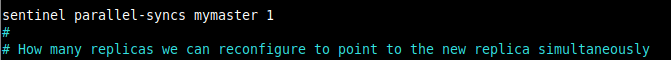Redis обеспечивает высокую доступность через распределенную систему Redis Sentinel. Sentinel помогает отслеживать экземпляры Redis, выявлять сбои и автоматически переключать роли, что позволяет развертыванию Redis противостоять любым сбоям.
Он обеспечивает мониторинг экземпляров Redis (мастер и реплики), поддерживает уведомление других служб/процессов или системного администратора с помощью скрипта, автоматическое переключение при сбое для продвижения реплики к мастеру, когда мастер выходит из строя и предоставляет конфигурация для клиентов, чтобы обнаружить текущий мастер, предлагающий конкретную услугу.
В этой статье показано, как настроить Redis для обеспечения высокой доступности с помощью Redis Sentinel в CentOS 8, включая настройку часов, проверку состояния установки и тестирование Отработка отказа Sentinel.
Условие:
Как настроить репликацию Redis (с отключенным режимом кластера) в CentOS 8 — часть 1
Настройка тестовой среды
Master Server and Sentinel1: 10.42.0.247 Redis Replica1 and Sentinel2: 10.42.0.21 Redis Replica2 and Sentinel3: 10.42.0.34
Согласно документации Redis Sentinel, для надежного развертывания требуется как минимум три экземпляра Sentinel. Принимая во внимание нашу настройку выше, в случае сбоя главного, Sentinels2 и Sentinel3 согласятся с ошибкой и смогут авторизовать аварийное переключение, делая клиентские операции могут продолжаться.
Шаг 1. Запуск и включение службы Redis Sentinel
1. В CentOS 8 служба Redis Sentinel устанавливается вместе с сервером Redis (что мы уже сделали в настройки репликации Redis).
Чтобы запустить службу Sentinel Redis и включить ее автоматический запуск при загрузке системы, используйте следующие команды systemctl. Кроме того, убедитесь, что он запущен и работает, проверив его статус (сделайте это на всех узлах):
Шаг 2. Настройка Redis Sentinel на всех узлах Redis
2. В этом разделе мы объясним, как настроить Sentinel на всех наших узлах. Служба Sentinel имеет тот же формат конфигурации, что и сервер Redis. Для его настройки используйте самодокументированный файл конфигурации /etc/redis-sentinel.conf.
Сначала создайте резервную копию исходного файла и откройте ее для редактирования.
# cp /etc/redis-sentinel.conf /etc/redis-sentinel.conf.orig
# vi /etc/redis-sentinel.conf
3. По умолчанию Sentinel прослушивает порт 26379, проверьте это на всех экземплярах. Обратите внимание, что параметр bind нужно оставить закомментированным (или задать значение 0.0.0.0).
port 26379
4. Затем сообщите Sentinel, чтобы он следил за нашим мастером и рассматривал его в разделе «Объективно отключен». только в том случае, если хотя бы 2 наблюдателя кворума согласны. Вы можете заменить mymaster на собственное имя.
#On Master Server and Sentinel1
sentinel monitor mymaster 127.0.0.1 6379 2
#On Replica1 and Sentinel2
sentinel monitor mymaster 10.42.0.247 6379 2
#On Replica1 and Sentinel3
sentinel monitor mymaster 10.42.0.247 6379 2
Важно: оператор Sentinel Monitor ДОЛЖЕН быть помещен перед оператором Sentinel auth-pass, чтобы избежать ошибки Нет такой мастер с указанным именем.» при перезапуске службы Sentinel.
5. Если на мастере Redis, который нужно отслеживать, установлен пароль (в нашем случае он есть на мастере), укажите пароль, чтобы экземпляр Sentinel мог пройти аутентификацию с помощью защищенного экземпляра.
sentinel auth-pass mymaster
6. Затем установите время в миллисекундах, в течение которого главный сервер (или любая подключенная реплика или контрольный элемент) должен быть недоступен, чтобы он считался в состоянии Субъективно отключен.
Следующая конфигурация означает, что мастер будет считаться неисправным, если мы не получим никакого ответа от наших пингов в течение 5 секунд (1 секунда эквивалентна 1000 миллисекундам).
sentinel down-after-milliseconds mymaster 5000
7. Затем установите время ожидания аварийного переключения в миллисекундах, которое определяет многие вещи (прочитайте документацию по параметру в файле конфигурации).
sentinel failover-timeout mymaster 180000
8. Затем установите количество реплик, которые можно перенастроить для одновременного использования нового главного сервера после отработки отказа. Поскольку у нас есть две реплики, мы установим одну реплику, поскольку другая будет повышена до нового мастера.
sentinel parallel-syncs mymaster 1
Обратите внимание, что файлы конфигурации в Redis Replica1 и Sentinel2, а также Redis Replica1 и Sentinel2 должны быть идентичными.
