Большие информационные системы генерируют огромное количество служебной информации, которую нужно где-то хранить. Я расскажу о том, как настроить хранилище для логов на базе Elasticsearch, Logstash и Kibana, которое называют ELK Stack. В это хранилище можно настроить отправку практически любых логов в разных форматах и большого объема.
Введение
Я буду настраивать одиночный хост. В данной статье будут самые азы — как сделать быструю установку и базовую настройку, чтобы можно было собирать логи в Elasticsearch и смотреть их в Kibana. Для примера, настрою сбор логов как с linux, так и windows серверов. Инструкция по установке будет полностью основана на официальной документации. Если вы хорошо читаете английские тексты, то можете использовать ее. Неудобство будет в том, что вся информация разрозненно располагается в разных статьях. Если вы первый раз настраиваете ELK Stack, то будет трудно сразу во всем разобраться. В своей статье я собрал в одном месте необходимый минимум для запуска Elasticsearch, Logstash, Kibana и агентов Filebeat и Winlogbeat для отправки логов с серверов.
Что такое ELK Stack
Расскажу своими словами о том, что мы будем настраивать. Ранее на своем сайте я уже рассказывал о централизованном сборе логов с помощью syslog-ng. Это вполне рабочее решение, хотя очевидно, что когда у тебя становится много логов, хранить их в текстовых файлах неудобно. Надо как-то обрабатывать и выводить в удобном виде для просмотра. Именно эти проблемы и решает представленный стек программ:
- Elasticsearch используется для хранения, анализа, поиска по логам.
- Kibana представляет удобную и красивую web панель для работы с логами.
- Logstash сервис для сбора логов и отправки их в Elasticsearch. В самой простой конфигурации можно обойтись без него и отправлять логи напрямую в еластик. Но с logstash это делать удобнее.
- Beats — агенты для отправки логов в Logstash или Elasticsearch. Они бывают разные. Я буду использовать Filebeat для отправки данных из текстовых логов linux и Winlogbeat для отправки логов из журналов Windows систем.
К этой связке еще добавляется Nginx, который проксирует соединения в Kibana. В самом простом случае он не нужен, но с ним удобнее. Можно, к примеру, добавить авторизацию или ssl сертификат, в nginx удобно управлять именем домена. В случае большой нагрузки, разные службы разносятся по разным серверам или кластерам. В своем примере я все установлю на один сервер. Схематично работу данной системы можно изобразить вот так: 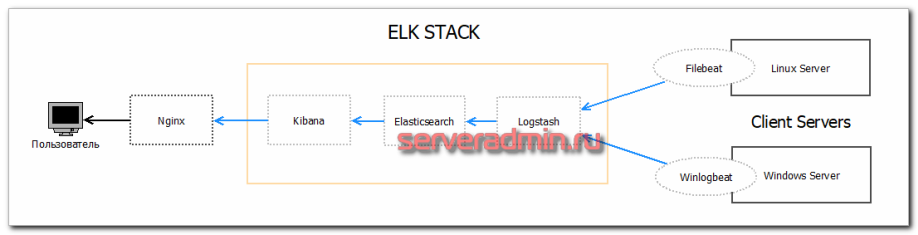 Начнем по этапам устанавливать и настраивать все компоненты нашей будущей системы хранения и обработки логов различных информационных систем.
Начнем по этапам устанавливать и настраивать все компоненты нашей будущей системы хранения и обработки логов различных информационных систем.
Раньше для установки всех перечисленных компонентов необходимо было отдельно устанавливать Java на сервер. Сейчас в этом нет необходимости, так как Java уже включена в пакеты устанавливаемого ПО.
Системные требования
Для установки одиночного инстанса с полным набором компонентов ELK необходимы следующие системные ресурсы.
| минимальные | рекомендуемые | |
| CPU | 2 | 4+ |
| Memory | 6 Gb | 8+ Gb |
| Disk | 10 Gb | 10+ Gb |
Некоторое время назад для тестовой установки ELK Stack достаточно было 4 Gb оперативной памяти. На текущий момент с версией 8.5 у меня не получилось запустить одновременно Elasticsearch, Logstash и Kibana на одной виртуальной машине с четырьмя гигабайтами памяти. После того, как увеличил до 6, весь стек запустился. Но для комфортной работы с ним нужно иметь не менее 8 Gb и 4 CPU. Если меньше, то виртуальная машина начинает тормозить, очень долго перезапускаются службы. Работать некомфортно.
В системных требованиях для ELK я указал диск в 10 Gb. Этого действительно хватит для запуска стека и тестирования его работы на небольшом объеме данных. В дальнейшем, понятное дело, необходимо ориентироваться на реальный объем данных, которые будут храниться в системе.
Установка Elasticsearch
Устанавливаем ядро системы по сбору логов — Elasticsearch. Его установка очень проста за счет готовых пакетов под все популярные платформы.
На момент последнего редактирования этой статьи доступ к репозиториям Elastic с IP адресов России заблокирован. Для установки нужно настраивать прокси или vpn на сервере, либо вручную скачивать пакеты по ссылке elastic.co/downloads и копировать на сервер.
Ubuntu / Debian
Копируем себе публичный ключ репозитория:
# wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Если у вас нет пакета apt-transport-https, то надо установить:
# apt install apt-transport-https
Добавляем репозиторий Elasticsearch в систему:
echo "deb https://artifacts.elastic.co/packages/8.x/apt stable main" | tee -a /etc/apt/sources.list.d/elastic-8.x.list
Если у вас нет доступа к репозиторию, то можете воспользоваться моим. Я создал копию репозитория elastic для Debian 11 и 12. Под все остальные системы можно через браузер скачать нужный пакет и установить вручную. Подключаем к Debian 11:
# echo "deb http://elasticrepo.serveradmin.ru bullseye main" | tee /etc/apt/sources.list.d/elasticrepo.list # wget -qO - http://elasticrepo.serveradmin.ru/elastic.asc | apt-key add -
Подключаем к Debian 12:
# echo "deb http://elasticrepo.serveradmin.ru bookworm main" | tee /etc/apt/sources.list.d/elasticrepo.list # wget -qO - http://elasticrepo.serveradmin.ru/elastic.asc | apt-key add -
Устанавливаем Elasticsearch на Debian или Ubuntu:
# apt update && apt install elasticsearch
В консоли вы увидите некоторую полезную информацию, которую имеет смысл сохранить.
- Пароль встроенной учётной записи elastic с полными правами.
- Команда на сброс пароля для elastic.
- Команда для генерации токена доступа для Kibana.
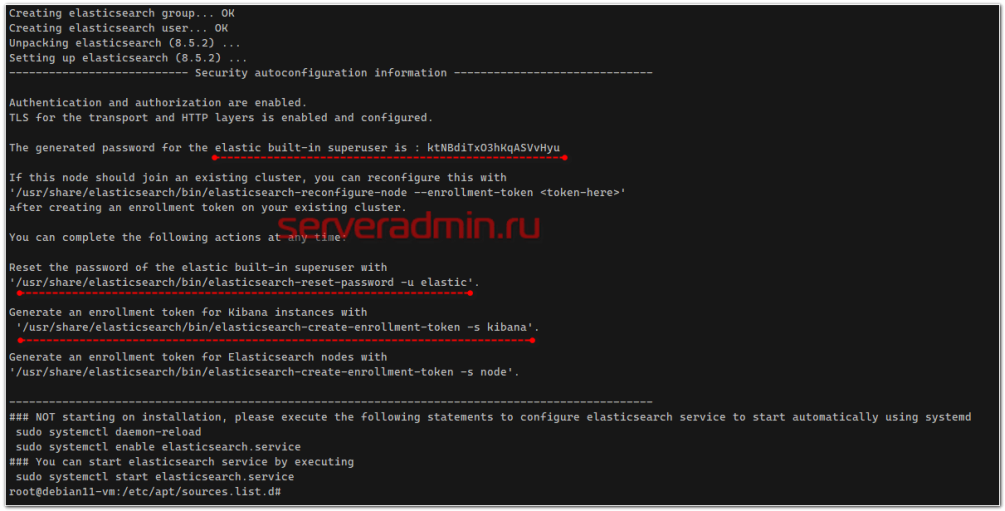
После установки добавляем elasticsearch в автозагрузку и запускаем.
# systemctl daemon-reload # systemctl enable elasticsearch.service # systemctl start elasticsearch.service
Проверяем, запустился ли он:
# systemctl status elasticsearch.service
Проверим теперь, что elasticsearch действительно нормально работает. Выполним к нему простой запрос об его статусе. Здесь нам уже пригодится учётная запись с правами доступа к кластеру. Неавторизованные запросы, а также запросы по HTTP в 8-й версии elasticsearch не принимаются.
# # curl -k --user elastic:'ktNBdiTxO3hKqASVvHyu' https://127.0.0.1:9200
{
"name" : "debian11-vm",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "vuinIS6tRACwasu9nG2kdw",
"version" : {
"number" : "8.5.2",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "a846182fa16b4ebfcc89aa3c11a11fd5adf3de04",
"build_date" : "2022-11-17T18:56:17.538630285Z",
"build_snapshot" : false,
"lucene_version" : "9.4.1",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
В случае запроса по HTTP, а не HTTPS, в логе Elasticsearch будет ошибка:
received plaintext http traffic on an https channel, closing connection Netty4HttpChannel{localAddress=/127.0.0.1:9200, remoteAddress=/127.0.0.1:39964
Если у вас всё в порядке, то переходим к настройке Elasticsearch.
Centos Stream, Rocky Linux, Almalinux, Oracle Linux
Установка Elasticsearch на rpm операционные системы (Centos, Rocky Linux, Almalinux, Oracle Linux) ничем не отличается от deb систем. Копируем публичный ключ репозитория:
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
Подключаем репозиторий Elasticsearch:
# mcedit /etc/yum.repos.d/elasticsearch.repo
[elastic-8.x] name=Elastic repository for 8.x packages baseurl=https://artifacts.elastic.co/packages/8.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md
Приступаем к установке еластика:
# yum install --enablerepo=elasticsearch elasticsearch
Если скачали пакет вручную с любого компьютера, скопировали на сервер, то установить можно следующим образом:
# rpm -ivh elasticsearch-8.5.2-x86_64.rpm
В консоли вы увидите некоторую полезную информацию, которую имеет смысл сохранить.
