Создание и удаление подов — распространенная задача при работе с Kubernetes. Новые поды создаются, когда вы выполняете плавающее обновление, масштабируете развертывание и релизите новую функциональность, а также при выполнении cron и других задач. Еще поды пересоздаются при каждом удалении и внесении изменений, например, когда узел помечается как непланируемый (unschedulable).
Команда Kubernetes aaS VK Cloud Solutions перевела статью о том, как безопасно завершить работу пода.
Основные термины из статьи:
Graceful shutdown — предсказуемое окончание работы системы, когда все запущенные процессы корректно завершают работу без потери данных или негативного пользовательского опыта.
Zero downtime deploy — нулевой простой во время развертывания новой версии приложения. Пользователь не заметит его недоступности.
Понятная схема, которая показывает, что происходит в кластере при удалении пода (PDF).
Создание пода
Чтобы лучше понимать, что происходит при удалении пода, давайте сначала разберемся, как его создают. Предположим, вы создаете в кластере следующий под:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
Вы можете создать кластер, определенный в YAML-файле с помощью команды:
$ kubectl apply -f pod.yaml
После ее выполнения kubectl передает описание пода в Kubernetes API.
Сохранение состояния кластера в базе данных
API Kubernetes получает YAML-описание пода, проверяет его и сохраняет в базе данных — etcd. Также под добавляется в очередь заданий планировщика.
Что делает планировщик:
- Проверяет описание в YAML-файле.
- Собирает сведения о нагрузке на процессор и запрошенную память контейнера.
- Решает, какой узел лучше всего подходит для запуска пода (через процесс, называемый фильтрами и предикатами).
В итоге:
- Под помечается как запланированный (scheduled) в etcd.
- Для пода определяется узел.
- Состояние пода сохраняется в etcd.
Но сам под пока не создан!
При использовании команды kubectl apply -f YAML-файл отправляется в Kubernetes API
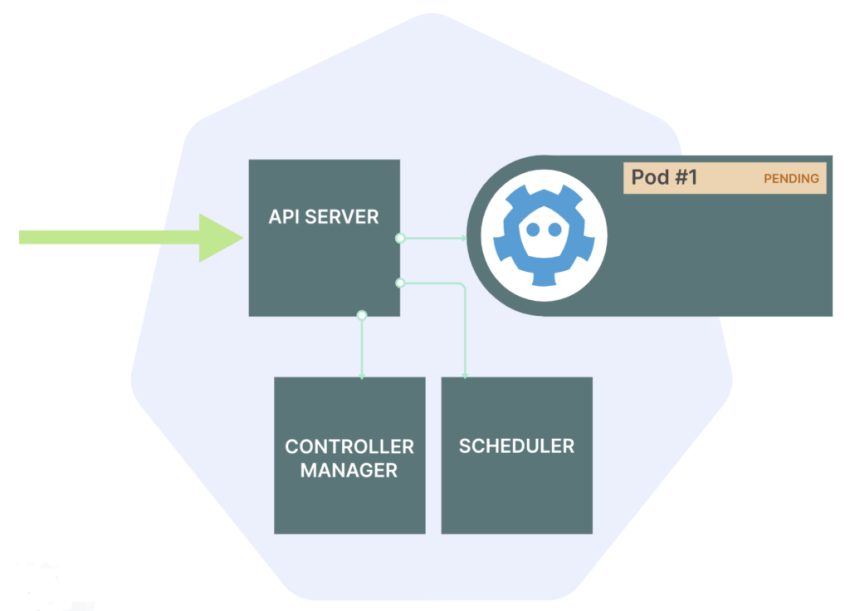
API сохраняет под в базе данных — etcd
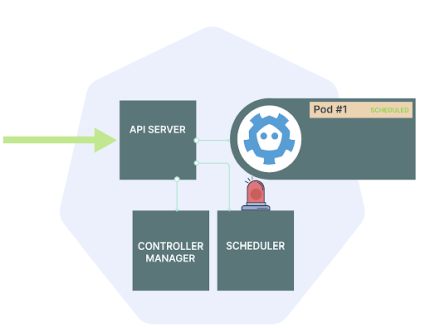
Планировщик выбирает оптимальный узел для создания пода, статус пода изменяется на «Ожидание». Но под пока существует только в etcd
Создание пода в кластере Kubernetes
Предыдущие задачи выполнялись в Control Plane, а состояние сохранилось в базе данных. Кто же создает под? Kubelet — агент Kubernetes. Его задача — опрашивать об обновлениях Control Plane. При этом kubelet не создает контейнеры самостоятельно, а делегирует эту работу трем другим компонентам:
- The Container Runtime Interface (CRI) создает контейнер для подов.
- The Container Network Interface (CNI) соединяет контейнеры с сетью кластера и назначает IP-адреса.
- The Container Storage Interface (CSI) монтирует тома в ваших контейнерах.
В большинстве случаев The Container Runtime Interface (CRI) выполняет работу, аналогичную команде по запуску контейнера в фоновом режиме:
$ docker run -d <my-container-image>
The Container Network Interface (CNI) устроен немного иначе, он отвечает за:
- создание валидного IP-адреса для пода;
- подключение контейнера к остальной сети.
Существует несколько способов подключить контейнер к сети и назначить ему валидный IP-адрес. Можно выбрать между IPv4 или IPv6, или назначить несколько IP-адресов.
Например, Docker создает пары виртуальных сетей Ethernet и подключает их к сети по типу мостов (bridge). AWS-CNI подключает под напрямую к остальной части виртуального частного облака (Virtual Private Cloud/VPC).
Когда CNI завершает работу, под подключается к остальной сети и получает валидный IP-адрес. Но есть проблема: kubelet знает об IP-адресе, поскольку это он вызвал Container Network Interface, а вот Control Plane не знает. Никто не сообщил главному узлу, что у пода появился IP-адрес и он готов к приему трафика — для Control Plane под все еще создается.
Так что задача kubelet — собрать информацию о поде, например IP-адрес, и передать их на уровень Control Plane. После этого через проверку etcd можно не только посмотреть, где работает под, но и узнать его валидный IP-адрес.
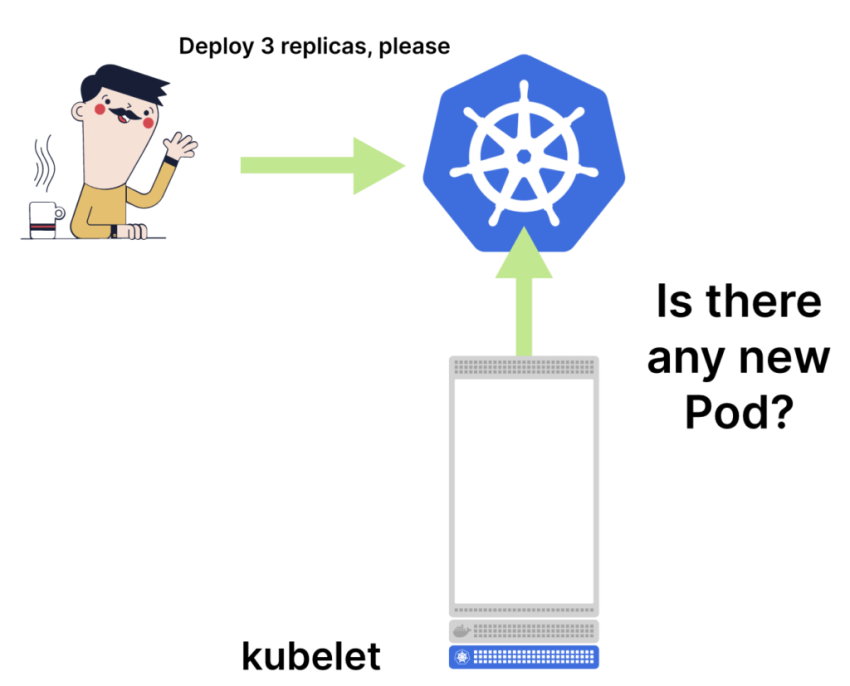
Kubelet выясняет у Control Plane, появились ли обновления
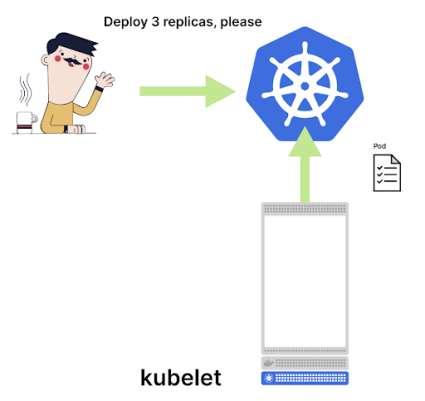
После того как для нового пода назначен узел, kubelet считывает информацию по поду
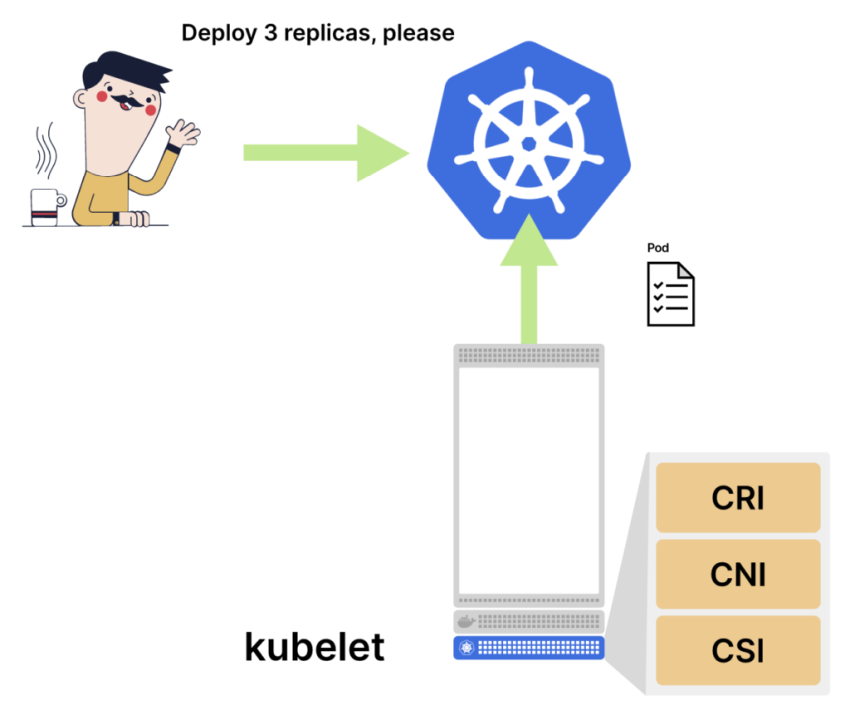
Kubelet не создает контейнер самостоятельно, а делегирует эту работу трем другим компонентам: Container Runtime Interface, Container Network Interface и Container Storage Interface
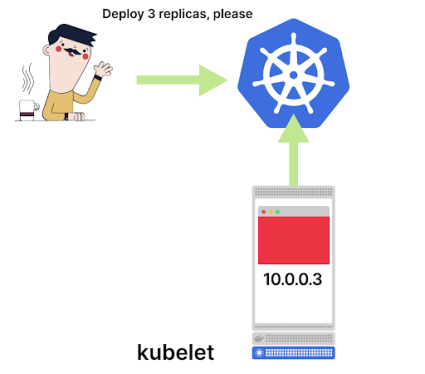
Как только все три компонента успешно выполнены, под запускается на узле и ему присваивается IP-адрес
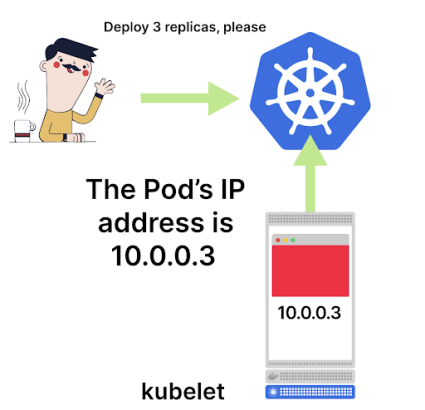
Kubelet сообщает IP-адрес пода в Control Plane
Если под не является частью какого-либо сервиса, то под создан и готов к использованию. Если же он часть cервиса, то нужно выполнить еще несколько шагов, о них рассказываем дальше.
