WireGuard — это современная технология VPN (виртуальная частная сеть) с самой современной криптографией. По сравнению с другими аналогичными решениями, такими как IPsec и OpenVPN , WireGuard быстрее, проще в настройке и более производительно. Это кроссплатформенный и может работать практически где угодно, включая Linux, Windows, Android и macOS. Wireguard — это одноранговая VPN; он не использует модель клиент-сервер. В зависимости от конфигурации одноранговый узел может действовать как традиционный сервер или клиент. Читать
Архив рубрики: Публикации
Вирусы и Linux
Среди пользователей бытует мнение, что Linux полностью безопасен от вирусов и поймать здесь какую-либо заразу невозможно. Антивирус не нужен и вообще про любые возможные опасности можно забыть, поскольку вирусов для этой операционной системы нет. Ходит даже шутка что если даже вы захотите запустить вирус в Linux то вам придется потратить несколько часов на его установку.
В этих словах есть доля истины, однако вирусы для Linux всё же существуют. Их гораздо меньше по сравнению с Windows, и система, в целом, защищённые, но вирусы существуют и о них не стоит забывать. В этой статье мы попытаемся разобраться почему Linux считается безопасным, какие у него слабые стороны, а также какие типы вирусов существуют.
Читать
Как перенаправить в PHP
URL-адрес браузера пользователя можно изменить с одного места на другое с помощью перенаправления. Перенаправление требуется для многих целей, таких как переключение с HTTP на HTTPS, изменение домена и т. д. Когда пользователь отправляет запрос на страницу на сервер, который не существует, или на местоположение страницы, которое изменилось, сервер будет отправьте информацию о новом URL с кодом HTTP 301 или 302. Это поможет пользователю узнать о новом URL-адресе путем перенаправления, и пользователь отправит запрос в новое место, чтобы получить желаемый контент. URL-адрес перенаправляется в PHP с помощью функции header(). В этой статьи показано, как функцию header() можно использовать в PHP для перенаправления URL-адреса с одной страницы на другую.
Функция header()
Это встроенная функция PHP для отправки клиенту необработанного HTTP-заголовка. Синтаксис этой функции показан ниже.
Синтаксис:
header( $header, [$replace, [$http_response_code]] )
Эта функция может принимать три аргумента. Первый аргумент является обязательным, а последние два аргумента — необязательными. $header используется для хранения строки заголовка, который содержит расположение перенаправления. $replace определяет, будет ли заменить предыдущий похожий заголовок и значение этого аргумента Boolean. $http_response_code используется для хранения определенного кода ответа, который будет отправлять пользователь.
Пример-1: URL-адрес перенаправления с кодом состояния по умолчанию
Создайте файл PHP со следующим кодом, который будет перенаправлять в новое место после ожидания в течение 2 секунд. Здесь функция die() используется для завершения скрипта. Когда функция header() используется с одним аргументом, 302 используется в качестве кода HTTP по умолчанию.
<?php
//Подождите 2 секунды
sleep(2);
//Перенаправление в конкретное место
header("Location: http://localhost/php/contactForm/index.html");
die();
?>
Вывод:
После выполнения кода URL-адрес перенаправляется в адрес http: //localhost/php/contactForm/index.html через 2 секунды. Если вы проверите код и откроете вкладку «Сеть», то в качестве кода состояния по умолчанию будет отображаться 302.
Пример-2: URL перенаправления навсегда
Создайте файл PHP со следующим кодом, который будет перенаправлять в новое место после ожидания в течение 2 секунд. Здесь функция die() используется для завершения скрипта. Здесь функция header() используется с тремя аргументами. TRUE, используется для второго аргумента и 301 используется для третьего аргумента. Код состояния 301 используется для постоянного перенаправления.
<?php
//Подождите 2 секунды
sleep(2);
//Перенаправление в конкретное место
header("Location: http://localhost/php/contactForm/index.html",TRUE,301);
die();
?>
Вывод:
После выполнения кода URL-адрес перенаправляется в адрес http: //localhost/php/contactForm/index.html через 2 секунды. Если вы проверите код и откроете вкладку «Сеть», то в качестве кода состояния отобразится 301, указывающий, что URL-адрес перемещен навсегда.
Пример-3: временный URL перенаправления
Создайте файл PHP со следующим кодом, который будет перенаправлять в новое место после ожидания в течение 2 секунд. Здесь функция die() используется для завершения скрипта. Здесь функция header() используется с тремя аргументами. TRUE, используется для второго аргумента и 307 используется для третьего аргумента. Код состояния 307 используется для временного перенаправления.
<?php
//Подождите 2 секунды
sleep(2);
//Перенаправление в конкретное место
header("Location: http://localhost/php/contactForm/index.html",TRUE,307);
die();
?>
Вывод:
После выполнения кода URL-адрес перенаправляется в адрес http: //localhost/php/contactForm/index.html через 2 секунды. Если вы проверите код и откроете вкладку «Сеть», то в качестве кода состояния отобразится 307, указывающий, что URL-адрес временно перенаправлен.
Пример-4: URL-адрес перенаправления на основе условия
Создайте файл PHP со следующим кодом, который будет перенаправлять URL-адрес на основе условного оператора. В сценарии создается HTML-форма для перенаправления URL-адреса на основе выбранного значения раскрывающегося списка. Здесь раскрывающийся список содержит три значения. Если в раскрывающемся списке выбрать Google, сценарий PHP перенаправит URL-адрес в адрес https://google.com с кодом состояния по умолчанию 302. Когда AndreyEx выбран в раскрывающемся списке, сценарий PHP перенаправит URL-адрес в расположение https://andreyex.ru с кодом состояния 301. Когда выбран WordPress из раскрывающегося списка, то скрипт PHP перенаправит URL-адрес в расположение https://andreyex.ru/blog-platforma-wordpress/ с кодом состояния 302.
<html>
<head>
<title>Пример заголовка</title>
</head>
<body>
<form method="post" action=#>
<select name="web">
<option>Google</option>
<option>AndreyEx</option>
<option>Wordpress</option>
</select>
<input type="submit" name="submit" value="Go" />
</html>
<?php
//Проверьте, нажата ли кнопка отправки или нет
if(isset($_POST["submit"]))
{
if($_POST['web'] == 'Google')
{
//Перенаправление в конкретное место
header("Location: https://google.com");
}
elseif($_POST['web'] == 'AndreyEx')
{
//Перенаправление в конкретное место
header("Location: https://andreyex.ru",TRUE,301);
}
else
{
//Перенаправление в конкретное место
header("Location: https://andreyex.ru/blog-platforma-wordpress/");
}
die();
}
?>
После выполнения кода в браузере появится следующий вывод, который отобразит раскрывающийся список с тремя значениями и кнопкой «Перейти». Код состояния сейчас 200. После перенаправления код статуса будет изменен.
Если Google выберет вариант из раскрывающегося списка, то после нажатия кнопки «Перейти» он перенаправит вас в адрес https://google.com, и появится следующее изображение. Здесь генерируется код состояния по умолчанию 302.
Если AndreyEx выберет из раскрывающегося списка, то после нажатия кнопки «Go» он будет перенаправлен в адрес https://andreyex.ru, и появится следующее изображение. Здесь генерируется постоянный код статуса 301.
Вывод:
Различные варианты использования функции PHP header() объясняются в этой статьи на нескольких примерах. Перенаправление может быть выполнено временно и постоянно на основе кода состояния, используемого в функции header(). Эта статья поможет читателям узнать больше о цели перенаправления и применить ее, используя скрипт PHP в своем веб-приложении, когда это необходимо.
2020-12-02T18:56:48
Python
Сравнение серверов HPE и Dell. Оценка плюсов и минусов
В этой статье мы рассмотрим серверы HPE и Dell, а также сравним и сопоставим некоторые из различных функций и качеств, которые сотрудник по закупкам, системный администратор или менеджер центра обработки данных могут учитывать при принятии решения.
