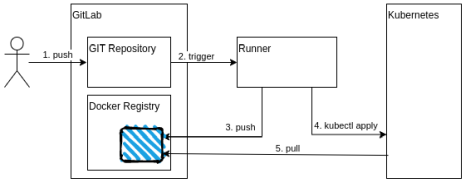
Kubernetes — одна из самых популярных платформ автоматизации для развертывания, масштабирования и работы контейнеров приложений в кластере хостов или узлов. Развертывание кластеров в Kubernetes на виртуальных машинах требует наличия специальных знаний, поэтому если нужна с этим помощь, можно обратиться к специалистам компании «Flant».
Если у вас есть веб-приложение с соответствующим файлом Dockerfile, теперь вы можете перейти к следующему шагу и использовать GitLab для автоматического развертывания вашего приложения в кластере kubernetes. Вот как…
Для этого поста в блоге вам понадобится:
ваш исходный код и файл Dockerfile размещены в проекте GitLab
бегун GitLab с исполнителем docker-in-docker
доступ к кластеру kubernetes
Процесс на самом деле состоит из 2 этапов:
создайте образ Docker и перейдите во встроенный реестр Docker в GitLab
используйте kubectl apply для развертывания новой версии
1. Сборка
Если ваш Dockerfile готов, создание образа — это просто вопрос запуска docker build ...и docker push .... Однако есть еще несколько хитростей:
мы будем использовать push для встроенного реестра Docker в GitLab;
мы будем использовать предопределенные переменные среды GitLab, чтобы получить соответствующий логин, пароль, имя изображения и т.д.;
нам нужен docker-in-docker runner, имидж и сервис.
бегун GitLab может получить доступ к кластеру kubernetes
кластеру kubernetes разрешено извлекать изображение из нашего частного реестра GitLab
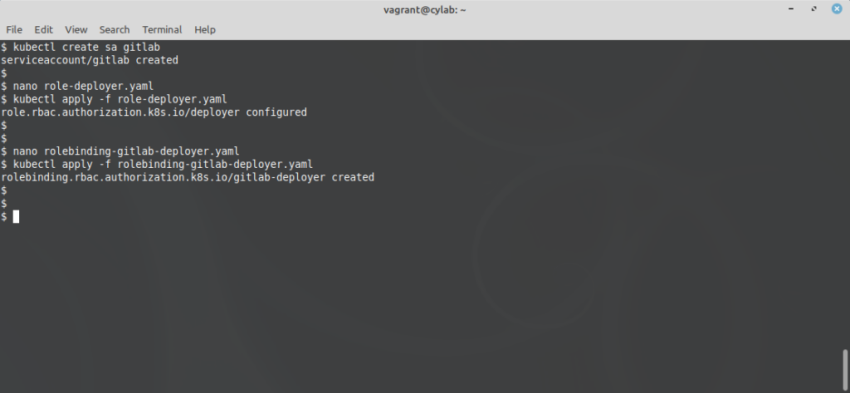
a. Доступ GitLab к kubernetes
Чтобы предоставить GitLab доступ к вашему кластеру kubernetes, используйте kubectl для создания учетной записи службы (SA):
kubectl create sa gitlab
В настоящее время этой учетной записи разрешен вход в систему, но у нее нет абсолютно никаких других прав. Это довольно бесполезно! Итак, мы должны определить роль, например, в файле с именем role-deployer.yaml:
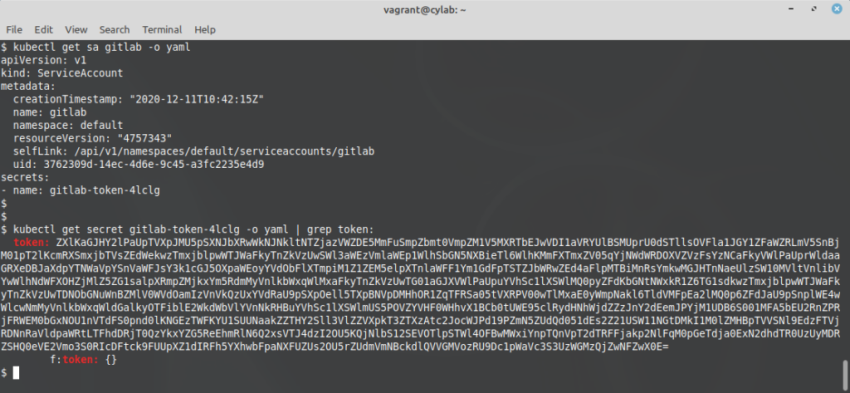
Now we have to extract the token that kubernetes created for the gitlab account:
kubectl get sa gitlab -o yaml
kubectl get secret gitlab-token-??? -o yaml | grep token:
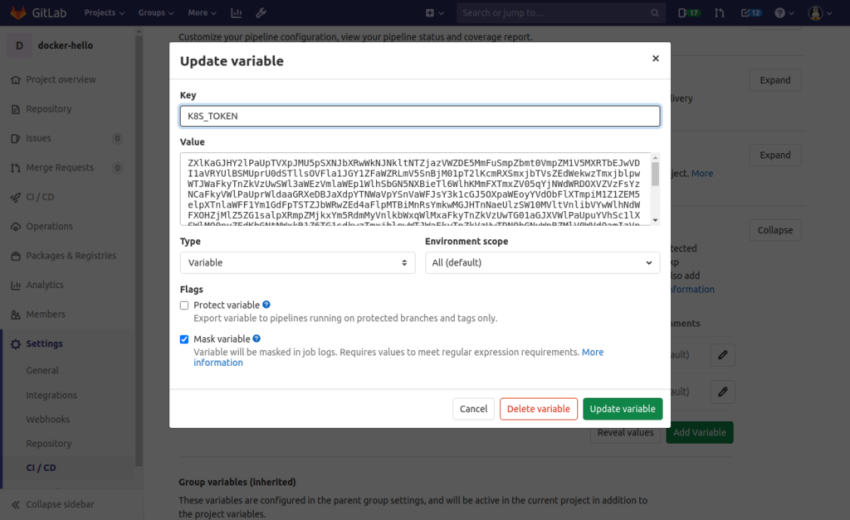
Наконец, в GitLab мы определяем 2 переменные вSettings > CI / CD / Variables:
K8S_TOKEN с помощью токена, который мы только что извлекли
K8S_SERVER с адресом сервера API kubernetes (https://kube.example.com:6443)
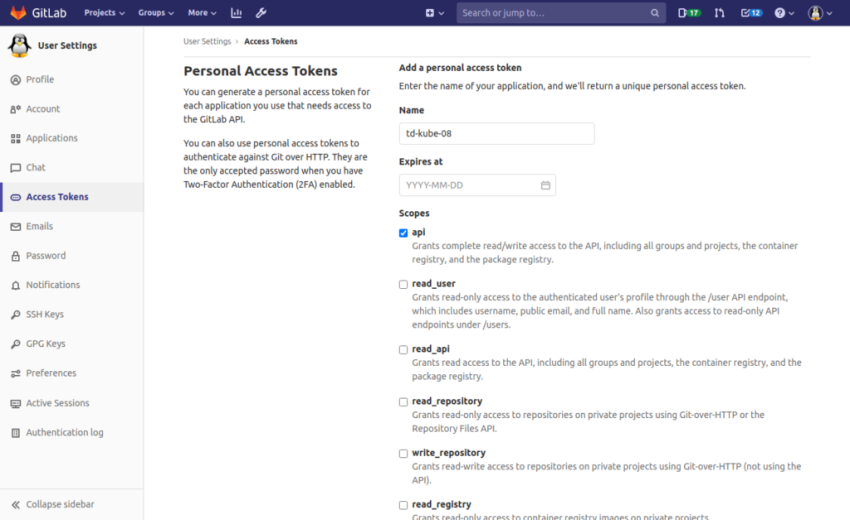
б. Доступ Kubernetes к GitLab
Чтобы разрешить доступ из Kubernetes к реестру GitLab, перейдите Personal menu > Settings > Access Tokensи создайте токен личного доступа с областью apiдействия .