Поды и сервисы
Обычно при создании cервиса нужно обратить внимание на несколько полей:
- selector — указывает, на какие поды будет направлен трафик.
- targetPort — порт, который поды используют для приема трафика.
Пример стандартного YAML-файла для описания сервиса:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- port: 80
targetPort: 3000
selector:
name: app
После выполнения команды <kubectl apply.> Kubernetes находит все поды с такой же меткой, что и переданное значение в selector (name: app), и собирает их IP-адреса. При этом поды обязательно должны пройти проверку readiness-пробы.
Каждый IP-адресc конкатенируется с переданным портом для формирования endpoint. Например, если IP-адрес — 10.0.0.3, а targetPort — 3000, то Kubernetes конкатенирует два значения и формирует единый enpdoint.
IP address + port = endpoint
---------------------------------
10.0.0.3 + 3000 = 10.0.0.3:3000
Перечень endpoint хранится в etcd в специальном объекте — Endpoint.
Примечание. В Kubernetes есть два похожих по названию компонента: первый называется endpoint — это пара IP-адрес и порт (10.0.0.3:3000), а второй — Endpoint, то есть перечень endpoint.
Объект Endpoint — реальный объект в Kubernetes, оркестратор создает его автоматически для каждого сервиса Kubernetes. Посмотреть Endpoint можно с помощью команды:
$ kubectl get services,endpoints
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
service/my-service-1 ClusterIP 10.105.17.65 <none> 80/TCP
service/my-service-2 ClusterIP 10.96.0.1 <none> 443/TCP
NAME ENDPOINTS
endpoints/my-service-1 172.17.0.6:80,172.17.0.7:80
endpoints/my-service-2 192.168.99.100:8443
$
Объект Endpoint хранит все IP-адреса и порты пода и обновляется каждый раз, когда:
- вы создаете под;
- вы удаляете под;
- метка пода изменяется.
Итак, Kubernetes обновляет все Endpoint после создания пода и после отправки IP-адреса главному узлу. Проверить это можно командой:
$ kubectl get services,endpoints
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
service/my-service-1 ClusterIP 10.105.17.65 <none> 80/TCP
service/my-service-2 ClusterIP 10.96.0.1 <none> 443/TCP
NAME ENDPOINTS
endpoints/my-service-1 172.17.0.6:80,172.17.0.7:80,172.17.0.8:80
endpoints/my-service-2 192.168.99.100:8443
$
Отлично, endpoint передан в Control Plane, а объект Endpoint обновлен.
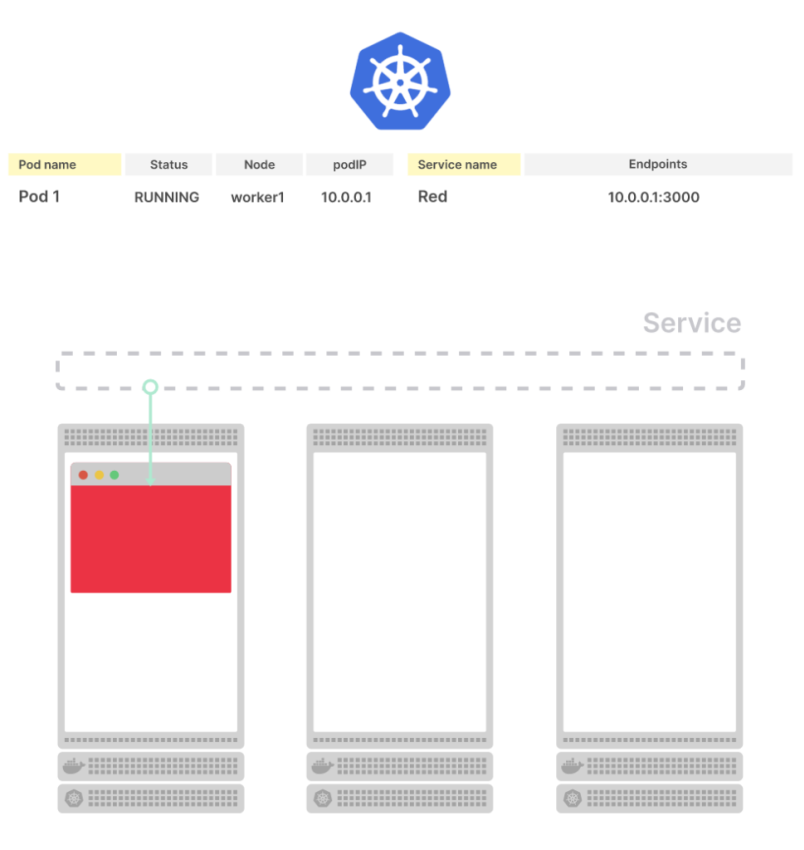
В вашем кластере развернут один под, он относится к сервису. В etcd можно найти подробную информацию как о поде, так и о сервисе
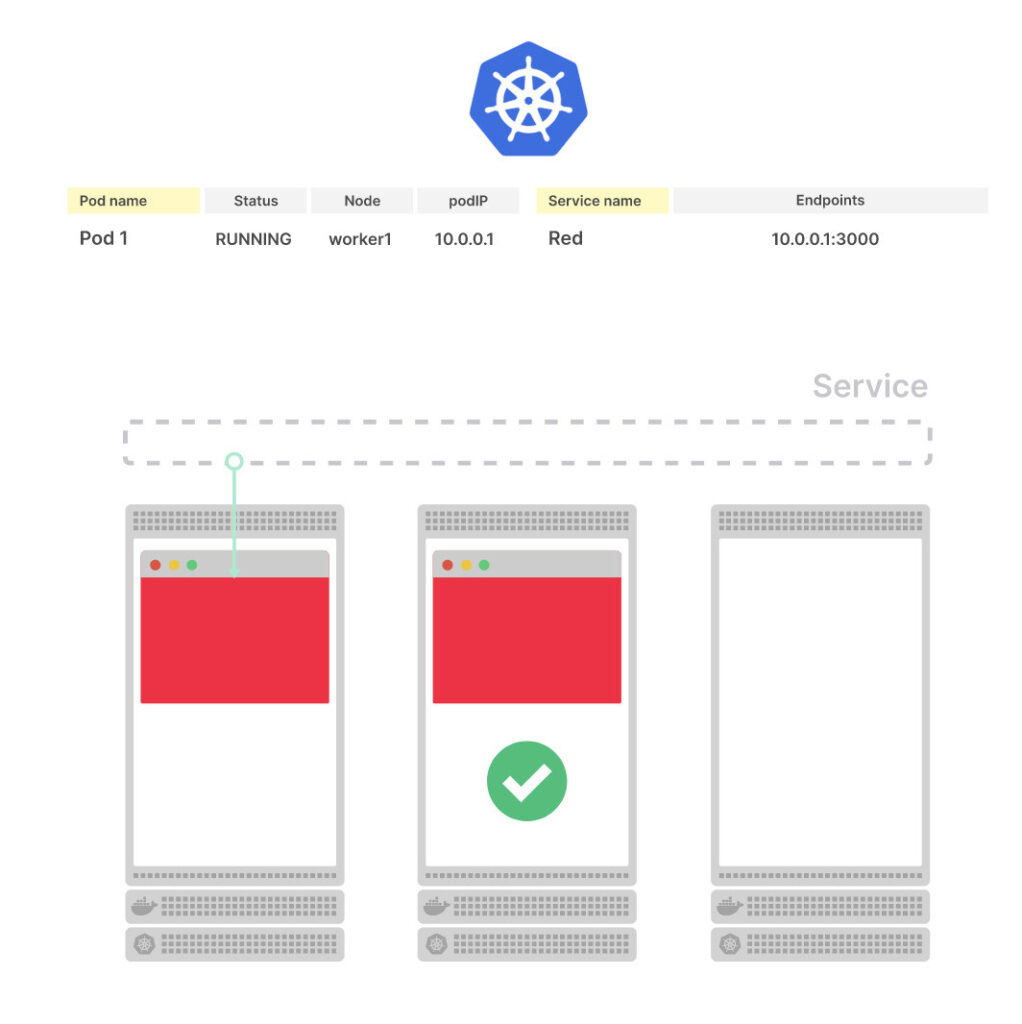
Что происходит при развертывании нового пода?
Kubernetes отслеживает под и его IP-адрес, сервис направляет трафик к новому endpoint. Так что IP-адрес и порт обновятся по всей системе
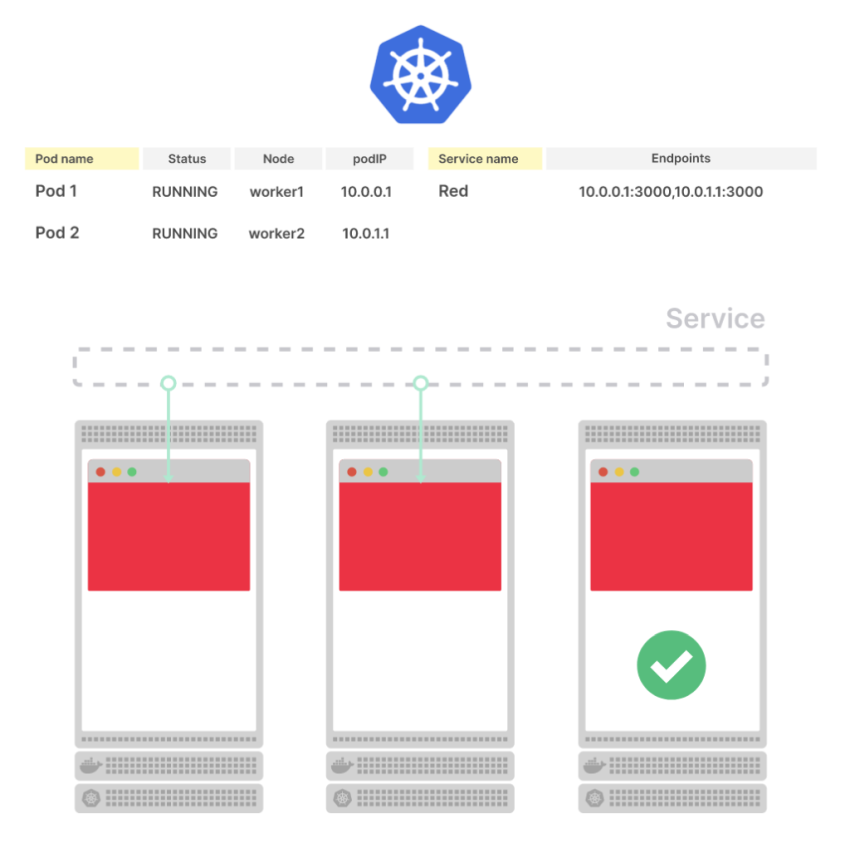
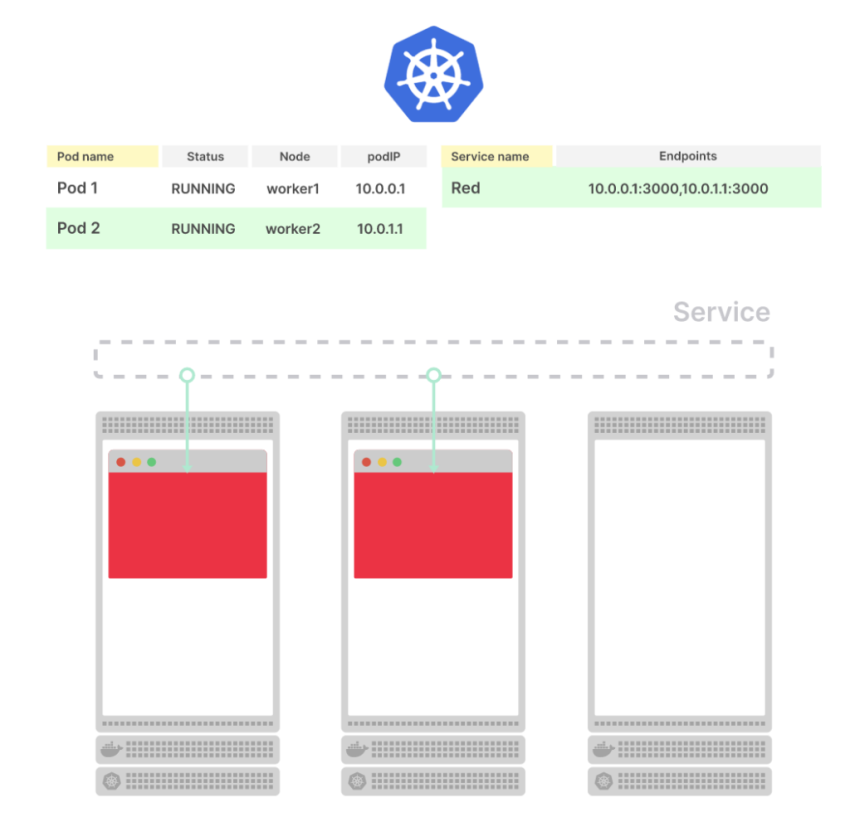
Что происходит при развертывании еще одного пода?