- Пароль встроенной учётной записи elastic с полными правами.
- Команда на сброс пароля для elastic.
- Команда для генерации токена доступа для Kibana.
В в завершении установки добавим elasticsearch в автозагрузку и запустим его с дефолтными настройками:
# systemctl daemon-reload # systemctl enable elasticsearch.service # systemctl start elasticsearch.service
Проверяем, запустилась ли служба:
# systemctl status elasticsearch.service
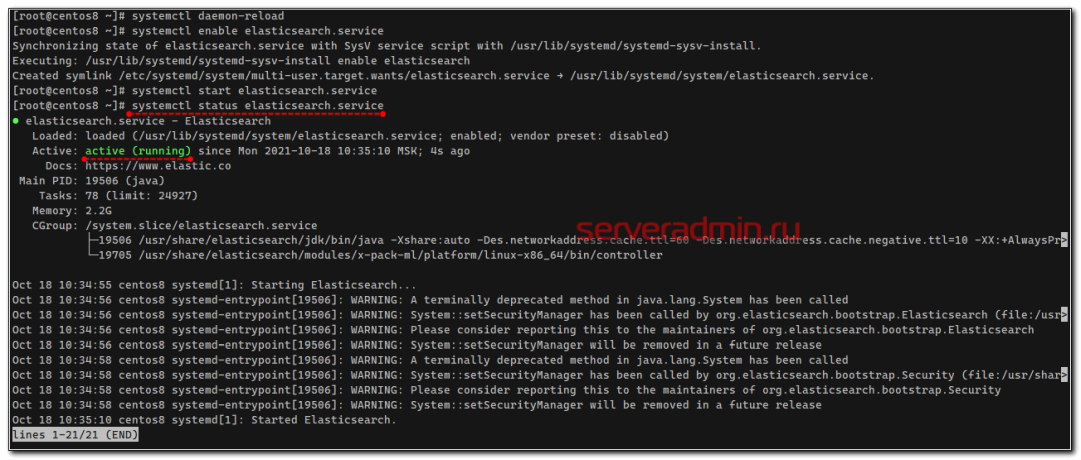
Проверим теперь, что elasticsearch действительно нормально работает. Выполним к нему простой запрос о его статусе, не забывая об аутентификации.
# curl -k --user elastic:'ktNBdiTxO3hKqASVvHyu' https://127.0.0.1:9200
{
"name" : "rockylinux8",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "vuinIS6tRACwasu9nG2kdw",
"version" : {
"number" : "8.5.2",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "a846182fa16b4ebfcc89aa3c11a11fd5adf3de04",
"build_date" : "2022-11-17T18:56:17.538630285Z",
"build_snapshot" : false,
"lucene_version" : "9.4.1",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
Все в порядке, сервис реально запущен и отвечает на запросы.
Настройка Elasticsearch
Настройки Elasticsearch находятся в файле /etc/elasticsearch/elasticsearch.yml. На начальном этапе нас будут интересовать следующие параметры:
path.data: /var/lib/elasticsearch # директория для хранения данных network.host: 127.0.0.1 # слушаем только локальный интерфейс http.host: 127.0.0.1 # слушаем только локальный интерфейс
По умолчанию Elasticsearch слушает localhost. Нам это и нужно, так как данные в него будет передавать logstash, который будет установлен локально. Обращаю отдельное внимание на параметр для директории с данными. Чаще всего они будут занимать значительное место, иначе зачем нам Elasticsearch. Подумайте заранее, где вы будете хранить логи. Все остальные настройки я оставляю дефолтными. После изменения настроек, надо перезапустить службу:
# systemctl restart elasticsearch.service
Смотрим, что получилось:
# netstat -tulnp | grep 9200 tcp6 0 0 127.0.0.1:9200 :::* LISTEN 19788/java
Elasticsearch повис на локальном интерфейсе. Причем я вижу, что он слушает ipv6, а про ipv4 ни слова. Но его он тоже слушает, так что все в порядке. Если вы хотите, чтобы elasticsearch слушал все сетевые интерфейсы, настройте параметр:
network.host: 0.0.0.0
Только не спешите сразу же запускать службу. Если запустите, получите ошибку:
[2021-10-18T10:41:51,062][ERROR][o.e.b.Bootstrap ] [centos8] node validation exception [1] bootstrap checks failed. You must address the points described in the following [1] lines before starting Elasticsearch. bootstrap check failure [1] of [1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
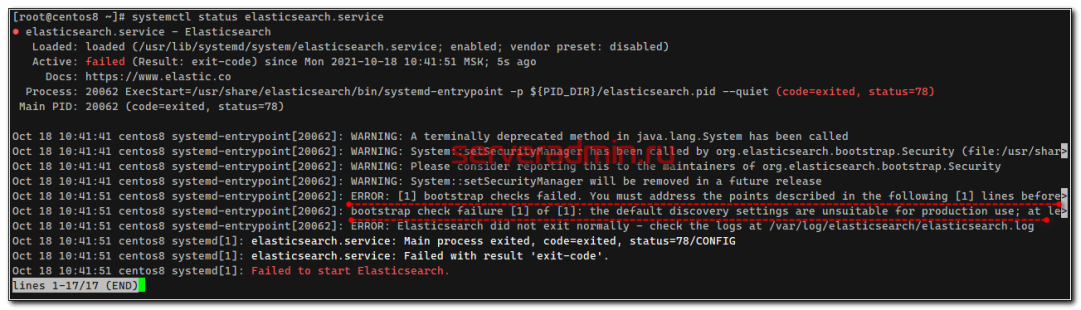
Чтобы ее избежать, дополнительно надо добавить еще один параметр:
discovery.seed_hosts: ["127.0.0.1", "[::1]"]
Этим мы указываем, что хосты кластера следует искать только локально. Переходим к установке Kibana.
Установка Kibana
Дальше устанавливаем web панель Kibana для визуализации данных, полученных из Elasticsearch. Тут тоже ничего сложного, репозиторий и готовые пакеты есть под все популярные платформы. Репозитории и публичный ключ для установки Kibana будут такими же, как в установке Elasticsearch. Но я еще раз все повторю для тех, кто будет устанавливать только Kibana, без всего остального. Это продукт законченный и используется не только в связке с Elasticsearch.
Centos Stream, Rocky Linux, Almalinux, Oracle Linux
Импортируем ключ репозитория:
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
Добавляем конфиг репозитория:
# mcedit /etc/yum.repos.d/kibana.repo
[elastic-8.x] name=Elastic repository for 8.x packages baseurl=https://artifacts.elastic.co/packages/8.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md
Запускаем установку Kibana:
# yum install kibana
Если репозиторий заблокирован, то качаем и копируем файл вручную, запускаем установку:
# rpm -ivh kibana-8.5.2-amd64.deb
Добавляем Кибана в автозагрузку и запускаем:
# systemctl daemon-reload # systemctl enable kibana.service # systemctl start kibana.service
Проверяем состояние запущенного сервиса:
# systemctl status kibana.service
По умолчанию, Kibana слушает порт 5601. Только не спешите его проверять после запуска. Кибана стартует долго. Подождите примерно минуту и проверяйте.
# netstat -tulnp | grep 5601 tcp 0 0 127.0.0.1:5601 0.0.0.0:* LISTEN 20746/node
Ubuntu, Debian
Установка Kibana на Debian или Ubuntu такая же, как и на центос — подключаем репозиторий и ставим из deb пакета. Добавляем публичный ключ:
# wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | apt-key add -
Добавляем репозиторий Kibana:
# echo "deb https://artifacts.elastic.co/packages/8.x/apt stable main" | tee -a /etc/apt/sources.list.d/elastic-8.x.list
Или мой репозиторий:
# echo "deb http://elasticrepo.serveradmin.ru bullseye main" | tee /etc/apt/sources.list.d/elasticrepo.list # wget -qO - http://elasticrepo.serveradmin.ru/elastic.asc | apt-key add -
Запускаем установку Kibana:
# apt update && apt install kibana
Добавляем Кибана в автозагрузку и запускаем:
# systemctl daemon-reload # systemctl enable kibana.service # systemctl start kibana.service
Проверяем состояние запущенного сервиса:
# systemctl status kibana.service
По умолчанию, Kibana слушает порт 5601. Только не спешите его проверять после запуска. Кибана стартует долго. Подождите примерно минуту и проверяйте.
# netstat -tulnp | grep 5601 tcp 0 0 127.0.0.1:5601 0.0.0.0:* LISTEN 1487/node
Настройка Kibana
Файл с настройками Кибана располагается по пути — /etc/kibana/kibana.yml. На начальном этапе нам нужно корректно настроить подключение к серверу elasticsearch. По умолчанию Kibana слушает только localhost и не позволяет подключаться удаленно. Это нормальная ситуация, если у вас будет на этом же сервере установлен nginx в качестве reverse proxy, который будет принимать подключения и проксировать их в Кибана. Так и нужно делать в production, когда системой будут пользоваться разные люди из разных мест. С помощью nginx можно будет разграничивать доступ, использовать сертификат, настраивать нормальное доменное имя и т.д. Если же у вас это тестовая установка, то можно обойтись без nginx. Для этого надо разрешить Кибана слушать внешний интерфейс и принимать подключения. Измените параметр server.host, указав ip адрес сервера, например вот так:
server.host: "10.20.1.56"
Если хотите, чтобы она слушала все интерфейсы, укажите в качестве адреса 0.0.0.0.