Если вы находитесь на рынке для обновления своих серверов, убедитесь, что вы планируете соответствующим образом, чтобы вы могли оптимально продавать свои серверы и другие компоненты, такие как оперативная память, диски и процессоры.
Оперативные поставки серверного оборудования, https://www.hp-pro.net/ является системным интегратором, который выполняет полный комплекс услуг, необходимый для реализации проектов любого масштаба.
Серверы HPE против Dell: 4 основных фактора
Поддержка
Dell
Dell не требует платной программы поддержки для загрузки каких-либо обновлений или встроенного программного обеспечения, а также предоставляет чрезвычайно интуитивно понятный сайт для поиска обновлений для ваших систем.
Кроме того, Dell Prosupport рассматривается в ИТ-сфере как одна из наиболее надежных и полезных программ поддержки. Если вы можете себе это позволить, профессиональная поддержка — это стоящая инвестиция. Тем не менее, ходят слухи, что Dell скоро потребует контакта со службой поддержки для загрузки в будущем, хотя пока ничего конкретного не всплыло.
HPE
HPE требует, чтобы у вас был контракт на обслуживание/поддержку для загрузки любого нового микропрограммного обеспечения или обновлений. Субъективно, это может быть трудно найти драйверы поддержки и прошивки через платформу HP, даже если вы это сделаете.
Веб-сайт HPE также довольно трудно использовать для получения какой-либо информации или поддержки в целом. Тем не менее, их документация чрезвычайно тщательна, и те, кто обладает ноу-хау, могут найти руководства по существу для любой части, которую вы можете себе представить. Поддержка HPE замены деталей и их цепочки поставок также улучшилась в последние годы.
Однако создание онлайн-учетной записи через веб-сайт HPE позволяет обеспечить обширную персонализацию. Пользователи могут обновить свой профиль с помощью конкретных портфолио, которые хроникуют каждую часть оборудования HPE, принадлежащего вашему бизнесу.
Кроме того, вы получите доступ к круглосуточной поддержке HPE, сможете управлять будущими заказами и использовать опыт службы оперативной поддержки HPE. Он утверждает ‘что » помогает управлять повседневными ИТ-операционными задачами, а также высвобождает ресурсы, чтобы помочь вашему бизнесу оставаться впереди конкурентов.”
В зависимости от уровня развития и опыта вашего бизнеса, возможно, стоит изучить все, что может предложить поддержка HPE. Тем не менее, навигация и общий пользовательский опыт по-прежнему ошеломляют.
Победитель: Dell
Надежность
Dell
Нередко можно услышать, что серверы Dell работают без единой поломки в течение многих лет. Dell EMC очень бдительна в том, что касается постоянного совершенствования своих серверов, и более поздние линии обычно подтверждают этот факт.
HPE
Согласно опросу, проведенному в середине 2017 года, у HP proliants было примерно в 2,5 раза больше простоев, чем у серверов dell poweredge. Тем не менее, системы HPE хорошо справляются с прогнозными предупреждениями для деталей, которые могут выйти из строя. Это позволяет предприятию ремонтировать или заменять детали до того, как они испортятся.
Кроме того, линия superdome от HPE продемонстрировала невероятную надежность. Таким образом, для критически важных рабочих нагрузок больших данных решение HPE действительно кажется надежным.
Линейка Apollo от HPE и более новые proliants, скорее всего, слишком новы для пользователей, чтобы определить долгосрочную надежность, поэтому имейте это в виду, когда сравниваете серверы HPE и Dell.
Победитель: Dell
Цена
Dell
Большинство пользователей сообщают о меньшей гибкости цен при переговорах с Dell, хотя с более крупными и последовательными клиентами они обычно готовы сократить большую часть сделки. В прошлые годы dell была более доступной, но в наши дни разница в ценах гораздо менее очевидна.
Обычно дешевле. По этой причине, как правило, это выбор для консультантов, которые пытаются сохранить свои материальные затраты низкими, чтобы увеличить прибыль. Он широко доступен по различным каналам. Там его много, так что подержанные и запасные части относительно легко найти. Он выигрывает от того, что является самореферентным. Dell дешевле, потому что все ею пользуются. Все пользуются им, потому что это дешевле. Dell — это бизнес-класс.
HPE
HPE обычно более гибок в цене, хотя начальные котировки в большинстве случаев аналогичны Dell. В большинстве случаев ваши отношения с продавцом будут более важным фактором.
В среднем чуть дороже. Как правило, это выбор более крупных консультационных магазинов, где долгосрочная стабильность является более важной целью по сравнению с затратами. Он поддерживается по всему миру через ряд каналов. Там также есть много использованного оборудования HPE. Запчасти и запчасти легко найти. HPE имеет за собой более полную систему документации. Я могу найти руководства по каждой неясной детали, которую когда-либо делала HPE. HPE — это корпоративный класс.
Победитель: Это зависит от вашего бизнеса
Инструменты управления
Что касается систем Внеполосного управления, то инструментом управления HPE является iLO, а Dell EMC-iDRAC. Обе системы значительно продвинулись вперед, чтобы обеспечить аналогичные функции, такие как поддержка HTML5.
В прошлые годы были некоторые резкие различия, но в наши дни реализации IPMI не контрастируют достаточно, чтобы быть существенным решающим фактором. Тем не менее, есть несколько отличий.
Dell
Идрак прошел долгий путь за последние поколения. Вам больше не нужно использовать java после iDRAC 7, что приятно, хотя графический пользовательский интерфейс не так хорош, как новый графический интерфейс iLO.
Что касается лицензирования, iDRAC использует физическую лицензию, которую можно купить на вторичном рынке и предотвратить повторную блокировку с OEM-производителем после окончания срока службы.
Обновления, как правило, немного длиннее с iDrac, и в целом он кажется немного более вялым, чем iLO. Что касается предыдущей точки зрения, то iDRAC действительно имеет аналогичный инструмент для RIS, называемый OpenManage Essentials, хотя оба имеют свои проблемы в некоторых версиях браузера.
HPE
Стандарт ILO включен, но Advanced (т. е. post console session) требует лицензии, которая может заблокировать вас с OEM, если ваши серверы перейдут на EOL; вы не можете купить их на подержанном рынке.
Некоторые пользователи будут утверждать, что вам нужно купить только один ключ, потому что вы можете повторно использовать расширенный ключ на нескольких серверах, но это противоречит условиям предоставления услуг; вам действительно нужно купить новые ключи, как и в случае iDRAC.
В целом графический интерфейс с ILO кажется более интуитивно понятным, а платформа-немного более быстрой, но есть более важные вещи, которые следует учитывать, чем внешний интерфейс управления.
Победитель: HPE
Финальная битва
В конце концов, HPE и Dell — это довольно похожие компании с похожими предложениями, и поэтому при сравнении серверов HPE и dell нет четкого победителя. Между компаниями нет большой разницы в качестве сборки, цене или надежности, поэтому их лучше всего оценивать в каждом конкретном случае.
Однако эффективная поддержка Dell и незначительные различия делают Dell нашим выбором поставщика серверов при оценке серверов HPE vs dell. Тем не менее, почти во всех случаях они предоставляют сопоставимое оборудование и услуги, поэтому компании всегда должны проводить свою должную проверку и оценивать свои варианты в каждом конкретном случае.
2020-12-02T15:58:40
Сервер
MikroTik – базовая настройка.
Эта базовая настройка используется в некоторых других описаниях MikroTik на сайте PC360. Чтоб каждый раз не повторять описание, решено вынести его на отдельную страницу.
Альтернативный вариант – использовать настройки по умолчанию (Default setings).
Еще один альтернативный вариант – быстрая настрйка из меню Quick Set – в конце страницы под спойлером.
Освоить MikroTik Вы можете с помощью онлайн-куса
«Настройка оборудования MikroTik». Курс содержит все темы, которые изучаются на официальном курсе MTCNA. Автор курса – официальный тренер MikroTik. Подходит и тем, кто уже давно работает с микротиками, и тем, кто еще их не держал в руках. В курс входит 162 видеоурока, 45 лабораторных работ, вопросы для самопроверки и конспект.

