Имеется приложение на Go, API-бекенд.
Периодически начинает возвращать 502 ошибку, хотя сам под работает и в статусе Running.
Что бы рассмотреть, как и почему Ingress и Service могут возвращать 502, и как работают readinessProbe и livenessProbe в Kubernetes Deployment – напишем простой веб-сервер на Go, в котором опишем два ендпоинта – один будет возвращать нормальный ответ, а во втором – выполнение программы будет прерываться.
Затем задеплоим его в AWS Elastic Kubernetes, создадим Kubernetes Ingress, который создаст AWS Application Load balancer, и потрестируем работу приложения.
Golang HTTP server
Пишем приложение на Go, которое потом упакуем в Docker-контейнер, и запустим в Kubernetes:
package main
import (
"fmt"
"log"
"net/http"
)
func main() {
http.HandleFunc("/ping", func(w http.ResponseWriter, r *http.Request){
fmt.Fprintf(w, "pong")
})
http.HandleFunc("/err", func(w http.ResponseWriter, r *http.Request){
panic("Error")
})
fmt.Printf("Starting server at port 8080n")
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatal(err)
}
}
Тут мы запускаем http.ListenAndServe() на порту 8080, и определяем два роута:
/ping– при обращении сюда всегда возвращаем 200/err– при обращении сюда прерываем выполнение функции сpanic, что сэмулировать некорретный ответ приложения
Проверяем локально.
Запускаем:
go run http.go
Starting server at port 8080
Проверяем роут /ping:
curl -I localhost:8080/ping
HTTP/1.1 200 OK
И URI /err, который вызовет panic:
curl -I localhost:8080/err
curl: (52) Empty reply from server
Лог приложения:
go run http.go
Starting server at port 8080
2020/11/11 14:34:53 http: panic serving [::1]:43008: Error
goroutine 6 [running]:
...
Docker образ
Пишем Dockefile:
FROM golang:latest
WORKDIR /app
COPY . .
RUN go build -o main .
EXPOSE 8080
CMD ["./main"]
Собираем образ и пушим в Docker Hub:
docker build -t setevoy/go-http .
docker push setevoy/go-http
Kubernetes
Deployment
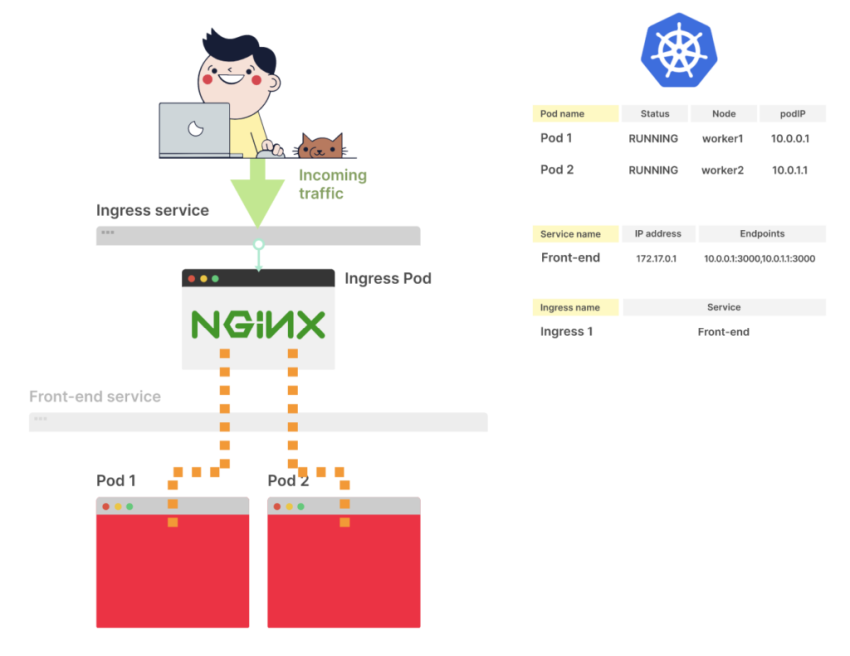
Описываем запуск пода с этим образом – создаём 1 под, Service для него, и Ingress, который создаст AWS Application Load Balancer.
