Microsoft представила новые меры по улучшению безопасности Windows, после недавних проблем, связанных с крупным сбоем в системе CrowdStrike, который затронул множество пользователей. Этот инцидент заставил Microsoft пересмотреть своё отношение к предоставлению доступа на уровне ядра для продуктов безопасности. Компания провела встречу с правительственными чиновниками и специалистами по кибербезопасности на саммите Windows Endpoint Security Ecosystem Summit, чтобы обсудить дальнейшие шаги в этом направлении.
Google меняет имя своего ИИ с «Бард» на «Близнецы»
С декабря прошлого года Google вносит ряд изменений в своего чат-бота Bard а теперь Гугл только что объявила, что изменит название своих продуктов искусственного интеллекта.
Bard, чат-бот с искусственным интеллектом, который Google запустил почти год назад в качестве конкурента ChatGPT OpenAI, Теперь он называется «Близнецы», который Google описывает как более продвинутый искусственный интеллект, который обещает революционизировать то, как мы взаимодействуем с технологиями.
Python — это язык программирования высокого уровня.
В последнее время один из главных Разработчики CPython представили новый JIT-компилятор для Python используя технику копирования и исправления, который новейшая и инновационная техника компиляции что выделяется своей скоростью, простотой обслуживания и его полная интеграция с существующим интерпретатором.
Копирование и исправление основан на использовании предопределённой библиотеки фрагментов двоичного кода, известных как «шаблоны» для вывода оптимизированного машинного кода. Эти шаблоны представляют собой предварительно созданные реализации узлов AST (абстрактного синтаксического дерева) или байтовых кодов операций, которые содержат пропущенные значения, такие как непосредственные литералы, смещения переменных стека, а также цели ветвления и вызова.
Искусственный интеллект (ИИ) — модное словечко 2023 года. И это правильно, поскольку технология во многих своих формах меняет образ жизни миллиардов людей. От отдыха до бизнеса и всего, что между ними, ИИ не затронет ни одну грань. Серьезной задачей для технологических компаний является внедрение значимого ИИ в любом масштабе. От центров обработки данных, заполненных стойками для интенсивного обучения, до клиентских устройств, на которых локально выполняются рабочие нагрузки, повышающие производительность, — Intel считает себя пионером в повсеместном внедрении ИИ. Давайте разберемся, почему.
Революция искусственного интеллекта
ИИ — чрезвычайно широкая церковь. В своей простейшей форме это способность компьютера имитировать обычное человеческое поведение, такое как решение проблем, понимание команд, обучение и рассуждение. Звучит надуманно, не правда ли, но Amazon Alexa или Apple Siri — это базовые формы искусственного интеллекта. На другом конце шкалы находятся более мощные решения, которые дают сложные, многоуровневые ответы на бесконечное количество вопросов. Я уверен, что нам всем было интересно попробовать модели больших языков (LLM) ChatGPT или Google Bard.
Ум, лежащий в основе ИИ, граничит с научной фантастикой. Глубокое обучение, возникшее на основе машинного обучения, существующего уже 50 лет, является основой большинства ИИ в том виде, в котором мы его знаем. Это ответвление использует нейронные сети для обработки массы данных – точно так же, как человеческий мозг понимает мир, накапливая информацию, которая в конечном итоге приводит к восприятию – и посредством итеративного процесса обучения, детерминизма и распознавания образов на потенциально миллиардах входных данных. хорошая модель эффективно понимает данные и позволяет получить полезную и точную информацию.
Хорошо настроенная модель искусственного интеллекта компьютерного зрения эффективно определяет, есть ли на случайном изображении кошка или собака, поскольку она понимает через тысячи или миллионы похожих изображений, подаваемых ей на этапе обучения, какие характеристики соответствуют каждому животному – четыре ноги и например, хвост у обоих общий. Именно это укоренившееся представление об общности и ассоциативности приводит к значимым результатам.
Точно так же складской поддон, велосипед или опухоль, хотя и совершенно разные друг от друга, обладают особыми характеристиками, которые помогают ИИ в классификации и идентификации.
Asus. Помощь в диагностике.
