Всякий раз, когда вы покупаете новое устройство Windows от производителя, отличного от самой Microsoft, продукт по умолчанию поставляется с антивирусом McAfee. Теперь определенно лучше иметь антивирусную программу на своем компьютере, чем полностью зависеть от Защитника Windows. Однако, если вы доверяете любой другой антивирусной защите вместо McAfee для защиты вашего компьютера; необходимо удалить антивирус McAfee.
С другой стороны, вы можете быть довольны антивирусом McAfee и просто захотеть временно отключить его, чтобы установить приложение неизвестного издателя или протестировать свои собственные приложения в разработке, или вы можете попробовать то, что другое антивирусное программное обеспечение может предложить вместо Макафи.
Какой бы ни была ваша причина отключить или удалить программу, это пошаговое руководство определенно поможет вам пройти этот процесс намного быстрее и удобнее. Поэтому без лишних слов давайте сначала начнем с отключения антивируса McAfee, а затем перейдем к процессу удаления программного обеспечения.
Временно отключите антивирусную защиту на вашем ПК
Временное отключение антивируса McAfee не является геркулесовой задачей, на самом деле вам просто нужно отключить защиту, и вы можете настроить ее на автоматическое включение по истечении желаемого периода времени.
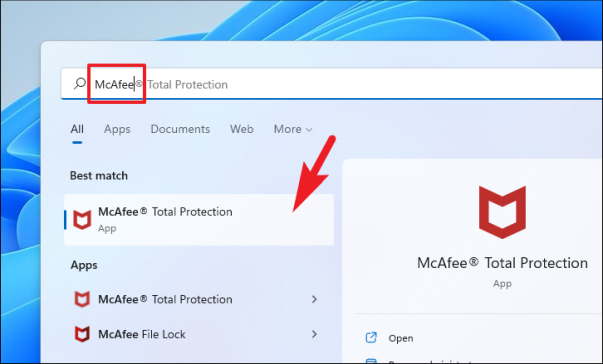
Для этого щелкните правой кнопкой мыши значок McAfee Antivirus в разделе значков на панели задач и выберите параметр «Открыть McAfee» в контекстном меню, чтобы открыть приложение, или выполните поиск приложения в меню «Пуск».

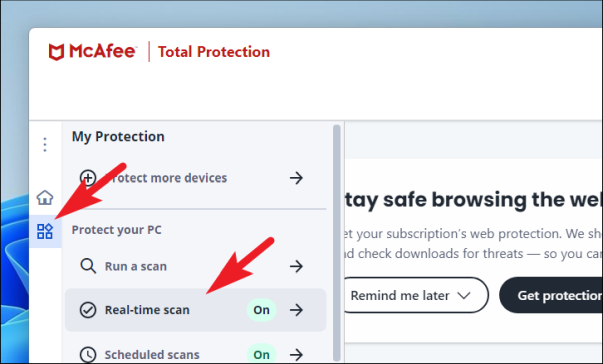
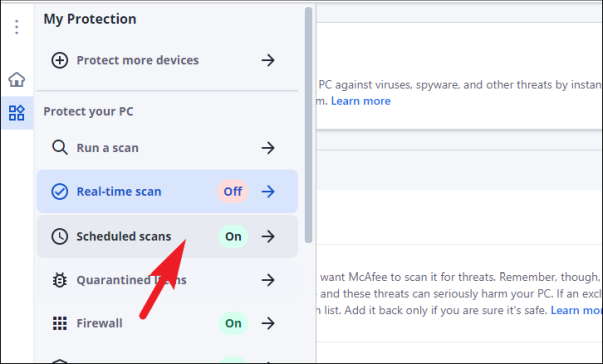
Затем в окне «McAfee» щелкните вкладку «Моя защита», чтобы открыть боковую панель. Затем найдите и щелкните параметр «Сканирование в реальном времени» на левой боковой панели, чтобы продолжить.
