Современный мир IT-технологий невозможно представить без оркестрации приложений. Кubernetes – это платформа, которая позволяет автоматизировать процессы работы с приложениями и значительно упростить развертывание и масштабирование их работы. Если вы хотите заниматься разработкой приложений и быть в курсе всех новинок в области автоматизации, то вам однозначно стоит обратить внимание на книги по Kubernetes.
Мы составили для вас список лучших книг на русском языке, которые помогут разобраться во всех тонкостях работы с Kubernetes и увеличат ваши знания в этой области.
В этом списке вы встретите книги разного уровня сложности – от начального до продвинутого. Они помогут как новичкам в области автоматизации, так и профессионалам, которые уже занимаются разработкой приложений на Kubernetes.
Выбирайте книги, которые вам ближе по духу и начинайте погружаться в увлекательный мир оркестрации приложений! Читать →
Я продолжаю разбираться в тонкостях платформы Kubernetes. Параллельно делаю какие-то конспекты вида этой публикации. Сегодня по плану — разобраться, как происходит обновление кластера Kubernetes.
Kubernetes (K8s) — это популярная и мощная система управления контейнерами, разработанная компанией Google. Она предоставляет средства для автоматизации развертывания, масштабирования и управления контейнеризированными приложениями. Kubernetes обеспечивает надежное и гибкое окружение для разработчиков и операционных специалистов, позволяя им сосредоточиться на разработке приложений, не беспокоясь о деталях инфраструктуры.
Одним из ключевых преимуществ Kubernetes является возможность создания собственного кластера при помощи https://cloud.obit.ru/, который можно настроить и настроить под конкретные потребности вашего проекта.
Кроме создания кластера cloud.obit.ru предоставляет услуги:
vStack cloud
VMware cloud
Хранилище 1С
Облако
Kubernetes
и другие услуги.
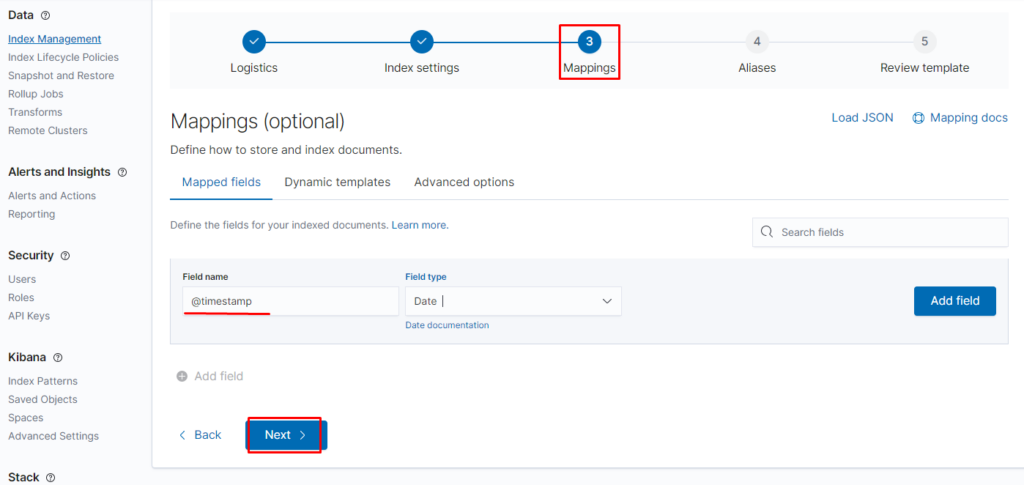
В этой статье мы рассмотрим процесс создания собственного кластера Kubernetes.
Шаг 1: Выбор платформы
Первым шагом в создании кластера kubernetes является выбор платформы, на которой он будет работать. Kubernetes может работать на различных облачных провайдерах, таких как Amazon Web Services (AWS), Google Cloud Platform (GCP) и Microsoft Azure. Вы также можете развернуть кластер Kubernetes на собственном оборудовании, используя физические серверы или виртуальные машины.
Шаг 2: Установка Kubernetes
После выбора платформы необходимо установить Kubernetes на выбранную инфраструктуру. В случае использования облачного провайдера это может включать в себя создание экземпляров виртуальных машин и настройку сетевых правил. Если вы развертываете Kubernetes на собственном оборудовании, вам понадобится установить и настроить необходимое программное обеспечение, включая контейнерный движок, такой как Docker.
Шаг 3: Конфигурация кластера
После установки Kubernetes необходимо настроить кластер, определив его параметры и поведение. Кластер Kubernetes состоит из нескольких узлов, включая мастер-узлы, ответственные за управление и координацию кластером, и рабочие узлы, на которых развертываются и запускаются контейнеры. Вам нужно будет указать количество и типы узлов, сетевые настройки и другие параметры, в зависимости от вашего проекта.
Шаг 4: Запуск и управление приложениями
После настройки кластера Kubernetes вы можете начать развертывать и управлять приложениями. Kubernetes предоставляет мощные механизмы для описания и управления приложениями в виде файлов конфигурации, называемых манифестами. Вы определяете требования к ресурсам, количество экземпляров, сетевые настройки и другие параметры приложения в манифесте, а затем Kubernetes берет на себя ответственность за развертывание и управление этими приложениями на узлах кластера.
Шаг 5: Масштабирование и обслуживание
Одним из основных преимуществ Kubernetes является его способность масштабировать приложения в зависимости от нагрузки. Вы можете настроить автомасштабирование, чтобы Kubernetes автоматически добавлял или удалял экземпляры приложения в зависимости от текущей нагрузки. Кроме того, Kubernetes обеспечивает возможность обновления приложений без прерывания обслуживания, позволяя развертывать новые версии приложений и переключаться на них без простоев.
Заключение
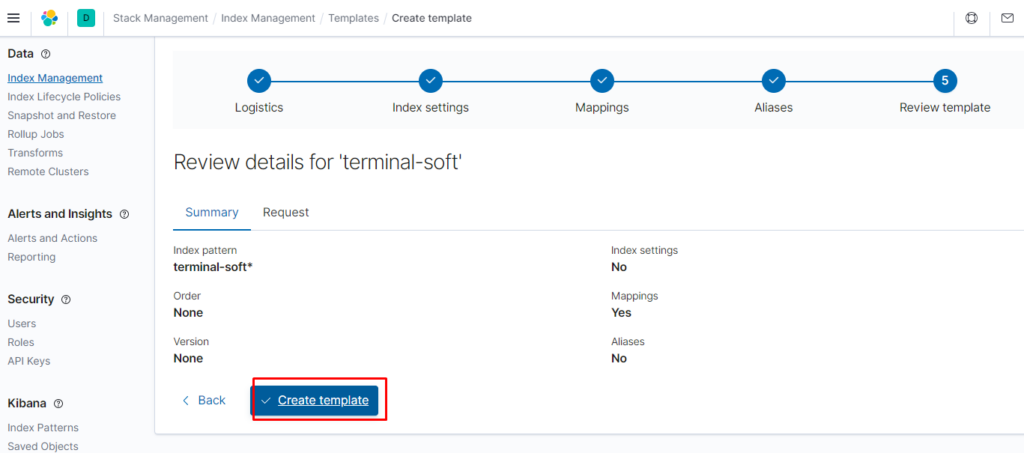
Создание собственного кластера Kubernetes может быть немного сложным процессом, но это предоставляет вам полный контроль над вашей инфраструктурой и приложениями. Kubernetes обладает богатым набором возможностей и инструментов, которые позволяют автоматизировать и упростить управление контейнеризированными приложениями в различных сценариях. Надеюсь, эта статья помогла вам получить общее представление о том, как создать свой собственный кластер Kubernetes и начать использовать его для развертывания и масштабирования ваших приложений.
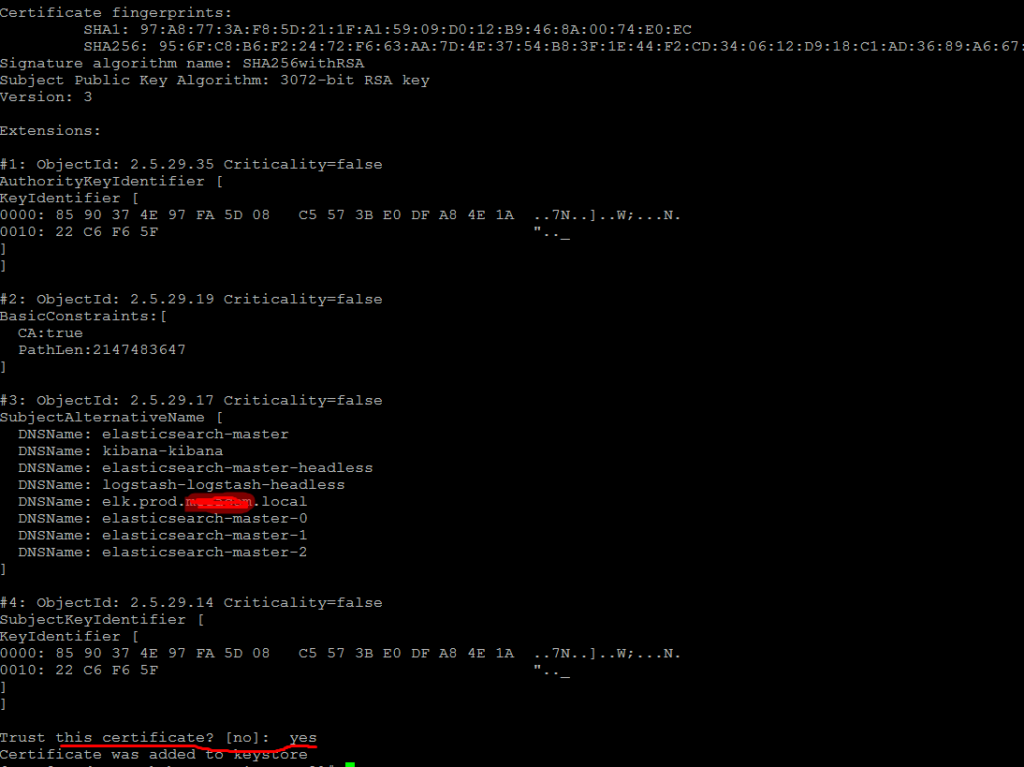
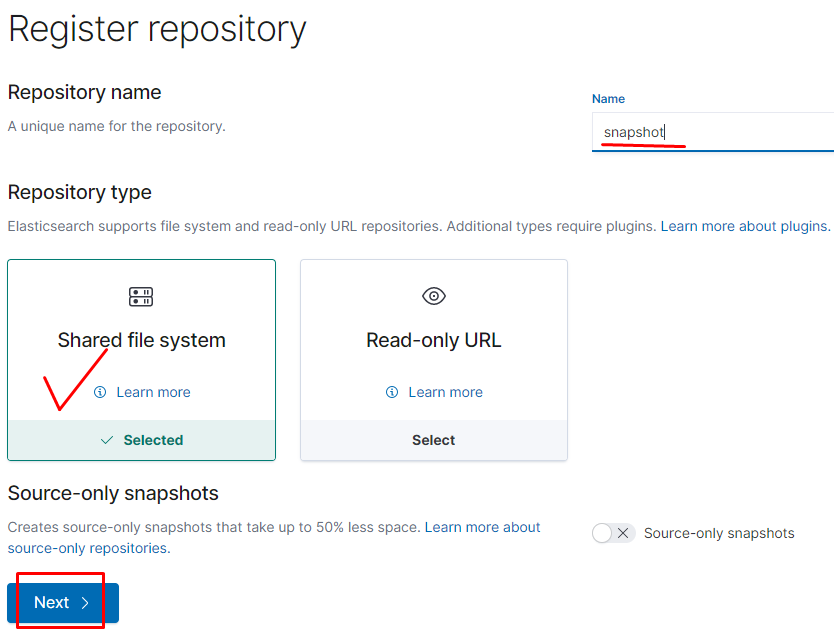
Тут надо будет ввести пароль при генерации а дальше заполнить данные сертификата. Я везде задал пароль 123456789 openssl req -new -x509 -key mysite.key -sha256 -config cnf -out mysite.crt -days 7300 Enter pass phrase for mysite.key:
создаём сертификат p12 который нужен elastic
openssl pkcs12 -export -in mysite.crt -inkey mysite.key -out identity.p12 -name «mykey» Enter pass phrase for mysite.key: вот тут вводим наш пароль 123456789 Enter Export Password: ТУТ ОСТАВЛЯЕМ БЕЗ ПАРОЛЯ Verifying — Enter Export Password: ТУТ ОСТАВЛЯЕМ БЕЗ ПАРОЛЯ
появится сообщение в котором мы соглашаемся, что доверяем сертификату
Вытаскиваем приватный ключ чтоб он у нас был без пароля openssl rsa -in mysite.key -out mysite-without-pass.key Enter pass phrase for mysite.key: writing RSA key
Всё готово, все нужные сертификаты для elasticsearch сгенерированы:
[root@prod-vsrv-kubemaster1 certs]# ll total 32 -rw-r—r— 1 root root 575 Feb 10 10:15 cnf -rw-r—r— 1 root root 3624 Feb 10 10:15 identity.p12 -rw-r—r— 1 root root 1935 Feb 10 10:15 mysite.crt -rw-r—r— 1 root root 2638 Feb 10 10:15 mysite.key -rw-r—r— 1 root root 2459 Feb 10 10:39 mysite-without-pass.key -rw-r—r— 1 root root 1682 Feb 10 10:15 trust.jks
