В ближайшее время нас ждет ряд новых интересных изменений в Windows 11, а именно в сборке 23506. На этот раз изменения, причем весьма значительные, коснуться раздела «Использование батареи» в приложении «Параметры». Кроме того, сборка 23506 получит новые элементы экрана OOBE, новый помощник по совместимости программ, улучшения функции автоматического управления цветом, а также поддержку плагинов модулем Windows Copilot. Читать
Как изменить тему Windows 10
Хотя лишь немногие люди индивидуализируют внешний вид своего ноутбука или настольного ПК, некоторые одержимы этим аспектом. К счастью, Windows 10 универсальна, когда дело доходит до настройки, а смена темы позволяет одновременно изменять несколько визуальных элементов и звуковых эффектов. Вы можете изменить фон, цвет, звук и курсор мыши всякий раз, когда выбираете новую тему. Вот как изменить тему на вашем компьютере или устройстве с Windows 10.
Что такое тема Windows 10?
Тема — это не просто обои, которые вы видите на рабочем столе Windows 10, а набор настроек, которые изменяют внешний вид и звуки операционной системы. Хотя большинство тем изменяют только цветовую схему и обои, используемые в Windows 10, некоторые также могут изменять звуковую схему, внешний вид курсора мыши и даже стандартные значки рабочего стола.
Вы можете настроить отдельные элементы, такие как звуки или курсор мыши, не меняя активную тему. Однако Windows 10 будет считать, что вы используете настраиваемую тему, как только вы измените какие-либо настройки вашей темы по умолчанию.
Как изменить тему в Windows 10
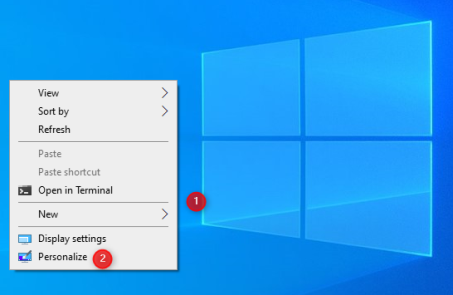
Изменение темы в Windows 10 осуществляется из приложения «Настройки». Поэтому вы либо открываете «Настройки» (Windows+I) и переходите в «Персонализация», либо щелкаете правой кнопкой мыши (или нажимаете и удерживаете) на свободной области рабочего стола и выбираете «Персонализация».
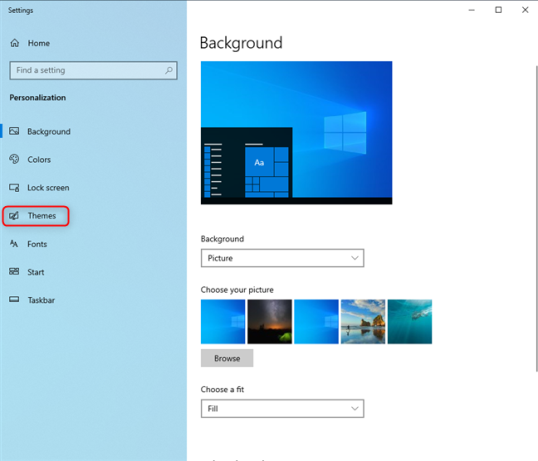
Сначала вы увидите раздел «Фон». Здесь вы можете изменить обои рабочего стола в Windows 10. Чтобы изменить тему, пропустите этот раздел и выберите Темы в столбце слева.
В верхней части раздела «Темы» справа вы видите элементы, из которых состоит ваша Текущая тема: ее фон, цвет, звуки и курсор мыши. Прокрутите вниз до раздела «Изменить тему», чтобы найти все темы, установленные на вашем компьютере или устройстве с Windows 10.
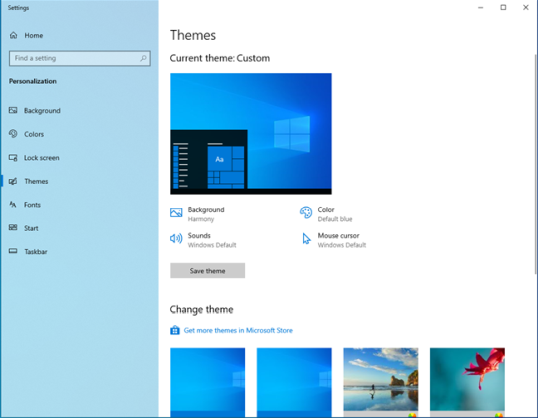
К сожалению, в Windows 10 есть только несколько встроенных тем:
- Windows — тема по умолчанию с одним фоновым рисунком с логотипом Windows 10.