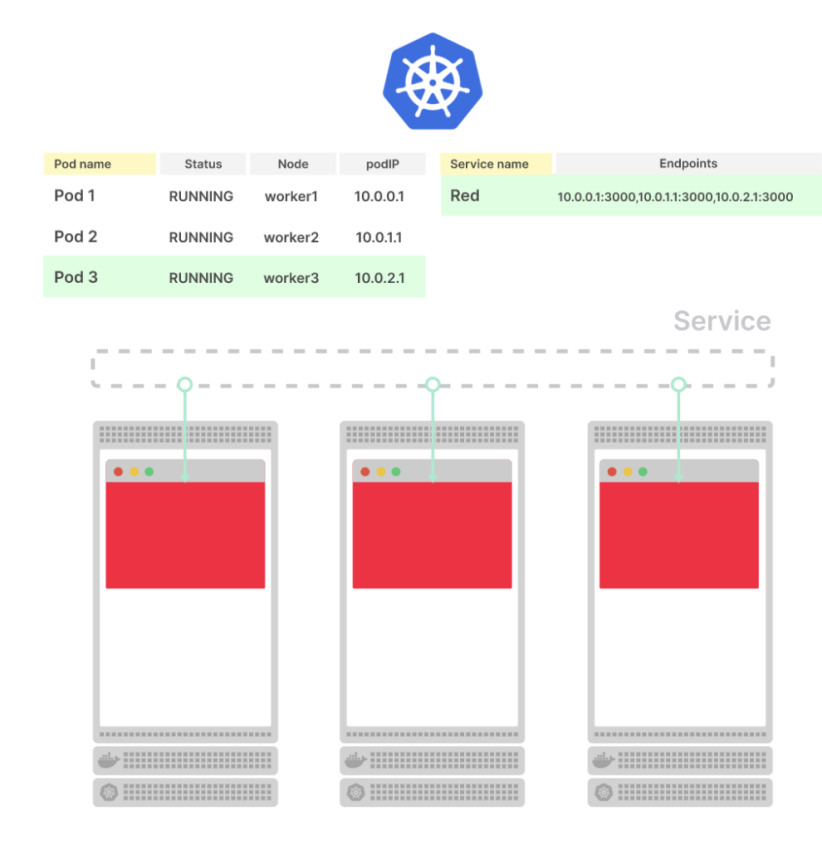
Процесс такой же: в базе данных появляется новая строка для пода, а новый endpoint распространяется по всей системе
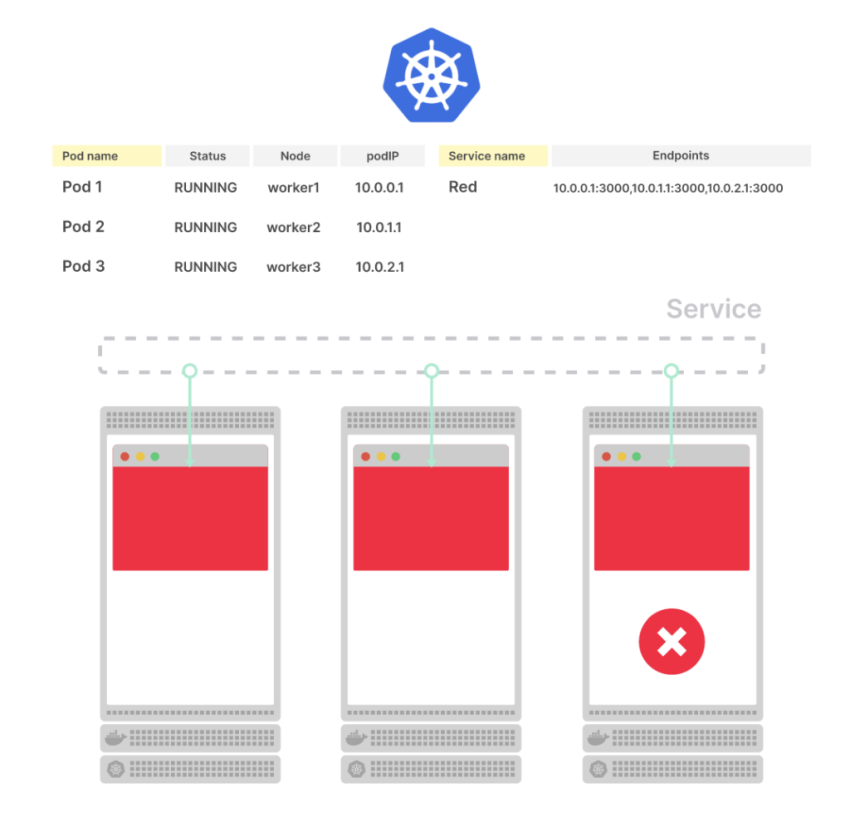
Но что происходит, когда под удаляется?
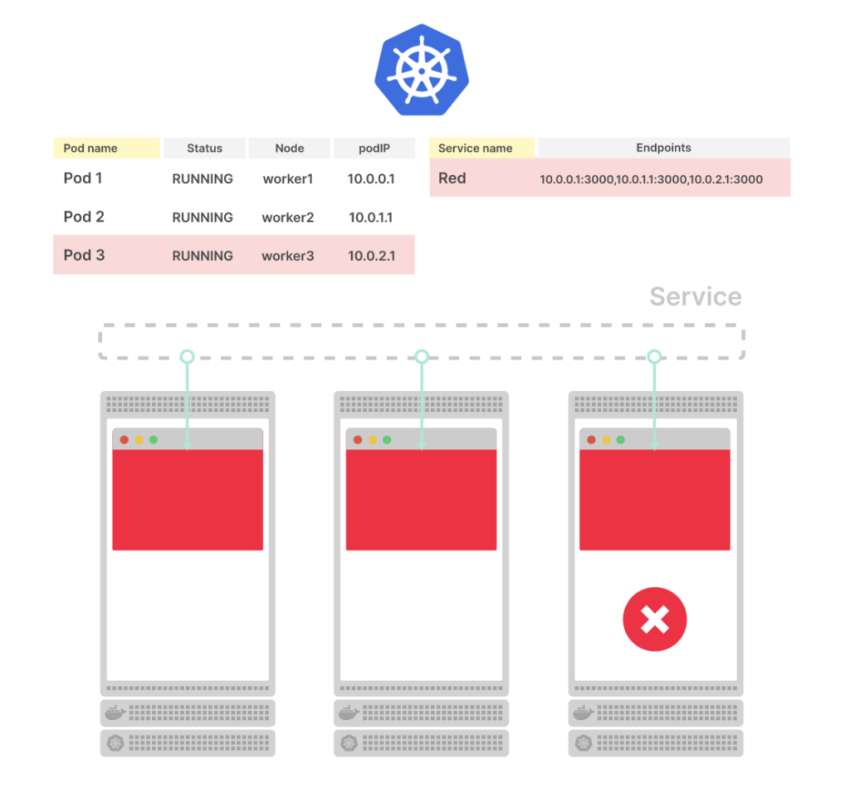
Сервис немедленно удаляет endpoint, и под удаляется из базы данных
Kubernetes реагирует на любое небольшое изменение в кластере
Готов ли теперь под к использованию? Осталось еще кое-что!
Использование endpoint в Kubernetes
Endpoint используют несколько компонентов Kubernetes.
Kube-proxy использует endpoint, чтобы настраивать iptables-правила на узлах. Каждый раз, когда объект Endpoint меняется, kube-proxy получает новый список IP-адресов и портов и записывает новые iptables-правила.
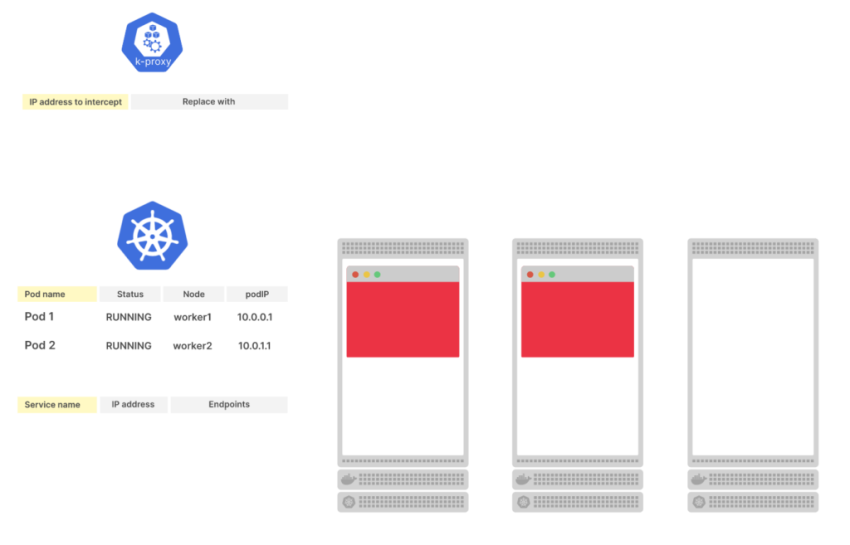
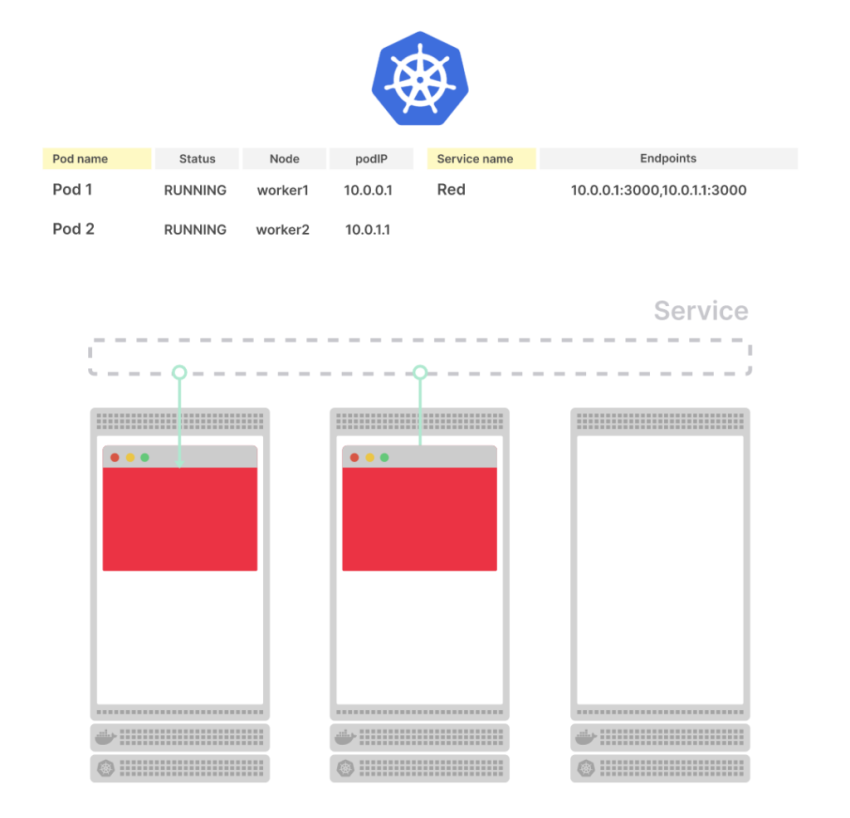
Рассмотрим трехузловой кластер с двумя подами без сервисов. Состояние подов хранится в etcd
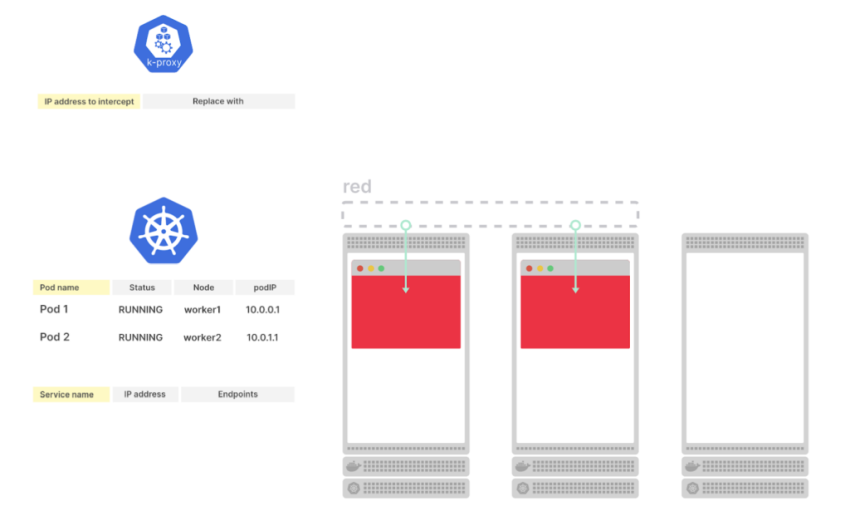
Что происходит, когда вы создаете cервис?
