В мире программирования компилятор выступает в качестве важнейшего связующего звена между читаемым человеком кодом и машиноисполнимыми инструкциями. Это безмолвный архитектор, который превращает наши абстрактные идеи в осязаемые действия, которые должны выполнять компьютеры. Процесс компиляции кода — это не единая монолитная задача, а скорее сложное путешествие, разделенное на отдельные этапы. Каждый этап играет определенную роль в процессе преобразования, гарантируя, что код не только синтаксически корректен, но и оптимизирован для эффективного выполнения. В этой статье мы углубляемся в различные этапы компилятора, раскрывая волшебство, которое позволяет нашему коду ожить.
Что такое компилятор?
Компилятор — это тип программного средства, которое преобразует высокоуровневый программный код, написанный людьми, в машиночитаемые инструкции, которые может выполнять компьютер. По сути, он действует как посредник между программистом и аппаратным обеспечением компьютера. Основная цель компилятора — преобразовать исходный код, часто написанный на таких языках, как C, C ++, Java или Python, в исполняемый машинный код, который центральный процессор компьютера может понять и выполнить.
Процесс компиляции включает в себя несколько отдельных этапов, каждый из которых играет определенную роль в преобразовании исходного кода в исполняемый код. Эти этапы включают лексический анализ, синтаксический анализ (синтаксический разбор), семантический анализ, генерацию промежуточного кода, оптимизацию кода, генерацию кода и управление таблицами символов. Каждый этап вносит свой вклад в обеспечение того, чтобы результирующая программа была правильной, эффективной и оптимизированной для целевой аппаратной архитектуры.
Как только исходный код скомпилирован, результирующий исполняемый код можно запускать несколько раз без необходимости перекомпиляции, при условии, что целевое оборудование и операционная система остаются неизменными. Это в отличие от интерпретируемых языков, где исходный код выполняется непосредственно интерпретатором при каждом запуске программы.
Подводя итог, можно сказать, что компилятор является важнейшим инструментом в процессе разработки программного обеспечения, позволяющим программистам писать код на понятных человеку языках, позволяя компьютерам эффективно выполнять код. Это облегчает перевод абстрактной логики в конкретные машинные инструкции, позволяя создавать широкий спектр программных приложений.
Прежде чем перейти к этапам компилятора, давайте посмотрим, что представляет собой таблица символов.
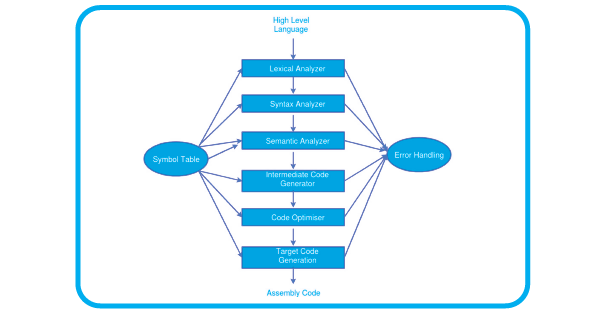
Что такое таблица символов?
Он представляет управляемую компилятором структуру данных, включающую имена и соответствующие им типы идентификаторов. Это помогает компилятору эффективно работать, облегчая быструю идентификацию идентификаторов. Анализ исходной программы обычно разбивается на три этапа. Следующим образом:
- Линейный анализ – включает в себя чтение потока символов слева направо на этапе сканирования. Затем он разделяется на несколько токенов с более широким значением.
- Иерархический анализ – На этом этапе анализа, на основе коллективного значения, токены иерархически распределяются по вложенным группам.
- Семантический анализ – Этот этап используется для проверки того, являются ли компоненты исходной программы значимыми или нет.Компилятор состоит из двух модулей, а именно внешнего интерфейса и серверной части. Внешний интерфейс представляет собой лексический анализатор, семантический анализатор, синтаксический анализатор и генератор промежуточного кода. А остальные собираются для формирования внутреннего интерфейса.
Давайте обсудим все этапы компилятора один за другим.