Далее нам нужно настроить аутентификацию в elasticsearch. Для этого создадим пароль для встроенного пользователя kibana_system:
# /usr/share/elasticsearch/bin/elasticsearch-reset-password -u kibana_system
Сохраняем пароль и добавляем учётку в конфигурацию kibana:
elasticsearch.username: "kibana_system" elasticsearch.password: "mtbg5rIwh*E*eWuBCECG"
Теперь нам нужно указать сертификат от центра сертификации, который использовал elasticsearch для генерации tls сертификатов. Напомню, что обращения он принимает только по HTTPS. Так как мы не устанавливали подтверждённый сертификат, будем использовать самоподписанный, который был сгенерирован автоматически во время установки elasticsearch. Все созданные сертификаты находятся в директории /etc/elasticsearch/certs. Скопируем их в /etc/kibana и настроим доступ со стороны веб панели:
# cp -R /etc/elasticsearch/certs /etc/kibana # chown -R root:kibana /etc/kibana/certs
Добавим этот CA в конфигурацию Кибаны:
elasticsearch.ssl.certificateAuthorities: [ "/etc/kibana/certs/http_ca.crt" ]
И последний момент — указываем подключение к elasticsearch по HTTPS:
elasticsearch.hosts: ["https://localhost:9200"]
Теперь Kibana можно перезапустить:
# systemctl restart kibana.service
Идём в веб интерфейс по адресу http://10.20.1.56:5601.
Заходим под учётной записью elastic. Можно продолжать настройку и тестирование, а когда все будет закончено, запустить nginx и настроить проксирование. Я настройку nginx оставлю на самый конец. В процессе настройки буду подключаться напрямую к Kibana. При первом запуске Kibana предлагает настроить источники для сбора логов. Это можно сделать, нажав на Add integrations. К сбору данных мы перейдем чуть позже, так что можете просто изучить интерфейс и возможности этой веб панели
Периодически вы можете видеть в веб интерфейсе предупреждение:
server.publicBaseUrl is missing and should be configured when running in a production environment. Some features may not behave correctly.
Чтобы его не было, просто добавьте в конфиг Kibana параметр:
server.publicBaseUrl: "http://10.20.1.23:5601/"
Или доменное имя, если используете его.
Установка и настройка Logstash
Logstash устанавливается так же просто, как Elasticsearch и Kibana, из того же репозитория. Не буду еще раз показывать, как его добавить. Просто установим его и добавим в автозагрузку. Установка Logstash в Centos:
# yum install logstash
 Установка Logstash в Debian/Ubuntu:
Установка Logstash в Debian/Ubuntu:
# apt install logstash
Добавляем logstash в автозагрузку:
# systemctl enable logstash.service
Запускать пока не будем, надо его сначала настроить. Основной конфиг logstash лежит по адресу /etc/logstash/logstash.yml. Я его не трогаю, а все настройки буду по смыслу разделять по разным конфигурационным файлам в директории /etc/logstash/conf.d. Создаем первый конфиг input.conf, который будет описывать приём информации с beats агентов.
input {
beats {
port => 5044
}
}
Тут все просто. Указываю, что принимаем информацию на 5044 порт. Этого достаточно. Если вы хотите использовать ssl сертификаты для передачи логов по защищенным соединениям, здесь добавляются параметры ssl. Я буду собирать данные из закрытого периметра локальной сети, у меня нет необходимости использовать ssl. Теперь укажем, куда будем передавать данные. Тут тоже все относительно просто. Рисуем конфиг output.conf, который описывает передачу данных в Elasticsearch.
output {
elasticsearch {
hosts => "https://localhost:9200"
index => "websrv-%{+YYYY.MM}"
user => "elastic"
password => "ktNBdiTxO3hKqASVvHyu"
cacert => "/etc/logstash/certs/http_ca.crt"
}
}
Что мы настроили? Передавать все данные в elasticsearch под указанным индексом с маской в виде даты. Разбивка индексов по дням и по типам данных удобна с точки зрения управления данными. Потом легко будет выполнять очистку данных по этим индексам. Для аутентификации я указал учётку elastic, но вы можете сделать и отдельную через Kibana (раздел Stack Management -> Users). При этом можно создавать под каждый индекс свою учётную запись с разрешением доступа только к этому индексу.
Как и в случае с Kibana, для Logstash нужно указать CA, иначе он будет ругаться на недоверенный сертификат elasticsearch и откажется к нему подключаться. Копируем сертификаты и назначаем права:
# cp -R /etc/elasticsearch/certs /etc/logstash # chown -R root:logstash /etc/logstash/certs
Остается последний конфиг с описанием обработки данных. Тут начинается небольшая уличная магия, в которой я разбирался некоторое время. Расскажу ниже. Рисуем конфиг filter.conf.
filter {
if [type] == "nginx_access" {
grok {
match => { "message" => "%{IPORHOST:remote_ip} - %{DATA:user} [%{HTTPDATE:access_time}] "%{WORD:http_method} %{DATA:url} HTTP/%{NUMBER:http_version}" %{NUMBER:response_code} %{NUMBER:body_sent_bytes} "%{DATA:referrer}" "%{DATA:agent}"" }
}
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
geoip {
source => "remote_ip"
target => "geoip"
add_tag => [ "nginx-geoip" ]
}
}Первое, что делает этот фильтр, парсит логи nginx с помощью grok, если указан соответствующий тип логов, и выделяет из лога ключевые данные, которые записывает в определенные поля, чтобы потом с ними было удобно работать. С обработкой логов у новичков возникает недопонимание. В документации к filebeat хорошо описаны модули, идущие в комплекте, которые все это и так уже умеют делать из коробки, нужно только подключить соответствующий модуль.
Модули filebeat работают только в том случае, если вы отправляете данные напрямую в Elasticsearch. На него вы тоже ставите соответствующий плагин и получаете отформатированные данные с помощью elastic ingest. Но у нас работает промежуточное звено Logstash, который принимает данные. С ним плагины filebeat не работают, поэтому приходится отдельно в logstash парсить данные. Это не очень сложно, но тем не менее. Как я понимаю, это плата за удобства, которые дает logstash. Если у вас много разрозненных данных, то отправлять их напрямую в Elasticsearch не так удобно, как с использованием предобработки в Logstash.
Для фильтра grok, который использует Logstash, есть удобный дебаггер, где можно посмотреть, как будут парситься ваши данные. Покажу на примере одной строки из конфига nginx. Например, возьмем такую строку из лога:
180.163.220.100 - travvels.ru [05/Sep/2021:14:45:52 +0300] "GET /assets/galleries/26/1.png HTTP/1.1" 304 0 "https://travvels.ru/ru/glavnaya/" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36"
И посмотрим, как ее распарсит правило grok, которое я использовал в конфиге выше.
%{IPORHOST:remote_ip} - %{DATA:user} [%{HTTPDATE:access_time}] "%{WORD:http_method} %{DATA:url} HTTP/%{NUMBER:http_version}" %{NUMBER:response_code} %{NUMBER:body_sent_bytes} "%{DATA:referrer}" "%{DATA:agent}"Собственно, результат вы можете сами увидеть в дебаггере. Фильтр распарсит лог и на выходе сформирует json, где каждому значению будет присвоено свое поле, по которому потом удобно будет в Kibana строить отчеты и делать выборки. Только не забывайте про формат логов. Приведенное мной правило соответствует дефолтному формату main логов в nginx. Если вы каким-то образом модифицировали формат логов, внесите изменения в grok фильтр. Надеюсь понятно объяснил работу этого фильтра. Вы можете таким образом парсить любые логи и передавать их в еластикс. Потом на основе этих данных строить отчеты, графики, дашборды.
Дальше используется модуль date для того, чтобы выделять дату из поступающих логов и использовать ее в качестве даты документа в elasticsearch. Делается это для того, чтобы не возникало путаницы, если будут задержки с доставкой логов. В системе сообщения будут с одной датой, а внутри лога будет другая дата. Неудобно разбирать инциденты.
В конце я использую geoip фильтр, который на основе ip адреса, который мы получили ранее с помощью фильтра grok и записали в поле remote_ip, определяет географическое расположение. Он добавляет новые метки и записывает туда географические данные. Для его работы используется база данных из файла /var/lib/logstash/plugins/filters/geoip/1669759580/GeoLite2-City.mmdb. Она будет установлена вместе с logstash. Впоследствии вы скорее всего захотите ее обновлять. Раньше она была доступна по прямой ссылке, но с 30-го декабря 2019 года правила изменились. База по-прежнему доступна бесплатно, но для загрузки нужна регистрация на сайте сервиса. Регистрируемся и качаем отсюда — https://dev.maxmind.com/geoip/geoip2/geolite2/#Download_Access. Передаем на сервер, распаковываем и копируем в /etc/logstash файл GeoLite2-City.mmdb. Теперь нам нужно в настройках модуля geoip указать путь к файлу с базой. Добавляем в /etc/logstash/conf.d/filter.conf:
geoip {
database => "/etc/logstash/GeoLite2-City.mmdb"
source => "remote_ip"
target => "geoip"
add_tag => [ "nginx-geoip" ]
}Закончили настройку logstash. Запускаем его:
# systemctl start logstash.service
Можете проверить на всякий случай лог /var/log/logstash/logstash-plain.log, чтобы убедиться в том, что все в порядке. Признаком того, что скачанная geoip база успешно добавлена будет вот эта строчка в логе:
[2021-10-18T12:52:07,118][INFO ][logstash.filters.geoip ][main] Using geoip database {:path=>"/etc/logstash/GeoLite2-City.mmdb"}
Теперь настроим агенты для отправки данных.
Установка Filebeat для отправки логов в Logstash
Установим первого агента Filebeat на сервер с nginx для отправки логов веб сервера на сервер с ELK. Ставить можно как из общего репозитория, который мы подключали ранее, так и по отдельности пакеты. Как ставить — решать вам. В первом случае придется на все хосты добавлять репозиторий, но зато потом удобно обновлять пакеты. Если подключать репозиторий не хочется, можно просто скачать пакет и установить его. Ставим на Centos.
# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.5.2-x86_64.rpm # rpm -ivh filebeat-8.5.2-x86_64.rpm
В Debian, Ubuntu ставим так:
# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.5.2-amd64.deb # dpkg -i filebeat-8.5.2-amd64.deb
Или просто:
# yum install filebeat # apt install filebeat
После установки рисуем примерно такой конфиг /etc/filebeat/filebeat.yml для отправки логов в logstash.
