Она решает вопрос создания вашего внутреннего побуждающего импульса для достижения желаемых результатов в жизни.
И для этого сегодня предлагаем вашему вниманию лучшие способы и техники для самомотивации.
Используя их, Вам не нужно будет искать «волшебную таблетку» или «ускоряющий пендель» извне. Вы сможете находить ресурсы для мотивации к действиям в самом себе, чтобы легко достигать своих целей…
Доброго времени суток, уважаемые читатели! Продолжаем изучать новые фишки блоггинга и заработка в интернете. Сегодня я расскажу Вам, как создать почту со своим доменом. Возможно, Вы неоднократно видели на различных сайтах, что адрес почтового ящика для связи с его владельцем выглядит примерно так admin@домен.ru Какие эмоции у Вас вызывает такой почтовый ящик? Хотели бы и Вы себе такую почту?
Зачем нужна почта для домена?
Любой блоггер может указать для связи просто свой имейл. Или установить форму обратной связи через которую письмо будет приходить на Ваш имейл, а отправитель не будет знать Вашего почтового ящика до тех пор, пока Вы ему не ответите обратным письмом.
Зачем тогда нужна почта с доменом сайта? К красивых коротких имейл адресов с годами все меньше и меньше. Чаще всего при регистрации своего первого почтового ящика мы не проявляем изобретательность, и чтобы побыстрее зарегистрировать имейл добавляем в конце циферку и все. А потом оказывается, что этот имейл бессмысленный, не несет никакой информации о его владельце. Оригинальная почта на своем домене позволяет выделить из толпы и заявить о себе. Для кампаний почта с названием сайта – это прежде всего статус. Для не коммерческого проекта почтовый ящик такого вида, подчеркнет его серьезность и статус. Как по мне, то еще один плюс такого имейла – возможность заявить о себе. К примеру, можно указать в комментарии имейл для связи и сразу будет видно, что он принадлежит владельцу сайта, домен которого, указан в нем. А это возможность привлечь дополнительных посетителей.
А как Вы считаете, есть ли польза от почты с именем сайта, или ее настройка пустая трата времени? Высказывайтесь в комментариях.
А теперь рассмотрим как привязать почту к домену. Я рассмотрю три наиболее популярные почты яндекса, гугла и майл.
Настройка почты для домена Google (Гугл)
Почта для домена google предоставляется бесплатно всего на 30 дней. Далее Вам предложат оплачивать по 5 долларов ежемесячно за использование услуги Google Apps. Если Вы не готовы к таким расходам, делайте настройку почты yandex для домена. Инструкция ниже.
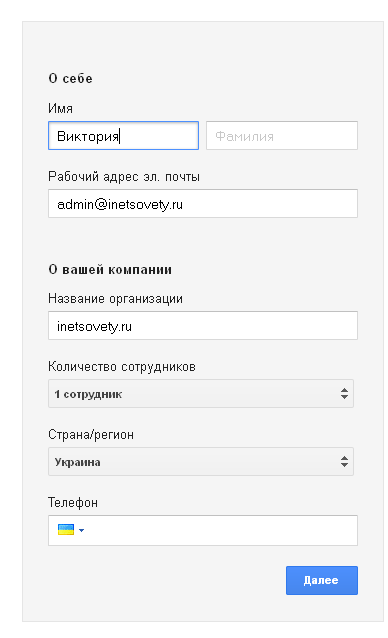
Для создания почты Гугл для домена переходите по ссылке По средине экрана Вы увидите зеленую кнопку с надписью «Начать здесь». После клика по ней откроется вот такая страничка:
Заполняйте все поля формы. Придумайте свой брендовый имейл.
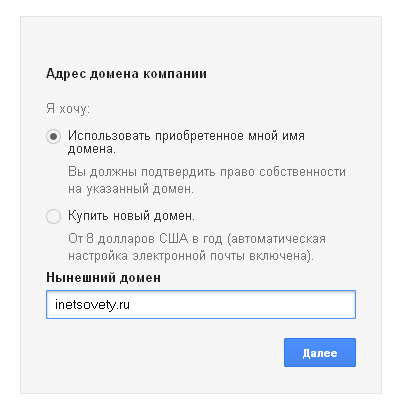
На следующем шаге выберите «использовать приобретенное имя»:
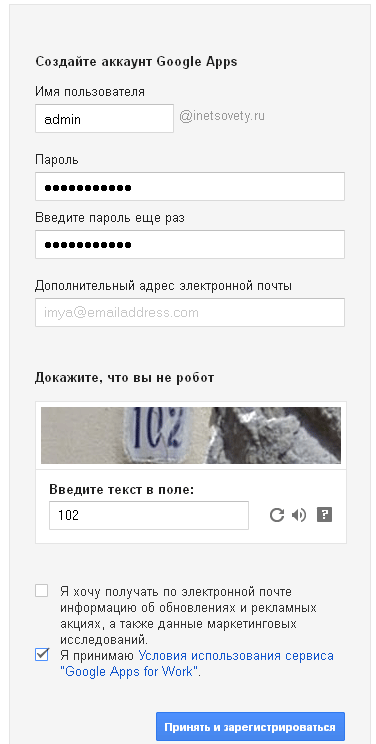
На последнем шаге регистрации укажите имя пользователя, пароль и согласитесь с правилами системы.