9. Затем перезапустите службы Sentinel на всех узлах, чтобы применить последние изменения.
# systemctl restart redis-sentinel
10. Затем откройте порт 26379 в брандмауэре на всех узлах, чтобы позволить экземплярам Sentinel начать общение, получать соединения от других >Sentinel, используя команду firewall-cmd.
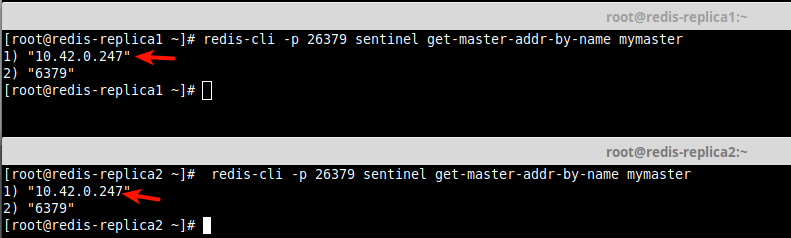
11. Все реплики будут обнаружены автоматически. Важно отметить, что Sentinel автоматически обновит конфигурацию, добавив дополнительную информацию о репликах. Вы можете убедиться в этом, открыв файл конфигурации Sentinel для каждого экземпляра и просмотрев его.
Например, если вы посмотрите в конец файла конфигурации мастера, вы должны увидеть операторы known-sentinels и known-replica, как показано на следующем снимке экрана.
Это должно быть одинаково для replica1 и replica2.
Обратите внимание, что конфигурация Sentinel также переписывается/обновляется каждый раз, когда реплика повышается до статуса master во время отработки отказа и каждый раз, когда в настройке обнаруживается новый Sentinel.
Шаг 3. Проверьте статус установки Redis Sentinel
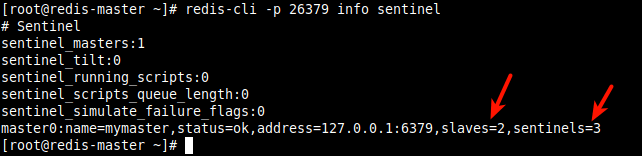
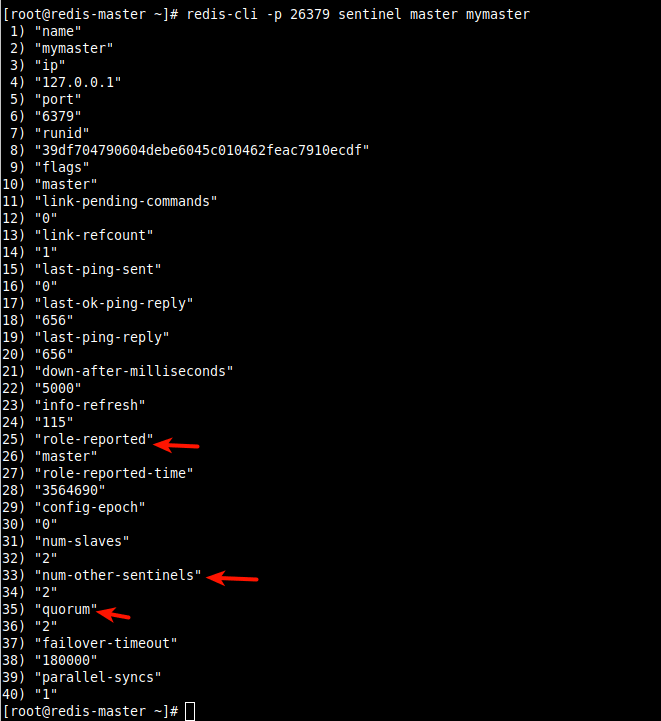
12. Теперь проверьте статус/информацию Sentinel на мастере, используя команду info sentinel следующим образом.
# redis-cli -p 26379 info sentinel
Из вывода команды, как видно на следующем снимке экрана, у нас есть две реплики/ведомые устройства и три часовых.
13. Чтобы отобразить подробную информацию о мастере (называемом mymaster), используйте команду sentinel master.
# redis-cli -p 26379 sentinel master mymaster
14. Чтобы отобразить подробную информацию о подчиненных устройствах и сторожевых устройствах, используйте команду sentinel slaves и sentinel sentinels соответственно.
