Microsoft всячески продвигает искусственный интеллект и добавила Copilot в Windows 11 в качестве функции по умолчанию. Copilot — это чат-бот на основе искусственного интеллекта (ИИ), который сочетает в себе возможности системного поиска Windows и онлайн-поиска Bing в диалоговом формате. Ранее известный как Bing Chat, теперь он переименован в Copilot и доступен в виде значка на панели задач. Все, что вам нужно, это просто щелкнуть значок Copilot и ввести или произнести свой вопрос, чтобы получить ответ. Однако при работе с Copilot вы можете столкнуться со многими проблемами, и вот как их исправить.
Читать
Архив автора: admin
Почему торренты снова в моде и чем так хорош μTorrent?
Торрент-трекеры — наше все. Такой лозунг негласно существовал в начале 2000-х годов. К нему, похожу, придется вернуться. Для этого достаточно установить на компьютер или телефон BitTorrent-клиент. И мы рекомендуем μTorrent.
Как изменить цветовую схему Vim
Vim — один из самых мощных текстовых редакторов UNIX, с которыми вы можете справиться. Это преемник текстового редактора vi (доступного во всех системах UNIX). Vim является бесплатным и открытым исходным кодом с множеством функций и параметров настройки. На самом деле, в нем есть все, что вы ожидаете от любого современного текстового редактора. Также доступно множество надстроек для расширения функциональных возможностей. В этой статье мы сосредоточимся на цветовых схемах Vim. Читать
Для чего нужны курсы по информационной безопасности?
Курсы по информационной безопасности обеспечивают всестороннее обучение фундаментальным принципам, концепциям и практикам кибербезопасности. От понимания основ криптографии и сетевой безопасности до изучения систем управления рисками и соответствия требованиям, эти курсы охватывают широкий спектр тем, необходимых для создания прочной основы в области информационной безопасности.
По последним данным, спрос на специалистов в области кибербезопасности растет с каждым годом. Не секрет, что все данные, даже самые чувствительные, хранятся в информационных системах и очень важно уметь их защищать. Читать
Как удалить приложение с компьютера Windows 10
Если нужно удалить установленное приложение с компьютера под управлением Windows 10, то разберем как это сделать.
Как удалить приложение через параметры Windows 10
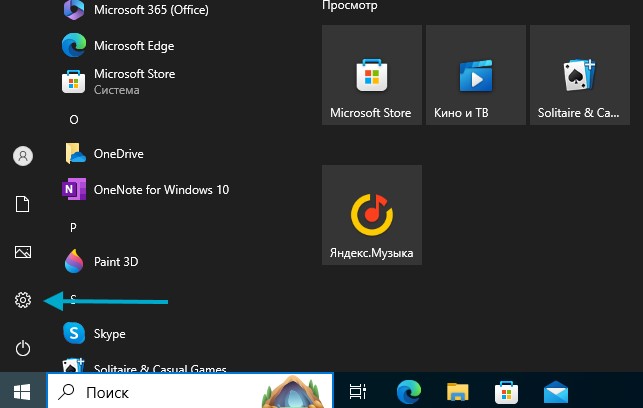
1. Откройте «Параметры» нажав на пуск и иконку в виде шестеренки.
WordPress. Удалить изображения ко всем постам
Появилась необычная задача. Потребовалось открепить от всех публикаций в WordPress их «изображения записи». Но при этом требовалось оставить сами изображения в медиафайлах. Читать