В вашей системе заканчивается место на диске, и вы не можете определить, какая папка занимает все пространство? С этой проблемой сталкиваются многие пользователи, но что, если вы сможете просмотреть размер каждой папки в вашей системе? Microsoft предлагает отличные возможности настройки, особенно для ОС Windows, и отображение размера папки — одна из них. Чтобы «Показать размер папки» в Windows, существует несколько способов.
Как показать/просмотреть размер папки через проводник Windows?
«Проводник Windows» — это утилита управления файлами на основе графического пользовательского интерфейса, которая позволяет пользователям получать доступ, удалять, создавать, перемещать и копировать файлы и папки. Он содержит множество функций, а также может отображать/просматривать размер папки. Хотя столбец размера обычно виден, для некоторых пользователей это не так, потому что он отключен в «Свойствах папки». Чтобы отобразить/просмотреть размер папки через «Проводник» Windows, выполните следующие действия:
Шаг 1. Откройте проводник Windows
Чтобы открыть «Проводник» Windows, используйте клавиши «Windows+E».

Теперь откроется «Проводник Windows» и перейдите к любой папке оттуда (мы выбрали папку «Загрузки»):
Шаг 2. Отображение/просмотр размера папки
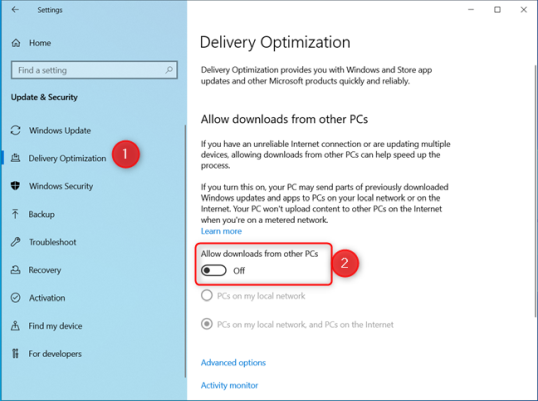
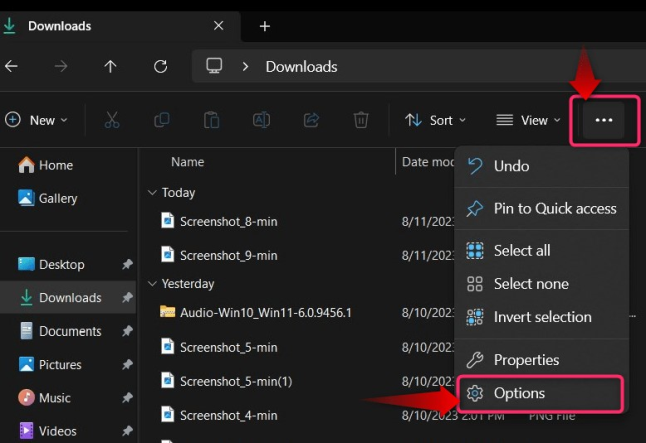
После перехода к любой папке в «Проводнике Windows» используйте три точки и выберите «Параметры», как показано ниже:
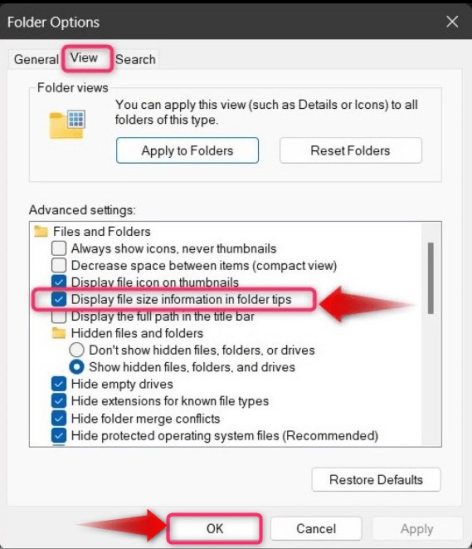
В «Параметры» выберите вкладку «Вид», установите флажок «Показывать информацию о размере файла в подсказках по папкам» и нажмите кнопку «ОК», чтобы сохранить изменения:
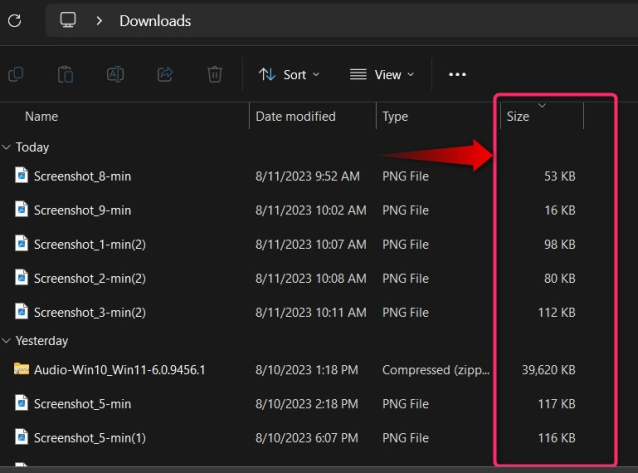
Столбец размера теперь виден в «Проводнике»:
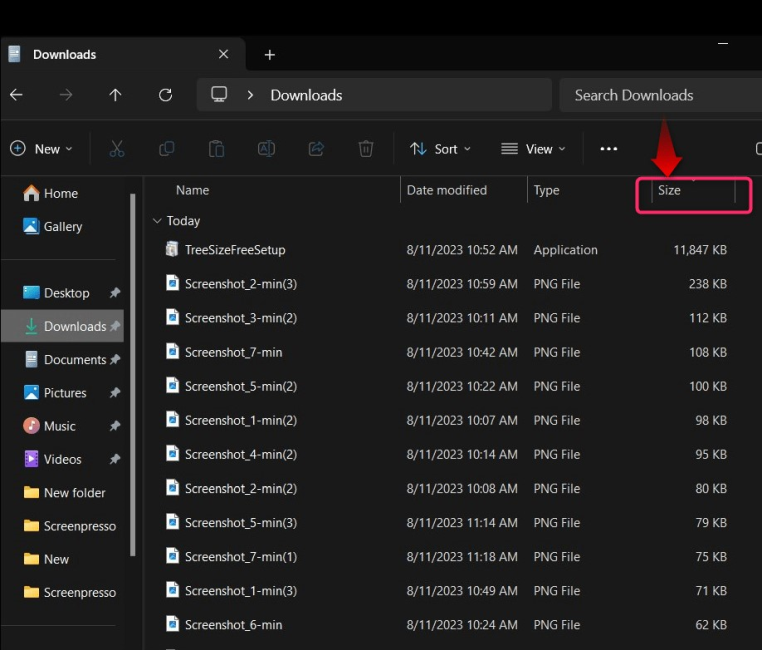
Нажмите/коснитесь столбца «Размер», чтобы отсортировать файлы и папки по размеру:
Как показать/просмотреть размер папки с помощью мыши?
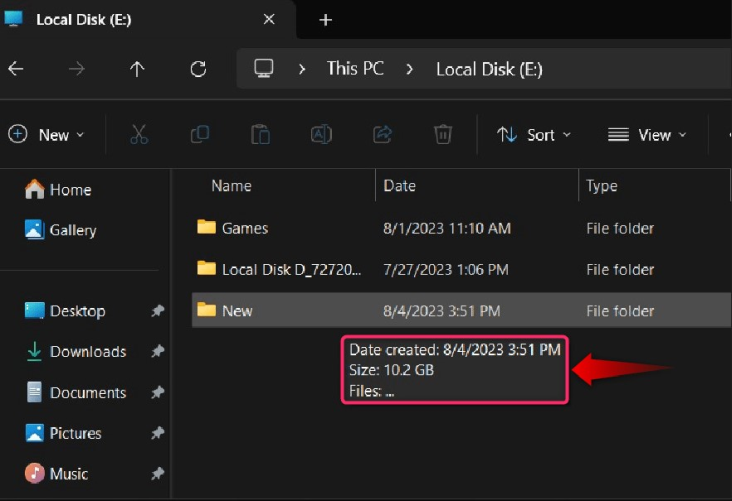
При наведении курсора на папку через 1–2 секунды вы увидите «Подсказку о папке», в которой отображается основная информация об этой папке, включая ее размер:
Примечание. Метод с использованием мыши работает только в том случае, если в папке «Параметры» включена опция «Отображать информацию о размере файла в подсказках папок».