Этапы компилятора
Вот список этапов компилятора с некоторыми важными моментами.
- Лексический анализатор: в качестве альтернативы его называют сканером. Принимая в качестве входных данных выходные данные препроцессора (ответственного за включение файлов и расширение макросов) на чистом языке высокого уровня, он обрабатывает символы из исходной программы, объединяя их в лексемы – последовательности символов, обладающие связностью. Каждой лексеме соответствует токен, который определяется регулярными выражениями, понятными лексическому анализатору. Более того, лексический анализатор устраняет лексические ошибки (такие как ошибочные символы), комментарии и пробелы.
- Синтаксический анализатор: Синтаксический анализ, или синтаксический разбор, является вторым этапом компилятора. На этом этапе проверяется поток токенов, созданных на этапе лексического анализа, чтобы увидеть, соответствуют ли они грамматике языка программирования. Результатом этого этапа часто является абстрактное синтаксическое дерево (AST).
- Семантический анализатор: проверяет, является ли дерево синтаксического анализа значимым. Дополнительно создается подтвержденное дерево синтаксического анализа. Дополнительно он выполняет проверки типа, метки и управления потоком.
- Генератор промежуточного кода: он создает промежуточный код, представляющий собой формат, который машина может легко выполнить. Мы предлагаем множество популярных промежуточных кодов. Например, три адресных кода. Последние два процесса, которые зависят от платформы, переводят промежуточный код на машинный язык.
- Каждый существующий компилятор создает промежуточный код одинаковым образом, но после этого платформа определяет, как все работает. Нам не нужно создавать новый компилятор с нуля. Последние два компонента могут быть созданы с использованием промежуточного кода из уже существующего компилятора.
- Оптимизатор кода: он изменяет код, чтобы заставить его использовать меньше ресурсов и выполняться быстрее. Измененный код сохраняет свое первоначальное значение. Существует два типа оптимизации: машинно-зависимая и машинно-независимая.
- Генератор целевого кода: Основной задачей генератора целевого кода является написание кода, который может быть понятен машине, наряду с распределением регистров, выбором команд и т.д. Тип ассемблера определяет выходные данные. Это последний шаг в процессе компиляции. Оптимизированный код преобразуется в перемещаемый машинный код и используется в качестве входных данных компоновщика и загрузчика.
- Согласно приведенной выше блок-схеме, все шесть из этих этапов связаны с менеджером таблицы символов и обработчиком ошибок.
Преимущества этапов компилятора
Процесс компиляции разделен на несколько этапов, каждый со своими специфическими задачами и преимуществами. Эти этапы вносят вклад в общую эффективность, точность и управляемость компилятора. Вот некоторые преимущества наличия отдельных этапов в компиляторе:
- Модульность и простота разработки: Разделение процесса компиляции на этапы позволяет разработчикам сосредоточиться на конкретных задачах на каждом этапе. Этот модульный подход упрощает разработку и обслуживание компилятора, поскольку разные эксперты могут работать на разных этапах.
- Эффективность: Разбиение процесса компиляции на этапы позволяет проводить оптимизацию, специфичную для каждого этапа. Это означает, что каждый этап может сосредоточиться на своем собственном наборе оптимизаций, что приводит к более эффективному общему процессу компиляции.
- Параллелизм: отдельные этапы могут выполняться параллельно, особенно с современными многоядерными процессорами. Такой параллелизм ускоряет процесс компиляции, поскольку разные этапы могут работать над разными частями исходного кода одновременно.
- Изоляция ошибок: выделяя ошибки для определенных этапов, становится проще находить и отлаживать проблемы в коде. Если ошибка возникает на определенной фазе, более вероятно, что основная причина связана с этой конкретной фазой.
- Независимость от языка: Ранние этапы компилятора, такие как лексический анализ и синтаксический анализ, имеют дело с синтаксисом языка. Изолируя эти этапы, остальная часть компилятора может сосредоточиться на преобразовании синтаксического дерева в целевой код, что упрощает адаптацию компилятора к различным языкам программирования.
