
Сегодня мы рассмотрим систему полнотекстового поиска, она позволяют искать слова в большом наборе документов и сортируют результаты поиска по релевантности найденных документов запросу. Алгоритмы полнотекстового поиска относятся к числу важнейших среди алгоритмов коллективного разума. Новые идеи в этой области помогли сколотить целые состояния. Широко распространено мнение, что своей быстрой эволюцией от академического проекта к самой популярной поисковой машине в мире система Google обязана прежде всего алгоритму ранжирования страниц PageRank.
Что такое поисковая машина
Итак, давайте же создадим здоровую конкуренцию мировым поисковикам!) Статья так же будет полезна начинающим SEO специалистам, т.к. покажет некоторые величины, которые могут влиять на позиции вашего сайта в поиске.
Первый шаг при создании поисковой машины – разработать методику сбора документов. Иногда для этого применяется ползание (начинаем с небольшого набора документов и переходим по имеющимся в них ссылкам), а иногда отправной точкой служит фиксированный набор документов, быть может, хранящихся в корпоративной сети интранет.
Далее собранные документы необходимо проиндексировать. Обычно для этого строится большая таблица, содержащая список документов и вхождений различных слов. В зависимости от конкретного приложения сами документы могут и не храниться в базе данных; в индексе находится лишь ссылка (путь в файловой системе или URL) на их местонахождение
Ну и последний шаг – это, конечно, возврат ранжированного списка документов в ответ на запрос. Имея индекс, найти документы, содержащие заданные слова, сравнительно несложно; хитрость заключается в том, как отсортировать результаты. Можно придумать огромное количество метрик, и недостатков в них.
class Indexer:
def __init__(self):
self.conn = psycopg2.connect("dbname='postgres' user='postgres' password='120789' host='localhost'")
self.cur = self.conn.cursor()
self.cur.execute("set search_path to 'rambler_search'")
self.grab = Grab()
def __del__(self):
self.conn.close()
def dbcommit(self):
self.conn.commit()
Код паука
Эта функция в цикле обходит список страниц, вызывая для каждой функцию addtoindex. Далее она получает все ссылки на данной странице и добавляет их URL в список newpages. В конце цикла newpages присваивается pages, и процесс повторяется.
Эту функцию можно было бы определить рекурсивно, так что при обработке каждой ссылки она вызывала бы сама себя. Но, реализовав поиск в ширину, мы упростим модификацию кода в будущем, позволив пауку ползать непрерывно или сохранять список неиндексированных страниц для последующего индексирования. Кроме того, таким образом мы избегаем опасности переполнить стек.
# Начинаем со списка страниц для индексации
# опускаемся в глубину на 2 уровня
def crawl(self, pages, depth=2):
rambler_news_href_pattern = re.compile(r'(^http://news.rambler.ru/[d]+)')
for i in range(depth):
newpages={}
for page in pages:
try:
self.grab.go(page)
except:
print "Could not open %s" % page
continue
try:
article_text = '' # текст статьи
for paragraph in self.grab.tree.xpath("//p[contains(@class, 'b-article__paragraph')]"):
article_text += paragraph.text_content()
self.addtoindex(page, article_text) # записываем в базу текст статьи с индексацией
links = self.grab.tree.xpath("//a")
for link in links:
if ('href' in link.attrib):
url = urljoin(page, link.attrib['href']).split('#')[0]# делаем полную ссылку и удаляем часть за # если она есть
match = rambler_news_href_pattern.findall(url)
if match:
url = match[0]
if url[0:4] == 'http' and not self.isindexed(url):
newpages[url] = 1
linkText = link.text_content() # текст ссылки
self.addlinkref(page, url, linkText) # записываем в базу текст ссылки с индексацией
self.dbcommit()
except Exception, e:
print "Could not parse page %s" % page, e
pages = newpages
Построение индекса
Наш следующий шаг – подготовка базы данных для хранения полнотекстового индекса. Я уже говорил, что такой индекс представляет собой список слов, с каждым из которых ассоциировано множество документов, где это слово встречается, и место вхождения слова в документ. В данном примере мы анализируем только текст на странице, игнорируя все нетекстовые элементы. Кроме того, индексируются только сами слова, а все знаки препинания удаляются. Такой метод выделения слов несовершенен, но для построения простой поисковой машины сойдет.