Как показать размер папки в свойствах папки?
С помощью описанного выше метода размер нескольких папок, содержащих множество файлов и папок, не отображается. В таких случаях «Свойства» могут пригодиться. Чтобы проверить размер свойств папки, щелкните ее правой кнопкой мыши и выберите «Свойства» или воспользуйтесь клавишами «ALT+Enter»:
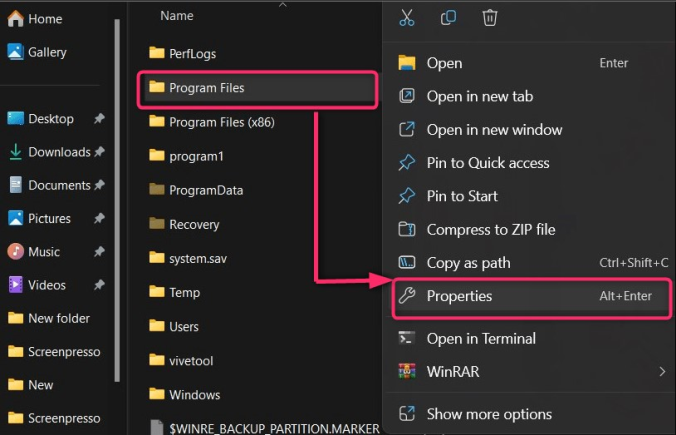
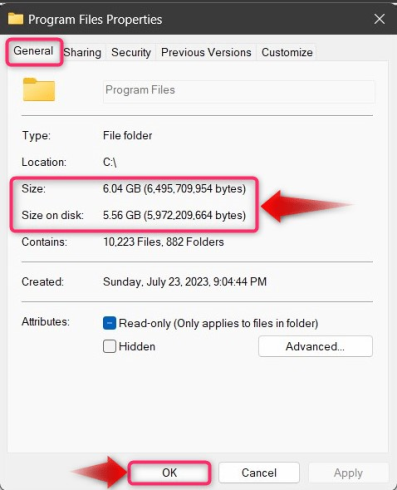
Теперь он покажет размер папки, а здесь у нас есть «Размер» и «Размер на диске»:
- Размер — это размер папки, который останется неизменным при копировании папки из одного места в другое.
- Размер на диске — это количество кластеров, которые операционная система делит на более мелкие части, которые затем распределяются по разным местам устройства хранения. Обычно он отличается от «Размера»:
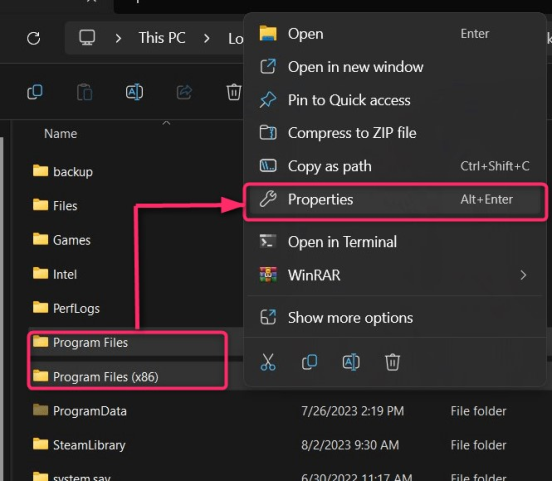
То же самое можно сделать для нескольких папок: для этого выберите папки, щелкните правой кнопкой мыши и выберите «Свойства»:
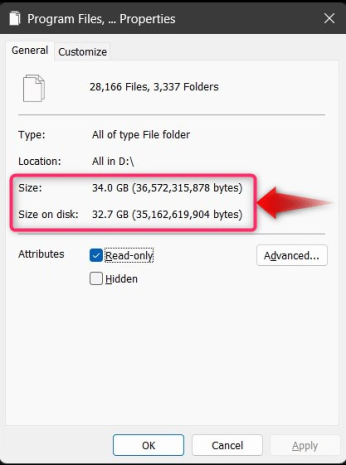
Теперь будут показаны объединенные свойства выбранных папок и их общий размер:
Как показать/просмотреть размер папки через командную строку?
