Viber соединяет нас с друзьями, семьей и коллегами, но, когда вокруг так много шума, легко отправить сообщение, которое позже хотелось бы удалить. В этой статье мы поможем вам удалить сообщения в Viber.
Мы все были там, когда нажимали кнопку «Отправить», и сразу же хотели перемотать время назад. Если ваша история Viber также полна сообщений, которые вы хотели бы удалить, не бойтесь! Удалить сообщения в Viber проще, чем вы думаете. Давайте избавимся от этих смущающих доказательств.
Как удалить сообщения в индивидуальном чате
Удалить сообщения в Viber несложно, особенно если речь идет об отдельных чатах. Придерживайтесь шагов, описанных ниже:
На мобильном телефоне
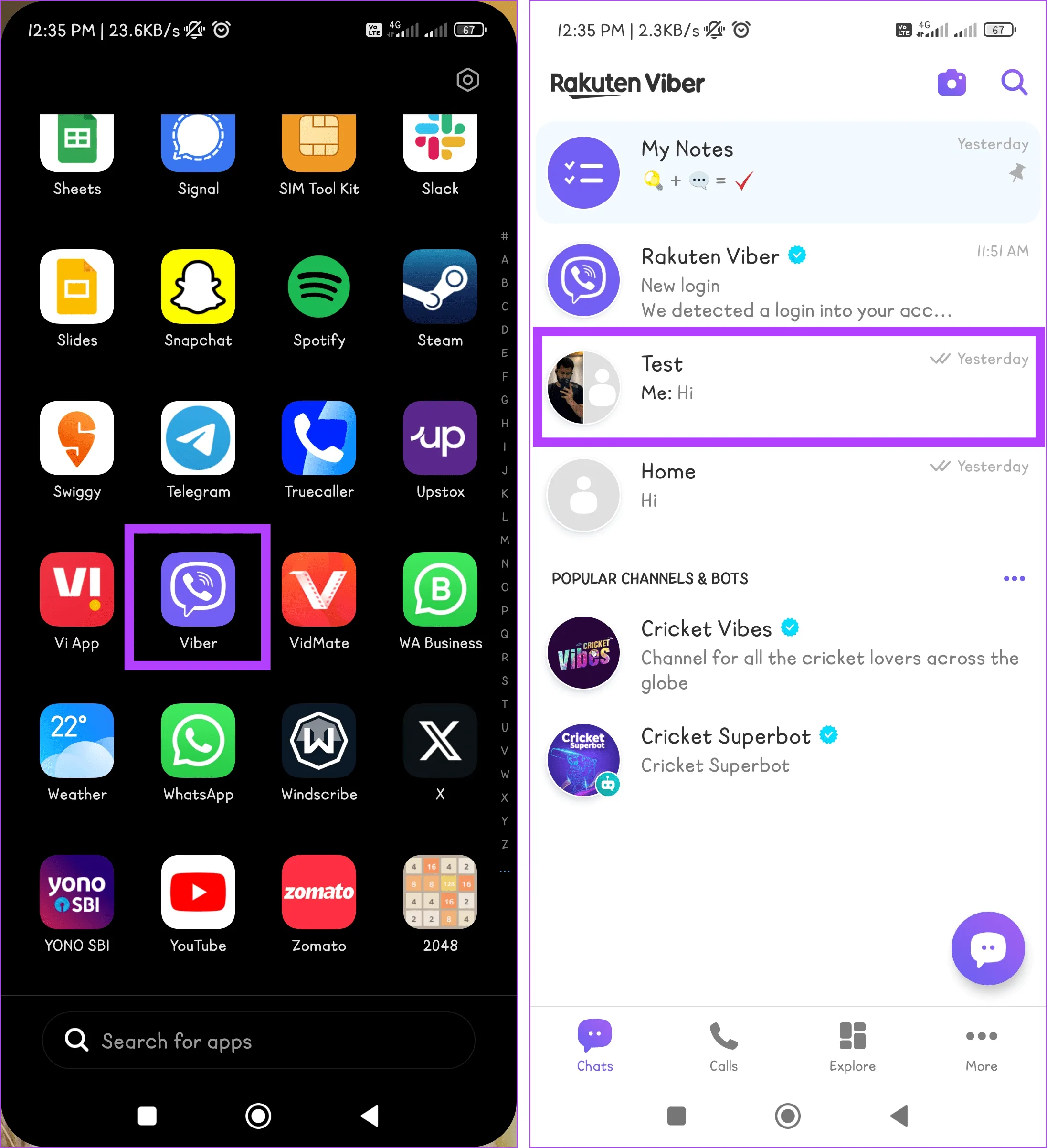
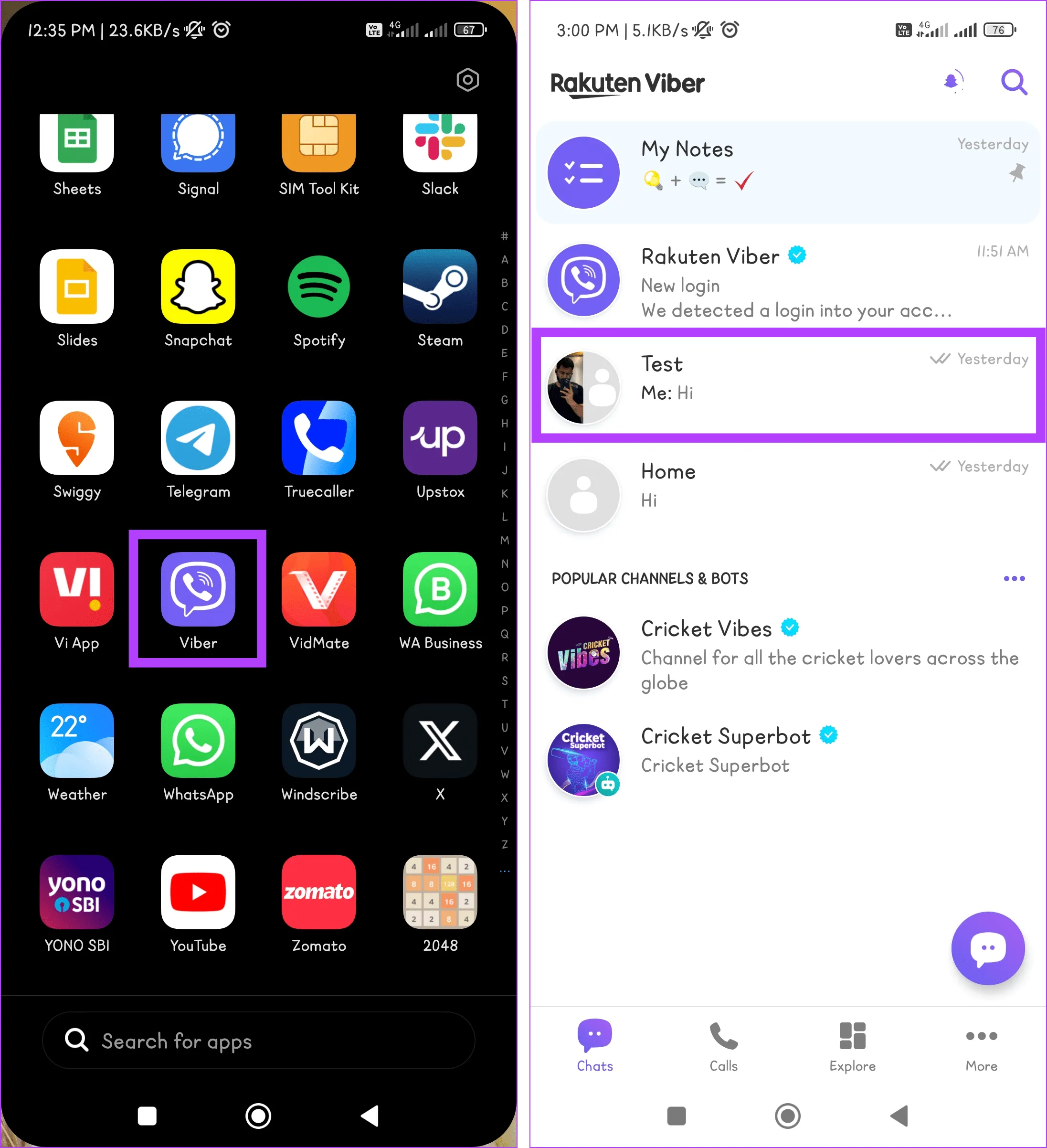
Шаг 1. Перейдите в приложение Viber на своем устройстве.
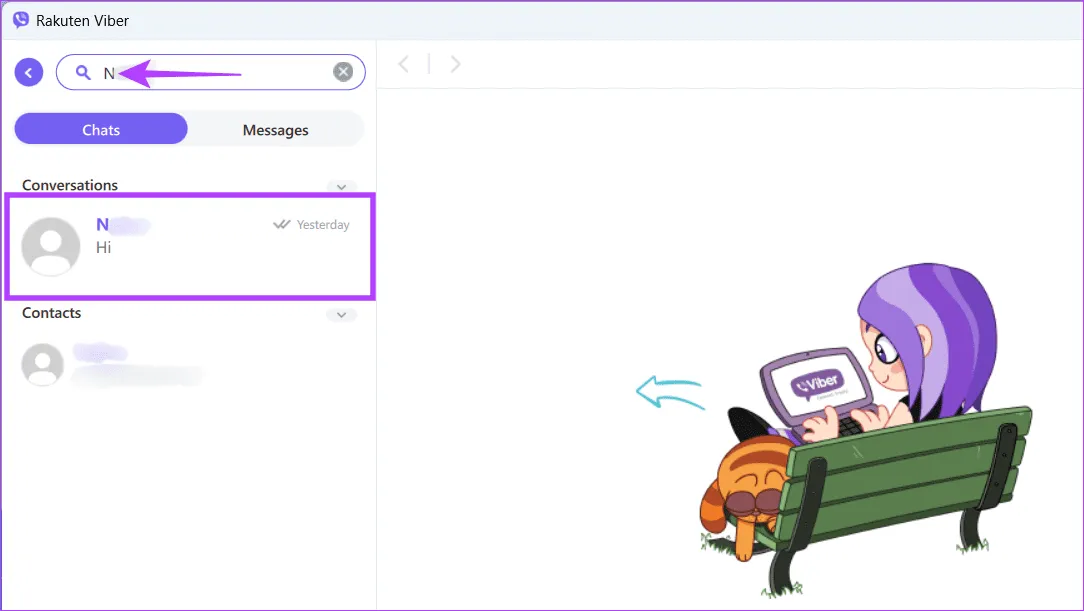
Шаг 2. Нажмите значок «Поиск» и напишите имя пользователя, с которым вы хотите удалить чаты. Теперь нажмите на карточку контакта, чтобы открыть чат.

