Для тех кто давно задумывался об удобном инструменте анализа производительности своего SQL сервера, есть хорошая новость!
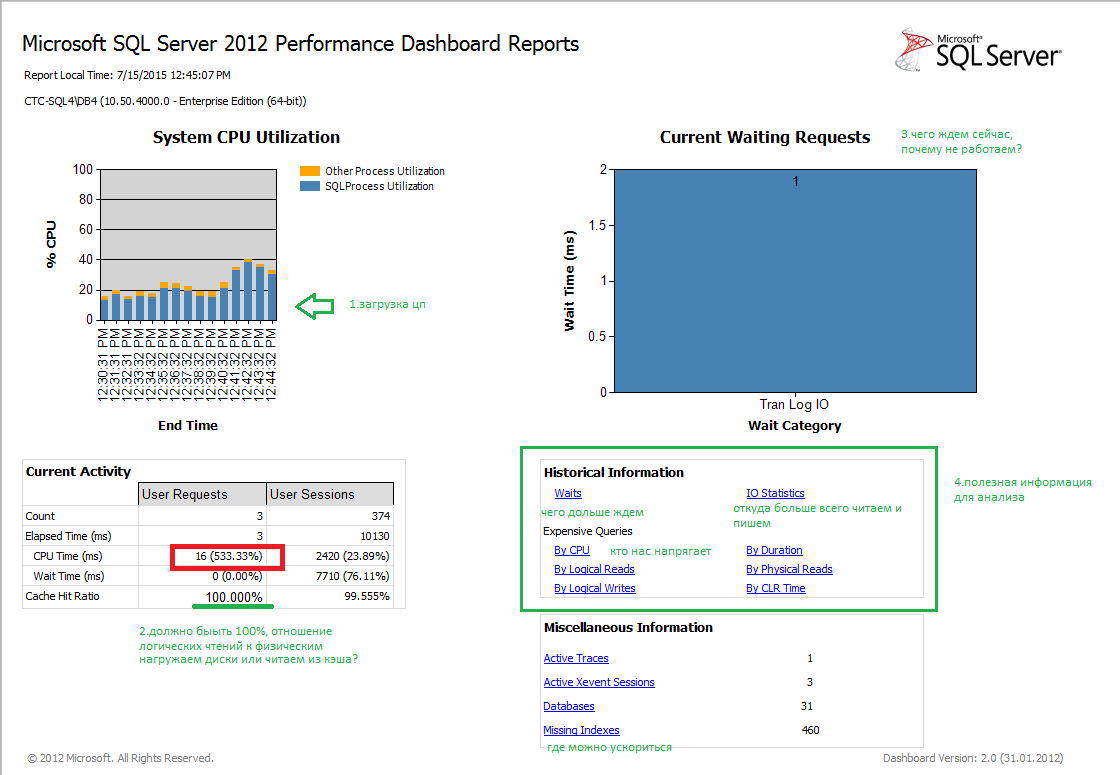
Кроме стандартных отчетов в SSMS, оказывается уже есть на базе отчётов SSRS от MS готовый пакет отчетов под шикарным названием «панель» производительности.
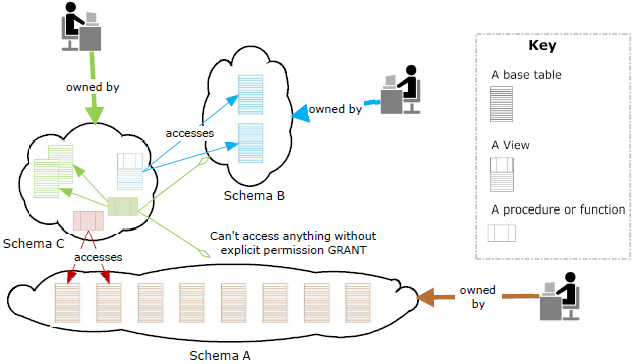
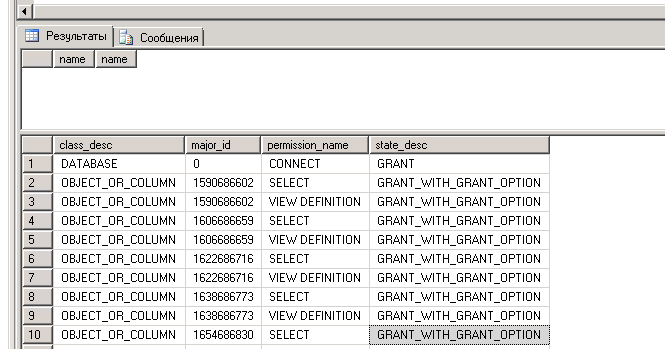
Что удобно, для выполнения этих отчетов не нужны права супер одмина.
Если внимательно присмотреться то не всегда этот отчет выдает адекватные цифры, так что будьте готовы к этому. Как говорится доверяй, но проверяй.
Ссылка на
отчеты и горячее
видео!
После установки отчеты можно найти здесь
Сама панель выглядит как то так.
Установка проста на сервер устанавливаем необходимые процедуры из файла setup.sql в базу msdb
В файле найдете все необходимые скрипты которые потом можно использовать по отдельности при желании.
При желании разворачиваем все отчеты на сервере отчетов.
И настраиваем подписки.
В общем как всегда у MS реализация получилась не айс, идея была на поверхности давно, но до ума довести так и не получилось.