«Командная строка» или «CMD» в Windows — это надежный инструмент, который помогает пользователям управлять своей системой путем выполнения команд. Он также может отображать размер папки, и для этого следуйте инструкциям ниже:
Шаг 1. Откройте командную строку
Чтобы открыть «Командную строку», используйте меню «Пуск» Windows:
Шаг 2. Просмотр/показ пути к папке в CMD
В «CMD» используйте следующую команду и замените «путь к папке» на путь к папке, размер которой вы хотите просмотреть:
dir /s "путь к папке"
Предположим, мы хотим просмотреть размер папки «Program Files», мы воспользуемся следующей командой:
dir /s "C:Program Files"
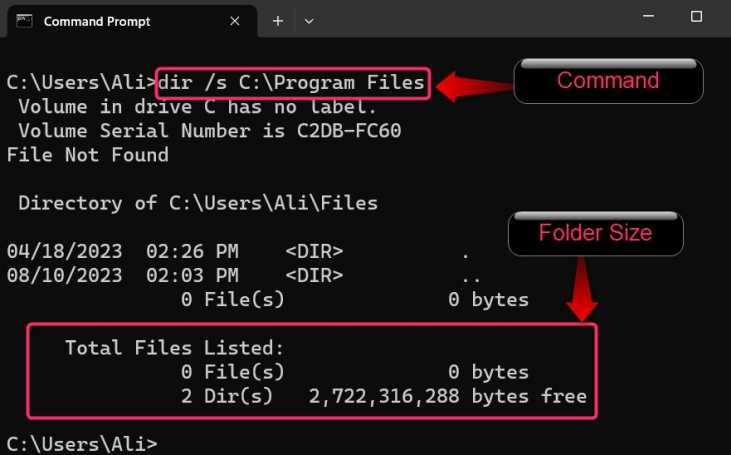
В приведенном выше фрагменте можно просмотреть размер.
Как показать/просмотреть размер папки с помощью стороннего программного обеспечения?