- Windows (светлая) — разновидность темы по умолчанию, которая также включает светлый режим в Windows 10.
- Windows 10 — тема, содержащая слайд-шоу из пяти красивых обоев.
- Цветы — еще одна тема с шестью обоями с цветами.
Список короткий, не так ли? О, и нет темы Dark Mode. Вместо этого в Windows 10 есть темный режим, который можно применить поверх активной темы. Чтобы переключаться между доступными темами, щелкните или коснитесь их названия.
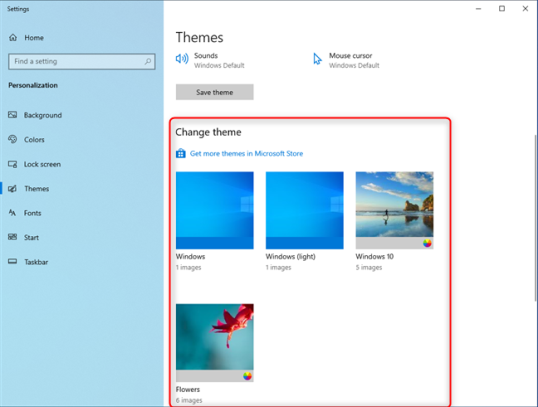
Windows 10 сразу меняет активную тему на ту, которую вы выбрали. Новая текущая тема и все ее элементы отображаются в верхней части раздела «Темы».
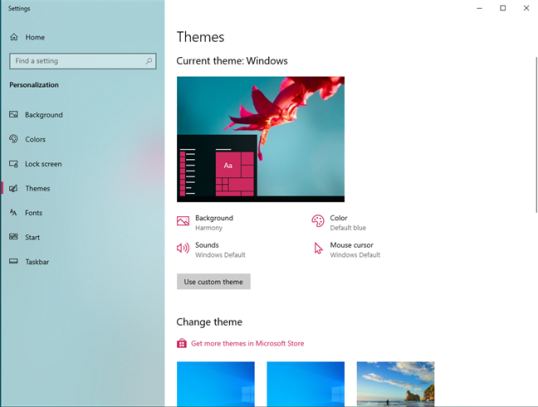
Если вы довольны своей новой темой, закройте настройки, и все готово.
Как скачать темы для Windows 10 бесплатно
Хотя вы можете искать в Bing или Google бесплатные темы для Windows 10, Microsoft также предлагает вам некоторые из них, которые можно легко загрузить. В разделе «Темы» в приложении «Настройки» прокрутите вниз до «Изменить тему». Нажмите или коснитесь ссылки «Получить больше тем в Microsoft Store».
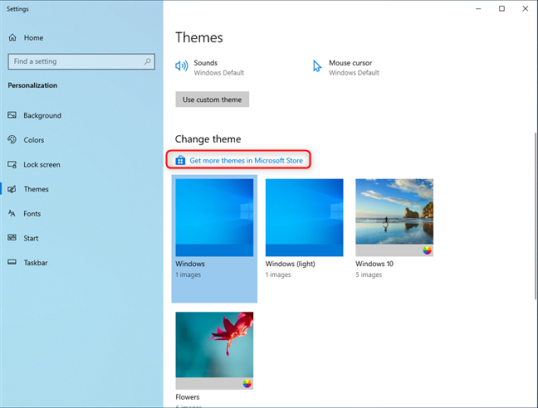
Это действие открывает Microsoft Store в разделе тем Windows, где вы найдете десятки вариантов. Просмотрите доступные. Тот, который мне нравится больше всего, находится первым в списке: цвет Pantone 2022 года. Чтобы установить тему, сначала нажмите или коснитесь ее названия.
