Изучение разных видов языков поможет Вам сформировать четкое представление о том, какой язык программирования необходимо выбрать для создания определенных видов приложений.
Сама Java была разработана компанией Sun Microsystems (в последующем приобретённой компанией Oracle) еще в 1995 году, и она до сих пор используется для широкого спектра программных приложений. Код Java выполняется виртуальной машиной, которая работает на устройствах Android и интерпретирует код.
Выбор языка программирования
C# — это более простая, чисто объектно-ориентированная версия разработки C и C+ от Microsoft. Основная цель Microsoft заключалась в том, чтобы объединить мощь C++ и простоту Visual Basic. Этот язык для разработки Android-приложений часто приходится по вкусу многим разработчикам, особенно сочетание C# и Unity.
Corona предлагает еще один простой вариант для разработки приложений для Android. Вы будете кодировать в LUA, который уже намного проще, чем Java. Он поддерживает все собственные библиотеки, что позволяет публиковать данные на нескольких платформах.
C# также можно использовать с Xamarin через Visual Studio. Это похоже на традиционную разработку Android с преимуществом кросс-платформенности, которая имеет кодовую базу для Android и iOS.
Мы разобрались, на каком языке пишут приложения для андроид. Их существует довольно много, каждый имеет свои особенности, функции и применение, большинство из них пересекаются и дополняют друг друга.
Чем так популярен PhoneGap? Это своеобразный «мост» между программой и функциями смартфона. Приложения смогут активно использовать возможности устройства и его ресурсы, такие, как камера, микрофон, акселерометр и другие.
Главным преимуществом Java является наличие собственной среды разработки под названием Android Studio. В 2014 году она была признана компанией Google в качестве официальной среды андроид программирования, что значительно облегчило жизнь разработчикам. Процесс разработки приложений упрощается за счет визуального UI-редактора, функции автодополнения кода и прочих возможностей.
PhoneGap
Существует большое количество языков, при помощи которых можно создать качественное приложение. Некоторые языки имеют встроенную среду разработки, что значительно облегчает процесс создания приложения. Другие нуждаются в дополнительных инструментах, однако их функционал не менее широкий. Давайте разберем, на каких языках происходит Android программирование.
Что касается самого языка BASIC, то он единственный платный для разработки. Игры и приложения получаются ресурсоемкими, поэтому не соответствуют Material Design. Скорость работы приложений на BASIC также не высокая. Но он очень прост в освоении, имеет понятный синтаксис и позволяет реализовывать как сложные, так и простые проекты. Программирование приложений для андроид при помощи BASIC рекомендуется делать в том случае, если задачи не требуют сложных вычислений.
Kotlin – это относительно молодой язык, который появился в 2017 году. Но за такой короткий промежуток он смог завоевать любовь многих программистов, и в 2019 году был признан компанией Google лучшим языком программирования для андроид, отодвинув Java на второе место.
Python первоначально воспринимается так, что программирование под андроид на нем невозможно. Считается, что на нем нельзя разрабатывать нативные приложения, но любители данного языка создали мощные инструменты, которые помогают разрабатывать приложения и компилировать код. Разработано большое количество библиотек, которые помогают строить нативные интерфейсы. К примеру, можно использовать фреймворк Kivy для работы с Python.
Наиболее популярная среда разработки мобильных приложений при помощи Lua – это Corona SDK. Распространяется она полностью бесплатно (с 2015 года) и считается очень удобной для начинающих разработчиков. По ней много документации и полезных советов от специалистов, в том числе, в Рунете.
Для работы под Android были созданы функциональные и очень удобные среды программирования Visual и Xamarin Studio. Также C# вам пригодится и станет большим плюсом, когда вы начнете использовать Unity 3D. Такой набор расширяет ваши возможности практически до безграничных.
На Java можно увидеть огромное количество исходников на GitHub, да и сами разработчики отмечают, что этот красивый и мощный язык очень удобен для написания мобильных приложений. Конечно, это не самый быстрый и простой процесс. В конце концов, языку уже 22 года, а простота никогда не была его преимуществом. Также бытует мнение, что при желании можно обойтись более современными аналогами. Но практика показывает, что без Java добиться успехов в сфере создания приложений под Android еще никому не удалось.