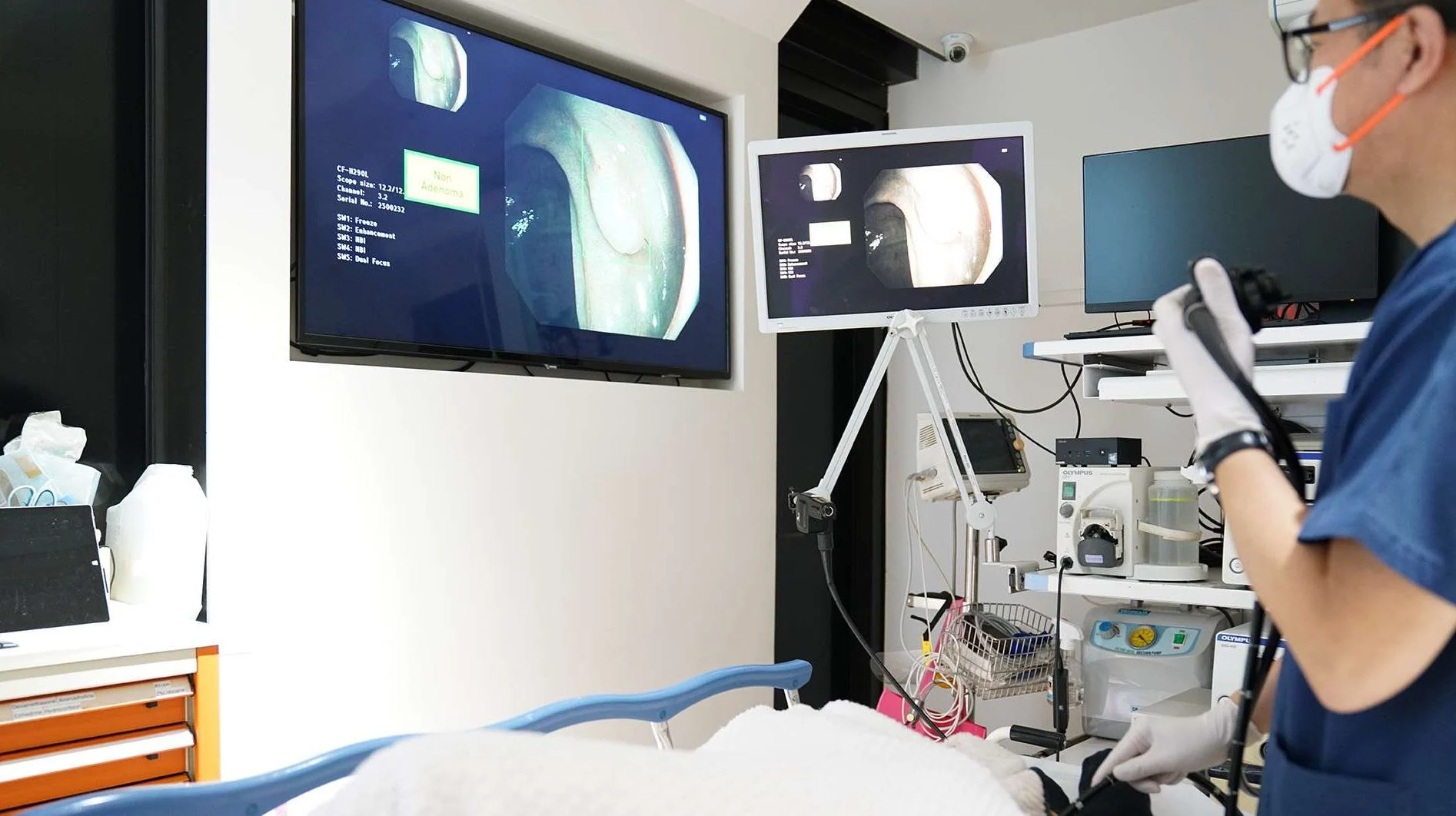
Некоторые ИИ превосходно справляются с этим типом распознавания образов, что приносит непосредственную пользу, скажем, в медицинском мире. Мощные модели теперь лучше людей обнаруживают потенциальные заболевания путем экстраполяции деталей сканирования. Представьте себе облегчение, когда ИИ обнаружил аденому, которую уставший врач не по своей вине не смог обнаружить после 12-часового марафона. По сути, хороший искусственный интеллект устраняет большую часть человеческих ошибок, вызванных внешними факторами. Хорошо обученные алгоритмы не утомляют. Конечно, это не значит, что это идеальная наука: любая модель хороша настолько, насколько качество и количество введенных в нее данных. Но трудно утверждать, что ИИ – отличный инструмент, который можно использовать наряду с экспертными человеческими знаниями.