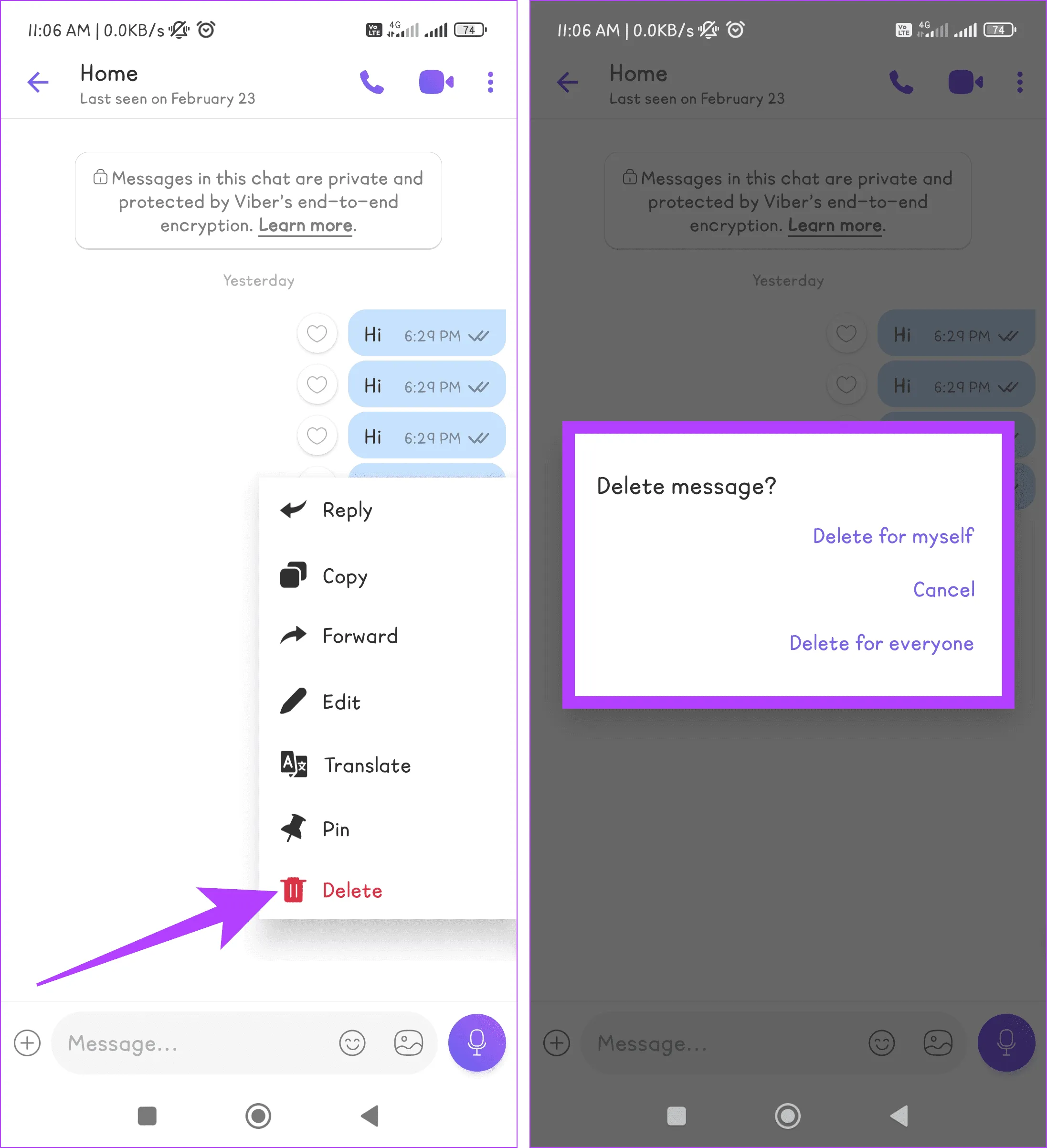
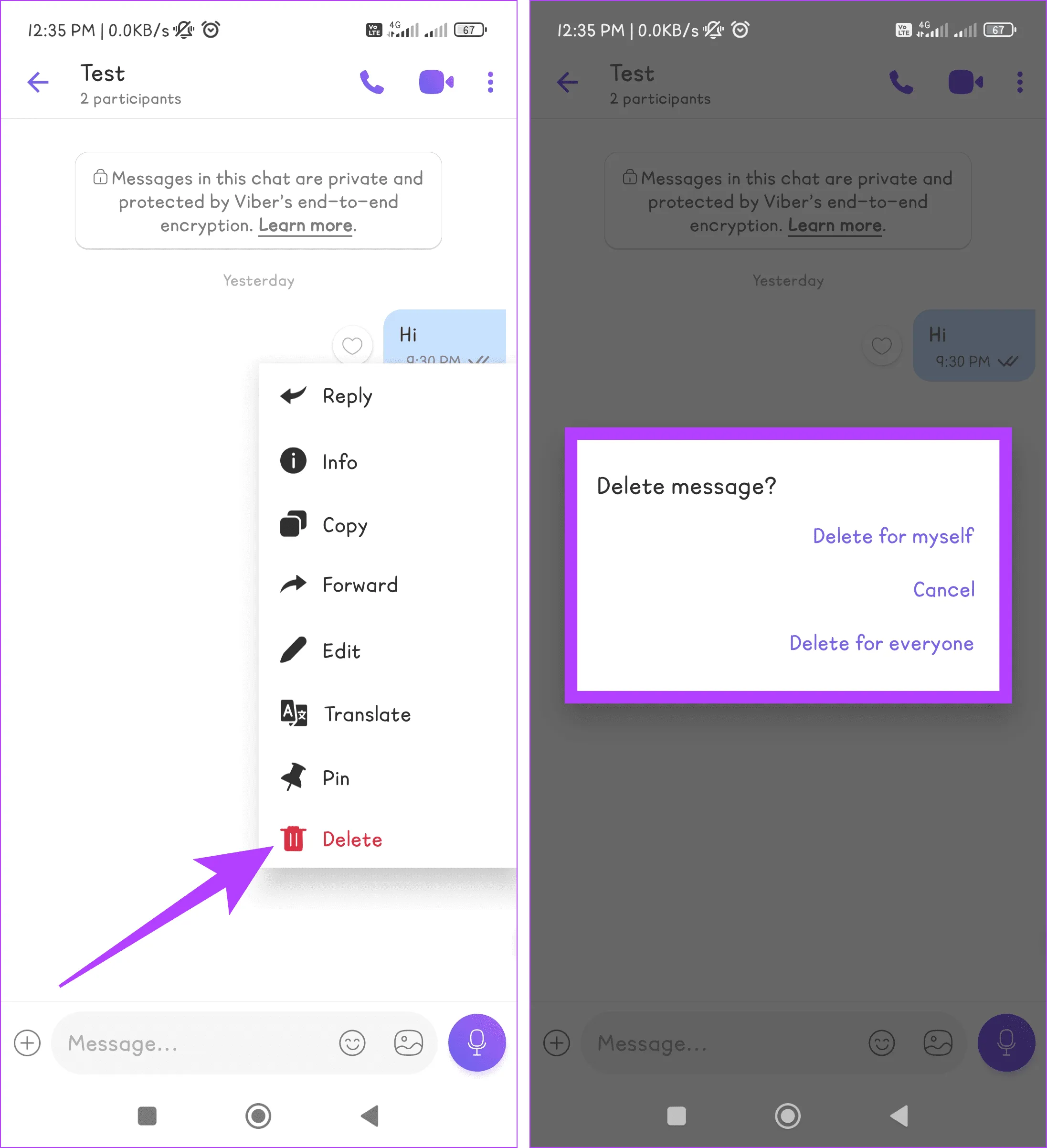
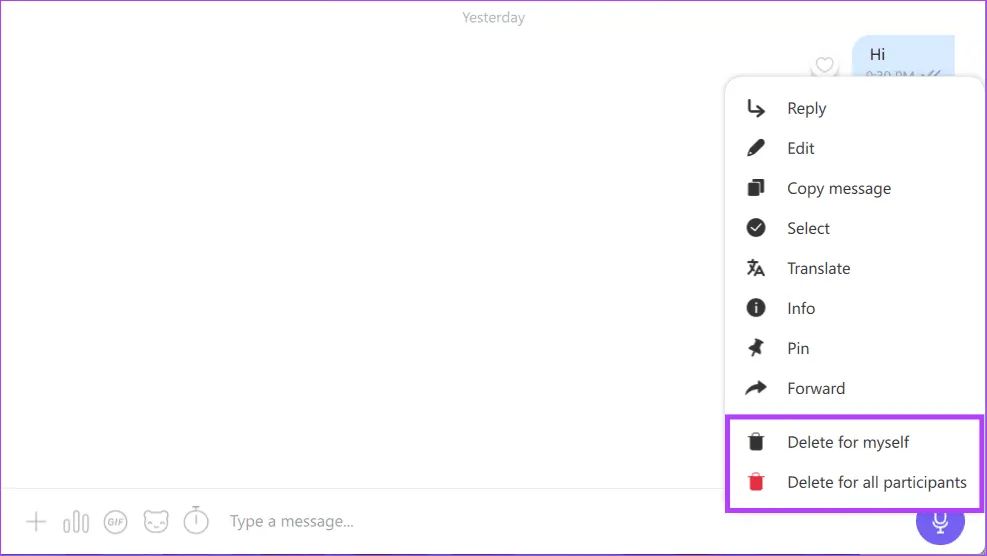
Шаг 3. Нажмите и удерживайте сообщение в чате, которое хотите удалить. Выберите «Удалить» из списка и выберите одно из следующих:
- Удалить для себя: сообщение будет удалено для вас, но другие участники чата все равно его увидят.
- Удалить для всех: сообщение будет удалено для всех участников разговора.
На рабочем столе
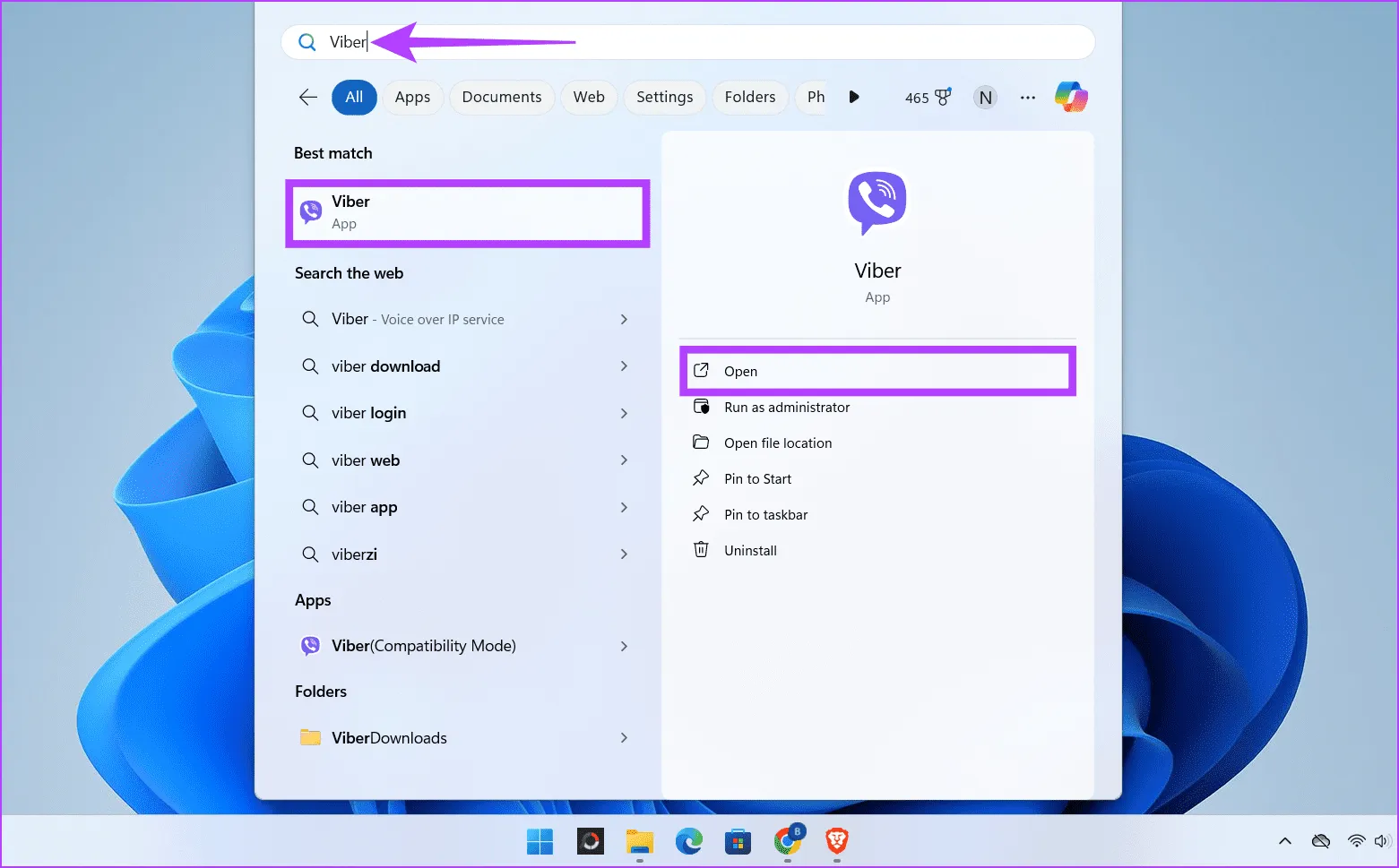
Шаг 1. Щелкните значок Windows, введите Viber в поле поиска и нажмите «Открыть».