Kotlin
Kotlin – один из молодых языков, уже заслуживших популярность. Он действительно достоин пристального внимания и сам по себе, и в связке с Java. Несмотря на юный возраст программисты не сумели найти в Kotlin практически никаких недостатков.
Лидирует в этой сфере, конечно, Java. Этот язык можно смело назвать основным официальным языком разработки Android. По крайней мере, все официальные курсы и образовательная документация по Android-программированию основана на этом языке.
Удивлены? Да, конечно, для создания нативных ndroid приложений язык Python считается неподходящим, так как Android его не поддерживает. Но на самом деле, нет ничего невозможного. Ценители языка Python создали много инструментов, которые помогут скомпилировать программы Python в нужный код.
Для работы с веб-версиями можно применять среду PhoneGap Build или, в отдельных случаях, Adobe Cordova. Глубоких знаний в этой сфере от разработчика мобильных приложений обычно не требуется. Но все же определенная база – очень важна.

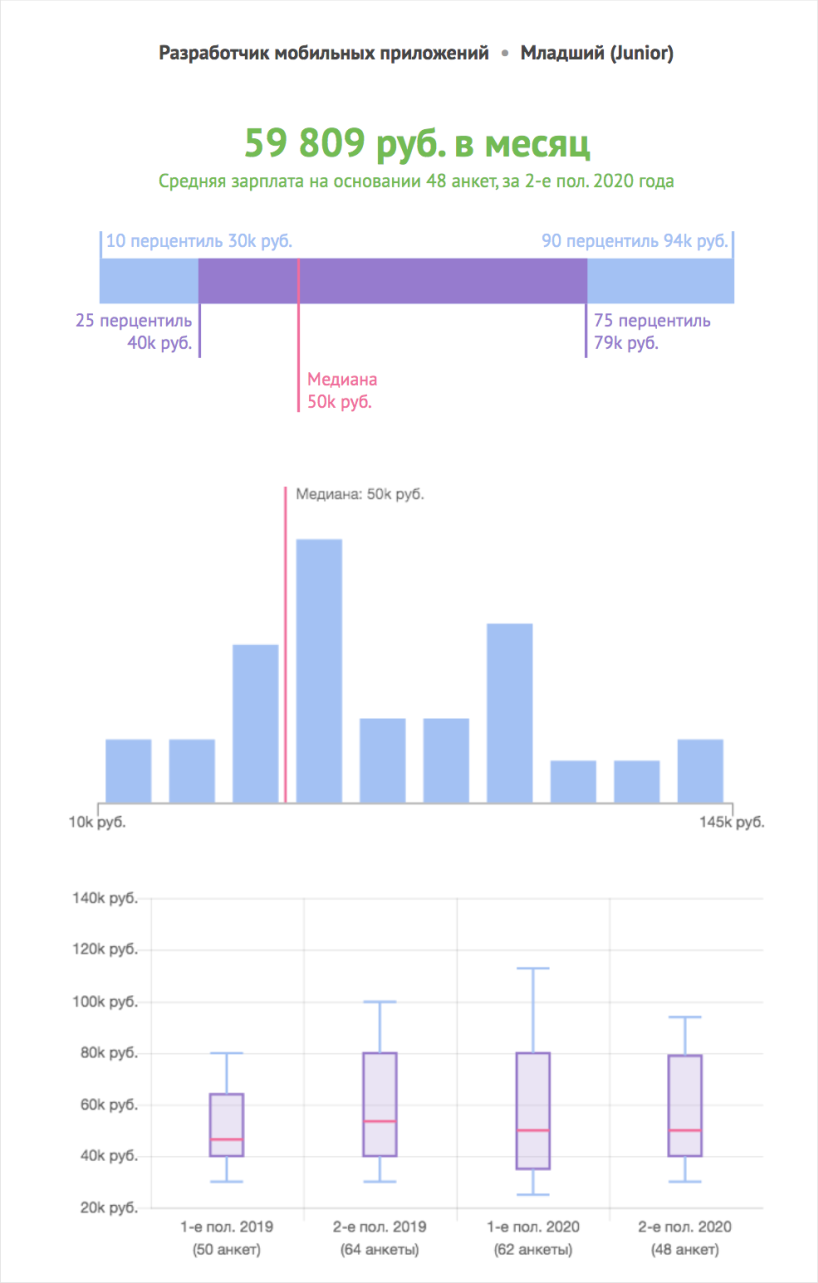
Откроем Хабр Карьера и посмотрим среднюю зарплату начинающего мобильного разработчика. Во второй половине 2020 года джунам платят 60 тысяч рублей.