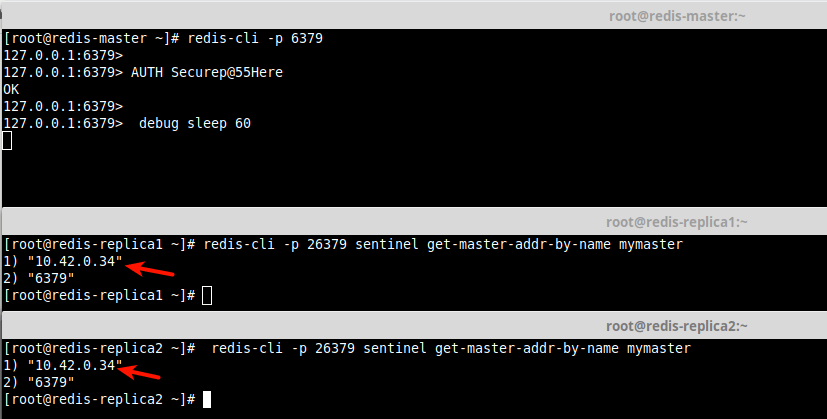
16. Наконец, давайте проверим автоматический переход на другой ресурс в нашей настройке Sentinel. На главном сервере Redis/Sentinel переведите главный сервер Redis (работающий через порт 6379) в спящий режим на 60 секунд. . Затем запросите адрес текущего мастера на репликах/ведомых устройствах следующим образом.
Судя по выходным данным запроса, новым мастером теперь является replica/slave2 с IP-адресом 10.42.0.34, как показано на следующем снимке экрана.
Вы можете получить больше информации из документации Redis Sentinel. Но если у вас есть какие-либо мысли или вопросы, которыми вы хотите поделиться, форма обратной связи ниже — ваш путь к нам.
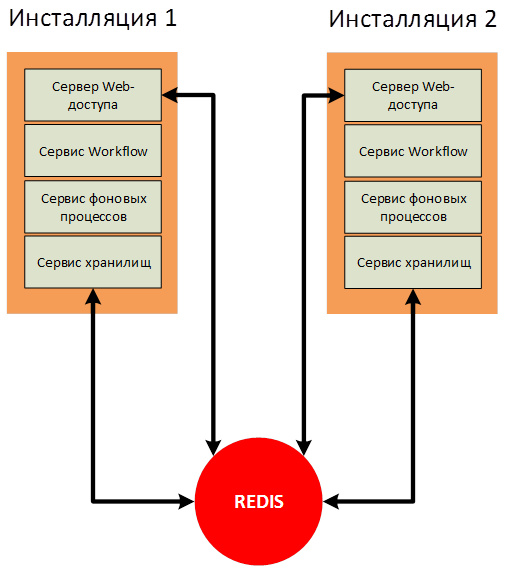
В случае применения горизонтального масштабирования сервисных служб DirectumRX необходимо использовать отказоустойчивую инсталляцию Redis для сервисных служб сервис хранилищ DirectumRX. В статье рассмотрим наиболее простой вариант реализации.
Введение в решаемую задачу
Redis – это система управления базами данных класса NoSQL (не реляционные СУБД), размещаемых целиком в оперативной памяти. Для доступа к данным используется модель «ключ» — «значение». Такая СУБД используется зачастую для хранения кэшей в масштабируемых сервисах, для хранения изображений и данных небольшого размера.
Широкое распространение СУБД Redis получила за счет:
высокой скорости работы, т.к. все данные хранятся в оперативной памяти,
кроссплатформенности,
распространению по BSD лицензии (относится к СПО).
Широту распространения и применимость Redis можно оценить по огромному количеству документации со всевозможными кейсами на официальном сайте проекта: https://redis.io/documentation.
В случае применения горизонтального масштабирования сервисных служб DirectumRX необходимо использовать отказоустойчивую инсталляцию Redis для корректной работы с сервисом хранилищ DirectumRX и сервисом веб-доступа DirectumRX.
В Redis будут храниться оперативные данные, кэши и прочая информация, которая необходима для работы служб, находящихся в режиме масштабирования, чтобы процесс взаимодействия пользователя с системой не зависел от инсталляции, с которой в текущий момент он работает.
В конфигурационных файлах служб необходимо указать необходимые параметры для подключения к Redis.
Вариант с использованием Redis Sentiel (Следящий узел Redis) был реализован в версии Redis 2.4 и состоит в том, что для мониторинга доступности мастера используется дополнительный сервис Redis Sentiel. Он же выполняет настройку узлов реплик, в случае выхода из строя мастера. Определяет какой из SLAVE узлов станет MASTER и выполнит перенастройку на ходу.