Кроме того, ИИ выходит далеко за рамки простого компьютерного зрения. Тот же базовый механизм распознавания образов, обучения и вывода полезен для создания нового контента, казалось бы, с нуля. Вы когда-нибудь удивлялись, когда генеративные модели искусственного интеллекта, такие как ChatGPT, за считанные секунды выдают абзацы полезной, контекстно-зависимой информации, или когда Stable Diffusion создает фотореалистичные изображения из базовых текстовых вводов? С ума сойти.
Показательный пример. Я прошу Stable Diffusion XL создать картинку с текстовыми подсказками «злой мужчина на велосипеде». Это в духе Монти Пайтона, дон. ты так не думаешь?
От большого к маленькому
Чем больше человек что-то делает, тем лучше у него это получается. Так называемое правило 10 000 часов гласит, что практика любого навыка в течение этого периода времени приводит к тому, что экспонент становится экспертом в нем. То же самое относится и к ИИ, поскольку все более крупные и сложные модели дают более точные и полезные результаты. Несмотря на то, что с ней интересно играть, последняя версия ChatGPT использует, подождите, модель со 175 миллиардами параметров для генерации ответов, подобных человеческим.
«INTEL СЧИТАЕТ СЕБЯ ПИОНЕРОМ В ПОВСЕМЕСТНОМ ВНЕДРЕНИИ ИИ».
По-настоящему огромные вычислительные возможности, необходимые для обработки и извлечения значимой информации из миллиардов точек данных, остаются исключительной прерогативой облака. Передовой искусственный интеллект обязательно требует невероятных масштабов. Это тоже имеет смысл, поскольку удаленные центры обработки данных, битком набитые специализированным оборудованием, обрабатывают массу информации и во многих случаях возвращают практически мгновенные результаты. Требуемая мощность просто слишком велика для локальной обработки на настольном ПК, ноутбуке или даже в собственной серверной комнате. Такое положение дел остается в значительной степени справедливым и для комплексного обучения и формирования выводов и сегодня.
Локальный ИИ — это следующий большой шаг вперед.
Тем не менее, мы повсюду вступаем в эпоху расцвета искусственного интеллекта. Это становится более личным. Хотя такие технологии, как ChatGPT, сами по себе являются чудесами, обеспечивая повсеместное распространение благодаря доступности Интернета практически в любой точке мира, предприятия и частные лица быстро поняли, что мелкомасштабный ИИ не менее полезен, прост в использовании и, возможно, более безопасен.
Мы только начинаем прикасаться к тому, как ИИ произведет революцию в бизнес-пространстве, и помяните мои слова, это произойдет на всех уровнях масштаба. Для офисного работника разве не было бы здорово, если бы на его собственном ноутбуке выполнялись оперативные языковые переводы, убедительные сводки совещаний и анализ данных, который требует усилий человека… без ожидания, обычно вызываемого онлайн-вариантами?
«ТЕМ НЕ МЕНЕЕ, МЫ ПОВСЮДУ ВСТУПАЕМ В ЭПОХУ РАСЦВЕТА ИСКУССТВЕННОГО ИНТЕЛЛЕКТА. ЭТО СТАНОВИТСЯ БОЛЕЕ ЛИЧНЫМ».
Предприятия также могут получить выгоду, используя локальную обработку ИИ для более обыденных, но не менее важных действий. Компьютерное зрение позволяет управлять физическими объектами и обнаруживать вторжения. Общая эффективность работников повышается за счет использования ИИ в их обычных рабочих процессах. Существует множество других вариантов использования, в которых ИИ снимает часть бремени, налагаемого традиционным трудоемким подходом.
Эмпирические данные лучше всего. Как владелец малого бизнеса, я, конечно, не сторонник просматривать сотни электронных писем в поисках нужной темы, относящейся к непонятному запросу; Я бы предпочел, чтобы это сделала умная нейронная обработка, которая позволила бы мне сосредоточиться на более важных вещах. Локальный ИИ также имеет финансовые преимущества, поскольку он снижает неизбежно более высокие затраты, связанные с использованием исключительно облачного подхода.