Шаг 2: Нажмите на поле поиска.

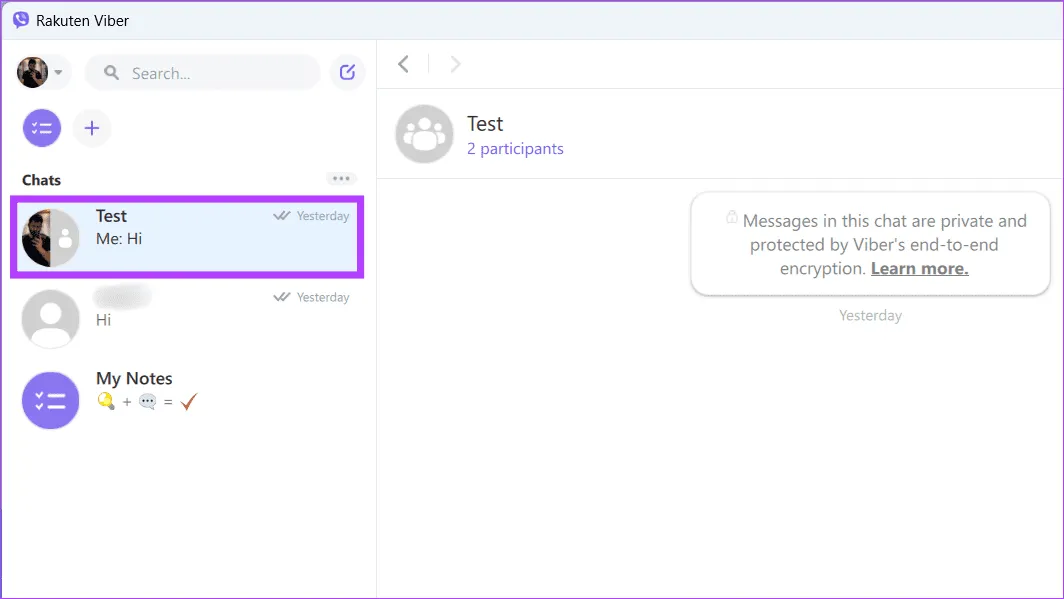
Шаг 3. Введите имя контакта и нажмите на карточку контакта, чтобы открыть чат.
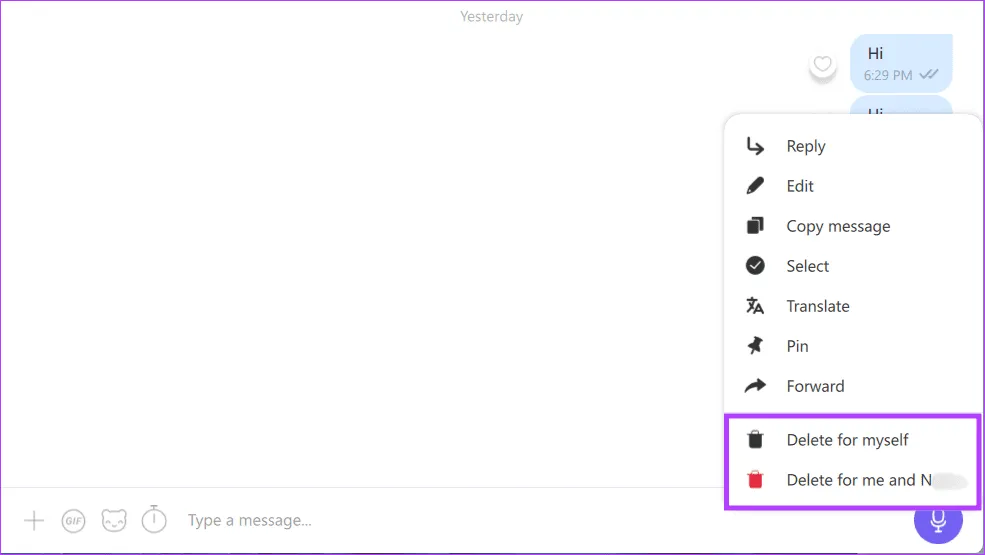
Шаг 3. Найдите сообщение, которое хотите удалить. Щелкните его правой кнопкой мыши и выберите один из следующих вариантов:
- Удалить для себя
- Удалить для меня и [имя пользователя]

Как удалить групповые чаты в Viber
Групповые чаты — это основная функция Viber, которая позволяет вам общаться с несколькими людьми в одном разговоре. Ниже описано два способа удаления группового чата в Viber.
Способ 1: удалить сообщения Viber, не выходя из группы
Если вы хотите удалить одно сообщение или несколько конкретных сообщений в группе, выполните следующие действия, в зависимости от используемого вами устройства:
На мобильном телефоне
Шаг 1. Откройте приложение Viber на своем устройстве и найдите группу Viber, из которой вы хотите удалить текст.
Совет: Вы можете использовать значок поиска, чтобы быстро найти группу.
Шаг 2. Найдите чат, который хотите удалить. Нажмите и удерживайте чат и нажмите «Удалить». Выберите один из следующих вариантов:
- Удалить для себя: сообщение будет удалено из вашего поля зрения. Другие участники группы все еще могут видеть это.
- Удалить для всех: это навсегда удалит сообщение для всех участников группы.
На рабочем столе
Шаг 1: Нажмите клавиши Windows+S, чтобы открыть панель поиска. Введите Viber в поле поиска и нажмите «Открыть».
Шаг 2. Найдите групповой разговор в левой части окна Viber. Нажмите на название группы, чтобы открыть групповой чат.