Реализует классическую схему:
SLAVE-узлов может быть множество (до 1000 по данным с официального сайта), для продуктивной работы рекомендуется использовать не менее двух SLAVE-узлов.
Обычно схема настраивается таким образом, что на MASTER- и на SLAVE-узлах настраивается сервис Redis Sentiel и при выходе из строя MASTER-узла, оставшиеся следящие узлы принимают решение о введении в работу нового MASTER.
Redis Cluster
Вариант кластеризации Redis Cluster реализован для версии redis 3.0 и выше, является решением для создания и управления кластером с сегментацией и репликацией данных. Выполняет задачи управления узлами, репликации, синхронизации данных на узлах и обеспечения доступа клиентского приложения к MASTER-узлу в случае выхода из строя одного из нескольких MASTER-узлов.
Redis Cluster наиболее надежный вариант. Работает в режиме мультимастера, у каждого MASTER-узла может быть один или более SLAVE-узлов (до 1000).
Представленная схема требует, как минимум 3-6 узлов. Запросы перенаправляются от клиентов на нужный MASTER или SLAVE — но это требует поддержки режима кластера Redis самим клиентским приложением.
В данной статье будем рассматривать наиболее простой вариант – Redis Sentiel.
Создание отказоустойчивой инсталляций по схеме Redis Sentiel
Актуальная версия Redis доступна для скачивания с официального сайта разработчика продукта https://redis.io/download. Однако на сайте доступен дистрибутив только для ОС Linux. В своё время развивался проект Microsoft по портированию Redis на ОС Windows (https://github.com/MicrosoftArchive/Redis), однако в настоящее время проект остановил развитие на версии 3.2.100, поэтому в данной статье будем рассматривать наиболее актуальный вариант разворачивания – на ОС Linux.
В качестве тестовых узлов будем использовать два виртуальных хоста redis1 и redis2 с установленным дистрибутивом Linux Debian 10.
Первым делом подключаем репозиторий Redis для получения актуальных версий:
1. Создадим файл /etc/apt/sources.list.d/dotdeb.list и пропишем адреса репозитория:
deb http://packages.dotdeb.org stable all
deb-src http://packages.dotdeb.org stable all
При необходимости, устанавливаем дополнительные компоненты:
apt install gnupg
3. Устанавливаем Redis:
apt install redis-server
Проверим версию:
root@redis1:/home/user# redis-server -v
Redis server v=5.0.3 sha=00000000:0 malloc=jemalloc-5.1.0 bits=64 build=afa0decbb6de285f
Пусть redis1 будет выступать в качестве MASTER-узла, а redis2 – в качестве SLAVE-узла.
Для этого в конфигурационных файлах Redis пропишем необходимые параметры, которые позволят создать реплику (пока не отказоустойчивую).
Для redis1 в конфигурационном файле /etc/redis/redis.conf указываем:
#указываем пароль, по которому MASTER будет разрешать работать с ним.
requirepass TestPass
Для redis2 в конфигурационном файле /etc/redis/redis.conf указываем:
# Указываем адрес MASTER и порт.
slaveof redis1 6379
# Указываем пароль для работы с мастером.
masterauth TestPass
# Также указываем пароль, чтобы с узлом можно было работать только по паролю.
requirepass TestPass
Выполним перезапуск сервисов redis-server на обоих узлах:
Проверяем на стороне MASTER, что узлы стали репликами и получили необходимые роли:
root@redis1:/etc/redis# redis-cli -a TestPass inforeplication
Warning: Using a passwordwith '-a' or '-u' optionon the command line interface may not be safe.
# Replicationrole:master
connected_slaves:1
slave0:ip=192.168.9.96,port=6379,state=online,offset=28,lag=0
master_replid:56b0a702d5823d107b0ca1ca2c80f8ef650a4b28
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:28
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:28
На стороне SLAVE видим такую же ситуацию:
root@redis2:/etc/redis# redis-cli -a TestPass info replicationWarning: Using a password with '-a' or '-u' option on the command line interface may not be safe.# Replicationrole:slavemaster_host:redis1master_port:6379master_link_status:upmaster_last_io_seconds_ago:4master_sync_in_progress:0slave_repl_offset:14slave_priority:100slave_read_only:1connected_slaves:0master_replid:56b0a702d5823d107b0ca1ca2c80f8ef650a4b28master_replid2:0000000000000000000000000000000000000000master_repl_offset:14second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:14
Теперь необходимо настроить реплику таким образом, чтобы она автоматически восстанавливалась в случае выхода из строя одного из узлов. Для этого нам понадобиться следящий сервис Redis Sentinel.