Then, back on kubernetes, use kubectl to create a PullSecret called gitlab-token:
before_scriptраздел использует переменные $K8S_SERVERи $K8S_TOKENдля создания соответствующего контекста kubectl
scriptраздел использует envsubstкоманду и deploy.tmplшаблон для создания соответствующего deploy.yaml
Вот пример deploy.tmpl, который вы, очевидно, должны настроить для своего приложения. Он содержит один контейнер и 4 реплики, он использует gitlab-token PullSecret и имеет службу NodePort для предоставления приложения:
Осенью 2018 года мы опубликовали список из 25 полезных инструментов Kubernetes. С тех популярность платформы сильно выросла. Экосистема оркестрации контейнеров бурно развивается, можно найти вспомогательные инструменты практически для любой задачи.
Поэтому команда Kubernetes aaS от Mail.ru обновила и дополнила подборку. Предлагаем вашему вниманию список с почти сотней полезных инструментов, упрощающих жизнь тем, кто работает с Kubernetes.
Оператор Kubernetes, который автоматизирует обновления DaemonSet, StatefulSet, Helm и Deployment. Одна команда, никаких зависимостей, конфигурационных файлов и блокировок.
Набор служб Kubernetes, который упрощает работу в продакшене под серьезной нагрузкой. Обеспечивает мониторинг производительности в кластере, ведение журналов, управление сертификацией и автоматическое обнаружение ресурсов в K8s через общедоступные DNS-серверы. Это полезный набор сервисов и для других инфраструктурных нужд.
После установки k3sup (произносится как ketchup) вы можете за считанные секунды сгенерировать kubeconfig на любой локальной или удаленной виртуальной машине.
На платформе можно развернуть кластеры Kubernetes в виде облачного сервиса: за несколько минут вы получите готовый к работе кластер без необходимости в настройке и обновите его до нужной версии. Также кластеры просто масштабировать — они работают на инфраструктуре Mail.Ru, рассчитанной на высоконагруженные сервисы.
Средство для инициализации кластеров Kubernetes в оптимальной конфигурации на вашей инфраструктуре. Главное преимущество — возможность запускать минимально жизнеспособные кластеры Kubernetes в любой среде. Надстройки и сетевые настройки не входят в конфигурацию из коробки, все придется настроить вручную.
Набор ролей Ansible для развертывания и конфигурации Kubernetes. Работает на разных облачных платформах: AWS, GCE, Azure, Mail.Ru Cloud Solutions, OpenStack и bare metal IaaS. Это open source проект, построен на kubeadm. Подходит тем, кто хорошо знаком с Ansible — с этим инструментом вам ничего не нужно больше знать, чтобы развернуть все нужные ресурсы.
Позволяет развертывать Kubernetes с помощью нескольких команд, поддерживает развертывания на локальном хосте, bare metal, в облачных средах, в том числе OpenStack.
Хорошее начало для тех, кто только знакомится с Kubernetes. Инструмент позволяет пользователям легко запускать одноузловой кластер локально внутри виртуальной машины на ноутбуке пользователя. Поддерживается в Mac OS X, Windows и Linux.
Запускает автономные кластеры и помогает настроить временную плоскость управления Kubernetes. Bootkube также можно использовать для создания необходимых ресурсов, которые будут использоваться при начальной загрузке нового кластера.
Сертифицированный CNCF дистрибутив Kubernetes, работающий внутри контейнеров. Позволяет упростить и автоматизировать установку Kubernetes, не зависеть от операционной системы и платформы, на которой вы работаете.
Простая утилита для прослушивания сервера Kubernetes API, помогает в генерации метрик о состоянии объектов. Фокусируется на работоспособности различных объектов внутри кластера, включая узлы, поды и развертывания.
Терминальная консоль, позволяющая управлять кластером Kubernetes и отслеживать его статус в режиме реального времени. Мониторит кластер, показывает, что происходит с ресурсами подов, журналы контейнеров и другие параметры. Позволяет легко перейти к нужному пространству имен и выполнить команду в нужном контейнере. Это помогает быстро справляться с неполадками и восстанавливать работу.
Плагин Rakess (Review Access) показывает все права доступа к кластеру Kubernetes. Конечно, для отдельных ресурсов можно выполнить проверку командой kubectl auth can-i list deployments, но она не дает полную информацию обо всех ресурсах на сервере.
Bash-скрипт, позволяющий агрегировать журналы многих подов в один поток. В исходной версии не умеет фильтровать или выделять, но на Github есть отдельный форк, позволяющий раскрашивает логи с помощью MultiTail.