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/*-access.log
fields:
type: nginx_access
fields_under_root: true
scan_frequency: 5s
- type: log
enabled: true
paths:
- /var/log/nginx/*-error.log
fields:
type: nginx_error
fields_under_root: true
scan_frequency: 5s
output.logstash:
hosts: ["10.1.4.114:5044"]
xpack.monitoring:
enabled: true
elasticsearch:
hosts: ["http://10.1.4.114:9200"]Некоторые пояснения к конфигу, так как он не совсем дефолтный и минималистичный. Я его немного модифицировал для удобства. Во-первых, я разделил логи access и error с помощью отдельного поля type, куда записываю соответствующий тип лога: nginx_access или nginx_error. В зависимости от типа меняются правила обработки в logstash.
Запускаем filebeat и добавляем в автозагрузку.
# systemctl enable --now filebeat
Проверяйте логи filebeat в дефолтном системном логе. По умолчанию, он все пишет туда. Лог весьма информативен. Если все в порядке, увидите список всех логов в директории /var/log/nginx, которые нашел filebeat по маске и начал готовить к отправке.
Если все сделали правильно, то данные уже потекли в elasticsearch. Мы их можем посмотреть в Kibana. Для этого открываем web интерфейс и переходим в раздел Discover. Так как там еще нет представления для нового индекса, нам предложат его добавить. Нажимайте Create data view.
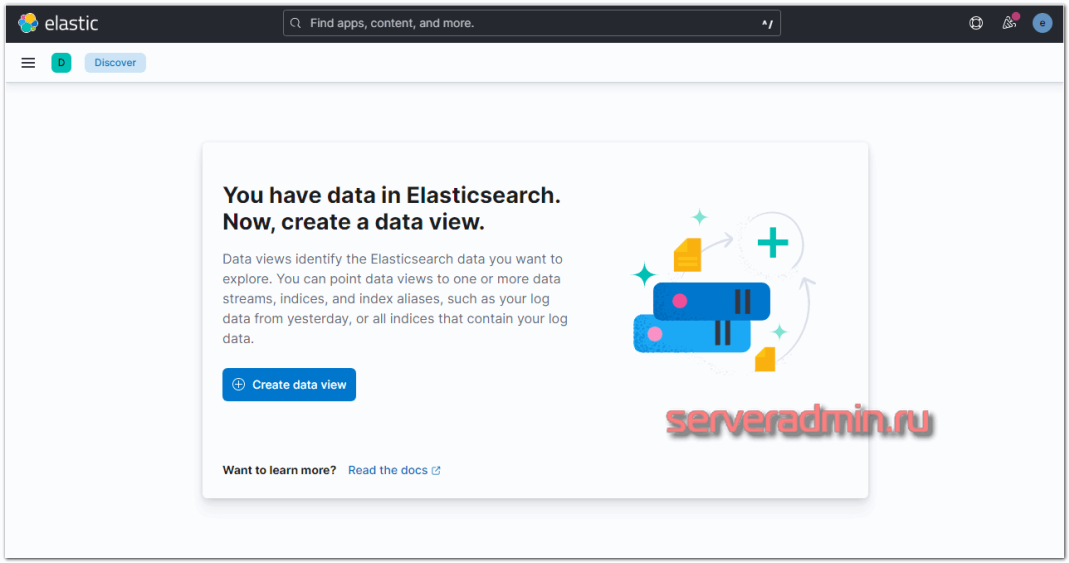
Вы должны увидеть индекс, который начал заливать logstash в elasticsearch. В поле Index pattern введите websrv-* . Выберите имя поля для временного фильтра. У вас будет только один вариант — @timestamp, выбирайте его и жмите Save data view to Kibana.
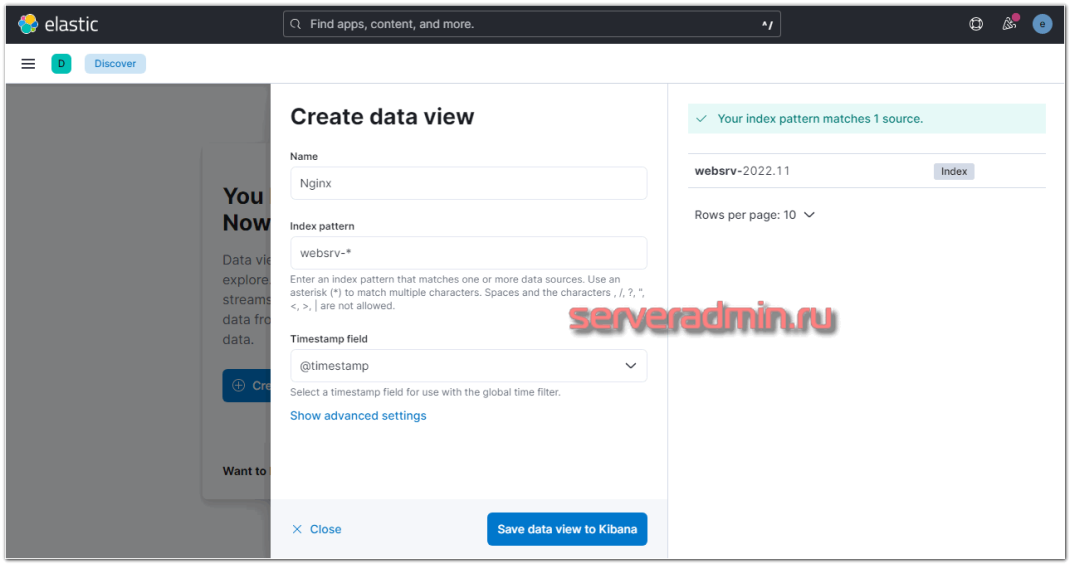
Новый индекс добавлен. Теперь при переходе в раздел Discover, он будет открываться по умолчанию со всеми данными, которые в него поступают.
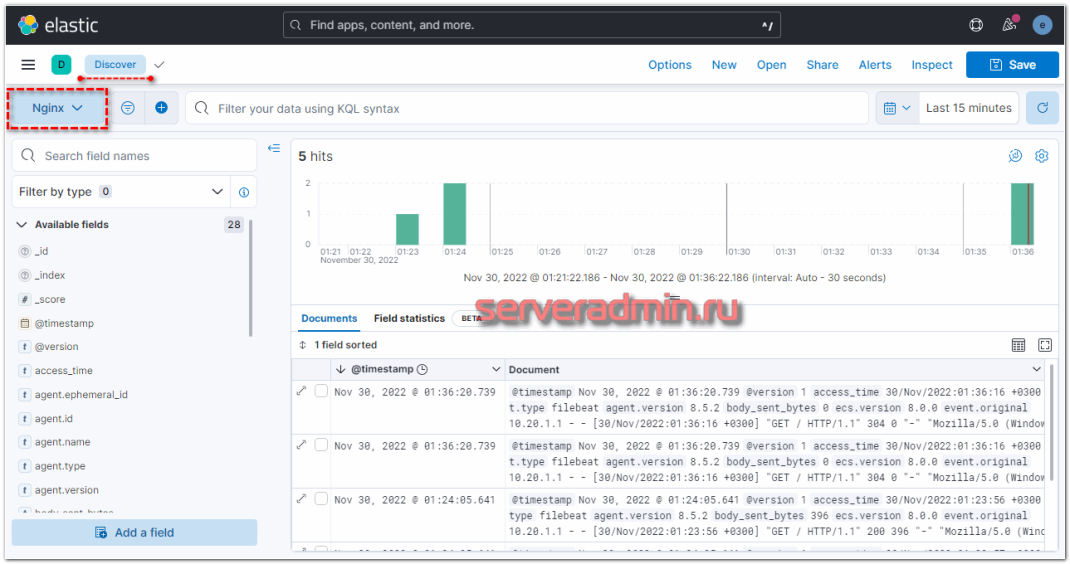
Получение логов с веб сервера nginx на Linux настроили. Подобным образом настраивается сбор и анализ любых логов. Можно либо самим писать фильтры для парсинга с помощью grok, либо брать готовые.
Теперь сделаем то же самое для журналов windows.
Установка и настройка Winlogbeat
Для настройки централизованного сервера сбора логов с Windows серверов, установим сборщика системных логов winlogbeat. Для этого скачаем его и установим в качестве службы. Идем на страницу загрузок и скачиваем msi версию под вашу архитектуру — 32 или 64 бита. Запускаем инсталлятор и в конце выбираем открытие директории по умолчанию.
 Создаем и правим конфигурационный файл winlogbeat.yml. Я его привел к такому виду:
Создаем и правим конфигурационный файл winlogbeat.yml. Я его привел к такому виду:
winlogbeat.event_logs:
- name: Application
ignore_older: 72h
- name: Security
- name: System
tags: ["winsrv"]
output.logstash:
hosts: ["10.20.1.56:5044"]
logging.level: info
logging.to_files: true
logging.files:
path: C:/ProgramData/Elastic/Beats/winlogbeat
name: winlogbeat.log
keepfiles: 7В принципе, по тексту все понятно. Я беру 3 системных лога Application, Security, System (для русской версии используются такие же названия) и отправляю их на сервер с logstash. Настраиваю хранение логов. Отдельно обращаю внимание на tags: [«winsrv»]. Этим тэгом я помечаю все отправляемые сообщения, чтобы потом их обработать в logstash и отправить в elasticsearch с отдельным индексом. Я не смог использовать поле type, по аналогии с filebeat, потому что в winlogbeat в поле type жестко прописано wineventlog и изменить его нельзя. Если у вас данные со всех серверов будут идти в один индекс, то можно tag не добавлять, а использовать указанное поле type для сортировки. Если же вы данные с разных серверов хотите помещать в разные индексы, то разделяйте их тэгами. Для того, чтобы логи виндовых журналов пошли в elasticsearch не в одну кучу вместе с nginx логами, нам надо настроить для них отдельный индекс в logstash в разделе output. Идем на сервер с logstash и правим конфиг output.conf.
output {
if [type] == "nginx_access" {
elasticsearch {
hosts => "https://localhost:9200"
index => "nginx-%{+YYYY.MM.dd}"
}
}
else if [type] == "nginx_error" {
elasticsearch {
hosts => "https://localhost:9200"
index => "nginx-%{+YYYY.MM.dd}"
}
}
else if "winsrv" in [tags] {
elasticsearch {
hosts => "https://localhost:9200"
index => "winsrv-%{+YYYY.MM.dd}"
}
}
else {
elasticsearch {
hosts => "https://localhost:9200"
index => "unknown_messages"
}
}
}Думаю, по тексту понятен смысл. Я разделил по разным индексам логи nginx, системные логи виндовых серверов и добавил отдельный индекс unknown_messages, в который будет попадать все то, что не попало в предыдущие. Это просто задел на будущее, когда конфигурация будет более сложная, можно будет ловить сообщения, которые по какой-то причине не попали ни в одно из приведенных выше правил. Я не смог в одно правило поместить оба типа nginx_error и nginx_access, потому что не понял сходу, как это правильно записать, а по документации уже устал лазить, выискивать информацию. Так получился рабочий вариант. После этого перезапустил logstash и пошел на windows сервер, запустил службу Elastic Winlogbeat.