Мониторинг: следящий узел проверяет доступность MASTER и SLAVE узлов и способен оправлять оповещения о недоступности узлов.
Обеспечение отказоустойчивости: если MASTER-узел вышел из строя, следящий узел может перевести SAVE-узел в режим MASTER, а также перенастраивает остальные SLAVE-узлы, и они начинают работать с новым MASTER.
Управление конфигурациями. Конфигурирует узлы MASTER и SLAVE.
Разместим для чистоты эксперимента следящий сервис на отдельную ВМ redis3.
Подключаем аналогичным способом репозиторий Redis и устанавливаем пакет redis-sentinel:
apt install redis-sentinel
После установки необходимо внести настройки в конфигурационный файл следящего узла /etc/redis/sentinel.conf:
# Настраиваем мониторинг узла redis1 по порту 6379. # Последняя цифра 1 - означает количество следящих узлов в кворуме, # мнение которых учитывается в случае необходимости изменить MASTER-узел.# То есть можно поднять несколько следящих узлов, # которые будут выполнять мониторинг MASTER-узла.
sentinel monitor master01 redis1 6379 1
# Ждем 3 секунды, прежде чем принимать решение о сбое узла.
sentinel down-after-milliseconds master01 3000
# Зададим таймаут восстановления MASTER-узла
sentinel failover-timeout master01 6000
# Указываем сколько SLAVE-узлов необходимо перенастраивать одновременно. # Необходимо указывать минимальное количество, чтобы не получилось так, # что все реплики станут недоступны одновременно.
sentinel parallel-syncs master01 1
# Обязательно прописываем прослушиваемые порты.
bind 192.168.9.97 127.0.0.1 ::1
# И прописываем пароль MASTER-узла.
sentinel auth-pass master01 TestPass
Восстановим работу узла redis1 и проверим его состояние:
root@redis3:/var/log/redis# redis-cli -h redis1 -p 6379 -a TestPass info replicationWarning: Using a password with '-a' or '-u' option on the command line interface may not be safe.# Replicationrole:slavemaster_host:192.168.9.96master_port:6379master_link_status:upmaster_last_io_seconds_ago:1master_sync_in_progress:0slave_repl_offset:15977slave_priority:100slave_read_only:1connected_slaves:0master_replid:6c0c7d0eedccede56f211f2db74a98c4d0ff6d56master_replid2:0000000000000000000000000000000000000000master_repl_offset:15977second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:15977
Видим, что узел получил роль SLAVE, а узел redis2 является MASTER-узлом.
Сымитируем сбой узла redis2 и проверим состояние следящего узла:
root@redis3:/var/log/redis# redis-cli -h redis1 -p 6379 -a TestPass inforeplication
Warning: Using a passwordwith '-a' or '-u' optionon the command line interface may not be safe.
# Replicationrole:master
connected_slaves:0
master_replid:6e9d67d6460815b925319c2bafb58bf2c435cffb
master_replid2:6c0c7d0eedccede56f211f2db74a98c4d0ff6d56
master_repl_offset:33610
second_repl_offset:26483
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:33610
Отлично, механизм работает. Но теперь возникла проблема, как мы будем подключать наши сервисы DirectumRX, ведь для них нужен адрес единственного узла. Решим вопрос с помощью сервисной службы HAProxy.
Проксирование обращения к узлам Redis
В качестве reverse-прокси для узлов Redis может выступать любой проксирующий tcp-сервис. В данной статье рассмотрим использование HAProxy поскольку это специализированный инструмент предназначенный для обеспечения высокой доступности и балансировки нагрузки и используется повсеместно известными онлайн сервисами. Подробнее о HAProxy можно почитать на странице разработчика http://www.haproxy.org/#desc.
Установим HAProxy на узел redis3:
root@redis3:/var/log/redis# apt search haproxy
В конфигурационный файл HAProxy /etc/haproxy/haproxy.cfg, добавим настройки для проксирования запросов к узлам Redis:
…
frontend ft_redis
bind *:6379 name redis
mode tcp
default_backend bk_redis
backend bk_redis
mode tcp
option tcp-check
tcp-checkconnect
# Не забываем, что все узлы принимают запросы только при наличии пароля.
tcp-check send AUTH TestPassrn
tcp-check expect string +OK
tcp-check send PINGrn
tcp-check expect string +PONG
tcp-check send inforeplicationrn
# Работаем только с MASTER, т.к. SLAVE по умолчанию работает только на чтение.
tcp-check expect string role:master
tcp-check send QUITrn
tcp-check expect string +OK
server Redis1 redis1:6379 check inter 3s
server Redis2 redis2:6379 check inter 3s
В данной конфигурации указано, что проксировать будем любые запросы, приходящие на все интерфейсы текущей виртуальной машины по адресу на порт 6379. Запросы будем передавать на узел, который ответит, что он имеет роль MASTER.