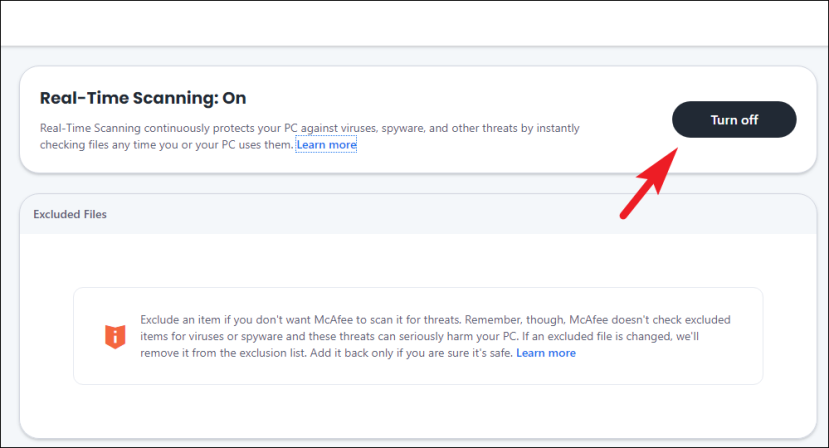
Затем на экране «Сканирование в реальном времени» нажмите кнопку «Выключить». На экране появится отдельное окно наложения.

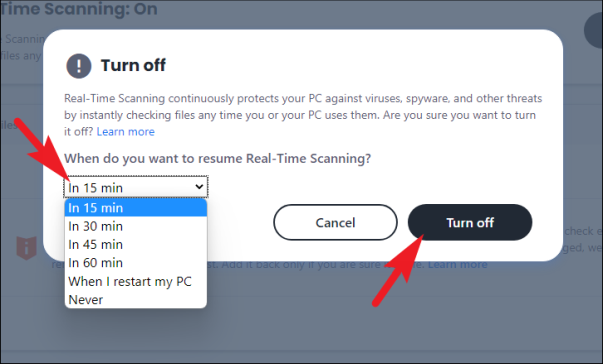
Теперь щелкните раскрывающееся меню и выберите предпочтительную продолжительность времени, если вы хотите включить защиту автоматически. Если вы хотите включить защиту вручную, выберите вариант «Никогда». Затем нажмите кнопку «Выключить» в правом нижнем углу панели, чтобы отключить сканирование McAfee в реальном времени.
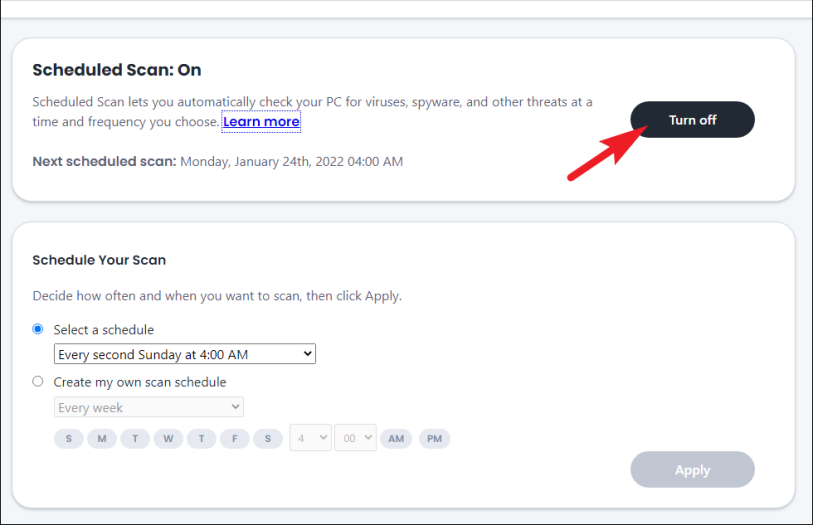
После того, как вы отключили сканирование в реальном времени, щелкните параметр «Сканирование по расписанию», расположенный на левой боковой панели прямо под параметром «Сканирование в реальном времени». Это откроет отдельное окно на вашем экране.
