
Быстрая сортировка (англ. quicksort), часто называемая qsort по имени реализации в стандартной библиотеке языка Си — широко известный алгоритм сортировки, разработанный английским информатиком Чарльзом Хоаром в 1960 году. Один из быстрых известных универсальных алгоритмов сортировки массивов (в среднем O(n log n) обменов при упорядочении n элементов), хотя и имеющий ряд недостатков. Например, в худшем случае (на некоторых входных массивах) использует время Ω(n2)
- ШАГ 1: Возьмем элемент A[p] за ось и «раскидаем» остальные элементы A[(p+1)..q] по разные стороны от него стороны — меньшие влево, большие — вправо, то есть переставим элементы подмассива A[p..q] так, чтобы вначале шли элементы меньше либо равные A[p] потом элементы, больше либо равные A[p]. Назовет этот шаг разделением (partition).
- ШАГ 2: Пусть r есть новый индекс элемента A[p]. Тогда, если q — p > 2, вызовем функцию сортировки для подмассивов A[p..(r-1)] и A[(r+1)..q].
- Элементы меньшие «оси»
- Элементы равные «оси»
- Элемент
Сервис онлайн тестирования Quizful
Недавно в блоге Алена С++ прочитал пост о бесплатном прохождении тестов на сайте Brainbench. Халява была ограниченна по времени, так что я задался вопросом найти бесплатный аналог и на русском. Больше всего мне понравился сайт онлайн тестов Quizful.
Читать
object.__del__(self) 2.7
- взаимные ссылки между объектами (в списках или в деревьях)
- ссылки на объекты в стеке функции, где было вызвано исключение, так как в таком случае ссылки на объекты этого стека сохранены в sys.exc_traceback
- ссылки на объекты в стеке, если было вызвано не перехваченное исключение в интерактивном режиме (так как в таком случае ссылки на объекты сохранены в sys.last_traceback)
Автор: Ishayahu Lastov
Связные списки

В информатике, свя́зный спи́сок — структура данных, состоящая из узлов, каждый из которых содержит как собственные данные, так и одну или две ссылки («связки») на следующий и/или предыдущий узел списка. Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.
Мы с вами рассмотрим реализацию односвязного (однонаправленного) списка.
*-Нравится статья? Кликни по рекламе! 🙂
Коли уж я натолкнулся на прелестные статьи Сергея Яковлева, на сайте IBM, которые люди так не заслужено оценили в 2 звезды, давайте обсудим их.
В конечном итоге мы получим реализацию данного рисунка
В одной из статей Sython’а (Cвойство замыкания, на примере list) мы уже создавали похожую структуру, методами функционального программирования. Пришло время задействовать ООП!)
История связных списков
Основной принцип связных списков крайне прост: эта структура данных состоит из последовательности записей, в которой каждая запись хранит помимо самих данных еще и ссылку на следующую запись в этой последовательности. На рисунке 1 изображен связный список из трех записей, каждая запись которого состоит из поля данных — целого числа и ссылки на следующую запись.
| Рисунок 1. Пример связного списка |
У последней записи на рисунке отсутствует ссылка, но она есть и указывает на NULL. На основе списков можно реализовать структуры данных, такие как стеки, очереди и ассоциативные массивы.
Ранее уже упоминалось, что в массиве все элементы расположены в памяти по порядку, а в списке они в памяти никак не упорядочены. Более того, элемент может быть добавлен в любую позицию в списке. Однако сама операция по вставке элемента в список требует дополнительных ресурсов, так как нужно последовательно просканировать список для поиска нужной позиции.
Основные правила реализации связных списков
Список состоит из элементов, называемых узлами (node). Первый узел списка называется «головным» (head), а последний — «хвостовым» (tail). На рисунке 2 изображен двойной связный список.
| Рисунок 2. Двойной связный список |
Каждый элемент состоит из 3-х полей, два из которых являются указателями на предыдущий или следующий узел. Элемент может указывать и более чем на два узла, и в этом случае список называется многосвязным.
Помимо упоминавшихся ранее стандартных массивов существуют еще динамические массивы. Размер обычн
Об уровнях абстракций — The Very Last API
При написании не тривиальных приложений возникает вопрос: над какими библиотеками делать еще один абстрактный слой, а над какими — нет? Какие абстракции делать?