Попробуем подключиться с помощью клиента redis-cli и создадим тестовый ключ:
root@redis3:/etc/haproxy# redis-cli -p 6379 -a TestPass
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> SET TestKey "Some test string"
OK
127.0.0.1:6379> GET TestKey
"Some test string"
127.0.0.1:6379> info keyspace
# Keyspace
db0:keys=1,expires=0,avg_ttl=0
Остановим узел redis1 и запросим снова список ключей:
127.0.0.1:6379> info keyspace
Error: Server closed the connection
(3.01s)
127.0.0.1:6379> info keyspace
# Keyspace
db0:keys=1,expires=0,avg_ttl=0
(2.01s)
Видим, что на некоторое время соединение оборвалось, но затем подключение снова восстановилось и все данные остались на месте.
Теперь достаточно прописать в конфигурационных файлах сервисов DirectumRX адрес reverse-прокси для подключения к Redis.
Вместо заключения
При настройке на реальной инсталляции, необходимо, чтобы следящих сервисов было несколько (по правилам на каждом узле реплики) и HAProxy работал в режиме кластера. В данной статье кластеризация HAProxy рассматриваться не будет, мы рассмотрели только основные принципы настройки отказоустойчивого Redis для сервисов DirectumRX.
Если статья наберет больше 30 лайков, продолжим данную тему и рассмотрим настройку Redis Cluster, а также в продолжении рассмотрим настройки балансировщиков на базе HAProxy и Ngnix применимо для DirectumRX.
Дисклеймер
Рекомендации представленные в статье не являются официальной документацией какой бы то ни было компании. Рекомендации предоставляются на основании личного опыта автора по настройке системы DirectumRX и серверных компонентов. Автор статьи не несет ответственности и не предоставляет гарантий в связи с публикацией фактов, сведений и другой информации, а также не предоставляет никаких заверений или гарантий относительно содержащихся здесь сведений.
Источник: https://club.directum.ru/post/222438
Redis + Sentinel behind HAProxy
Просто краткое замечание, недавно я выяснил, как установить один IP-адрес для вашего набора Redis.
Возьмем следующий сценарий, в котором у вас есть три экземпляра Redis, один ведущий и два ведомых. У вас также есть три Redis стражей которые управляют состоянием master / slave этого набора.
Я не хотел, чтобы моим клиентам приходилось поддерживать соединения с экземплярами Redis sentinel, подписываясь на событие master change и затем обновляя свою конфигурацию. Я также не хотел открывать правила брандмауэра, чтобы разрешить клиентам подключаться к каждому из трех экземпляров Redis.
Я предпочитаю, чтобы все было просто, мои клиенты просто занимаются чтением и записью в Redis, и что-то еще отвечает за управление доступностью кластера. Что я на самом деле обнаружил, так это то, что я могу использовать проверки работоспособности TCP Layer7 в HAProxy чтобы проверить состояние «master», впоследствии я только «балансирую нагрузку» своего трафика на главный узел, а «slave» считаются отключенными.
Предварительные условия
Это не статья о том, как настроить HAProxy, поэтому, боюсь, вам придется обратиться за этим в другое место, и я не объясняю конфигурации Redis master / slave / sentinel. Итак, в принципе, продолжайте и настройте свою настройку Redis как обычно, а затем установите другой хост с HAProxy .
Конфигурация
Конфигурация HAProxy вокруг redis сама по себе довольно проста, довольно проста:
listen redis-postprocess-TCP-6379 0.0.0.0:6379
mode tcp
option tcplog
option tcp-check
#uncomment these lines if you have basic auth
#tcp-check send AUTH yourpasswordrn
#tcp-check expect +OK
tcp-check send PINGrn
tcp-check expect string +PONG
tcp-check send info replicationrn
tcp-check expect string role:master
tcp-check send QUITrn
tcp-check expect string +OK
server redis-1 192.168.0.2:6379 maxconn 1024 check inter 1s
server redis-2 192.168.0.3:6379 maxconn 1024 check inter 1s
server redis-3 192.168.0.4:6379 maxconn 1024 check inter 1s
То, что мы в основном просим HAProxy делать здесь, — это каждые 1 секунду, ping сервер и ожидать pong, затем запрашивать info и ожидать строку role:master.
