Инструменты управления ИИ — это программное обеспечение или платформы, которые помогают организациям управлять и регулировать разработку, развертывание и использование систем искусственного интеллекта (ИИ). Поддерживая дисциплинированное управление ИИ, эти инструменты предоставляют функции, которые помогают организациям внедрять этичные и ответственные методы управления ИИ, а также создают конкурентные преимущества.
Мы проанализировали лучшее программное обеспечение для управления искусственным интеллектом для различных команд и организаций, их функции, цены, а также сильные и слабые стороны, чтобы помочь вам определить лучший инструмент для вашего бизнеса.
Сравнение лучших программ для управления ИИ
Ознакомьтесь с высокоуровневыми функциями и сравнением цен на лучшие инструменты управления и программное обеспечение для искусственного интеллекта, которые помогут вам определить наилучшее решение для вашего бизнеса.
| Бесплатная пробная версия | Начальная цена | Лучшая функция | |
|---|---|---|---|
| IBM Cloud Pak для обработки данных | 60 дней | 350 долларов в месяц за ядро виртуального процессора | Динамично выявляйте конфиденциальные данные и применяйте правила защиты данных |
| Amazon SageMaker | 60 дней | Оплата по мере поступления | Автоматическая настройка модели (AMT) |
| Dataiku DSS | 14 дней | Доступно по запросу | Обеспечивает визуальную интерактивную подготовку данных (более 80 процессоров) |
| Машинное обучение Azure | 12 месяцев | Оплата по мере поступления | Ответственный ИИ для построения объяснимых моделей |
| Платформа Datatron MLOps | Нет (Демонстрация, практическая пробная версия) | Доступно по запросу | Обеспечивает общую работоспособность всех моделей в системе |
| Qlik Staige | 30 дней | 20 долларов США на пользователя в месяц, счет выставляется ежегодно | Встроенная прогностическая аналитика с полной объяснимостью |
| Monitaur | НЕТ | Отслеживает предвзятость, дрейф данных и аномалии | |
| Целостный ИИ | НЕТ | Доступно по запросу | Отчетность о рисках ИИ |
| Credo AI | НЕТ | Доступно по запросу | Отслеживание внедрения искусственного интеллекта |

IBM Cloud Pak для обработки данных: лучшее решение для комплексного управления проектами с искусственным интеллектом
Общая оценка: 4.6
- Стоимость: 4.1
- Набор функций: 5
- Простота использования: 4.5
- Поддержка клиентов: 5
IBM Cloud Pak for Data — это интегрированная платформа для обработки данных и искусственного интеллекта, которая помогает организациям ускорить процесс получения информации, основанной на искусственном интеллекте. Построенный на многооблачной архитектуре, он обеспечивает единое представление о данных и сервисах искусственного интеллекта, позволяя инженерам по обработке данных, специалистам по обработке данных и бизнес-аналитикам сотрудничать и быстрее создавать модели искусственного интеллекта.
Платформа включает в себя широкий спектр функций управления, включая каталогизацию данных, цепочку данных, мониторинг качества данных и управление соответствием требованиям. Возможности IBM по комплексному управлению позволяют организациям управлять своими проектами ИИ, решая ключевые проблемы, такие как конфиденциальность данных, безопасность, соответствие требованиям и объяснимость моделей.
Плюсы и минусы
| Плюсы | Минусы |
|---|---|
| Оперативная поддержка клиентов. | Пользователи сообщили о сложности настройки. |
| Решают проблемы с качеством данных. | Это дорого для малого бизнеса и стартапов. |
Цены
IBM требует, чтобы потенциальные покупатели связывались со своим отделом продаж для получения индивидуальных предложений. Однако наше исследование показало, что стандартный вариант IBM Cloud Pak for Data с 48 VPC стоит 19 824 доллара в месяц и 237 888 долларов в год. Между тем, опция IBM Cloud Pak for Data Enterprise с 72 VPC стоит 59 400 долларов в месяц и оплачивается на 712 800 долларов ежегодно.
Дальнейшие исследования показывают, что IBM Cloud Pak for Data standard edition стоит 350 долларов в месяц за ядро виртуального процессора, в то время как enterprise edition стоит 699 долларов в месяц за ядро виртуального процессора. Вы также можете попробовать этот инструмент бесплатно в течение 60 дней, прежде чем брать на себя финансовые обязательства.
Характеристики
- Интеграция данных.
- Наблюдаемость данных.
- Динамически выявляйте конфиденциальные данные и применяйте правила защиты данных.
- Расширенное обнаружение данных.
- 360-градусный обзор корпоративных данных.
- Доступны для самостоятельного размещения или в качестве управляемой службы в IBM Cloud.

Amazon SageMaker: лучшее для создания и обучения моделей ML
Общая оценка: 4.6
- Стоимость: 4.1
- Набор функций: 5
- Простота использования: 4.5
- Поддержка клиентов: 5
Amazon SageMaker предлагает разработчикам и специалистам по обработке данных интегрированную среду разработки «все в одном» (IDE), которая позволяет создавать, обучать и развертывать масштабируемые модели ML с использованием таких инструментов, как ноутбуки, отладчики, профилировщики, конвейеры и MLOP.
SageMaker предоставляет различные инструменты и возможности, включая встроенные алгоритмы, функцию маркировки данных, настройку модели, автоматическое масштабирование и опции размещения. Это упрощает рабочий процесс машинного обучения, от подготовки данных до развертывания модели, и предлагает интегрированную среду разработки для управления всем процессом. Платформа позволяет вам управлять вашими проектами, моделями и данными ML и контролировать доступ к ним, обеспечивая соответствие требованиям, подотчетность и прозрачность ваших рабочих процессов ML.
SageMaker интегрируется с такими сервисами AWS, как AWS Glue для интеграции данных, AWS Lambda для бессерверных вычислений и Amazon CloudWatch для мониторинга и ведения журнала.