Настройки протестированы на двух доступных моделях MikroTik: Rb750Gr3 и 951Ui 2HnD и так же подойдут для многих других моделей из-за единой операционной системы всех роутеров MikroTik – RouterOS.
Настройка выполняется из ПК с ОС Windows10. Роутер и ПК соединены прямым патч-кордом. ПК подключен в пятый порт роутера. Настройка IP-адреса сетевого адаптера ПК автоматическая (по DHCP). Специально вводить стандартный для микротиков IP-адрес 192.168.88.xxx не требуется.
Назначение портов:
ether1 – для внешней сети (Интернет);
ether2 – для внутренней сети;
ether3 – для внутренней сети;
ether4 – для внутренней сети;
ether5 – для внутренней сети.
Перед выполнением настроек, рекомендуется обновить прошивку.
Все настройки выполняются через спец. ПО для Windows от разработчика — WinBox. Скачать его можно с официального сайта.
О других способах подключения к роутерам MikroTik тут
Выполнение каждой настройки представлено в графическом интерфейсе и в виде текстовой команды для терминала.
Чтоб ввести текстовую команду, в боковом меню RouterOS микротика нужно выбрать New Terminal и в открывшейся командной строке ввести команду.

Содержание.
1.Подключение через WinBox.
2.Сброс конфигурации.
3.Создание моста (bridge).
4.Добавление портов в мост.
5.Назначение IP-адрес для моста локальной сети.
6.DHCP сервер.
7.Получение внешнего IP-адреса.
8.DNS.
9.Создание правила NAT для доступа в Интернет.
10.Для роутеров с wi—fi активация точки доступа.
11.Правила фильтрации в Firewall.
12.Создание новой учетной записи администратора.
13.Удаление учетной записи admin.
14.Интерфейсы доступа.
15.Настройка даты и время.
16.Идентификатор роутера.
17.Резервная копия конфигурации.
18.Сброс в заводские настройки.
19.Настройка электронной почты.
20.Список команд – базовая настройка.
21.Настройка через Quick Set.
22.Настройка через файл скрипта.
23.Дополнительные полезности.
1.Запускаем WinBox.
2.Нажимаем на вкладку Neighbors.
3 Кликаем на MAC-адрес нужного роутера.
4.Вводим логин-пароль (базовый логин admin, пароля нет).
5.Нажимаем кнопку «Connect».

1.Нажимаем System в боковом меню.
2.Из выпадающего меню выбираем пунк Reset Configuration.
3.В открывшемся окне отмечаем галочкой No Dafault Configuration (для сброса дефолтной конфигурации).
4.Нажимаем кнопку Reset Configuration. 
Через командную строку терминала:
|
1
| /system reset—configuration no—defaults=yes |
!!!Удаляя базовые настройки, удалятся параметры безопасности. Если роутер будет работать шлюзом в интернет необходимо настроить интерфейсы доступа, учетные записи, фильтры firewall и прочие настройки безопасности.
Переподключаемся.
Мост нужен для организации коммутатора локальной сети.
1.В боковом меню выбираем Bridge.
2.В открывшемся окне нажимаем синий крест (плюс).
3.В окне New Interface нажимаем ОК (в настройках моста ничего не меняем). 
Через командную строку терминала:
|
1
| /interface bridge add name=bridge1 |
Добавляем в мост по очереди порты ether2-4.
1.В окне Bridge выбираем вкладку Ports.
2.Нажимаем синий крест (плюс).
3.В открывшемся окне New Bridge Port указываем интерфейс Interface: ether2
— проверяем строку Bridge: bridge1 (созданный ранее мост)
4.Нажимаем кнопку «ОК».
Другие настройки не изменяем.
Выполняем эти действия для четырех портов(ether2, ether3, ether4, ether5). 
В итоге получится 4 порта в мосте, как на картинке ниже.

Произойдет дисконект. Подключаемся в роутер еще раз.
Через командную строку терминала:
|
1 2 3 4
| /interface bridge port add bridge=bridge1 interface=ether2 hw=yes /interface bridge port add bridge=bridge1 interface=ether3 hw=yes /interface bridge port add bridge=bridge1 interface=ether4 hw=yes /interface bridge port add bridge=bridge1 interface=ether5 hw=yes |
* Hardware Offload доступно начиная с прошивки 6.41. Активация этой настройки включает использование switch-чипа для передачи информации на втором уровне модели OSI через мост. Если hw отключено, то обработка информации осуществляется средствами RouterOS. Если прошивка роутера ниже 6.41, или в устройстве отсутствует нужный чип, то из строк команд надо убрать hw=yes. Поддерживаемые устройства.
Для роутера с wi-fi можно добавить интерфейс wlan в bridge.
Через командную строку терминала:
|
1
| /interface bridge port add bridge=bridge1 interface=wlan1 |
5.Назначение IP-адрес для моста локальной сети.
1.В боковом меню выбираем IP.
2.В раскрывшемся меню выбираем Addresses.
3.В открывшемся окне Adress List нажимаем синий крест (плюс).
В открывшемся окне New Address вводим параметры:
4.Address: 192.168.100.1/24 (/24 – это маска 255.255.255.0);
-Network: — вводить не надо, появится автоматически;
5.Interface: bridge1
6.Нажимаем кнопку «ОК».