- Оптимизация: Отдельные этапы оптимизации могут быть сосредоточены на различных аспектах улучшения кода, таких как постоянное сворачивание, оптимизация цикла и распределение регистров. Это обеспечивает более целенаправленный и эффективный процесс оптимизации.
- Переносимость: Разделение этапов может упростить перенос компилятора на разные платформы или архитектуры. Пока интерфейс (ранние фазы) может обрабатывать синтаксис целевого языка, серверная часть (более поздние фазы) может быть адаптирована для генерации кода для различных архитектур.
- Гибкость: Если вы хотите внести изменения или усовершенствования в определенный аспект компилятора, вы можете сосредоточиться на соответствующем этапе, не влияя на весь процесс компиляции.
- Инкрементная компиляция: Некоторые компиляторы поддерживают инкрементную компиляцию, при которой перекомпилируются только измененные части кода. Модульный характер этапов позволяет использовать эту функцию, поскольку так проще определить, какие части компиляции необходимо обновить.
- Уровни оптимизации: Компиляторы часто предлагают различные уровни оптимизации, которые позволяют сократить время компиляции ради производительности кода. Модульность этапов позволяет применять больше или меньше оптимизаций в зависимости от желаемого компромисса.
Заключение
В сложном мире языков программирования и разработки программного обеспечения компиляторы играют ключевую роль в преобразовании удобочитаемого кода в машиноисполнимые инструкции. Концепция разделения процесса компиляции на отдельные фазы является фундаментальным подходом, который повышает эффективность, точность и адаптивность этих мощных инструментов.
Каждый этап, от лексического анализа до генерации кода, служит определенной цели, внося свой уникальный набор преимуществ в общий процесс компиляции. Разбивая сложную задачу перевода исходного кода в исполняемые программы, компиляторы становятся более управляемыми, позволяя разработчикам сосредоточиться на оптимизации конкретных аспектов процесса. Эта модульность также облегчает идентификацию и изоляцию ошибок, делая процесс отладки более плавным.
Часто задаваемые вопросы по этапам компилятора
Вот несколько часто задаваемых вопросов по этапам компилятора.
1. Каковы этапы компилятора?
Фазы компилятора представляют собой последовательные этапы, посредством которых исходный код преобразуется в исполняемый код. Эти фазы включают лексический анализ, синтаксический анализ, семантический анализ, оптимизацию, генерацию кода и оптимизацию кода.
2. Почему в компиляторе существуют разные фазы?
Разделение процесса компиляции на этапы дает ряд преимуществ. Это повышает модульность, упрощая разработку и обслуживание. Каждый этап может быть сфокусирован на конкретных задачах, что приводит к более эффективной оптимизации. Это также обеспечивает изоляцию ошибок и параллелизм, способствуя более оптимизированному и адаптируемому процессу компиляции.
3. Как этапы компиляции способствуют идентификации ошибок?
Каждая фаза компилятора обрабатывает определенные аспекты анализа кода. Ошибки, выявленные на одной фазе, с большей вероятностью связаны с этим конкретным аспектом кода. Это упрощает поиск, диагностику и исправление ошибок, что приводит к более эффективному процессу отладки.
4. Могут ли фазы компилятора выполняться параллельно?
Да, многие современные компиляторы используют преимущества многоядерных процессоров, выполняя различные этапы параллельно. Такой параллелизм ускоряет процесс компиляции и более эффективно использует аппаратные ресурсы.
5. Все ли языки программирования используют одни и те же этапы компиляции?
Хотя базовая структура этапов компиляции остается неизменной, детали каждого этапа могут варьироваться в зависимости от синтаксиса и семантики языка программирования. Некоторым языкам могут потребоваться дополнительные этапы или модификации существующих для обработки их специфических функций.
6. Как этапы компиляции способствуют оптимизации?
Различные этапы компилятора фокусируются на различных аспектах оптимизации кода, таких как постоянное сворачивание, развертывание цикла и распределение регистров. Этот целенаправленный подход позволяет проводить более эффективную оптимизацию, адаптированную к конкретным характеристикам кода.