PS: Использование скриптов в анализе никто конечно не отменял
—задержки с IO (чтение,запись)
SELECT DB_NAME(vfs.database_id) AS database_name ,
vfs.database_id ,
vfs.FILE_ID ,
io_stall_read_ms / NULLIF(num_of_reads, 0) AS avg_read_latency ,
io_stall_write_ms / NULLIF(num_of_writes, 0)
AS avg_write_latency ,
io_stall / NULLIF(num_of_reads + num_o
f_writes, 0)
AS avg_total_latency ,
num_of_bytes_read / NULLIF(num_of_reads, 0)
AS avg_bytes_per_read ,
num_of_bytes_written / NULLIF(num_of_writes, 0)
AS avg_bytes_per_write ,
vfs.io_stall ,
vfs.num_of_reads ,
vfs.num_of_bytes_read ,
vfs.io_stall_read_ms ,
vfs.num_of_writes ,
vfs.num_of_bytes_written ,
vfs.io_stall_write_ms ,
size_on_disk_bytes / 1024 / 1024. AS size_on_disk_mbytes ,
physical_name
FROM sys.dm_io_virtual_file_stats(NULL, NULL) AS vfs
JOIN sys.master_files AS mf ON vfs.database_id = mf.database_id
AND vfs.FILE_ID = mf.FILE_ID
ORDER BY avg_total_latency DESC
OPTION (RECOMPILE);
—что в буферном <
/span>пуле
SELECT count(*)*8/1024 AS 'Cached Size (MB)'
,CASE database_id
WHEN 32767 THEN 'ResourceDb'
ELSE db_name(database_id)
END AS 'Database'
FROM sys.dm_os_buffer_descriptors
GROUP BY db_name(database_id),database_id
ORDER BY 'Cached Size (MB)' DESC
OPTION (RECOMPILE);
— Содержимое буферного пула, для базы
SELECT obj.name AS TableName, count(*)
FROM sys.dm_os_buffer_descriptors buf
INNER JOIN sys.allocation_units alloc ON alloc.allocation_unit_id = buf.allocation_unit_id
INNER JOIN sys.partitions part ON part.hobt_id = alloc.container_id
INNER JOIN sys.indexes ind ON ind.object_id = part.object_id AND ind.index_id = part.index_id
INNER JOIN sys.objects obj ON obj.object_id = part.object_id
WHERE buf.database_id = 2
group by obj.name
order by count(*) desc
OPTION (RECOMPILE);
—10 запросов по времени работы и тд
SELECT TOP 10
QT.TEXT AS STATEMENT_TEXT,
QP.QUERY_PLAN,
QS.TOTAL_WORKER_TIME AS CPU_TIME
FROM SYS.DM_EXEC_QUERY_STATS QS
CROSS APPLY SYS.DM_EXEC_SQL_TEXT (QS.SQL_HANDLE) AS QT
CROSS APPLY SYS.DM_EXEC_QUERY_PLAN (QS.PLAN_HANDLE) AS QP
ORDER BY TOTAL_WORKER_TIME DESC
—plan_generation_num DESC
—[IO_total] DESC
—last_worker_time DESC
—last_logical_reads DESC
—last_elapsed_time DESC
OPTION (RECOMPILE);
—проверка статистики
SELECT OBJECT_NAME(object_id) AS ObjectName,
STATS_DATE(object_id, stats_id) AS StatisticsDate,
*
FROM sys.stats
OPTION (RECOMPILE);
—использование tempdb
SELECT
sys.dm_exec_sessions.session_id AS [SESSION ID]
,DB_NAME(database_id) AS [DATABASE Name]
,HOST_NAME AS [System Name]
,program_name AS [Program Name]
,login_name AS [USER Name]
,status
,cpu_time AS [CPU TIME (in milisec)]
,total_scheduled_time AS [Total Scheduled TIME (in milisec)]
,total_elapsed_time AS [Elapsed TIME (in milisec)]
,(memory_usage * 8) AS [Memory USAGE (in KB)]
,(user_objects_alloc_page_count * 8) AS [SPACE Allocated FOR USER Objects (in KB)]
,(user_objects_dealloc_page_count * 8) AS [SPACE Deallocated FOR USER Objects (in KB)]
,(internal_objects
_alloc_page_count * 8) AS [SPACE Allocated FOR Internal Objects (in KB)]
,(internal_objects_dealloc_page_count * 8) AS [SPACE Deallocated FOR Internal Objects (in KB)]
,CASE is_user_process
WHEN 1 THEN 'user session'
WHEN 0 THEN 'system session'
END AS [SESSION Type], row_count AS [ROW COUNT]
FROM
sys.dm_db_session_space_usage
INNER join
sys.dm_exec_sessions
ON sys.dm_db_session_space_usage.session_id = sys.dm_exec_sessions.session_id
where status = 'running'
OPTION (RECOMPILE);
—текущие запросы
SELECT sqltext.TEXT,
req.session_id,
req.status,
req.command,
req.cpu_time,
req.total_elapsed_time,
req.logical_reads,
req.wait_type,
req.wait_time,
req.wait_resource,
req.blocking_session_id
FROM sys.dm_exec_requests req
CROSS APPLY sys.dm_exec_sql_text(sql_handle) AS sqltext
ORDER BY req.total_elapsed_time desc
OPTION (RECOMPILE);
—использование памяти
select type, name, memory_node_id , (sum(single_pages_kb)+sum(multi_pages_kb)+ sum(virtual_memory_committed_kb) )/1024 Totalmb
from sys.dm_os_memory_clerks
group by type, name, memory_node_id
ORDER BY TotalKB DESC
OPTION (RECOMPILE);
—количество строк по таблицам
SELECT tbl.name , CAST(p.rows AS float)
FROM sys.tables AS tbl
INNER JOIN sys.indexes AS idx ON idx.object_id = tbl.object_id and idx.index_id < 2
INNER JOIN sys.partitions AS p ON p.object_id=CAST(tbl.object_id AS int)
AND p.index_id=idx.index_id
WHERE SCHEMA_NAME(tbl.schema_id)='dbo'
order by p.rows desc
OPTION (RECOMPILE);