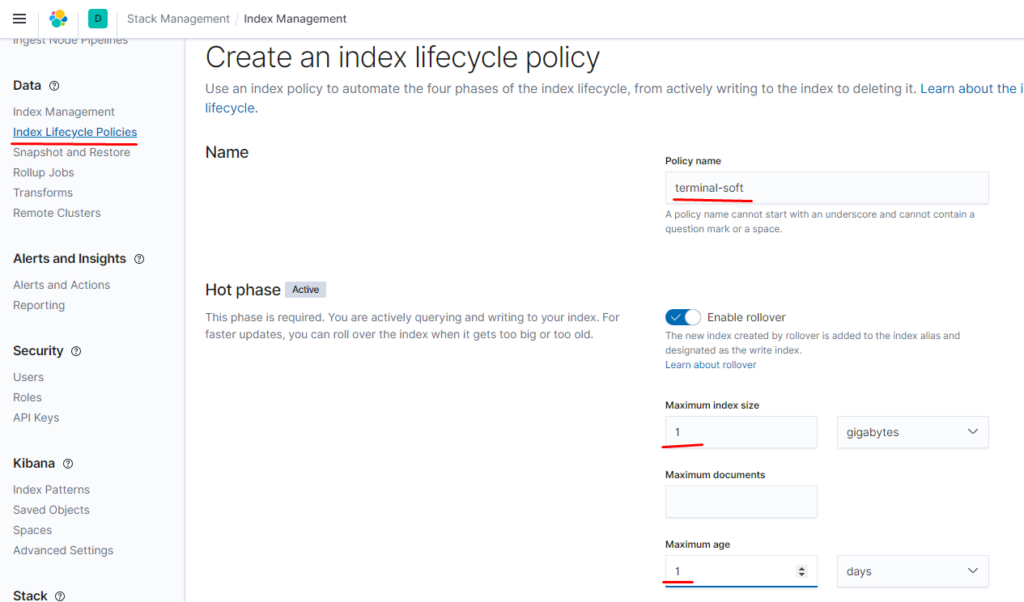
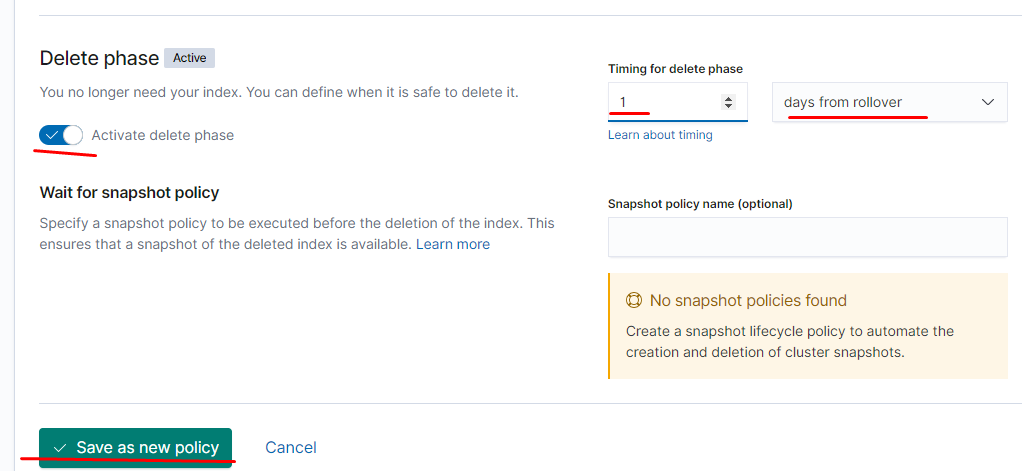
также выставляем antiAffinity soft (так как у нас 2 воркера а эластик запускается в 3х подах он не может стартануть) эта настройка говорит что на одной ноде могут быть запущены 2 пода из кластера уэластика.
---
clusterName: "elasticsearch"
nodeGroup: "master"
# The service that non master groups will try to connect to when joining the cluster
# This should be set to clusterName + "-" + nodeGroup for your master group
masterService: ""
# Elasticsearch roles that will be applied to this nodeGroup
# These will be set as environment variables. E.g. node.master=true
roles:
master: "true"
ingest: "true"
data: "true"
remote_cluster_client: "true"
# ml: "true" # ml is not availble with elasticsearch-oss
replicas: 3
minimumMasterNodes: 2
esMajorVersion: ""
# Allows you to add any config files in /usr/share/elasticsearch/config/
# such as elasticsearch.yml and log4j2.properties
esConfig:
elasticsearch.yml: |
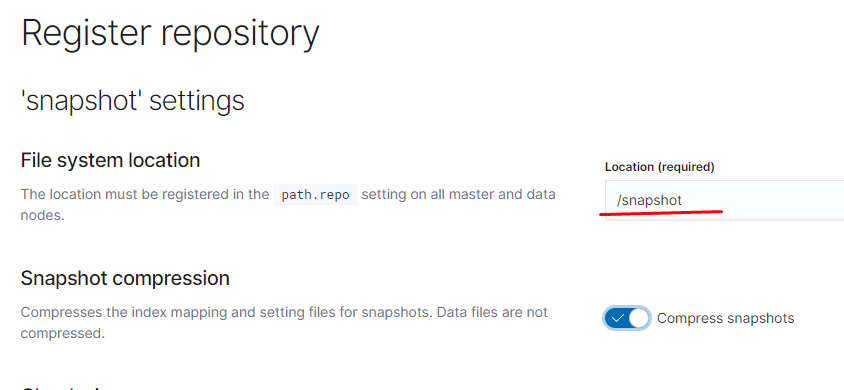
path.repo: /snapshot
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/identity.p12
xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/identity.p12
xpack.security.http.ssl.enabled: true
xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/identity.p12
xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/identity.p12
# key:
# nestedkey: value
# log4j2.properties: |
# key = value
# Extra environment variables to append to this nodeGroup
# This will be appended to the current 'env:' key. You can use any of the kubernetes env
# syntax here
extraEnvs:
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: secret-basic-auth
key: password
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: secret-basic-auth
key: username
# - name: MY_ENVIRONMENT_VAR
# value: the_value_goes_here
# Allows you to load environment variables from kubernetes secret or config map
envFrom: []
# - secretRef:
# name: env-secret
# - configMapRef:
# name: config-map
# A list of secrets and their paths to mount inside the pod
# This is useful for mounting certificates for security and for mounting
# the X-Pack license
secretMounts:
- name: elastic-certificates
secretName: elastic-certificates
path: /usr/share/elasticsearch/config/certs
# defaultMode: 0755
image: "docker.elastic.co/elasticsearch/elasticsearch"
imageTag: "7.9.4-SNAPSHOT"
imagePullPolicy: "IfNotPresent"
podAnnotations: {}
# iam.amazonaws.com/role: es-cluster
# additionals labels
labels: {}
esJavaOpts: "-Xmx1g -Xms1g"
resources:
requests:
cpu: "1000m"
memory: "2Gi"
limits:
cpu: "1000m"
memory: "2Gi"
initResources: {}
# limits:
# cpu: "25m"
# # memory: "128Mi"
# requests:
# cpu: "25m"
# memory: "128Mi"
sidecarResources: {}
# limits:
# cpu: "25m"
# # memory: "128Mi"
# requests:
# cpu: "25m"
# memory: "128Mi"
networkHost: "0.0.0.0"
volumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
storageClassName: nfs-storageclass
resources:
requests:
storage: 3Gi
rbac:
create: false
serviceAccountAnnotations: {}
serviceAccountName: ""
podSecurityPolicy:
create: false
name: ""
spec:
privileged: true
fsGroup:
rule: RunAsAny
runAsUser:
rule: RunAsAny
seLinux:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
volumes:
- secret
- configMap
- persistentVolumeClaim
persistence:
enabled: true
labels:
# Add default labels for the volumeClaimTemplate fo the StatefulSet
enabled: false
annotations: {}
extraVolumes: []
# - name: extras
# emptyDir: {}
extraVolumeMounts: []
# - name: extras
# mountPath: /usr/share/extras
# readOnly: true
extraContainers: []
# - name: do-something
# image: busybox
# command: ['do', 'something']
extraInitContainers: []
# - name: do-something
# image: busybox
# command: ['do', 'something']
# This is the PriorityClass settings as defined in
# https://kubernetes.io/docs/concepts/configuration/pod-priority-preemption/#priorityclass
priorityClassName: ""
# By default this will make sure two pods don't end up on the same node
# Changing this to a region would allow you to spread pods across regions
antiAffinityTopologyKey: "kubernetes.io/hostname"
# Hard means that by default pods will only be scheduled if there are enough nodes for them
# and that they will never end up on the same node. Setting this to soft will do this "best effort"
antiAffinity: "soft"
# This is the node affinity settings as defined in
# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#node-affinity-beta-feature
nodeAffinity: {}
# The default is to deploy all pods serially. By setting this to parallel all pods are started at
# the same time when bootstrapping the cluster
podManagementPolicy: "Parallel"
# The environment variables injected by service links are not used, but can lead to slow Elasticsearch boot times when
# there are many services in the current namespace.
# If you experience slow pod startups you probably want to set this to `false`.
enableServiceLinks: true
protocol: https
httpPort: 9200
transportPort: 9300
service:
labels: {}
labelsHeadless: {}
type: ClusterIP
nodePort: ""
annotations: {}
httpPortName: http
transportPortName: transport
loadBalancerIP: ""
loadBalancerSourceRanges: []
externalTrafficPolicy: ""
updateStrategy: RollingUpdate
# This is the max unavailable setting for the pod disruption budget
# The default value of 1 will make sure that kubernetes won't allow more than 1
# of your pods to be unavailable during maintenance
maxUnavailable: 1
podSecurityContext:
fsGroup: 1000
runAsUser: 1000
securityContext:
capabilities:
drop:
- ALL
# readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
# How long to wait for elasticsearch to stop gracefully
terminationGracePeriod: 120
sysctlVmMaxMapCount: 262144
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 3
timeoutSeconds: 5
# https://www.elastic.co/guide/en/elasticsearch/reference/7.9/cluster-health.html#request-params wait_for_status
clusterHealthCheckParams: "wait_for_status=green&timeout=1s"
## Use an alternate scheduler.
## ref: https://kubernetes.io/docs/tasks/administer-cluster/configure-multiple-schedulers/
##
schedulerName: ""
imagePullSecrets: []
nodeSelector: {}
tolerations: []