Теперь нажмите кнопку «Отключить» на экране «Сканирование по расписанию», чтобы полностью отключить службы запланированного сканирования.

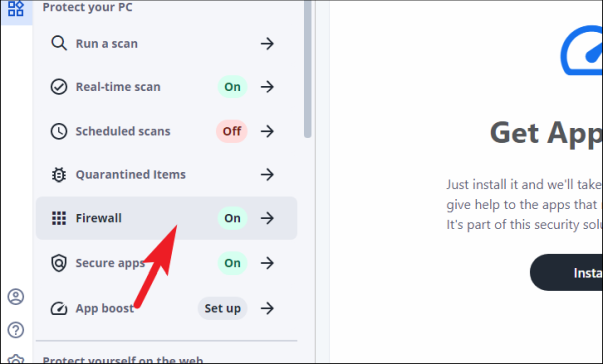
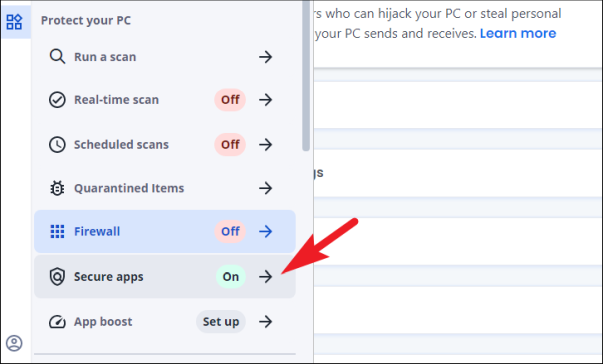
После этого, аналогично предыдущим шагам, нажмите на вкладку «Брандмауэр», расположенную на левой боковой панели. Это приведет вас к экрану настроек «Брандмауэр».
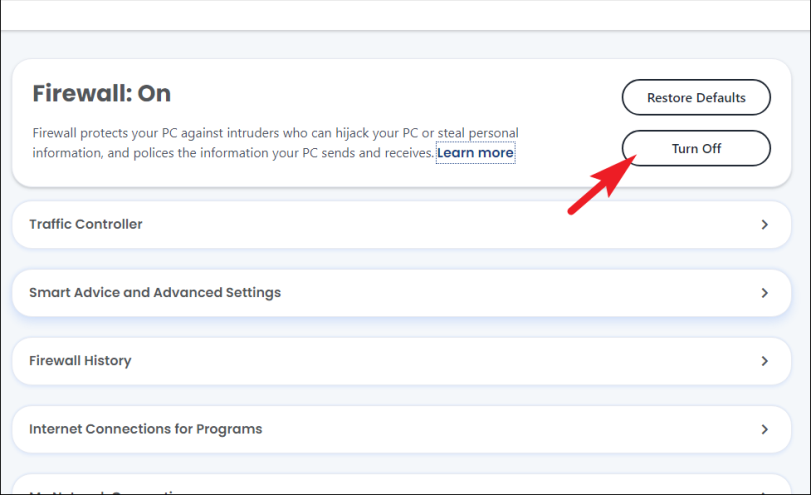
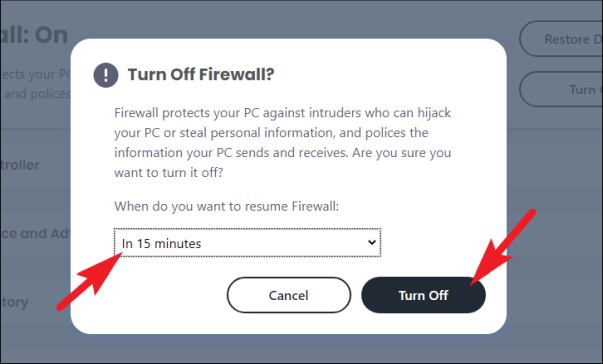
Теперь нажмите кнопку «Выключить» на экране «Настройки брандмауэра», чтобы продолжить. Это откроет отдельное окно наложения на вашем экране.

