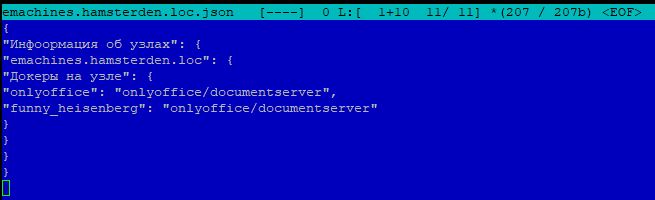
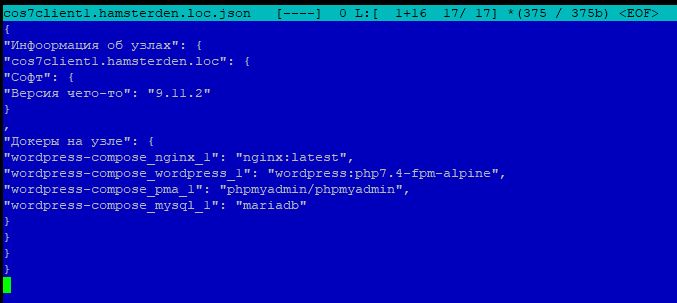
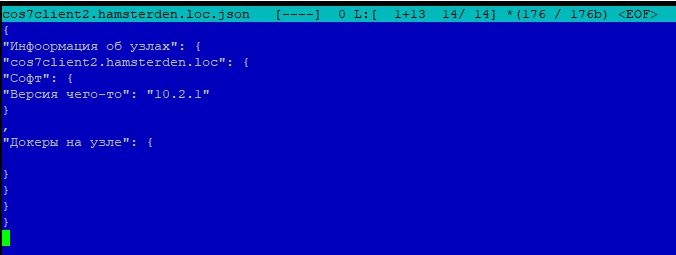
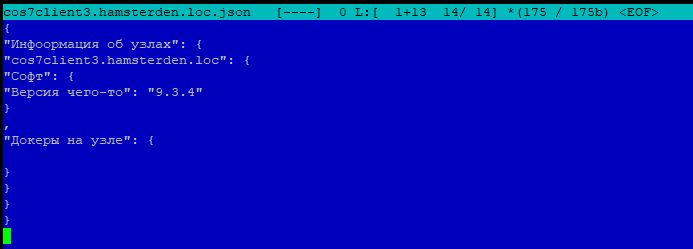
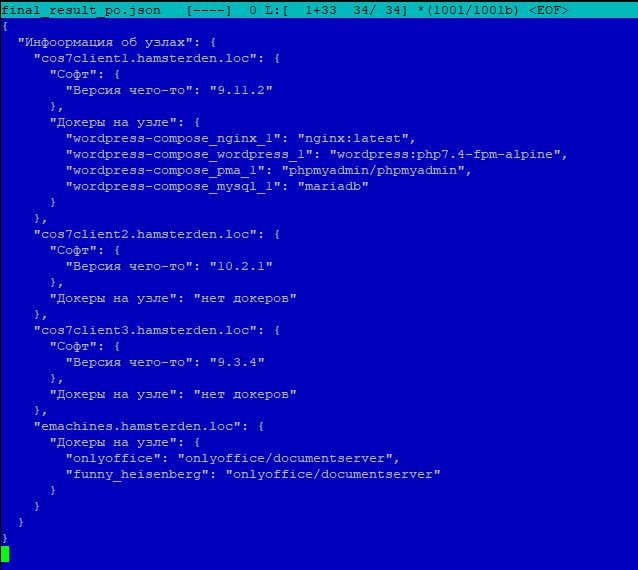
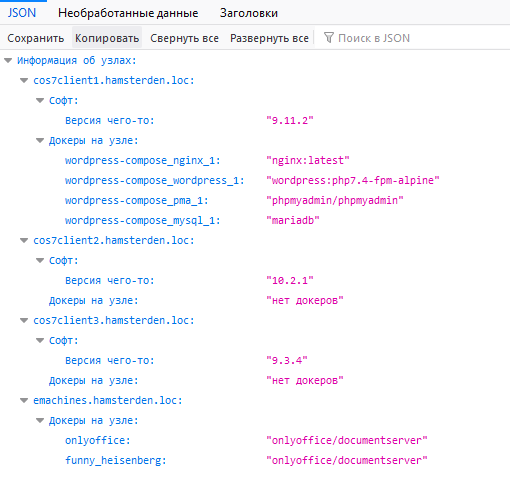
На чем было опробовано:
- Ansible 2.9.18
- Hyper-V на Windows 10 Pro.