Еще один инструмент из категории «tail для подов в Kubernetes». Особенности: использование регулярных выражений для удобной фильтрации подов (не нужно знать конкретные ID), аналогично можно фильтровать отдельные контейнеры для запрашиваемых подов, есть стандартные и кастомные Go-шаблоны для выводимых логов, ограничение вывода логов по периоду времени или количеству строк и много чего еще.
Не можем снова не упомянуть этот опенсорсный инструмент для мониторинга и уведомлений, который давно стал стандартом для мониторинга Kubernetes. Он интегрирован со всеми популярными языками программирования, помогает создавать собственные метрики и содержит много готовых интеграций с популярными технологиями, например: PostgreSQL, MySQL, ETCD.
С помощью Prometheus Operator можно создавать экземпляры Prometheus в кластерах Kubernetes, в том числе тесную интеграцию с Grafana и Alertmanager.
Инструмент трассировки с открытым исходным кодом. Умеет мониторить транзакции и сервисные зависимости в распределенных системах, выявлять и устранять неполадки. Один из способов начать работу с ним в Kubernetes — использовать специальный оператор Jaeger.
Оператор Kubernetes для Icinga. Умеет запускать периодические проверки на кластерах Kubernetes, а потом отправлять уведомления по электронной почте, СМС или в чат, если что-то идет не так. В инструмент по дефолту включен комплект проверок специально для Kubernetes. С его помощью можно расширить возможности мониторинга Prometheus, также он станет резервной системой, если внутренние системы мониторинга полностью откажут.
Read-only системная панель, способная работать со многими кластерами Kubernetes. Позволяет удобно перемещаться между кластерами, отслеживать ноды и состояние подов. Визуализирует ряд процессов, таких как создание и уничтожение подов.
Запускается в подах в кластере Kubernetes, отслеживает системные изменения, после запуска вы будете получать уведомления через веб-хуки. Можно настроить свои уведомления, просто отредактировав файл конфигурации.
Отслеживает и устраняет неполадки в кластерах Kubernetes и Docker, чтобы вы могли легко выявлять и устранять проблемы с контейнеризованными приложениями. Вы можете использовать его, чтобы определить узкие места производительности приложений.
Обеспечивает видимость всего вашего стека, позволяет контролировать эффективность базовой инфраструктуры и производительность запущенных микросервисов в Kubernetes.
Инструмент для проверки конфигурационного файла Kubernetes YAML или JSON. Проверка осуществляется с использованием схем, сгенерированных из Kubernetes OpenAPI. Это позволяет производить валидацию схем для разных версий Kubernetes.
Плагин Helm, используемый для валидации диаграмм на соответствие схемам Kubernetes. Для проверки диаграмм можете выбрать определенные версии Kubernetes.
BotKube может отслеживать, отлаживать и запускать проверки в кластерах Kubernetes. Инструмент также интегрируется в различные платформы для обмена сообщениями, такие как Slack и Mattermost. Преимущества — открытый исходный код и простота настройки.
Sonobuoy — диагностический инструмент для проверки на соответствие нормативам, отладки рабочей нагрузки и проведения пользовательских тестов, которые помогают определить состояние кластера. Тесты выполняются неразрушающим образом, при этом генерируются четкие информативные отчеты.
Состоит из двух диаграмм Helm для тестирования пропускной способности сети и нагрузочного тестирования кластеров Kubernetes. Это поможет убедиться в правильности их конфигурации, а также в работоспособности служб и правильном распределении нагрузки.
Инструмент специфичен для Kubernetes и также следует принципам хаос-инжиниринг, позволяя проверить объекты, работающие в контейнерах. Также его можно использовать для проверки выбранных компонентов кластера вручную через интерактивный режим. После развертывания инструмент работает автономно.
Реестры Harbor защищают образы с контейнерами путем внедрения системы управления доступом на основе ролей. Инструмент также проверяет образы на наличие уязвимостей и подписывает их как надежные.
Инструмент с открытым исходным кодом для анализа рисков безопасности ресурсов Kubernetes. С ним вы сможете контролировать систему и получите полный список рекомендаций по повышению ее общей безопасности.
Это приложение разработки компании SIGHUP позволяет легко управлять ролями доступа для Kubernetes через систему Role-Based Access Control. Создайте пользователей, назначьте пространство имен/разрешения, а также распространите файлы Kubeconfig YAML.
Инструмент от компании Octarine фокусируется на оценке рисков в рабочих нагрузках Kubernetes. Kube-scan запускается как под в кластерах и оценивает 30 параметров безопасности, чтобы вывести максимально приемлемый уровень риска. Затем инструмент анализирует, какие параметры работают в тандеме, чтобы понять, какие комбинации уменьшат уровень угроз.
K-rail предназначен для ситуаций, когда требуется чуть больше контроля в реализации ваших политик. Есть множество простых способов повышения привилегий, но в мультитенантном кластере они могут представлять опасность или приводить к нестабильности.
KeyCloak — опенсорсный инструмент управления доступом и идентификационной информацией пользователей. Он добавляет функцию аутентификации приложений и помогает минимальными усилиями обеспечить безопасность служб. Устраняет необходимость детально разбираться с ведением списка пользователей и их аутентификацией. Всё это теперь работает прямо из коробки.
Инструмент предназначен для защиты инсталляций Kubernetes на протяжении всего жизненного цикла. Он развертывает на каждом контейнере выделенный агент, работающий как межсетевой экран и устраняющий возможные уязвимости. Управлять ограничениями безопасности вы сможете через центральную консоль. Кроме того, инструмент позволяет использовать гибкие настройки безопасности в локальных и облачных средах.
С ним связан еще один open source инструмент — Kube-Bench, проверяющий среду Kubernetes по тестам из документа CIS Kubernetes Benchmark.
Инструмент от создателей проекта Calico, набор решений для сетевой безопасности Kubernetes с поддержкой мультиоблачных и устаревших сред через автоматизированную универсальную политику безопасности.
Klum, или Kubernetes Lazy User Manager, выполняет простые задачи, такие как создать/удалить/изменить пользователей. Он выдает файлы kubeconfig и управляет ролями юзеров.