Затем щелкните раскрывающееся меню на панели наложения «Отключение брандмауэра» и выберите продолжительность, по истечении которой вы хотите повторно активировать защиту. Если вы хотите повторно активировать его вручную, выберите параметр «Никогда», а затем нажмите кнопку «Выключить» на панели, чтобы отключить брандмауэр.
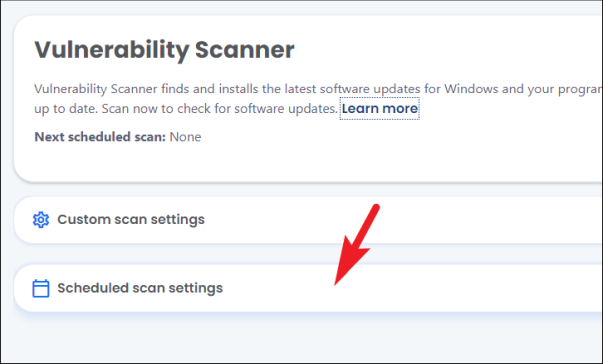
После этого нажмите на опцию «Безопасные приложения» на боковой панели, чтобы продолжить. Вы перейдете на страницу настроек «Сканер уязвимостей».
Затем на странице настроек «Сканер уязвимостей» щелкните плитку «Настройки запланированного сканирования», чтобы открыть параметры.
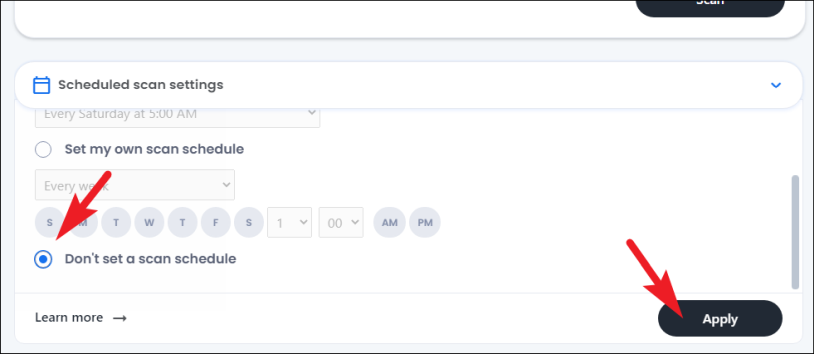
После этого прокрутите вниз показанные параметры, пока не найдете «Не устанавливать расписание сканирования», и щелкните переключатель, предшествующий параметру. Затем нажмите кнопку «Применить», чтобы сохранить изменения.

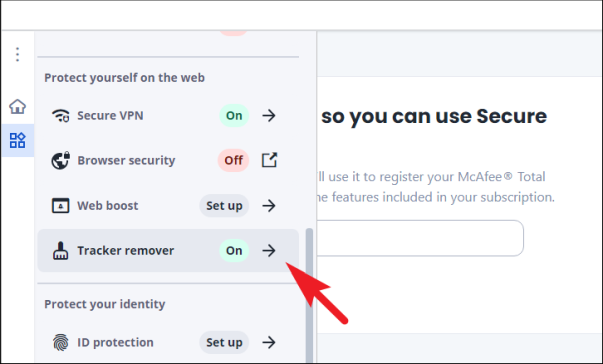
Затем прокрутите открывшуюся боковую панель вниз, пока не найдете раздел «Защитите себя в Интернете», затем щелкните плитку «Удаление трекера».
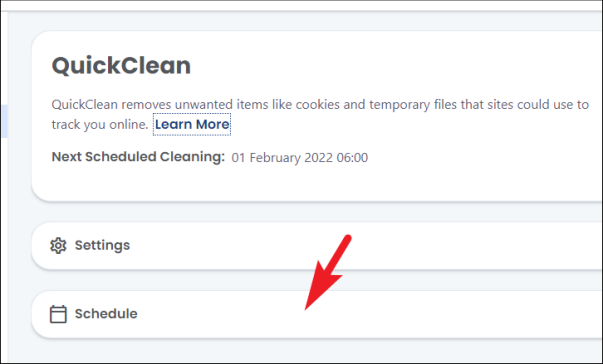
Затем щелкните плитку «Расписание», чтобы открыть настройки планирования функции.