Начнём с Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: go-http
labels:
app: go-http
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: go-http
template:
metadata:
labels:
app: go-http
spec:
containers:
- name: go-http
image: setevoy/go-http
ports:
- containerPort: 8080
imagePullPolicy: Always
livenessProbe:
httpGet:
path: /ping
port: 8080
initialDelaySeconds: 1
periodSeconds: 1
readinessProbe:
httpGet:
path: /ping
port: 8080
initialDelaySeconds: 1
periodSeconds: 1
restartPolicy: Always
Тут создаём один под, который слушает порт 8080.
В strategy деплоймента указываем Recreate, что бы при тестах не оставались старые поды.
Для него описываем проверки – livenessProbe и readinessProbe, обе проверки ходят на URI /ping, где получают ответ 200.
Позже мы поменяем путь в проверках, и посмотрим, к чему это приведёт.
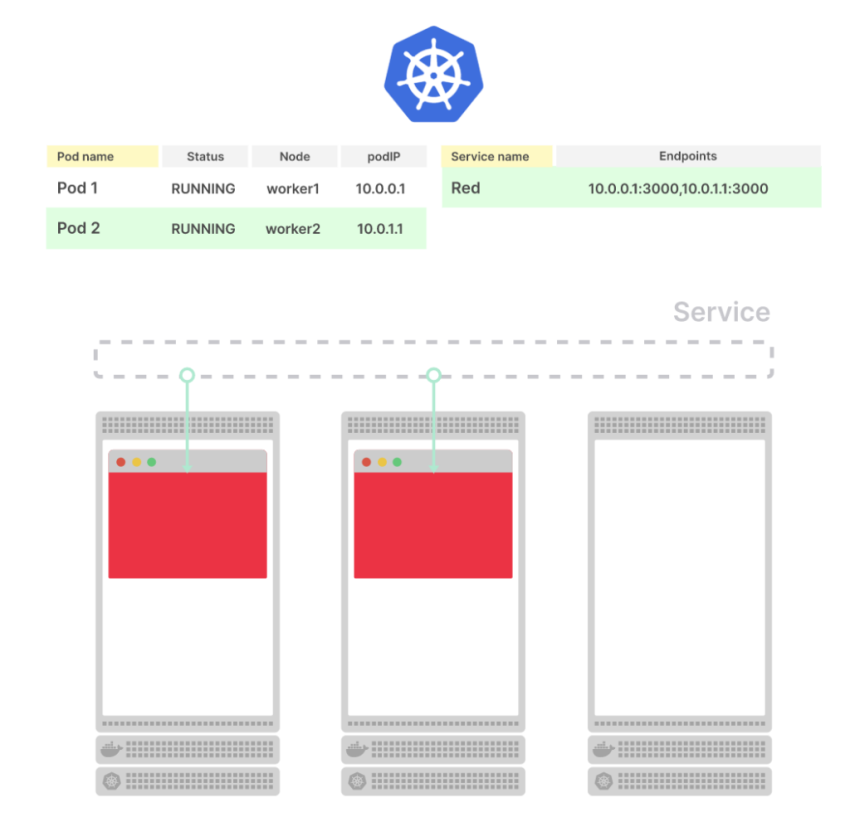
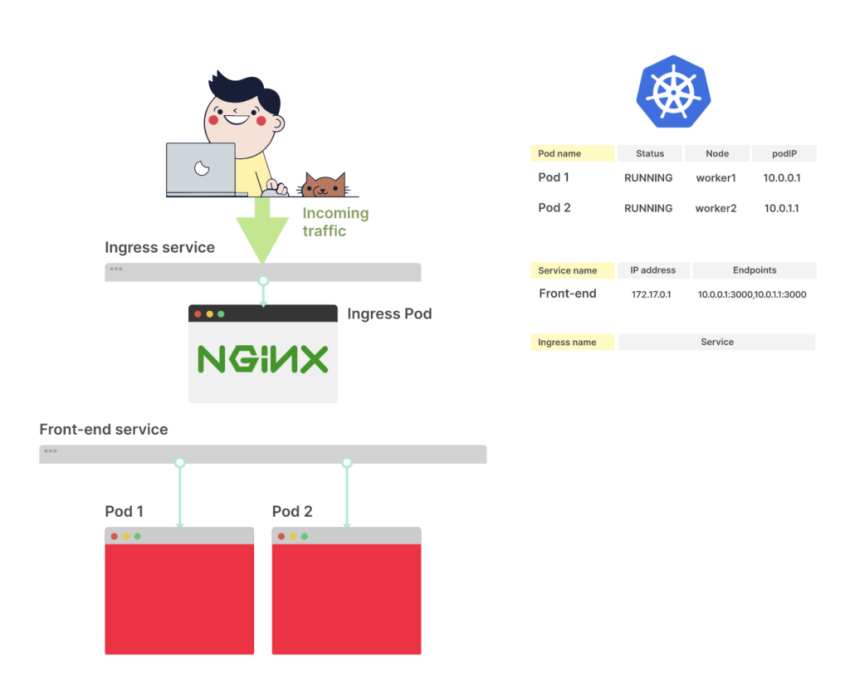
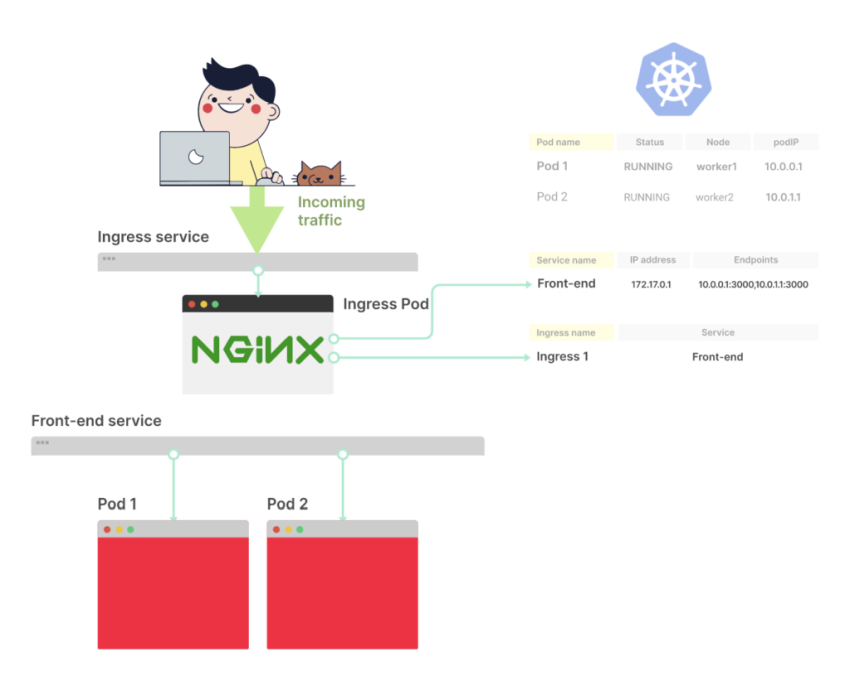
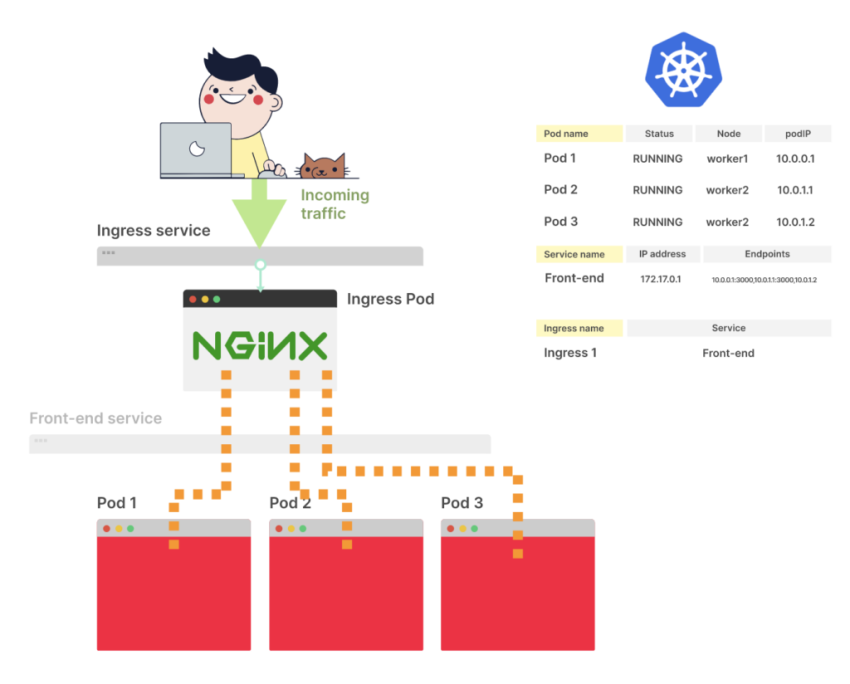
Service
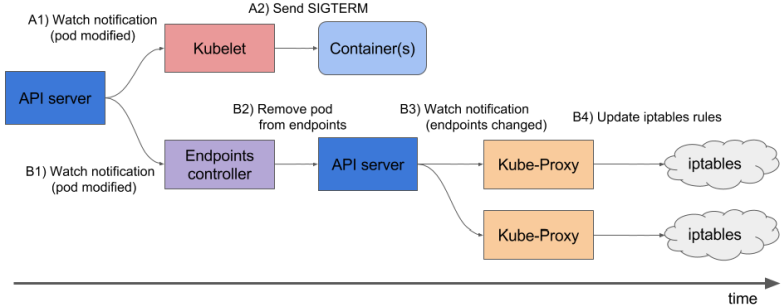
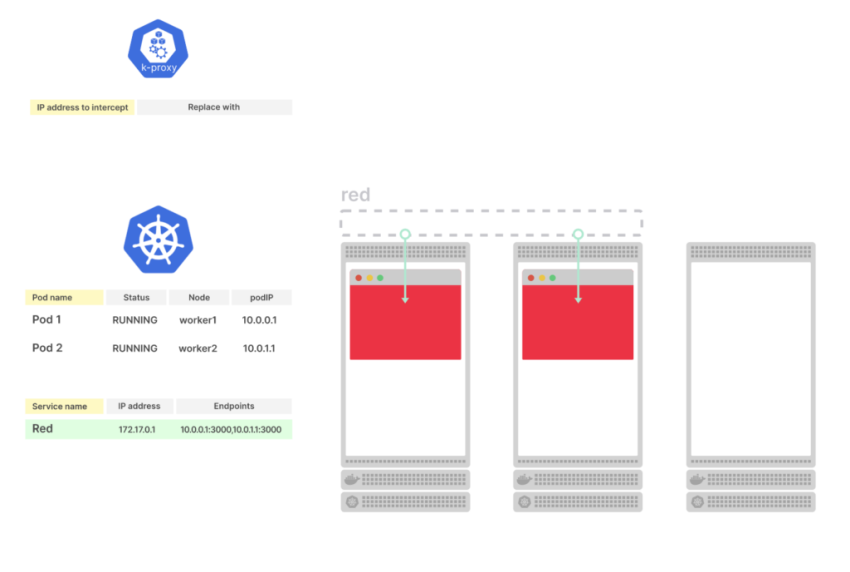
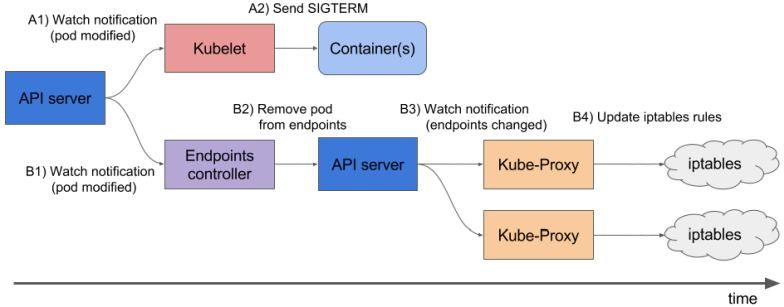
Создаём Kubernetes Service, который откроет на WorkerNode порт для ALB, и будет роутить трафик к нашему поду на порт 8080 (см. Kubernetes: Service, балансировка нагрузки, kube-proxy и iptables):
---
apiVersion: v1
kind: Service
metadata:
name: go-http-svc