Создание схемы
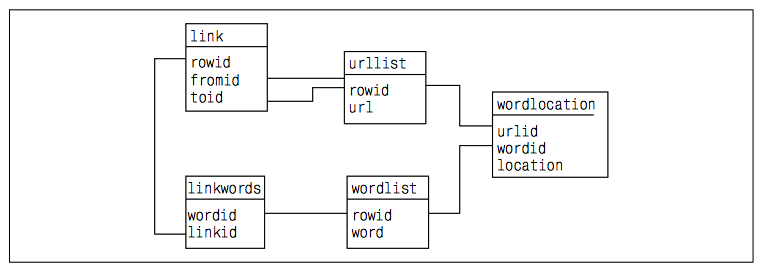
Подождите запускать программу – нужно сначала подготовить базу данных. Схема простого индекса состоит из пяти таблиц. Первая (url_list) – это список проиндексированных URL. Вторая (word_list) – список слов, а третья (word_location) – список мест вхождения слов в документы. В оставшихся двух таблицах хранятся ссылки между документами. В таблице link хранятся идентификаторы двух URL, связанных ссылкой, а в таблице link_words есть два столбца – word_id и link_id – для хранения слов, составляющих ссылку. Вся схема изображена на рисунке ниже. Код запросов приводить не буду, должны ведь и вы поработать)))
Выделение слов на странице
def getwords(html):
words = []
for split_str in html.split():
t = re.split("[s;:-_*".,?!()'&#«»]", split_str)
words += [a.lower() for a in t if a != '' and len(a) > 3]
return words
Добавление в индекс
Теперь мы готовы написать код метода addtoindex. Он вызывает две функции, написанные в предыдущем разделе, чтобы получить список слов на странице. Затем эта страница и все найденные на ней слова добавляются в индекс и создаются ссылки между словами и их вхождениями в документ. В нашем примере адресом вхождения будет считаться номер слова в списке слов.
def addtoindex(self, url, text):
if self.isindexed(url): return # если уже индексирована - пропускаем
print 'Indexing %s' % url
# Получаем слова из текста
words = getwords(text)
# Получаем id url'а
url_id = self.getentryid('url_list', 'url', url)
# Связываем слова с этим урлом
for i, word in enumerate(words): # пронумеруем слова
word_id = self.getentryid('word_list', 'word', word)
self.cur.execute("insert into word_location(url_id, word_id, location) values (%d, %d, %d)" % (url_id, word_id, i))
self.dbcommit()
# Узнаем id записи в БД, если нет
# иначе записываем и возвращаем новый
def getentryid(self, table, field, value, createnew=True):
self.cur.execute("select id from %s where %s = '%s'" % (table, field, value))
cur = self.cur.fetchone()
if not cur:
# print (table, field, value)
self.cur.execute("insert into %s (%s) values ('%s') returning %s.id" % (table, field, value, table))
cur = self.cur.fetchone()
self.dbcommit()
return cur[0]
else:
return cur[0]
# Возвращаем True, если посещали страницу
def isindexed(self, url):
self.cur.execute("select id from url_list where url = '%s'" % url)
u = self.cur.fetchone()
if u:
# Проверяем, что паук посещал страницу
self.cur.execute("select count(1) from word_location where url_id = %d" % u[0])
v = self.cur.fetchone()
if v[0]:
return True
return False
Последняя функция, необходимая нам для начала индексирования — это addlinkref. Как следует из ее названия, она заносит ссылки и слова из которых они состоят к нам в БД.
def addlinkref(self, urlFrom, urlTo, linkText):
words = getwords(linkText)
from_id = self.getentryid('url_list', 'url', urlFrom)
to_id = self.getentryid('url_list', 'url', urlTo)
if from_id == to_id: return
self.cur.execute("insert into link(from_id, to_id) values (%d, %d) returning link.id" % (from_id, to_id))
link_id = self.cur.fetchone()[0]
for word in words:
word_id = self.getentryid('word_list', 'word', word)
self.cur.execute("insert into link_words(link_id, word_id) values (%d, %d)" % (link_id, word_id))
Ну что же, на этом этапе мы можем запустить паука и создать базу данных)
Запросы
ого, грубого поиска, по абсолютному вхождению фразы в новость.