StrongDM — это плоскость управления для проверки безопасности и доступа к вашим серверам и/или базам данных. Состоит из API аутентификации, прокси-сервера, поддерживающего протокол, и хранилища журналов.
Инструмент для обеспечения безопасности с открытым исходным кодом для облачных вычислений, обнаруживает риски для Kubernetes. Замечает неожиданное поведение приложения и оповещает об угрозах во время его выполнения.
Платформа, обеспечивающая мониторинг безопасности микросервисов и контейнеров. Поддерживаются Kubernetes и Docker. Может быть использована в облаке и локально.
Krew помогает разработчикам находить полезные плагины kubectl для программ и устанавливать, а потом управлять ими. Этот инструмент похож на APT, DNF или Homebrew.
Скрипт Kube-ps1 добавляет текущий контекст Kubernetes и сконфигурированное пространство имен из kubectl в консоль Bash/Zsh, никаких команд не требуется.
Если вы запускаете службы Kubernetes на удаленном кластере, то Kubefwd поможет перенаправить их на локальную рабочую станцию. Никаких модификаций не требуется: если вы используете kubectl, вы уже соответствуете всем требованиям.
Skaffold — консольная утилита, помогающая обеспечить процесс непрерывной разработки приложений Kubernetes. Инструмент очень легкий и не требует компонентов на стороне кластера.
Простой и очень мощный генератор алиасов для kubectl. С его помощью вы сможете очень быстро писать команды для повседневного администрирования Kubernetes, так как он предоставляет более 800 коротких алиасов на все случаи жизни.
Опенсорсная утилита, дополняет Kubectl, позволяет переключать контекст и подключаться одновременно к нескольким кластерам Kubernetes, а также перемещаться между пространствами имен. Есть поддержка автозаполнения в оболочках bash/zsh/fish.
kubectx помогает переключаться между кластерами вперед и назад:
kubens помогает плавно переключаться между пространствами имен Kubernetes:
Инструмент, ускоряющий работу с kubectl. Автодополняет команды, предлагает разные варианты, ищет и исправляет команды, которые введены неправильно, отображает in-line справку о выполняемых командах.
Если вы редко выходите из консоли, Tilt синхронизирует все изменения с кластером и обновляет серверы, так что вы сразу видите, как внесенные изменения влияют на систему. Инструмент показывает состояние каждого ресурса, выдает журналы для каждого из них или всё вместе. Все обновления выполняются внутри контейнера, что делает их очень быстрыми.
Инструмент позволяет отслеживать логи Docker для нужных подов. Он фильтрует поды по службам, развертываниям, меткам и иным параметрам. В соответствии с критериями фильтрации поды после запуска будут автоматически добавлены в журнал или удалены из него.
Пакетный менеджер, помогает управлять приложениями Kubernetes с помощью Helm Charts. Это позволяет пользователям создавать воспроизводимые сборки, которыми можно делиться.
Rook помогает автоматизировать различные задачи для хранилища данных, такие как развертывание, загрузка, масштабирование, обновление и так далее. Это гарантирует, что на Kubernetes будет стабильно работать решение любого поставщика (Ceph, EdgeFS, CockroachDB, Cassandra, NFS, Yugabyte DB).
Shell Operator упрощает создание операторов Kubernetes. Он обеспечивает интеграцию между событиями кластера Kubernetes и сценариями оболочки. Упрощает управление кластером.
Инструмент для управления релизами helm-чартов. Позволяет в одном месте описывать множество helm релизов, задавать порядок их деплоя и делать другие полезные вещи.
Этот инструмент автоматически генерирует документацию из диаграмм Helm в файл markdown. Данный файл содержит метаданные, включая таблицу со всеми значениями диаграммы и значениями по умолчанию.
Позволяет запускать дополнительный контейнер в интересующем вас поде. Новый контейнер будет использовать пространство имен совместно с целевым контейнером/контейнерами.
Почти мгновенно синхронизирует файлы вашей локальной системы с кластером Kubernetes. Подходит, если вы используете сценарии, в которых основной проблемой является доставка кода в работающий контейнер.
Используют для отладки процессов во время их работы в кластере. Простой в использовании, вы можете в интерактивном режиме выбрать нужный отладчик и пространство имен/под интересующего процесса.
Rafay — программный инструмент, который упрощает для компании или отдельного разработчика создание собственной платформы, системы автоматизации и управления жизненным циклом приложений. Rafay также способен запускать кластеры Kubernetes.
Rancher — полноценная программная платформа, которая легко развертывает контейнерные среды, выходящие за рамки инсталляторов Kubernetes, таких как Kops и Kubespray. Предоставляет множество функций, включая управление инфраструктурой, планирование и оркестровку контейнеров, мониторинг, проверку работоспособности, ведение журналов, а также мощную систему управления доступом на основе ролей.
Утилита от разработчиков Helm. Ее цель — упростить приложения, которые разрабатываются для работы в Kubernetes. С помощью двух простых команд вы можете работать с контейнерными приложениями, даже не нуждаясь в установке Docker или Kubernetes.
Пожалуй, наиболее популярный open source CI/CD-сервер в мире. К нему есть бесплатный плагин, помогающий развертывать приложения в Kubernetes, обновлять их с минимальным простоем и обеспечивать Green/Blue-развертывание обновлений.
Известный CI/CD сервис от JetBrains. Есть плагин, с которым можно использовать инфраструктуру кластера Kubernetes для запуска билд-агентов TeamCity (в версии 2017.1.x и новее).
Решение для непрерывного развертывания (CD), предоставляющее интерфейс самообслуживания для команд. Может интегрироваться с существующими процессами сборки. Это позволяет управлять кластерами Kubernetes, предоставляя каждому пользователю определенные разрешения для обеспечения безопасности развертывания.
CLI-инструмент с открытым исходным кодом, написанный на Go, предназначен для упрощения и ускорения доставки приложений. Werf создает образы Docker с использованием Dockerfiles или альтернативного быстрого встроенного компоновщика на основе собственного синтаксиса. Он также удаляет неиспользуемые образы из реестра Docker. Потом Werf развертывает ваше приложение в Kubernetes, используя диаграмму в формате, совместимом с Helm, с удобными настройками и улучшенным механизмом отслеживания развертывания, обнаружения ошибок и вывода журнала.