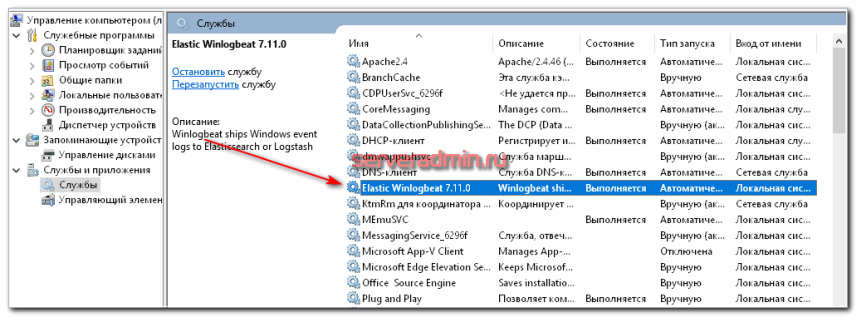
Подождал немного, пока появятся новые логи на виндовом сервере, зашел в Kibana и добавил новые data views. Напомню, что делается это в разделе Stack Management -> Data views. Добавляем новый вид по маске winsrv-*.
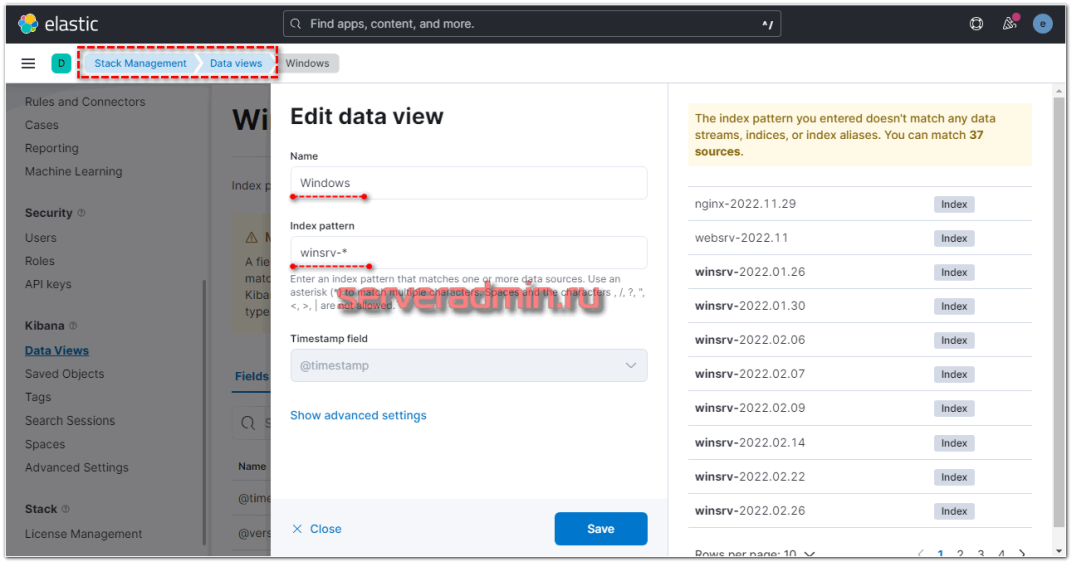
Можно идти в раздел Discover и просматривать логи с Windows серверов.
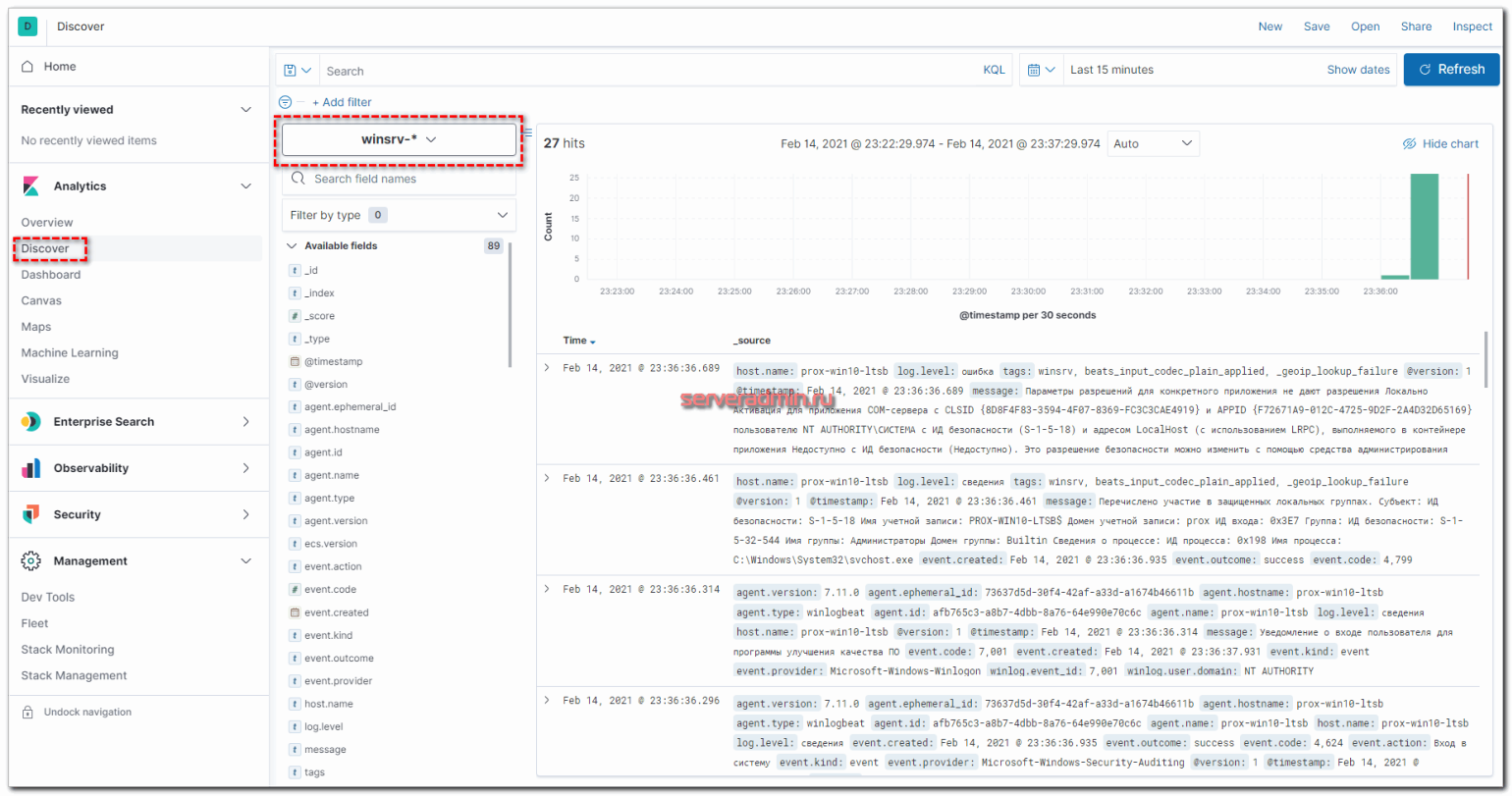
У меня без проблем все заработало в том числе на серверах с русской версией Windows. Все логи, тексты в сообщениях на русском языке нормально обрабатываются и отображаются. Проблем не возникло нигде. На этом я закончил настройку ELK стека из Elasticsearch, Logstash, Kibana, Filebeat и Winlogbeat. Описал основной функционал по сбору логов. Дальше с ними уже можно работать по ситуации — строить графики, отчеты, собирать дашборды и т.д. В отдельном разделе ELK Stack у меня много примеров на этот счет.
Настройка безопасности и авторизация в Kibana
Мы настроили по умолчанию доступ в Kibana по паролю. Управлять пользователями и ролями можно через веб интерфейс. Делается это в разделе Stack Management -> Users. Там можно как отредактировать встроенные учетные записи, так и добавить новые.