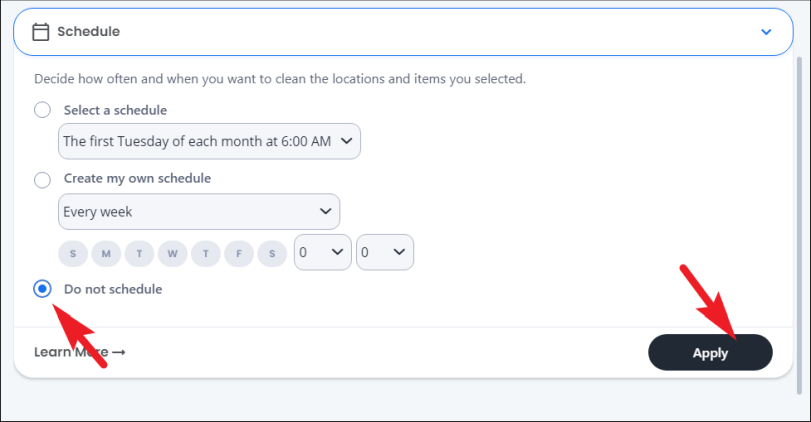
Теперь прокрутите вниз, чтобы найти параметр «Не планировать», и щелкните переключатель перед параметром для выбора. Затем нажмите кнопку «Применить», чтобы сохранить изменения.

Вот и все, вы отключили все службы McAfee в своей системе. Если вы хотите полностью удалить приложение из своей системы, перейдите к следующему разделу.
Полностью удалите McAfee с вашего ПК с Windows
Удаление приложения никогда не бывает громоздким процессом, и это утверждение верно и в этом случае. Интересно, что существует несколько способов удалить антивирус McAfee с вашего ПК с Windows 11.
Удалите McAfee из приложения «Настройки».
Самый удобный способ удалить антивирус McAfee из вашей системы — через приложение «Настройки». Это быстро, просто и легко. Таким образом, это первый метод в списке.
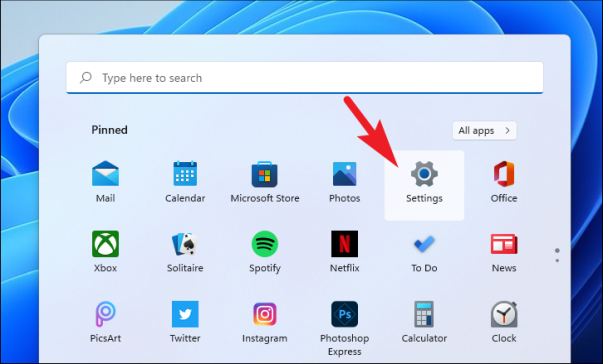
Чтобы удалить McAfee с помощью этого метода, откройте приложение «Настройки» либо из закрепленных приложений в меню «Пуск», либо выполнив поиск. Кроме того, вы также можете открыть приложение «Настройки», одновременно нажав клавиши «Windows+» I на клавиатуре.
Затем нажмите на вкладку «Приложения» на левой боковой панели окна «Настройки».
После этого щелкните плитку «Приложения и функции» в правой части окна.
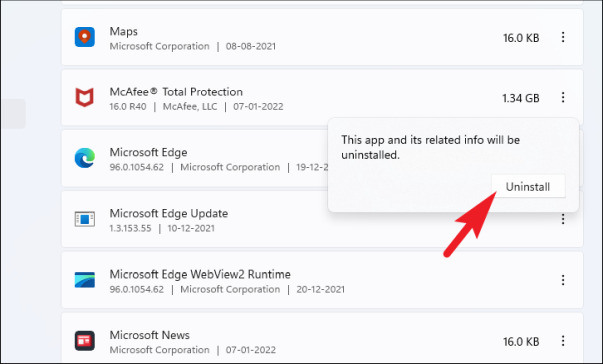
Затем в разделе «Список приложений» найдите «McAfee», либо прокрутив вручную, либо выполнив поиск с помощью имеющейся панели «поиска».