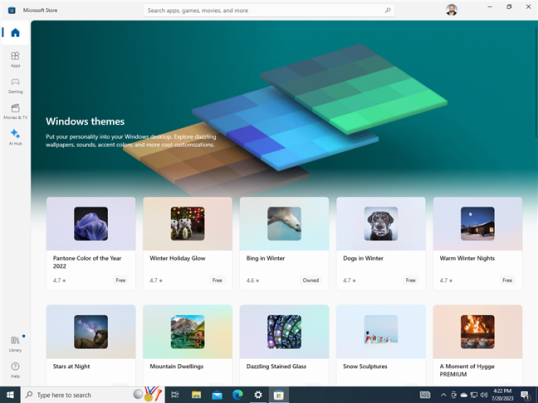
Вы видите страницу в Microsoft Store с подробной информацией о теме, снимками экрана и т. д. Чтобы ее установить, нажмите Получить.
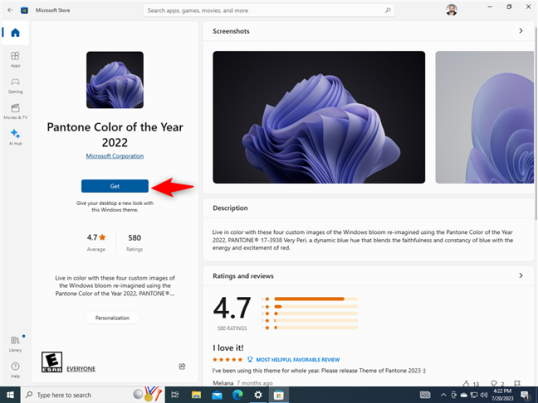
Подождите, пока тема Windows 10 будет загружена и установлена на ваш компьютер или устройство. Затем щелкните или коснитесь Открыть.
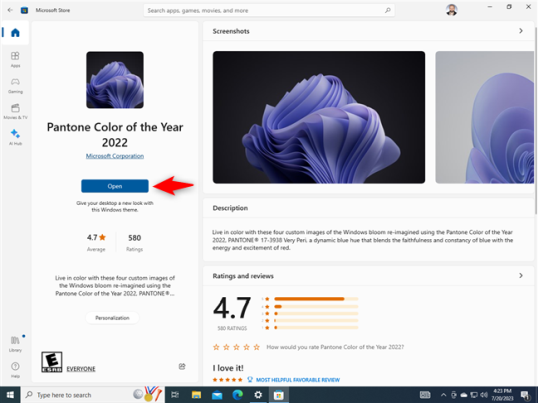
Вы вернетесь в раздел «Темы» из приложения «Настройки». Вы можете увидеть только что установленную тему справа в разделе «Изменить тему». Нажмите или коснитесь его имени, чтобы применить его.
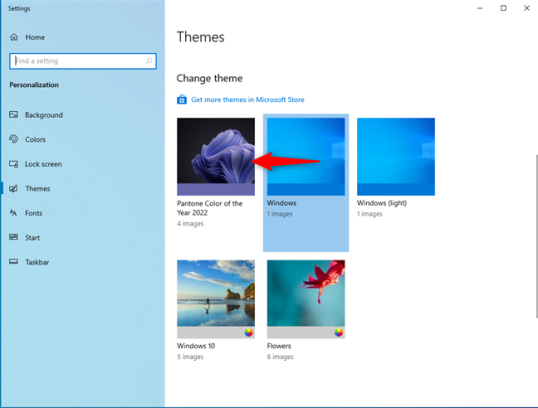
Тема Pantone Color of the Year 2022 даже круче, чем Dark Mode, который многие любят. Вы также должны попробовать это.
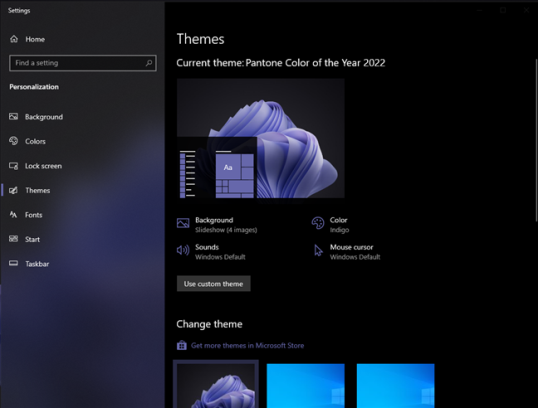
Процесс загрузки тем Windows 10 из Магазина Microsoft работает одинаково для всех доступных там тем.