В результате вы получаете ситуацию, когда весь ваш трафик отправляется только на «master», как вы можете видеть на экране состояния HAProxy:
Вуаля, на самом деле все, просто укажите своим клиентам ваш IP-адрес HAProxy и оставьте заботу о высокой доступности Sentinels + HAProxy, работающим в унисон.
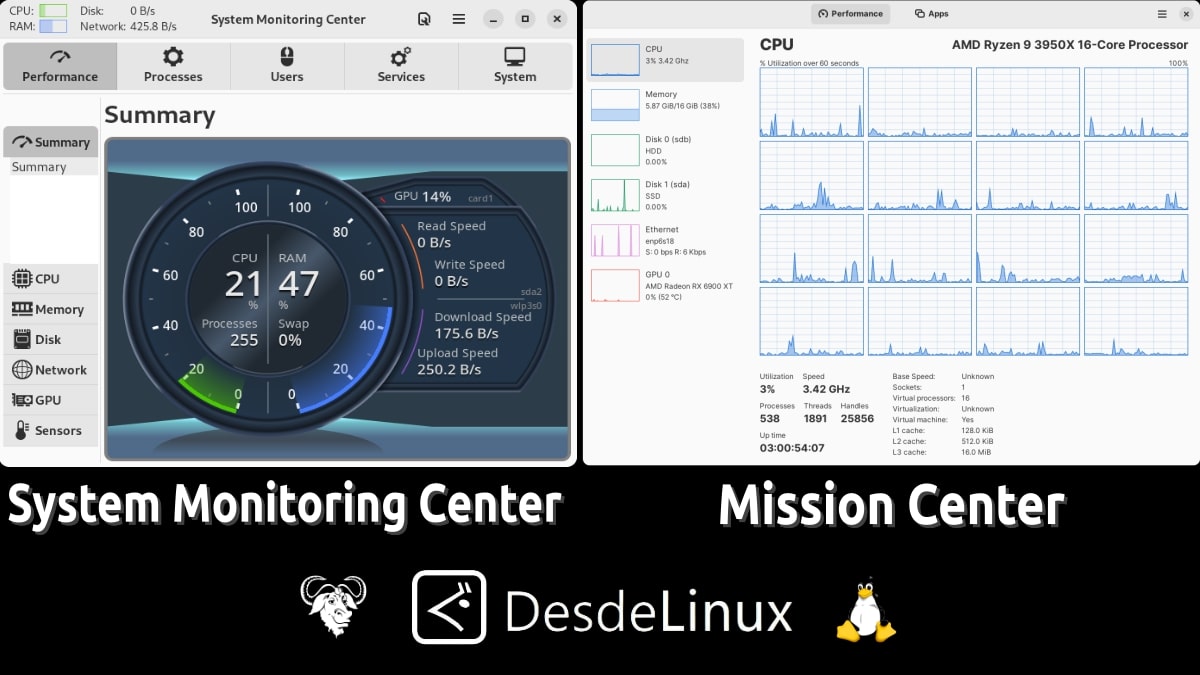
Центр системного мониторинга и Центр задач: 2 монитора задач
Несколько дней назад мы поделились еще одним постом об одном из многих мониторы ресурсов, задач или операционной системы доступен в Linuxverse, то есть для свободных и открытых операционных систем, которые мы обычно называем дистрибутивами или дистрибутивами GNU/Linux. В частности, мы рассказали им о мониторе задач терминала (CLI), который называется Бpytop. Создатель которого такой же, как и другие, известные как БашТоп и БТоп, оба также для терминала.
Хотя, еще раньше, мы рассказали вам о других приложениях, которые представляют собой графические приложения для рабочего стола и, следовательно, гораздо более дружелюбны, привлекательны и имеют гораздо больше интегрированных функций. Хорошим примером этого является так называемый SysMonTask и WSysMon. Оба очень похожи на Монитор задач Windows. Поэтому сегодня мы познакомим вас с еще одним рабочим столом 2 (GUI) для ознакомления и реализации теми, кто считает его полезным и необходимым в своих различных дистрибутивах GNU/Linux. И они называются: «Центр системного мониторинга и миссионерский центр».
Анонсирован выпуск новой версии Savant 0.2.5, основанной на новом SDK Nvidia DeepStream 6.3, а также с улучшениями в адаптерах, кодировщиках и многом другом.
Для тех, кто не знаком с фреймворком, вы должны знать, что это берет на себя всю работу с GStreamer или FFmpeg, что позволяет сосредоточиться на создании оптимизированных конвейеров вывода с использованием декларативного (YAML) синтаксиса и функций Python.