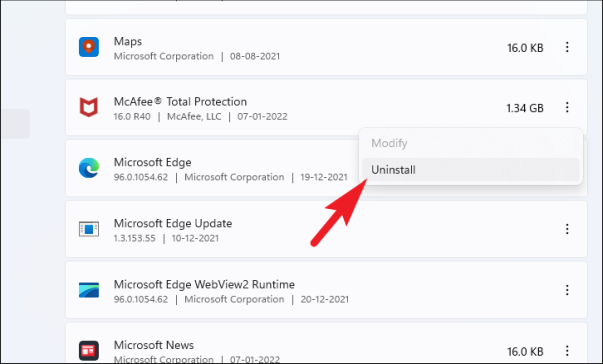
После обнаружения щелкните меню кебаба в дальнем правом краю каждой плитки и нажмите кнопку «Удалить» в контекстном меню, чтобы запустить программу удаления McAfee в отдельном окне.
Затем снова нажмите кнопку «Удалить», чтобы начать процесс удаления.
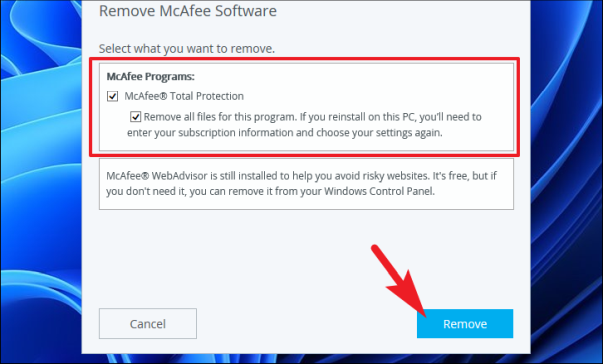
Как только программа удаления появится на экране, установите флажок перед каждым параметром в разделе «Выберите, что вы хотите удалить», чтобы выбрать все продукты McAfee, установленные в вашей системе. Затем нажмите кнопку «Удалить», чтобы продолжить.
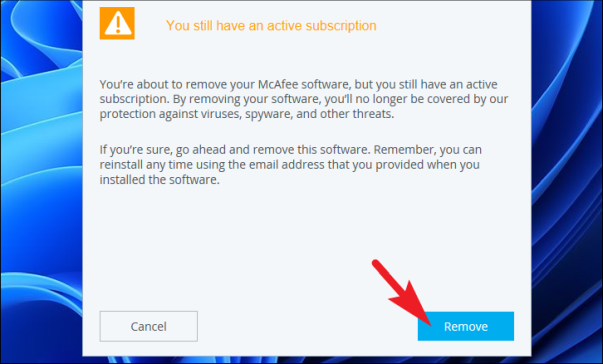
После этого на следующем экране, если у вас есть активная подписка в вашей учетной записи, McAfee уведомит вас об этом. Внимательно прочитайте информацию и нажмите кнопку «Удалить».
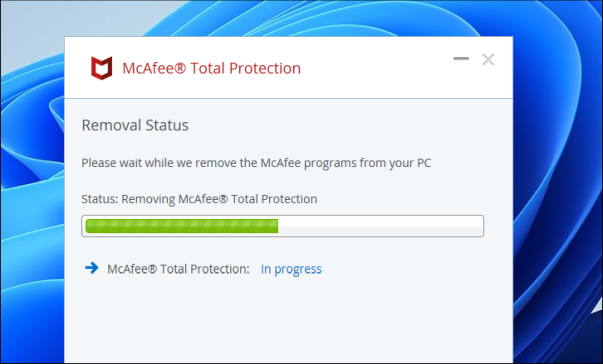
Теперь McAfee удалит выбранные продукты, терпеливо подождите, пока процесс будет работать в фоновом режиме.