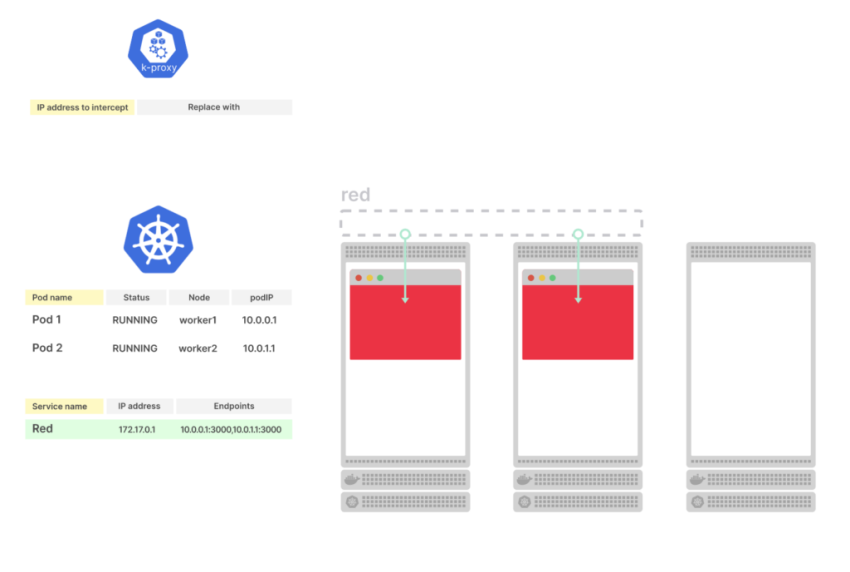
Kubernetes создает объект Endpoint и собирает все endpoint (пары IP-адресов и портов) из подов
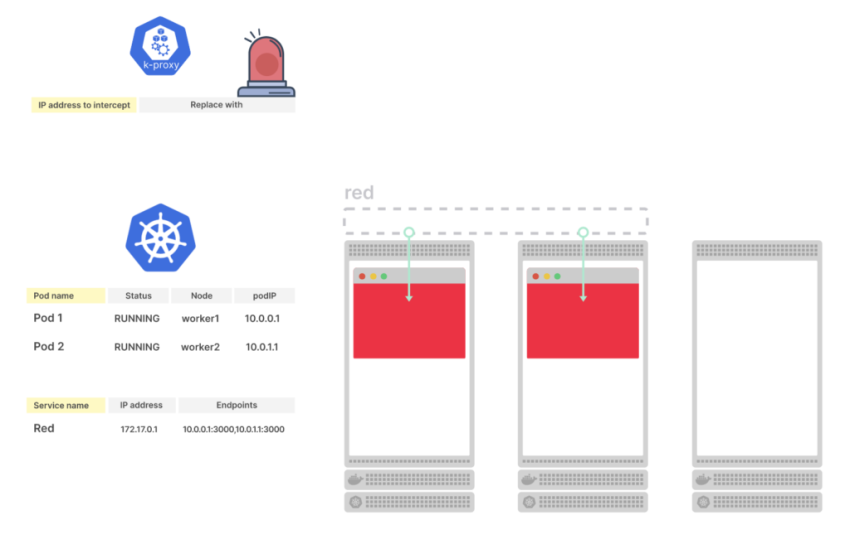
Демон Kube-proxy подписан на изменения в Endpoint
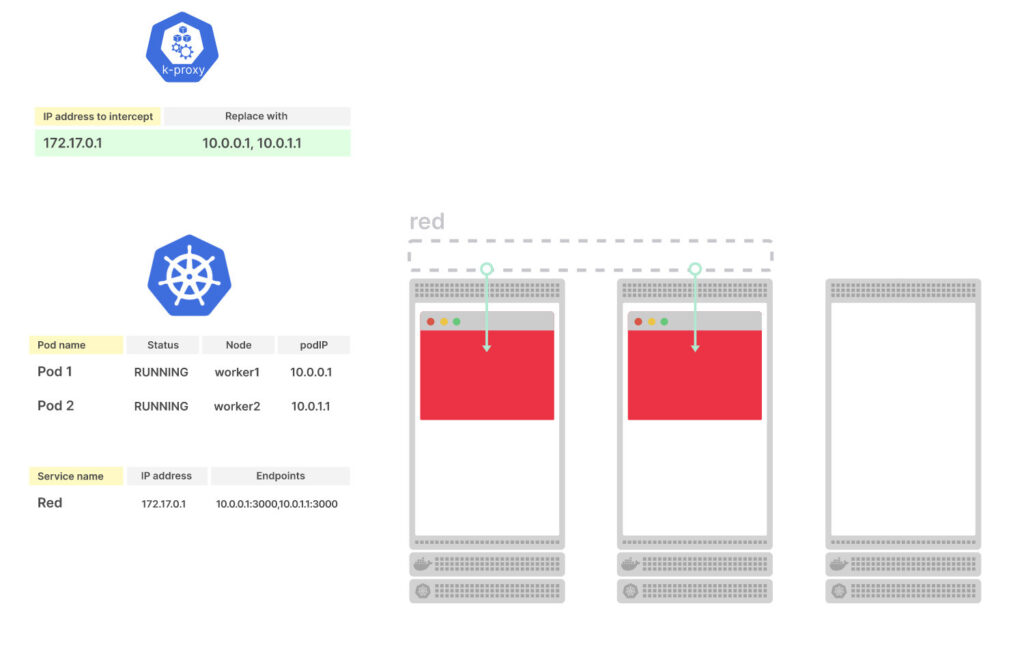
Когда Endpoint добавляется, удаляется или обновляется, kube-proxy считывает новый список endpoint
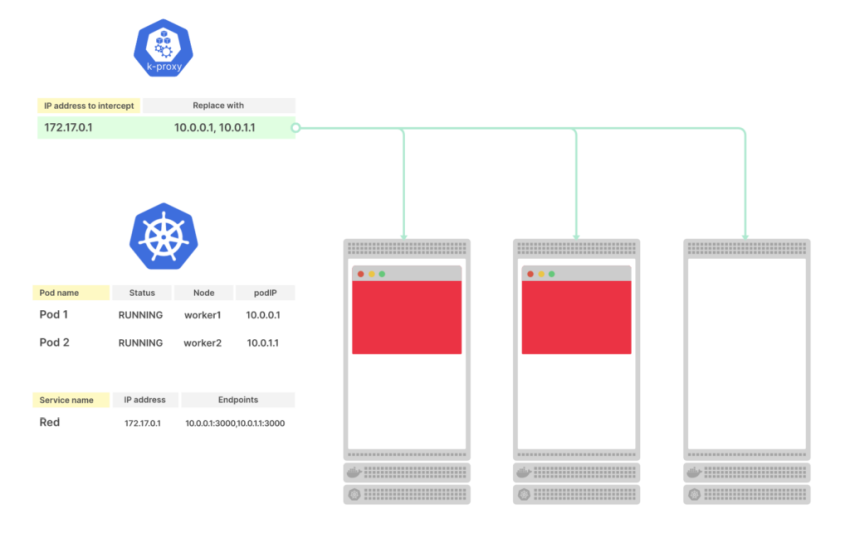
Kube-proxy использует endpoint для создания iptables-правил на каждом узле кластера
Ingress-контроллер — компонент кластера, он направляет внешний трафик в кластер и использует тот же самый список endpoint. При настройке Ingress-манифеста в поле destination обычно указывают сервис. Вот пример такого файла:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
spec:
rules:
- http:
paths:
- backend:
service:
name: my-service
port:
number: 80
path: /
pathType: Prefix
На самом деле трафик на сервис не направляется. Вместо этого Ingress-контроллер подписывается на изменения Endpoint этого сервиса.
Ingress направляет трафик непосредственно к поду, не используя сервис. Каждый раз, когда Endpoint объекта меняется, Ingress извлекает новый список IP-адресов и портов и перенастраивает контроллер для подключения новых подов.
На изменения endpoint подписываются и другие компоненты Kubernetes, например CoreDNS — компонент DNS в кластере. Если вы используете сервис типа Headless, CoreDNS подписывается на изменения endpoint и перенастраивает себя после каждого изменения. Эти же endpoint используют Service Mesh, — например Istio или Linkerd, — поставщики облачных услуг для создания сервисов типа LoadBalancer и другие службы Kubernetes.
Несколько компонентов подписываются на изменение endpoint и могут получать уведомления об этом в разное время.