Плюсы и минусы
| Плюсы | Минусы |
|---|---|
| Предлагает инструменты, которые позволяют разработчикам создавать генеративные приложения для искусственного интеллекта. | Пользовательский интерфейс может быть улучшен. |
| Amazon SageMaker Canvas способствует развитию сотрудничества между бизнес-аналитиками и командами специалистов по обработке данных. | При обработке больших объемов данных он редко дает сбои. |
Цены
SageMaker предлагает два варианта оплаты: ценообразование по запросу, которое не предполагает минимальных комиссий и предварительных обязательств, и сберегательные планы SageMaker, которые обеспечивают модель ценообразования, основанную на использовании. Вы можете просмотреть страницу с ценами платформы, чтобы узнать ваш фактический тариф.
Характеристики
- Интерфейс без кода для построения моделей ML.
- Автоматическая настройка модели (AMT).
- Студия SageMaker поддерживает различные полностью управляемые интегрированные среды разработки (IDE) для ML-разработки, включая JupyterLab, редактор кода на основе Code-OSS (Visual Studio Code—Open Source) и RStudio.
- Чат SageMaker Canvas поможет вам создать потоки подготовки данных с использованием LLM.

Dataiku DSS: Лучшее для совместной работы
Overall rating: 3.5
- Cost: 2.2
- Набор функций: 3.8
- Простота использования: 4.5
- Поддержка клиентов: 3.5
Dataiku DSS (Data Science Studio) — это совместная и комплексная платформа для анализа данных, которая позволяет группам обработки данных создавать, развертывать и отслеживать модели прогнозной аналитики и машинного обучения. Он предоставляет визуальный интерфейс для подготовки, анализа данных и моделирования с помощью искусственного интеллекта, а также возможность внедрять модели в производство и контролировать их производительность.
Dataiku DSS уделяет особое внимание совместной работе, позволяя как техническим пользователям (программистам), так и бизнес-пользователям (некодерам) совместно работать над проектами обработки данных в общем рабочем пространстве. Эта функция совместной работы позволяет специалистам по обработке данных, бизнес-аналитикам и потребителям искусственного интеллекта делиться своим опытом и аналитическими соображениями с проектами обработки данных.
В рамках своей инициативы по управлению ИИ Dataiku Government централизует отслеживание множества инициатив по обработке данных, гарантируя наличие надлежащих рабочих процессов для обеспечения ответственного ИИ. Такой централизованный надзор важен по мере того, как компании расширяют свое присутствие в сфере искусственного интеллекта и приступают к генеративным инициативам в области искусственного интеллекта, поскольку это помогает поддерживать прозрачность различных проектов и снижает риск потенциальных проблем.
Плюсы и минусы
| Плюсы | Минусы |
|---|---|
| Встроенные вики-страницы проекта для централизованного управления базой знаний. | Не хватает прозрачности ценообразования. |
| Это полезно как для программистов, так и для некодеров и позволяет им работать как со структурированными, так и с неструктурированными данными. | Поддержка клиентов могла бы быть лучше. |
Цены
Ниже приведены различные тарифные планы, предлагаемые Dataiku. Чтобы узнать фактический тариф, свяжитесь с компанией для получения индивидуального предложения. Компания также предлагает 14-дневную бесплатную пробную версию.
- Бесплатная версия: бесплатно для трех пользователей.
- Откройте для себя: Лучше всего подходит для небольших команд до пяти пользователей.
- Бизнес: Лучше всего подходит для команд среднего размера численностью до 20 пользователей.
- Предприятие: лучшее для масштабируемой автоматизации и управления.
Характеристики
Dataiku DSS предлагает несколько возможностей, включая подготовку данных, визуализацию данных, машинное обучение, операции с данными, MLOP, аналитические приложения, совместную работу, управление, объяснимость и архитектуру. Он также поддерживает функциональные возможности с помощью плагинов и соединителей, таких как OpenAI GPT, Geo Router, GDPR, Splunk, Collibra Connector и других.
- Позволяет пользователям создавать генеративные приложения ИИ в масштабе предприятия.
- Предлагает визуальный анализ и автоматизированную предварительную обработку функций.
- Позволяет пользователям устанавливать и запускать их в своем облаке — AWS, Azure и GCP.
- Обеспечивает визуальную интерактивную подготовку данных (более 80 процессоров).

Машинное обучение Azure: лучшее для ответственных приложений искусственного интеллекта в области машинного обучения
Общая оценка: 4.3
- Стоимость: 4.2
- Набор функций: 5
- Простота использования: 4.5
- Поддержка клиентов: 2.5
Azure Machine Learning поддерживает управление искусственным интеллектом, предоставляя инструменты, сервисы и фреймворки для оптимизации процесса машинного обучения, от подготовки данных и обучения модели до развертывания и мониторинга, позволяя специалистам по обработке данных и разработчикам создавать, обучать и развертывать модели машинного обучения в широком масштабе.
Azure Machine Learning предоставляет инструменты и функции, которые позволяют пользователям внедрять ответственные методы ИИ в свои проекты машинного обучения. Сюда входят такие функции, как интерпретируемость моделей, справедливость и прозрачность, которые помогают специалистам по обработке данных и разработчикам понимать и смягчать потенциальные предубеждения, обеспечивать этичное использование своих моделей и поддерживать прозрачность процесса принятия решений.
Ответственный ИИ в области машинного обучения Azure основан на шести основных принципах: честности, надежности и безопасности, конфиденциальности и защищенности, инклюзивности, прозрачности и подотчетности в моделях и процессах машинного обучения. Эти принципы, по сути, являются основой управления ИИ.
Плюсы и минусы
| Плюсы | Минусы |
|---|---|
| Встроенные и настраиваемые политики для управления соответствием требованиям. | Качество поддержки может быть |
| Обнаруживать дрейф и поддерживать точность модели. | Меньшая гибкость с точки зрения интеграции. |
Цены
Azure предлагает три варианта ценообразования: с оплатой по мере использования, план экономии Azure на вычислениях и резервирование. Вы можете ознакомиться с таблицей цен Azure, чтобы узнать о своих тарифах, или связаться с отделом продаж компании для получения персонализированных предложений.
Характеристики
- Конструктор перетаскивания.
- Встроенная поддержка библиотек и фреймворков с открытым исходным кодом, таких как Scikit-learn, PyTorch, TensorFlow, Keras и Ray RLlib.
- Встроенное управление, безопасность и соответствие требованиям для выполнения рабочих нагрузок машинного обучения.
- Ответственный ИИ для построения объяснимых моделей.
- Анализ ошибок.

