Ошибка управления памятью стоп-кода Windows обычно возникает, когда в системе возникают проблемы, связанные с выделением и управлением памятью. Память — это важный компонент вашего компьютера, в котором хранятся данные и инструкции для ваших программ и процессов. Когда вы запускаете несколько приложений или выполняете сложные задачи, вашей системе необходимо эффективно и правильно выделять и освобождать память. Процесс управления памятью поддерживает и записывает каждую ячейку памяти, независимо от того, выделена она или нет. Однако если что-то пойдет не так при распределении памяти, это может привести к сбою системы или ошибке управления памятью синего экрана. В этой статье рассматривается распространенная причина этого и некоторые возможные решения по исправлению ошибки управления памятью стоп-кода Windows.
Ошибка управления памятью в Windows 10
Управление памятью стоп-кода Windows может быть вызвано различными факторами, такими как неисправное оборудование, поврежденные драйверы, заражение вредоносным ПО или неправильные настройки системы. В зависимости от причины ошибка может возникать случайно или часто и может помешать вам нормально использовать компьютер.
- Проблема с картой памяти (ОЗУ) или Если ОЗУ работает неправильно, это может вызвать нестабильность в системе и вызвать управление памятью bsod.
- Опять же, устаревшие, поврежденные или несовместимые драйверы устройств могут мешать правильному управлению памятью, что приводит к появлению синего экрана управления памятью Windows.
- Иногда поврежденные системные файлы нарушают нормальную работу системы управления памятью, вызывая нестабильность в системе.
- Некоторые приложения или компоненты программного обеспечения могут быть несовместимы с конфигурацией системы, что приводит к конфликтам, приводящим к ошибкам управления памятью.
- Разгон процессора, графического процессора или оперативной памяти сверх рекомендованных пределов может создать дополнительную нагрузку на систему и привести к ошибкам, связанным с памятью.
Отключите внешние устройства и перезагрузите компьютер.
Всякий раз, когда у вас возникают проблемы с компьютером, первым делом вам необходимо перезагрузить Windows. Да, это простое исправление может решить любые проблемы Windows 10, включая ошибку управления памятью синего экрана Windows. Иногда неисправное внешнее устройство может вызвать проблемы, связанные с памятью, поэтому его отключение может быть полезным шагом для устранения неполадок. Итак, прежде чем пытаться что-либо еще, отключите все внешние устройства и перезагрузите компьютер. Это поможет, если какой-либо временный сбой или конфликт драйверов приведет к сбою Windows 10.
- Выключите компьютер и отключите все внешние устройства, включая USB-накопители, принтеры и внешние устройства хранения данных.
- Перезагрузите компьютер и проверьте, сохраняется ли ошибка управления памятью. Если ошибка исчезла, подключите внешние устройства по одному, чтобы выявить виновника.
Отключение внешних устройств, таких как USB-накопители, принтеры или внешние устройства хранения данных, может помочь изолировать ошибки управления памятью, вызванные неисправными или несовместимыми периферийными устройствами.
Выполните восстановление при запуске
Если Windows не загружается должным образом, восстановление при загрузке может помочь диагностировать и устранить проблемы, препятствующие правильной загрузке операционной системы. Startup Repair сканирует и автоматически устраняет распространенные проблемы, которые могут вызывать ошибки управления памятью во время запуска, например поврежденные системные файлы или неправильно настроенные параметры загрузки.
Чтобы выполнить восстановление при запуске, вам необходимо запустить компьютер с установочного носителя и использовать расширенный доступ.
- Вставьте установочный носитель Windows (USB-накопитель или DVD) и перезагрузите компьютер.
- При появлении соответствующего запроса нажмите любую клавишу для загрузки с установочного носителя.
- Выберите язык, время, валюту и настройки клавиатуры и нажмите «Далее».
- Нажмите «Восстановить компьютер» в левом нижнем углу.
- Выберите «Устранение неполадок» > «Дополнительные параметры» > «Восстановление при запуске» и следуйте инструкциям на экране, чтобы устранить любые проблемы с запуском.