Шаг 3. Прокрутите групповой чат справа и найдите сообщение, которое хотите удалить. Щелкните сообщение правой кнопкой мыши и выберите один из следующих вариантов:
- Удалить для себя
- Удалить для всех участников

Способ 2: удалить сообщения Viber и выйти из группы
Если вы хотите выйти из группы и стереть историю сообщений, сделайте это следующим образом:
На мобильном телефоне
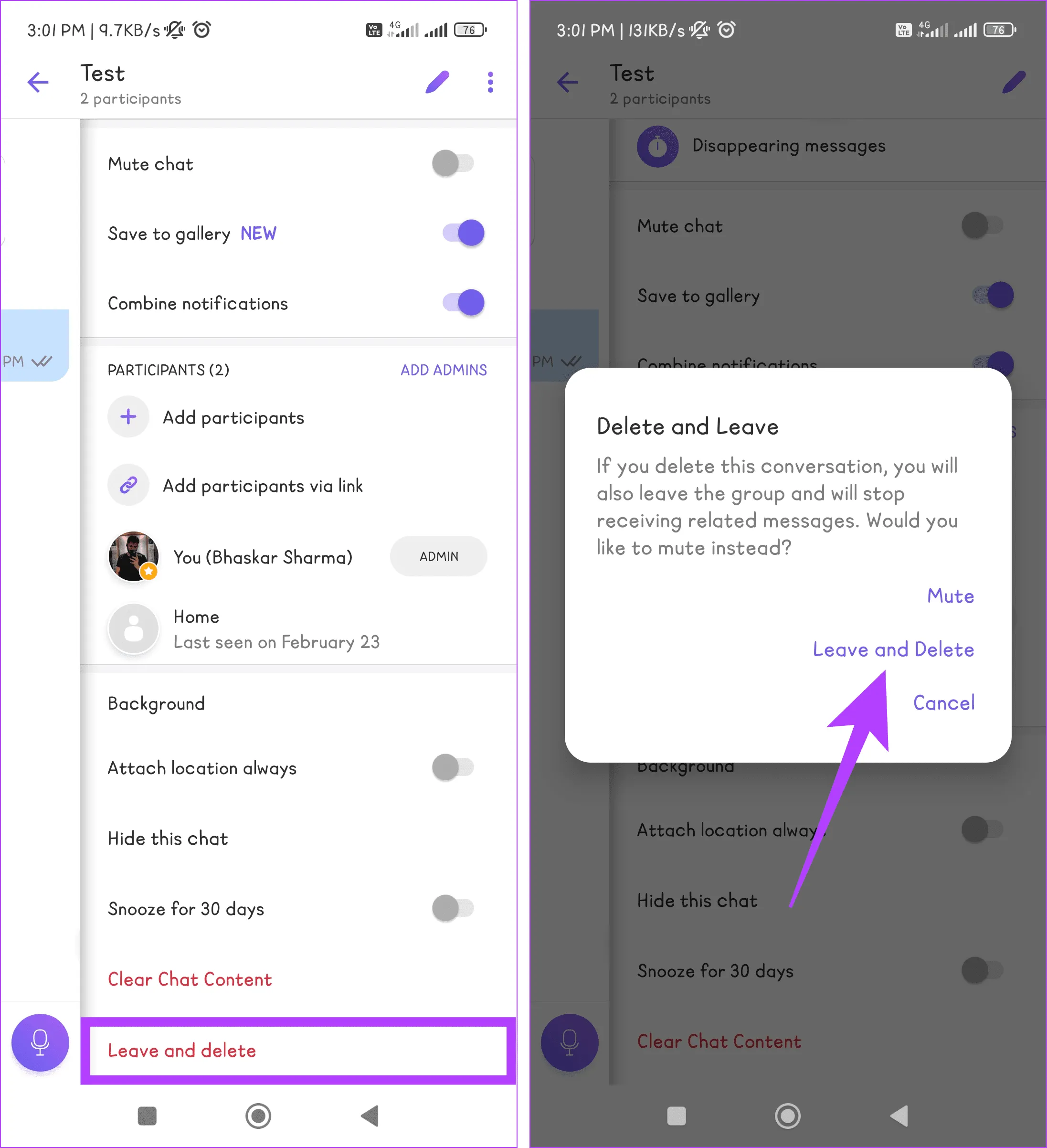
Шаг 1. Запустите приложение Viber на своем телефоне и перейдите в групповой чат, где находится сообщение, которое вы хотите удалить.
Шаг 2. Коснитесь трехточечного значка в верхней части экрана и выберите «Информация о чате» в списке опций.
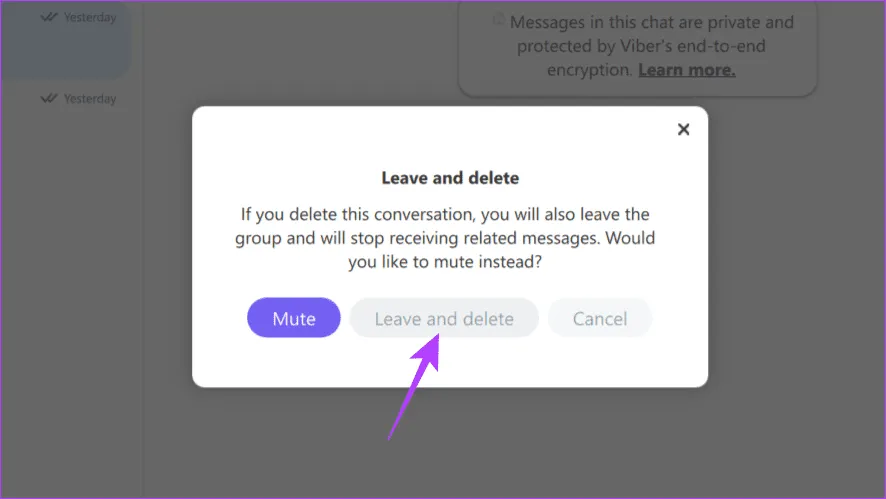
Шаг 4: Прокрутите вниз, нажмите «Выйти» и «Удалить». Теперь снова выберите «Оставить и удалить» во всплывающем окне для подтверждения.