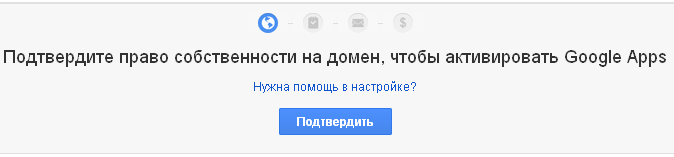
Регистрация окончена, переходите к настройкам Google Apps:
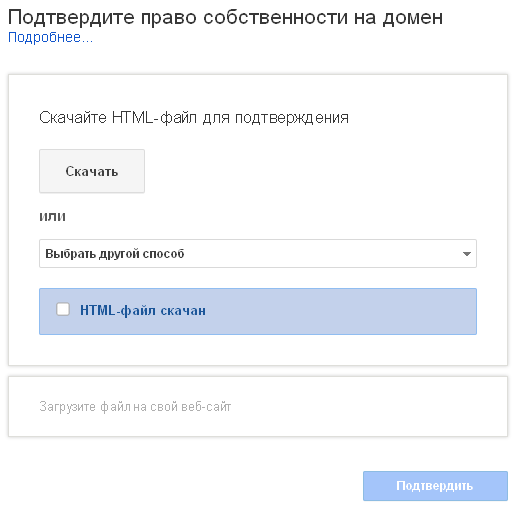
Первое, что Вам нужно сделать – подтвердить право собственности на домен:
Я обычно выбираю подтверждение прав через загрузку файла на хостинг, но Вы можете выбрать для себя другой способ из списка.
Скачиваете файл, загружаете его на папку public_html, проверяете открывается ли файл по нужному адресу и подтверждаете проверку прав собственности.
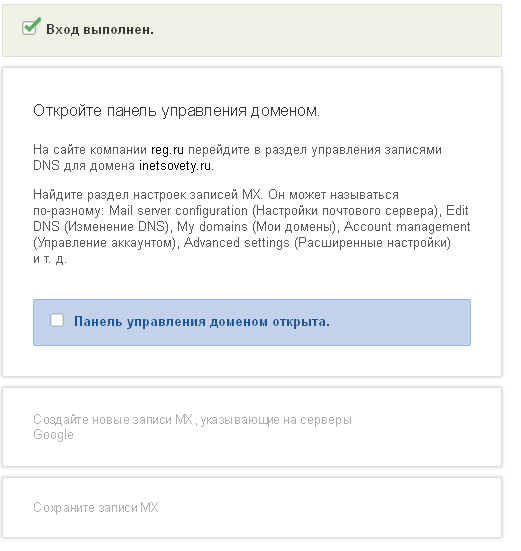
Последний этап настройки gmail почты для домена – создание MX записей для перенаправления почты на красивый почтовый ящик. Следуйте пунктам инструкции на странице гугла.
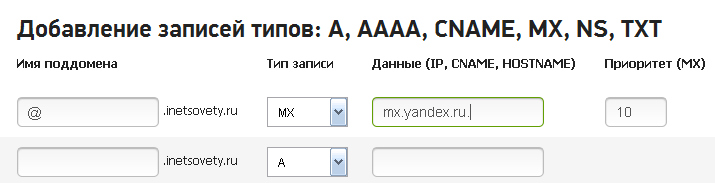
Пересказывать каждый шаг не буду. Расскажу, что необходимо сделать на сайте регистратора доменного имени. У меня это 2domains. В панели управления доменом выбирайте «Управление зоной DNS». Ни в коем случае не удаляйте DNS сервера хостера, иначе сайт перестанет работать. Находите форму добавления записей:
В ней выбирайте тип добавляемой записи MX, данные хоста, которые указаны у Google Apps и приоритет. Заполняйте все строки последовательно. После этого нажмите на кнопку добавить.
Готово!
Почта для домена Яндекс (yandex)
Yandex почта для домена пока бесплатная в отличии от Google. Говорю пока, потому что все может поменяться. Настройка почты яндекс для домена во многом схожа с рассмотренной выше гугловской почтой.