spec:
type: NodePort
ports:
- port: 80
targetPort: 8080
protocol: TCP
selector:
app: go-http
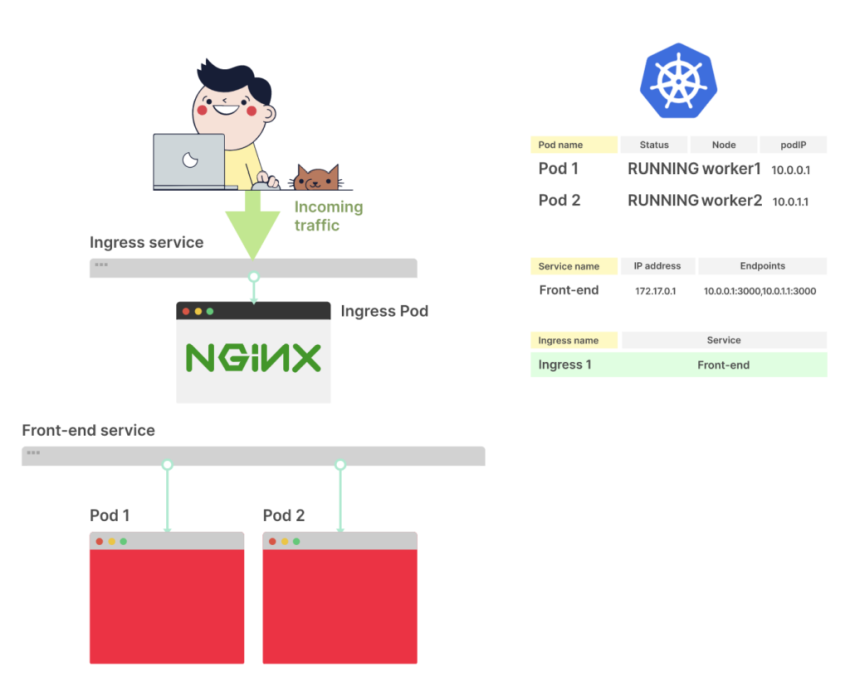
Ingress
Добавляем Ingress, который создаст AWS Application Load Balancer, который будет направлять трафик к go-http-svc Service:
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: go-http-ingress
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/healthcheck-path: /ping
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}]'
labels:
app: go-http
spec:
rules:
- http:
paths:
- path: /*
backend:
serviceName: go-http-svc
servicePort: 80
Создаём ресурсы:
kubectl apply -f go-http.yaml
deployment.apps/go-http created
service/go-http-svc created