- Сервер Ansible: CentOS Linux release 7.9.2009 (Core).
- Node 1: CentOS Linux release 7.9.2009 (Core).
- Node 2: CentOS Linux release 7.9.2009 (Core).
- Node 3: CentOS Linux release 7.9.2009 (Core).
1. Введение.
Как установить и первоначально настроить Ansible описано здесь:
Ссылка: «Ansible: Часть 1. Описание, установка и первоначальная настройка.»
Так как простые задачи для Ansible реально простые, в буквальном смысле слова, то я принял решение вынести их в отдельную инструкцию:
Ссылка: «Ansible: Часть 2. Примеры простых задач.»
Рассмотрим структуру и правила написания таких сценариев более подробно.
Ссылка: «Ansible: Часть 3. Сценарии (плейбуки) — Playbooks.»
По данной ссылке я создам небольшую подборку самых интересных и типовых плейбуков, которые могут пригодиться вам в повседневной работе.
Ссылка: «Ansible: Часть 4. Практические примеры плейбуков.»
2. Ansible Vault для хранения конфиденциальных данных.
Если ваши плейбуки Ansible содержат конфиденциальные данные, такие как пароли, ключи API и учетные данные, важно обеспечить их безопасность с помощью шифрования. Ansible предоставляет ansible-vault для шифрования файлов и переменных.
Несмотря на то, что любой файл данных Ansible, а также двоичные файлы, возможно зашифровать изначально, чаще для шифрования переменных файлов, содержащих конфиденциальные данные, используется ansible-vault. После шифрования файла с помощью этого инструмента вы сможете выполнять, редактировать или просматривать его, только предоставив соответствующий пароль, указанный при первом шифровании файла.
2.1. Создание нового зашифрованного файла.
Вы можете создать новый зашифрованный файл Ansible с помощью:
# ansible-vault create credentials.yml
Эта команда выполнит следующие действия:
- Сначала вам будет предложено ввести новый пароль. Вам нужно будет указывать этот пароль при каждом доступе к содержимому файла, будь то редактирование, просмотр или просто запуск плейбука или команд с использованием его значений.
- Затем откроется редактор командной строки по умолчанию, чтобы вы могли заполнить файл требуемым содержимым.
- Наконец, когда вы закончите редактирование,
ansible-vault сохранит файл как зашифрованный.
2.2. Шифрование существующего файла.
Чтобы зашифровать существующий файл Ansible, вы можете использовать следующую команду:
# ansible-vault encrypt credentials.yml
Эта команда запросит у вас пароль, который вам нужно будет вводить при каждом доступе к файлу credentials.yml.
2.3. Просмотр содержимого зашифрованного файла.
Если вы хотите просмотреть содержимое файла, который ранее был зашифрован с помощью ansible-vault, и вам не нужно изменять его содержимое, вы можете использовать команду:
# ansible-vault view credentials.yml
Она предложит вам указать пароль, который вы выбрали при первом шифровании файла с помощью ansible-vault.
2.4. Редактирование зашифрованного файла.
Чтобы изменить содержимое файла, который ранее был зашифрован с помощью ansible-vault, выполните:
# ansible-vault edit credentials.yml
Эта команда предложит вам указать пароль, который вы выбрали при первом шифровании файла credentials.yml. После проверки пароля откроется редактор командной строки по умолчанию с незашифрованным содержимым файла, что позволит вам внести нужные изменения. По завершении вы можете сохранить и закрыть файл, как обычно, и обновленное содержимое будет сохранено и зашифровано.
2.5. Расшифровка файлов.
Если вы хотите навсегда расшифровать файл, ранее зашифрованный с помощью ansible-vault, вы можете сделать это с помощью следующего синтаксиса:
# ansible-vault decrypt credentials.yml
Эта команда предложит вам ввести тот пароль, который использовался при первом шифровании файла. После проверки пароля содержимое файла будет сохранено на диск в виде незашифрованных данных.
3. Использование нескольких паролей.
Ansible поддерживает для хранилища несколько паролей, сгруппированных по разным идентификаторам. Это полезно, если вы хотите иметь выделенные пароли хранилища для различных сред – для разработки, тестирования и производства.