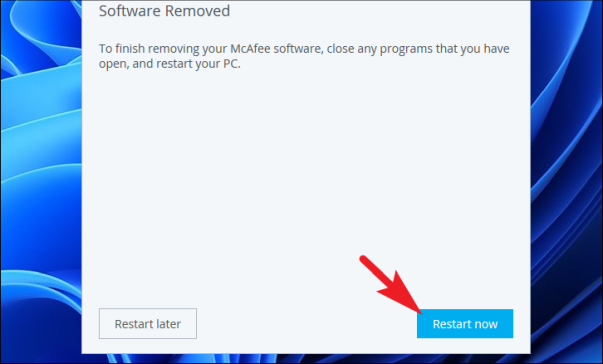
Как только продукты будут полностью удалены, вы получите уведомление об этом в окне удаления. Чтобы завершить удаление, вам придется перезагрузить компьютер с Windows, нажать кнопку «Перезагрузить сейчас», чтобы перезагрузить компьютер, и завершить установку.
Удаление McAfee с помощью McAfee Product Removal Tool
Если погружение в настройки слишком сложно для вас, чтобы удалить приложение, или обычное удаление не работает в вашей системе по какой-либо причине, вы можете использовать инструмент удаления от самого McAfee, чтобы удалить все следы программного обеспечения из вашей системы.
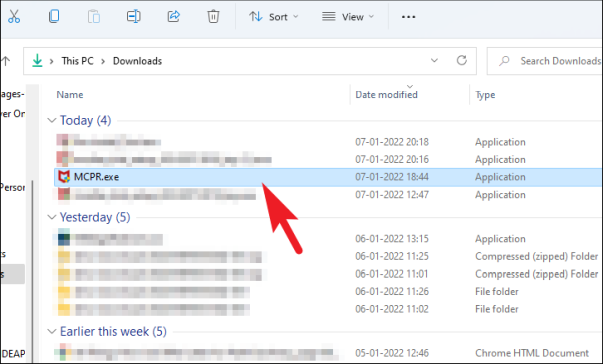
Сначала загрузите McAfee Product Removal Tool (MCPR) на свой ПК с Windows 11. После загрузки перейдите в каталог загрузок по умолчанию и дважды щелкните .EXEфайл, который вы только что скачали, чтобы запустить инструмент.
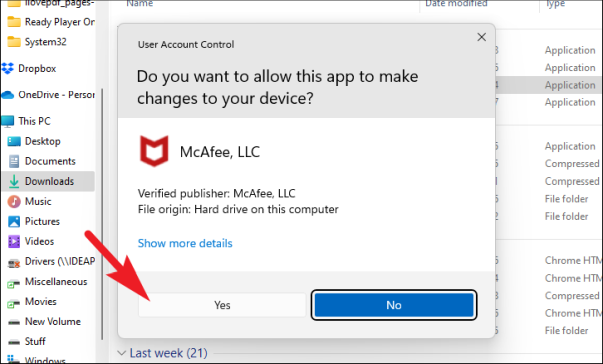
После этого на вашем экране может появиться экран UAC. Если вы не вошли в систему с учетной записью администратора, введите учетные данные для нее. В противном случае нажмите кнопку «Да», чтобы продолжить.
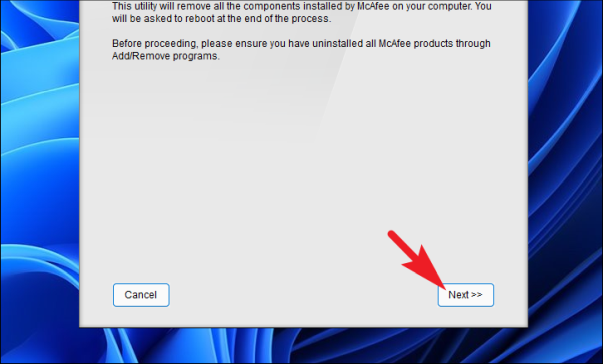
Теперь на экране MCPR нажмите кнопку «Далее», чтобы продолжить процесс удаления.