Инструмент позволяет создавать конвейеры, которые можно встроить в любую существующую систему CI/CD.
Garden — инструмент для разработчиков, который автоматизирует ваши рабочие процессы и делает разработку и тестирование приложений Kubernetes быстрее и проще. Подходит для совместной разработки в удаленном кластере.
Kiali помогает создавать определения, проверять и наблюдать за работой микросервисов и соединений в сервисной сетке Istio. Инструмент создает визуальное графическое представление топологии сервисной сетки и дает представление о таких функциях, как разрыв цепи (circuit breaker), маршрутизация запросов, задержка и других.
Универсальная панель управления для сервисных сеток и микросервисов. Может нативно работать и в виртуальной среде, и в Kubernetes. Легко вводится в арсенал инструментов любой команды в организации.
Tenkai — это менеджер микросервисов, основанный на диаграммах Helm. Инструмент с графическим веб-интерфейсом позволяет вызывать репозитории из диаграмм Helm, легко их настраивать и деплоить.
Репозиторий с множеством инструментов для обнаружения служб, которые видны из ваших приложений с микросервисами. Службы можно импортировать и из Kubernetes (а также из Docker и Consul).
Веб-инструмент с открытым исходным кодом, который позволяет визуализировать ваши рабочие нагрузки Kubernetes и предоставляет по ним обновления в режиме реального времени.
Kubernetic помогает легко и быстро развертывать общедоступные или приватные диаграммы, видеть все связанные объекты кластера и их зависимости на одном экране. Отличается такими функциями, как визуализация в реальном времени, а также поддержка нескольких кластеров.
Веб-интерфейс для каталога приложений в кластерах Kubernetes. Позволяет устанавливать, обновлять и удалять Helm-чарты нажатием одной кнопки, без использования командной строки.
Приложение для рабочего стола, работает в Windows, Mac и Linux. Может подключаться к локальному кластеру K8s, подходит для небольшого количества кластеров.
Программное обеспечение с открытым исходным кодом, удобный графический интерфейс. Отображает все конфигурации, относящиеся к приложению, в одном месте. Это экономит время, избавляя от необходимости искать настройки и копаться в селекторах и метках. Один из недостатков инструмента — он работает непосредственно на кластере K8s. Значит, вам придется развертывать Kubevious на каждом кластере, а не просто указывать на существующий.
Основанный на терминалах пользовательский интерфейс, использующий Node.js. Довольно прост в использовании, но в настоящее время ограничен несколькими командами kubectl. Позволяет легко перемещаться по различным пространствам имен кластера K8s и быстро отображать состояние заданного набора подов.
Безсерверная инфраструктура Kubernetes с открытым исходным кодом, которая позволяет вам развертывать небольшие фрагменты кода. Поддерживает большинство популярных языков, позволяет редактировать и развертывать функции в режиме реального времени.
Еще один открытый серверный фреймворк Kubernetes с открытым исходным кодом. Поддерживает все языки программирования. Напишите недолговечные функции на любом языке и сопоставьте их с HTTP-запросами (или другими триггерами событий) — инструмент позволяет развернуть функции мгновенно с помощью одной команды. Нет контейнеров для сборки и нет реестров Docker для управления.
Это модель программирования лямбда-стиля с открытым исходным кодом для Kubernetes. Позволяет разработчикам сосредоточиться на написании функций, в то время как Kubernetes позаботится обо всем остальном.
Серверная вычислительная платформа с открытым исходным кодом для любого облака — частного, общедоступного или гибридного. Используя этот инструмент, разработчики могут просто загрузить свой код, пока платформа работает с инфраструктурой.
Упрощает развертывание как функций, так и существующего кода в Kubernetes. Работает в публичных и частных облаках. Позволяет создавать микросервисы и функции на любом языке.
Cерверный проект, который позволяет использовать его в качестве автономного контейнера Docker или даже поверх другого кластера Kubernetes. Предназначен для работы с высокопроизводительными событиями и большими объемами данных. Также обеспечивает обработку данных в режиме реального времени с минимальными издержками.
Является открытой реализацией Kubernetes Kubelet. Запускается внутри контейнера в вашем текущем кластере и маскируется под узел. Оттуда он контролирует запланированные пакеты так, как это делает настоящий Kubelet.
На этом всё. Пишите в комментариях, если знаете другие полезные инструменты.
Стоит попробовать Mizu – это ПО для мониторинга Kubernetes-трафика. Программа может сильно упростить ежедневную диагностику сетей, да и жизнь в целом.
Одна из наиболее частых задач, с которыми сталкиваются администраторы Kubernetes по ходу тестирования и дебаггинга – проверка коммуникаций между компонентами внутри сети.
Если вы хоть как-то взаимодействуете c Kubernetes по работе, то наверняка частенько проверяете входящий трафик, чтобы изучить входящие запросы и т.п. Обычно задачи подобного рода решаются при помощи утилиты tcpdump, установленной в конкретный контейнер. Таким образом, проверяются некоторые сетевые аспекты вне контейнеров, но иногда такой подход оказывается довольно сложным из-за специфики окружения или конфигурации системы.
Чтобы не натыкаться на кучу проблем по ходу мониторинга сети, советую использовать утилиту Mizu. Многие программисты, работающие с Kubernetes, мечтали бы найти подобный инструмент раньше.
Mizu можно описать как простой, но при этом мощный инструмент для отслеживания трафика в Kubernetes. Он позволяет отслеживать все API-коммуникации между микросервисами независимо от используемого протокола и упрощает процесс дебаггинга соединений.
Установка Mizu
Процесс установки довольно простой. Все что нужно – загрузить бинарный файл Mizu и настроить соответствующие разрешения в системе. Выбор бинарного файла (установщика) зависит от архитектуры устройства. Например, чтобы установить Mizu на компьютер Apple с чипом Intel нужно ввести в терминал команду:
Обычно этого достаточно. Загруженный бинарный файл теперь можно использовать для подключения к кластеру Kubernetes и работы с Kubernetes API, но для этого нужно внести несколько изменений в настройки Докера.