Стоит ли делать прослойку над, например, SQLAlchemy? Это же и так прослойка над SQL и DBAPI. Имеет ли смысл делать уровни абстракций над такими достаточно хорошими и отточенными в смысле интерфейсов библиотеками?
Ответ очень простой — библиотеки представляют API который должен быть применим для широкого спектра приложений. Они отображают низкоуровневые (с точки зрения их API ) вызовы на более высокоуровневый, но абстрактный интерфейс. Характерный пример — библиотеки передачи сообщений. Они позволяют не думать о сокетах, упаковке/распаковке float/int и т.п., а просто передавать структуры данных.
Типичный API системы пересылки сообщений выглядит как:
class Messaging(object):
def send_message_async(self, dest, message_tp, message_data):
# some code
def send_message_sync(self, dest, message_tp, message_data):
# some code
def get_message(self):
# some code
Но программе не нужно посылать никакие сообщения! Ей нужно выполнить действия — показать пользователю GUI, узнать завершился ли удаленный процесс, etc. API сообщений, которое было-бы идеально для некоторой программы выглядит примерно так:
class MyAPI(object):
@exception_on_false
def show_ui_message(self, level, text):
return self.messanger.send_message_async(self.UI_PROC_ID,
SHOW_DIALOG,
dict(level=level, text=text))
@exception_on_false
def reboot_vm(self, ip):
return self.messanger.send_message_async(
self.get_remote_agent_id(ip),
REBOOT_VM,
None)
def ls_remote(self, ip, remote_path):
tp, res = self.messanger.send_message_sync(
self.get_remote_agent_id(ip),
EXEC_CMD,
'ls -l {0}'.format(remote_path))
if tp == EXECUTION_FINISHED_OK:
return res
else:
raise RuntimeError("Cmd ... finished with error code {0}".
format(res))
Очень принципиальный момент — конечный API должен отражать задачи, стоящие перед программой. Четкое отделение основной логики программы от деталей реализации имеет минимум два очень важных плюса — позволяет сделать главный код легче для чтения (убирает лишние абстракции) и максимально отвязать программу от API библиотек (локализовать привязку).
Это особенная прослойка, это «последняя линия». Если остальные API предоставляют нам абстракции, то эта прослойка не должна добавлять ничего лишнего, она избавляет нас от более не нужных абстракций и говорит языком предметной области программы.
Вам нужно хранить в базе список фруктов? Сделайте функцию store_fruits. Такая функция позволить вам перейти от PostgreSQL к Cassandra, а потом к текстовым файлам (маловероятная ситуация, но не суть) без влияния на остальную программу. Потому что программе все равно где лежат данные. Программу интересует только что они сохраняются и восстанавливаются.
Мы никак не может защититься от изменения требований к программе и вместе с изменениями требований нужно будет меняться и API, который предоставляет наш слой абстракции. Но вот изменения в типе базы/структуре базы/ORM не будет приводить к изменению кода. Если смена БД или ORM — маловероятная ситуация, то вот добавление нового поля вида deleted, означающего, что запись вроде как удалена и почти нигде не должна использоваться — весьма частый случай.
# почти реальный запрос прямо из функции, отвечающей за логики программы
services = session.query(Service).
filter(Service.zone_id == zone_id).
filter(Service.service_id == service_id).
with_lockmode('update').
limit(10).all()
# Чего-чего?????
# комментарий к запросу немного бы спас ситуацию
# но вместо решения проблем с помощью комментирования их лучше не создавать
# Этот код не требует комментариев
for service in db.get_10_services(zone_id, service_id):
# some code
# в файле db.py
def get_10_services(self, zone_id, service_id):
return self.session.query(Service).
filter(Service.zone_id == zone_id).
filter(Service.service_id == service_id).
with_lockmode('update').
