Vim — свободный текстовый редактор, созданный на основе более старого vi. Ныне это мощный текстовый редактор с полной свободой настройки и автоматизации. vim не похож ни на один другой редактор. Что в нем такого особенного и почему его стоит изучать. Зачем использовать vim. Философия и процесс изучения текстового редактора vim. Читать
Архив автора: admin
Dynamic Lighting: управляем подсветкой клавиатуры и мыши в Windows 11
Windows 11 получила встроенную функцию Dynamic Lighting, которая позволяет управлять RGB-подсветкой совместимых устройств (клавиатуры, мыши, контроллеры и другие LED-аксессуары) прямо из настроек Windows без необходимости использования фирменных утилит каждого производителя. В этой статье расскажем — как работает Dynamic Lighting, как узнать, поддерживает ли ваш девайс, и как настроить подсветку.
Руководство для начинающих по Nano, текстовый редактор командной строки Linux
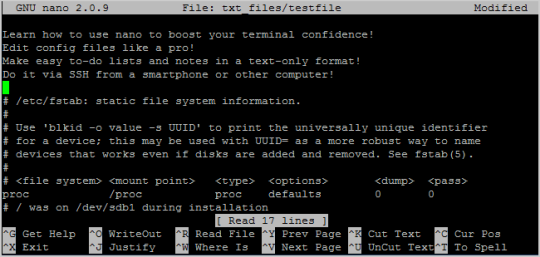
Новичок в командной строке Linux? Смущены всеми другими продвинутыми текстовыми редакторами? TutoryBird поддержат вас этим руководством к Nano, простому текстовому редактору, который очень удобен для новичков. Читать
Эта операция была прервана из-за ограничений, наложенных на данный компьютер — решение ошибки в Word
При попытке открыть или вставить гиперссылку в Microsoft Word вы можете столкнуться с сообщением:
«Эта операция была прервана из-за ограничений, наложенных на данный компьютер. Обратитесь к системному администратору».
Многие пользователи думают, что причина в самом Office, но на самом деле ошибка связана с настройками Windows. Чаще всего это происходит из-за того, что в системе сбились ассоциации программ по умолчанию для протоколов HTTP и HTTPS, либо были внесены изменения в реестр. Word просто не знает, каким браузером открыть ссылку. Читать
🐧 3 способа использования SSH в Windows для входа на сервер Linux
Что такое SSH?
SSH означает Secure Shell – протокол, который был изобретен в 1995 году для замены небезопасного Telnet (телекоммуникационная сеть).
Теперь системный администратор является основным способом безопасного входа на удаленные серверы Linux через общедоступный Интернет. Читать
Перенос проекта GIT на другой сервер
В данной инструкции мы рассмотрим несколько примеров, как можно выполнить перенос со всеми настройками git-проекта в другой git-репозиторий. Предполагается, что у нас уже подготовлен новый репозиторий, куда нужно отправить проект, а также у нас есть представление о работе с командой git. В конце инструкции приведены соответствующие ссылки. Читать