ОС Windows является наиболее широко используемой ОС, поэтому независимые разработчики выпускают множество новых программ для выполнения различных функций. Несколько надежных программ, которые можно использовать для просмотра размера папок в Windows 10/11, включают следующее:
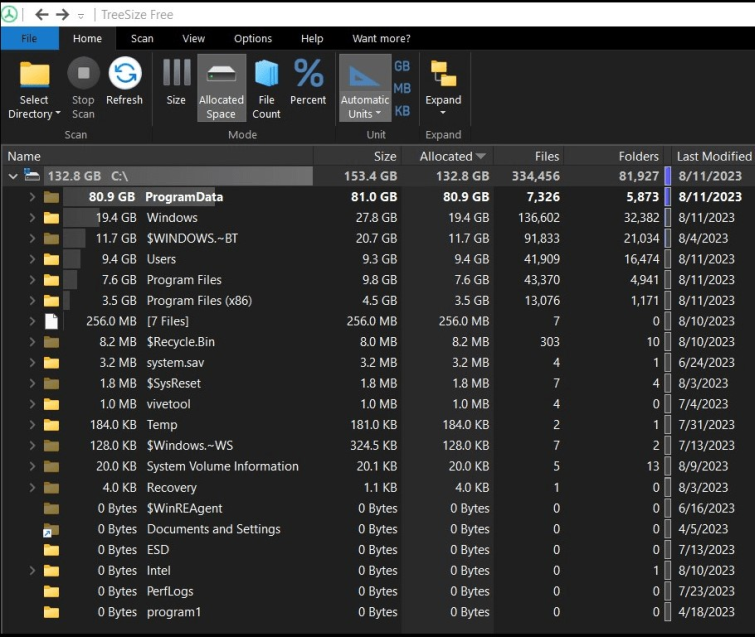
Tree Size
«Tree Size» — это бесплатная программа, предлагаемая «JAM Software». Это безопасное программное обеспечение, если вы загружаете и устанавливаете его из официального источника или из Microsoft Store. «Размер дерева» отображает размер папки, как показано на следующем снимке:
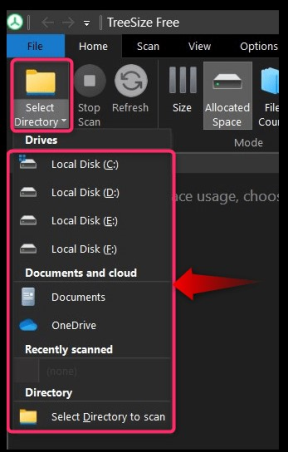
Вы можете переходить к различным каталогам с помощью опции «Выбрать каталог»:
OWLNext Folder Size
«Размер папки OWLNext» — это инструмент с открытым исходным кодом, разработанный для просмотра размера папки и подпапки в Microsoft Windows. Он доступен в Microsoft Store и автоматически устанавливается по этой ссылке. При запуске «Размер папки OWLNext» просит пользователей указать «Обзор папки»:
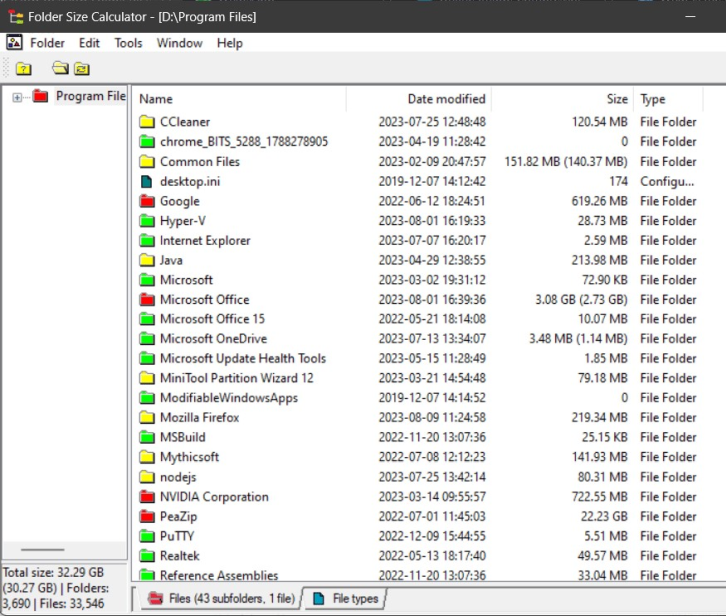
После указания папки будет показан размер папок в ней:
Совет для профессионалов: всегда используйте программное обеспечение из официальных источников и надежных источников, таких как Microsoft Store.
Заключение
Чтобы «Показать размер папки» в Windows 10/11, пользователи могут использовать «Проводник Windows», включив «Отображать информацию о размере файла в подсказках по папкам» в параметрах папки. Кроме того, папка «Свойства», «Командная строка» и несколько сторонних программ также могут помочь в просмотре размера папки в Windows 10/11. В этом руководстве продемонстрированы методы «Показать размер папки» в Windows 10/11.