В окне Adress List можно увидеть назначенный адрес.
Через командную строку терминала:
|
1
| /ip address add interface=bridge1 address=192.168.100.1/24 |
Указание сети для работы DHCP.
1.В боковом меню выбираем IP.
2.В раскрывшемся меню выбираем DHCP Server.
3.Переходим на вкладку Networks.
4.Нажимае синий крест (плюс).
В открывшемся окне DHCP Network вводим параметры:
5.Address: 192.168.100.0/24
6.Gateway: 192.168.100.1
7.Нажимаем кнопку «ОК».
Другие настройки не изменяем.

Сеть появится в списке. 
Через командную строку терминала:
|
1
| /ip dhcp—server network add address=192.168.100.0/24 gateway=192.168.100.1 |
Создание пула адресов для работы DHCP.
1.В боковом меню выбираем IP.
2.В раскрывшемся меню выбираем Pool.
3.В открывшемся окне IP Pool нажимаем синий крест (плюс).
В открывшемся окне NEW IP Pool вводим параметры:
4.Name: POOL1
5.Addresses: 192.168.100.10-192.168.100.254
6.Нажимаем кнопку «ОК».
Другие настройки не изменяем.

Через командную строку терминала:
|
1
| /ip pool add name=POOL1 ranges=192.168.100.10—192.168.100.254 |
Создание DHCP сервера.
1.В боковом меню выбираем IP.
2.В раскрывшемся меню выбираем DHCP Server.
3.На вкладке DHCP нажимае синий крест (плюс).
В открывшемся окне DHCP Server вводим параметры:
4.Name: dhcp1
5.Interface: bridge1
6.Address Pool: POOL1
7.Нажимаем кнопку «ОК».
Другие настройки не изменяем.

Созданный DHCP сервер. 
Через командную строку терминала:
|
1
| /ip dhcp—server add interface=bridge1 address—pool=POOL1 disabled=no |
7.Получение внешнего IP-адреса.
DHCP Client.
1.В боковом меню выбираем IP.
2.В раскрывшемся меню выбираем DHCP Client.
3.Переходим на вкладку DHCP Client.
4.Нажимаем синий крест (плюс).
В открывшемся окне New DHCP Client вводим параметры:
5.Interface: ether1
6.Нажимаем кнопку «ОК».
Другие настройки не изменяем.

Можно добавить описание, нажав кнопку Comment. Коментарии к настройкам лучше писать латинскими буквами.
Полученный IP адрес отобразится в списке. 
Через командную строку терминала:
|
1
| /ip dhcp—client add interface=ether1 disabled=no |
СПОЙЛЕР Статический внешний IP-адрес.
IP-адрес, маску, шлюз и DNS должен предоставить провайдер.
1.В боковом меню выбираем IP.
2.В раскрывшемся меню выбираем Addresses.
3.В окнеAdress List нажимаем синий крест (плюс).
В открывшемся окне New Address вводим параметры:
4.Address: 192.168.0.2/24 (внешний IP-адрес и маска от провайдера)
5.Network: 192.168.0.0 (сеть провайдера)
6.Interface: ether1 (порт внешнего интерфейса)
7.Нажимаем кнопку «ОК».

Через командную строку терминала:
|
1
| /ip address add address=192.168.0.2/24 network=192.168.0.0 interface=ether1 |
В списке адресов появится новый адрес внешней сети. 
Добавим шлюз (Gateway). Он указывается в списке статических маршрутов. 
Через командную строку терминала:
|
1
| /ip route add gateway=192.168.0.1 distance=1 comment=GATEWAY |

Интернет появится после указания DNS и NAT.
СПОЙЛЕР PPPoE.
IP-адрес, маску, шлюз и DNS должен предоставить провайдер. В некоторых случаях возможно автоматическое получение этих параметров.
1.В боковом меню выбираем Interfaces.
2.В открывшемся окне Interface List на вкладке Interface нажимаем на маленький треугольник в кнопке синего креста.
3.В выпадающем меню выбираем пункт PPPoE Client. 
4.В открывшемся окне переходим на вкладку General.
5.Вводим Name: ByFly (любое понятное имя).
6.Указываем Interface: ether1 (интерфейс внешней сети). 
7.Переходим на вкладку Dial Out.
8.Вводим пользователя User: 1234567891011121@beltel.by (из договора с провайдером)
9.Вводим пароль Password: 11111 (из договора с провайдером)
10.Отмечаем галочкой Use Peer DNS.
11.Отмечаем галочкой Add Default Route.
12.Нажимаем кнопку ОК. 
В списке появится новый интерфейс. 
Через командную строку терминала:
|
1
| /interface pppoe—client add name=ByFly interface=ether1 user=1234567891011121@beltel.by password=11111 use—peer—dns=yes add—default—route=yes disabled=no |
Интернет появится после указания DNS и NAT.
Статически DNS.
1.В боковом меню выбираем IP.
2.В раскрывшемся меню выбираем DNS.
3.В окне DNS Settings указываем Servers: 192.168.0.1
(можно указать DNS вышестоящего роутера провайдера, или гугла или еще какой-нибудь)
4.Отмечаем галочкой Allow Remote Requests.
5.Нажимаем кнопку ОК. 
Через командную строку терминала:
|
1
| /ip dns set servers=192.168.0.1 allow—remote—requests=yes |
Автоматическое получение DNS.
При получении внешнего IP-адреса по DHCP, DNS настроится автоматически. Проверить это можно в меню IP >> DNS.

9.Создание правила NAT для доступа в Интернет.
NAT (Network Address Translation) выполняет замену IP-адресов локальной сети на IP-адрес внешней сети и обратно.
1.В боковом меню выбираем IP.
2.В раскрывшемся меню выбираем Firewall.
3.В открывшемся окне Firewall переходим на вкладку NAT.
4.Добавляем правило нажав синий крест (плюс).
В открывшемся окне NAT Rule вводим параметры:
На вкладке General:
5.Chain: srcnat
6.Out.Interface: ether1
7.Нажимаем кнопку «Apply».
8.Переходим на вкладку Action.

На вкладке Action:
9.Action: masquerade
10.Нажимаем кнопку «ОК».
Другие настройки не изменяем. 
В списке правил NAT появится новое правило.

Через командную строку терминала:
|
1
| /ip firewall nat add action=masquerade chain=srcnat out—interface=ether1 |
После создания этого правила должен заработать Интернет.
10.Для роутеров с wi—fi активация точки доступа.
1.В боковом меню выбираем пункт Wireless.
2.В открывшемся окне Wireless Tables на вкладке Interfaces присутствует строчка неактивного профиля wlan1. Нажимаем на нее мышкой один раз.
3.Нажимаем синию галочку на панели выше для активации профиля.
4.Нажимаем дважды на строчку профиля wlan1и в открывшемся окне Interface wlan1 переходим на вкладку Wireless.
5.Указываем режим Mode: ap bridge
6.SSID: wi-fi PC360 (любое удобное имя латиницей для названия точки wi-fi)
7.Нажимаем кнопку «ОК» для сохранения настроек.