# Enabling this will publically expose your Elasticsearch instance.
# Only enable this if you have security enabled on your cluster
ingress:
enabled: false
annotations: {}
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: "true"
path: /
hosts:
- chart-example.local
tls: []
# - secretName: chart-example-tls
# hosts:
# - chart-example.local
nameOverride: ""
fullnameOverride: ""
# https://github.com/elastic/helm-charts/issues/63
masterTerminationFix: false
lifecycle: {}
# preStop:
# exec:
# command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
# postStart:
# exec:
# command:
# - bash
# - -c
# - |
# #!/bin/bash
# # Add a template to adjust number of shards/replicas
# TEMPLATE_NAME=my_template
# INDEX_PATTERN="logstash-*"
# SHARD_COUNT=8
# REPLICA_COUNT=1
# ES_URL=http://localhost:9200
# while [[ "$(curl -s -o /dev/null -w '%{http_code}n' $ES_URL)" != "200" ]]; do sleep 1; done
# curl -XPUT "$ES_URL/_template/$TEMPLATE_NAME" -H 'Content-Type: application/json' -d'{"index_patterns":['""$INDEX_PATTERN""'],"settings":{"number_of_shards":'$SHARD_COUNT',"number_of_replicas":'$REPLICA_COUNT'}}'
sysctlInitContainer:
enabled: true
keystore: []
# Deprecated
# please use the above podSecurityContext.fsGroup instead
fsGroup: ""
также настраиваем ingress чтобы по нашему домену открывалась кибана, отметим что строка: nginx.ingress.kubernetes.io/backend-protocol: «HTTPS» обязательна так как без неё ингрес по умолчанию проксирует всё на HTTP
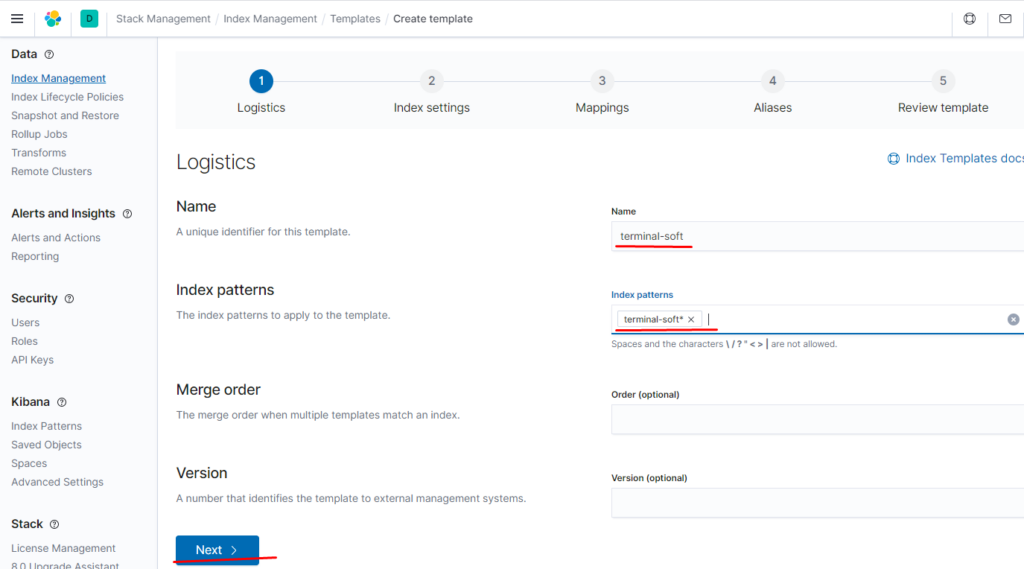
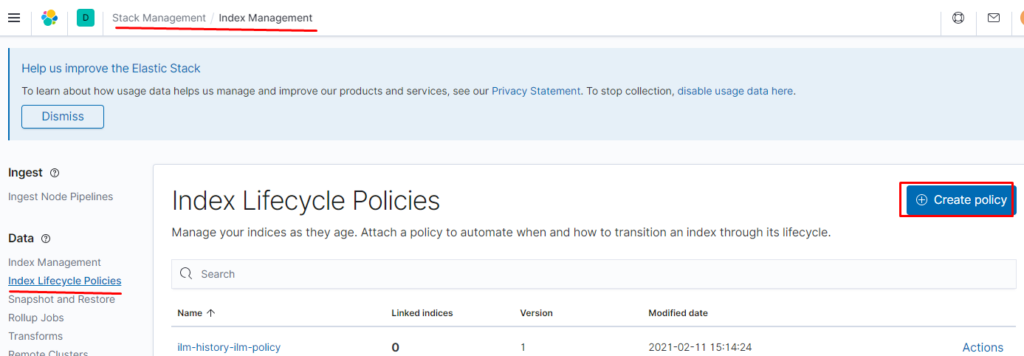
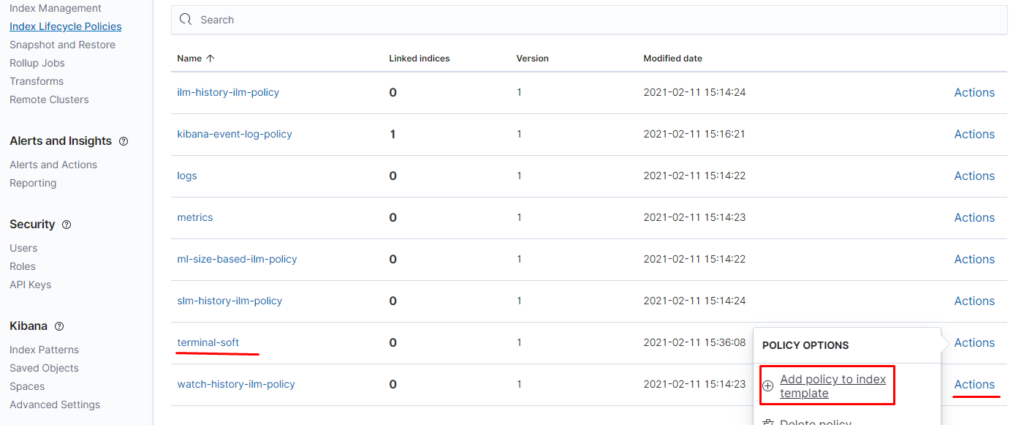
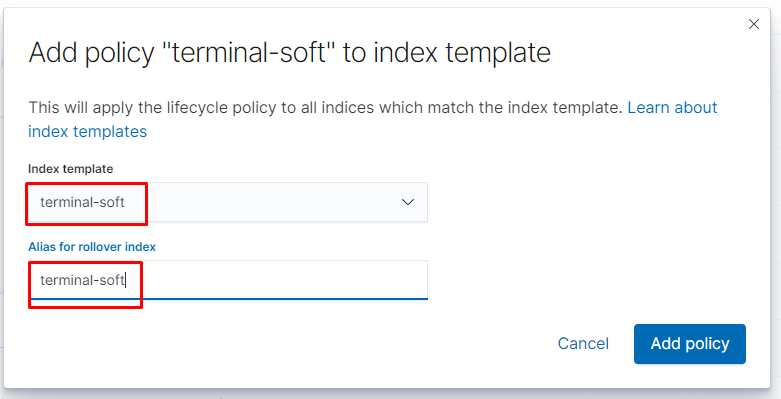
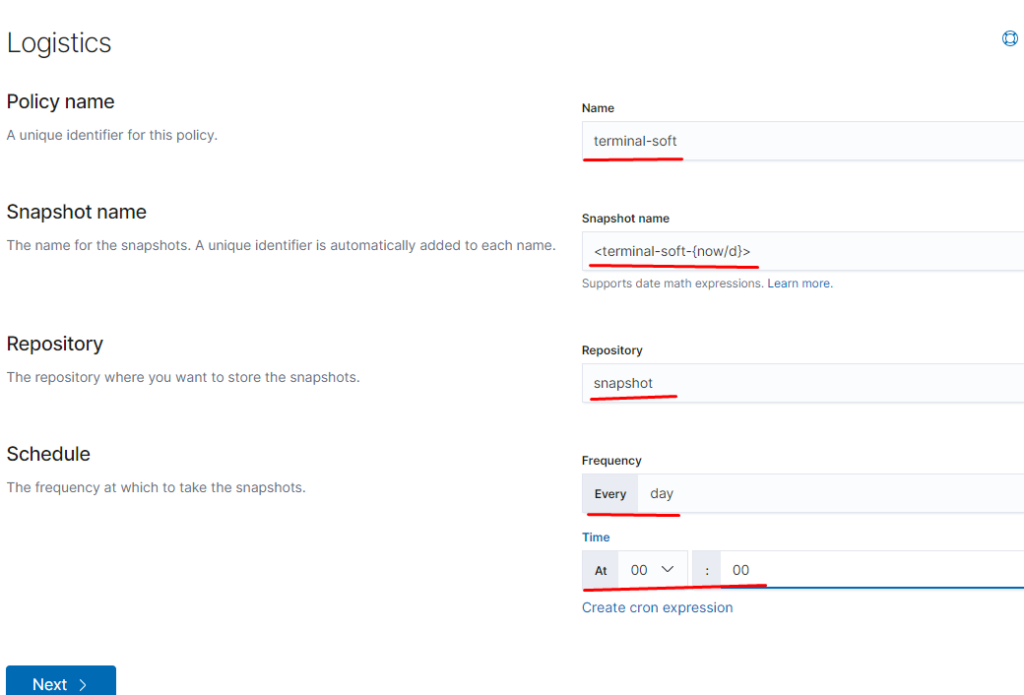
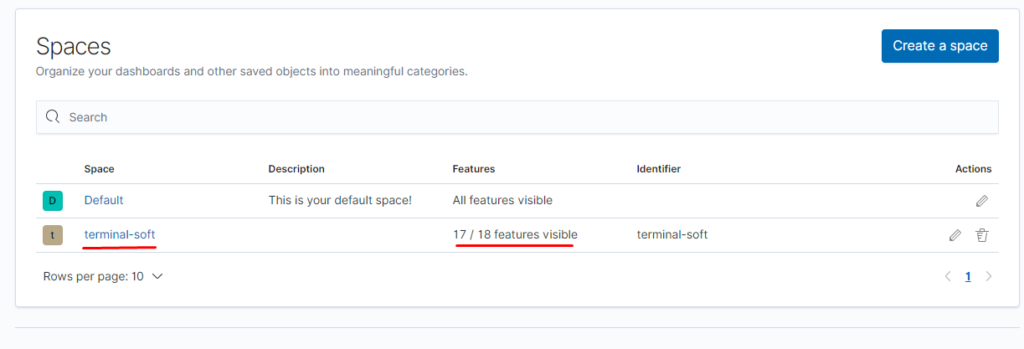
также настраиваем приём на порт 5045 так как 5044 поднимается автоматически и если оставить input с 5044 то будет конфликт портов, настраиваем также фильтр по неймспейсу если приходят логи из неймспейса terminal-soft мы к ним добавляем тэг, убираем пару лишних полей и отправляем в ластик, указывая имя индекса имя ilm политики -которая должна быть предварительно создана.
---
replicas: 1
# Allows you to add any config files in /usr/share/logstash/config/
# such as logstash.yml and log4j2.properties
#
# Note that when overriding logstash.yml, `http.host: 0.0.0.0` should always be included
# to make default probes work.
logstashConfig:
logstash.yml: |
http.host: 0.0.0.0
xpack.monitoring.enabled: true
xpack.monitoring.elasticsearch.username: '${ELASTICSEARCH_USERNAME}'
xpack.monitoring.elasticsearch.password: '${ELASTICSEARCH_PASSWORD}'
xpack.monitoring.elasticsearch.hosts: [ "https://elasticsearch-master:9200" ]
xpack.monitoring.elasticsearch.ssl.certificate_authority: /usr/share/logstash/config/certs/mysite.crt
# key:
# nestedkey: value
# log4j2.properties: |
# key = value
# Allows you to add any pipeline files in /usr/share/logstash/pipeline/
### ***warn*** there is a hardcoded logstash.conf in the image, override it first
logstashPipeline:
logstash.conf: |
input {
exec { command => "uptime" interval => 30 }
beats {
port => 5045
}
}
filter {
if [kubernetes][namespace] == "terminal-soft" {
mutate {
add_tag => "tag-terminal-soft"
remove_field => ["[agent][name]","[agent][version]","[host][mac]","[host][ip]"] }
}
}
output {
if "tag-terminal-soft" in [tags] {
elasticsearch {
hosts => [ "https://elasticsearch-master:9200" ]
cacert => "/usr/share/logstash/config/certs/mysite.crt"
manage_template => false
index => "terminal-soft-%{+YYYY.MM.dd}"
ilm_rollover_alias => "terminal-soft"
ilm_policy => "terminal-soft"
user => '${ELASTICSEARCH_USERNAME}'
password => '${ELASTICSEARCH_PASSWORD}'
}
}
}
# input {
# exec {
# command => "uptime"
# interval => 30
# }
# }
# output { stdout { } }
# Extra environment variables to append to this nodeGroup
# This will be appended to the current 'env:' key. You can use any of the kubernetes env
# syntax here
extraEnvs:
- name: 'ELASTICSEARCH_USERNAME'
valueFrom:
secretKeyRef:
name: secret-basic-auth
key: username
- name: 'ELASTICSEARCH_PASSWORD'
valueFrom:
secretKeyRef:
name: secret-basic-auth
key: password
# - name: MY_ENVIRONMENT_VAR
# value: the_value_goes_here
# Allows you to load environment variables from kubernetes secret or config map
envFrom: []
# - secretRef:
# name: env-secret
# - configMapRef:
# name: config-map
# Add sensitive data to k8s secrets
secrets: []