БОНУС: лучшие темы для Windows 10 от Microsoft
Microsoft также создала веб-сайт с бесплатными темами, которые вы можете скачать для Windows 10 и других версий Windows. Перейти на эту страницу: Темы рабочего стола. Темы разделены на категории: животные, искусство, автомобили и т. д.
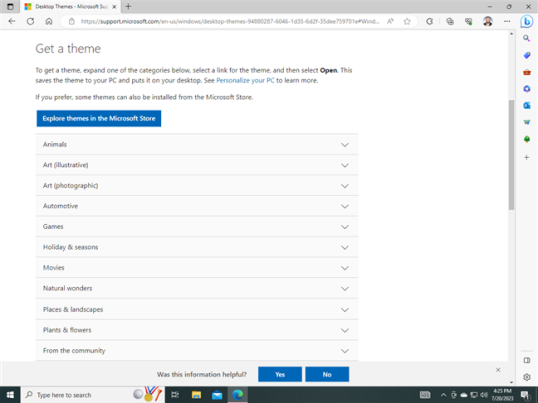
Расширьте интересующие вас категории и загрузите темы, которые кажутся вам привлекательными. Затем откройте проводник, перейдите в папку «Загрузки», и вы сможете найти там темы. Они сохраняются в виде файлов с расширением «.themepack». Дважды щелкните загруженную тему, и она будет применена автоматически.
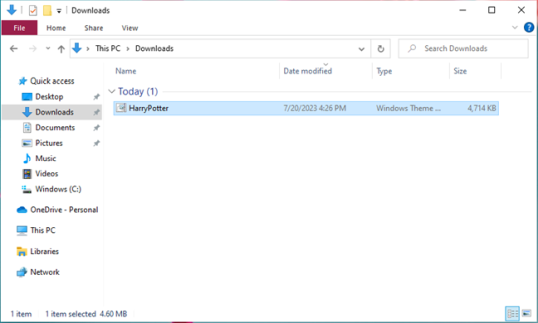
Вот тема Гарри Поттера, которую я скачал. Выглядит круто, не правда ли?

Какая тема из коллекции Microsoft вам нравится?
Как удалить тему Windows 10
Если вы скачаете и установите много тем, а потом обнаружите, что некоторые из них вам не нравятся, вы можете их удалить. Перейдите в раздел «Темы» в приложении «Настройки», как показано в первом разделе этого руководства. Прокрутите вниз до «Изменить тему» и сначала нажмите или коснитесь темы, которую вы хотите использовать в качестве текущей. Затем щелкните правой кнопкой мыши (или нажмите и удерживайте) тему, которую хотите удалить, и выберите «Удалить».
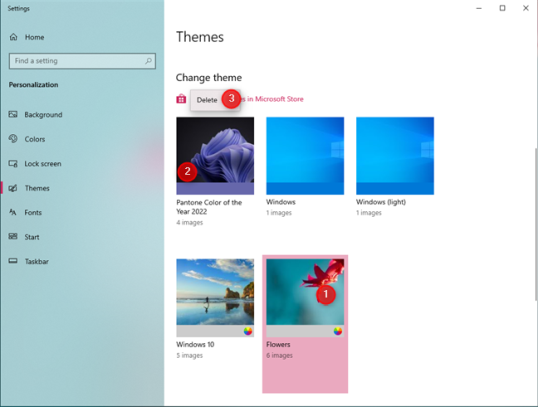
Имейте в виду, что вы не можете удалить активную тему. Вы должны сначала изменить активную тему на другую, а затем удалить тему, которая вам больше не нужна. Если вы загрузили тему в папку «Загрузки», не забудьте удалить оттуда ее файл «.themepack».
Вы нашли красивые темы для Windows 10?
Темы — отличный способ опробовать различные варианты пользовательского интерфейса, отображаемого в Windows 10. Я настоятельно рекомендую просмотреть Microsoft Store или специальный веб-сайт Microsoft и попробовать темы. Мне лично нравятся Street Views Premium и Fibonacci Sequence in Nature. А вы? Какие темы Windows 10 показались вам интересными? Поделитесь своими выводами в комментариях ниже.