8.В окне Wireless Tables переходим на вкладку Security Profiles.
9.Дважды кликаем на профиль с названием default.
В открывшемся окне Security Profile выполняем настройки:
10.Mode: dynamic keys;
11.Authentication Types: отмечаем WPA PSK и WPA2 PSK;
12.Указываем пароли для:
WPA Pre-Shared Key: Password12345 (латинские цифры и буквы)
WPA2 PrShared Key: Password12345 (латинские цифры и буквы)
13. Нажимаем кнопку «ОК» для сохранения настроек. 
Через командную строку терминала:
|
1 2
| /interface wireless set [ find default—name=wlan1 ] mode=ap—bridge band=2ghz—b/g/n channel—width=20/40mhz—Ce distance=indoors frequency=auto ssid=«Wi-fi PC360» wireless—protocol=802.11 disabled=no /interface wireless security—profiles set [ find default=yes ] authentication—types=wpa—psk,wpa2—psk eap—methods=«» mode=dynamic—keys supplicant—identity=MikroTik wpa—pre—shared—key=Password12345 wpa2—pre—shared—key= Password12345 |
Точка wi-fi начнет работать.
Включаем wi-fi в Windows10, нажав на значок сети в нижнем правом углу рабочего стола и активируем беспроводную сеть. Выбираем из списка созданную точку. Подключаемся, введя созданный ранее пароль.

11.Правила фильтрации в Firewall.
Правила необходимы для контроля трафика между внешней и внутренней сетями, а так же для ограничения нежелательного доступа в роутер.
Все правила с разным содержанием, но с одинаковым принципом добавления.
Для добавления любого правила в графическом интерфейсе нужно выполнить последовательность действий.
1.В боковом меню выбираем пункт IP.
2.В выпадающем меню выбираем Firewall.
3.В открывшемся окне переходим на вкладку Filter Rules.
4.Нажимаем синий крест (плюс).
5.В открывшемся окне вводим настройки, для каждого правила и назначения разные.

6.Переходим на вкладку «Action».
7.Указываем вид действия в поле «Action» (разное для разных правил).
8.Нажимаем кнопку «ОК» для сохранения правила. 
Добавить к правилу описание или коvментарий можно нажав кнопку «Comment».
Часто в правилах нужно указывать статус соединения для проверяемых пакетов. Сделать это можно в нижней части вкладки General. 
Для удаления правила нужно выбрать правило и нажать минус на вкладке Filter Rules. 
Ниже представлены правила, которые MikroTik предлагает в дефолтной настройке. 
Из этих правил убраны 3шт., правила №5,6 (ipsec) и 7 (fasttrack). Остальные вполне подходят для базовой настройки роутера.
Все правила представлены в виде текстовых команд для компактности.
Правила входящего (input) в роутер трафика.
1.Правило разрешает входящие пакеты от установленных и связанных (с ранее разрешенными) соединений.
|
1
| /ip firewall filter add action=accept chain=input connection—state=established,related comment=«RULE 1 accept established,related» |
2.Правило отбрасывает неверные пакеты входящего трафика.
|
1
| /ip firewall filter add action=drop chain=input connection—state=invalid comment=» RULE 2 drop invalid» |
3.Правило разрешает трафик ICMP протокола. Используется для Ping, Traceroute.
|
1
| /ip firewall filter add action=accept chain=input protocol=icmp comment=» RULE 3 accept ICMP» |
*для запрета пинга из внешней сети в поле action нужно указать drop
4.Правило отбрасывает весь трафик, который идет не от интерфейсов локальной сети.
|
1
| /ip firewall filter add action=drop chain=input in—interface=!bridge1 comment=» RULE 4 drop all not coming from LAN» |
Правила транзитного (forward) трафика.
5.Правило разрешает проходящий трафик для пакетов в соединениях established, related, untracked
|
1
| /ip firewall filter add action=accept chain=forward connection—state=established,related,untracked comment=» RULE 5 accept established,related, untracked» |
6.Правило отбрасывает неверные пакеты проходящего трафика.
|
1
| /ip firewall filter add action=drop chain=forward connection—state=invalid comment=» RULE 6 drop invalid» |
7.Правило отбрасывает проходной трафик из внешней сети не относящийся к NAT.
|
1
| /ip firewall filter add action=drop chain=forward connection—nat—state=!dstnat connection—state=new in—interface=ether1 comment=» RULE 7 drop all from WAN not DSTNATed» |
В самой нижней строке нужно разместить правило, запрещающее все прочее по входу роутера.
|
1
| /ip firewall filter add action=drop chain=input in—interface=ether1 comment=«FINAL RULE drop all input» |
Внимание! Если в роутере используется не только базовая настройка, а например VPN или какие-то другие внешние подключения, их необходимо указать в правилах выше последнего. Иначе неуказанные подключения перестанут работать.
При удаленной настройке роутера нужно сперва нажать кнопку Safe Mode.

Если какое-то правило отключит удаленный доступ, то при нажатой кнопке Safe Mode через 9 мин.(TCP timeout) произойдет отмена всех введенных настроек и можно снова подключаться.
12.Создание новой учетной записи администратора.
1.В боковом меню выбираем пункт System.
2.В выпадающем меню выбираем Users.
3.В открывшемся окне переходим на вкладку Users и нажимаем синий крест (плюс).
В открывшемся окне вводим:
4.Name: Kalsarikännit (имя для нового администратора, не использовать admin1 admin..xx, user1 user..xx и т.п.)
5.Group: full (все разрешено)
6.Password: Kfqnfvjhrtyyf!@# (новый сложный пароль)
Confirm Password: Kfqnfvjhrtyyf!@# (подтверждаем новый пароль)
(пароль должен быть с буквами и цифрами разного регистра и спец. символами)
7.Нажимаем кнопку OK.

Через командную строку терминала:
|
1
| /user add name=Kalsarikannit password=Kfqnfvjhrtyyf!@# group=full |
13.Удаление учетной записи admin.
1.В боковом меню выбираем пункт System.
2.В выпадающем меню выбираем Users.
3.Отмечаем нужного пользователя (в данном случае admin).
4.Нажимаем красный минус.

Через командную строку терминала:
|
1
| /user remove admin |
Интерфейсы доступа в MikroTik необходимо заблокировать в целях безопасности.
1.В боковом меню выбираем пункт IP.
2.В выпадающем меню выбираем Services.
3.В открывшемся окне IP Service List выбираем нужный сервис.
4.Нажимаем красный крестик на верхней панели окна.
Выполняем эти действия для всех не используемых сервисов.

В данном случае оставлен доступ через WinBox. Все остальные сервисы заблокированы.
Через командную строку терминала:
|
1 2 3 4 5 6
| /ip service set telnet disabled=yes /ip service set ftp disabled=yes /ip service set www disabled=yes /ip service set ssh disabled=yes /ip service set api disabled=yes /ip service set api—ssl disabled=yes |
Способы подключения в MikroTik(Ссылка).
Вручную.
1.В боковом меню выбираем пункт System.
2.В выпадающем меню выбираем Clock.
3.Переходим на вкладку Time.
4.Выставляем актуальное время.
5.Выставляем актуальную дату.
6.Выставляем временную зону (в зависимости от расположения).
7.Нажимаем кнопку «ОК».

