
Давайте разберемся, как решать задачи со множеством участников, применяя технику стохастической оптимизации. По существу, оптимизация сводится к поиску наилучшего решения задачи путем апробирования различных решений и сравнения их между собой для оценки качества. Обычно оптимизация применяется в тех случаях, когда число решений слишком велико и перебрать их все невозможно.
У методов оптимизации весьма широкая область применения: в физике они используются для изучения молекулярной динамики, в биологии – для прогнозирования белковых структур, а в информатике – для определения времени работы алгоритма в худшем случае. В НАСА методы оптимизации применяют даже для проектирования антенн с наилучшими эксплуатационными характеристиками. Выглядят они так, как ни один человек не мог бы вообразить.
Мы же, для примера, возьмем классическую задачу группового путешествия!)
Формат данных
Члены семьи живут в разных концах страны и хотят встретиться в Урюпинске. Все они должны вылететь в один день и в один день улететь и при этом в целях экономии хотели бы уехать из аэропорта и приехать в него на одной арендованной машине. Ежедневно, в славный город Урюпинск, из мест проживания любого члена семьи отправляются десятки рейсов, все в разное время. Цена билета и время в пути для каждого рейса разные.
peoples = [('Seymour','BOS'),
('Franny','DAL'),
('Zooey','CAK'),
('Walt','MIA'),
('Buddy','ORD'),
('Les','OMA')]
# место назначения
destination = 'LGA'
# словарь рейсовflights = {('LGA', 'CAK'): [('6:58', '9:01', 238), ('8:19', '11:16', 122), ('9:58', '12:56', 249), ('10:32', '13:16', 139), ('12:01', '13:41', 267), ('13:37', '15:33', 142), ('15:50', '18:45', 243), ('16:33', '18:15', 253), ('18:17', '21:04', 259), ('19:46', '21:45', 214)], ('DAL', 'LGA'): [('6:12', '10:22', 230), ('7:53', '11:37', 433), ('9:08', '12:12', 364), ('10:30', '14:57', 290), ('12:19', '15:25', 342), ('13:54', '18:02', 294), ('15:44', '18:55', 382), ('16:52', '20:48', 448), ('18:26', '21:29', 464), ('20:07', '23:27', 473)], ('LGA', 'BOS'): [('6:39', '8:09', 86), ('8:23', '10:28', 149), ('9:58', '11:18', 130), ('10:33', '12:03', 74), ('12:08', '14:05', 142), ('13:39', '15:30', 74), ('15:25', '16:58', 62), ('17:03', '18:03', 103), ('18:24', '20:49', 124), ('19:58', '21:23', 142)], ('LGA', 'MIA'): [('6:33', '9:14', 172), ('8:23', '11:07', 143), ('9:25', '12:46', 295), ('11:08', '14:38', 262), ('12:37', '15:05', 170), ('14:08', '16:09', 232), ('15:23', '18:49', 150), ('16:50', '19:26', 304), ('18:07', '21:30', 355), ('20:27', '23:42', 169)], ('LGA', 'OMA'): [('6:19', '8:13', 239), ('8:04', '10:59', 136), ('9:31', '11:43', 210), ('11:07', '13:24', 171), ('12:31', '14:02', 234), ('14:05', '15:47', 226), ('15:07', '17:21', 129), ('16:35', '18:56', 144), ('18:25', '20:34', 205), ('20:05', '21:44', 172)], ('OMA', 'LGA'): [('6:11', '8:31', 249), ('7:39', '10:24', 219), ('9:15', '12:03', 99), ('11:08', '13:07', 175), ('12:18', '14:56', 172), ('13:37', '15:08', 250), ('15:03', '16:42', 135), ('16:51', '19:09', 147), ('18:12', '20:17', 242), ('20:05', '22:06', 261)], ('CAK', 'LGA'): [('6:08', '8:06', 224), ('8:27', '10:45', 139), ('9:15', '12:14', 247), ('10:53', '13:36', 189), ('12:08', '14:59', 149), ('13:40', '15:38', 137), ('15:23', '17:25', 232), ('17:08', '19:08', 262), ('18:35', '20:28', 204), ('20:30', '23:11', 114)], ('LGA', 'DAL'): [('6:09', '9:49', 414), ('7:57', '11:15', 347), ('9:49', '13:51', 229), ('10:51', '14:16', 256), ('12:20', '16:34', 500), ('14:20', '17:32', 332), ('15:49', '20:10', 497), ('17:14', '20:59', 277), ('18:44', '22:42', 351), ('19:57', '23:15', 512)], ('LGA', 'ORD'): [('6:03', '8:43', 219), ('7:50', '10:08', 164), ('9:11', '10:42', 172), ('10:33', '13:11', 