве, которое обычно расположено сбоку или сзади. Попробуйте отформатировать устройство хранения данных через Windows еще раз после отключения защиты от записи, чтобы проверить, сохраняется ли проблема.
9. Используйте Дискпарт
Откройте командную строку с правами администратора, чтобы исправить ошибку «Windows не удалось завершить форматирование» с помощью Diskpart. Введите «diskpart» и нажмите Enter. Затем выполните такие команды, как «list disk», «select disk [disk number]», «clean» и «create partition primary». После этого отформатируйте раздел, используя «format fs=ntfs» (замените «ntfs» предпочитаемой файловой системой). Этот метод Diskpart часто решает проблемы форматирования, напрямую взаимодействуя с процессами разметки и форматирования диска.
10. Использование регистрационного ключа
Попробуйте отредактировать ключ реестра, чтобы устранить ошибку «Windows не удалось завершить форматирование». Нажмите Win+R, введите «regedit» и перейдите к «HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlStorageDevicePolicies». Если «WriteProtect» существует, установите его значение на 0; если нет, создайте новый DWORD с именем «WriteProtect» и установите для него значение 0. Перезагрузите систему, а затем попытайтесь снова отформатировать устройство хранения. Эта настройка реестра часто решает проблемы с защитой от записи, вызывающие ошибку форматирования.
11. Сканируйте свой компьютер на наличие вредоносного ПО
Рассмотрите возможность запуска сканирования вашего компьютера на наличие вредоносных программ, чтобы устранить ошибку «Windows не удалось завершить форматирование». Эта проблема может возникнуть из-за того, что вредоносное программное обеспечение мешает процедурам форматирования. Используйте надежное антивирусное или антивирусное программное обеспечение для выполнения комплексного сканирования системы. Удаляйте вредоносное ПО сразу же после его обнаружения, чтобы гарантировать чистоту среды. Сделайте большой шаг к решению проблемы, повторив процедуру форматирования после удаления вредоносного ПО и проверьте, возникает ли ошибка по-прежнему.
12. Используйте сторонний инструмент форматирования
Вы можете использовать сторонний инструмент форматирования, чтобы исправить ошибку «Windows не удалось завершить форматирование». Эти программы могут обойти некоторые ограничения, налагаемые операционной системой Windows, и часто предлагают сложные параметры форматирования. Выберите надежную стороннюю программу форматирования, следуйте конкретным инструкциям к ней и начните процедуру форматирования. Этот альтернативный метод может успешно решить проблему и упростить форматирование устройства хранения данных.
Windows не удалось завершить форматирование: часто задаваемые вопросы
1. Что означает ошибка «Windows не удалось завершить форматирование»?
Ответ: Когда появляется сообщение об ошибке «Windows не удалось завершить форматирование», это означает, что в операционной системе возникли проблемы при попытке отформатировать USB-накопитель или SD-карту. Успешному форматированию носителя могут препятствовать такие проблемы, как защита от записи, повреждение файловой системы, поврежденные сектора или проблемы совместимости.
2. Почему я могу столкнуться с ошибкой «Windows не удалось завершить форматирование»?
Ответ: Ряд факторов, включая защиту от записи на запоминающем устройстве, повреждение файловой системы, наличие поврежденных секторов, несовместимую файловую систему для форматирования, проблемы с USB-портом или кабелем, заражение вредоносным ПО или вирусом, а также физическое повреждение или неисправность. устройства хранения данных, может вызвать ошибку «Windows не удалось завершить форматирование». Устранение этих проблем может помочь исправить ошибку форматирования Windows.
3. Как снять защиту от записи на запоминающем устройстве, чтобы исправить ошибку «Windows не удалось завершить форматирование»?
Ответ: Сначала найдите физический переключатель защиты от записи на устройстве хранения, чтобы снять защиту от записи и исправить ошибку «Windows не удалось завершить форматирование». Если переключателя нет, откройте свойства диска в проводнике, выберите вкладку «Безопасность» и измените разрешения. Альтернативно вы можете очистить атрибуты защиты от записи и включить успешное форматирование с помощью командной строки и команды «diskpart».
4. Могу ли я использовать «Управление дисками», чтобы исправить ошибку «Не удалось завершить форматирование» в Windows?
Ответ: Да, вы можете исправить ошибку Windows «Windows не удалось завершить форматирование» с помощью «Управления дисками». Найдите целевой диск в «Управлении дисками», затем щелкните правой кнопкой мыши и выберите «Форматировать». Перед началом форматирования убедитесь, что вы выбрали подходящую файловую систему. Однако, если этот метод не работает, возможно, вам придется рассмотреть другие варианты, например, использовать стороннее программное обеспечение для форматирования или поискать защиту от записи.
5. Как устранить повреждение файловой системы, из-за которого Windows не смогла завершить ошибку форматирования?
Ответ: используйте командную строку, чтобы запустить проверку диска и устранить повреждение файловой системы, вызывающее ошибку «Windows не удалось завершить форматирование». Выполните команду «chkdsk /f X:» (вставьте сюда букву диска X). Этот инструмент выявит и устранит проблемы файловой системы. После завершения попробуйте еще раз отформатировать устройство хранения, чтобы исправить ошибку, связанную с повреждением файловой системы.
Заключение
Подводя итог, можно сказать, что ошибка «Windows не удалось завершить форматирование» — это неприятная проблема, которая часто возникает из-за поврежденных секторов, защиты от записи или повреждения файловой системы. Для исправления этой ошибки необходим системный подход, который может включать использование сторонних инструментов форматирования, таких как chkdsk, для устранения повреждения файловой системы или проверки защиты от записи. Каждое обстоятельство может потребовать разного ответа. Чтобы успешно отформатировать устройство хранения данных и устранить эту ошибку, потребуется настойчивость и тщательное рассмотрение деталей. Понимая и устраняя основные причины, пользователи могут эффективно преодолевать эти препятствия, гарантируя эффективное администрирование данных и удобство использования устройств в системах Windows.
2024-01-23T16:58:51
Вопросы читателей