Через командную строку терминала:
|
1
| /system clock set time=12:05:00 date=dec/01/2020 time—zone—name=Europe/Minsk time—zone—autodetect=yes |
(месяца jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec)
Автоматически.
Указываем NTP сервер и часы будут синхронизироваться автоматически через Интернет. Сервера.
После нажатия кнопки Apply или OK режим поменяется на unicast, а вместо доменных имен появятся IP-адреса серверов. 
Можно проверить актуализацию времени в System >> Clock.
Установка NTP через командную строку терминала:
|
1
| /system ntp client set enabled=yes primary—ntp=88.147.254.230 secondary—ntp=88.147.254.232 |

Идентификатор так же отображается в WinBox при подключении к роутеру.
Через командную строку терминала:
|
1
| /system identity set name=PC360 Wi—fi Router |
17.Резервная копия конфигурации.
После выполнения всех настроек необходимо сделать резервную копию конфигурации.
1.В боковом меню выбираем пункт Files.
2.В открывшемся окне нажимаем кнопку Backup.
В открывшемся окне вводим:
3.Name: Config_1 (любое понятное имя латинскими буквами)
4.Don’t Encrypt: отмечаем галочкой
5.Нажимаем кнопку Backup.

Через командную строку терминала:
|
1
| /system backup save name=config1 |
Перетягиваем резервную копию в папку на компьютер для сохранения. 
Чтобы восстановит конфигурацию из резервной копии нужно выбрать резервную копию в списке и нажать кнопку Restore.
Каким-то любым удобным сбособом нужно отмечать какой логи-пароль относится к определенной резервной копии.
Были случаи на практике, когда после срочного восстановления конфигурации из резервной копии отсутстввали данные для авторизации. Приходилось сбрасывать роутер в заводские установки, подключаться под стандартным пользователем и выполнять настройки с самого начала.
18.Сброс в заводские настройки.
Если настройка не удалась и к меню роутера пропал доступ, можно выполнить сброс в заводские настройки кнопкой на корпусе. Как это сделать написано тут.
19.Настройка электронной почты.
20.Списки команд для терминала.
СПОЙЛЕР Список команд – базовая настройка (без wi—fi)
*нужно изменить логин-пароль, идентификатор, внешний IP-адрес по DHCP (для прошивок 6.41 и выше)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
| /interface bridge add name=bridge1 /interface bridge port add bridge=bridge1 interface=ether2 hw=yes /interface bridge port add bridge=bridge1 interface=ether3 hw=yes /interface bridge port add bridge=bridge1 interface=ether4 hw=yes /interface bridge port add bridge=bridge1 interface=ether5 hw=yes /ip address add interface=bridge1 address=192.168.100.1/24 /ip dhcp—server network add address=192.168.100.0/24 gateway=192.168.100.1 /ip pool add name=POOL1 ranges=192.168.100.10—192.168.100.254 /ip dhcp—server add interface=bridge1 address—pool=POOL1 disabled=no /ip dhcp—client add interface=ether1 disabled=no /ip firewall nat add action=masquerade chain=srcnat out—interface=ether1 /ip firewall filter add action=accept chain=input connection—state=established,related comment=«RULE 1 accept established,related» /ip firewall filter add action=drop chain=input connection—state=invalid comment=» RULE 2 drop invalid» /ip firewall filter add action=accept chain=input protocol=icmp comment=» RULE 3 accept ICMP» /ip firewall filter add action=drop chain=input in—interface=!bridge1 comment=» RULE 4 drop all not coming from LAN» /ip firewall filter add action=accept chain=forward connection—state=established,related,untracked comment=» RULE 5 accept established,related, untracked» /ip firewall filter add action=drop chain=forward connection—state=invalid comment=» RULE 6 drop invalid» /ip firewall filter add action=drop chain=forward connection—nat—state=!dstnat connection—state=new in—interface=ether1 comment=» RULE 7 drop all from WAN not DSTNATed» /ip firewall filter add action=drop chain=input in—interface=ether1 comment=«FINAL RULE drop all input» /user add name=Kalsarikannit password=Password12345 group=full /user remove admin /ip service set telnet disabled=yes /ip service set ftp disabled=yes /ip service set www disabled=yes /ip service set ssh disabled=yes /ip service set api disabled=yes /ip service set api—ssl disabled=yes /system ntp client set enabled=yes primary—ntp=88.147.254.230 secondary—ntp=88.147.254.232 /system identity set name=«PC360 Router» /system backup save name=config1 / |
СПОЙЛЕР Список команд – базовая настройка (с wi-fi)
*нужно изменить логин-пароль, идентификатор, внешний IP-адрес по DHCP
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
| /interface bridge add name=bridge1 /interface bridge port add bridge=bridge1 interface=ether2 hw=yes /interface bridge port add bridge=bridge1 interface=ether3 hw=yes /interface bridge port add bridge=bridge1 interface=ether4 hw=yes /interface bridge port add bridge=bridge1 interface=ether5 hw=yes /interface bridge port add bridge=bridge1 interface=wlan1 /ip address add interface=bridge1 address=192.168.100.1/24 /ip dhcp—server network add address=192.168.100.0/24 gateway=192.168.100.1 /ip pool add name=POOL1 ranges=192.168.100.10—192.168.100.254 /ip dhcp—server add interface=bridge1 address—pool=POOL1 disabled=no /ip dhcp—client add interface=ether1 disabled=no /interface wireless set [ find default—name=wlan1 ] mode=ap—bridge band=2ghz—b/g/n channel—width=20/40mhz—Ce distance=indoors frequency=auto ssid=«Wi-fi PC360» wireless—protocol=802.11 disabled=no /interface wireless security—profiles set [ find default=yes ] authentication—types=wpa—psk,wpa2—psk eap—methods=«» mode=dynamic—keys supplicant—identity=MikroTik wpa—pre—shared—key=Password12345 wpa2—pre—shared—key= Password12345 /ip firewall nat add action=masquerade chain=srcnat out—interface=ether1 /ip firewall filter add action=accept chain=input connection—state=established,related comment=«RULE 1 accept established,related» /ip firewall filter add action=drop chain=input connection—state=invalid comment=» RULE 2 drop invalid» /ip firewall filter add action=accept chain=input protocol=icmp comment=» RULE 3 accept ICMP» /ip firewall filter add action=drop chain=input in—interface=!bridge1 comment=» RULE 4 drop all not coming from LAN» /ip firewall filter add action=accept chain=forward connection—state=established,related,untracked comment=» RULE 5 accept established,related, untracked» /ip firewall filter add action=drop chain=forward connection—state=invalid comment=» RULE 6 drop invalid» /ip firewall filter add action=drop chain=forward connection—nat—state=!dstnat connection—state=new in—interface=ether1 comment=» RULE 7 drop all from WAN not DSTNATed» /ip firewall filter add action=drop chain=input in—interface=ether1 comment=«FINAL RULE drop all input» /user add name=Kalsarikannit password=Password12345 group=full /user remove admin /ip service set telnet disabled=yes /ip service set ftp disabled=yes /ip service set www disabled=yes /ip service set ssh disabled=yes /ip service set api disabled=yes /ip service set api—ssl disabled=yes /system ntp client set enabled=yes primary—ntp=88.147.254.230 secondary—ntp=88.147.254.232 /system identity set name=«PC360 Wi-fi Router» /system backup save name=config1 / |
СПОЙЛЕР Настройка через Quick Set для роутера с wi-fi.