# - name: "env"
# value:
# ELASTICSEARCH_PASSWORD: "LS1CRUdJTiBgUFJJVkFURSB"
# api_key: ui2CsdUadTiBasRJRkl9tvNnw
# - name: "tls"
# value:
# ca.crt: |
# LS0tLS1CRUdJT0K
# LS0tLS1CRUdJT0K
# LS0tLS1CRUdJT0K
# LS0tLS1CRUdJT0K
# cert.crt: "LS0tLS1CRUdJTiBlRJRklDQVRFLS0tLS0K"
# cert.key.filepath: "secrets.crt" # The path to file should be relative to the `values.yaml` file.
# A list of secrets and their paths to mount inside the pod
secretMounts:
- name: elastic-certificates
secretName: elastic-certificates
path: /usr/share/logstash/config/certs
image: "docker.elastic.co/logstash/logstash"
imageTag: "7.9.4-SNAPSHOT"
imagePullPolicy: "IfNotPresent"
imagePullSecrets: []
podAnnotations: {}
# additionals labels
labels: {}
logstashJavaOpts: "-Xmx1g -Xms1g"
resources:
requests:
cpu: "100m"
memory: "1536Mi"
limits:
cpu: "1000m"
memory: "1536Mi"
volumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
rbac:
create: false
serviceAccountAnnotations: {}
serviceAccountName: ""
podSecurityPolicy:
create: false
name: ""
spec:
privileged: true
fsGroup:
rule: RunAsAny
runAsUser:
rule: RunAsAny
seLinux:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
volumes:
- secret
- configMap
- persistentVolumeClaim
persistence:
enabled: false
annotations: {}
extraVolumes: ""
# - name: extras
# emptyDir: {}
extraVolumeMounts: ""
# - name: extras
# mountPath: /usr/share/extras
# readOnly: true
extraContainers: ""
# - name: do-something
# image: busybox
# command: ['do', 'something']
extraInitContainers: ""
# - name: do-something
# image: busybox
# command: ['do', 'something']
# This is the PriorityClass settings as defined in
# https://kubernetes.io/docs/concepts/configuration/pod-priority-preemption/#priorityclass
priorityClassName: ""
# By default this will make sure two pods don't end up on the same node
# Changing this to a region would allow you to spread pods across regions
antiAffinityTopologyKey: "kubernetes.io/hostname"
# Hard means that by default pods will only be scheduled if there are enough nodes for them
# and that they will never end up on the same node. Setting this to soft will do this "best effort"
antiAffinity: "soft"
# This is the node affinity settings as defined in
# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#node-affinity-beta-feature
nodeAffinity: {}
# The default is to deploy all pods serially. By setting this to parallel all pods are started at
# the same time when bootstrapping the cluster
podManagementPolicy: "Parallel"
httpPort: 9600
# Custom ports to add to logstash
extraPorts: []
# - name: beats
# containerPort: 5044
updateStrategy: RollingUpdate
# This is the max unavailable setting for the pod disruption budget
# The default value of 1 will make sure that kubernetes won't allow more than 1
# of your pods to be unavailable during maintenance
maxUnavailable: 1
