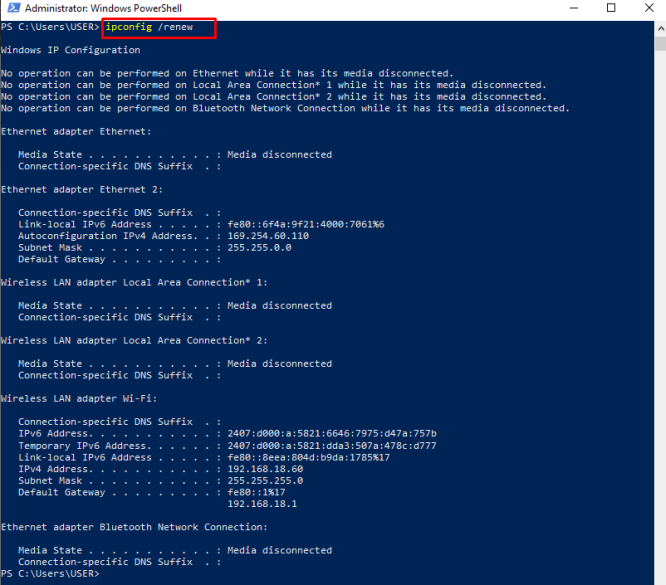
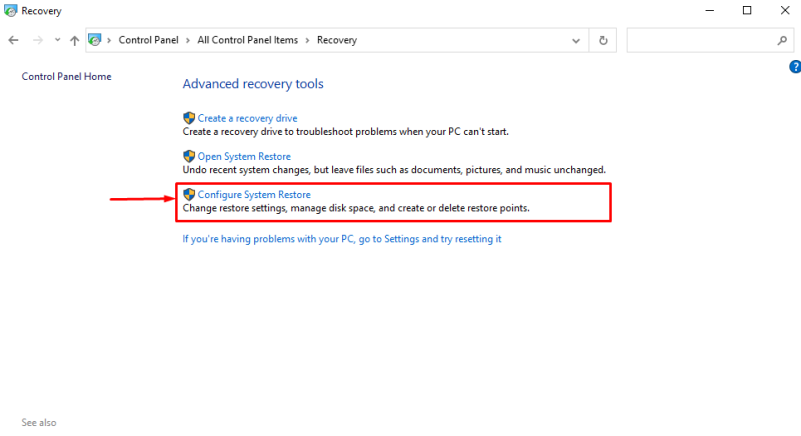
Вчера произошла одна из крупнейших утечек, которые мы когда-либо видели. Помимо основного анонса обновления Xbox Series X и дорожной карты для будущих консолей Xbox, просочившиеся документы также включали пятилетний прогноз руководства Zenimax.
Имейте в виду, что этим документам уже более трех лет, но, по крайней мере, у нас есть представление о том, чего ожидать от Bethesda и других зонтичных студий в ближайшем будущем. Прежде всего, среди списка неанонсированных игр, в работе находятся ремастеры The Elder Scrolls IV: Oblivion и Fallout 3.