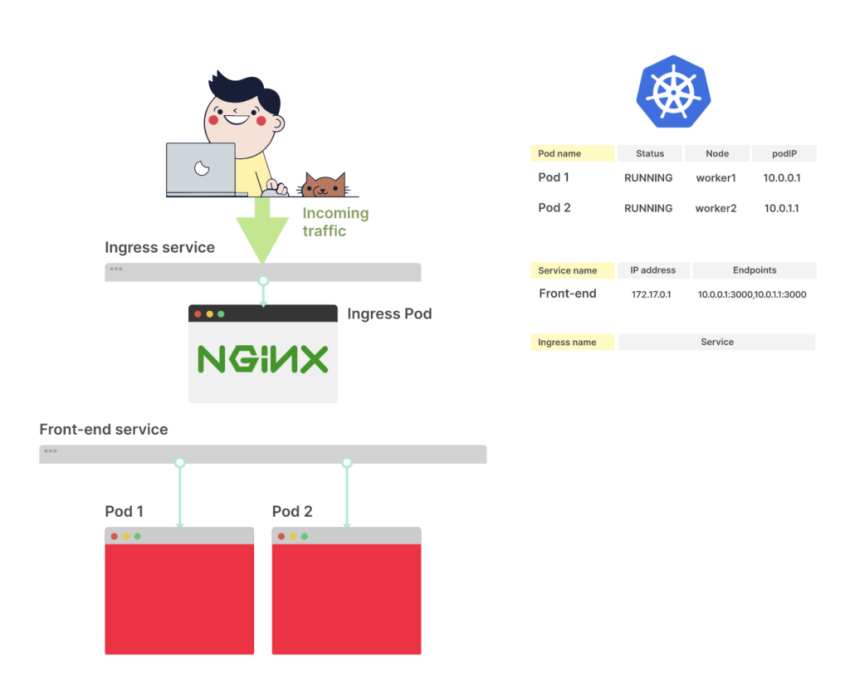
Рассмотрим Ingress-контроллер с развертыванием из двух реплик и сервисом
Если вы хотите направить внешний трафик к подам через Ingress, то отразите это в Ingress-манифесте (YAML-файле)
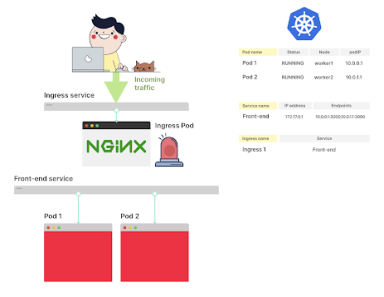
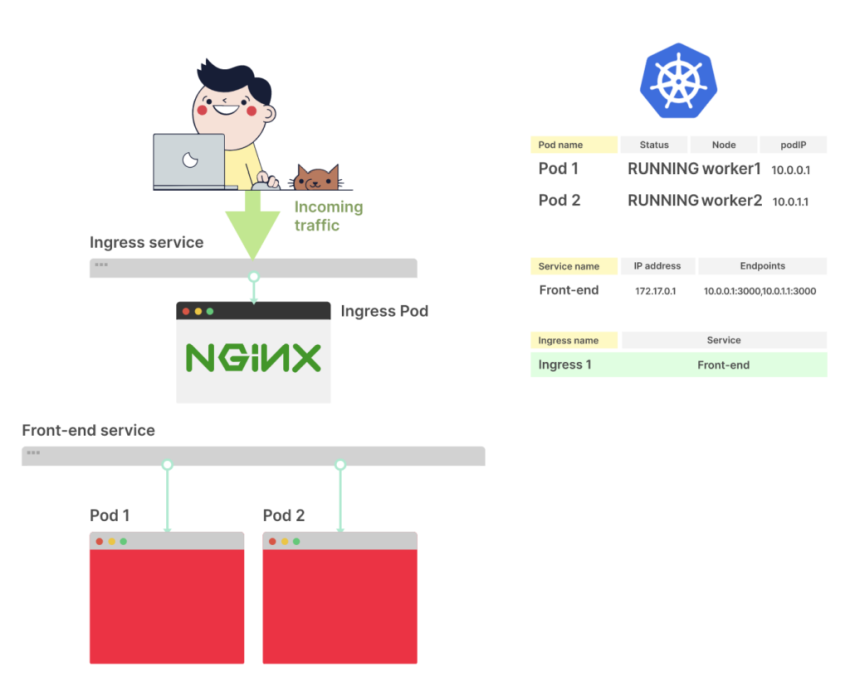
Как только выполнится команда <kubectl apply -f ingress.yaml>, Ingress-контроллер получит файл от Control Plane
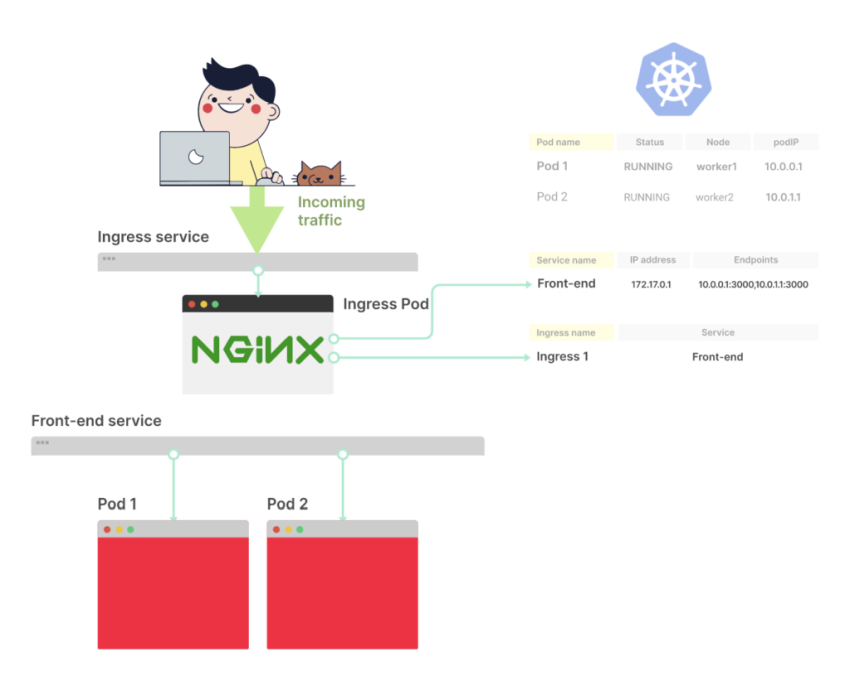
В YAML-описании Ingress есть свойство serviceName, оно описывает, какой сервис должен быть использован
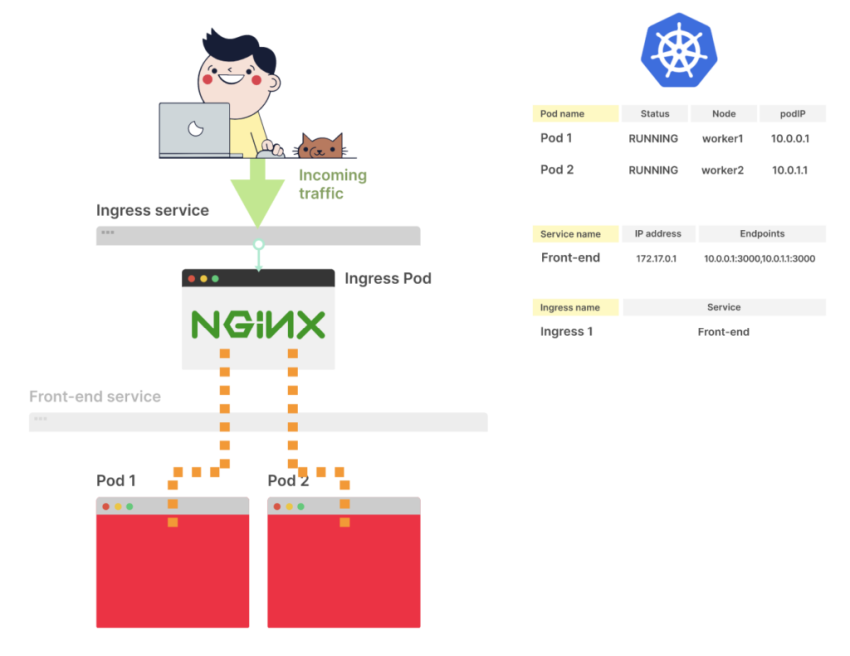
Ingress-контроллер получает список endpoint из сервиса и пропускает его. Трафик направляется непосредственно к endpoint подов
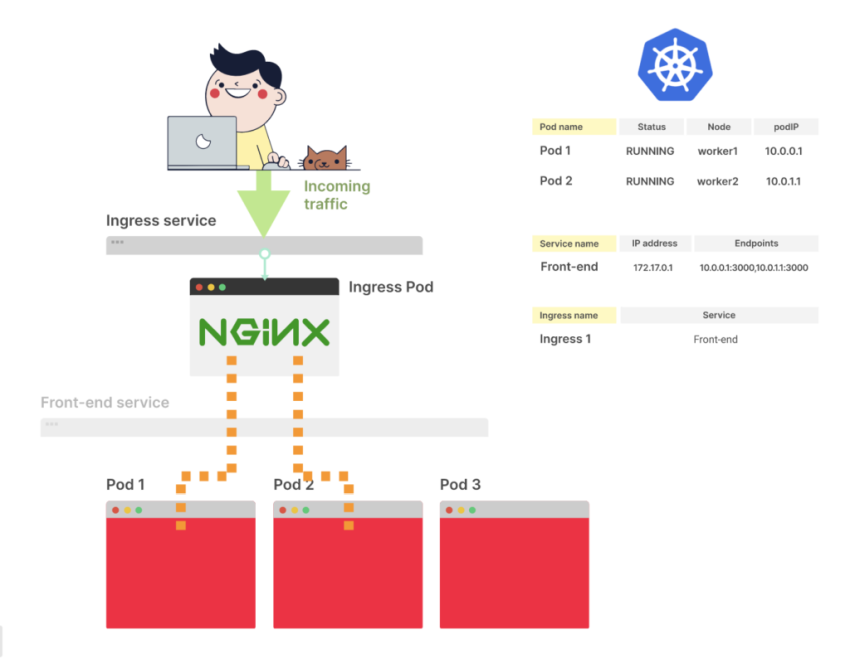
Что происходит при создании нового пода?
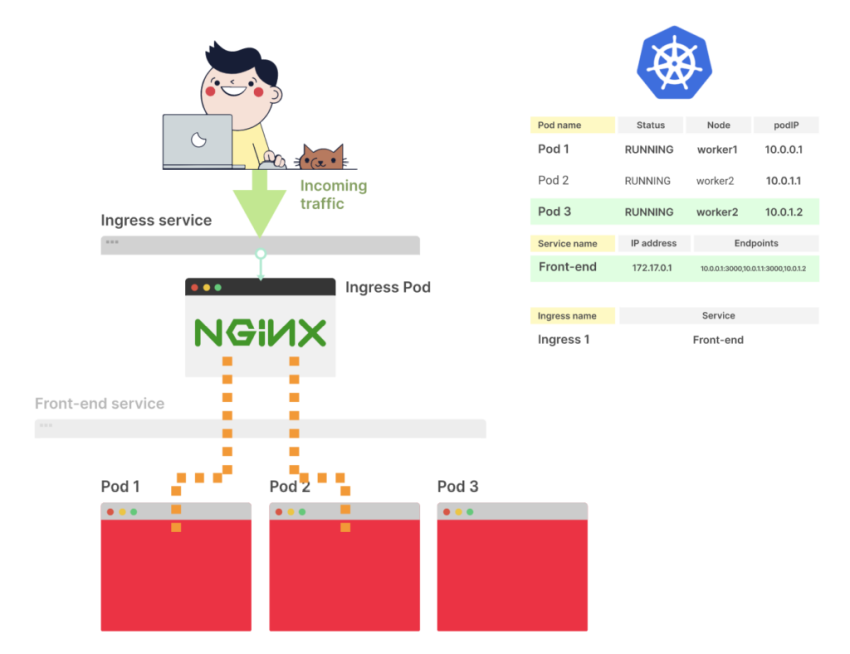
Вы уже знаете, как Kubernetes создает под и распространяет его endpoint
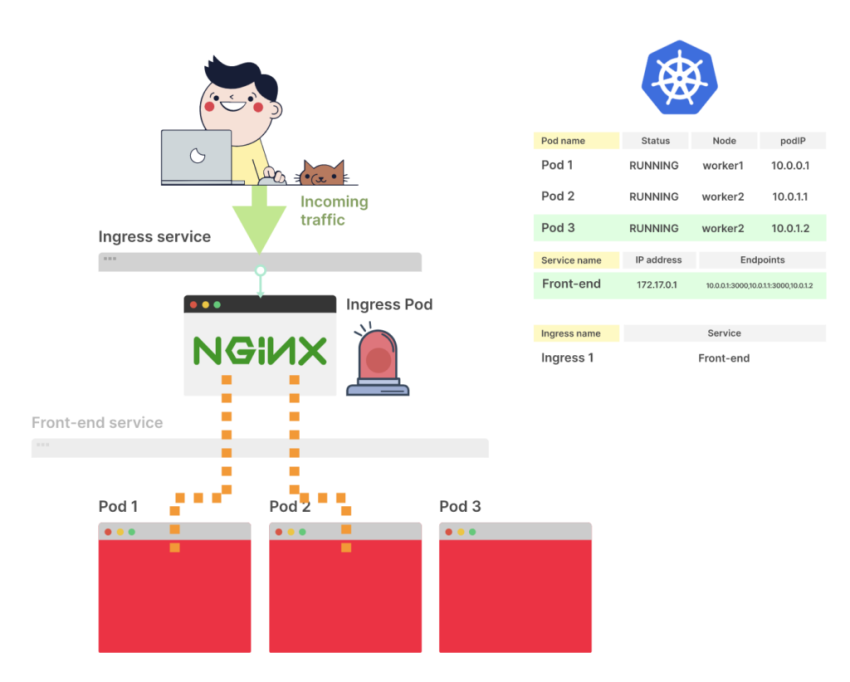
Ingress-контроллер подписывается на изменения endpoint. После входящего изменения он получает новый список endpoint
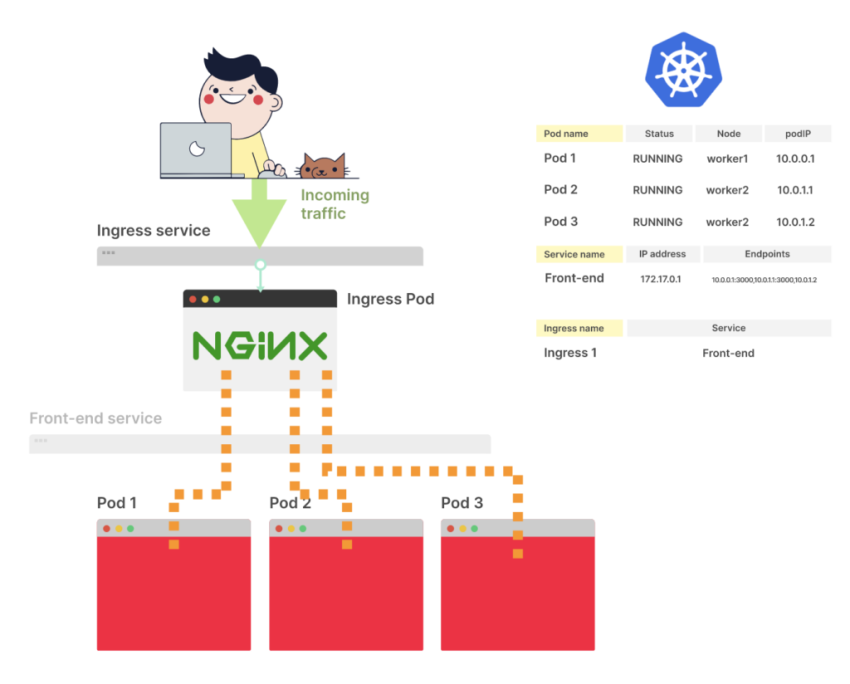
Ingress-контроллер направляет трафик к новому поду
Промежуточный итог
Вот краткий обзор того, что происходит при создании пода, если он не относится к сервису:
- Под сохраняется в etcd.