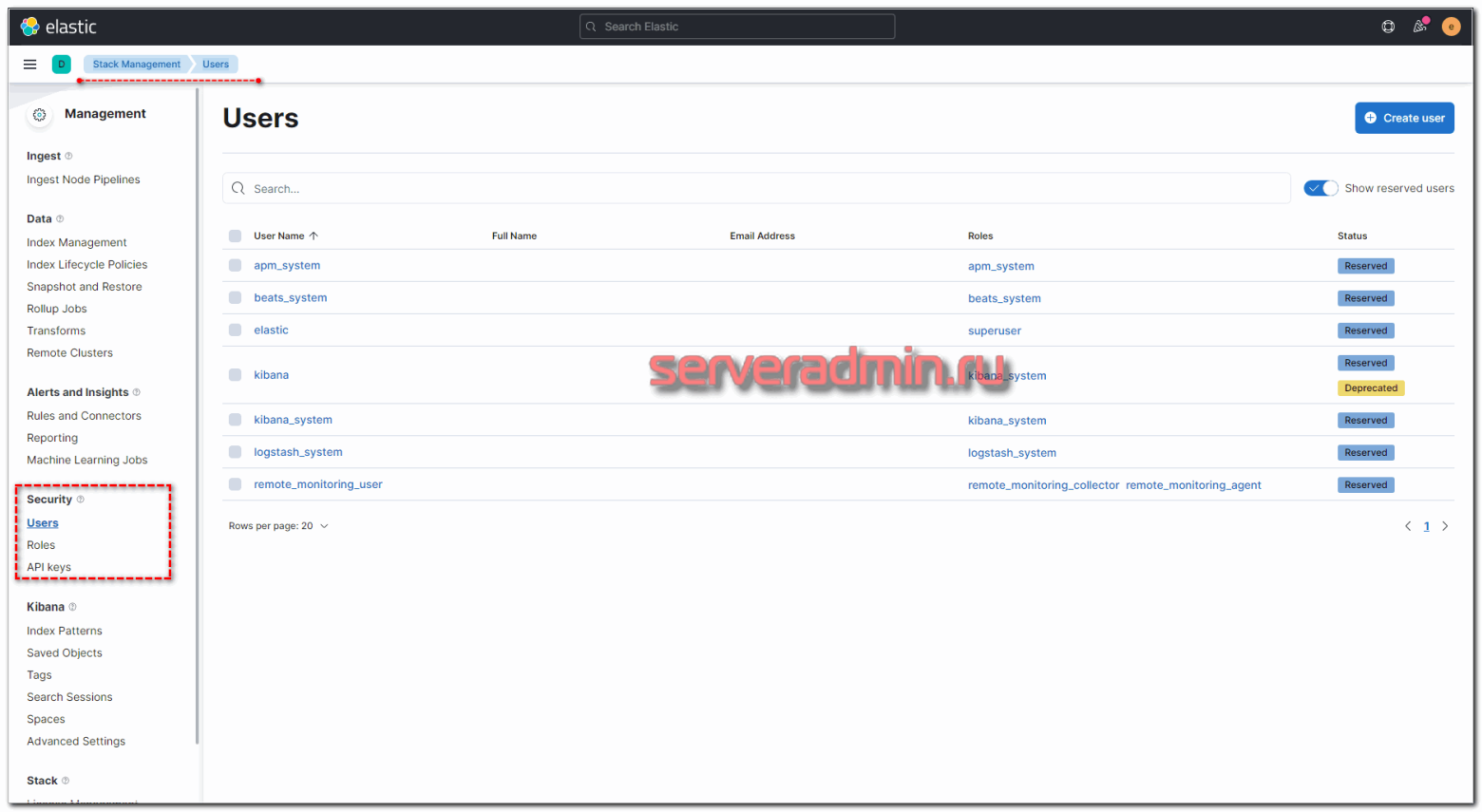
Сделаем это на примере пользователя для Logstash. Создадим отдельного юзера с правами на запись в нужные нам индексы. Для этого сначала создадим роль с соответствующими правами. Переходим в Roles и добавляем новую.
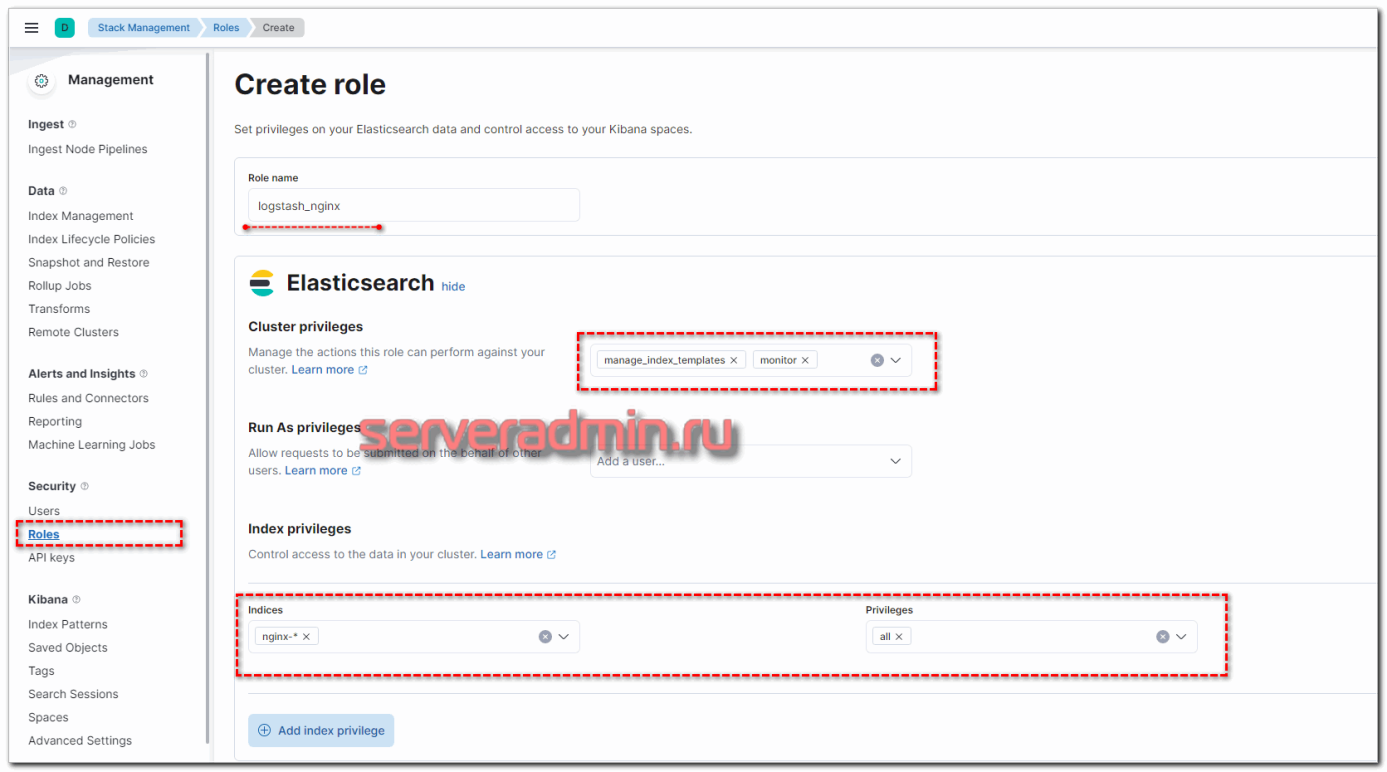
Набор индексов и права доступа к ним вы можете выбрать те, что вам нужны. Можно разделить доступ: одни могут только писать данные, другие удалять и т.д. После создания роли, добавьте пользователя и добавьте ему созданную ранее роль.
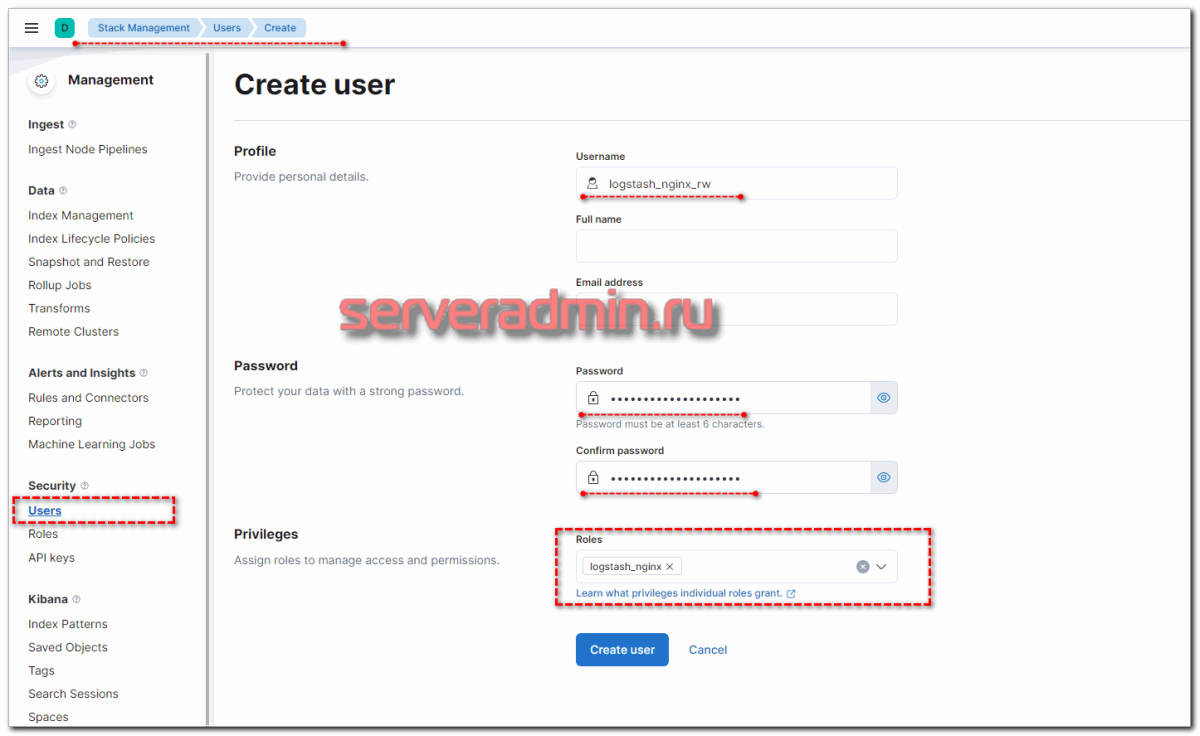
Теперь нам нужно настроить Logstash для авторизации в кластере. Если это ещё не сделано, он не может отправлять данные. В логе у него будут ошибки, которые явно не указывают, в чем проблема, но мы это знаем и так.
[ERROR][logstash.outputs.elasticsearch][main][f8cdb7a9c640d0ed412a776071b8530fd5c0011075712a1979bee6c58b4c1d9f] Encountered a retryable error (will retry with exponential backoff) {:code=>401, :url=>"http://localhost:9200/_bulk", :content_length=>2862}
Открываем конфиг logstash, отвечающий за output и добавляем туда учетные данные для доступа в кластер. Выглядеть это будет примерно так:
output {
elasticsearch {
user => "logstash_nginx_rw"
password => "gdhsgfadsfsdfgsfdget45t"
hosts => "https://localhost:9200"
index => "nginx-%{+YYYY.MM.dd}"
cacert => "/etc/logstash/certs/http_ca.crt"
}
}После этого данные как и прежде начнут поступать из logstash в elasticsearch, только теперь уже с авторизацией по пользователю и паролю.