2023-07-25T21:51:51
Вопросы читателей
🖧 Bash скрипт для сканирования диапазона портов
Сетевым администраторам и специалистам по безопасности часто требуется сканирование портов для выявления открытых или закрытых служб и оценки безопасности сети.
Хотя для этих целей существуют такие надежные инструменты, как nmap, иногда может потребоваться создание собственного решения, отвечающего конкретным требованиям.
Например, отсутствие возможности скачать и установить nmap.
В этой статье мы рассмотрим, как создать скрипт Bash для сканирования ряда портов.
Основы сканирования портов
Сканирование портов – это систематическая проверка системы на наличие открытых портов.
Порт в данном контексте – это логическая конструкция, идентифицирующая определенный процесс или тип сетевого сервиса.
Номера портов варьируются от 0 до 65535, причем первые 1024 известны как “общеизвестные порты”, назначаемые для таких распространенных протоколов, как HTTP (порт 80) и FTP (порт 21).
Сканирование портов позволяет определить, какие службы запущены и прослушивают соединения, что может быть особенно полезно для обнаружения потенциальных уязвимостей в системе безопасности.
Скрипт Bash для сканирования портов
Bash (Bourne Again SHell) – это мощная оболочка, с помощью которой можно создавать скрипты для автоматизации задач в среде Linux.
Наш скрипт будет принимать два аргумента – IP-адрес для сканирования и диапазон портов для сканирования.
Вот простой скрипт на Bash, который сканирует ряд портов:
#!/bin/bash
ip=$1
startport=$2
endport=$3
function portscan {
for ((counter=$startport; counter<=$endport; counter++))
do
(echo > /dev/tcp/$ip/$counter) > /dev/null 2>&1 && echo "$counter open"
done
}
portscan
Принцип работы скрипта
Первая строка (#!/bin/bash): Эта строка известна как shebang.
Она сообщает системе, что данный скрипт должен быть выполнен с помощью оболочки Bash.
Строки 3-5: Сценарий принимает три аргумента. $1 – IP-адрес, $2 – номер начального порта и $3 – номер конечного порта.
Строки 7-12: Здесь определяется функция portscan, которая сканирует каждый порт в заданном диапазоне.
Она пытается перенаправить эхо-вывод на определенный порт по IP-адресу.
Если запись в port прошла успешно (значит, порт открыт), то выводится номер порта, за которым следует “open”.
Использование скрипта
Для использования необходимо предоставить ему права на выполнение и запустить его с IP-адресом и диапазоном портов для сканирования.
- Сохраните скрипт в файл, например portscan.sh
- Сделайте скрипт исполняемым: chmod +x portscan.sh
- Запустите скрипт с IP-адресом и диапазоном портов: ./portscan.sh 192.168.1.1 20 80
- Будет произведено сканирование портов с 20 по 80 на IP-адресе 192.168.1.1.
Заключение
Несмотря на то, что данный скрипт подходит для базового сканирования портов, в нем отсутствуют многие функции, присущие более продвинутым инструментам, таким как nmap, например, обнаружение служб, определение ОС и более продвинутые методы сканирования портов.
Однако он позволяет понять, как работает сканирование портов и как его можно выполнить с помощью простого скрипта Bash.
см. также:
- 👁️ Zenmap – графический интерфейс Nmap
- 🖧 Как просканировать цель с помощью Nmap?
- Как сканировать удаленный хост на открытые порты с помощью портативного сканера nmap
2023-07-24T17:36:40
Скрипты
Обработка телефонных звонков: Оптимизация эффективности и качества обслуживания
Обработка телефонных звонков играет критическую роль в бизнесе, независимо от его масштаба. Качественное обслуживание клиентов через телефонные звонки может повысить лояльность клиентов и улучшить репутацию компании. В данной статье рассмотрим стратегии и подходы к оптимизации процесса обработки телефонных звонков с целью повышения эффективности и качества обслуживания.
1. Предварительная подготовка
Перед началом обработки телефонных звонков необходимо провести подготовительную работу. Важно обеспечить сотрудников необходимой информацией о продуктах или услугах компании, а также обучить их основным принципам клиентоориентированного общения. Кроме того, необходимо установить стандарты времени ожидания звонка и разработать скрипты для обслуживания клиентов.