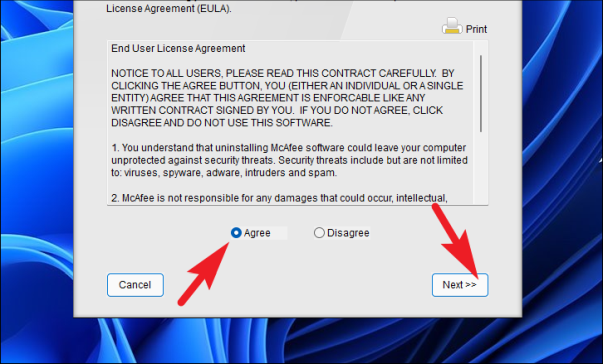
На следующем экране нажмите переключатель перед опцией «Согласен», а затем нажмите кнопку «Далее», чтобы продолжить.
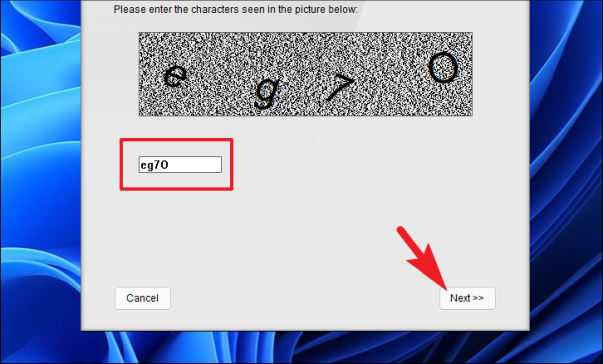
После этого введите текст CAPTCHA в текстовом поле, представленном на изображении, отображаемом в окне, и нажмите кнопку «Далее», чтобы подтвердить его и двигаться вперед.
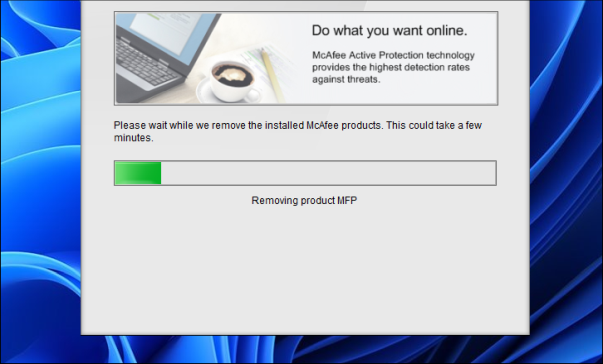
Теперь на следующем экране McAfee Product Removal Tool обнаружит все установленные продукты в вашей системе и полностью удалит их из вашей системы.
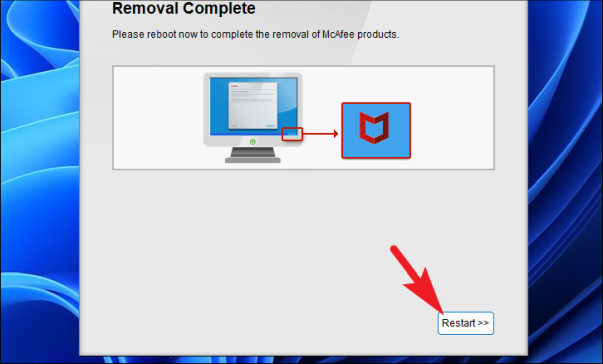
Как только процесс будет запущен, MCPR уведомит об этом в окне. Теперь нажмите кнопку «Перезагрузить», расположенную в правом нижнем углу окна, чтобы перезагрузить компьютер и завершить процесс.
Вот и все, это все способы, которыми вы можете отключить или удалить McAfee с вашего ПК с Windows 11.
https://www.youtube.com/watch?v=jyzrP0xSG_M
2022-01-24T13:26:25
Вопросы читателей