ingress.extensions/go-http-ingress created
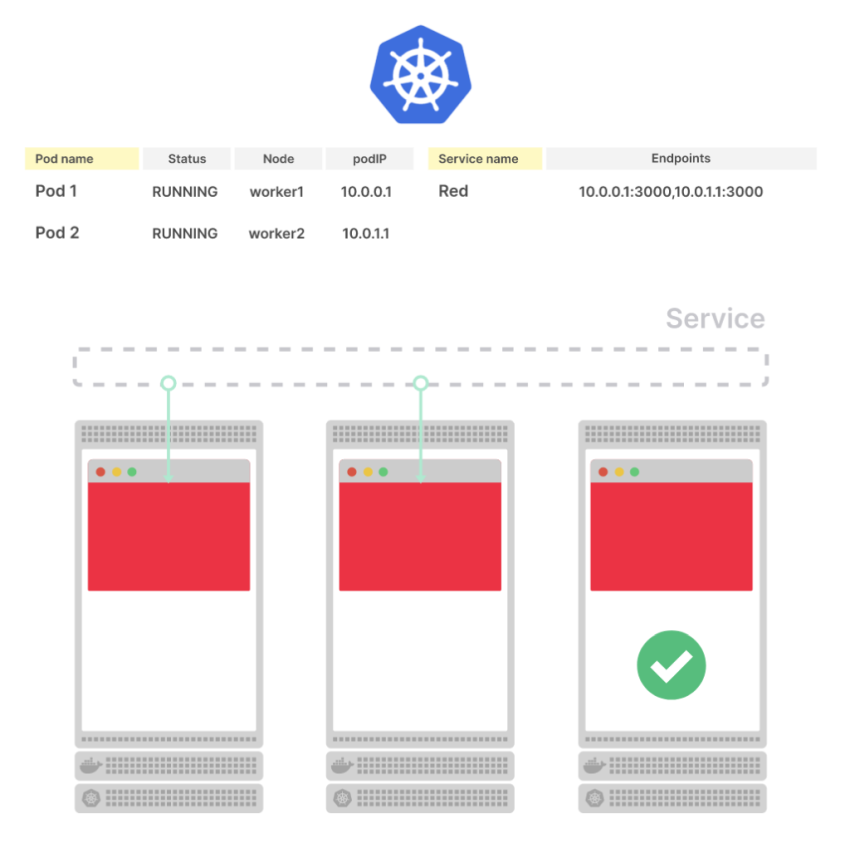
Проверяем под:
kubectl get pod -l app=go-http
NAME READY STATUS RESTARTS AGE
go-http-8dc5b4779-7q4kw 1/1 Running 0 8s
И его Ingress:
kubectl get ingress -l app=go-http
NAME HOSTS ADDRESS PORTS AGE
go-http-ingress * e172ad3e-default-gohttping-ec00-691779486.us-east-2.elb.amazonaws.com 80 31s
Ждём, пока наш DNS увидит новый URL e172ad3e-default-gohttping-ec00-691779486.us-east-2.elb.amazonaws.com, и проверяем работу приложения – выполняем запрос к /ping:
curl -I e172ad3e-default-gohttping-ec00-691779486.us-east-2.elb.amazonaws.com/ping
HTTP/1.1 200 OK
Kubernetes Ingress 502