podSecurityContext:
fsGroup: 1000
runAsUser: 1000
securityContext:
capabilities:
drop:
- ALL
# readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
# How long to wait for logstash to stop gracefully
terminationGracePeriod: 120
# Probes
# Default probes are using `httpGet` which requires that `http.host: 0.0.0.0` is part of
# `logstash.yml`. If needed probes can be disabled or overrided using the following syntaxes:
#
# disable livenessProbe
# livenessProbe: null
#
# replace httpGet default readinessProbe by some exec probe
# readinessProbe:
# httpGet: null
# exec:
# command:
# - curl
# - localhost:9600
livenessProbe:
httpGet:
path: /
port: http
initialDelaySeconds: 300
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
successThreshold: 1
readinessProbe:
httpGet:
path: /
port: http
initialDelaySeconds: 60
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
successThreshold: 3
## Use an alternate scheduler.
## ref: https://kubernetes.io/docs/tasks/administer-cluster/configure-multiple-schedulers/
##
schedulerName: ""
nodeSelector: {}
tolerations: []
nameOverride: ""
fullnameOverride: ""
lifecycle: {}
# preStop:
# exec:
# command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
# postStart:
# exec:
# command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
service:
annotations: {}
type: ClusterIP
ports:
- name: beats
port: 5044
protocol: TCP
targetPort: 5045
# - name: http
# port: 8080
# protocol: TCP
# targetPort: 8080
ingress:
enabled: false
# annotations: {}
# hosts:
# - host: logstash.local
# paths:
# - path: /logs
# servicePort: 8080
# tls: []
---
# Allows you to add any config files in /usr/share/filebeat
# such as filebeat.yml
filebeatConfig:
filebeat.yml: |
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*.log
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
output.logstash:
enabled: true
hosts: ["logstash-logstash:5044"]
# Extra environment variables to append to the DaemonSet pod spec.
# This will be appended to the current 'env:' key. You can use any of the kubernetes env
# syntax here
extraEnvs: []
# - name: MY_ENVIRONMENT_VAR
# value: the_value_goes_here
extraVolumeMounts: []
# - name: extras
# mountPath: /usr/share/extras
# readOnly: true
extraVolumes: []
# - name: extras
# emptyDir: {}
extraContainers: ""
# - name: dummy-init
# image: busybox
# command: ['echo', 'hey']
extraInitContainers: []
# - name: dummy-init
# image: busybox
# command: ['echo', 'hey']
envFrom: []
# - configMapRef:
# name: configmap-name
# Root directory where Filebeat will write data to in order to persist registry data across pod restarts (file position and other metadata).
hostPathRoot: /var/lib
hostNetworking: false
dnsConfig: {}
# options:
# - name: ndots
# value: "2"
image: "docker.elastic.co/beats/filebeat"