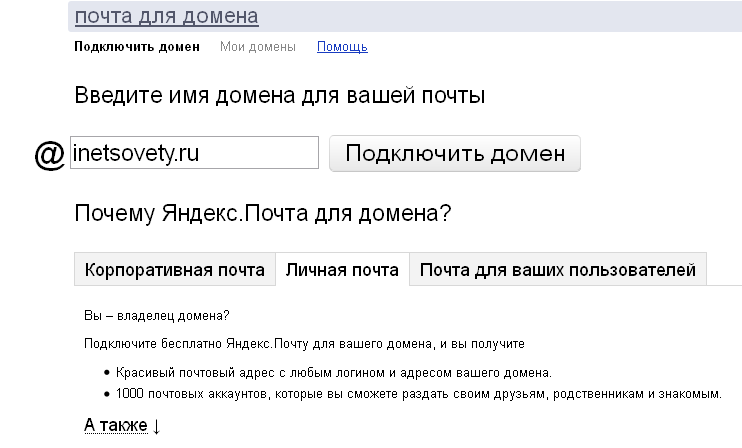
Перед тем, как подключить яндекс почту к домену нужно зарегистрировать почтовый ящик в Яндеке. Если он у Вас уже есть, просто заходите в аккаунт. Кликайте по ссылке и на открывшейся странице вводите тот домен, который хотите подключить к почте Яндекса.
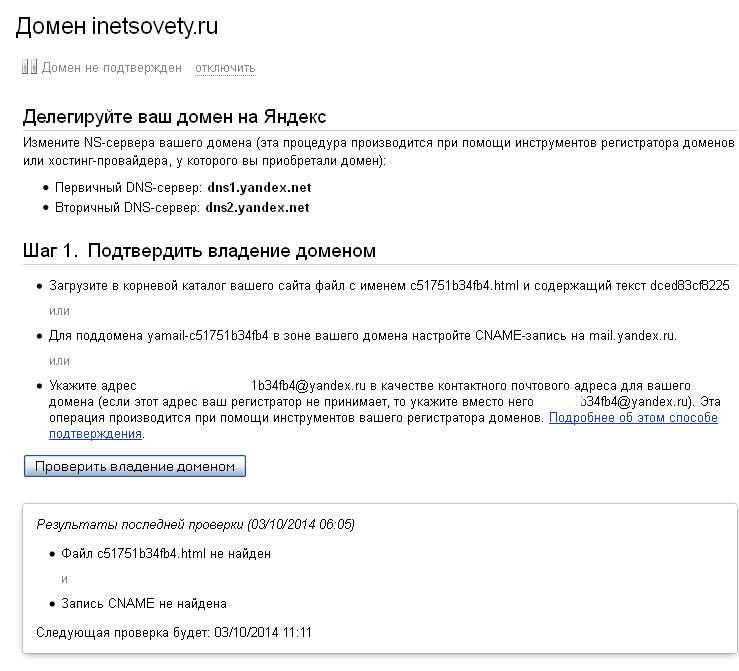
На следующем этапе подтверждаем, что именно Вы владелец этого домена. На рабочем столе создайте текстовый документ и назовите его именно так, как хочет Яндекс. Внутрь его добавьте проверочный текст и сохраните его. Загрузите этот файл в папку public_html. Если яндекс пишет, что проверочный файл не найден, проверьте расширение загруженного файла, чтобы на конце не было .txt. Если оно присутствует — удалите его.
Делегировать домен на Яндекс не нужно!
На втором этапе, прописываем MX-записи у регистратора домена. Куда заходить и где их прописывать я объясняла на примере настройки Гугл почты с доменным именем Вашего сайта. Посмотрите.
Не пропустите точку на конце строки mx.yandex.ru.
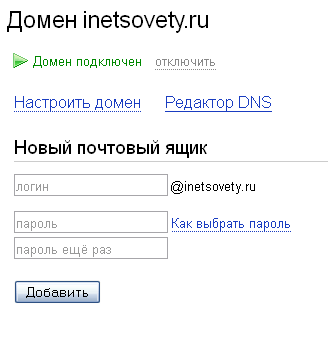
Если Вы все сделали правильно, через некоторое время увидите надпись «Домен подключен». Осталось указать желаемый логин почты и пароль к нему.