На рабочем столе
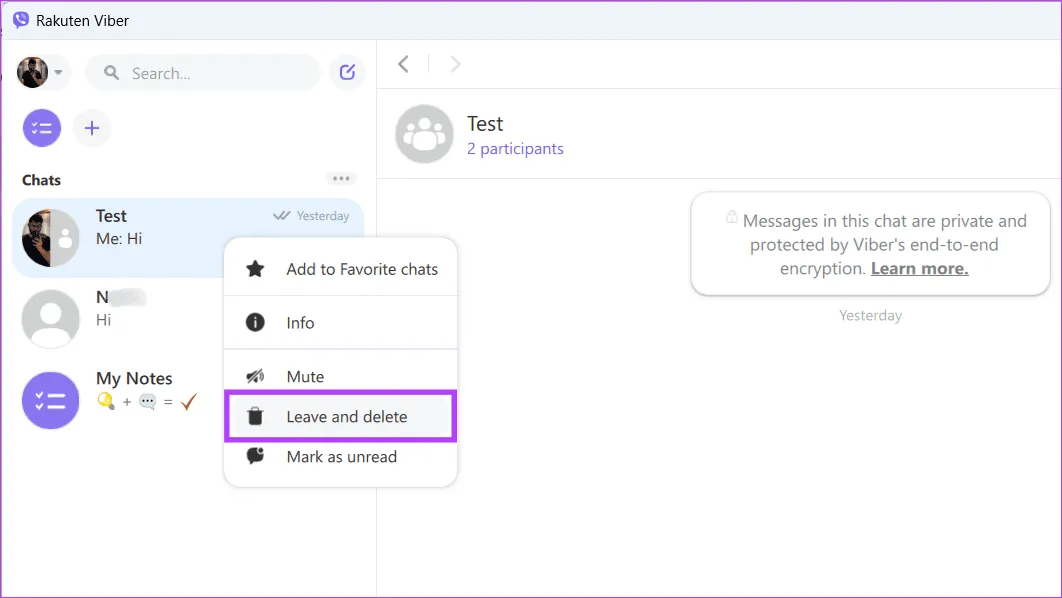
Шаг 1. Перейдите в меню «Пуск», нажав клавишу Windows. Введите Viber и нажмите «Открыть».
Шаг 2. Найдите группу, содержащую сообщение, которое нужно удалить. Щелкните правой кнопкой мыши имя группы и выберите в меню пункт «Оставить и удалить».
Шаг 3. Подтвердите свой выбор, нажав «Выйти и удалить еще раз».

Удалить историю чата
Если вы хотите освободить место для хранения данных или начать все сначала, Viber позволяет вам очистить историю чатов. Это приведет к безвозвратному удалению всех сообщений, мультимедиа и истории звонков в отдельных чатах или группах. Следуйте инструкциям ниже, чтобы автоматически удалить все сообщения Viber за несколько шагов:
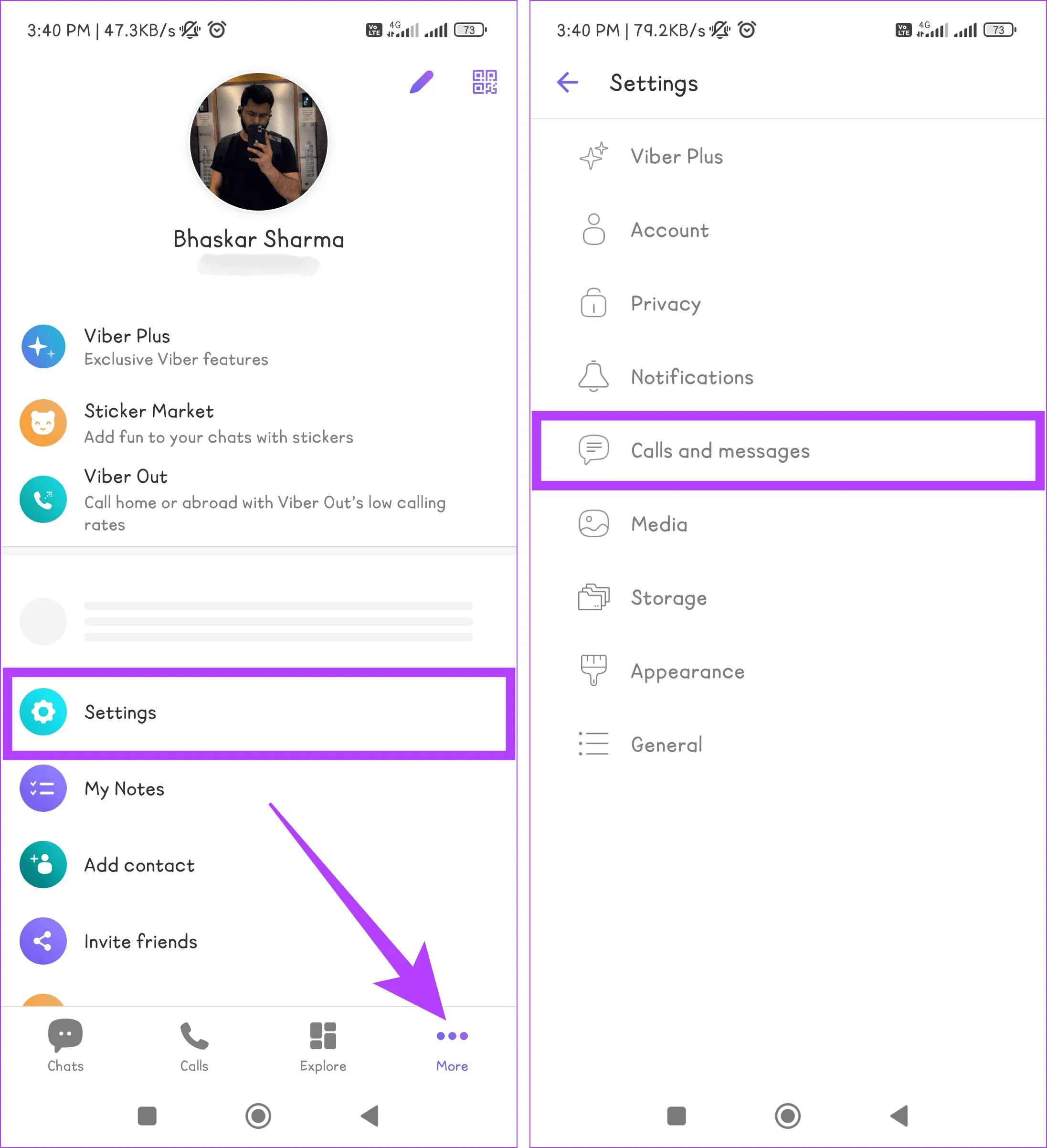
Шаг 1. Откройте приложение Viber на своем устройстве Android или iOS.