Вот как это может выглядеть в случае с базовым nginx-сервером. Начать стоит с команды:
kubectl run simple-app --image=nginx --port 3000
После развертки базового приложения на основе nginx переходим непосредственно к запуску Mizu. Делается это всего одной командой:
mizu tap
Через пару секунд на экране появится веб-страница с интерфейсом Mizu. Здесь и отображается весь трафик на выбранном сервере. Но для настройки такого поведения необходимо внести изменения в параметры портов. К примеру, если ваше приложение называется ‘my-app’, команда будет выглядеть так:
kubectl expose pod/my-app
После этого деплоим еще один временный сервер, используя готовый образ (при помощи следующей команды):
kubectl run -it --rm --image=curlimages/curl curly -- sh
Теперь можно использовать утилиту curl для отправки запросов непосредственно на nginx-сервер. Например, так:
curl -vvv http://my-app:3000
Уже после первых нескольких запросов вы увидите большой объем полезной информации, отображающейся в интерфейсе Mizu. В первую очередь стоит отметить то, насколько детально описываются все процессы, происходящие внутри Kubernetes. Но что еще важнее, в Mizu есть диаграммы, наглядно показывающие зависимости между запросами с учетом используемого протокола и другой полезной информации.
Конечно, Mizu не сможет заменить более сложные продукты и полноценные системы наблюдения за сетью. Но это довольно удобный инструмент, который поможет вам исправить немало багов по ходу работы с Kubernetes, и его точно стоит иметь под рукой.
Kubernetes поставляется в комплекте с выдающимся CLI.
Для основных операций это работает чудесно.
Увы, когда нужно что-то сделать быстро, сложность возрастает.
Сообщество Kubernetes создало все виды веб-инструментов для мониторинга вашего кластера – kube ops, grafana и т. д.
Однако наличие полностью настроенного терминала быстро сократит время, необходимое для поиска причины проблемы.
Это основная часть вашего швейцарского армейского ножа.
Ниже приведен очень короткий список инструментов с открытым исходным кодом, которые можно применить в своем терминале.
При совместном использовании они позволяют управлять кластером kubernetes, быстро устранять неполадки и отслеживать поведение.
Предпосылки
Прежде чем приступить к изучению этих инструментов, я настоятельно рекомендую установить zsh.
Это выдающаяся оболочка с открытым исходным кодом для стандартного терминала OSX.
Он более многофункциональный и интуитивно понятный, а плагины, которые вы можете установить, просто фантастические.
Некоторые из перечисленных инструментов предполагают, что у вас установлен ZSH.
Лучшие инструменты для управления Kubernetes
k9s
Я начинаю с самого мощного.
K9s – это основа CLI для кластера kubernetes.
Вы можете проваливаться по SSH прямо в поды одним нажатием клавиши, просматривать журналы, удалять ресурсы и многое другое.
Он обеспечивает выдающийся доступ к наиболее распространенным операциям, которые вы будете выполнять.
Это основной продукт для любого инженера, использующего kubernetes.
kubectx
Очень редко у нас будет только один кластер.
Переключение между ними можно так же просто осуществлять:
kubectl config use-context my-context
Но при этом есть некоторые предпосылки:
Вам нужно знать имя кластера, прежде чем запускать команду.
Есть другая, похожая команда set-context, которая может сбить вас с толку.
kubectx представляет более простую альтернативу этому варианту.
Если вы запустите kubectx самостоятельно, он перечислит все контексты в вашем файле .kube/config.
Затем вы можете указать название интересующего вас контекста:
kubectx my-context
Не нужно запоминать все контексты, не нужно вручную проверять файлы и нет возможности ввести неправильную команду.
Красиво и просто.
В сочетании с K9s, этот набор обеспечивает классную навигацию из вашего CLI с минимальными нажатиями клавиш.
kubens
Как только вы переключаетесь между контекстами, вы можете долго копаться в определенном пространстве имен.
Еще раз, очень часто в вашем кластере имеется несколько пространств имен.
Короче, в двух словах это то же самое, что kubectx, только для пространств имен.
kubens kube-system
Теперь все ваши команды по умолчанию выполняются в пространстве имен системы kube-system.
Вы также можете запустить Kubens без флагов, чтобы увидеть список ваших пространств имен.
kube-ps1
Таким образом, вы можете переключаться между контекстами и пространствами имен.
Но как узнать, на кого вы сейчас нацелены?
Каждый раз постоянно это проверять?
На данный момент, чтобы узнать, вам нужно запустить:
kubens
kubectx
kubectl <my-command>
Чтобы не делать этого, ps1 является плагином zsh, который автоматически покажет вам ваш текущий контекст и пространство имен:
Теперь вы можете увидеть, на какое пространство имен и контекст вы указываете, не выполняя ни одной команды.
Он также очень настраиваемый – вы можете отключить пространство имен или контекст, если вас интересует только что-то одно из них, или вы можете использовать kubeoff, чтобы полностью отключить все это.
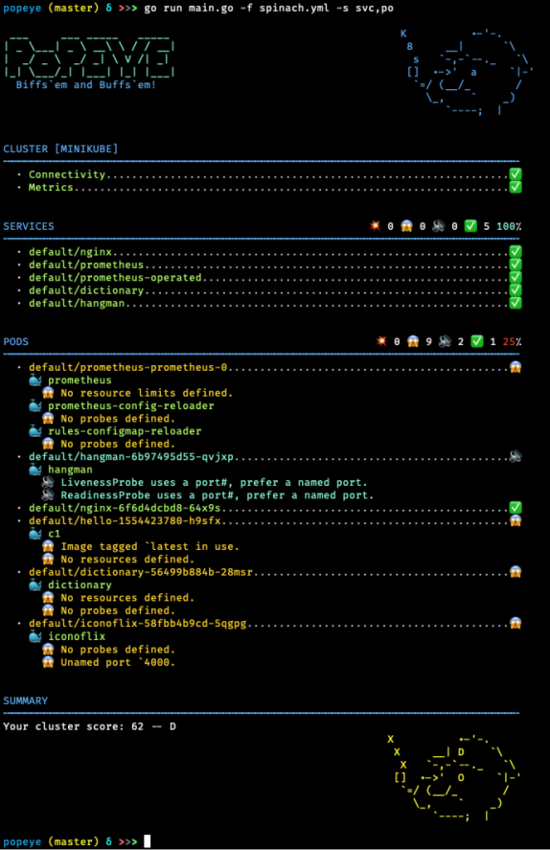
popeye
Popeye запускает автоматическое сканирование ресурсов в вашем хранилище и выявляет очевидные проблемы.