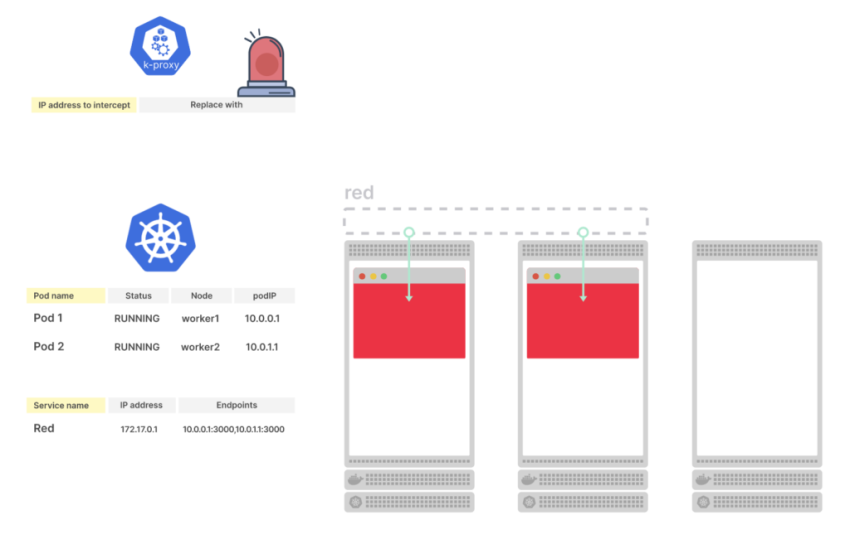
А теперь – обращаемся к ендпоинту /err, который в Go-приложении вызовет panic, и ловим 502 ошибку:
curl -vI e172ad3e-default-gohttping-ec00-691779486.us-east-2.elb.amazonaws.com/err
...
< HTTP/1.1 502 Bad Gateway
HTTP/1.1 502 Bad Gateway
< Server: awselb/2.0
Server: awselb/2.0
Логи пода:
kubectl logs go-http-8dc5b4779-7q4kw
Starting server at port 8080
2020/11/11 12:57:10 http: panic serving 10.3.39.145:8926: Error
goroutine 5169 [running]:
net/http.(*conn).serve.func1(0xc000260e60)
/usr/local/go/src/net/http/server.go:1801 +0x147
panic(0x654840, 0x6f0ba0)
/usr/local/go/src/runtime/panic.go:975 +0x47a
main.main.func2(0x6fa0a0, 0xc00012c540, 0xc000127700)