132), ('12:08', '14:47', 231), ('14:19', '17:09', 190), ('15:04', '17:23', 189), ('17:06', '20:00', 95), ('18:33', '20:22', 143), ('19:32', '21:25', 160)], ('ORD', 'LGA'): [('6:05', '8:32', 174), ('8:25', '10:34', 157), ('9:42', '11:32', 169), ('11:01', '12:39', 260), ('12:44', '14:17', 134), ('14:22', '16:32', 126), ('15:58', '18:40', 173), ('16:43', '19:00', 246), ('18:48', '21:45', 246), ('19:50', '22:24', 269)], ('MIA', 'LGA'): [('6:25', '9:30', 335), ('7:34', '9:40', 324), ('9:15', '12:29', 225), ('11:28', '14:40', 248), ('12:05', '15:30', 330), ('14:01', '17:24', 338), ('15:34', '18:11', 326), ('17:07', '20:04', 291), ('18:23', '21:35', 134), ('19:53', '22:21', 173)], ('BOS', 'LGA'): [('6:17', '8:26', 89), ('8:04', '10:11', 95), ('9:45', '11:50', 172), ('11:16', '13:29', 83), ('12:34', '15:02', 109), ('13:40', '15:37', 138), ('15:27', '17:18', 151), ('17:11', '18:30', 108), ('18:34', '19:36', 136), ('20:17', '22:22', 102)]}
рейсов имеет следующий формат: {(‘LGA’, ‘CAK’): [(‘6:58’, ‘9:01’, 238), (‘8:19′, ’11:16’, 122),….], …..} — (аэропорт вылета, прилета), как ключ и (время вылета, время прилета, стоимость), как значение. Заполните его произвольным способом, можно поискать на сайтах авиа и заполнить реальной ситуацией))
Для подобных задач необходимо определиться со способом представления потенциальных решений. Функции оптимизации, с которыми вы вскоре ознакомитесь, достаточно общие и применимы к различным задачам, поэтому так важно выбрать простое представление, которое не было бы привязано к конкретной задаче о групповом путешествии. Очень часто для этой цели выбирают список чисел. Каждое число обозначает рейс, которым решил лететь участник группы.
Например, в решении, представленном списком [1,4,3,2,7,3,6,3,2,4,5,3]
Сеймур (Seymour) летит первым рейсом из Бостона в Нью-Йорк и четвертым рейсом из Нью-Йорка в Бостон, а Фрэнни (Franny) – третьим рейсом из Далласа в Нью-Йорк и вторым обратно.
Целевая функция
Ключом к решению любой задачи оптимизации является целевая функция, и именно ее обычно труднее всего отыскать. Цель оптимизационного алгоритма состоит в том, чтобы найти такой набор входных переменных, который минимизирует целевую функцию. Поэтому целевая функция должна возвращать значение, показывающее, насколько данное решение неудовлетворительно. Возвращаемое значение должно быть тем больше, чем хуже решение.
- Цена
Полная стоимость всех билетов или, возможно, среднее значение, взвешенное с учетом финансовых возможностей.
- Время в пути
Суммарное время, проведенное всеми членами семьи в полете.
- Время ожидания
Время, проведенное в аэропорту в ожидании прибытия остальных членов группы.
- Время вылета
Если самолет вылетает рано утром, это может увеличивать общую стоимость из-за того, что путешественники не выспятся.
- Время аренды автомобилей
Если группа арендует машину, то вернуть ее следует до того часа, когда она была арендована, иначе придется платить за лишний день.
Определившись с тем, какие переменные влияют на стоимость, нужно решить, как из них составить одно число. В нашем случае можно, например, выразить в деньгах время в пути или время ожидания в аэропорту. Скажем, каждая минута в воздухе эквивалентна $1 (иначе гово- ря, можно потратить лишние $90 на прямой рейс, экономящий полтора часа), а каждая минута ожидания в аэропорту эквивалентна $0,50. Можно было бы также приплюсовать стоимость лишнего дня аренды машины, если для всех имеет смысл вернуться в аэропорт к более поз- днему часу.
Определенная ниже, целевая функция shedule_cost принимает во внимание полную стоимость поездки и общее время ожидания в аэропорту всеми членами семьи. Кроме того, она добавляет штраф $50, если машина возвращена в более поздний час, чем арендована.