Платформа Datatron Flops: лучшее решение для управления рисками и соблюдения нормативных требований
Общая оценка: 3.7
- Стоимость: 2.4
- Набор функций: 4.8
- Простота использования: 4
- Поддержка клиентов: 3
Datatron MLOps предлагает платформу мониторинга и управления моделью искусственного интеллекта, которая помогает организациям управлять и оптимизировать свои MLOP. Платформа предоставляет надежные функции мониторинга и отслеживания, гарантирующие, что модели работают должным образом и соответствуют стандартам соответствия. Это включает мониторинг производительности модели в режиме реального времени, идентификацию смещения данных и настройку оповещений о любых аномалиях или отклонениях.
Платформа предоставляет единую информационную панель для мониторинга производительности и работоспособности развернутых моделей в режиме реального времени, позволяя организациям выявлять и решать проблемы на упреждение. Возможности Datatron по объяснению играют решающую роль в управлении рисками и соблюдении нормативных требований. Это дает представление о том, как модели искусственного интеллекта принимают решения, позволяя организациям понимать и оценивать потенциальные предубеждения или риски, связанные с этими суждениями.
Это помогает компаниям обеспечить справедливость, прозрачность и подотчетность в своих системах искусственного интеллекта, что особенно важно в регулируемых отраслях.
Плюсы и минусы
| Плюсы | Минусы |
|---|---|
| Возможность обнаружения аномалий. | Некоторые пользователи говорят, что интерфейс сложный. |
| Оповещения и уведомления по электронной почте, Slack или PagerDuty. | Иногда работает медленно. |
Цены
Свяжитесь с компанией для получения персонализированного предложения.
Характеристики
- Обеспечивает общую работоспособность всех моделей в системе.
- Смещение, дрейф, производительность, обнаружение аномалий.
- Вы можете настроить мониторинг и отчетность на основе пользовательских показателей.
- Журнал действий и контрольный журнал.

Qlik Staige: лучшее решение для аналитики и визуализации данных на основе искусственного интеллекта
Общая оценка: 3.4
- Стоимость: 2.7
- Набор функций: 3.5
- Простота использования: 4
- Поддержка клиентов: 3.5
Qlik Staige — это решение для управления искусственным интеллектом, обеспечивающее аналитику на базе искусственного интеллекта, позволяющее компаниям динамизировать визуализации, генерировать данные на естественном языке, которые предоставляют простые для понимания сводки и позволяют работать с данными в интерактивном режиме, основанном на диалоге.
Платформа позволяет компаниям использовать возможности ИИ, сохраняя при этом контроль, безопасность и управление своими моделями ИИ и данными. Она обеспечивает интеграцию данных, обеспечение качества и возможности преобразования для создания готовых к ИИ наборов данных. Этот инструмент облегчает автоматизацию процессов машинного обучения, позволяя аналитическим группам генерировать объяснимые прогнозы и интегрировать модели в режиме реального времени для всестороннего анализа «что, если».
Плюсы и минусы
| Плюсы | Минусы |
|---|---|
| Оповещение об изменениях данных. | Дорого. |
| Это позволяет вам проводить анализ совместно с другими пользователями. | Начальная кривая обучения. |
Цены
- Стандарт: 20 долларов США на пользователя в месяц, счет выставляется ежегодно. Минимум десять пользователей.
- Премиум: Стоимость начинается от 2700 долларов в месяц, оплачивается ежегодно. Поддерживает 50 ГБ и 10 полноправных пользователей.
- Предприятие: индивидуальное предложение.
Характеристики
- Интерактивная визуализация данных и информационные панели.
- Расширенная аналитика с помощью продвинутого искусственного интеллекта.
- Встроенная прогностическая аналитика с полной объяснимостью.
- Прогнозы в реальном времени с помощью API.
- Анализ и инсайты, созданные с помощью искусственного интеллекта, включая поиск и взаимодействие на естественном языке.

Monitaur: Лучшее решение для регулируемой отрасли
Общая оценка: 3.3
- Стоимость: 1.5
- Набор функций: 4.8
- Простота использования: 4
- Поддержка клиентов: 2.5
Monitaur облегчает координацию и сотрудничество между различными командами и заинтересованными сторонами, вовлеченными в процесс разработки и внедрения модели ИИ, включая инженеров по программному обеспечению, специалистов по обработке данных, специалистов по соблюдению требований, андеррайтеров и руководителей, принимающих решения. Monitaur помогает организациям продемонстрировать, что их модели ИИ соответствуют требованиям и заслуживают доверия, централизуя процессы управления и предоставляя библиотеку стандартных политических средств контроля.
Платформа особенно полезна для регулируемых отраслей со строгими стандартами и требованиями соответствия. Благодаря централизованно управляемой библиотеке организации в этих отраслях могут придерживаться нормативных актов и легко демонстрировать соответствие.
Плюсы и минусы
| Плюсы | Минусы |
| Обеспечение соответствия требованиям. | Средний балл поддержки клиентов. |
| Централизованное управление. | Не хватает прозрачного ценообразования. |
Цены
Свяжитесь с компанией для получения персонализированного предложения.
Характеристики
- Отслеживает предвзятость, дрейф данных и аномалии.
- Консолидируйте представление о типовых проектах и целях, включая ИИ, машинное обучение, LLM, GPT и статистические модели.
- Мониторинг соответствия требованиям.
- Управление рисками.

Holistic AI: лучшее для управления рисками ИИ и аудита
Общая оценка: 3.7
- Стоимость: 2.2
- Набор функций: 4.8
- Простота использования: 4
- Поддержка клиентов: 3.5
Платформа управления Holistic AI предлагает ряд функций для решения различных аспектов управления ИИ, включая управление рисками и комплаенс. Платформа позволяет организациям проводить комплексные аудиты своих систем искусственного интеллекта и создает подробные аудиторские отчеты, документирующие производительность системы, уязвимости и области, требующие улучшения. Функциональность отчетности также включает анализ воздействия с учетом контекста, позволяющий понять влияние систем ИИ на бизнес-процессы и заинтересованные стороны.
Целостный ИИ поддерживает оценки, ориентированные на конкретные нормативные акты, гарантируя, что ваши системы ИИ соответствуют соответствующим законам и нормативным актам. Это помогает вам выявлять, смягчать и отслеживать риски, связанные с конкретными правилами, позволяя вам соблюдать их.