Проксирование подключений к Kibana через Nginx
Я не буду подробно рассказывать о том, что такое проксирование в nginx. У меня есть отдельная статья на эту тему — настройка proxy_pass в nginx. Приведу просто пример конфига для передачи запросов с nginx в kibana. Я рекомендую использовать ssl сертификаты для доступа к Kibana. Даже если в этом нет объективной необходимости, надоедают уведомления браузеров о том, что у вас небезопасное подключение. Подробная инструкция по установке, настройке и использованию ssl в nginx так же есть у меня на сайте — настройка web сервера nginx. Все подробности настройки nginx смотрите там. Вот примерный конфиг nginx для проксирования запросов к Kibana с ограничением доступа по паролю:
server {
listen 443;
server_name kibana.site.ru;
ssl_certificate /etc/letsencrypt/live/kibana.site.ru/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/kibana.site.ru/privkey.pem;
location / {
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.kibana;
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Создаем файл для пользователей и паролей:
# htpasswd -c /etc/nginx/htpasswd.kibana kibanauser
Если утилиты htpasswd нет в системе, то установите ее:
# yum install httpd-tools
После этого выйдет запрос на ввод пароля. С помощью приведенной выше команды мы создали файл с информацией о пользователе и пароле kibanauser для ограничения доступа к web панели кибана. Если у вас настроена внутренняя авторизация в Kibana, то большого смысла делать примерно то же самое через nginx нет. Но это на ваше усмотрение. Auth_basic позволяет полностью скрыть информацию о том, какой сервис находится за авторизацией, что может быть очень актуально при прямом доступе к Kibana из интернета.
Автоматическая очистка индексов в elasticsearch
Некоторое время назад для автоматической очистки индексов в Elasticsearch необходимо было прибегать к помощи сторонних продуктов. Наиболее популярным был Curator. Сейчас в Kibana есть встроенный инструмент для очистки данных — Index Lifecycle Policies. Его не трудно настроить самостоятельно, хотя и не могу сказать, что там всё очевидно. Есть некоторые нюансы, так что я по шагам расскажу, как это сделать. Для примера возьму всё тот же индекс nginx-*, который использовал ранее в статье.
Настроим срок жизни индексов следующим образом:
- Первые 30 дней — Hot phase. В этом режиме индексы активны, в них пишутся новые данные.
- После 30-ти дней — Cold phase. В этой фазе в индексы невозможна запись новых данных. Запросы к этим данным имеют низкий приоритет.
- Все, что старше 90 дней удаляется.
Чтобы реализовать эту схему хранения данных, идем в раздел Stack Management -> Index Lifecycle Management и добавляем новую политику. Я её назвал Nginx_logs. Выставляем параметры фаз в соответствии с заданными требованиями.
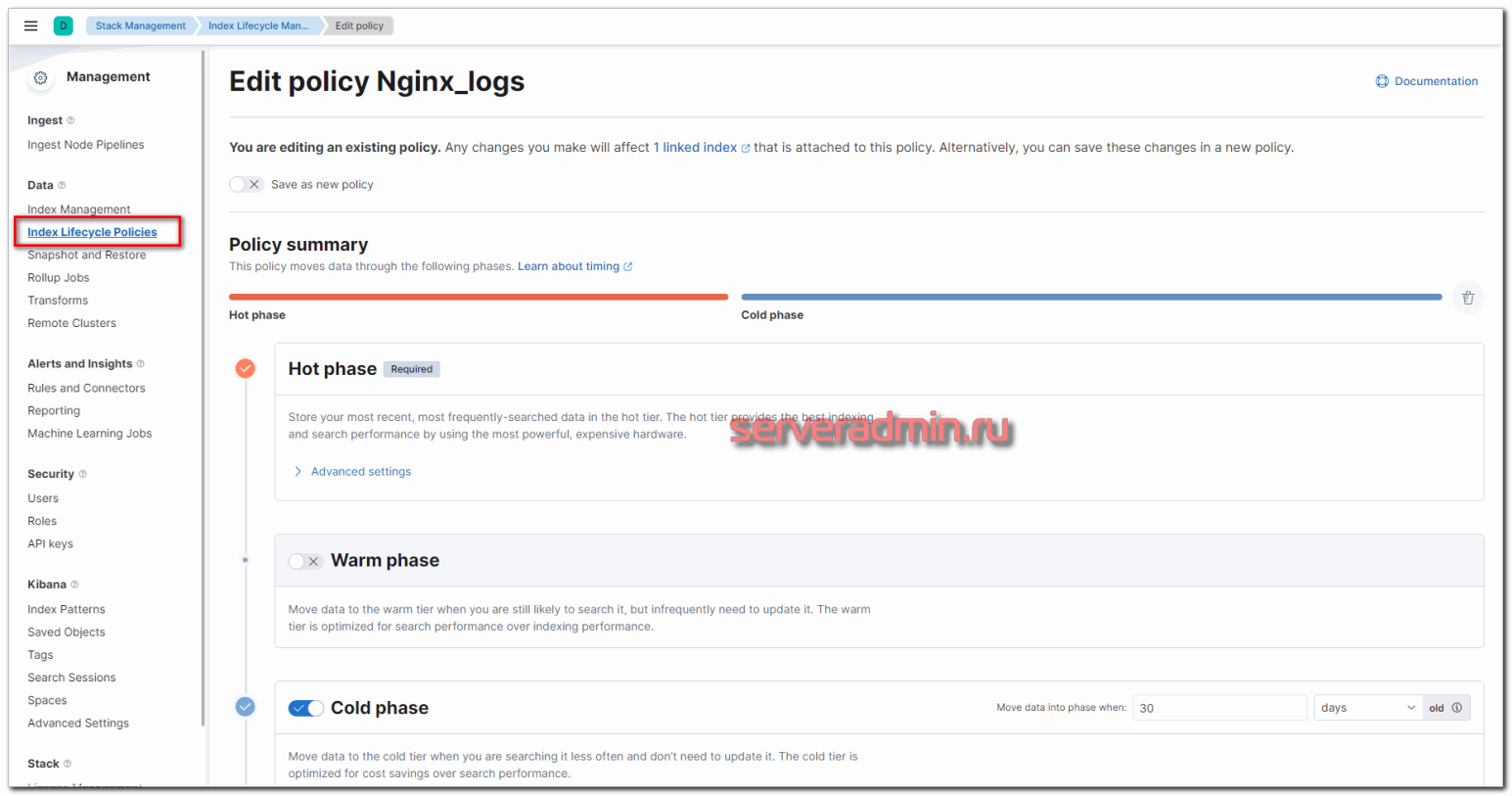
Не уместилось полное изображение настроек, но, думаю, вы там сами разберётесь, что выбрать. Ничего сложного тут нет. Далее нам нужно назначить новую политику хранения данных к индексам. Для этого переходим в Index Management -> Index Templates и добавляем новый индекс. В качестве шаблона укажите nginx-*, все остальные параметры можно оставить дефолтными.
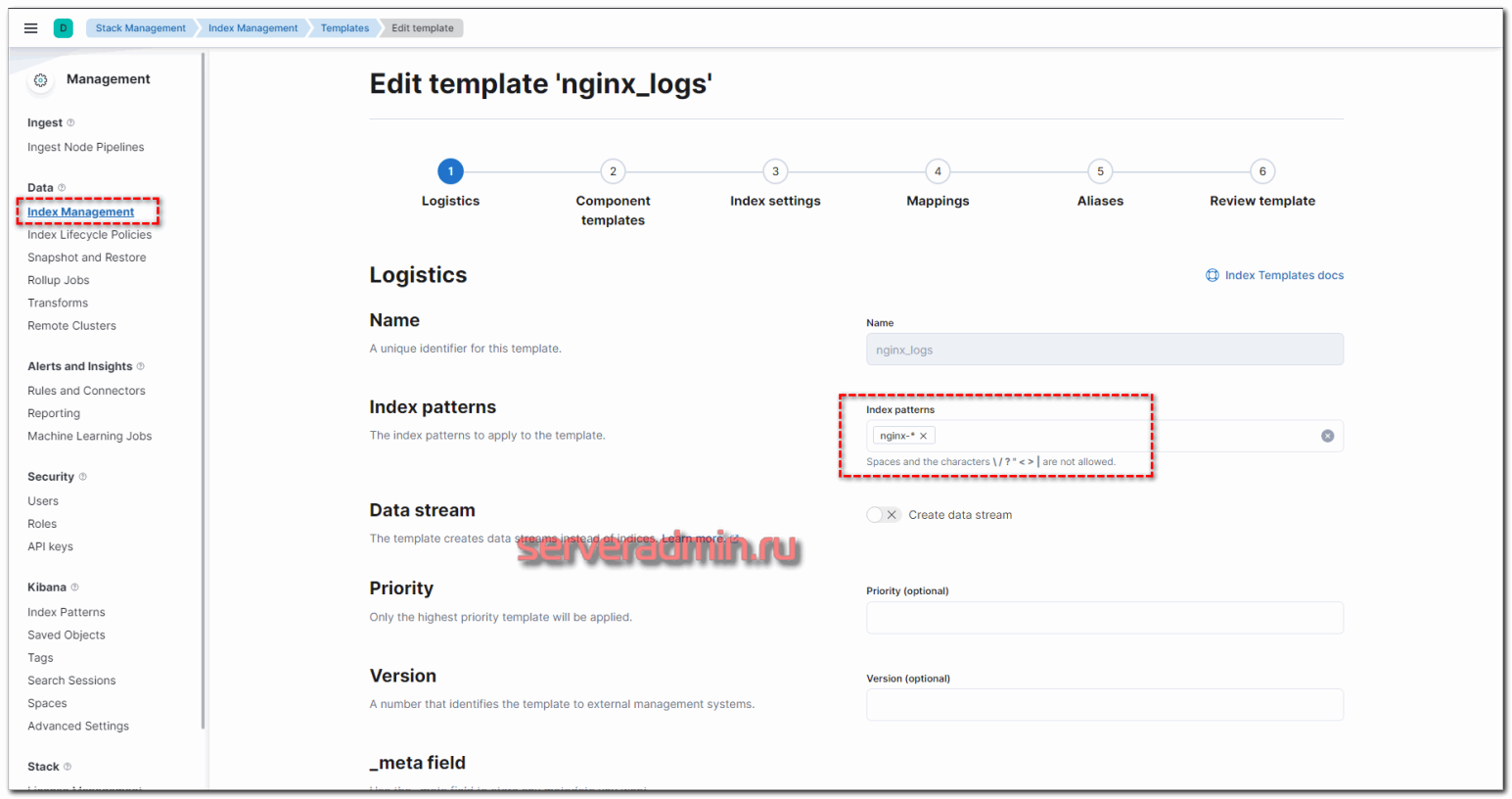
Теперь возвращаемся в Index Lifecycle Policies, напротив нашей политики нажимаем на + и выбираем только что созданный шаблон.