После этого войдите в почтовый ящик:
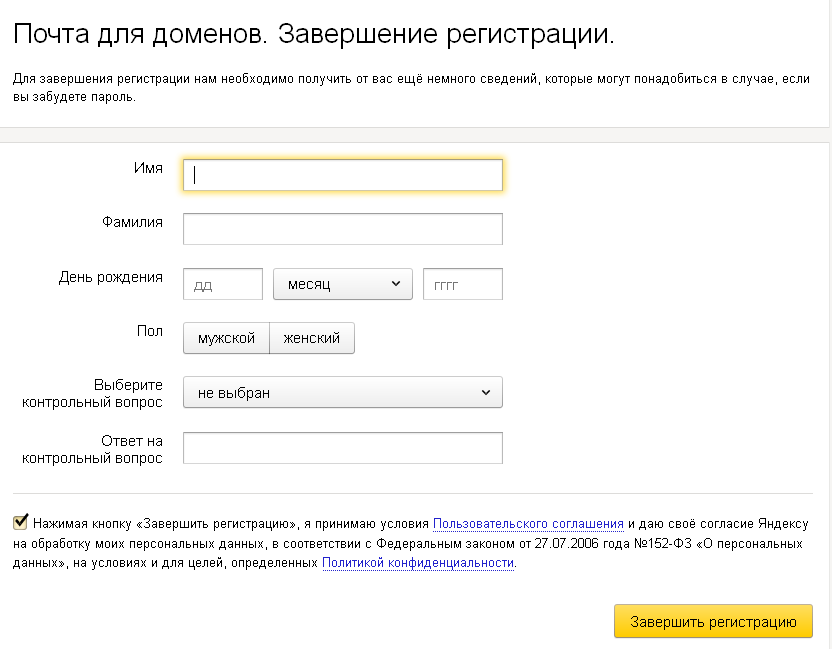
После первого входа заполните регистрационную форму:
Вот собственно и все. При желании можете подключить перенаправление писем из других почтовых ящиков на этот.
Вот так происходит подключение почты к домену. Проделав все шаги Вы получите свой красивый почтовый ящик на домене. Привязывать яндекс или гугл почту к домену выбирайте сами. Хочу только напомнить, что на данный момент яндекс почта для домена бесплатная.
Cуществует множество советов, домашних средств или лекарственных препаратов против головной боли, резях в желудке или от насморка. Однако не хочется немедленно прибегать к сильнодействующим лекарствам. Возможно, поможет имбирь!
Клубневидный корень из Юго-Восточной Азии известен многим как острая вкусовая приправа из азиатской кухни, а также пряная добавка для изготовления сладостей и выпечки. Скромный на вид корень заключает в себе огромный спектр целебных свойств и широко используется в натуропатии в качестве лекарственного средства.
Имбирный корень славится особым пряным и терпким ароматом, который ощущается благодаря содержащимся в нем эфирным маслам. А своим жгучим вкусом имбирный корень обязан веществу — гингеролу. В нем содержится более 150 полезных микроэлементов и витаминов. Клинически доказано, что имбирь действует как противовоспалительное и антибактериальное средство, активизирует работу желудочно-кишечного тракта.
В традиционной китайской медицине (TCM) и индийской медицине (Аюрведа) на протяжении многих веков корень имбиря используется как согревающее средство. Его применяют при простуде, в качестве болеутоляющего, он помогает справиться с укачиванием в транспорте, тошнотой и мигренью.
Современная классическая медицина лишь сравнительно недавно начала изучать целебные свойства имбиря. Последние опубликованные исследования доказывают эффективность имбирного корня при борьбе с токсикозом во время беременности, с тошнотой при укачивании, а также с рвотным рефлексом, возникающим вследствие химиотерапии. Доказано также, что с помощью препаратов из имбиря можно облегчить периодические боли у женщин, значительно уменьшить боль при артрозе и в мышцах.
Однако это далеко не полный перечень целебных свойств чудодейственного корня. Исследования на крысах показали, что имбирь способен предотвратить или замедлить развитие катаракты у больных сахарным диабетом, понизить уровень сахара в крови. Экстракт имбирного корня, а точнее, его жгучие вещества – гингеролы, ускоряют поступление глюкозы в клетки мышечных тканей, уровень которой у больных сахарным диабетом 2-го типа понижен из-за нарушения инсулиновой реакции.
Лечебные свойства имбирного корня наиболее ярко выражены при употреблении его в виде чая или так называемой «имбирной воды». Для её приготовления необходимо тонкие ломтики свежего корня настоять в течение 10 минут в горячей воде, а затем сразу выпить этот отвар. Для снятия мышечного напряжения можно принимать ванну с имбирем, прикладывать его к коже, делая «имбирное» обёртывание. Рекомендуется всем, кого укачивает в автомобиле, автобусе или самолете брать с собой в дорогу кусочек имбиря или имбирное печенье.
Чудо-корень не только обогатит Вашу домашнюю кухню, даст возможность насладиться неповторимым характерным вкусом, но и дополнит Вашу аптечку эффективными, хорошо переносимыми лекарственными средствами.

 Для чего нужна самомотивация?
Для чего нужна самомотивация?