Это новый инструмент, который я нашел очень полезным.
Если вы затеяли генеральную уборку в кластере, начните с popeye, и вы получите четкие указания о том, что нужно исправить.
Stern
Вы когда-нибудь использовали логи kubectl?
Заметили, что вы можете следить только за журналами с одного пода одновременно?
Не беспокойтесь больше об этом!
Stern – это инструмент, который позволяет вам извлекать логи из нескольких подов, основываясь на очень гибком запросе.
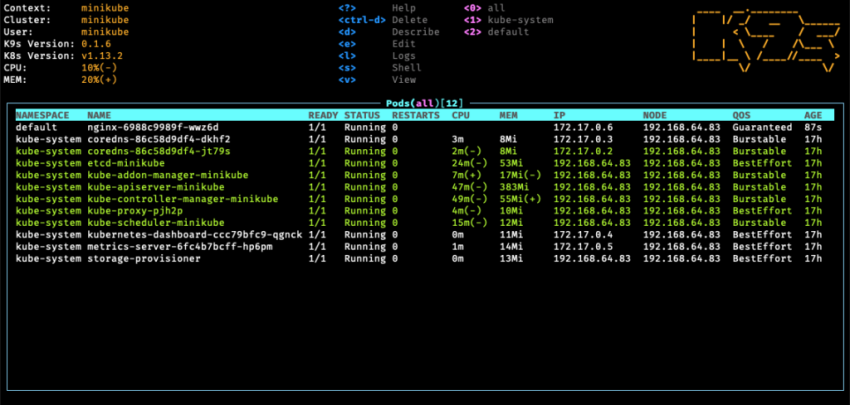
K9s предоставляет пользовательский интерфейс терминала для взаимодействия с кластерами Kubernetes. Цель этого Open Source-проекта — облегчить удобную навигацию по приложениям в K8s, наблюдение за ними и управление ими. K9s постоянно следит за изменениями в Kubernetes и предлагает быстрые команды для работы с наблюдаемыми ресурсами.
Проект написан на Go, существует уже более полутора лет: первый коммит был сделан 1 февраля 2019 года. На момент написания статьи насчитывается 9000+ звезд на GitHub и около 80 контрибьюторов. Посмотрим, что умеет k9s?
Установка и запуск
Это клиентское (по отношению к кластеру Kubernetes) приложение, которое проще всего запустить как Docker-образ:
docker run --rm -it -v $KUBECONFIG:/root/.kube/config quay.io/derailed/k9s
Для некоторых Linux-дистрибутивов и других ОС также есть готовые для установки пакеты. В общем случае для Linux-систем можно установить бинарный файл:
Каких-то специфических требований к самому кластеру K8s нет. Судя по отзывам, приложение работает и с такими старыми версиями Kubernetes, как 1.12.
Приложение запускается, используя стандартный конфиг .kube/config — аналогичному тому, как это делает kubectl.
Навигация
По умолчанию открывается окно со стандартным namespace, который указан для контекста. То есть, если вы прописали kubectl config set-context --current --namespace=test, то и откроется namespace test. (О смене контекстов/пространств имён см. ниже.)
Переход в режим команд осуществляется нажатием на «:». После этого можно управлять работой k9s с помощью команд — например, для просмотра списка StatefulSets (в текущем пространстве имен) можно ввести :sts.
Для некоторых других ресурсов Kubernetes:
:ns — Namespaces;
:deploy — Deployments;
:ing — Ingresses;
:svc — Services.
Чтобы вывести полный список типов ресурсов, доступных для просмотра, есть команда :aliases.
Удобно просматривать и список команд, доступных по горячим комбинациям клавиш в рамках текущего окна: для этого достаточно нажать на «?».
Также в k9s есть режим поиска, для перехода в который достаточно ввести «/». С ним осуществляется поиск по содержимому текущего «окна». Допустим, если вы до этого ввели :ns, у вас открыт список пространств имён. Если их слишком много, то, чтобы не скроллить долго вниз, достаточно в окне с namespaces ввести /mynamespace.
Для поиска по лейблам можно выбрать все pod’ы в нужном пространстве имён, после чего ввести, например, / -l app=whoami. Мы получим список pod’ов с этим лейблом:
Поиск работает во всех видах окон, включая логи, просмотр YAML-манифестов и describe для ресурсов — подробнее об этих возможностях см. ниже.
Как в целом выглядит последовательность действий для навигации?
С помощью команды :ctx можно выбрать контекст:
Для выбора namespace’а есть уже упоминавшаяся команда :ns, а далее можно воспользоваться поиском для нужного пространства: /test.
Если теперь выбрать интересующий нас ресурс (например, всё тот же StatefulSet), для него покажется соответствующая информация: сколько запущено pod’ов с краткими сведениями о них.
Могут быть интересны только pod’ы — тогда достаточно ввести :pod. В случае с ConfigMap’ами (:cm — для списка этих ресурсов) можно выбрать интересующий объект и нажать на «u», после чего K9s подскажет, кто конкретно его (этот CM) использует.
Ещё одна удобная фича для просмотра ресурсов — их «рентген» (XRay view). Такой режим вызывается командой :xray RESOURCE и… проще показать, как он работает, чем объяснять. Вот иллюстрация для StatefulSets:
(Каждый из этих ресурсов можно редактировать, изменять, делать describe.)
А вот Deployment с Ingress:
Работа с ресурсами
О каждом ресурсе можно получить информацию в YAML или его describe нажатием на соответствующие клавиатурные сочетания («y» и «d» соответственно). Базовых операций, конечно, ещё больше: их список и клавиатурные сочетания всегда на виду благодаря удобной «шапке» в интерфейсе (скрывается нажатием на Ctrl + e).
При редактировании любого ресурса («e» после его выбора) открывается текстовый редактор, определённый в переменных окружения (export EDITOR=vim).
А вот как выглядит подробное описание ресурса (describe):
Такой вывод (или вывод просмотр YAML-манифеста ресурса) можно сохранить с помощью привычного сочетания клавиш Ctrl + s. Куда он сохранится, будет известно из сообщения K9s:
Из созданных файлов-бэкапов можно и восстанавливать ресурсы, предварительно убрав системные лейблы и аннотации. Для этого потребуется перейти в директорию с ними (:dir /tmp), после чего выбрать нужный файл и применить apply.