Загрузитесь в безопасном режиме
Если восстановление при запуске не помогает решить проблему, загрузка в безопасном режиме позволяет Windows загружаться только с необходимыми драйверами и службами, что может помочь определить, является ли стороннее программное обеспечение или драйвер причиной ошибки управления памятью.
Снова откройте параметр «Дополнительно», используя установочный носитель, на этот раз выберите параметры запуска и нажмите «Перезагрузить».
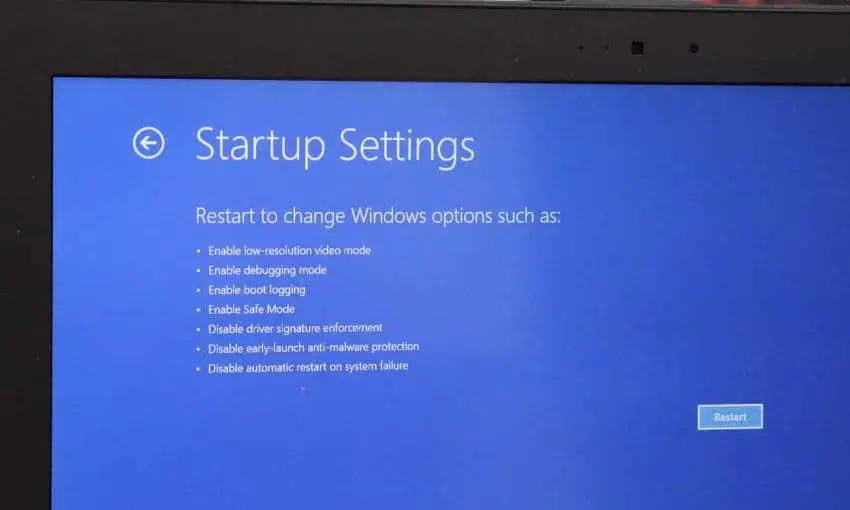
В параметрах настроек запуска нажмите F4, чтобы включить безопасный режим. F5 включает доступ в Интернет в безопасном режиме.

Если ошибка не возникает в безопасном режиме, это указывает на то, что причиной может быть недавно установленное программное обеспечение или драйвер.
Запустите средство диагностики памяти Windows.
Это первое, что вам следует сделать, если вы столкнулись с ошибкой управления памятью синего экрана в Windows 10. Средство диагностики памяти Windows запускает серию тестов, чтобы проверить вашу оперативную память на наличие ошибок и предложить возможные исправления. ОЗУ — это физическая память, которую ваша система использует для хранения данных и быстрого доступа к ним. Если ваша оперативная память неисправна или несовместима, это может вызвать ошибки, связанные с памятью.
- Нажмите Windows+R, введите mdsched.exe и нажмите «ОК».
- Откроется средство диагностики памяти Windows.
Вы увидите два варианта: «Перезагрузить сейчас и проверить наличие проблем» или «Проверить наличие проблем при следующем запуске компьютера». Выберите вариант, который подходит вам лучше всего.

Ваш компьютер перезагрузится, и инструмент просканирует вашу память на наличие ошибок. Если он их обнаружит, он отобразит их на экране и предложит возможные решения. Для получения точных результатов важно, чтобы инструмент мог завершить процесс тестирования без перерывов.

Вы можете проверить результаты диагностики памяти здесь . Если да, то вам придется либо заменить оперативную память самостоятельно, либо отправить компьютер обратно, если он находится на гарантии.
Кроме того, вы можете использовать MemTest86 для выполнения углубленного теста памяти.
Настройте параметры виртуальной памяти
Виртуальная память — это функция, которая позволяет вашей системе использовать часть жесткого диска в качестве расширения оперативной памяти. Это может улучшить производительность вашей системы и предотвратить ошибки, связанные с памятью. Однако если настройки вашей виртуальной памяти не оптимальны, они также могут вызвать проблемы.
- Нажмите Windows+Pause/Break, чтобы открыть окно «Система».
- Нажмите «Дополнительные параметры системы» на левой панели.
- Перейдите на вкладку «Дополнительно», а затем нажмите «Настройки» в разделе «Производительность».
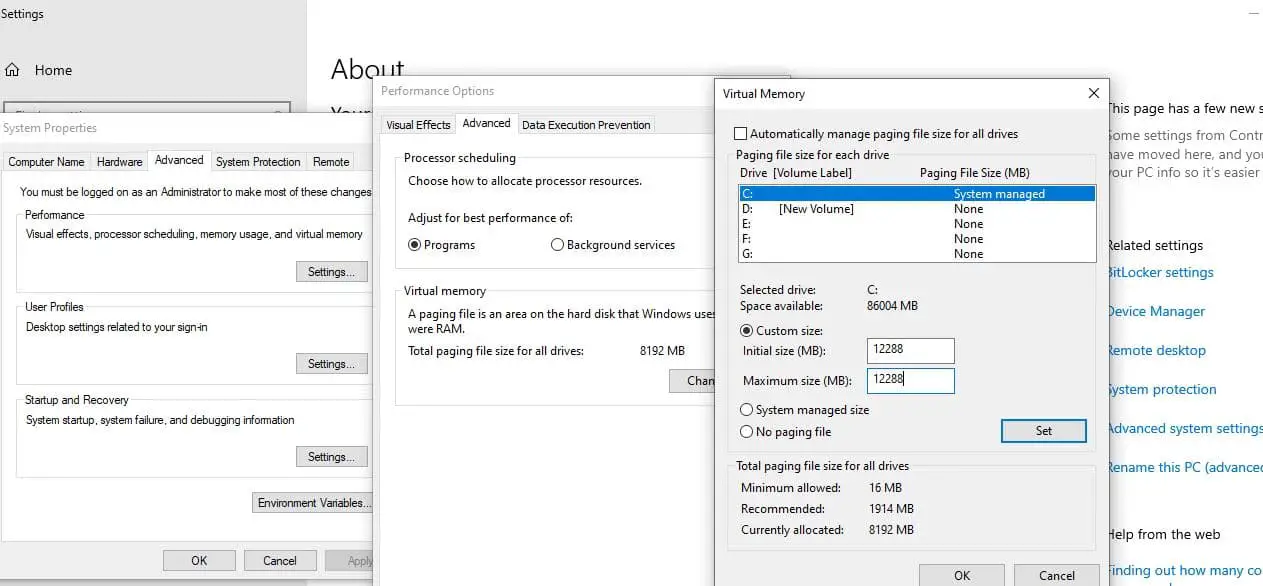
- Снова нажмите вкладку «Дополнительно», а затем нажмите «Изменить» в разделе «Виртуальная память».
- Снимите флажок «Автоматически управлять размером файла подкачки для всех дисков».
- Выберите системный диск (обычно C:) и нажмите «Нестандартный размер».
Введите значение, которое в 1,5 раза превышает общий объем оперативной памяти, в полях «Начальный размер» и «Максимальный размер». Например, если у вас 8 ГБ ОЗУ, введите в оба поля 12288 МБ.
Нажмите «Установить», а затем нажмите «ОК». Перезагрузите компьютер и проверьте, устранена ли ошибка.
Обновите поврежденный драйвер устройства
Другой распространенной причиной ошибки управления памятью стоп-кода Windows являются устаревшие или несовместимые драйверы. Драйверы — это программные компоненты, которые позволяют вашим аппаратным устройствам взаимодействовать с вашей операционной системой. Если они не обновлены или несовместимы, они могут вызвать конфликты и ошибки. Поэтому, чтобы исправить ошибку, вам необходимо обновить необходимый драйвер до самой последней правильной версии.
Хотя Диспетчер устройств — это удобный встроенный инструмент для обновления драйверов, вы также можете рассмотреть возможность использования стороннего программного обеспечения для обновления драйверов для более полного процесса сканирования и обновления.
- Щелкните правой кнопкой мыши кнопку «Пуск» и в меню выберите «Диспетчер устройств».
- В диспетчере устройств разверните категории аппаратных компонентов, которые вы хотите обновить, например «Видеоадаптеры» для драйверов видеокарты.
- Щелкните правой кнопкой мыши устройство, которое хотите обновить, и выберите «Обновить драйвер».
- Выберите либо «Автоматический поиск обновленного программного обеспечения драйвера», чтобы позволить Windows искать последние версии драйверов в Интернете, либо «Просмотреть программное обеспечение драйвера на моем компьютере», если вы загрузили файлы драйверов вручную.