2. Применение технологий IVR
Интерактивная голосовая система (IVR) позволяет автоматизировать процесс маршрутизации звонков, предоставляя клиентам определенные опции для переадресации на подходящего оператора. Применение IVR помогает сократить время ожидания клиентов и уменьшить нагрузку на операторов.
3. Внедрение CRM-системы
Система управления взаимоотношениями с клиентами (CRM) является важным инструментом для эффективной обработки звонков. Она позволяет отслеживать информацию о клиентах, предыдущие взаимодействия и обращения, что помогает операторам предоставлять персонализированное обслуживание.
4. Обучение персонала
Обучение персонала является непременным этапом для повышения качества обслуживания. Обучение должно включать основы коммуникации, управления временем, разрешения конфликтов и навыки работы с технологиями обработки звонков. Регулярные тренинги и обратная связь помогут улучшить производительность операторов.
5. Мониторинг и анализ звонков
Организация мониторинга звонков позволяет оценить качество обслуживания и выявить слабые места. Это может быть осуществлено путем аудита звонков, прослушивания записей разговоров и анализа обратной связи клиентов. Проведенные анализы помогут принимать меры для улучшения процесса обработки звонков.
6. Постоянное совершенствование
Обработка телефонных звонков — процесс, который требует постоянного совершенствования. Компания должна постоянно отслеживать изменения потребностей клиентов и рыночных условий, чтобы адаптироваться к новым вызовам и тенденциям. «Звонок» — Автоматизируйте обработку входящих вызовов и избавьте сотрудников от рутины и нецелевых клиентов. Регулярные обновления и модернизации технологий также необходимы для обеспечения оптимального качества обслуживания.
Заключение
Эффективная обработка телефонных звонков — ключевой элемент успешной деятельности компании. Оптимизация процесса обработки звонков, внедрение современных технологий и обучение персонала помогут повысить качество обслуживания клиентов и укрепить позиции бизнеса на рынке. Следуя приведенным выше стратегиям, компании смогут успешно управлять потоком звонков и обеспечить высокий уровень удовлетворенности своих клиентов.
2023-07-24T16:16:49
Работа
🌐 Как разрешить в Apache только методы GET и POST
Apache HTTP Server, в просторечии называемый Apache, – одна из самых популярных и широко используемых в мире программных систем для веб-серверов.
Он обладает множеством возможностей, в том числе возможностью ограничения доступа к ресурсам на основе методов HTTP.
Это может быть особенно важно в тех случаях, когда по соображениям безопасности или логики работы приложения необходимо разрешить только определенные типы HTTP-запросов, например GET и POST.
В этой статье мы рассмотрим, как настроить веб-сервер Apache на разрешение только методов GET и POST.
Для этого необходимо отредактировать конфигурационный файл Apache, который может быть либо httpd.conf, либо apache2.conf, либо файл .htaccess, расположенный в каталоге с веб-ресурсами, которые необходимо защитить.
Примечание: Приведенные в данной статье инструкции предполагают, что у вас уже есть работающий сервер Apache.
Если это не так, то сначала необходимо установить и настроить Apache.
Шаги по ограничению методов GET и POST на Apache:
- Найдите конфигурационный файл
Расположение конфигурационного файла Apache зависит от операционной системы и способа установки.
Обычно он находится в каталоге /etc/apache2/ для систем Ubuntu/Debian и в каталоге /etc/httpd/ для систем CentOS/RHEL.
Например:
/etc/apache2/apache2.conf # Ubuntu/Debian /etc/httpd/conf/httpd.conf # CentOS/RHEL
Кроме того, для контроля доступа к определенным каталогам можно использовать файл .htaccess.
Если его нет, то можно создать его в каталоге ресурсов, которые необходимо защитить.
- Редактирование файла конфигурации
С помощью текстового редактора (например, nano, vi, emacs) откройте и отредактируйте файл конфигурации.
- Настройка контроля доступа
Чтобы разрешить только методы GET и POST, добавьте в файл следующий блок конфигурации.
Этот блок может быть размещен внутри тега для контроля, специфичного для каталога, или внутри тега для контроля, специфичного для местоположения.
<Directory "/var/www/html"> <LimitExcept GET POST> Deny from all </LimitExcept> </Directory>
В этом блоке вместо /var/www/html должен быть указан путь к директории, которую вы хотите ограничить.