- Планировщик определяет узел и записывает этот узел в etcd.
- Kubelet получает уведомление о новом и запланированном поде.
- Kubelet делегирует создание контейнера The Container Runtime Interface (CRI).
- Kubelet делегирует добавление контейнера The Container Network Interface (CNI).
- Kubelet делегирует монтирование томов в контейнере The Container Storage Interface (CSI).
- CSI назначает IP-адрес.
- Kubelet сообщает IP-адрес Control Plane.
- IP-адрес сохраняется в etcd.
Если же под относится к сервису:
- Kubelet ждет успешного выполнения readiness-пробы.
- Все соответствующие Endpoint (объекты) уведомляются об изменении.
- В список Endpoint добавляются новые endpoint (пара IP-адрес + порт).
- Kube-proxy получает уведомление об изменении endpoint. Kube-proxy обновляет iptables-правила для каждого узла.
- Ingress-контроллер уведомляется об изменении endpoint, направляет трафик на новые IP-адреса.
- CoreDNS получает уведомление об изменении endpoint. Если сервис headless, то запись DNS обновляется.
- Облачный провайдер получает уведомление об изменении endpoint. Если тип Service — LoadBalancer, то новый endpoint становится частью балансировщика нагрузки.
- Все служебные сети, установленные в кластере, получают уведомление об изменении endpoint.
- Любая другая функциональность, подписанная на изменения endpoint, также получает уведомление.
Удаление пода
При удалении пода те же действия выполняют в обратном порядке:
- Сначала необходимо удалить endpoint из Endpoint (объекта).
- Readiness-проба игнорируется, и endpoint сразу удаляется из Control Plane. Это, в свою очередь, запускает все события в kube-proxy, Ingress-контроллере, DNS, service mesh и т. д.
- Перечисленные компоненты обновляют свое внутреннее состояние и прекращают маршрутизацию трафика на IP-адрес.
Поскольку компоненты могут быть заняты другими задачами, непонятно, сколько времени потребуется для удаления IP-адреса из их внутреннего состояния.

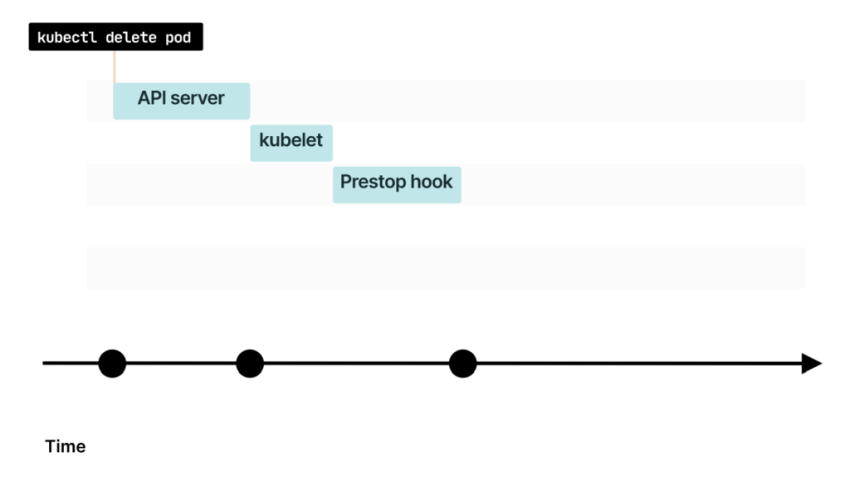
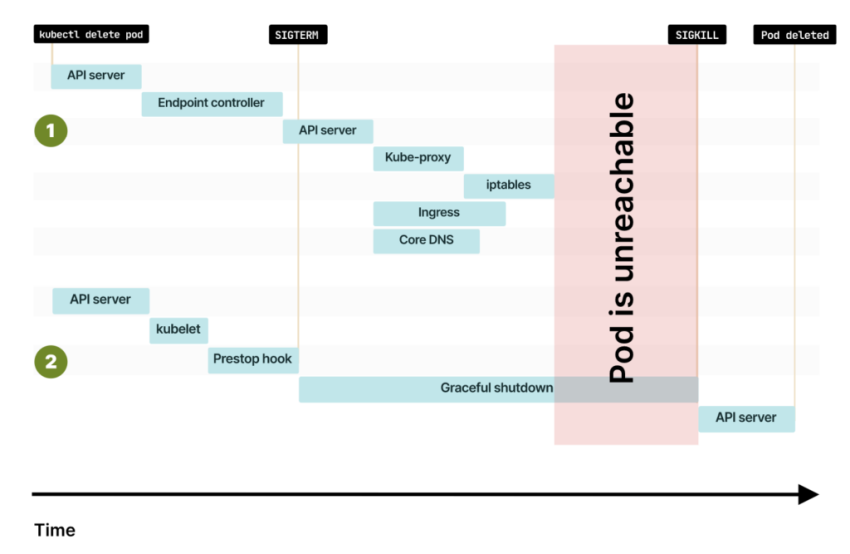
При удалении пода команда сначала попадает в API Kubernetes

Сообщение перехватывает Endpoint-контроллер в Control Plane
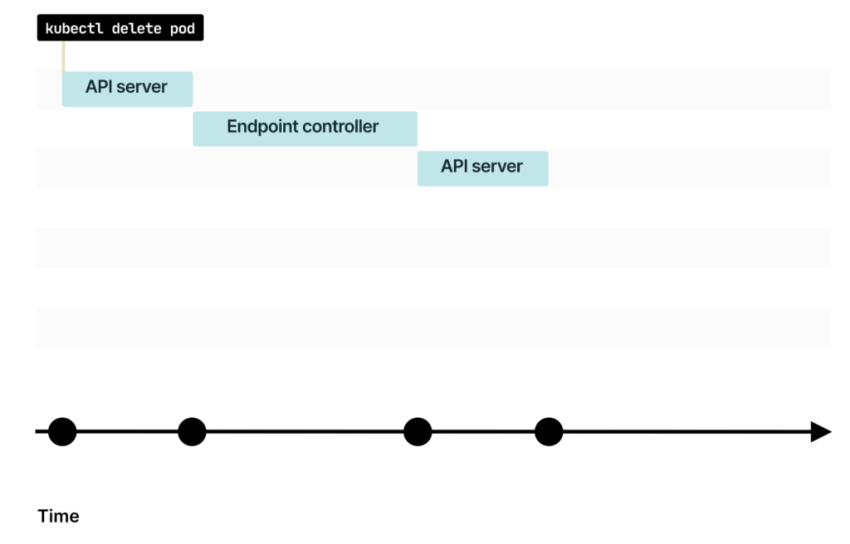
Endpoint-контроллер отправляет команду в API для удаления IP-адреса и порта из Endpoint-объекта
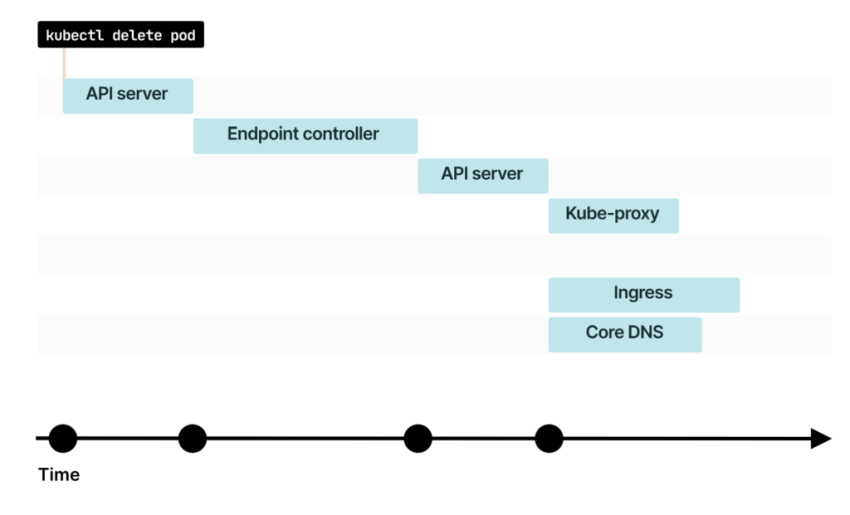
Кто следит за изменениями в Endpoint? Об изменениях уведомляют Kube-proxy, Ingress-контроллер, CoreDNS и другие компоненты
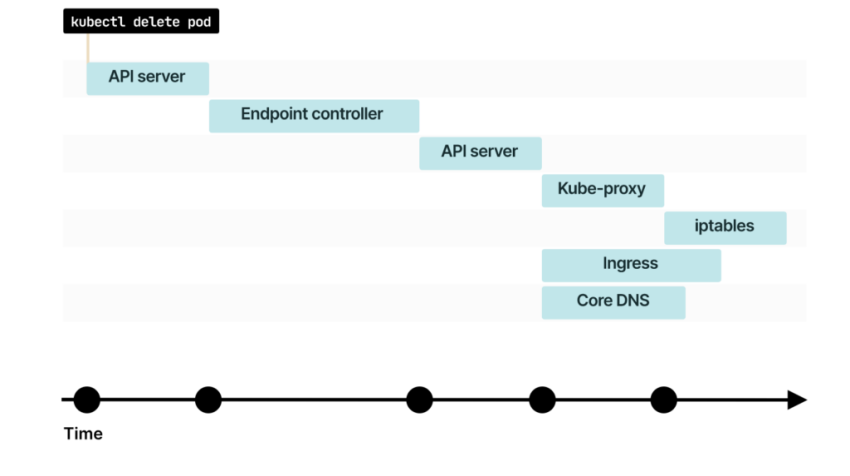
Некоторым компонентам, например kube-proxy, может понадобиться дополнительное время для дальнейшего оповещения об изменениях
Kubelet уведомляется об изменении и делегирует:
- CSI — размонтирование любых томов из контейнера.
- CNI — отсоединение контейнера от сети и передачу IP-адреса.
- CRI — уничтожение контейнера.
Таким образом, Kubernetes выполняет точно такие же шаги, как и при создании пода, но в обратном порядке.