22.Настройка через файл скрипта.
СПОЙЛЕР Настройка через файл скрипта
1.Первоначальная настройка выполняется через графический интерфейс или текстовые команды в терминале.
2.Настройка экспортируется в файл скрипта.
3.Файл скрипта применяется при настройке роутера.
Выполнение.
1.Первый пункт выполнены выше — роутер настроен.
2.Экспортируем файл с настройками.
Открываем New Terminal и вводим команду:
|
1
| /export file=config2.rsc |
(имя файла config2 может быть любое латинскими буквами, расширение .rsc)
Среди файлов появится экспортированный файл. 
3.Переходим в меню System >> Reset Configuration
В поле Run After Reset (Выполнить после сброса) указываем экспортированный файл скрипта.
Нажимаем кнопку «Reset Configuration». 
После сброса конфигурации и перезагрузки в настройках будет применена конфигурация из файла config2.rsc
Среди замеченных багов происходит сброс пользователя и пароль на стандартные admin-без пароля.
СПОЙЛЕР Дополнительные полезности.
Просмотр всех введенных настроек в терминале.
|
1
| /export compact |
Логирование.
Обо всех происходящих в роутере событиях можно узнать в логах. В боковом меню выбираем Log. 
Любой конкретно указанный лог можно отслеживать в терминале.
Переходим в меню System >> Logging
В открывшемся окне на вкладке Rules создаем новое правило.
В теме правила указываем событие, за которым хотим наблюдать, например system.
В поле Action выбираем echo.
Нажимаем ОК.

Теперь все события с тегом System отображаются в терминале.