# время в минутах
def get_minutes(t):
x=time.strptime(t,'%H:%M')
return x[3]*60+x[4]
def schedule_cost(sol):
totalprice = 0
latestarrival = 0
earliestdep = 24*60
for d in xrange(len(sol)/2):
# Получить список прибывающих и убывающих реисов
origin = peoples[d][1]
outbound = flights[(origin, destination)][int(sol[d])]
returnf = flights[(destination, origin)][int(sol[d+1])]
# Полная цена равна сумме цен на билет туда и обратно
totalprice += outbound[2]
totalprice += returnf[2]
# Находим самыи позднии прилет и самыи раннии вылет
if latestarrival < get_minutes(outbound[1]): latestarrival = get_minutes(outbound[1])
if earliestdep > get_minutes(returnf[0]): earliestdep = get_minutes(returnf[0])
# Все должны ждать в аэропорту прибытия последнего участника группы.
# Обратно все прибывают одновременно и должны ждать свои реисы.
totalwait = 0
for d in xrange(len(sol)/2):
origin = peoples[d][1]
outbound = flights[(origin, destination)][int(sol[d])]
returnf = flights[(destination, origin)][int(sol[d+1])]
totalwait += latestarrival - get_minutes(outbound[1])
totalwait += get_minutes(returnf[0]) - earliestdep
# Для этого решения требуется оплачивать дополнительныи день аренды?
# Если да, это обоидется в лишние $50!
if latestarrival > earliestdep: totalprice += 50
return totalprice + totalwait
Логика этой функции очень проста, но суть вопроса она отражает. Улучшить ее можно несколькими способами. Так, в текущей версии предполагается, что все члены семьи уезжают из аэропорта вместе, когда прибывает самый последний, а возвращаются в аэропорт к моменту вылета самого раннего рейса. Можно поступить по-другому: если человеку приходится ждать два часа или дольше, то он арендует отдельную машину, а
цены и время ожидания соответственно корректируются.
Случайный поиск
Случайный поиск – не самый лучший метод оптимизации, но он позволит нам ясно понять, чего пытаются достичь все алгоритмы, а также послужит эталоном, с которым можно будет сравнивать другие алгоритмы.
Соответствующая функция принимает два параметра. Domain – это список значений, определяющих количество вариантов рейсов каждого из участников путешествия. Важно что они отсортированы в том же порядке, что и сами участники, сначала идут в Урюпинск, потом оттуда. Длина решения совпадает с длиной этого списка.
Второй параметр, costf, – это целевая функция; в нашем примере в этом качестве используется schedule_cost. Она передается в виде параметра, чтобы алгоритм можно было использовать повторно и для других задач оптимизации. Алгоритм случайным образом генерирует 1000 гипотез и для каждой вызывает функцию costf. Возвращается наилучшая гипотеза (с минимальной стоимостью).
domain = []
for people in peoples:
domain.append(len(flights[(people[1], destination)]) - 1)
domain.append(len(flights[(destination, people[1])]) - 1)
print domain
def random_optimize(domain, costf):
best=999999999
bestr=None
for i in xrange(0, 1000):
# Выбрать случаиное решение
r = [random.randint(0, domain[i]) for i in xrange(len(domain))]
# Get the cost
cost = costf(r)
# Сравнить со стоимостью наилучшего наиденного к этому моменту решения
if cost < best:
best = cost
bestr = r
return r, best
result, score = random_optimize(domain, schedule_cost)
print result, score
Алгоритм спуска с горы
Случайное апробирование решений очень неэффективно, потому что пренебрегает выгодами, которые можно получить от анализа уже найденных хороших решений. В нашем примере можно предположить, что расписание с низкой полной стоимостью похоже на другие расписания с низкой стоимостью.

Представьте, что человечек на рисунке – это вы и оказались в этом месте по воле случая. Вы хотите добраться до самой низкой точки, чтобы найти воду. Для этого вы, наверное, осмотритесь и направитесь туда, где склон самый крутой. И будете двигаться в направлении наибольшей крутизны, пока не дойдете до точки, где местность становится ровной или начинается подъем.
def hill_climb(domain, costf):
# Выбрать случаиное решение
sol = [random.randint(0, domain[i]) for i in xrange(len(domain))]
best = costf(sol)
# Главныи цикл
is_stop = False
while not is_stop:
# Создать список соседних решении
neighbors = []
for j in xrange(len(domain)):
# Отходим на один шаг в каждом направлении
if 0 < sol[j] < 9:
neighbors.append(sol[0:j] + [sol[j]+1] + sol[j+1:])
neighbors.append(sol[0:j] + [sol[j]-1] + sol[j+1:])
if 0 == sol[j]:
neighbors.append(sol[0:j] + [sol[j]+1] + sol[j+1:])
if sol[j] == domain[j]:
neighbors.append(sol[0:j] + [sol[j]-1] + sol[j+1:])
# Ищем наилучшее из соседних решении
is_stop = True
for j in xrange(len(neighbors)):
cost = costf(neighbors[j])
if cost < best:
is_stop = False
best = cost
sol = neighbors[j]
return sol, best
result, score = hill_climb(domain, schedule_cost)
print result, score
Для выбора начального решения эта функция генерирует случайный список чисел из заданного диапазона. Соседи текущего решения ищутся путем посещения каждого элемента списка и создания двух новых списков, в одном из которых этот элемент увеличен на единицу, а в другом уменьшен на единицу. Лучшее из соседних решений становится новым решением.