Шаг 2. Перейдите на вкладку «Дополнительно», выберите «Настройки» и выберите «Звонки и сообщения» в списке опций.
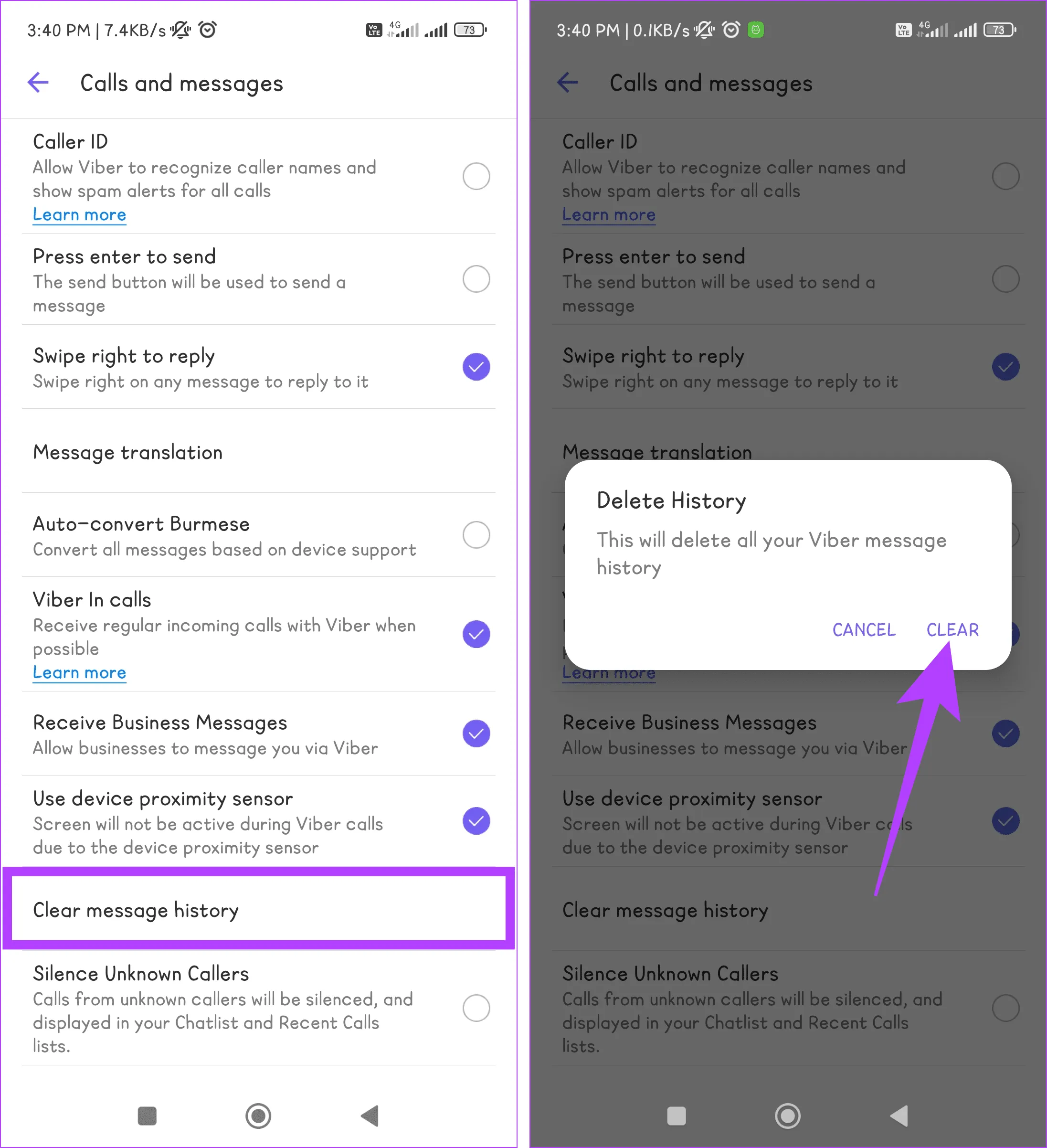
Шаг 3. Нажмите «Очистить историю сообщений» и подтвердите выбор, снова нажав «Очистить» во всплывающем окне.
Часто задаваемые вопросы
1. Могу ли я удалить сразу несколько сообщений в Viber?
Нет, вы не можете удалить несколько сообщений в Viber одновременно. Вам необходимо удалить все сообщения по отдельности.
2. Могу ли я удалить сообщение, отправленное мне кем-то другим?
Да, вы можете удалить сообщение, отправленное вам кем-то другим в Viber. Однако помните, что сообщение будет удалено с вашего устройства, а другой человек по-прежнему сможет просмотреть его на своем устройстве.
3. Узнает ли получатель, что я удалил сообщение?
Если вы удалите сообщение для всех, получатель увидит примечание: «Это сообщение было удалено». Однако получатель не будет уведомлен, если вы удалите сообщение для себя.
Избавьтесь от нежелательных сообщений
Возможность удалять сообщения в Viber — это удобная функция, разработанная с учетом ваших потребностей. Если вы случайно отправили сообщение не тому человеку или вам нужно отозвать заявление, Viber понимает такие ситуации и дает вам возможность контролировать ваши разговоры.
2024-03-07T20:08:49
Вопросы читателей