limit(10).all()
Еще одна ошибка — попытка сэкономить на таком API и сделать в этом духе:
import sqlalchemy as sa
# one Function to rule them all!!
def get_user(session, *opts):
return session.query(User).filter(sa.and_(*opts)).all()
# этот код уже требует знания что там у нас за sqlalchemy такая
# и на mongo его уже не переписать так-же легко
# тут "торчат уши" sqlalchemy. Да, мы съекономили 10-20 нажатий клавишь
# на каждый вызов, но это не "the very last API"
for user in get_user(User.name == 'vasya', User.age > datetime.now()):
pass
Безусловно у любого абстрагирования есть минимум один существенный минус — пользуясь им люди хуже понимают что происходит на уровнях ниже. При возникновении проблем внутри абстракций или еще ниже (например могут быть проблемы с сетью) на их решение может уйти много времени — а проблемы возникают постоянно. Во-вторых исчезает контроль над ситуацией. Любая сложная библиотека несет свои неожиданности в добавок к особенностям нижнего уровня. В итоге вопрос «почему функция выборки из базы зависает» может стать не решаемым.
Я за последнее время видел некоторое количество достаточно опытных программистов, которые почти ничего не знают про сокеты и TCP, потому что RabbitMQ и про потоки, потому что фреймфорк подставьтет-тут-свой-фреймфорк. Нет, это не проявления вселенского зла. Отлично что программирование упрощается, но эта категория программистов — клиенты обеих проблем сверху.
Впрочем это уже другой вопрос. А наш вопрос — абстракции :).
Уровни абстракции должны быть Надежными и легкими для изучения. А ваши абстракции
«последнего рубежа» должны отражать проблемную область программы и закрывать ими я бы стал почти все нетривиальные внешние зависимости, которые используются в значительной части кода программы и привносят свои абстракции.
P.S. Обычно такой подход хорошо работает, но как и все обобщенные рассуждения эти мысли стоит материализовывать без фанатизма — случаи то разные бывают.
Ссылки:
www.sqlalchemy.org/
www.python.org/dev/peps/pep-0249/
Исходники этого и других постов со скриптами лежат тут — github.com/koder-ua.При использовании их, пожалуйста, ссылайтесь на koder-ua.blogspot.com.
Автор: konstantin danilov
Пузырьковая сортировка

Алгоритм состоит в повторяющихся проходах по сортируемому массиву. За каждый проход элементы последовательно сравниваются попарно и, если порядок в паре неверный, выполняется обмен элементов. Проходы по массиву повторяются до тех пор, пока на очередном проходе не окажется, что обмены больше не нужны, что означает — массив отсортирован. При проходе алгоритма, элемент, стоящий не на своём месте, «всплывает» до нужной позиции как пузырёк в воде, отсюда и название алгоритма.
Для понимания и реализации этот алгоритм — простейший, но эффективен он лишь для небольших массивов. Сложность алгоритма: O(n²).
*-Нравится статья? Кликни по рекламе! 🙂
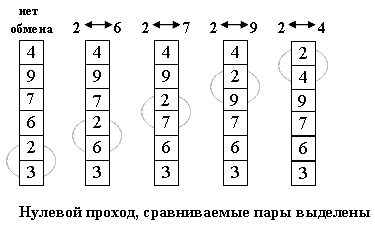
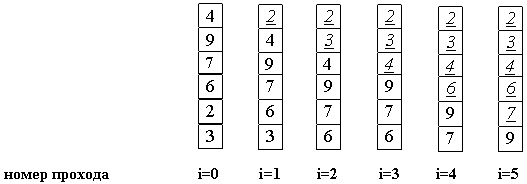
Тем не менее, у него есть громадный плюс: он прост и его можно по-всякому улучшать.
- Во-первых, рассмотрим ситуацию, когда на каком-либо из проходов не произошло ни одного обмена. Что это значит ?Это значит, что все пары расположены в правильном порядке, так что массив уже отсортирован. И продолжать процесс не имеет смысла(особенно, если массив был отсортирован с самого начала !).Итак, первое улучшение алгоритма заключается в запоминании, производился ли на данном проходе какой-либо обмен. Если нет — алгоритм заканчивает работу.
- Процесс улучшения можно продолжить, если запоминать не только сам факт обмена, но и индекс последнего обмена k. Действительно: все пары соседих элементов с индексами, меньшими k, уж