Kotlin → Java
В каком порядке учить

Подробнее
Увеличим выборку и посмотрим все вакансии hh.ru, где новичкам готовы заплатить 40–80 тысяч рублей. На момент обзора опубликовано 56 объявлений: восемь работодателей требуют только Java; пять — только Kotlin; 43 — Java и Kotlin.
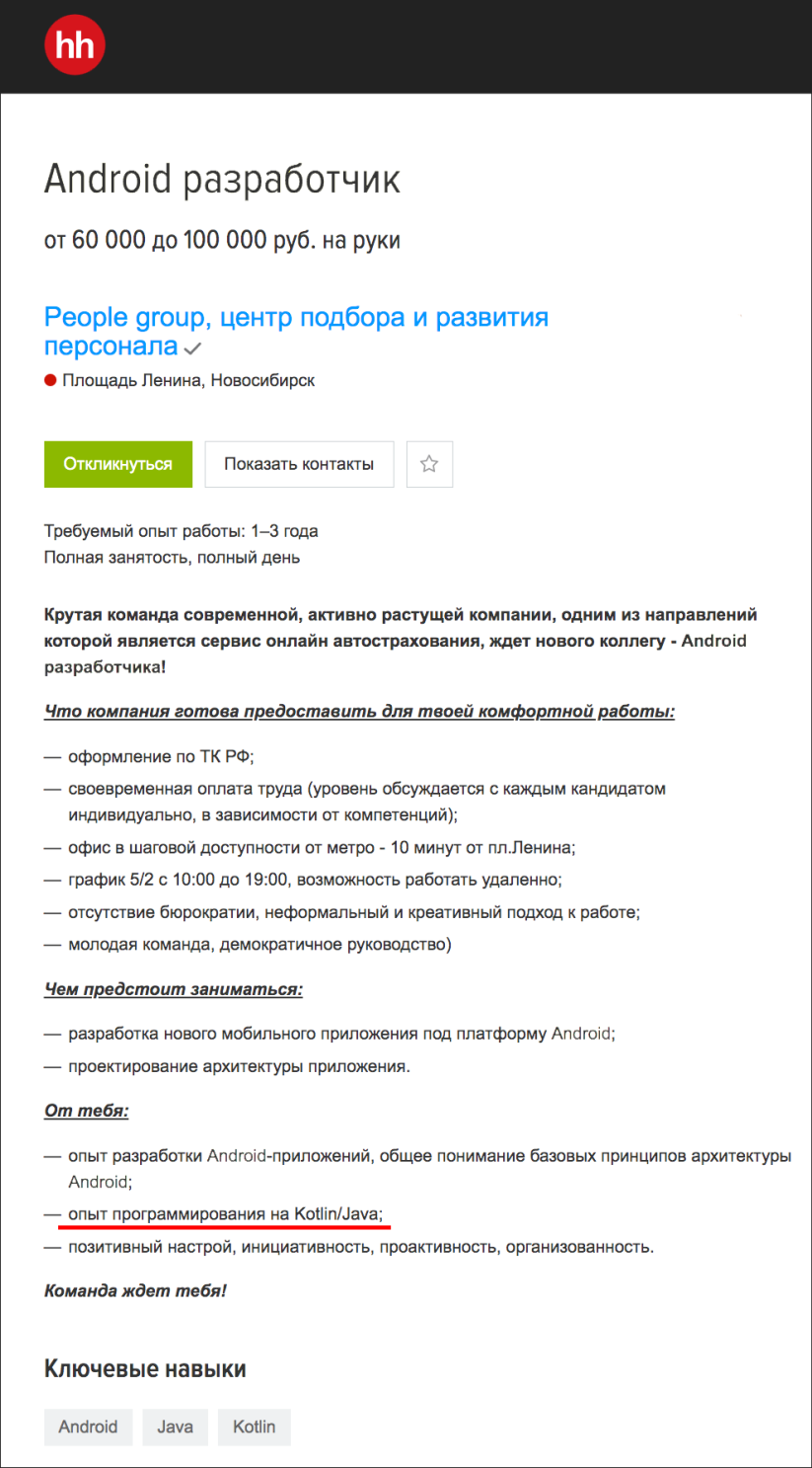
Перейдём на hh.ru и рандомно выберем вакансию андроид-разработчика с зарплатой от 60 тысяч рублей. От кандидата требуется опыт программирования на Java и Kotlin.