- Следуйте инструкциям на экране, чтобы завершить процесс обновления драйвера, перезагрузите компьютер, чтобы применить изменения.
Кроме того, вы можете посетить веб-сайт производителя устройства, чтобы загрузить и установить последнюю доступную версию драйвера для вашей системы. (Особенно драйвер дисплея, сетевой адаптер и аудиодрайвер)
Запустите команду SFC и DISM.
Тем не менее, возникает ошибка управления памятью? Это может быть связано с тем, что важные системные файлы повреждены или повреждены из-за сбоя питания, ошибки диска или заражения вредоносным ПО. Запустите средства проверки системных файлов (SFC) и обслуживания образов развертывания и управления ими (DISM) для сканирования и восстановления поврежденных системных файлов.
Сначала откройте командную строку с правами администратора. Нажмите клавишу Windows, введите cmd, щелкните правой кнопкой мыши командную строку и выберите «Запуск от имени администратора».
- Сначала запустите команду «
sfc /scannow», чтобы просканировать и восстановить поврежденные системные файлы. - После завершения сканирования SFC запустите команду «
DISM /Online /Cleanup-Image /RestoreHealth», чтобы исправить любые повреждения хранилища компонентов. - Дождитесь завершения сканирования. Это может занять до 20 минут, в зависимости от состояния вашей системы.
- Когда процесс завершится, выйдите из командной строки и перезагрузите компьютер.

Установите последние обновления Windows
Устаревшие версии Windows 10 или системные файлы могут вызывать непредвиденные ошибки. Проверка и установка ожидающих обновлений — еще один быстрый и простой способ выяснить, вызывает ли это ошибку синего экрана.
- Нажмите Windows+I, чтобы открыть приложение настроек,
- Нажмите «Обновление и безопасность», затем «Центр обновления Windows».
- Нажмите кнопку «Проверить наличие обновлений». При наличии последних обновлений будут загружены и установлены.
- Перезагрузите Windows, чтобы применить изменения, и проверьте, не возникает ли больше ошибка BSOD.
Сканируйте вашу систему на наличие вредоносных программ
Кроме того, выполните полное сканирование системы с помощью безопасности Windows или стороннего антивируса, чтобы удалить любые вредоносные программы, которые могут вызвать эту ошибку. Сканирование во время загрузки выполняется до полной загрузки Windows, что упрощает обнаружение и удаление вредоносных программ, которые могут активно мешать процессам управления памятью.