Плюсы и минусы
| Плюсы | Минусы |
|---|---|
| Выявляйте и смягчайте предвзятость. | Поддержка может быть лучше. |
| Всеобъемлющая аудиторская отчетность. | Документация может быть улучшена. |
Цены
Свяжитесь с компанией для получения предложений.
Характеристики
- Отчетность о рисках ИИ.
- Управление сторонними поставщиками ИИ.
- Оценка соответствия ИИ.
- Оценка предвзятости ИИ.

Credo AI: лучшее для корпоративного использования на базе искусственного интеллекта
Общая оценка: 3.8
- Стоимость: 1.5
- Набор функций: 4.1
- Простота использования: 4
- Поддержка клиентов: 4
Платформа Credo для управления ИИ удовлетворяет потребности предприятий, основанных на ИИ, предлагая такие функции, как централизованное хранилище метаданных ИИ, центр рисков для визуализации рисков и ценности ИИ и автоматизированные отчеты по управлению для укрепления доверия с заинтересованными сторонами. Он также предлагает реестр ИИ для отслеживания инициатив в области ИИ и рабочее пространство по управлению ИИ для совместной работы над вариантами использования ИИ.
Credo AI генерирует автоматизированные отчеты по управлению, включая типовые карты, оценки воздействия, отчеты и информационные панели, которыми можно поделиться с руководителями, членами правления, клиентами и регулирующими органами для укрепления доверия и прозрачности к инициативам в области ИИ. Функция реестра искусственного интеллекта компании обеспечивает наглядное представление о рисках и ценности всех проектов искусственного интеллекта путем их регистрации и сбора метаданных для определения приоритетности проектов на основе потенциального дохода, воздействия и риска.
Плюсы и минусы
| Плюсы | Минусы |
|---|---|
| Автоматизированные отчеты по управлению. | Интеграция требует технических знаний. |
| Гибкое развертывание — локальное, общедоступное и частное облако. | Получил низкую оценку за непрозрачное ценообразование. |
Цены
Доступно по запросу.
Характеристики
- Отслеживание внедрения ИИ.
- Управление рисками искусственного интеллекта.
- Артефакты для аудита.
- Генеративные ограждения ИИ.
- Соблюдение нормативных требований.
- Оценка рисков поставщиков.
Как выбрать лучшее программное обеспечение для управления искусственным интеллектом для вашего бизнеса
Многие факторы помогают определить лучшее программное обеспечение для управления ИИ для вашего бизнеса. Некоторые решения превосходны с точки зрения правил конфиденциальности данных и ИИ, в то время как другие хорошо подходят для установления стандартов соответствия, этических рекомендаций или оценки рисков.
При покупке лучшего решения для управления искусственным интеллектом вам следует обратить внимание на программное обеспечение, предлагающее такие функции, как управление данными, управление моделями, автоматизация соответствия требованиям и возможности мониторинга. В зависимости от характера вашего бизнеса вам может потребоваться специализированное программное обеспечение для управления искусственным интеллектом, адаптированное к уникальным требованиям вашего сектора.
Например, организациям здравоохранения может потребоваться программное обеспечение, соответствующее правилам HIPAA, в то время как финансовым учреждениям могут потребоваться инструменты обнаружения мошенничества и оценки рисков. Проведите тщательное исследование, оцените свои варианты и учтите свои потребности – и бюджет, — чтобы определить лучшее программное обеспечение для управления ИИ для вашего бизнеса.
Как мы оценили лучшее программное обеспечение для управления искусственным интеллектом
Ценообразование – 25%
Мы рассмотрели стоимость программного обеспечения и то, соответствует ли оно цене. Инструменты, предлагающие бесплатные пробные версии и прозрачное ценообразование, получили более высокие оценки в этой категории.
Набор функций – 35%
Набор функций программного обеспечения для управления ИИ был важным фактором в нашей оценке. Мы оценили спектр предлагаемых функций,
- Сосредоточьтесь на этике в ИИ.
- Полный спектр мер безопасности.
- Обрабатывает типовую документацию.
- Качественные инструменты отчетности и информационные панели.
Мы также рассмотрели возможность настройки программного обеспечения для удовлетворения конкретных потребностей различных организаций.
Простота использования – 25%
Мы оценили пользовательский интерфейс программного обеспечения и опыт работы с ним, чтобы определить, насколько пользователям легко ориентироваться, настраивать и использовать программное обеспечение. Мы рассмотрели, предлагает ли программное обеспечение интуитивно понятные рабочие процессы и варианты настройки.
Поддержка клиентов – 15%
Мы оценили уровень поддержки клиентов, предлагаемый поставщиком программного обеспечения, включая доступность, оперативность реагирования и опыт. Мы изучили каналы поддержки, документацию, обучающие ресурсы и сообщества пользователей.
Часто задаваемые вопросы о программном обеспечении для управления искусственным интеллектом
Как практика управления ИИ согласуется с этическими соображениями?
Практика управления ИИ согласуется с этическими соображениями ИИ, гарантируя, что системы ИИ разрабатываются, развертываются и используются для соблюдения этических принципов, таких как справедливость, прозрачность, подотчетность и конфиденциальность.
Какие отрасли лидируют в внедрении управления искусственным интеллектом?
Такие отрасли, как финансовые услуги, здравоохранение и технологии, лидируют по внедрению управления искусственным интеллектом, поскольку эти отрасли часто имеют дело с конфиденциальными данными и решениями с высокими ставками, где этические соображения имеют решающее значение.
Как компании могут извлечь выгоду из эффективного управления искусственным интеллектом в нынешних условиях?
- Повышение доверия со стороны клиентов и заинтересованных сторон.
- Снижение рисков предвзятости, дискриминации и юридической ответственности.
- Улучшена безопасность данных и защита конфиденциальности.
- Соответствие нормативным актам и отраслевым стандартам.
Итог: программное обеспечение для управления искусственным интеллектом
По мере того, как все больше организаций в различных секторах продолжают внедрять решения на основе искусственного интеллекта в свои рабочие процессы, становится критически важным наличие управления искусственным интеллектом для обеспечения ответственного и этичного использования искусственного интеллекта.