Директива <LimitExcept> разрешает перечисленные методы (GET, POST) и запрещает все остальные.
- Сохранить изменения и выйти
После добавления необходимых настроек сохраните изменения и выйдите из текстового редактора.
Если вы используете nano, то это можно сделать, нажав Ctrl+X, затем Y для подтверждения сохранения изменений и, наконец, Enter для подтверждения имени файла для записи.
- Перезапустить Apache
Последний шаг – перезапуск Apache для применения изменений.
В зависимости от системы можно воспользоваться одной из следующих команд:
Теперь ваш сервер Apache должен разрешать только HTTP-запросы GET и POST к указанной директории.
Любые другие HTTP-методы, такие как PUT, DELETE, OPTIONS и т.д., будут запрещены.
Обратите внимание: методы, описанные в этой статье, предназначены для серверов с полным контролем и доступом к конфигурационным файлам.
Если вы используете тарифный план виртуального хостинга, то, возможно, у вас нет такого уровня доступа.
Обратитесь за помощью к своему хостинг-провайдеру или системному администратору.
см. также:
- 🔐 Как настроить файл htaccess в Apache на CentOS/RHEL
- 🔎 Парсинг полезной информации из логов сервера Apache с помощью awk
- 🌐 Как отключить ETags на сервере Apache
- 🌐 Исключение URL-адресов из ProxyPass на Apache
- 🌐 Настройка заголовков безопасности HTTP на сервере Nginx / Apache
- 🐳 Установка ModSecurity 3 с Apache в контейнере Docker
2023-07-24T15:11:40
Закрытие уязвимостей
Savant 0.2.4 поставляется с улучшениями функциональности, расширенными вариантами использования и многим другим.
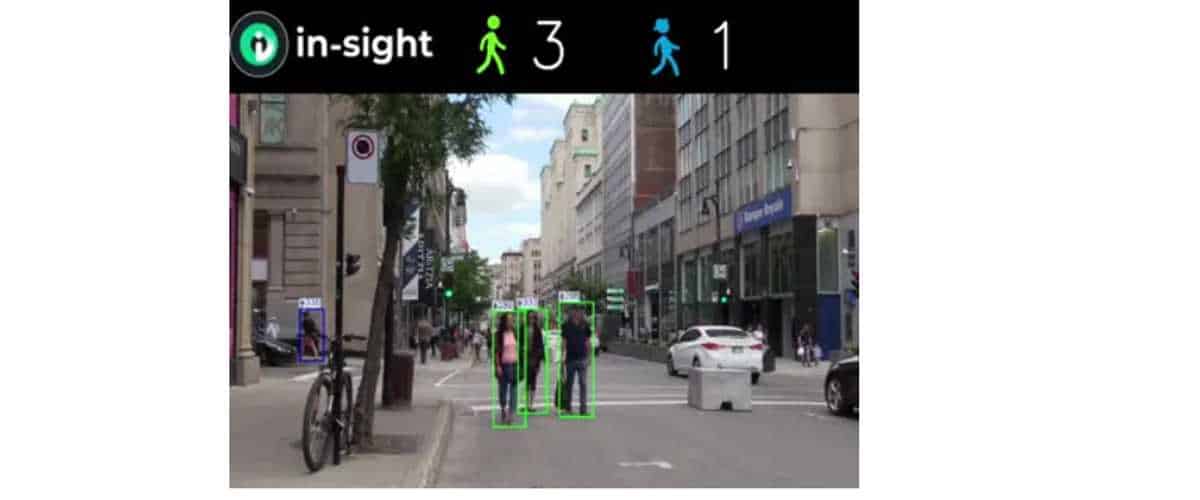
каркас Савант
Несколько недель назад мы делимся здесь в блоге немного информации о Savant — фреймворк для анализа видео. это упрощает использование NVIDIA DeepStream для решения задач машинного обучения. Причина разговора об этом в том, что в последнее время объявила о выходе новой версии «Savant 0.2.4“, в котором были интегрированы новые функции и расширены варианты использования этой замечательной платформы.
Для тех, кто не знаком с фреймворком, вы должны знать, что это берет на себя всю работу с GStreamer или FFmpeg, что позволяет сосредоточиться на создании оптимизированных конвейеров вывода с использованием декларативного (YAML) синтаксиса и функций Python.