Чтобы создать новый зашифрованный файл с пользовательским идентификатором хранилища, включите параметр --vault-id вместе с меткой и расположением, где ansible-vault может найти пароль для этого хранилища. Метка может быть любой, а расположение может быть либо prompt (что означает, что команда должна предложить вам ввести пароль), либо путь к файлу паролей.
# ansible-vault create --vault-id dev@prompt credentials_dev.yml
Это создаст новый идентификатор по имени dev, который использует prompt для получения пароля. Комбинируя этот метод с файлами переменных группы, вы сможете создать отдельные хранилища для каждой среды приложения:
# ansible-vault create --vault-id prod@prompt credentials_prod.yml
Мы использовали dev и prod в качестве идентификаторов хранилищ, чтобы продемонстрировать, как вы можете создавать отдельные хранилища для каждой среды. Самостоятельно вы можете создать столько хранилищ, сколько захотите, и использовать любой ID.
Теперь, чтобы просмотреть, отредактировать или расшифровать эти файлы, вам необходимо предоставить тот же ID хранилища и источник пароля вместе с командой ansible-vault:
# ansible-vault edit credentials_dev.yml --vault-id dev@prompt
4. Использование файла паролей.
Если вам нужно автоматизировать процесс инициализации серверов в Ansible с помощью стороннего инструмента, вам потребуется способ ввода пароля хранилища без его запроса. Вы можете сделать это, используя файл паролей через ansible-vault.
Файл паролей может быть простым текстовым файлом или исполняемым скриптом. Если файл является исполняемым, выходные данные, созданные ним, будут использоваться в качестве пароля хранилища. В противном случае в качестве пароля хранилища будет использоваться необработанное содержимое файла.
Чтобы применить файл паролей в ansible-vault, необходимо указать путь к файлу паролей при выполнении любой из команд vault:
# ansible-vault create --vault-id dev@path/to/passfile credentials_dev.yml
Ansible не различает контент, который был зашифрован с помощью prompt, и простой файл пароля при условии, что входной пароль один и тот же. С практической точки зрения это означает, что файл можно зашифровать, используя prompt, а затем создать файл пароля для хранения того же пароля, который использовался в методе prompt. Также верно и обратное: вы можете зашифровать содержимое, используя файл паролей, а затем использовать метод prompt, предоставляя тот же пароль при запросе Ansible.
Для большей гибкости и безопасности, чтобы не хранить свой пароль в текстовом файле, вы можете использовать скрипт Python для получения пароля из других источников.
Официальный репозиторий Ansible содержит несколько примеров сценариев, которые вы можете использовать для справки при создании своего скрипта под потребности вашего проекта.
5. Запуск плейбука с зашифрованными данными.
Каждый раз, когда вы запускаете плейбук, в котором используются данные, ранее зашифрованные с помощью ansible-vault, вам нужно будет указывать пароль хранилища в команде playbook.
Если вы использовали параметры по умолчанию и prompt при шифровании данных плейбука, вы можете использовать опцию --ask-vault-pass, чтобы Ansible запрашивал пароль:
# ansible-playbook myplaybook.yml --ask-vault-pass
Если вы использовали файл пароля вместо prompt, вы должны использовать опцию --vault-password-file:
# ansible-playbook myplaybook.yml --vault-password-file my_vault_password.py
Если вы используете данные, зашифрованные с помощью ID, вам нужно указать тот же ID хранилища и источник пароля, который вы использовали при первом шифровании данных:
# ansible-playbook myplaybook.yml --vault-id dev@prompt
Если вы используете файл пароля с ID, вы должны указать метку, а затем полный путь к файлу пароля в качестве источника:
# ansible-playbook myplaybook.yml --vault-id dev@vault_password.py
Если ваш play использует несколько хранилищ, вы должны добавить параметр --vault-id для каждого из них в произвольном порядке:
# ansible-playbook myplaybook.yml --vault-id dev@vault_password.py --vault-id test@prompt --vault-id ci@prompt
6. Оригиналы источников информации.
- selectel.ru «Система управления конфигурацией Ansible».
- dmosk.ru «Инструкция по установке и запуску Ansible на CentOS».
- dmosk.ru «Что такое ansible».
- 8host.com «Как работать с Ansible: простая удобная шпаргалка».
- habr.com «Автоматизируем и ускоряем процесс настройки облачных серверов с Ansible. Часть 1: Введение».
- kamaok.org.ua «Установка и использование Ansible на Centos7».
- Источник: https://hamsterden.ru/ansible-vault-playbooks/
2021-09-01T15:40:11
Software