Если ИИ не контролировать, он может быстро стать источником предвзятых решений, нарушений конфиденциальности и других непреднамеренных последствий. Таким образом, инструменты управления искусственным интеллектом должны быть не второстепенной мыслью, а неотъемлемой частью стратегии вашей компании в области искусственного интеллекта.

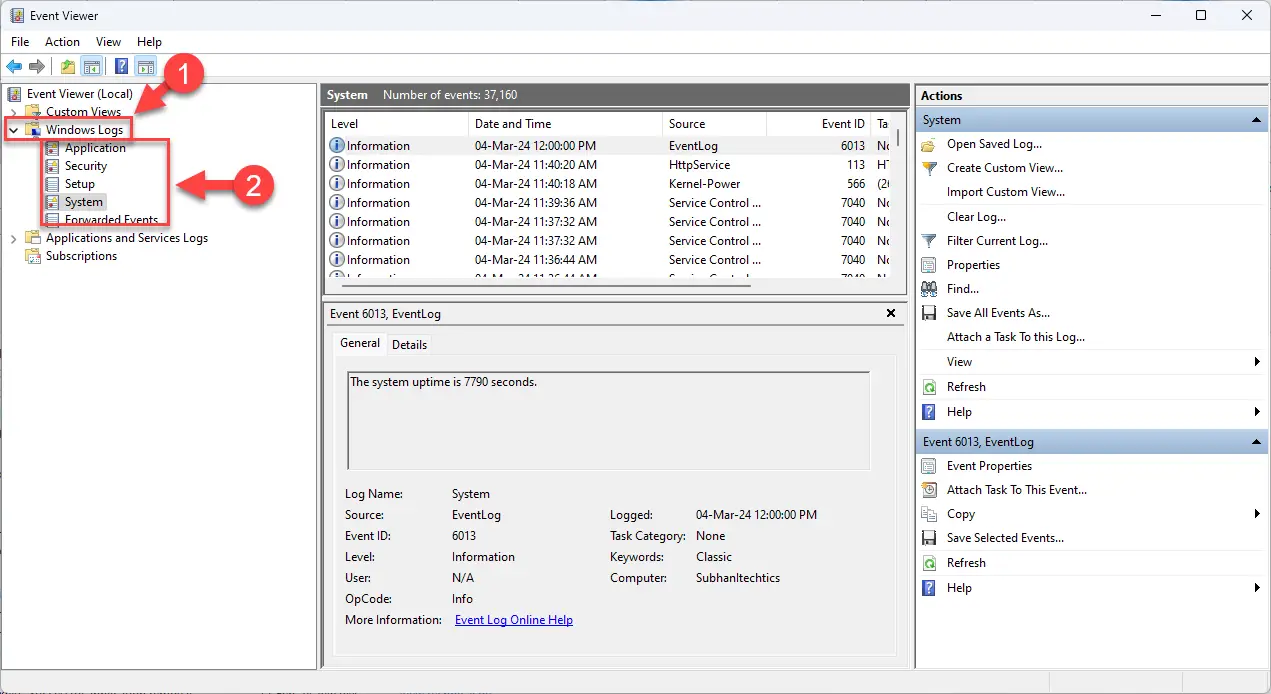 Категория событий открытого журнала
Категория событий открытого журнала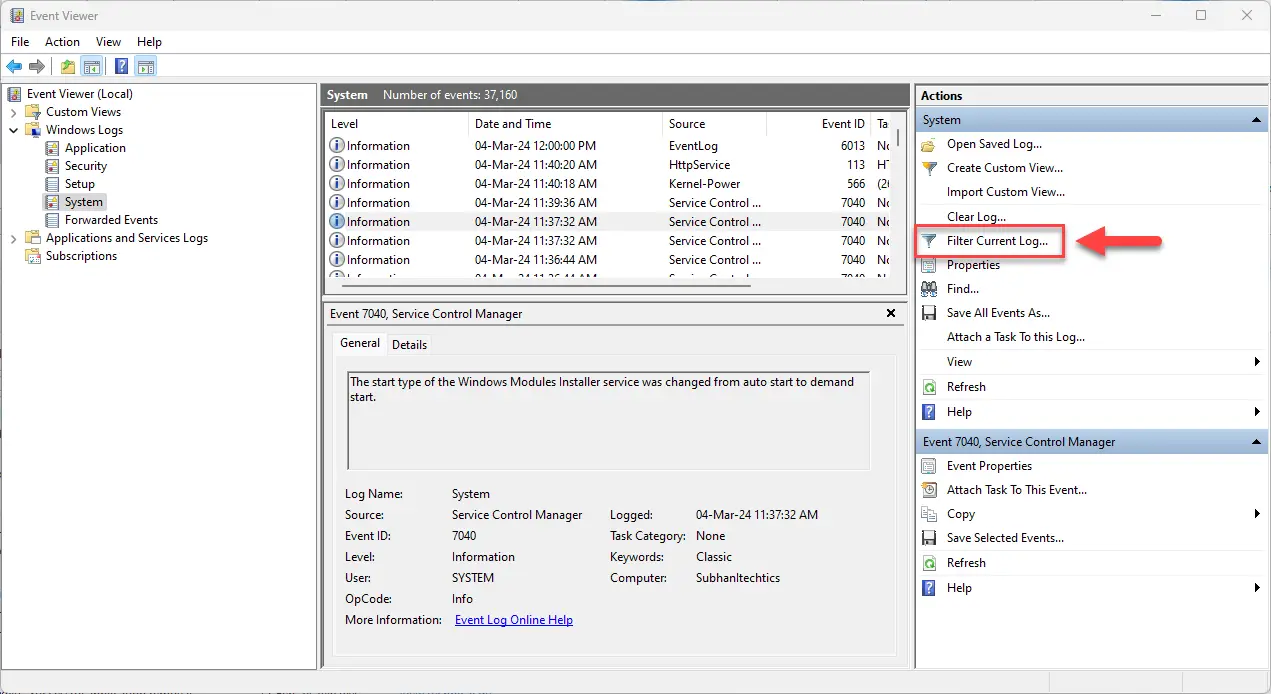