Однако внедрение ИИ в каждый уголок — нетривиальная задача. Истинная демократизация требует обработки данных в облаке, на клиенте и на периферии, в гетерогенных архитектурах и стеках программного обеспечения. Понимая уникальные возможности для бизнеса, которые открываются на общем адресуемом рынке (TAM), исчисляемом десятками миллиардов долларов, Intel занята созданием инфраструктур, необходимых для повсеместного распространения искусственного интеллекта во всех отраслях и бизнес-сегментах.
План Intel по масштабному внедрению искусственного интеллекта
Спрос на ИИ остается ненасытным, если рассматривать его через призму мировых возможностей. Учитывая миллиарды фактически бестолковых устройств, которые служат просто конечными точками для облачной обработки, крупномасштабное обучение ИИ и получение выводов никуда не денутся. Хотя модели действительно работают на старом серверном оборудовании, обычно используемом для стандартных задач, таких как управление базами данных, транзакционные службы и веб-обслуживание, резкое изменение производительности требует переосмысления всей архитектуры.
Новые процессоры Intel Xeon твердо ориентированы на искусственный интеллект. Например, масштабируемая серия Xeon 4-го поколения отводит драгоценное пространство на кристалле для технологии, известной как Advanced Matrix Extensions (AMX). Используемый для обработки более простого искусственного интеллекта, математический AMX совместим с широко используемыми форматами данных – BFloat16 и int8 – и впоследствии помогает выполнять определенные новые рабочие нагрузки до 10 раз. быстрее, чем предыдущие поколения. Вот о каком поэтапном изменении я говорю.
Сегодняшнее присутствие серверного оборудования, оснащенного искусственным интеллектом, не случайно; это сделано намеренно, поскольку архитектура ЦП разрабатывается за много лет до начала производства. Новая линейка процессоров Xeon Max Series поддерживает до 64 ГБ оперативной памяти HBM2e, помогая выполнять высокопроизводительные вычисления (HPC) и рабочие нагрузки искусственного интеллекта. Дополнительная память помогает загружать большие наборы данных (если вы разбираетесь в искусственном интеллекте, вы понимаете, что рабочие нагрузки огромны) ближе к вычислительным механизмам и, следовательно, ускоряет обработку.
Переходя в мир массовой обработки искусственного интеллекта, цель Data Center GPU Max Series и ускорителей искусственного интеллекта Gaudi2 состоит в том, чтобы облегчить масштабировать производительность. Часто LLM обучают несколько кластеров серверов, включающих Xeon и Gaudi2. В качестве подходящего примера: совсем недавно 384 ускорителям Gaudi2 потребовалось 311 минут для широкого обучения 1%-ной части модели ChatGPT-3 со 175 миллиардами параметров. используется сегодня. Я ожидаю скачка производительности Gaudi2, когда появится программная поддержка более быстрого в обучении формата FP8.
Масштаб действительно лучше всего иллюстрируется компаниями и правительствами, удваивающими инвестиции в ИИ. Ведущие технологии Intel объединены в Dawn, самом быстром суперкомпьютере искусственного интеллекта в Великобритании. На первом этапе Dawn, который является краеугольным камнем недавно объявленной инициативы UK AI Research Resource (AIRR), будет размещено 256 серверов Dell PowerEdge XE9640, каждый из которых оснащен двумя масштабируемыми процессорами Xeon 4-го поколения и четырьмя графическими процессорами Data Center GPU Max Series.
Первый этап суперкомпьютера Dawn.
Фаза 2, которая выйдет в 2024 году, обещает десятикратное увеличение производительности. Казалось бы, достаточно, чтобы войти в мировой список суперкомпьютеров TOP500. Это экстремальный масштаб и предвестник грядущих событий.
Почему личный ИИ важен
Между тем, искусственный интеллект повсюду требует инвестиций нескольких поколений в специально созданное оборудование для персональных устройств, таких как ноутбуки или ПК. Идя рука об руку, экосистема программного обеспечения также должна создавать модели меньшего размера, которые эффективно работают на самих компьютерах. Недавние разработки в области программного обеспечения показывают, что модели преобразования текста в изображение (Stable Diffusion), модели с большим языком (самые маленькие Llama 2 и DoctorGPT от Meta) и программы автоматического распознавания речи (Whisper) вполне вписываются в число менее 10 миллиардов человек. Порог параметра считается ключевым для локальной обработки… при правильном подборе аппаратного и программного обеспечения, конечно.