Дополнительные материалы
Строго говоря, Python не является языком мобильной разработки, а больше используется в веб-проектах. Однако, как все мы знаем, в ближайшем будущем боты заменят приложения, а с помощью Python вы как раз и сможете их создавать + язык широко используется и в других областях, например, в машинном обучении. К тому же он легко постигаем новичками, у него много библиотек, синтаксис легко читаемый и довольно аккуратный код.
Objective-C — компилируемый объектно-ориентированный язык программирования корпорации Apple, построенный на основе языка C и парадигм Smalltalk. Язык был создан Брэдом Коксом в начале 1980 и сейчас уже морально устарел, его заменяет новый и более простой Swift. Тем не менее, еще 3-5 лет разработчики на Objective-C будут очень востребованы на рынке.
5. Objective-C
JavaScript — прототипно-ориентированный сценарный язык программирования. Наиболее широкое применение нашел в браузерах как язык сценариев для придания интерактивности веб-страницам, а также в кроссплатформенных фреймворках (React Native, Ionic, Sencha и т.п.).
Swift — язык, разработанный компанией Apple и предназначенный для разработки приложений под iOS и OS X. Swift заимствовал довольно многое из C++ и Objective-C.
Java — строго типизированный объектно-ориентированный язык программирования, разработанный компанией Sun Microsystems (в последующем приобретённой компанией Oracle).
C# — объектно-ориентированный язык программирования. Разработан в 1998-2001 годах группой инженеров в компании Microsoft как язык разработки приложений для платформы Microsoft .NET Framework. В области разработки мобильных приложений и используется во фреймворке Xamarin.

Google на данный момент официально поддерживает достаточно мощную среду разработки Android Studio, которая собрана на основе Intellij IDEA от JetBrains. Также не стоит забывать про очень подробную документацию от Google, в которой разбирается всё: от match_parent и wrap_content до конструкторов, констант и основных методов класса JavaHttpConnection — обязательно стоит почитать.
Операционная система Android с каждым годом становится не только годной ОС для обычных пользователей, но и мощной платформой для разработчиков. Что ж поделать: Google всегда идёт навстречу девелоперам, предоставляя широкие возможности и мощный инструментарий, приправленный информативной документацией.
Java — основное средство для Android-разработчика

Подойдёт для создания игр и простых приложений
Своё путешествие в мир Android рекомендуется начинать именно отсюда: любой androi разработчик знаком с Java и понимает все немалочисленные плюсы и минусы этого языка.
Если вам по каким-то причинам не хочется изучать Java или разбираться в построении интерфейса через XML, то вы можете выбрать для себя данное IDE. Corona — это достаточно легковесная среда разработки, код в которой необходимо писать на достаточно лёгком LUA (любители Pascal оценят по достоинству).
Android разработка — это не только Java и Android Studio. Писать под Андроид можно на разных языках. Мы расскажем про 10 самых популярных языков для Андроид.
Большая часть комьюнити разработчиков просто игнорирует NDK, считая его недостойным внимания. На практике данная среда обеспечивает лучшие показатели быстродействия и эффективнее задействует ресурсы системы. Помните, хорошая идея и хорошая реализация – разные понятия.
Kotlin

Практически без преувеличения Java является основным языком для Андроид. Большая часть документации, приложений, курсов в сети и прочей информации основаны на Java. По оценке другого авторитетного источника, рейтинга TIOBE, Java является самым популярным языком в мире. По числу исходников на GitHub он находится на втором месте.