Таблица word_location обеспечивает простой способ связать слова с документами, так что мы можем легко найти, какие страницы содержат данное слово. Однако поисковая машина была бы довольно слабой, если бы не позволяла задавать запросы с несколькими словами. Чтобы исправить это упущение, нам понадобится функция, которая принимает строку запроса, разбивает ее на слова и строит SQL-запрос для поиска URL тех документов, в которые входят все указанные слова.
def get_match_rows(self, query):
select_query_add = []
join_query_add = []
where_query_add = []
main_search_query = """
SELECT wl0.url_id, %s
FROM word_location wl0
%s
WHERE %s
"""
query_words = getwords(query)
query_word_ids = []
for query_word in query_words:
self.cur.execute("select id from word_list where word = '%s'" % query_word)
query_word_id = self.cur.fetchone()
if query_word_id:
query_word_ids.append(query_word_id[0])
if query_word_ids:
for position, query_word_id in enumerate(query_word_ids):
if position:
join_query_add.append('JOIN word_location wl%d ON wl%d.url_id = wl%d.url_id' % (position, position-1, position))
select_query_add.append('wl%d.location' % position)
where_query_add.append('wl%d.word_id = %d' % (position, query_word_id))
main_search_query = main_search_query % (', '.join(select_query_add), ' '.join(join_query_add), ' and '.join(where_query_add))
self.cur.execute(main_search_query)
search_results = self.cur.fetchall()
return search_results, query_word_ids
SELECT wl0.url_id, wl0.location, wl1.location
FROM word_location wl0
JOIN word_location wl1 ON wl0.url_id = wl1.url_id
WHERE wl0.word_id = 2734 and wl1.word_id = 2698

В результате, получаем список кортежей и список с id слов. Каждый кортеж — это сто список вида (id новости, позиция 1го слова, позиция 2го слова…)
Ранжирование по содержимому
В этом разделе мы рассмотрим несколько способов вычисления ранга
на основе самого запроса и содержимого страницы, а именно:
- Частота слов
Количество вхождений в документ слова, указанного в запросе, помогает определить степень релевантности документа.
- Расположение в документе
Основная тема документа, скорее всего, раскрывается ближе к его началу.
- Расстояние между словами
Если в запросе несколько слов, то они должны встречаться в документе рядом.
# Функция, которая взвешивает результаты
def get_scored_list(self, rows, word_ids):
total_scores = {row[0]: 0 for row in rows}
if rows:
# Список весовых функций
weight_functions = [
]
for (weight, scores) in weight_functions:
for url in total_scores:
total_scores[url] += weight * scores[url]
return total_scores
# Возвращает полный урл по id
def get_url_name(self, url_id):
self.cur.execute("select url from url_list where id = %d" % url_id)
return self.cur.fetchone()[0]
# Основная функция поиска
def search(self, search_sentence):
search_results, word_ids = self.get_match_rows(search_sentence)
scores = self.get_scored_list(search_results, word_ids)
ranked_scores = [(score, url) for (url, score) in scores.items()]
ranked_scores.sort()
ranked_scores.reverse()
for (score, url_id) in ranked_scores[0:10]:
print '%ft%s' % (score, self.get_url_name(url_id))
return word_ids, [r[1] for r in ranked_scores[0:10]]
Наиболее важна здесь функция get_scored_list, код которой мы будем постепенно уточнять. По мере добавления функций ранжирования мы будем вводить их в список weight_functions и начнем взвешивать полученные результаты.
Функция нормализации
имо как-то нормализовать их, то есть привести к одному и тому же диапазону и направлению.