Более разумное обучение позволяет этим меньшим моделям воспроизводить большую часть точности и полезности, присущих масштабированию типа центра обработки данных. Интересный генеративный искусственный интеллект и продвинутый языковой перевод в реальном времени уже достаточно продвинулись вперед, чтобы обеспечить удовлетворительные впечатления от использования процессора, содержащегося в ультратонком ноутбуке последнего поколения.
Тем не менее, есть предостережения. Несмотря на то, что по своей природе они проще, чем облачные модели, эффективная обработка ИИ на старых процессорах и графических процессорах по-прежнему затруднена — это все равно, что вставить круглый штифт в квадратное отверстие. Как и в облачном пространстве, перспективные процессоры должны иметь искусственный интеллект в самой своей ДНК.
Отвечая насущным потребностям, выпущенные сегодня чипы Intel Core Ultra, ранее известные как Meteor Lake, используют новейшие технологии ЦП и графического процессора совершенно новый нейронный процессор (NPU) для выполнения определенных операций ИИ. Хорошим примером такого трехпроцессорного подхода к совместной работе является использование автономной модели Meta Llama 2 7bn. НПУ с низким энергопотреблением помогает в общей обработке LLM, но берет на себя исключительные обязанности по автоматическому распознаванию речи с помощью вышеупомянутого Whisper.
Конечно, вы можете попробовать запустить Llama 2 LLM (7 миллиардов) на более старой технологии, но это обнажает то, что даже скромные локальные вычисления ИИ сбивают с толку неоптимизированные проекты. Проще говоря, хороший опыт работы с искусственным интеллектом требует правильного сочетания аппаратного обеспечения.
«ЧТОБЫ ИИ БЫЛ ПОВСЮДУ, ОН ДОЛЖЕН РАБОТАТЬ НА ВСЕМ».
Включение еще одного выделенного процессора — настоящее благо для повышения производительности ИИ в обычных творческих рабочих процессах. В качестве яркого примера возьмем локально запущенную Stable Diffusion. Последний процессор Core Ultra 7 165H почти в два раза быстрее Core i7-1370P последнего поколения и, согласно данным Intel, находится в другой лиге, чтобы конкурировать с мобильными решениями AMD.
И в этом вся суть. Важные новые рабочие нагрузки всегда диктовали проектирование архитектуры. Однако сейчас внутри всеобъемлющего ИИ достаточно инерции, чтобы потребовать, чтобы большинство будущих процессоров имели специализированное оборудование. Если бы я делал ставки, последующие процессоры Core будут выделять больше кремния для обработки искусственного интеллекта, чем, скажем, для традиционных исполнительных ядер. По сути, процессор быстро превращается в полноценную SoC, и новейший многоячеечный процессор Core Ultra является свидетельством этого факта.
«ВКЛЮЧЕНИЕ ЕЩЕ ОДНОГО ВЫДЕЛЕННОГО ПРОЦЕССОРА — НАСТОЯЩЕЕ БЛАГО ДЛЯ ПРОИЗВОДИТЕЛЬНОСТИ ИИ».
Поскольку искусственный интеллект никуда не денется, его последствия для реального мира будут очень глубокими. Я считаю, что нет смысла приобретать клиентские процессоры, в которых отсутствуют встроенные технологии, специфичные для искусственного интеллекта. Большинство читателей понимают инициализмы ЦП и ГП: скоро в эту знакомую категорию попадут и NPU.
Упрощение разработки ИИ
В крестовом походе ИИ нет пути назад. Говоря о масштабах, внутренние исследования показывают, что к 2025 году на рынке появится более 100 миллионов ПК на базе процессоров Intel с той или иной формой ускорения искусственного интеллекта. Это большая база установок, готовая для разработки. Понимая, что хорошее программное обеспечение способствует внедрению аппаратного обеспечения, Intel планирует иметь более 100 партнеров по программному обеспечению для искусственного интеллекта до 2024 года. Если вы его создадите, они придут.
Большая часть исследований и моделирования началась в научном сообществе и развивалась на платформах глубокого обучения, таких как PyTorch, Caffe, ONNYX и TensorFlow. Обеспечивая хорошую работу с гетерогенным оборудованием Intel за счет подхода «однократная запись и развертывание где угодно», набор инструментов OpenVINO упрощает импорт и оптимизацию моделей.