Фактически Android не готов использовать Python в качестве основного языка для создания нативных программ, но это все равно возможно. Сами разработчики придумали немало инструментов для интеграции Python на Android. Достаточно лишь правильно его скомпилировать.
В отношении программирования под Андроид можно отметить наличие доступа к наиболее функциональным средам разработки: Visual и Xamarin Studio . Язык C# ещё пригодится при необходимости применять Unity . Таким образом удаётся получить практически безграничные возможности в разработке.
Kotlin совместим с Java, имеет больше синтаксического сахара и считается более лёгким для начинающих. Прекрасный язык программирования для тех, кто учится разрабатывать под Android. Но учтите, что некоторые специалисты считают, что знать Java всё же необходимо (статью о Kotlin и Java вы можете почитать здесь). Как бы там ни было, с помощью Kotlin вы не будете чувствовать особых проблем при создании нативных Android-приложений.
Инструмент является официальным средством разработки Android-приложений. Он поставляется в виде пакета с Android SDK и представляет собой набор специализированных инструментов с соответствующим функционалом. По сути, здесь есть всё, что нужно программисту.
Kotlin
Да, язык непростой, но он стоит потраченных усилий. К тому же, многие утверждают, что сложно добиться каких-либо значимых успехов в Android-разработке, совершенно не зная Java.
Сам по себе язык Basic4Android очень похож на популярный Visual Basic. Разрабатывая приложения на нём, вы сможете использовать много дополнительных библиотек с разным функционалом, а для выполнения программ специальных runtime-средств не потребуется.
Что касается Android-разработки, то к вашим услугам такие функциональные среды, как Visual и Xamarin Studio. Кроме того, знание C# станет отличным бонусом, если вы доберётесь до Unity 3D. А вот с этим набором ваши возможности точно станут безграничны.

В студии AppCraft мы разрабатываем нативные приложения для iOS и Android. За 10 лет собрали в портфолио более 200 проектов: корпоративные решения, соцсети, банковские системы, мессенджеры и e-commerce и не планируем останавливаться 🙂
Что такое фирменный стиль бренда и почему он важен?
В 2014 году вышел более мощный Swift, который взял себе все лучшее от Objective-C, но был лишен его недочетов. Сейчас большинство программистов выбирают Swift, но Objective С тоже сохраняет позиции как классический способ написания кода на iOS.
Недостатки:
До 2018 года был основным языком для создания приложений под Android, но и в 2021 его продолжают использовать многие разработчики.
В любом проекте мы стремимся создать работающий продукт, который решит задачи клиентов и увеличит прибыль. Если вы хотите разработать быстрое и функциональное мобильное приложение — оставьте заявку и мы с вами свяжемся, чтобы обсудить детали.
Rust начал создаваться в 2006 году разработчиком Грейдоном Хором, который хотел соединить в нем скорость C++ и надежность Haskell. В 2009-ом к нему присоединилась Mozilla, и год спустя его презентовали на Mozilla Summit. Сейчас Rust является одним из самых популярных среди разработчиков кроссплатформенных приложений.
Выбор языка программирования зависит от OC, задач приложения и способа разработки, который вы выберете.
От вас же, в свою очередь, требуется только желание и базовое понимание программирования на языке Java. Не так много, правда? Что ж, начнём!
Итак, давайте приступим к созданию простого Android-приложения, которое будет выводить на экран «Hello World!».
У вас к этому времени уже должен быть установлен Android Studio последней версии. Ниже будет приведена небольшая пошаговая инструкция:
Это файл типа «Манифест», который описывает основные характеристики приложения и определяет каждый из его компонентов. Он является своего рода интерфейсом между ОС Android и вашим приложением – если компонент не упомянут в этом файле, он не будет отображен и в операционной системе.
Компоненты приложения являются своего рода «строительными блоками» для приложения Android. Эти компоненты связаны файлом-манифестом приложения AndroidManifest.xml, который описывает каждый компонент приложения и взаимодействие этих компонентов между собой.
Сообщение На каком языке пишутся приложения для Android появились сначала на ZDRONS.RU.
Source: zdrons.ru php