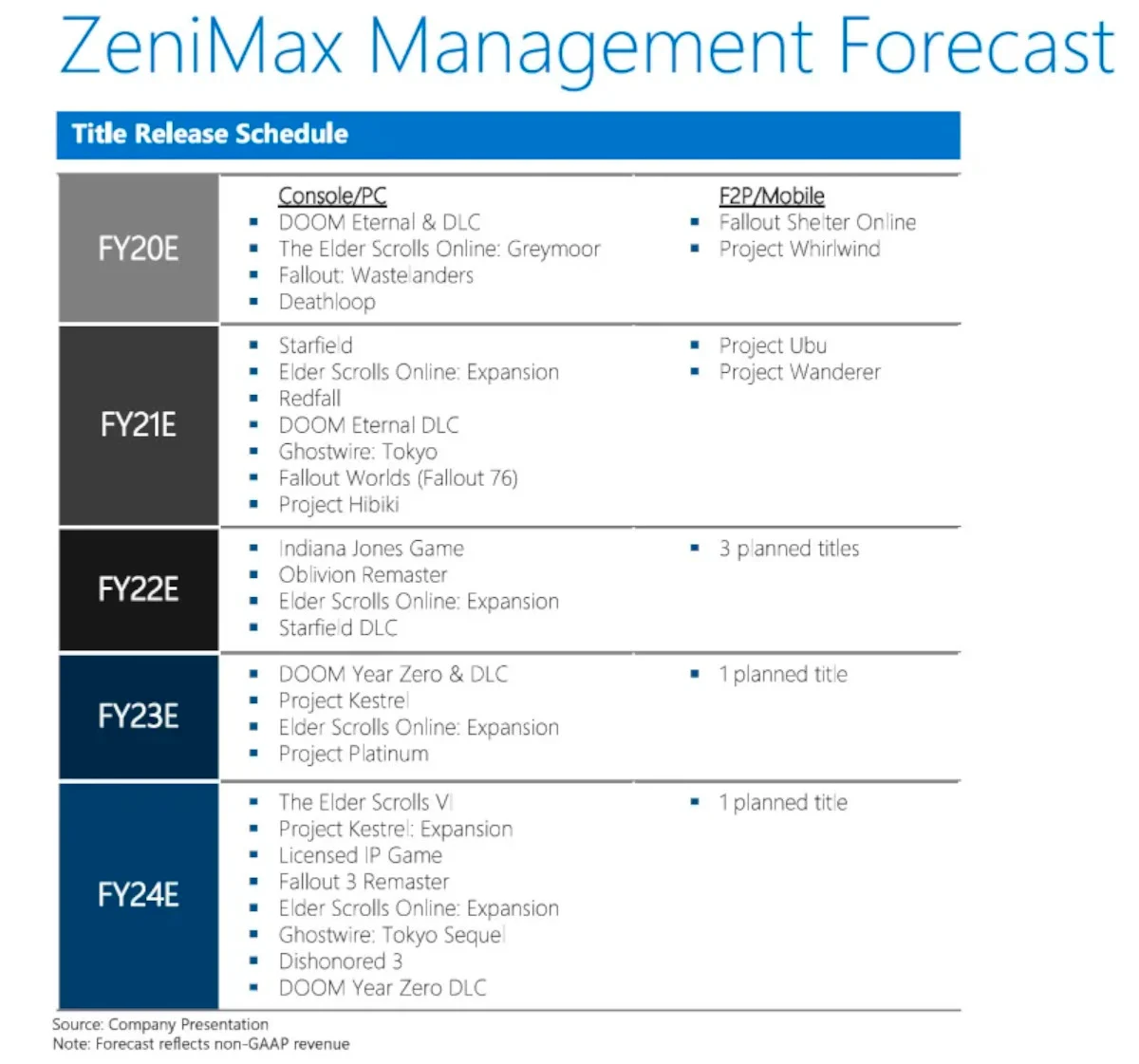
Предлагаемый прогноз был составлен до крупной покупки Microsoft ZeniMax за 7,5 миллиардов долларов еще в марте 2021 года, и с момента покупки мы теперь знаем, что Microsoft несколько нарушила первоначальный график, предоставив Bethesda больше времени для работы над Starfield. Генеральный директор Xbox Фил Спенсер уже несколько раз затрагивал эту тему в прошлом, и, несмотря на многочисленные задержки с выпуском игры, я думаю, можно с уверенностью сказать, что для Skyrim in Space от Bethesda все сложилось довольно хорошо.
Помимо этого, утечка также подтверждает удаленный пост на Reddit предполагаемого бывшего сотрудника Virtuos Games, стороннего разработчика из Парижа. По словам источника, ремастер Oblivion от Bethesda под кодовым названием Altar, наряду с рядом других нераскрытых проектов, в настоящее время разрабатывается командой, а Black Shamrock из Дублина помогает с оформлением.