Эта простота использования является абсолютно ключевым моментом в распространении ИИ с помощью эклектичного оборудования. Клиентам нужен простой способ внедрения искусственного интеллекта как для обучения, так и для получения логических выводов.
Хорошим примером такого подхода является программа Intel Geti. Программное обеспечение позволяет создавать модели компьютерного зрения для приложений искусственного интеллекта. Простота является ключевым моментом. Geti требуется всего 10–20 изображений, чтобы начать работу и обучение. Программное обеспечение, оптимизированное для OpenVINO, хорошо подходит для обнаружения, классификации и сегментации объектов. Оно позволяет быстро создавать прототипы и сокращает время, необходимое для полноценного запуска и запуска искусственного интеллекта.
Создание более разумных решений
Появление ИИ фундаментально меняет то, как технологические компании создают будущие продукты и услуги. Любая дорожная карта продукта, лишенная продуманной интеграции, находится под серьезной угрозой немедленного устаревания.
Большая часть текущего внимания сосредоточена на огромных центрах обработки данных с доступом к облаку, которые производят обучение и логические выводы в невероятных масштабах. Это будет продолжаться, поскольку неудовлетворенный спрос на существующие вычисления значителен и усиливается за счет возникающего интереса со стороны отраслей, пытающихся освоить внутренние преимущества, предоставляемые ИИ.
Однако для настоящего распространения требуется нечто большее, чем просто центры обработки данных с интенсивными вычислениями, передающие результаты через Интернет. Следующий неизбежный этап — это этап, когда ИИ проникает в повседневную жизнь, хотя и практически не обращает внимания на пользователя, а для этого ему необходимо стать более персонализированным и запускаться на локальных устройствах. Дело не только в облаке.
Эта переходная революция ПК уже идет полным ходом. Чтобы ИИ был повсюду, ему необходимо обрабатывать все — будь то ноутбук, ПК или сервер. Для повышения эффективности рабочие нагрузки искусственного интеллекта должны работать на правильном кристалле, и именно здесь совершенно новый NPU присоединяется к традиционным CPU и GPU как братья по оружию.
Объединив эти технологии, новейшие процессоры Intel используют этот многосторонний подход, делая локально управляемый искусственный интеллект доступным и эффективным. Если вы планируете купить ноутбук, который будет хорош сегодня и будет лучше завтра, определенно стоит инвестировать в перспективный дизайн.
Python — это язык программирования высокого уровня.
После года разработки Анонсирован выход стабильной версии а также начало фазы альфа-тестирования языка программирования Python 3.12 и Python 3.13 (соответственно). Упоминается, что эта новая ветка Python 3.12 будет поддерживаться в течение полутора лет, после чего еще в течение трех с половиной лет будут генерироваться исправления для устранения уязвимостей.
Представленная новая версия Python 3.12 содержит улучшения в гибкость анализа f-строки. Теперь с этим улучшением многие ограничения можно оставить в стороне, поскольку, например, теперь вы можете содержать любое допустимое выражение в Python, включая многострочные выражения, комментарии, обратную косую черту и escape-последовательности Unicode. Кроме того, внутренние строки теперь позволяют повторно использовать одни и те же кавычки, т. е. теперь двойные кавычки можно повторно использовать внутри. без необходимости перехода на одинарные кавычки.
WordPress 6.3 Lionel: доступны новости о новой версии
Прошло некоторое время с тех пор, как мы делились информацией, связанной с великим CMS WordPress, поэтому и воспользовавшись тем, что несколько дней назад (8 августа 2023) новая версия называется «WordPress 6.3 Лайонел», сегодня мы посвятим этот пост изучению того, что нового в этом выпуске.
И в случае, если вы не знаете что такое CMS и что такое WordPressСтоит уточнить, что первым является Интегрированная среда разработки (IDE) что позволяет нам создавать, управлять, поддерживать и обновлять веб-сайт в дополнение к самому себе. По этой причине он обычно включает в себя определенное количество опций и дополнительных функций. Принимая во внимание, что WordPress надежная CMS, которую можно бесплатно скачать и использовать, но это также огромная и отличная бесплатная и платная платформа для публикации и хостинга сайтов, известная как WordPress.com, которая получает очень частые обновления. Имея это в виду, давайте перейдем к новостям.
 Windows 11 Читать
Windows 11 Читать