этот мест даст так себе результаты. Хотя, в большинстве случаев, лучше чем 1000 случайных вариантов. Однако у алгоритма спуска с горы, есть один существенный недостаток.
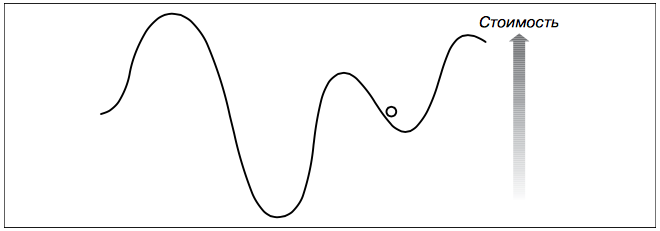
Из рисунка видно, что, спускаясь по склону, мы необязательно отыщем наилучшее возможное решение. Найденное решение будет локальным минимумом, то есть лучшим из всех в ближайшей окрестности, но это не означает, что оно вообще лучшее. Решение, лучшее среди всех возможных, называется глобальным минимумом, и именно его хотят найти все алгоритмы оптимизации. Один из возможных подходов к решению проблемы называется спуском с горы со случайным перезапуском. В этом случае алгоритм спуска выполняется несколько раз со случайными начальными точками в надежде, что какое-нибудь из найденных решений будет близко к глобальному минимуму. Так же, все усугубляется тем, что у такой ф-ии как наша, большая импульсивность (много локальных минимумов и максимумов), очень не линейная скорость роста в разных точках, в общем очень много факторов, с учетом того, что мы рассматриваем ф-ию в 12 мерном пространстве и в каждом из них она ведет себя по-разному…
Алгоритм имитации отжига
Алгоритм имитации отжига навеян физическими аналогиями. Отжигом называется процесс нагрева образца с последующим медленным охлаждением. Поскольку сначала атомы заставляют попрыгать, а затем постепенно «отпускают вожжи», то они переходят в новую низко-энергетичную конфигурацию.
Алгоритмическая версия отжига начинается с выбора случайного решения задачи. В ней используется переменная, интерпретируемая как температура, начальное значение которой очень велико, но постепенно уменьшается. На каждой итерации случайным образом выбирается один из параметров решения и изменяется в определенном направлении.
Тут есть важная деталь: если новая стоимость ниже, то новое решение становится текущим, как и в алгоритме спуска с горы. Но, даже если новая стоимость выше, новое решение все равно может стать текущим с некоторой вероятностью. Так мы пытаемся избежать ситуации скатывания в локальный минимум.
Поскольку температура (готовность принять худшее решение) вначале очень высока, то показатель степени близок к 0, поэтому вероятность равна почти 1. По мере уменьшения температуры разность между высокой стоимостью и низкой стоимостью становится более значимой, а чем больше разность, тем ниже вероятность, поэтому алгоритм из всех худших решений будет выбирать те, что лишь немногим хуже текущего.
def annealing_optimize(domain, costf, T=10000.0, cool=0.99, step=1):
# Выбрать случаиное решение
vec = [random.randint(0, domain[i]) for i in xrange(len(domain))]
while T > 0.1:
# Выбрать один из индексов
i = random.randint(0, len(domain)-1)
# Выбрать направление изменения
dir = random.randint(-step, step)
# Создать новыи список, в котором одно значение изменено
vecb = vec[:]
vecb[i] += dir
if vecb[i] < 0: vecb[i] = 0
elif vecb[i] > domain[i]: vecb[i] = domain[i]
# Вычислить текущую и новую стоимость
ea = costf(vec)
eb = costf(vecb)
p = pow(math.e, (-eb-ea)/T)
# Новое решение лучше? Если нет, метнем кости
if (eb < ea or random.random() < p):
vec = vecb
# Уменьшить температуру
T = T * cool
return vec, eb
result, score = annealing_optimize(domain, schedule_cost)
print result, score
На каждой итерации в качестве i случайно выбирается одна из переменных решения, а dir случайно выбирается межд