imageTag: "7.9.4-SNAPSHOT"
imagePullPolicy: "IfNotPresent"
imagePullSecrets: []
livenessProbe:
exec:
command:
- sh
- -c
- |
#!/usr/bin/env bash -e
curl --fail 127.0.0.1:5066
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
exec:
command:
- sh
- -c
- |
#!/usr/bin/env bash -e
filebeat test output
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 5
# Whether this chart should self-manage its service account, role, and associated role binding.
managedServiceAccount: true
# additionals labels
labels: {}
podAnnotations: {}
# iam.amazonaws.com/role: es-cluster
# Various pod security context settings. Bear in mind that many of these have an impact on Filebeat functioning properly.
#
# - User that the container will execute as. Typically necessary to run as root (0) in order to properly collect host container logs.
# - Whether to execute the Filebeat containers as privileged containers. Typically not necessarily unless running within environments such as OpenShift.
podSecurityContext:
runAsUser: 0
privileged: false
resources:
requests:
cpu: "100m"
memory: "100Mi"
limits:
cpu: "1000m"
memory: "200Mi"
# Custom service account override that the pod will use
serviceAccount: ""
# Annotations to add to the ServiceAccount that is created if the serviceAccount value isn't set.
serviceAccountAnnotations: {}
# eks.amazonaws.com/role-arn: arn:aws:iam::111111111111:role/k8s.clustername.namespace.serviceaccount
# A list of secrets and their paths to mount inside the pod
# This is useful for mounting certificates for security other sensitive values
secretMounts: []
# - name: filebeat-certificates
# secretName: filebeat-certificates
# path: /usr/share/filebeat/certs
# How long to wait for Filebeat pods to stop gracefully
terminationGracePeriod: 30
tolerations: []
nodeSelector: {}
affinity: {}
# This is the PriorityClass settings as defined in
# https://kubernetes.io/docs/concepts/configuration/pod-priority-preemption/#priorityclass
priorityClassName: ""
updateStrategy: RollingUpdate
# Override various naming aspects of this chart
# Only edit these if you know what you're doing
nameOverride: ""
fullnameOverride: ""
Появилась задача: логи с контейнера в котором джава приложение приходят построчно, т.е. каждая строка это отдельный месседж при отображении в kibana, это не удобно читать, чтоб их объеденить в одно сообщение, добавим в filebeat фильтр
multiline.pattern: ‘^([0-9]{4}-[0-9]{2}-[0-9]{2})’ multiline.negate: true multiline.match: after
в общем виде:
vim filebeat/values.yaml
---
# Allows you to add any config files in /usr/share/filebeat
# such as filebeat.yml
filebeatConfig:
filebeat.yml: |
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*.log
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
multiline.pattern: '^([0-9]{4}-[0-9]{2}-[0-9]{2})'