К слову, в любой момент можно откатиться и на прошлый ReplicaSet, если с текущим есть проблемы. Для этого надо выбрать нужный RS (:rs для их списка):
… и выполнить rollback с помощью Ctrl + l. Мы должны получить уведомление, что все прошло успешно:
k9s/whoami-5cfbdbb469 successfully rolled back
А чтобы масштабировать реплики, достаточно нажать на «s» (scale) и выбрать нужное количество экземпляров:
В любой из контейнеров можно зайти с помощью shell: для этого перейдите к нужному pod’у, нажмите на «s» (shell) и выберите контейнер.
Другие возможности
Конечно, поддерживается и просмотр логов («l» для выбранного ресурса). А чтобы смотреть новые логи, нет необходимости постоянно нажимать Enter: достаточно сделать маркировку («m»), после чего отслеживать только новые сообщения.
Также в этом же окне можно выбрать временной диапазон для вывода логов:
клавиша «1» — за 1 минуту;
«2» — 5 минут;
«3» — 15 минут;
«4» — 30 минут;
«5» — 1 час;
«0» — за все время жизни pod’а.
Специальный режим работы Pulse (команда :pulse) показывает общие сведения о Kubernetes-кластере:
В нем можно увидеть количество ресурсов и их состояние (зеленым показываются те, что имеют статус Running).
Еще одна интересная функция K9s называется Popeye. Она проверяет все ресурсы на определённые критерии корректности и выводит получившийся «рейтинг» с пояснениями. Например, можно увидеть, что не хватает проб или лимитов, а какой-то контейнер может запускаться под root…
Имеется базовая поддержка Helm. Например, так можно посмотреть релизы, задеплоенные в кластер:
:helm all # все
:helm $namespace # в конкретном пространстве имен
Benchmark
В K9s встроили даже hey — это простой генератор нагрузки на HTTP-сервер, альтернатива более известному ab (ApacheBench).
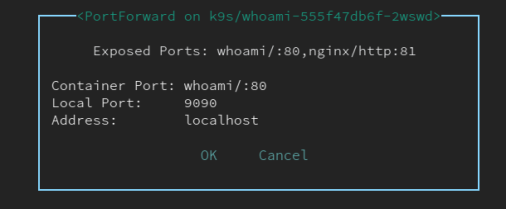
Чтобы включить его, потребуется активация port-forward в pod’е. Для этого выбираем pod и нажимаем на Shift + f, переходим в подменю port-forward с помощью алиаса «pf».
После выбора порта и нажатия на Ctrl + b запустится сам benchmark. Результаты его работы сохраняются в /tmp и доступны для последующего просмотра в K9s.
Для изменения конфигурации benchmark’а нужно создать файл $HOME/.k9s/bench-<my_context>.yml (определяется для каждого кластера).
NB: Важно, чтобы расширение всех YAML-файлов в директории .k9s было именно .yml (.yaml не работает корректно).
Пример конфигурации:
benchmarks:
defaults:
# Количество потоков
concurrency: 2
# Количество запросов
requests: 1000
containers:
# Настройки для контейнера с бенчмарком
# Контейнер определяется как namespace/pod-name:container-name
default/nginx:nginx:
concurrency: 2
requests: 10000
http:
path: /
method: POST
body:
{"foo":"bar"}
header:
Accept:
- text/html
Content-Type:
- application/json
services:
# Можно проводить бенчмарк на сервисах типа NodePort и LoadBalancer
# Синтаксис: namespace/service-name
default/nginx:
concurrency: 5
requests: 500
http:
method: GET
path: /auth
auth:
user: flant
password: s3cr3tp455w0rd
Интерфейс
Вид столбцов для списков ресурсов модифицируется созданием файла $HOME/.k9s/views.yml. Пример его содержимого:
k9s:
views:
v1/pods:
columns:
- AGE
- NAMESPACE
- NAME
- IP
- NODE
- STATUS
- READY
v1/services:
columns:
- AGE
- NAMESPACE
- NAME
- TYPE
- CLUSTER-IP
Правда, не хватает колонки по лейблам, на что есть issue в проекте.
Сортировка по столбцам осуществляется клавиатурными сочетаниями:
Shift + n — по имени;
Shift + o — по узлам;
Shift + i — по IP;
Shift + a — по времени жизни контейнера;
Shift + t — по количеству рестартов;
Shift + r — по статусу готовности;
Shift + c — по потреблению CPU;
Shift + m — по потреблению памяти.
Если же кому-то не нравится цветовое оформление по умолчанию, в K9s даже поддерживаются скины. Готовые примеры (7 штук) доступны здесь. Вот пример одного из таких скинов (in the navy):
Плагины
Наконец, плагины позволяют расширять возможности K9s. Сам я в работе использовал только один из них — kubectl get all -n $namespace.
Выглядит это следующим образом. Создаем файл $HOME/.k9s/plugin.yml с таким содержимым:
plugin:
get-all:
shortCut: g
confirm: false
description: get all
scopes:
- all
command: sh
background: false
args:
- -c
- "kubectl -n $NAMESPACE get all -o wide | less"
Теперь можно перейти в пространство имён и нажать на «g» для выполнения с соответствующей команды:
Среди плагинов есть, например, интеграции с kubectl-jq и утилитой для просмотра логов stern.
Заключение
На мой вкус, K9s оказалась очень удобна в работе: с ней довольно быстро привыкнуть искать всё нужное без использования kubectl. Порадовал просмотр логов и их сохранение, быстрое редактирование ресурсов, скорость работы в целом*, оказался полезным режим Popeye. Отдельного упоминания стоят возможности создавать плагины и дорабатывать приложение под свои нужды.
* Хотя при большом объеме логов замечал также медленную работу K9s. В такие моменты утилита «съедала» 2 ядра у Intel Xeon E312xx и могла даже зависать.
Чего не хватает в настоящий момент? Быстрого отката на предыдущую версию (речь не про RS) без перехода в директорию. К тому же, восстановление происходит только для всего ресурса: если вы удалили аннотацию или лейбл, придется удалить и восстановить весь ресурс (здесь и понадобится переходить в директорию). Другая мелочь — не хватает даты таких сохраненных «бэкапов».