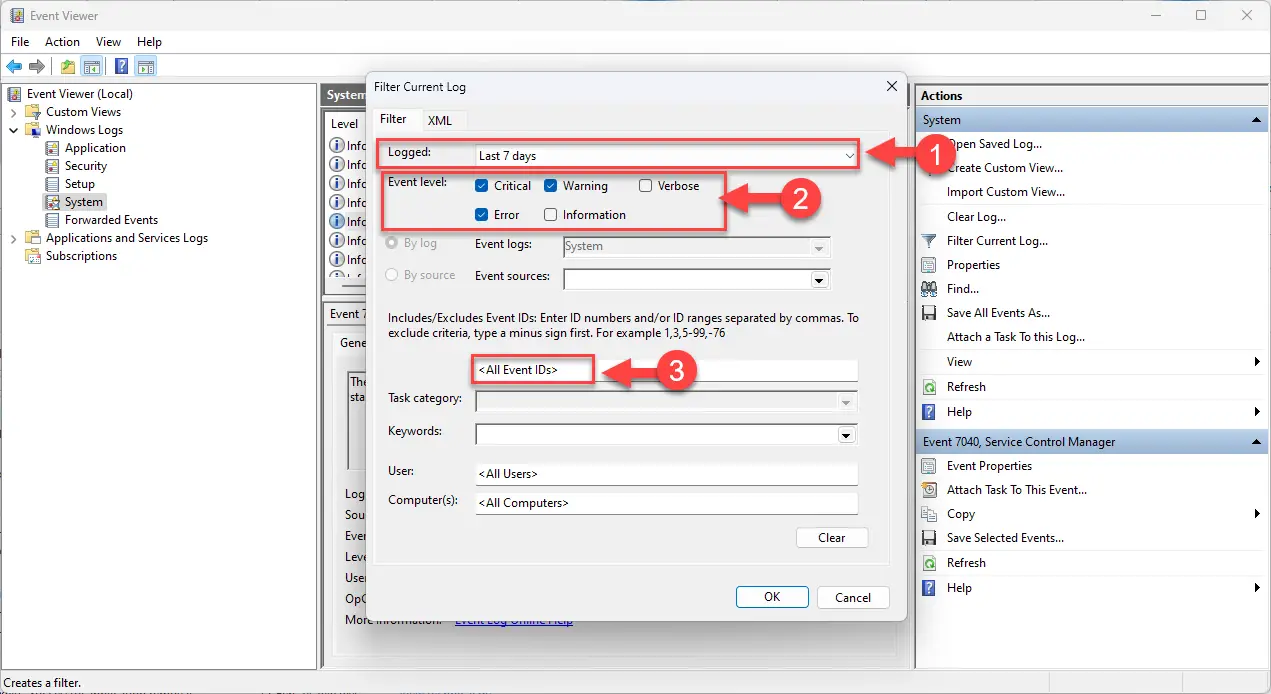
 Создайте собственный фильтр в средстве просмотра событий.
Создайте собственный фильтр в средстве просмотра событий.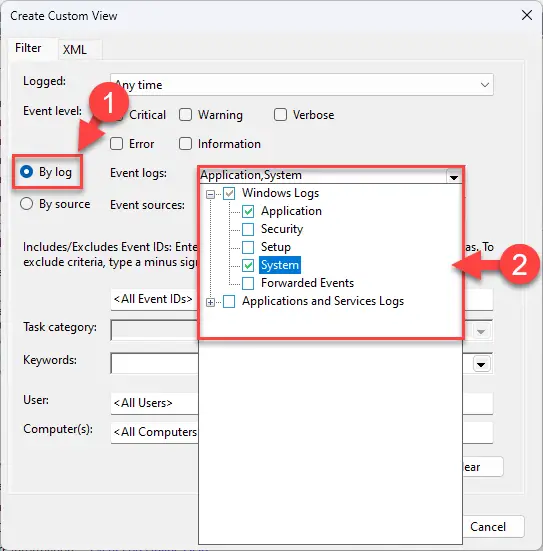 Выберите категории журнала событий для просмотра
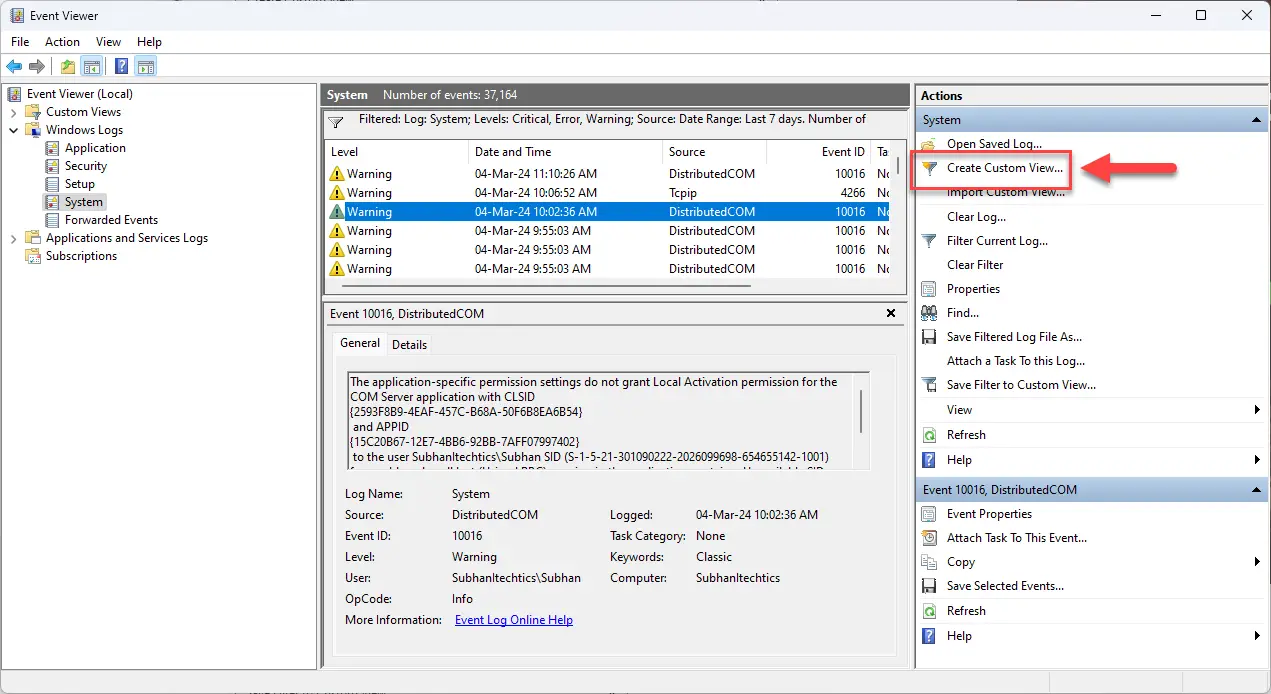
Выберите категории журнала событий для просмотра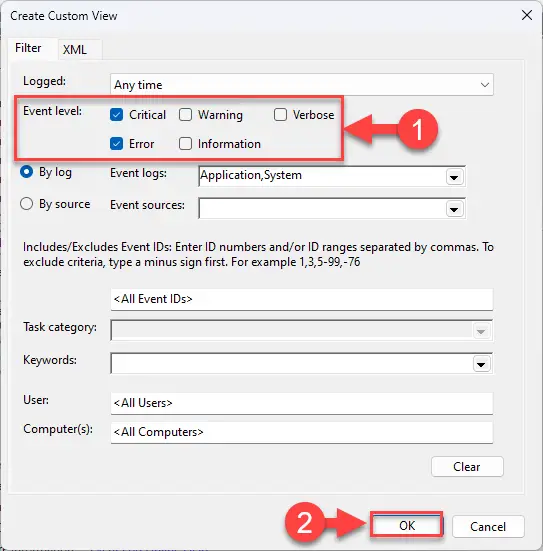 Создайте собственное представление для журналов событий.