Так же информацию о выбранном событии можно отправлять по email.
Нагрузка на процессор.
System >> Resources 
Какая из служб больше всего загружает процессор можно узнать в Tool >> Profile.
Нажимаем Start и в графе Usage видим использование ресурсов. 
Освоить MikroTik Вы можете с помощью онлайн-куса
«Настройка оборудования MikroTik». Курс содержит все темы, которые изучаются на официальном курсе MTCNA. Автор курса – официальный тренер MikroTik. Подходит и тем, кто уже давно работает с микротиками, и тем, кто еще их не держал в руках. В курс входит 162 видеоурока, 45 лабораторных работ, вопросы для самопроверки и конспект.
2020-12-02T13:52:42
Настройка ПО
MikroTik — отправка электронной почты по событию.
На этой странице рассмотрена настройка электронной почты и отправка сообщения через e-mail при неудачной попытке авторизации в роутер MIkroTik. Настройки протестированы для почтовых служб Яндекс и Гугл. Параметры серверов отправки для этих сервисов можно посмотреть на их сайтах соответственно. Настройка выполнялась на RouterOS v6.
Освоить MikroTik Вы можете с помощью онлайн-куса
«Настройка оборудования MikroTik». Курс содержит все темы, которые изучаются на официальном курсе MTCNA. Автор курса – официальный тренер MikroTik. Подходит и тем, кто уже давно работает с микротиками, и тем, кто еще их не держал в руках. В курс входит 162 видеоурока, 45 лабораторных работ, вопросы для самопроверки и конспект.
Подключаемся в роутер через WinBox.
Настройка электронной почты.
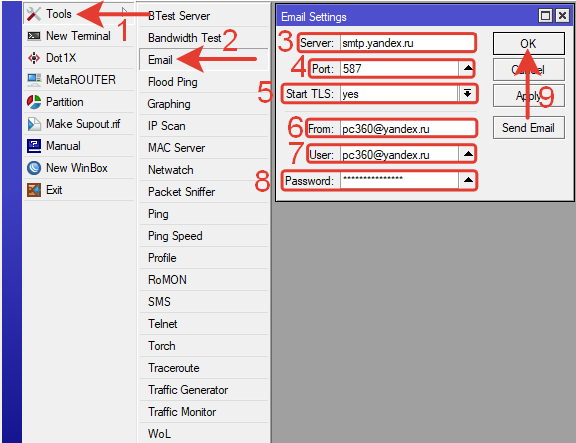
1.В боковом меню выбираем пункт Tools.
2.В выпадающем меню выбираем Email.
В открывшемся окне Email Settings вводим параметры:
3.Server: 77.88.21.158 (или smtp.yandex.ru сервер исходящей почты яндекс)
4.Port: 587
5.Start TLS: yes
6.From: эл.почта отправителя
7.User: почта@yandex.ru (пользователь=email)
8.Password: 12345Password (Пароль электронной почты)
9.Нажимаем кнопку ОК.
Через командную строку терминала:
|
1
| /tool e—mail set address=smtp.gmail.com port=587 start—tls=yes from=mail@yandex.ru user=mail@yandex.ru password=12345Password |
Просмотр статуса.
|
1
| /tool e—mail print |
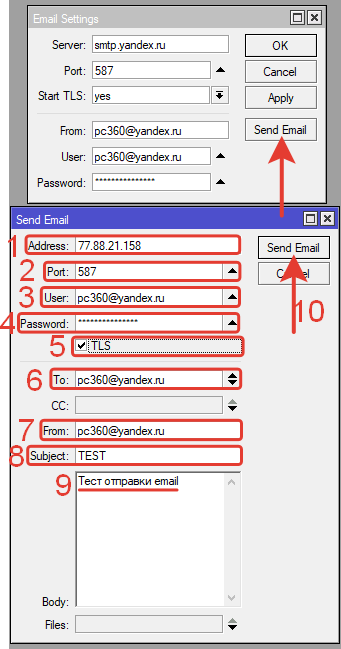
Для тестовой отправки электронного письма нажимаем кнопку Send Email в окне Email Settings.
В открывшемся окне Send Email вводим параметры:
1.Address: 77.88.21.158 (или smtp.yandex.ru сервер исходящей почты яндекс).
2.Port: 587;
3.User: почта@yandex.ru (пользователь=email).
4.Password: 12345Password (Пароль электронной почты).
5.TLS активировано.
6.To: эл.почта получателя письма.
7.From: эл.почта отправителя.
8.Subject: тема письма.
9.Содержание письма.
10.Нажимаем кнопку Send Email.
В случае если отправка не удалась и появилось сообщение об ощибке Couldn’t perform action – AUTH failed.
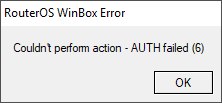
1.Проверяем правильность ввода данных (логин, пароль, сервер, порт, TLS)
2.Проверяем настройку в сервисе почты.
В почте Яндекс – Почтовые программы. 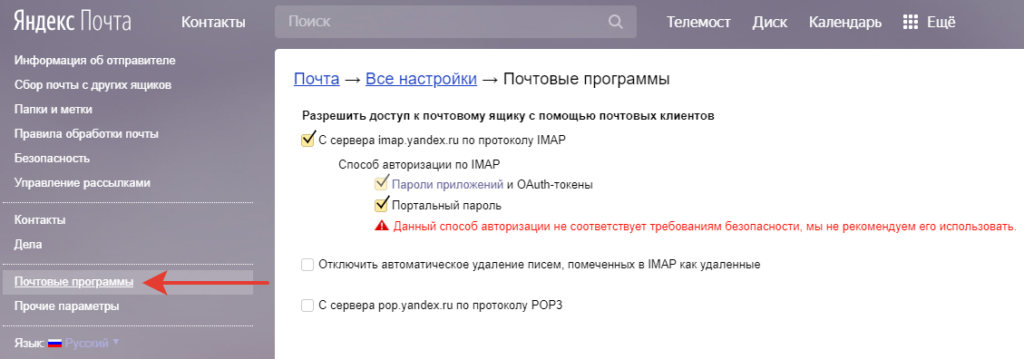
В аккаунте Гугл — настройка безопасности для надежного приложения. Надежные приложения. Если Выкл – включаем. 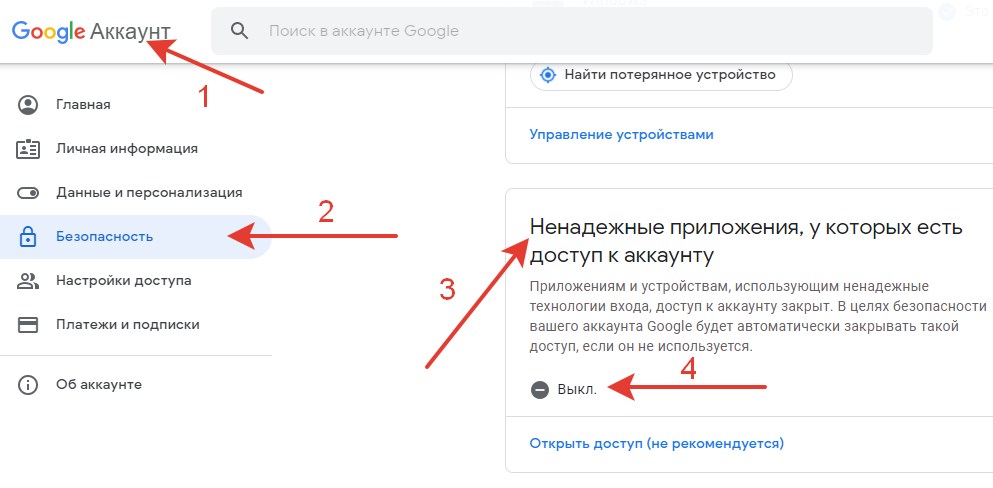
*при тестировании письмо одинаково успешно пришло в Гугл и Яндекс почту
Оповещение на e-mail о попытке подключения к роутеру.
В логе событие о неудачной попытке подключения обозначено system, error, critical.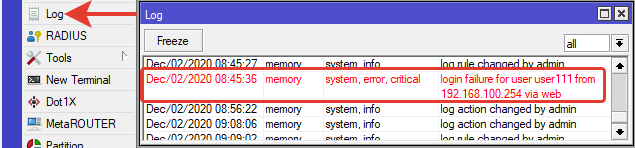
Настраиваем отправку эл.почты по этому событию.
1.В боковом меню выбираем пункт System.
2.В выпадающем меню выбираем Logging.
3.В открывшемся окне Logging переходим на вкладку Action.
4.Редактируем существующее правило или создаем новое нажав плюс.
В открывшемся окошке Log Action вводим параметры:
5.Name: email (любое понятное имя латинскими буквами).
6.Type: email (выбираем из выпадающего списка).
7.Email: почта@yandex.ru (электронная почта получателя)
8.Start TLS — активируем галочкой.
9.Нажимаем кнопку ОК.
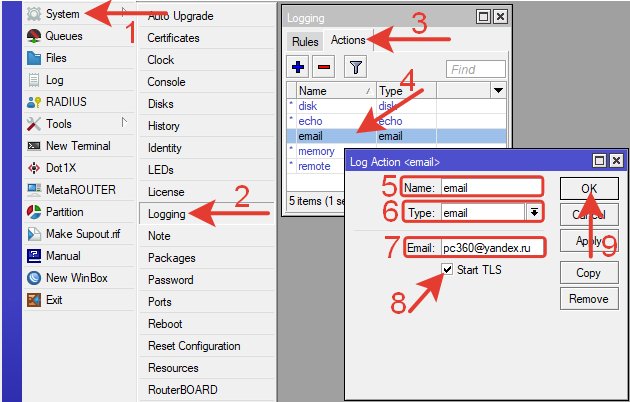
10.Переходим на вкладку Rules в окне Logging.
11.Нажимаем плюс для добовления нового правила.
В окне нового правила указываем:
12.Topics: error и critical (темы событий).
13.Action: email
14.Нажимаем кнопку ОК.
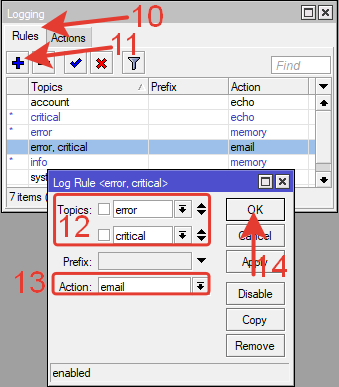
В Prefix можно добавить комментарий.
Через командную строку терминала:
|
1 2
| /system logging action add email—start—tls=yes email—to=mail@yandex.ru name=email target=email /system logging add action=email prefix=«WARNING» topics=error,critical |
Чтоб почту не засыпало бесконечным логом событий, сперва все то же самое лучше сделать с указанием вместо Action: email >> Action: echo
В этом случае оповещение будет приходить в терминал. 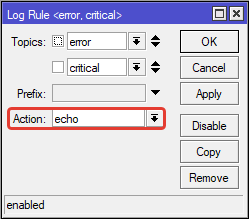
Ниже отображается неудачная попытка войти в роутер с неверной учетной записью. Запись об этом событии дублируется в Terminal через echo.

Если все устраивает, указываем email вместо echo.
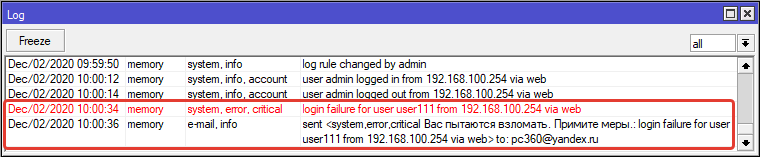
В логе видно, что после неудачной попытки подключения к роутеру было отправлено письмо на email. Вас пытаются взломать. Примите меры.
*у почты gmail возникает проблема авторизации при доставке, письмо не пришло, с почтой Яндекс всё ОК
Освоить MikroTik Вы можете с помощью онлайн-куса
«Настройка оборудования MikroTik». Курс содержит все темы, которые изучаются на официальном курсе MTCNA. Автор курса – официальный тренер MikroTik. Подходит и тем, кто уже давно работает с микротиками, и тем, кто еще их не держал в руках. В курс входит 162 видеоурока, 45 лабораторных работ, вопросы для самопроверки и конспект.
2020-12-02T10:57:21
Настройка ПО