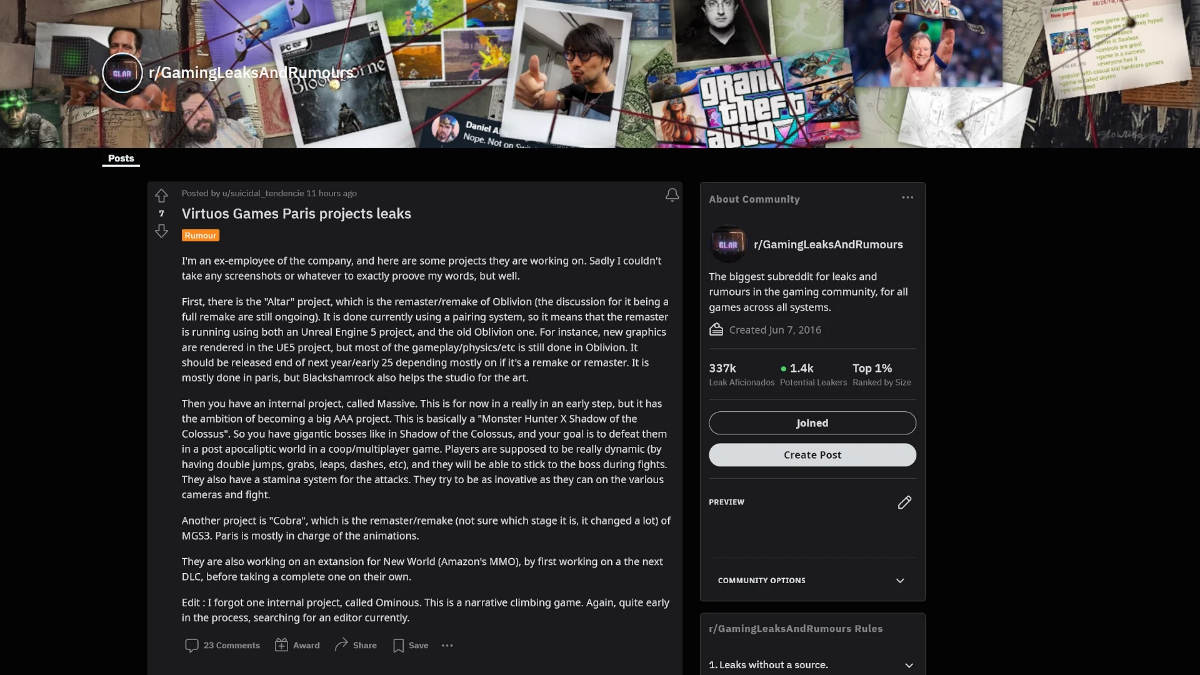
Еще один интересный момент из удаленного поста заключается в том, что игра в настоящее время разрабатывается с использованием «системы сопряжения», где оригинальный движок Gamebryo будет обрабатывать весь игровой процесс и рендеринг на основе физики, а Unreal Engine 5 позаботится о графике и визуальных эффектах.
Это имеет большой смысл, поскольку во многих ремейках и ремастерах этот метод использовался и раньше, включая ремейк Shadow of the Colossus Remake, выпущенный еще в 2018 году, а совсем недавно плохо принятый GTA: Trilogy и The Last of Us. Часть 1. Хм, интересно, что это значит для амбициозного переработанного мода Skyblivion, выпуск которого запланирован на 2025 год?
Двигаясь дальше, дорожная карта также включает в себя Elder Scrolls VI, хотя мы все знаем, что игра запланирована только на 2026 год, плюс в разработке находится ряд сиквелов, включая триквел Dishonored, продолжение Ghostwire: Tokyo, а также два нераскрытых проекта с дублированием. «Пустельга» и «Платина». В списке еще больше игр, в том числе игра об Индиане Джонсе, которая, по словам Тодда Ховарда, уже находится «на полпути» разработки, а также еще одна безымянная «лицензированная IP-игра», которая, как предполагают многие пользователи, может быть игрой по «Звездным войнам».
Как всегда, ко всей приведенной выше информации следует относиться с небольшой долей скептицизма, поскольку внутренняя разработка может быть изменена в кратчайшие сроки, а некоторые игры могут даже не увидеть свет. Тем не менее, по крайней мере, нам есть что передать от Bethesda в ближайшем будущем.