Вы потратили большую часть часа в ожидании загрузки и установки новой игры. Наконец, кнопка Play подсвечивается, и вы жадно щелкаете курсором, чтобы запустить игру.
Вскоре после нажатия на экране появляется сообщение об ошибке. Это страшная ошибка Bad_Module_Info. Что теперь?
Когда ваша игра решает сбить вас с ошибкой bad_module_info, вам не нужно беспокоиться. Эта статья предоставит вам несколько различных способов, которые помогут вам быстро войти в игру.
Запустите его в режиме совместимости
Режим совместимости может помочь вам запустить некоторые старые игры и приложения, которые Windows 10 не поддерживает по умолчанию.
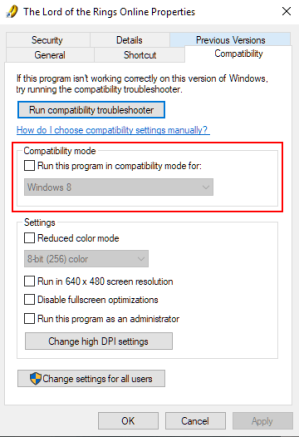
- Чтобы запустить игру в режиме совместимости, вам нужно перейти в папку, в которой находится программа или игра.
- Щелкните правой кнопкой мыши по ярлыку внутри папки и выберите «Свойства» в меню.
- Перейдите на вкладку «Совместимость» и поставьте галочку в поле «Запустить эту программу в режиме совместимости» для:

- Это позволит вам получить доступ к раскрывающемуся меню, в котором вы можете выбрать более подходящую версию Windows, которая будет работать с игрой. Знание года выпуска программы или игры может помочь определить версию Windows, которая работает лучше всего.
- Выбрав ОС Windows, сохраните настройки, нажав кнопку «ОК».
Отключить полноэкранную оптимизацию
Мониторы с высоким разрешением отлично подходят для новых игр. Не так много для старых игр, которые никогда не предназначались для игры в таком высоком разрешении. Существует вероятность того, что игра может даже не запуститься, если разрешение монитора установлено слишком высоким. Что вы можете попробовать, так это отключить полноэкранную оптимизацию.
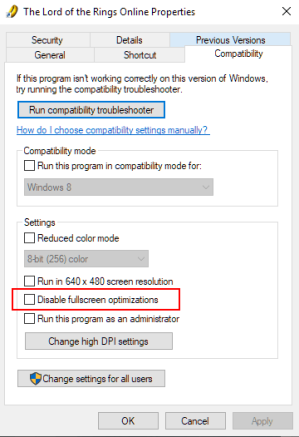
- Вам нужно будет зайти в папку с игрой, где находится файл .exe. Щелкните правой кнопкой мыши и в меню выберите «Свойства».
- Откройте вкладку «Совместимость» и поставьте галочку в поле «Отключить полноэкранные оптимизации».
- Нажмите кнопку ОК, чтобы сохранить изменения.
Обновления драйвера видеокарты
Устаревшие драйверы графического процессора могут вызвать у вас несколько головных болей. Одной из которых является ошибка bad_module_info.
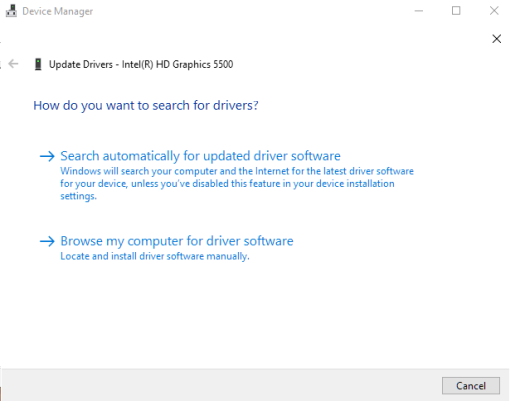
- Проверьте наличие последней версии драйверов вашей видеокарты, перейдя в диспетчер устройств. Вы можете попасть туда, щелкнув правой кнопкой мыши на панели задач и выбрав ее в меню. Не видите это там? Введите диспетчер устройств в строке поиска Cortana и выберите, когда он появится в списке.
- Разверните раздел « Адаптеры дисплея », чтобы увидеть список доступных графических процессоров. У большинства владельцев ПК будет только один. Щелкните правой кнопкой мыши и выберите «Обновить драйвер».