Создайте собственное представление для журналов событий.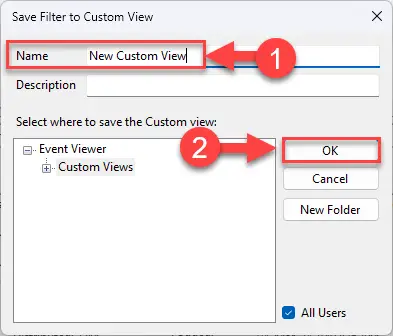 Присвойте имя пользовательскому представлению событий
Присвойте имя пользовательскому представлению событий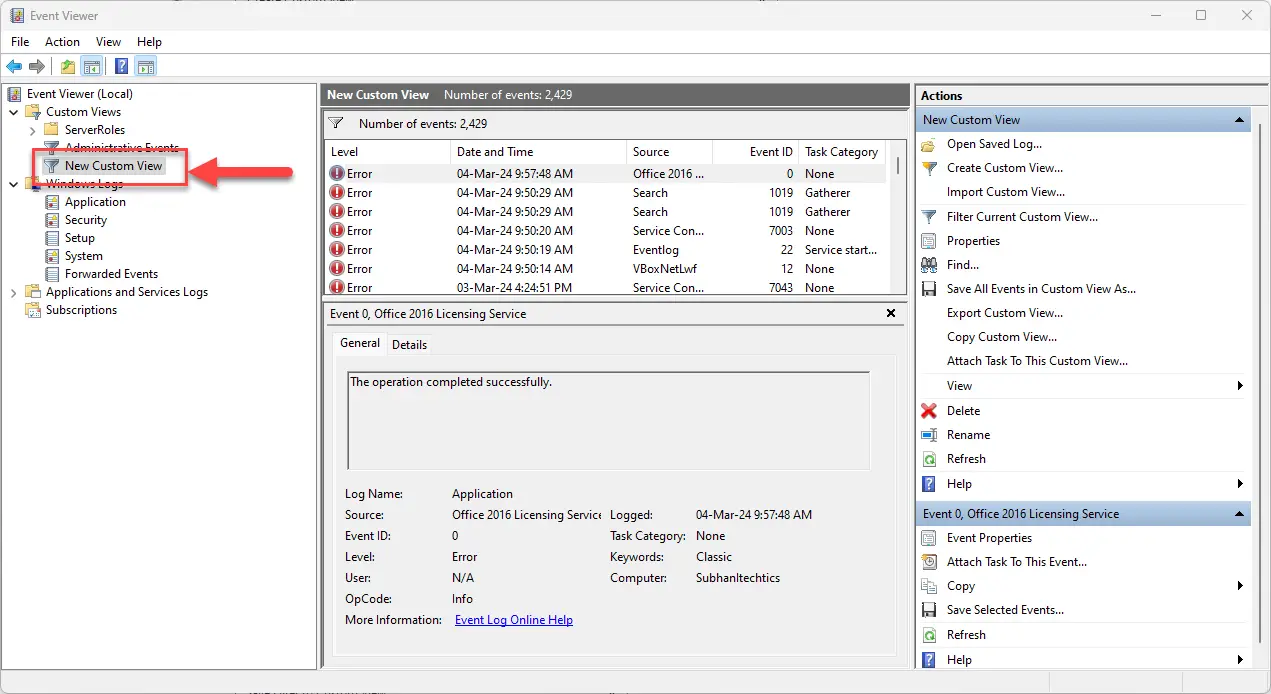
 Развернуть Техническое обслуживание
Развернуть Техническое обслуживание Открыть монитор надежности
Открыть монитор надежности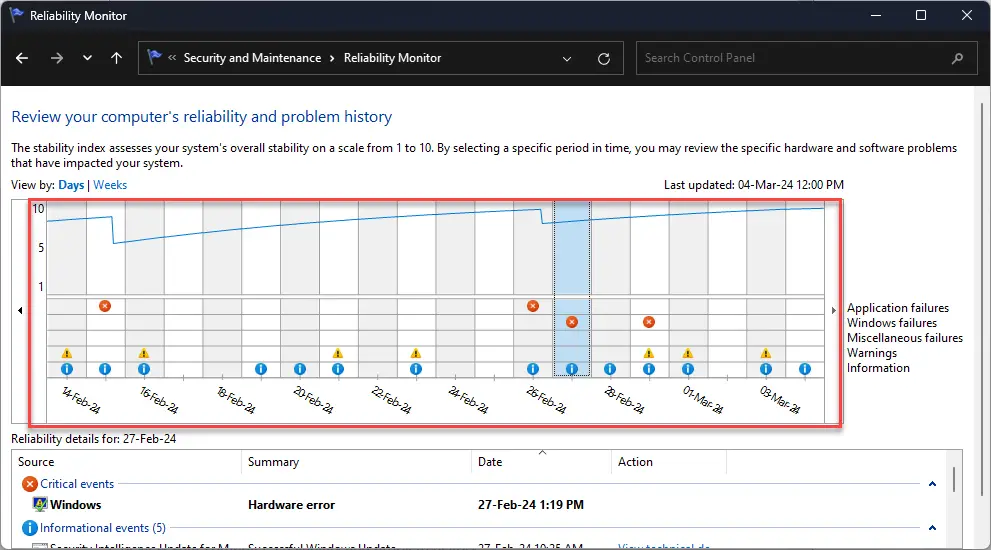 Выберите день для просмотра журналов событий.