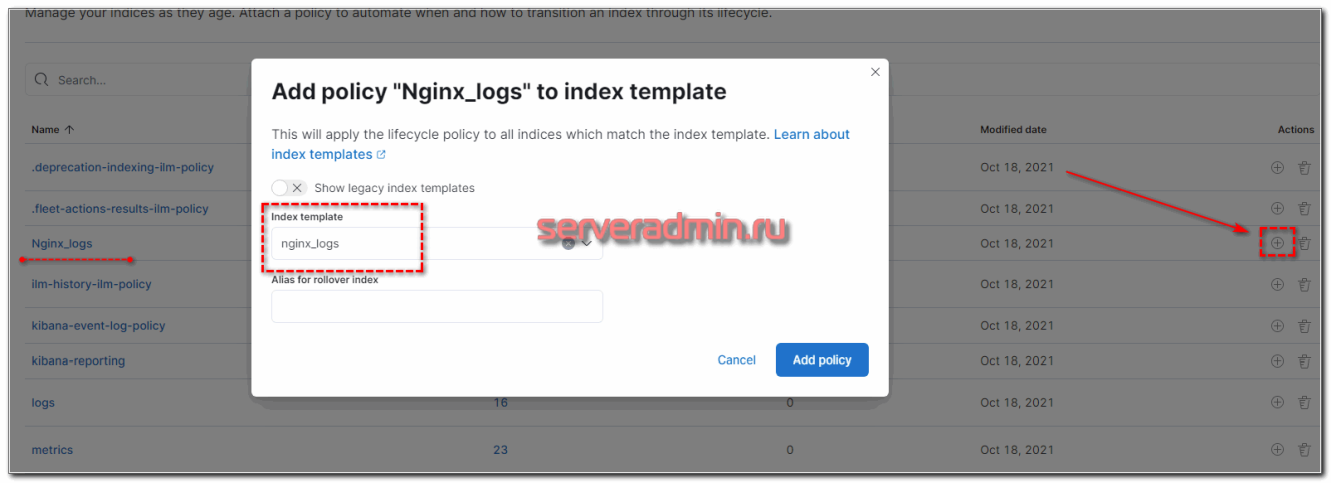
Проверяем свойства шаблона и убеждаемся в том, что Lifecycle Policies применилась.
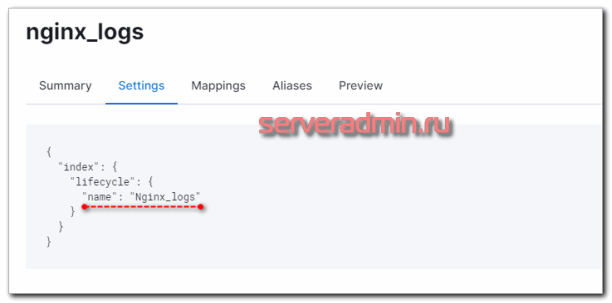
Теперь ко всем новым индексам, созданным по этому шаблону, будет применяться политика хранения данных. Для уже существующих это нужно проделать вручную. Достаточно выбрать нужный индекс и в выпадающем списке с опциями выбрать нужное действие.
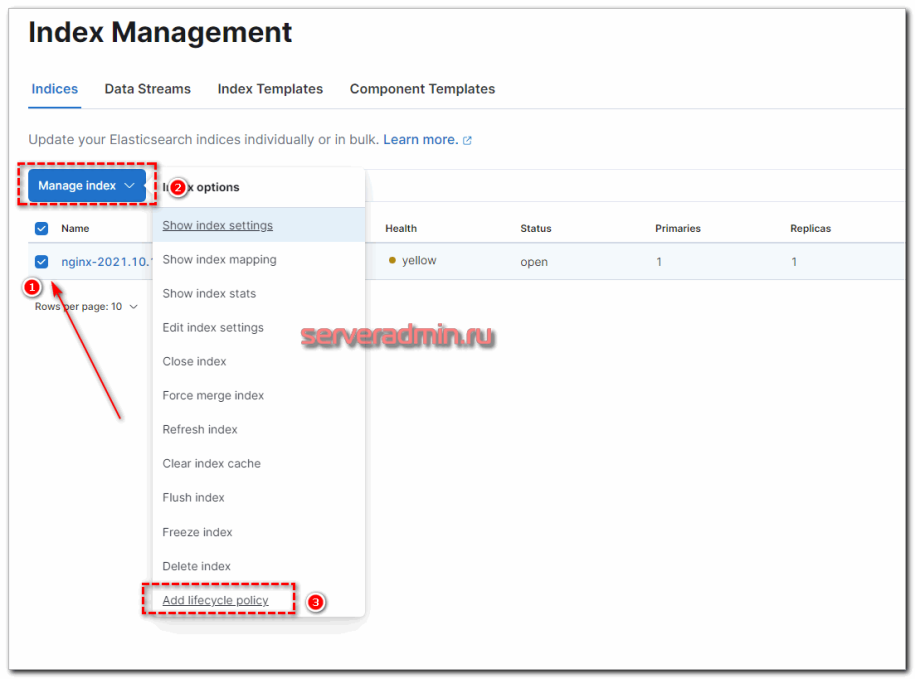
Такими несложными действиями можно настроить автоматическую очистку индексов встроенными инструментами Elasticsearch и Kibana. В некоторых случаях быстрее и удобнее воспользоваться Curator, особенно если нужно быстро реализовать много разных схем. Единый конфиг куратора выглядит более наглядным, но это уже вкусовщина и от ситуации зависит.
Часто задаваемые вопросы по теме статьи (FAQ)
Можно ли вместо filebeat использовать другие программы для сбора логов?
Да, можно. Наиболее популярными заменами filebeat является Fluentd и Vector. Они более функциональны и производительны. В некоторых случаях могут брать на себя часть функционала по начально обработке данных. В итоге, можно отказаться от logstash.
Можно ли в данной связке обойтись без logstash?
Да, если вы просто собираете логи, без предварительной обработки и изменения, можно отправлять данные напрямую в elasticsearch. На нем их так же можно обработать с помощью grok фильтра в elastic node. Вариант рабочий, но не такой функциональный, как logstash.
Есть ли в elasticsearch какой-то штатный механизм очистки старых данных?
Да, есть такой механизм — Index Lifecycle Policies, который требует отдельной настройки в Kibana. Также можно использовать сторонний софт. Пример такого софта — curator.
Как штатно настроить tls сертификат в Kibana?
Проще всего использовать для этого nginx в режиме proxy_pass. С его помощью можно без проблем подключить бесплатные сертификаты от Let’s Encrypt.
Какие минимальные системные требования для запуска ELK Stack?
Начать настройку можно с 2CPU и 6Gb RAM. Но для более ли менее комфортной работы желательно 8G RAM.
Заключение
Я постарался рассказать подробно и понятно о полной настройке ELK Stack. Информацию в основном почерпнул в официальной документации. Мне не попалось более ли менее подробных статей ни в рунете, ни в буржунете, хотя искал я основательно. Вроде бы такой популярный и эффективный инструмент, но статей больше чем просто дефолтная установка я почти не видел.
В эксплуатации подобного стэка много нюансов. Например, если отказаться от Logstash и отправлять данные с beats напрямую в Elasticsearch, то на первый взгляд все становится проще. Штатные модули beats сами парсят вывод, устанавливают готовые визуализации и дашборды в Kibana. Вам остается только зайти и любоваться красотой 🙂 Но на деле все выходит не так красиво, как хотелось бы. Кастомизация конфигурации усложняется. Изменение полей в логах приводит к более сложным настройкам по вводу этих изменений в систему. Все настройки поступающей информации переносятся на каждый beats, изменяются в конфигах отдельных агентов. Это неудобно.
В то же время, при использовании Logstash, вы просто отправляете данные со всех beats на него и уже в одном месте всем управляете, распределяете индексы, меняете поля и т.д. Все настройки перемещаются в одно место. Это более удобный подход. Плюс, при большой нагрузке вы можете вынести logstash на отдельную машину.
Я не рассмотрел в своей статье такие моменты как создание визуализаций и дашбордов в Кибана, так как материал уже и так получился объемный. Мне стало трудно всё это увязывать в одном месте. Смотрите остальные мои материалы по данной теме. Там есть примеры. Также я не рассмотрел такой момент. Logstash может принимать данные напрямую от syslog. Вы можете, к примеру, в nginx настроить отправку логов в syslog, минуя файлы и beats. Это может быть более удобно, чем описанная мной схема. Особенно это актуально для сбора логов с различных сетевых устройств, на которые невозможно поставить агента, например mikrotik. Syslog поток также можно парсить на ходу с помощью grok.
Подводя итог скажу, что с этой системой хранения логов нужно очень вдумчиво и внимательно разбираться. С наскока ее не осилить. Чтобы было удобно пользоваться, нужно много всего настроить. Я описал только немного кастомизированный сбор данных, их визуализация — отдельный разговор. Сам я постоянно использую и изучаю систему, поэтому буду рад любым советам, замечаниям, интересным ссылкам и всему, что поможет освоить тему.