Функция нормализации принимает на входе словарь идентификаторов и рангов и возвращает новый словарь, в котором идентификаторы те же самые, а ранг находится в диапазоне от 0 до 1. Ранги масштабируются по близости к наилучшему результату, которому всегда припи- сывается ранг 1. От вас требуется лишь передать функции список рангов и указать, какой ранг лучше – меньший или больший:
def normalize_scores(self, scores, smallIsBetter=0):
vsmall = 0.00001 # Avoid division by zero errors
if smallIsBetter:
minscore = min(scores.values())
return {u: float(minscore)/max(vsmall, l) for (u,l) in scores.items()}
else:
maxscore = max(scores.values())
if maxscore == 0: maxscore = vsmall
return {u: float(c)/maxscore for (u,c) in scores.items()}
return scores
Весовые функции
Частота слов
Метрика, основанная на частоте слов, ранжирует страницу исходя из того, сколько раз в ней встречаются слова, упомянутые в запросе. Если я выполняю поиск по слову python, то в начале списка скорее получу страницу, где это слово встречается много раз, а не страницу о музыканте, который где-то в конце упомянул, что у него дома живет питон.
def frequency_score(self, rows):
counts = {row[0]:0 for row in rows}
for row in rows:
counts[row[0]] += 1
return self.normalize_scores(counts)
Чтобы активировать ранжирование документов по частоте слов, измените строку функции get_scored_list, где определяется список weight_functions, следующим образом:
weight_functions = [(1.0,self.frequency_score(rows))]
Расположение в документе
Еще одна простая метрика для определения релевантности страницы запросу – расположение поисковых слов на странице. Обычно, если страница релевантна поисковому слову, то это слово расположено близко к началу страницы, быть может, даже находится в заголовке.
def location_score(self, rows):
locations = {}
for row in rows:
loc = sum(row[1:])
if locations.has_key(row[0]):
if loc < locations[row[0]]:
locations[row[0]] = loc
else:
locations[row[0]] = loc
return self.normalizescores(locations, smallIsBetter=1)
Расстояние между словами
Если запрос содержит несколько слов, то часто бывает полезно ранжировать результаты в зависимости от того, насколько близко друг к другу встречаются поисковые слова. Как правило, вводя запрос из нескольких слов, человек хочет найти документы, в которых эти слова концептуально связаны. Рассматриваемая метрика допускает изменение порядка и наличие дополнительных слов между поисковыми.
def distance_score(self, rows):
mindistance = {}
# Если только 1 слово, любой документ выигрывает
if len(rows[0]) <= 2:
return {row[0]: 1.0 for row in rows}
mindistance = {}
for row in rows:
dist = sum([abs(row[i]-row[i-1]) for i in xrange(2, len(row))])
if mindistance.has_key(row[0]):
if dist < mindistance[row[0]]:
mindistance[row[0]] = dist
else:
mindistance[row[0]] = dist
return self.normalize_scores(mindistance, smallIsBetter=1)
Использование внешних ссылок на сайт
Все обсуждавшиеся до сих пор метрики ранжирования были основаны на содержимом страницы. Часто результаты можно улучшить, приняв во внимание, что говорят об этой странице другие, а точнее те сайты, на которых размещена ссылка на нее. Особенно это полезно при индексировании страниц сомнительного содержания или таких, которые могли быть созданы спамерами, поскольку маловероятно, что на такие страницы есть ссылки с настоящих сайтов.
Простой подсчет ссылок
Простейший способ работы с внешними ссылками заключается в том, чтобы подсчитать, сколько их ведет на каждую страницу, и использовать результат в качестве метрики. Так обычно оцениваются научные работы; считается, что их значимость тем выше, чем чаще их цитируют.
def inbound_link_score(self, rows):
unique_urls = {row[0]: 1 for row in rows}
inbound_count = {}
for url_id in unique_urls:
self.cur.execute('select count(*) from link where to_id = %d' % url_id)
inbound_count[url_id] = self.cur.fetchone()[0]
return self.normalize_scores(inbound_count)
Описанный алгоритм трактует все внешние ссылки одинаково, но такой уравнительный подход открывает возможность для манипулирования, поскольку кто угодно может создать несколько сайтов, указывающих на страницу, ранг которой он хочет поднять. Также возможно, что людям более интерес
Друзья помогите этому контенту стать доступнее в социальных сетях.Не проходи мимо жмакни по кнопке возможно кому то еще он будет полезен!