multiline.negate: true
multiline.match: after
output.logstash:
enabled: true
hosts: ["logstash-logstash:5044"]
и обновляем наш чарт: helm upgrade —install filebeat -n elk —values filebeat/values.yaml filebeat/
всё теперь логи будут формироваться относительно даты в самом начале сообщения.
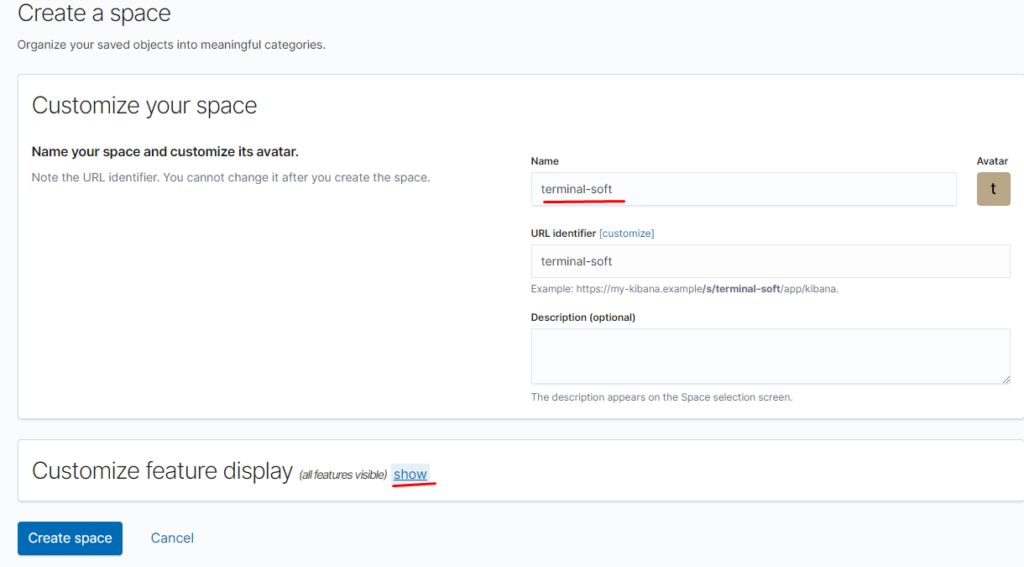
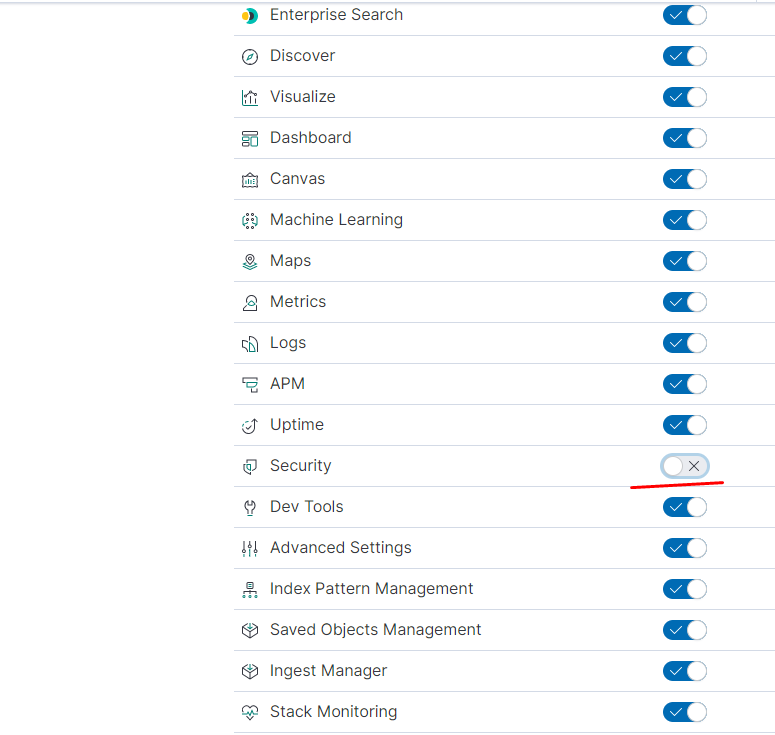
указываем — что должно отображаться в пространстве:
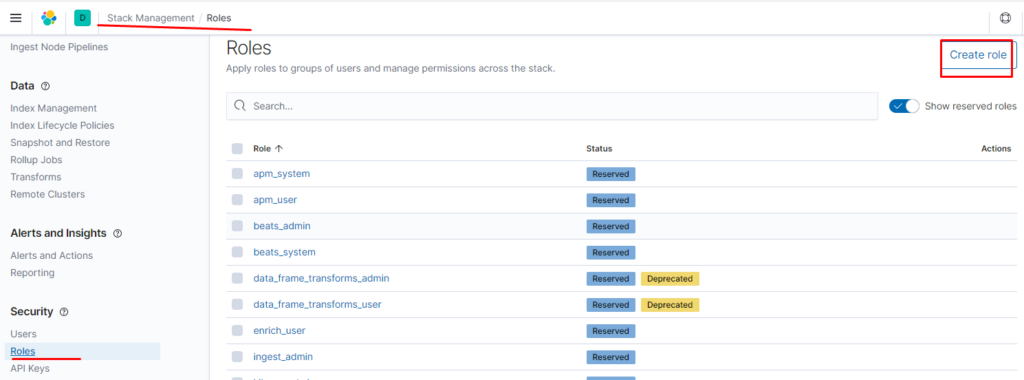
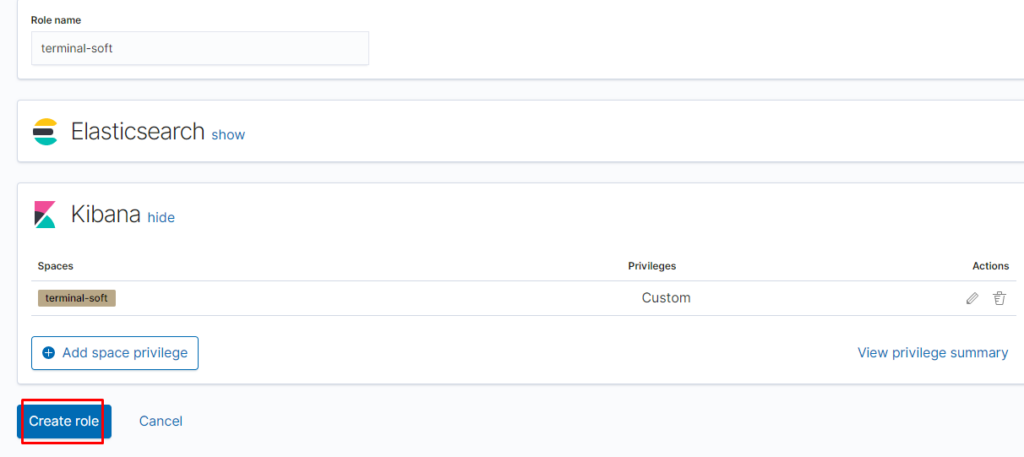
Создаём роль для нашего индекса:
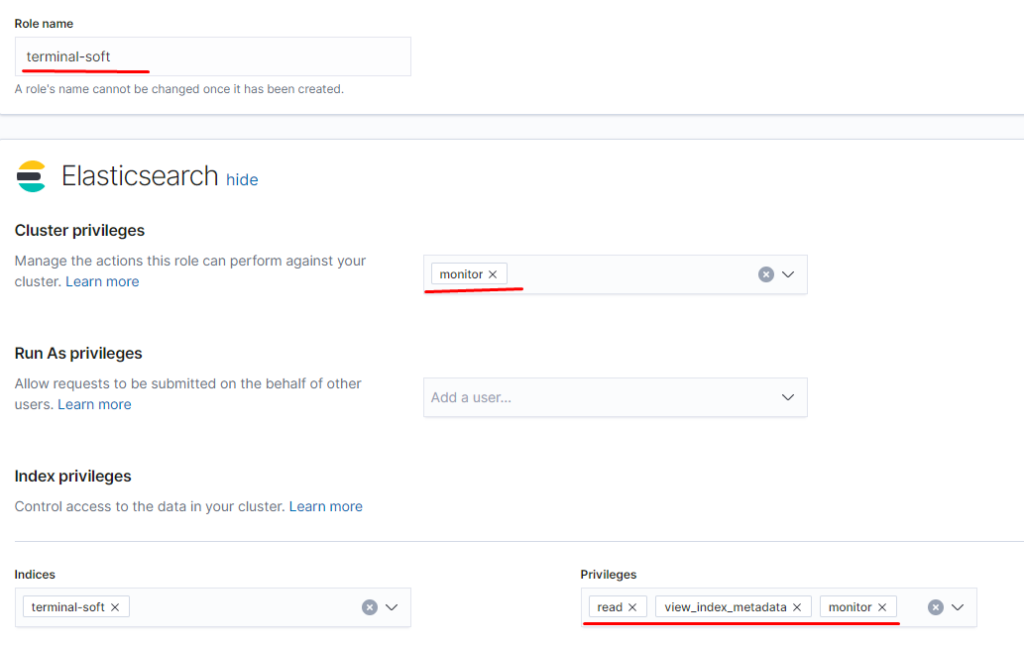
указываем привилегии как для кластера так и непосредственно для индекса terminal-soft
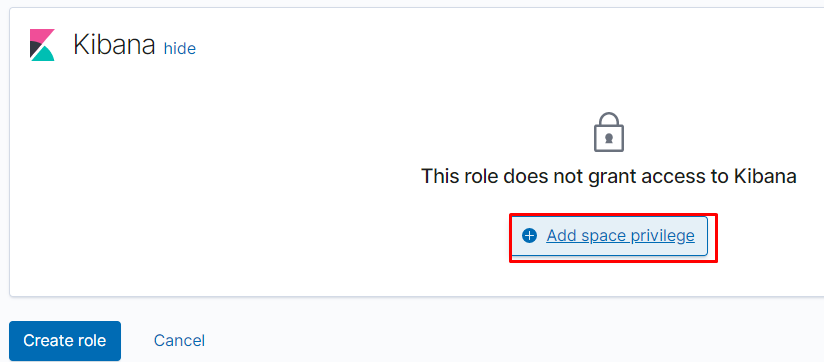
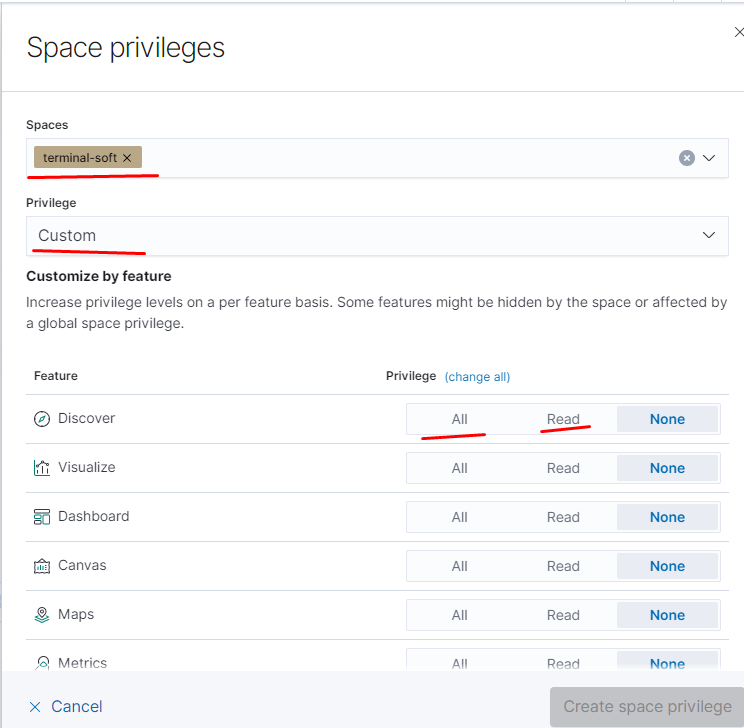
добавляем привилегии для пространства:
настраиваем доступы для пространства, — чтение/полный доступ/отключить
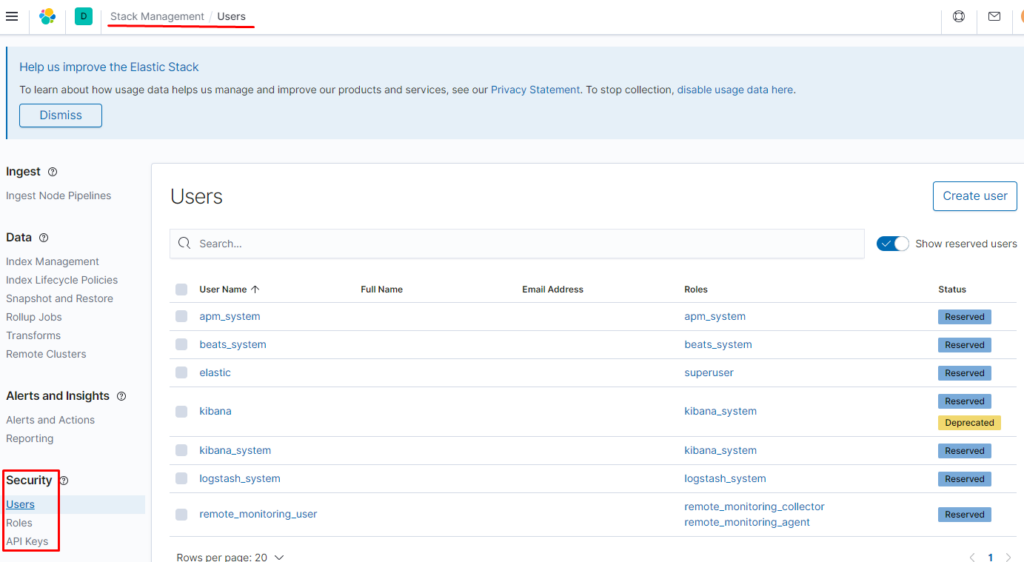
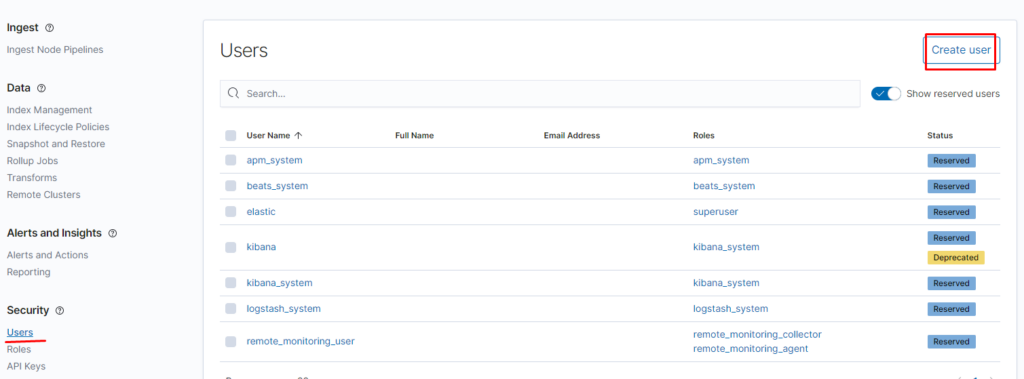
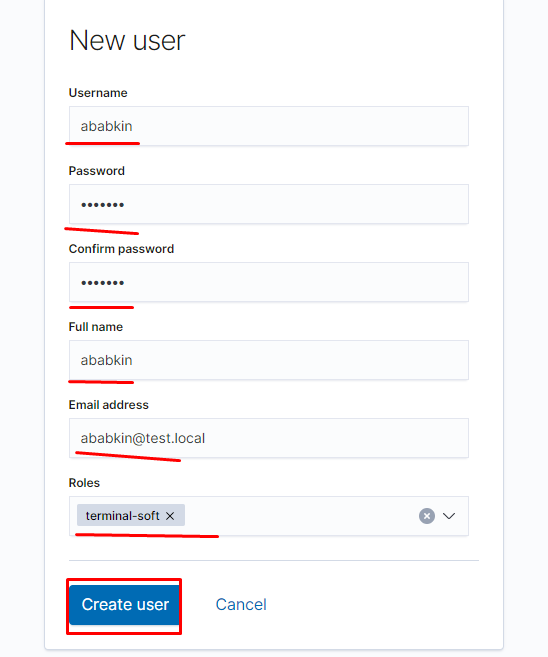
Создаём пользователя:
задаём пароль и созданную нами ранее роль:
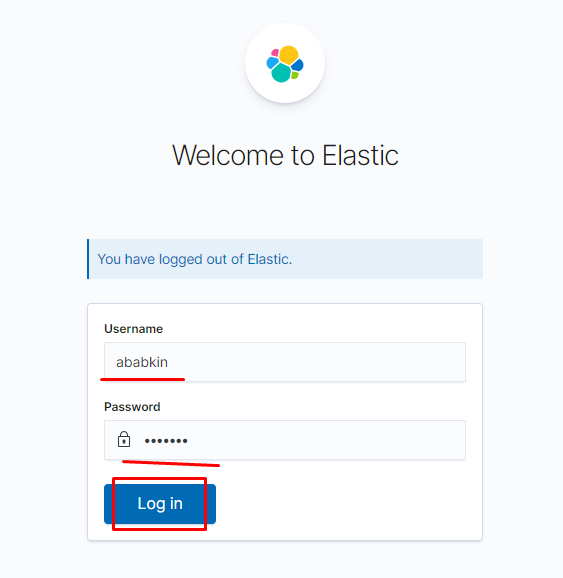
Логинимся под нашим новым пользователем
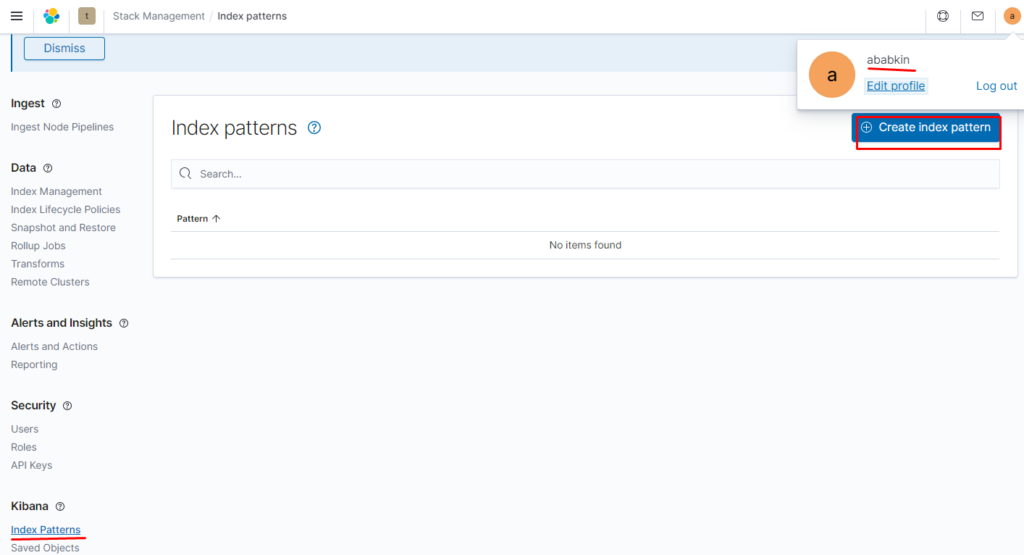
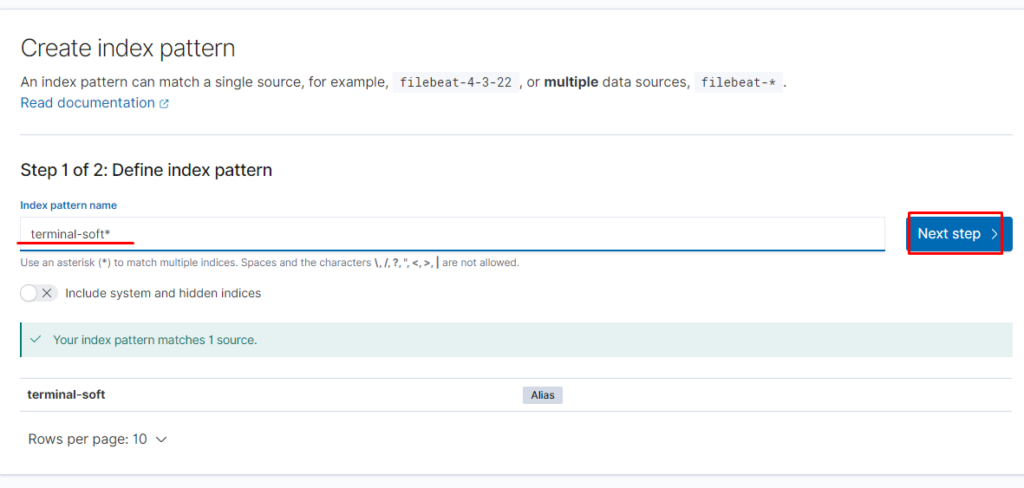
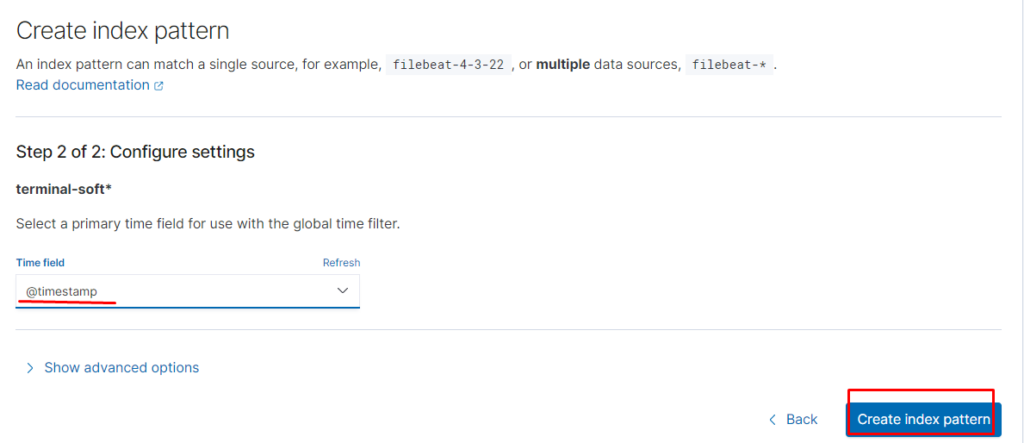
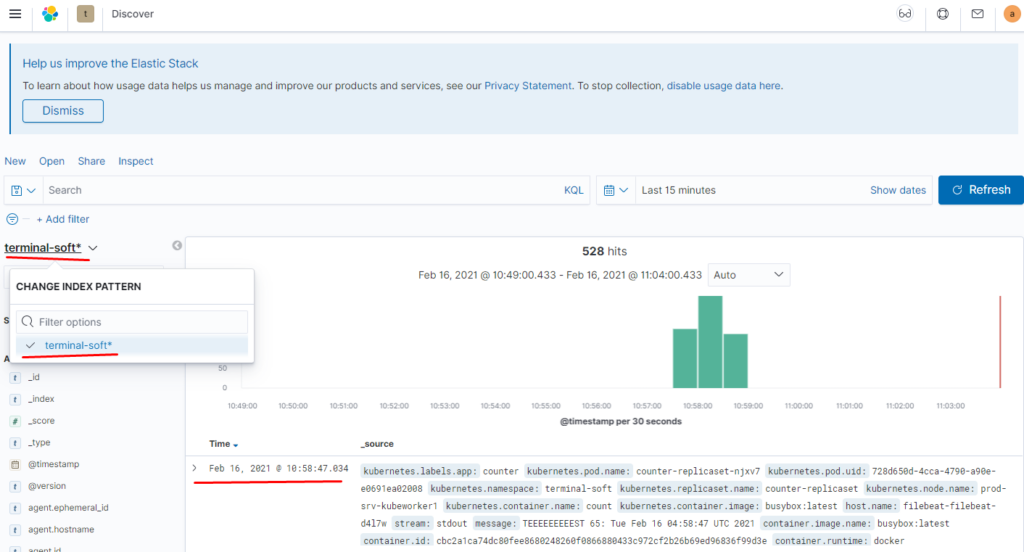
Создаём index pattern
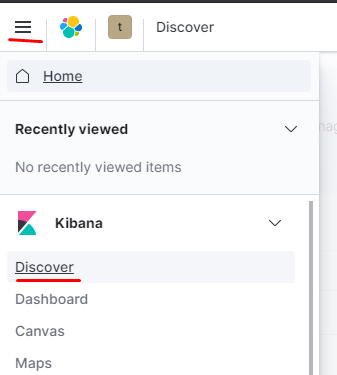
Проверяем:
как видим данные отображаются:
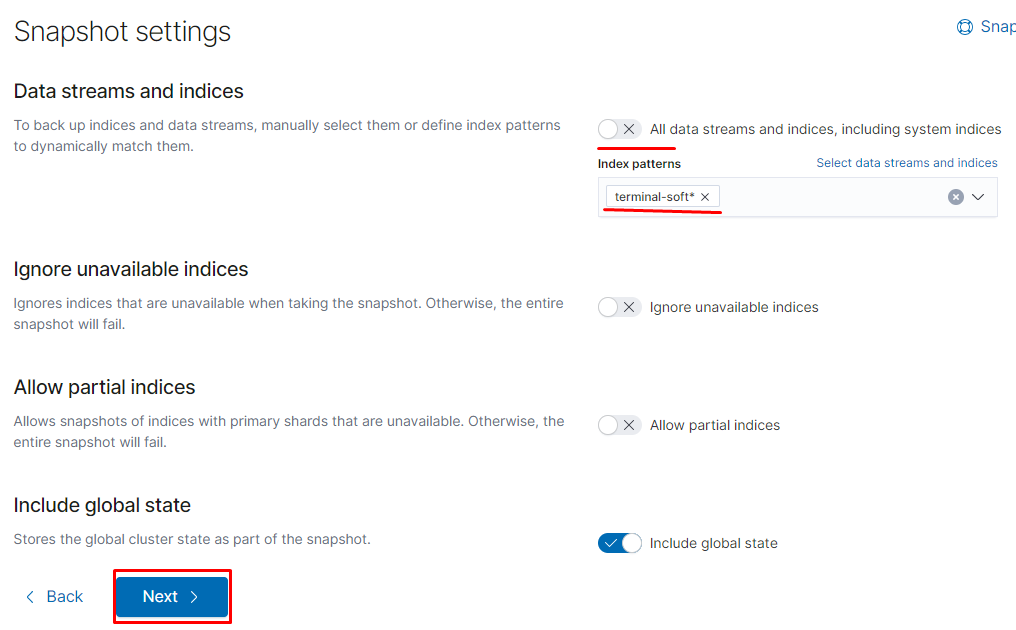
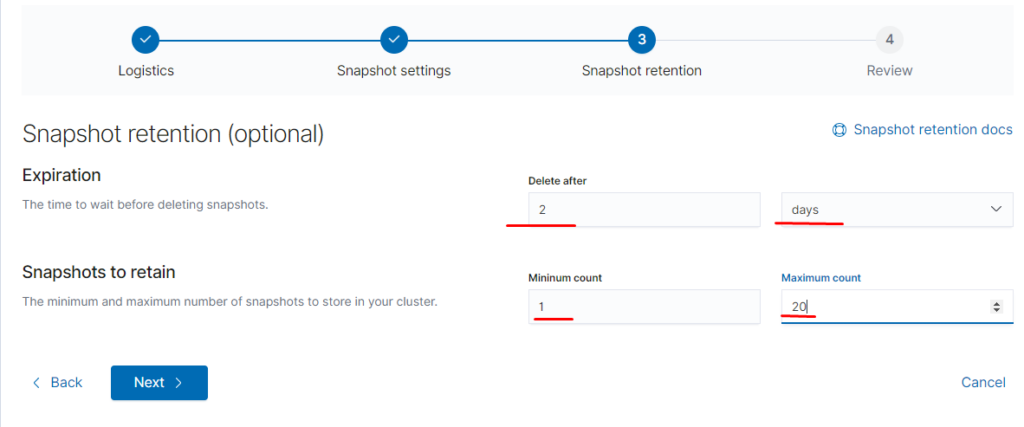
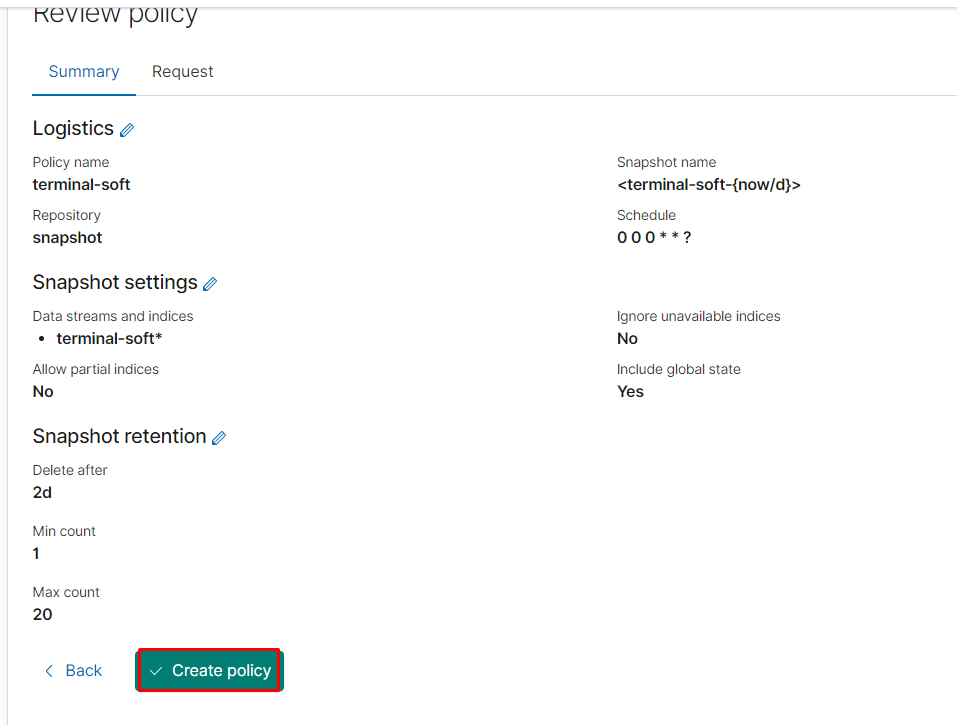
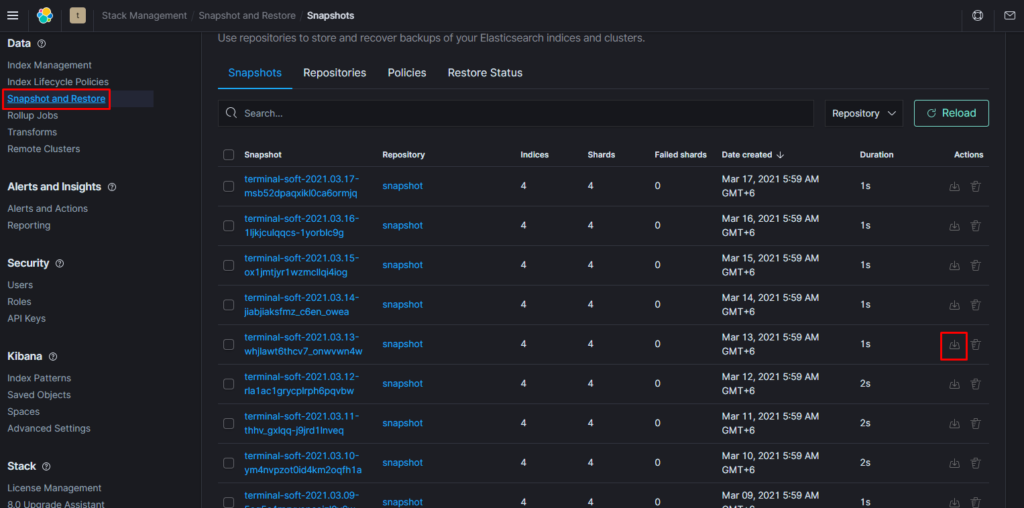
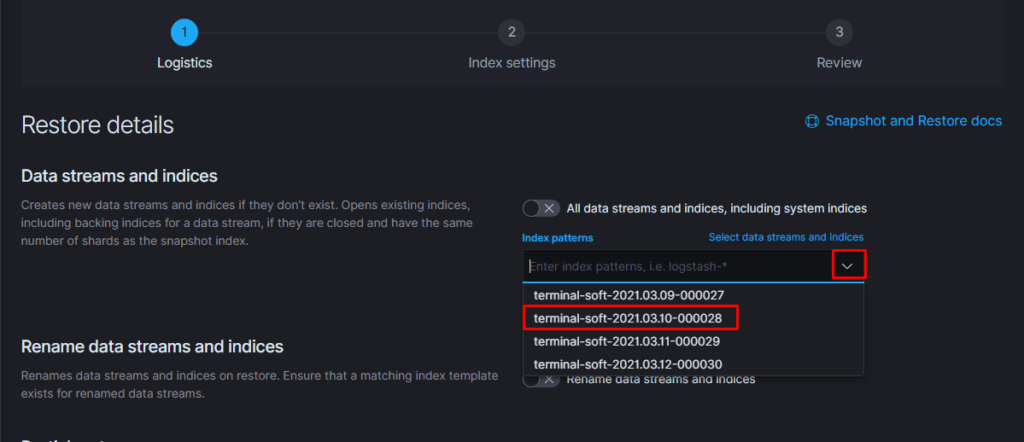
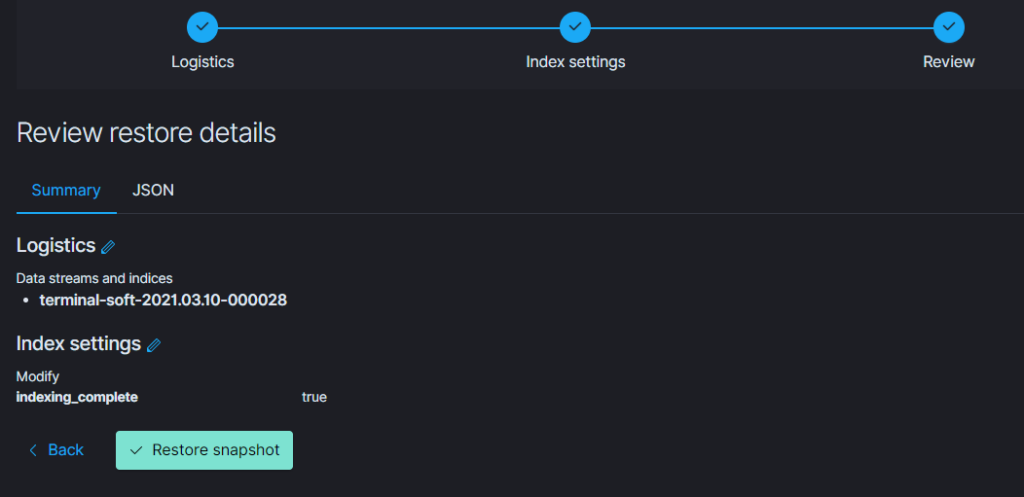
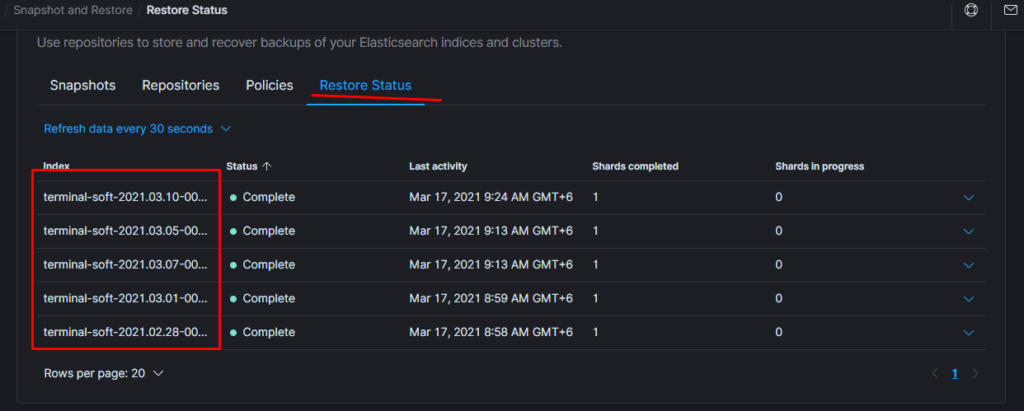
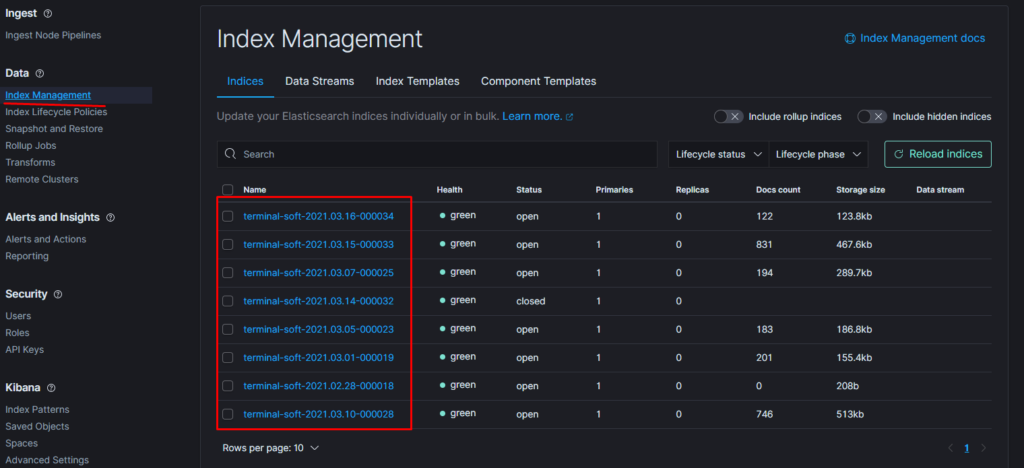
11.Восстановление из snapshot
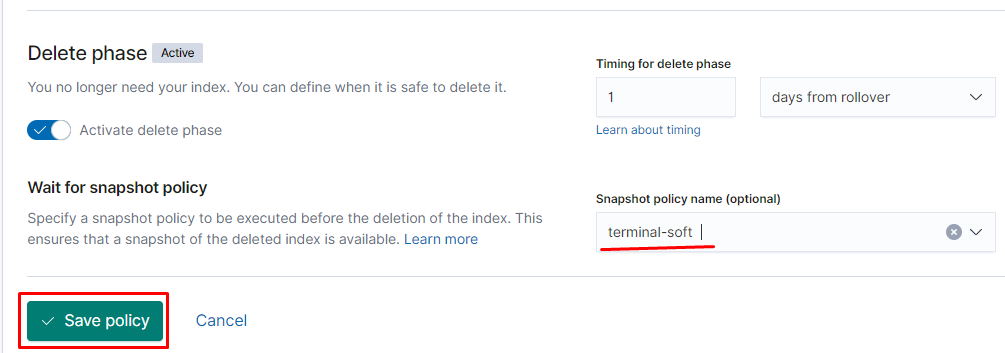
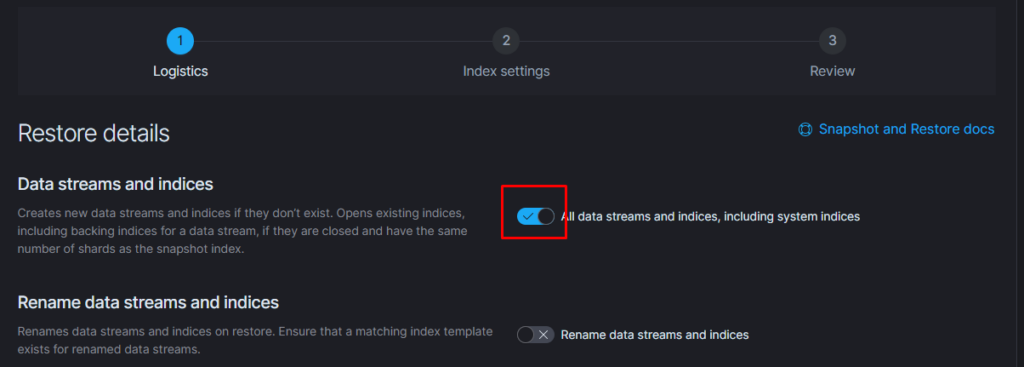
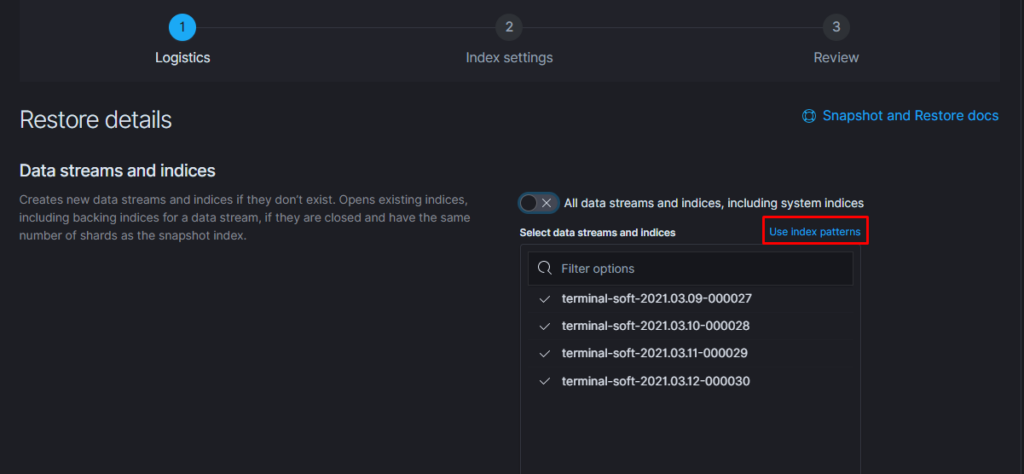
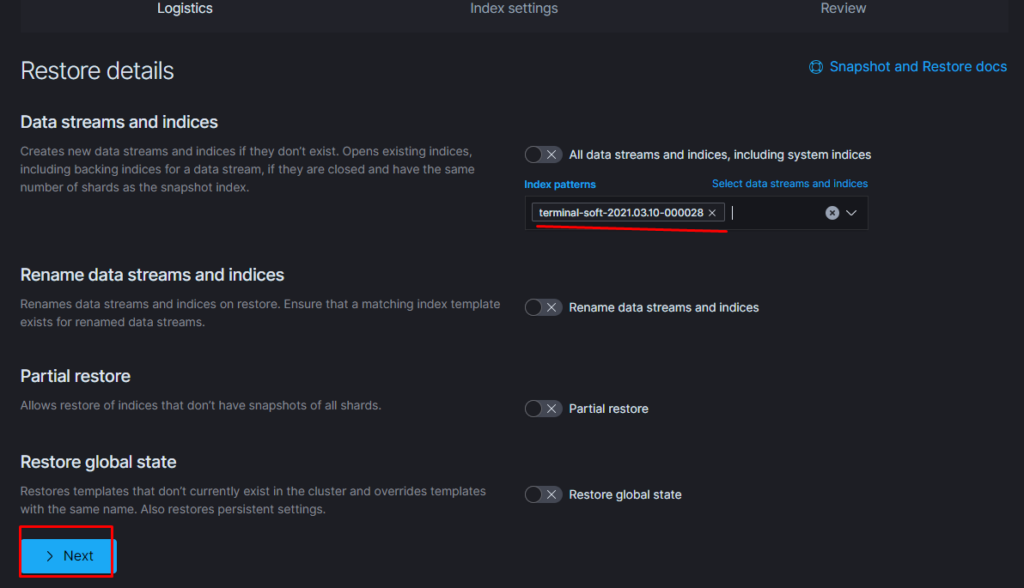
Если требуется восстановить индексы из snapshot то делаем следующее:
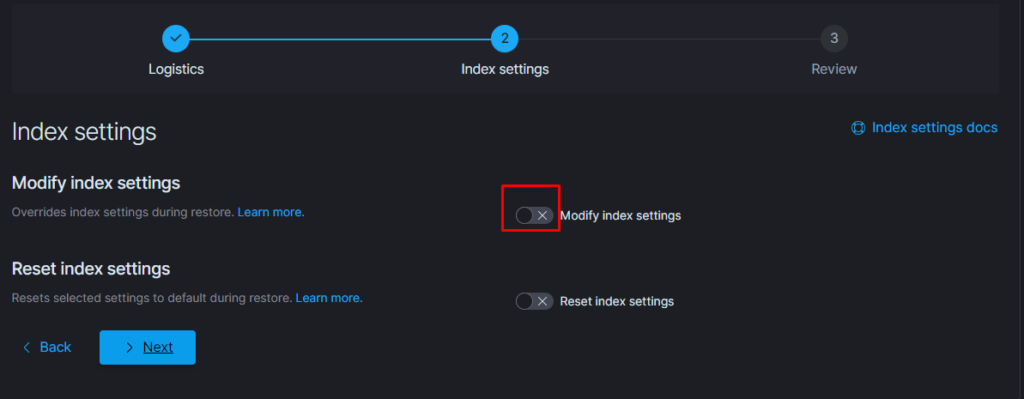
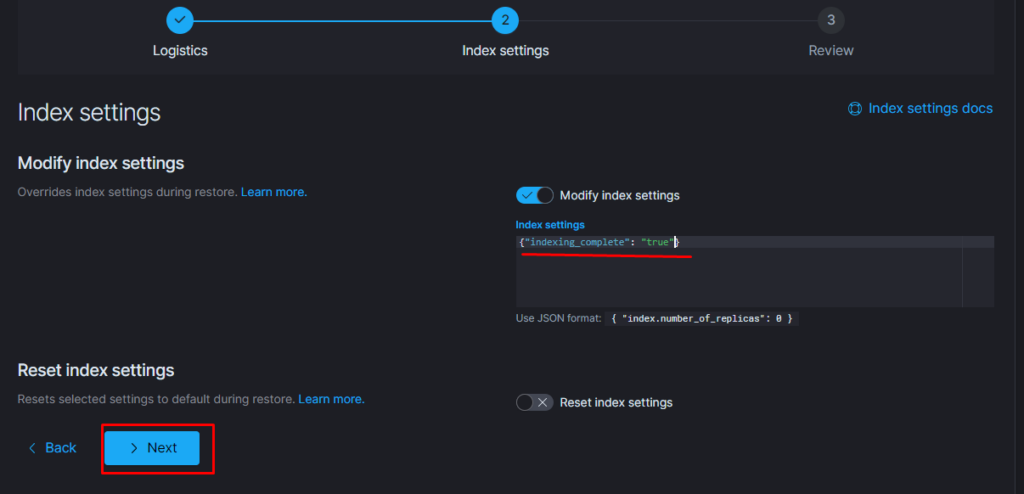
Тут надо добавить параметр
«indexing_complete»: «true» только в том случае если при восстановлении возникает ошибка следующего вида:
Unable to restore snapshot
[illegal_state_exception] alias [terminal-soft] has more than one write index [terminal-soft-2021.03.04-000022,terminal-soft-2021.03.16-000034]
Поэтому когда производишь восстановление необходимо восстанавливать индекс из самого последнего снапшота. т.е. Если нужен индекс за 10 число то снапшот смотрим где-то за 15 число. Ну или добавляем пераметр «indexing_complete»: «true»
Kubernetes позволяет автоматически масштабировать приложения (то есть Pod в развертывании или ReplicaSet) декларативным образом с использованием спецификации Horizontal Pod Autoscaler.