Wireshark 4.2.0: что нового в последней разрабатываемой версии
Если вы меньше из тех, кто время от времени тратит свое время на изменение и тестирование дистрибутива GNU/Linux, и больше из тех, кто тратит свое время на тестирование и изучение полезные компьютерные сетевые приложения и, возможно, немного хакинга, эта новость вам скорее всего понравится. И вот 5 октября анализатор трафика с открытым исходным кодом под названием Wireshark выпустила свою разрабатываемую версию под номером 4.2.0 RC1, и теперь она доступна для загрузки и тестирования и включает в себя новые интересные функции.
Кроме того, и учитывая, что мы уже говорили ранее о что такое вайршарк и каковы его основные и основные характеристики, сегодня мы остановимся исключительно на новых возможностях этой развивающейся версии, то есть: «Wireshark 4.2.0 RC1».
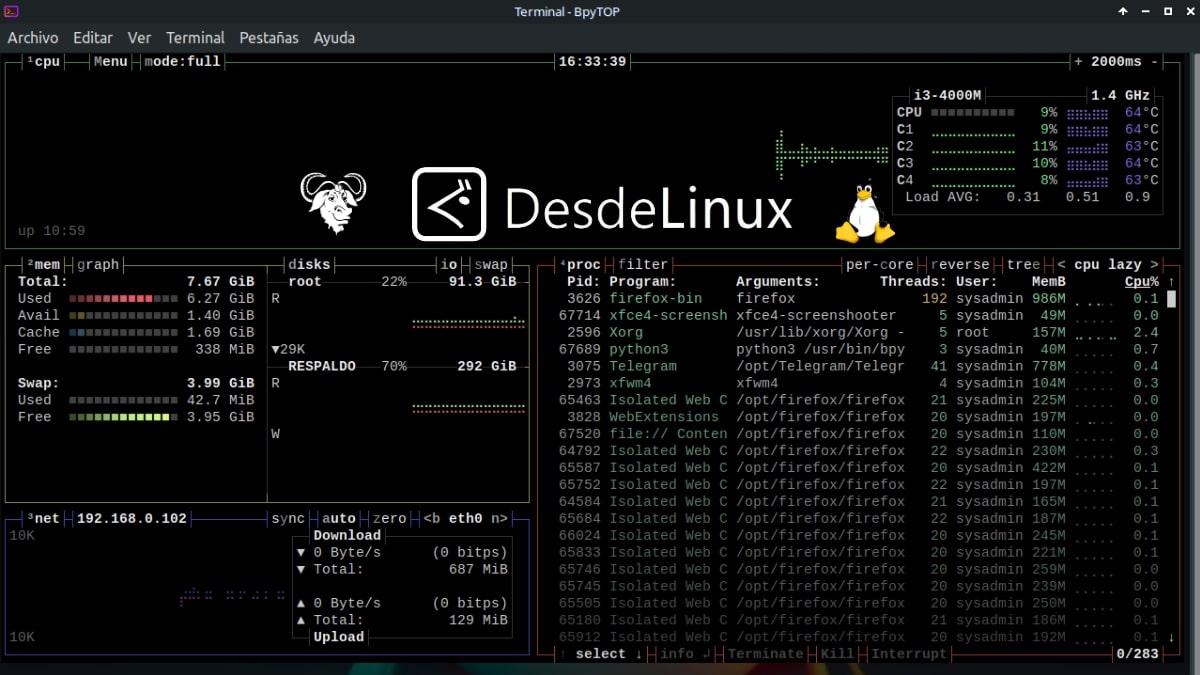
Bpytop: элегантный и надежный монитор ресурсов для терминала.
Независимо от того, являемся ли мы средний пользователь дистрибутивов GNU/Linux с небольшими или большими техническими знаниями об установленных нами дистрибутивах или с профессионалом такого типа, Администратор сервера и системы (SysAdmin), разработчик программного обеспечения (разработчики/DevOps) или специалист в области компьютерной безопасности (хакеры/пентестеры); Что обычно характеризует всех нас, так это стремление к настройке и мониторингу операционной системы.
По этой причине мы с определенной частотой изменяем, изменяем и оптимизируем базу и ее приложения, чтобы придать им уникальный или оригинальный вид и повысить их эффективность. И для измерения последнего мы обычно используйте мониторы графических ресурсов, а также мониторы терминалов. Хотя многие склонны использовать классику команда htop Для этого, особенно для того, чтобы продемонстрировать потребление ресурсов на праздновании «Настольной пятницы», правда в том, что существуют более элегантные и надежные инструменты, подобные тому, который мы сегодня впервые покажем здесь, в Desde Linuxпозвоните «Бпитоп».