Выберите день для просмотра журналов событий.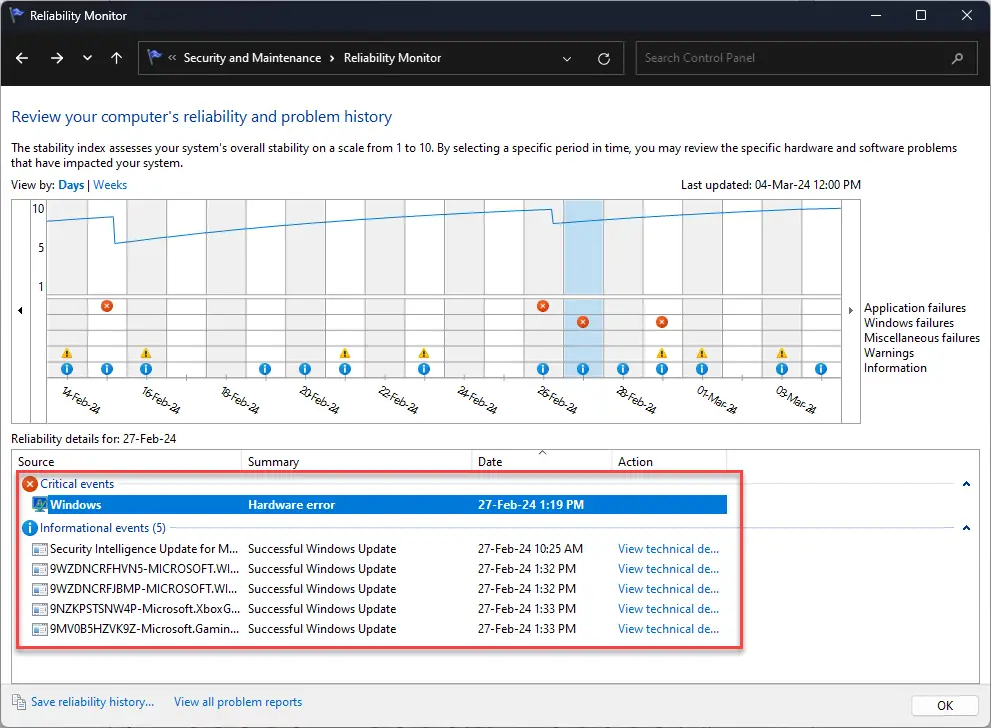 Откройте журнал событий с помощью монитора надежности.
Откройте журнал событий с помощью монитора надежности.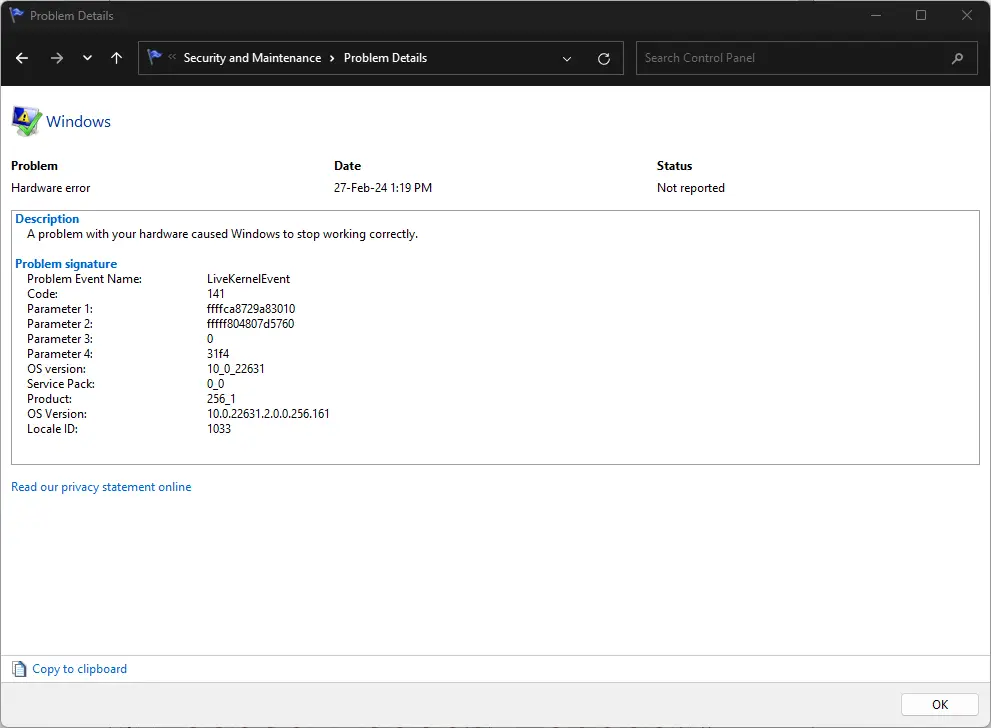
 Вы в последнее время не высыпаетесь? Постоянно находитесь в состоянии стресса? В этом можно легко обвинить свои ежедневные обязанности, такие, как работа или дети. Но, может быть, вашему стрессу способствуют иные вещи, о которых вы не знаете?
Вы в последнее время не высыпаетесь? Постоянно находитесь в состоянии стресса? В этом можно легко обвинить свои ежедневные обязанности, такие, как работа или дети. Но, может быть, вашему стрессу способствуют иные вещи, о которых вы не знаете?