- Вам предоставляется два варианта обновления. Автоматическая опция заставит Windows искать обновления на вашем ПК и в Интернете. Переход по ручному маршруту потребует, чтобы вы нашли и установили обновление самостоятельно.
Не забывайте постоянно обновлять все программное обеспечение и прошивки, чтобы избежать многих проблем в будущем.
Изменение виртуальной памяти
Это исправление предназначено для тех, кто все еще использует версию Windows 10 1709 на твердотельном диске.
- Зайдите в свою панель управления и поменяйте местами View by: на маленькие или большие значки, чтобы упростить задачу.
- В списке вариантов найдите и нажмите «Система».

- Нажмите на Дополнительные настройки системы в левом боковом меню, чтобы открыть новое окно.

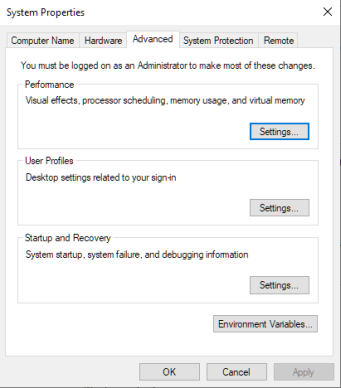
- В окне «Свойства системы» перейдите на вкладку «Дополнительно» и нажмите кнопку «Настройки…» в разделе «Производительность».

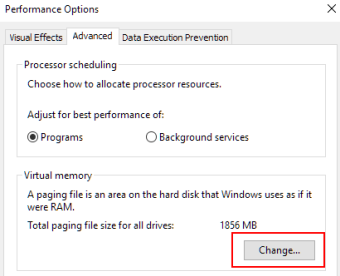
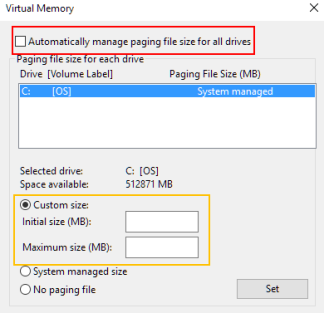
- Перейдите на вкладку «Дополнительно» в этом окне и нажмите «Изменить», расположенную в разделе «Виртуальная память». Снимите флажок «Автоматически управлять размером файла подкачки для всех дисков» и установите переключатель «Пользовательский размер:».

- Введите пользовательские значения (в мегабайтах) в соответствующие поля. Нажмите OK во всех открытых окнах, когда закончите.

Попробуйте переустановить
Если ни одно из решений до сих пор не сработало, проблема может быть не в вашей операционной системе, а в самой программе. У нас есть еще две вещи, которые мы можем попробовать, первая из которых — новая переустановка.
- Вернувшись в панель управления, переключите вид: на значок «большой» или «маленький» и щелкните ссылку «Программы и компоненты».
- Этот шаг может занять некоторое время в зависимости от того, сколько программ вы установили. Дождитесь загрузки всех установленных функций и программ для поиска проблемной. Как только вы сможете, щелкните левой кнопкой мыши на программе и нажмите «Удалить».

- Разрешить изменения на вашем компьютере, чтобы иметь место. Возможно, вам придется нажимать несколько всплывающих кнопок, пока программа не будет полностью удалена. После завершения удаления перезагрузите компьютер.
- Переустановите игру и попробуйте снова.
Обновление BIOS
Последнее, что вы можете сделать, и вы, безусловно, должны сохранить это навсегда, это обновить BIOS. Вам нужно знать модель и производителя для вашей материнской платы, так что делайте это заранее, если вы не уверены.
- Запустите командную строку и выполните следующую команду:

- Запишите информацию и перейдите на сайт производителя, чтобы загрузить и установить обновление BIOS. Следуйте инструкциям производителя.
- После обновления BIOS вы можете попытаться запустить игру еще раз.

До сих пор не работает
Есть большая вероятность, что если вы все еще получаете сообщение об ошибке, часть оборудования может быть повреждена. Вероятным виновником будет GPU. Пока вы чувствуете себя комфортно, откройте свой компьютер и посмотрите. Следите за всем очевидным, что может быть причиной ваших бед. При необходимости заменить оборудование.