При удалении пода команда сначала попадает в API Kubernetes
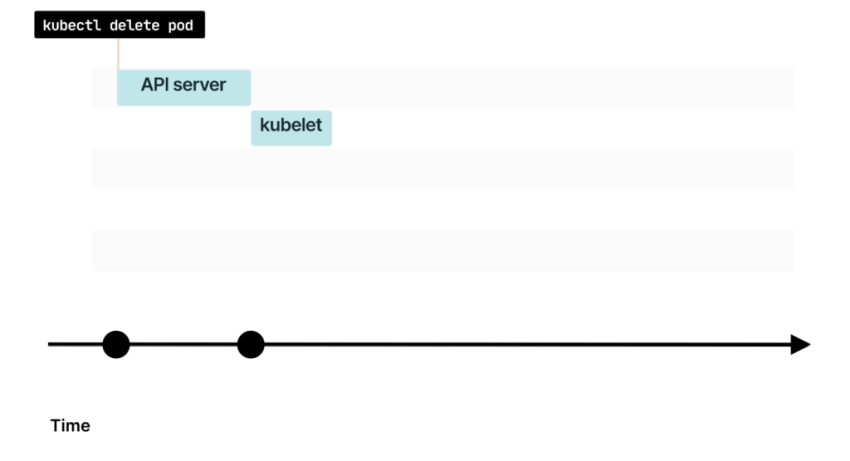
Kubelet опрашивает Control Plane на наличие обновлений и понимает, что под удален
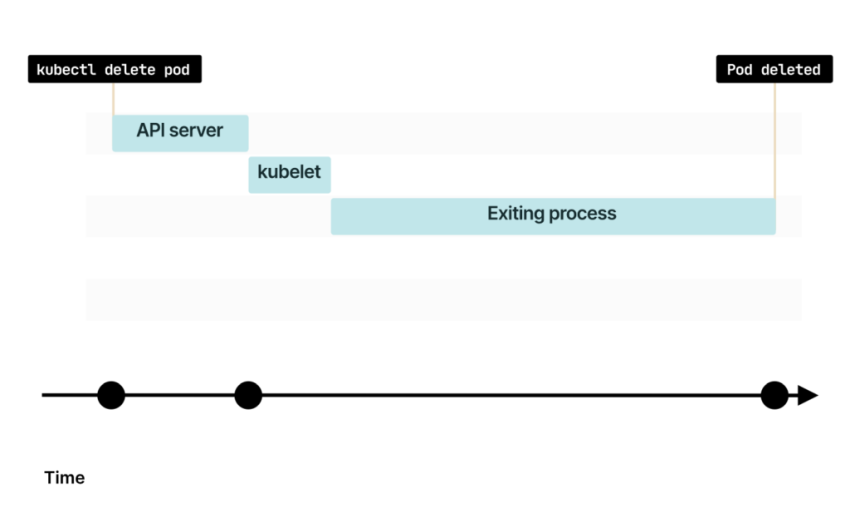
Kubelet делегирует удаление пода Container Runtime Interface, Container Network Interface и Container Storage Interface
Есть небольшое, но существенное различие. Когда вы завершаете работу пода, удаление endpoint и сигнал для kubelet отправляется одновременно. Когда вы создаете под в первый раз, Kubernetes ждет, пока kubelet сообщит IP-адрес, а затем оповещает систему об изменении endpoint систему. Но при удалении пода события начинаются параллельно, и это может привести систему в состояние гонки.
Что, если под будет удален до распространения новых endpoint?
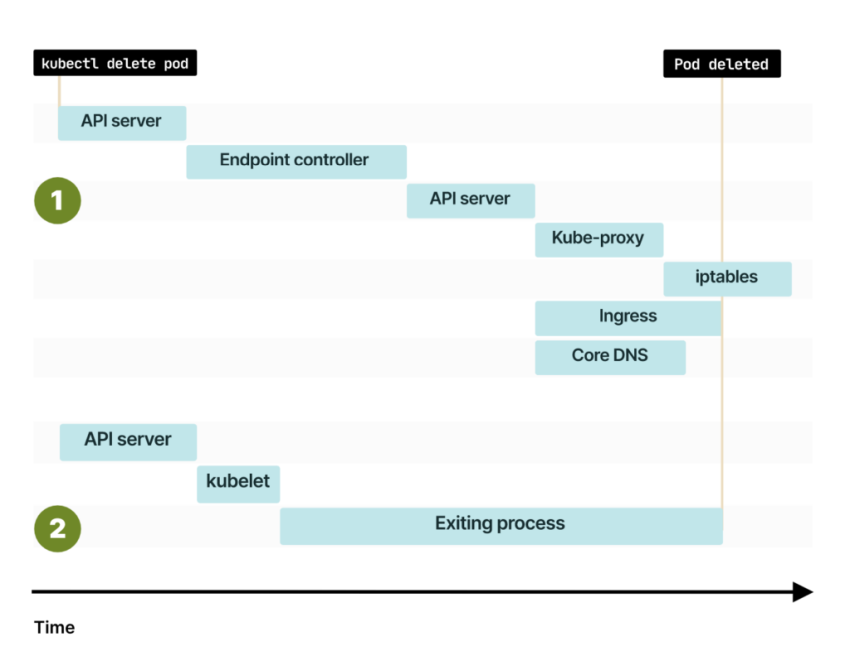
Удаление endpoint и пода происходит одновременно
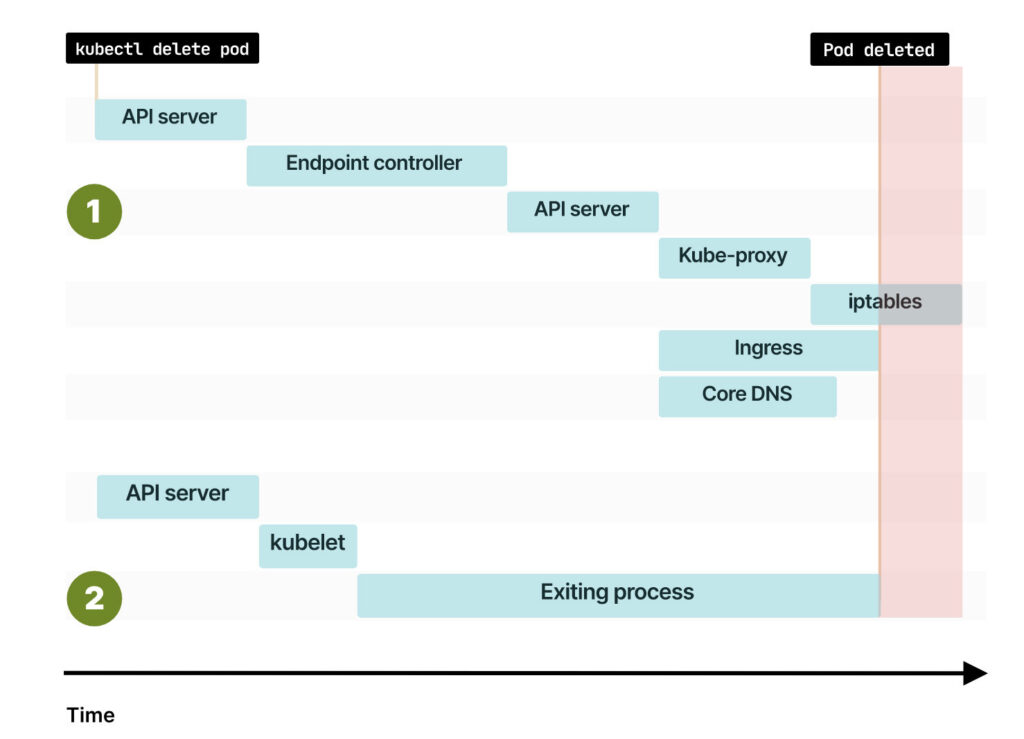
Значит, вы можете удалить endpoint до того, как kube-proxy обновит iptables-правила
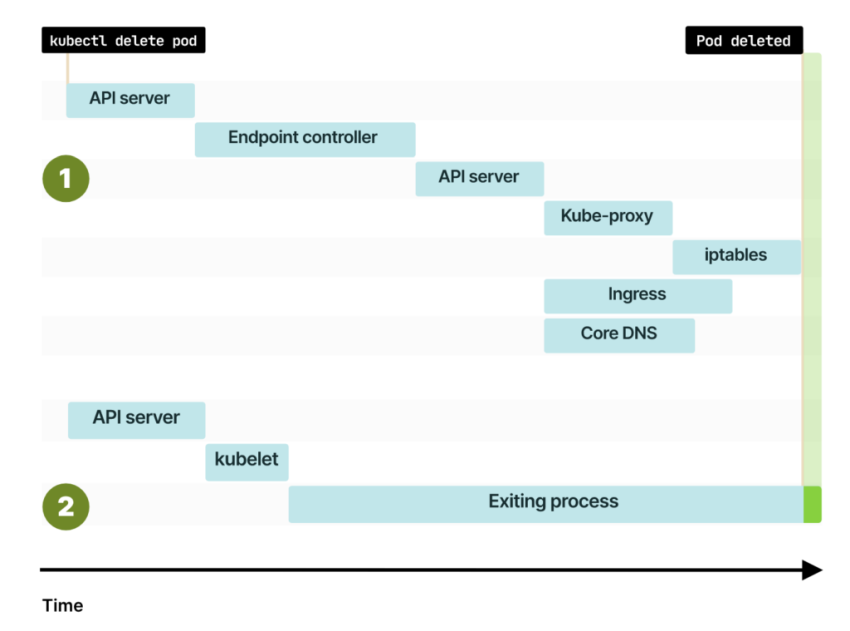
Или вам может повезти и под удалится только после того, как endpoint изменится во всей системе
Graceful shutdown
Если работа пода завершается до того, как endpoint удален из kube-proxy или Ingress-контроллера, система может перейти в режим ожидания. И, если подумать, это имеет смысл.
Kubernetes по-прежнему направляет трафик на IP-адрес, но пода больше нет. Компоненты Ingress-контроллер, kube-proxy, CoreDNS и другие компоненты не успели удалить этот IP-адрес из своей памяти.
В идеальном мире Kubernetes проверяет, что все компоненты в кластере получили обновленный список endpoint, и только после этого удаляет под. Но Kubernetes так не работает. Он предлагает надежные примитивы для управления endpoint. Endpoint-объект и более продвинутые абстракции, например, Endpoint Slices. Однако Kubernetes не проверяет, соответствуют ли компоненты, подписывающиеся на изменения endpoint, актуальному состоянию кластера.
Итак, как же убедиться, что под удален после изменения endpoint?
Перед удалением под получает сигнал SIGTERM. Ваше приложение может перехватить его и начать завершение работы. Маловероятно, что endpoint будет немедленно удалена из всех компонентов Kubernetes. Так что вы можете:
- Немного подождать.
- Продолжить обрабатывать входящий трафик, несмотря на SIGTERM.
- Закрыть существующие долгоживущие соединения (например, соединение с базой данных или WebSockets).
- Завершить процесс.
По умолчанию Kubernetes отправляет сигнал SIGTERM и ждет 30 секунд перед принудительным завершением процесса.
Таким образом, можно подождать 15 секунд перед завершением работы. Вероятно, этого времени хватит для удаления endpoint из kube-proxy, Ingress-контроллера, CoreDNS и т. д. И меньше трафика будет перенаправлено на под до его отключения. Через 15 секунд можно безопасно закрыть соединение с базой данных (или любыми постоянными соединениями) и завершить процесс.
Примечание. Если вы считаете, что вам нужно больше времени, то можете остановить процесс через 20 или 25 секунд. Но помните: Kubernetes принудительно завершит процесс через 30 секунд, если вы не измените terminationGracePeriodSeconds.
Что делать, если вы не можете изменить код, чтобы управлять процессом завершения?
Вы можете реализовать сценарий, при котором приложение ждет фиксированное время перед завершением работы. Например, перед отправкой команды SIGTERM Kubernetes вызывает хук preStop в поде. Можно настроить preStop на ожидание в 15 секунд.
Давайте посмотрим на примере:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
lifecycle:
preStop:
exec:
command: ["sleep", "15"]
Хук preStop — один из хуков жизненного цикла пода.
15-секундная задержка — рекомендованное время?