По умолчанию критерий для автоматического масштабирования — метрики использования CPU (метрики ресурсов), но можно интегрировать пользовательские метрики и метрики, предоставляемые извне.
Вместо горизонтального автомасштабирования подов, применяется Kubernetes Event Driven Autoscaling (KEDA) — оператор Kubernetes с открытым исходным кодом. Он изначально интегрируется с Horizontal Pod Autoscaler, чтобы обеспечить плавное автомасштабирование (в том числе до/от нуля) для управляемых событиями рабочих нагрузок. Код доступен на GitHub.
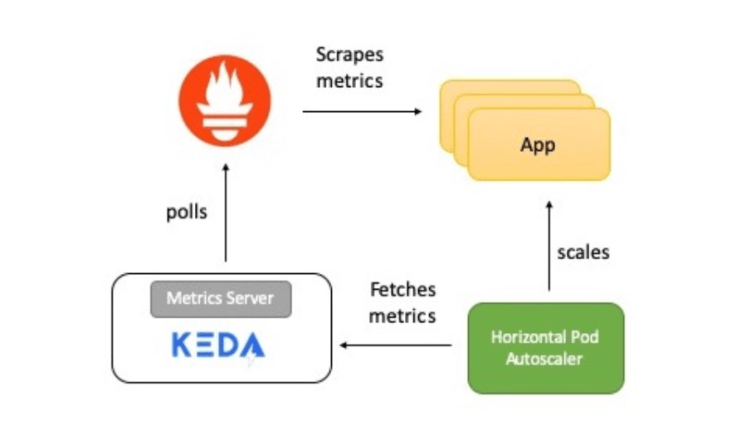
Краткий обзор работы системы
На схеме — краткое описание того, как все работает:
Приложение предоставляет метрики количества обращений к HTTP в формате Prometheus.
Prometheus настроен на сбор этих показателей.
Скейлер Prometheus в KEDA настроен на автоматическое масштабирование приложения на основе количества обращений к HTTP.
Теперь подробно расскажу о каждом элементе.
KEDA и Prometheus
Prometheus — набор инструментов для мониторинга и оповещения систем с открытым исходным кодом, часть Cloud Native Computing Foundation. Собирает метрики из разных источников и сохраняет в виде данных временных рядов. Для визуализации данных можно использовать Grafana или другие инструменты визуализации, работающие с API Kubernetes.
KEDA поддерживает концепцию скейлера — он действует как мост между KEDA и внешней системой. Реализация скейлера специфична для каждой целевой системы и извлекает из нее данные. Затем KEDA использует их для управления автоматическим масштабированием.
Скейлеры поддерживают нескольких источников данных, например, Kafka, Redis, Prometheus. То есть KEDA можно применять для автоматического масштабирования развертываний Kubernetes, используя в качестве критериев метрики Prometheus.
KEDA Prometheus ScaledObject
Скейлер действует как мост между KEDA и внешней системой, из которой нужно получать метрики. ScaledObject — настраиваемый ресурс, его необходимо развернуть для синхронизации развертывания с источником событий, в данном случае с Prometheus.
ScaledObject содержит информацию о масштабировании развертывания, метаданные об источнике события (например, секреты для подключения, имя очереди), интервал опроса, период восстановления и другие данные. Он приводит к соответствующему ресурсу автомасштабирования (определение HPA) для масштабирования развертывания.
Когда объект ScaledObject удаляется, соответствующее ему определение HPA очищается.
Вот определение ScaledObject для нашего примера, в нем используется скейлер Prometheus:
Тип триггера — Prometheus. Адрес сервера Prometheus упоминается вместе с именем метрики, пороговым значением и запросом PromQL, который будет использоваться. Запрос PromQL — sum(rate(http_requests[2m])).
Согласно pollingInterval, KEDA запрашивает цель у Prometheus каждые пятнадцать секунд. Поддерживается минимум один под (minReplicaCount), а максимальное количество подов не превышает maxReplicaCount (в данном примере — десять).
Можно установить minReplicaCount равным нулю. В этом случае KEDA активирует развертывание с нуля до единицы, а затем предоставляет HPA для дальнейшего автоматического масштабирования. Возможен и обратный порядок, то есть масштабирование от единицы до нуля. В примере мы не выбрали ноль, поскольку это HTTP-сервис, а не система по запросу.
Магия внутри автомасштабирования
Пороговое значение используют в качестве триггера для масштабирования развертывания. В нашем примере запрос PromQL sum(rate (http_requests [2m])) возвращает агрегированное значение скорости HTTP-запросов (количество запросов в секунду), ее измеряют за последние две минуты.
Поскольку пороговое значение равно трем, значит, будет один под, пока значение sum(rate (http_requests [2m])) меньше трех. Если же значение возрастает, добавляется дополнительный под каждый раз, когда sum(rate (http_requests [2m])) увеличивается на три. Например, если значение от 12 до 14, то количество подов — четыре.
Теперь давайте попробуем настроить!
Установка KEDA
Вы можете развернуть KEDA несколькими способами, они перечислены в документации. Я использую монолитный YAML:
helm repo add kedacore https://kedacore.github.io/charts helm repo update kubectl create namespace keda helm install keda kedacore/keda —namespace keda
я ставил через монолитный файл. проверим что всё поднялось:
[root@kub-master-1 ~]# kubectl get all -n keda
NAME READY STATUS RESTARTS AGE
pod/keda-metrics-apiserver-57cbdb849f-w7rfg 1/1 Running 0 70m
pod/keda-operator-58cb545446-5rblj 1/1 Running 0 70m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/keda-metrics-apiserver ClusterIP 10.100.134.31 <none> 443/TCP,80/TCP 70m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/keda-metrics-apiserver 1/1 1 1 70m
deployment.apps/keda-operator 1/1 1 1 70m
NAME DESIRED CURRENT READY AGE
replicaset.apps/keda-metrics-apiserver-57cbdb849f 1 1 1 70m
replicaset.apps/keda-operator-58cb545446 1 1 1 70m
3. Пример работы
создаём namespace
kubectl create ns my-site
запускаем обычное приложение например apache:
[root@kub-master-1 ~]# cat my-site.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment-apache
namespace: my-site
spec:
replicas: 1
selector:
matchLabels:
app: apache # по вот этому лейблу репликасет цепляет под
# тут описывается каким мокаром следует обновлять поды
strategy:
rollingUpdate:
maxSurge: 1 # указывает на какое количество реплик можно увеличить
maxUnavailable: 1 # указывает на какое количество реплик можно уменьшить
#т.е. в одно время при обновлении, будет увеличено на один (новый под) и уменьшено на один (старый под)
type: RollingUpdate
## тут начинается описание контейнера
template:
metadata:
labels:
app: apache # по вот этому лейблу репликасет цепляет под
spec:
containers:
- image: httpd:2.4.43
name: apache
ports:
- containerPort: 80
# тут начинаются проверки по доступности
readinessProbe: # проверка готово ли приложение
failureThreshold: 3 #указывает количество провалов при проверке
httpGet: # по сути дёргает курлом на 80 порт
path: /
port: 80
periodSeconds: 10 #как часто должна проходить проверка (в секундах)
successThreshold: 1 #сбрасывает счётчик неудач, т.е. при 3х проверках если 1 раз успешно прошло, то счётчик сбрасывается и всё ок
timeoutSeconds: 1 #таймаут на выполнение пробы 1 секунда
livenessProbe: #проверка на жизнь приложения, живо ли оно
failureThreshold: 3
httpGet:
path: /
port: 80
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
initialDelaySeconds: 10 #означает что первую проверку надо сделать только после 10 секунд
# тут начинается описание лимитов для пода
resources:
requests: #количество ресурсов которые резервируются для pod на ноде
cpu: 60m
memory: 200Mi
limits: #количество ресурсов которые pod может использовать(верхняя граница)
cpu: 120m
memory: 300Mi
[root@kub-master-1 ~]# cat my-site-service.yaml
---
apiVersion: v1
kind: Service
metadata:
name: my-service-apache # имя сервиса
namespace: my-site
spec:
ports:
- port: 80 # принимать на 80
targetPort: 80 # отправлять на 80
selector:
app: apache #отправлять на все поды с данным лейблом
type: ClusterIP
[root@kub-master-1 ~]# cat my-site-ingress.yaml
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: my-ingress
namespace: my-site
spec:
rules:
- host: test.ru #тут указывается наш домен
http:
paths: #список путей которые хотим обслуживать(он дефолтный и все запросы будут отпаврляться на бэкенд, т.е. на сервис my-service-apache)
- backend:
serviceName: my-service-apache #тут указывается наш сервис
servicePort: 80 #порт на котором сервис слушает
# path: / все запросы на корень '/' будут уходить на наш сервис
NAME READY STATUS RESTARTS AGE
pod/my-deployment-apache-859486bd8c-k6bql 1/1 Running 0 20m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/my-service-apache ClusterIP 10.100.255.190 <none> 80/TCP 20m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/my-deployment-apache 1/1 1 1 20m
NAME DESIRED CURRENT READY AGE
replicaset.apps/my-deployment-apache-859486bd8c 1 1 1 20m
будем автоскейлить — для примера по метрике nginx nginx_ingress_controller_requests
запрос в prometheus будет следующий:
sum(irate( nginx_ingress_controller_requests{namespace=»my-site»}[3m] )) by (ingress)*10
т.е. считаем общее количество запросов в неймспейс my-site за 3 минуты
тут мы указываем в каком namespace нам запускаться: namespace: my-site
указываем цель, т.е. наш deployment: name: my-deployment-apache
задаём минимальное и максимальное количество реплик minReplicaCount: 1 # значение по умолчанию: 0 maxReplicaCount: 8 # значение по умолчанию: 100
есть ещё 2 стандартные переменные отвечающие за то когда поды будут подыматься и убиваться: pollingInterval: 30 # Optional. Default: 30 seconds cooldownPeriod: 300 # Optional. Default: 300 seconds
указываем адрес нашего prometheus
serverAddress: http://prometheus-kube-prometheus-prometheus.monitoring.svc.cluster.local:9090 адрес идёт в виде сервис.неймспейс.svc.имя_кластера
Продолжаю цикл статей про кластерные решения, который был начат с установки kubernetes. Я расскажу как установить и настроить кластер ceph, также покажу, как им потом пользоваться. Статья с практическими примерами от и до — поднятие кластера и подключение дисков к конечным серверам.