Зависит от обстоятельств, но можно оттолкнуться от этого времени и затем подобрать оптимальное в процессе тестирования. Возможные варианты:
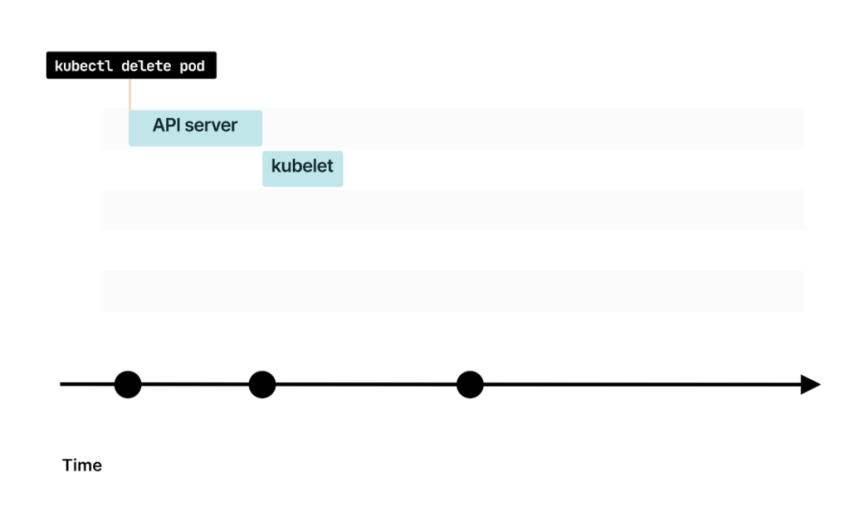
Вы уже знаете, что при удалении пода kubelet получает уведомление об изменении
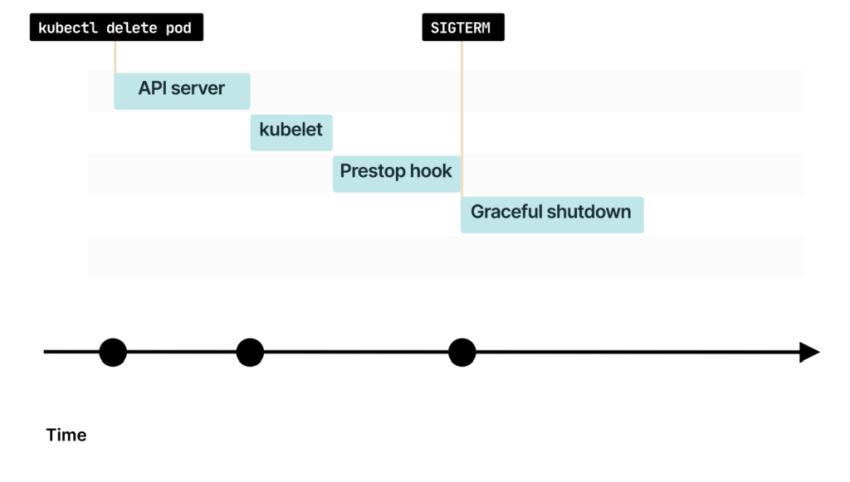
Если у пода есть preStop-хук, он будет вызван первым
Когда preStop завершается, kubelet отправляет в контейнер сигнал SIGTERM. С этого момента контейнер должен закрыть все long-lived-соединения и подготовиться к завершению
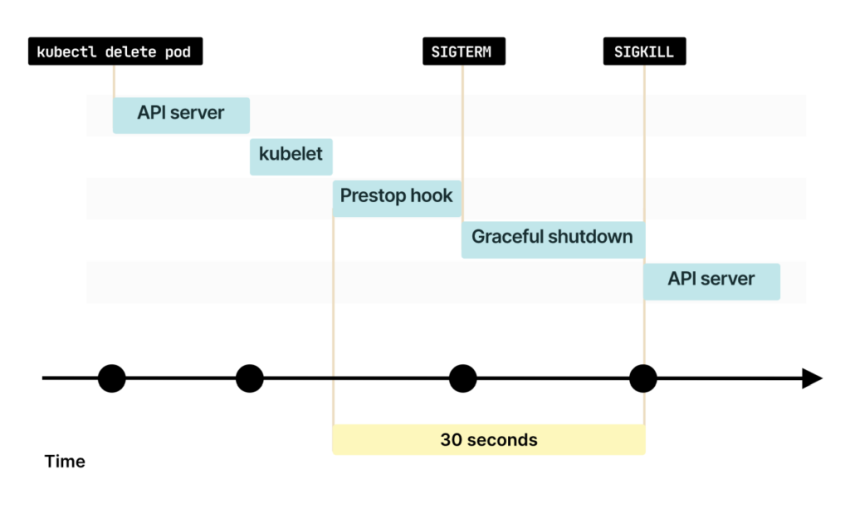
По умолчанию у процесса есть 30 секунд для завершения работы, включая хук preStop. Если к этому времени процесс не завершится, то kubelet отправит сигнал SIGKILL и принудительно завершит процесс
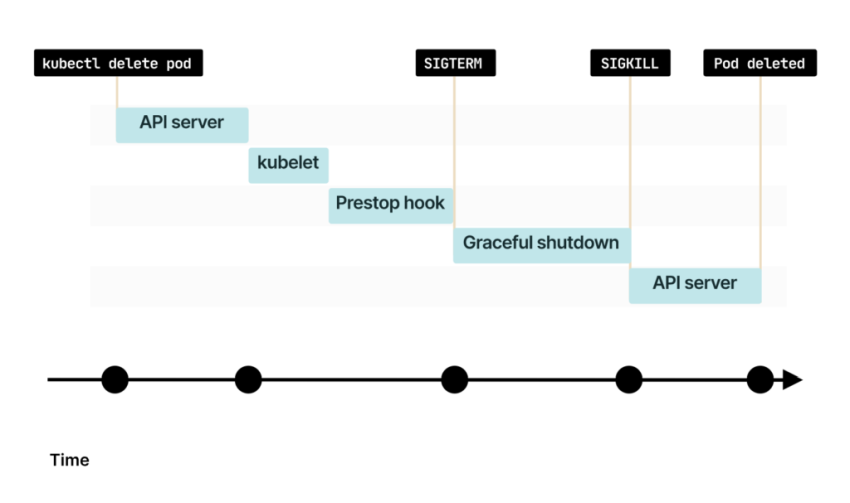
Kubelet уведомляет Control Plane об успешном удалении пода
Grace periods и скользящие обновления
При удалении пода применяется плавное завершение работы. Но как быть, если под так и не удален? Даже если вы этого не сделаете, Kubernetes все равно удаляет под.
Kubernetes создает и удаляет под каждый раз, когда вы развертываете новую версию приложения. Когда вы изменяете образ в своем развертывании, Kubernetes разворачивает изменение постепенно.
apiVersion: apps/v1
kind: Deployment
metadata:
name: app
spec:
replicas: 3
selector:
matchLabels:
name: app
template:
metadata:
labels:
name: app
spec:
containers:
- name: app
# image: nginx:1.18 OLD
image: nginx:1.19
ports:
- containerPort: 3000
Допустим, у вас есть три реплики, и как только вы отправляете новый YAML-файл, Kubernetes:
- создает под с новым образом контейнера;
- уничтожает существующий контейнер;
- дожидается готовности пода.
Система повторяет эти шаги до тех пор, пока все поды не будут обновлены. Kubernetes повторяет каждый цикл только после того, как новый под готов к приему трафику, то есть прошел проверку readiness-пробы.
Ждет ли Kubernetes удаления текущего пода перед переходом к следующему?
Нет, если у вас 10 подов и для одного требуется две секунды на подготовку и 20 на завершение работы, то происходит следующее:
- Первый под создается, а предыдущий под прекращает работу.
- Новый под готов через две секунды, после чего Kubernetes создает новый.
- Находясь в процессе завершения, под продолжает жить в течение 20 секунд.
Через 20 секунд все новые поды становятся активными, а все 10 предыдущих подов завершают работу. В общей сложности количество подов удваивается на некоторое время: одновременно работают 10 запущенных и 10 завершающихся подов.
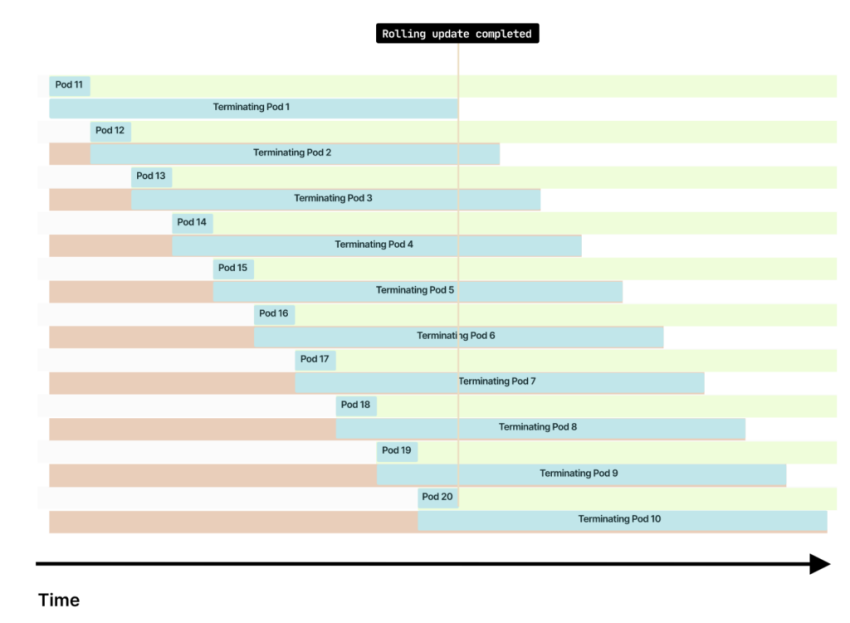
Чем дольше graceful-период по сравнению с readiness-пробой, тем больше подов будет запущено (и завершено) одновременно.
Это плохо?
Не обязательно, пока вы не обрываете соединения.
Прерывание long-running-задач
А как насчет длительной работы? Если вы кодируете большое видео, есть ли способ отложить завершение пода?
Представим, что у вас есть развертывание с тремя репликами. Каждой из них поставлена задача кодирования видео, и ее выполнение такой задачи может занимать несколько часов. Когда вы запускаете непрерывное обновление, у подов есть 30 секунд, чтобы выполнить задачу, прежде чем они будут удалены.
Можно ли не откладывать завершение работы пода?
Вы можете увеличить terminationGracePeriodSeconds до нескольких часов. Но endpoint пода в этот момент недоступен.
Инструменты мониторинга не смогут получить доступ к метрикам пода. Почему?
Инструменты вроде Prometheus полагаются на актуальность перечня endpoint в вашем кластере. Как только вы удаляете под, удаление endpoint распространяется на весь кластер и даже на Prometheus!
Поэтому вместо увеличения параметра terminationGracePeriodSeconds рекомендуют создавать новое развертывание для каждого релиза, при этом существующее развертывание остается нетронутым. То есть long-running-задачи могут по-прежнему выполнять обработку видео. По мере выполнения задач можно удалять их вручную. Автоматическое удаление возможно при настройке автомасштабирования, которое позволяет уменьшать количество реплик до нуля по мере выполнения задач.
Подробнее об уровнях автомасштабирования читайте в статье.
Такой способ масштабирования называют rainbow deployment. Его используют, когда работу предыдущих версий подов нужно поддерживать дольше, чем значение параметра gracePeriod.
Система поддерживает WebSocket — вам не нужно их прерывать каждый раз. Если вы часто выпускаете релизы в течение дня, это может привести к прерываниям передаче данных в реальном времени. В таком случае создание нового развертывания для каждого релиза — менее очевидный, но более оптимальный выбор.
Существующие пользователи могут продолжать работу с потоковой передачей данных, а новая версия развертывания уже обслуживает новых пользователей. По мере того как пользователь перестает использовать старые поды, вы можете постепенно уменьшать количество реплик и удалять прошлые развертывания.
Заключение
Помните: несмотря на удаление подов из кластера, их IP-адреса могут по-прежнему использоваться для маршрутизации трафика. Так что вместо немедленного отключения пода стоит немного подождать, чтобы приложение могло корректно завершить свою работу, или же вам следует предусмотреть preStop-обработчик.
Под следует удалять только после того, как все endpoint в кластере обновятся в kube-proxy, Ingress-контроллере, CoreDNS и других компонентах.
Если ваши поды выполняют long-running задачи, например кодирование видео или WebSockets, возможно, будет полезно использовать rainbow deployment. В rainbow deployment вы развертываете новую версию для каждого релиза и удаляете предыдущую версию только после завершения всех ее задач.
Вы можете вручную удалить предыдущую версию после завершения long-running-задачи, а также можете автоматизировать процесс и уменьшать количество реплик до нуля.
Источник: https://habr.com/ru/company/vk/blog/654471/