/app/http.go:16 +0x39
net/http.HandlerFunc.ServeHTTP(0x6bab98, 0x6fa0a0, 0xc00012c540, 0xc000127700)
/usr/local/go/src/net/http/server.go:2042 +0x44
net/http.(*ServeMux).ServeHTTP(0x8615e0, 0x6fa0a0, 0xc00012c540, 0xc000127700)
/usr/local/go/src/net/http/server.go:2417 +0x1ad
net/http.serverHandler.ServeHTTP(0xc0000ea000, 0x6fa0a0, 0xc00012c540, 0xc000127700)
/usr/local/go/src/net/http/server.go:2843 +0xa3
net/http.(*conn).serve(0xc000260e60, 0x6fa4e0, 0xc00011b8c0)
/usr/local/go/src/net/http/server.go:1925 +0x8ad
created by net/http.(*Server).Serve
/usr/local/go/src/net/http/server.go:2969 +0x36c
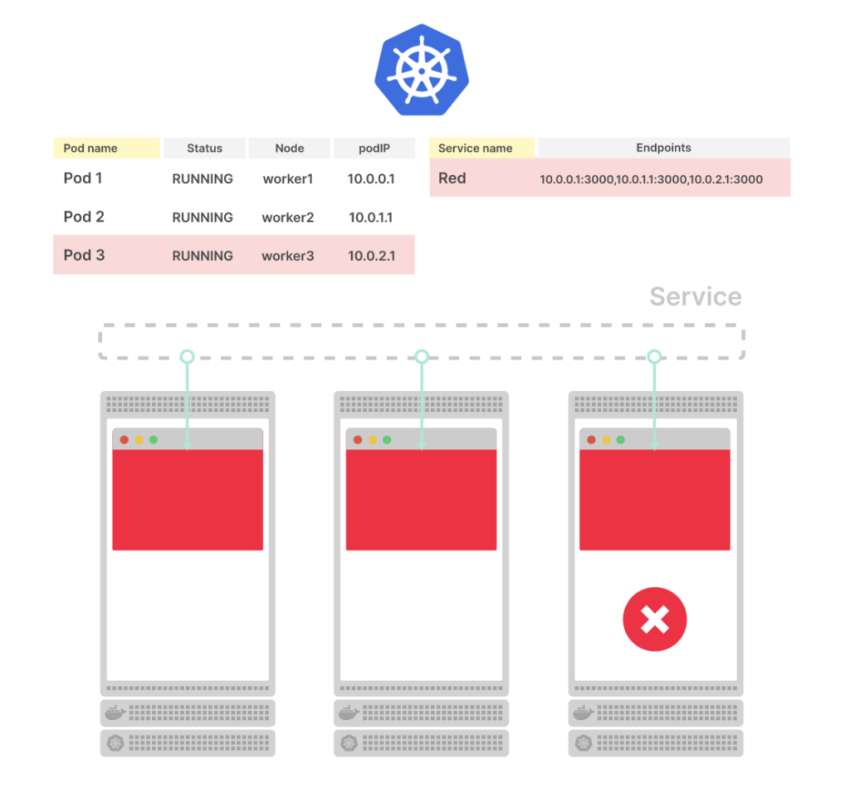
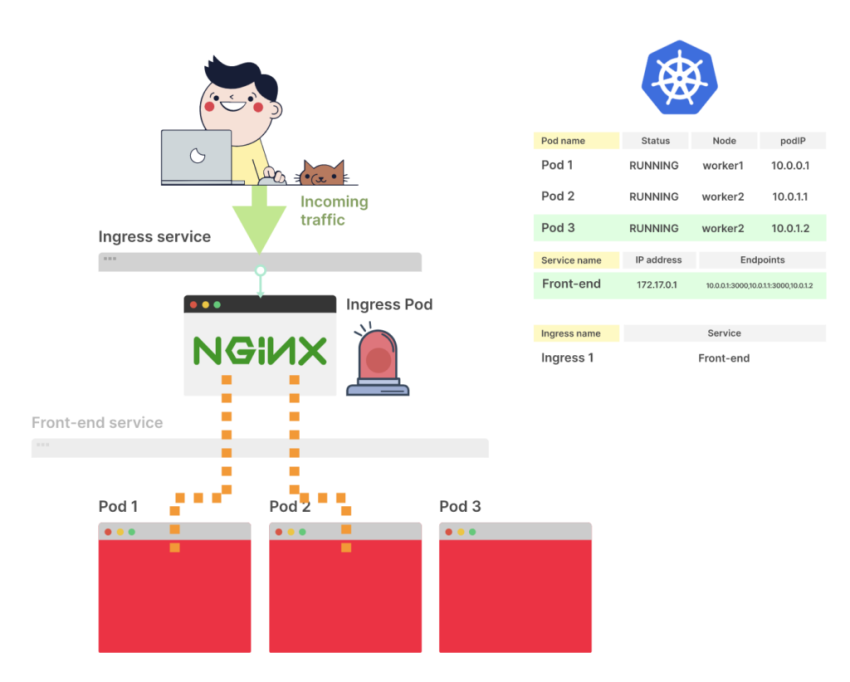
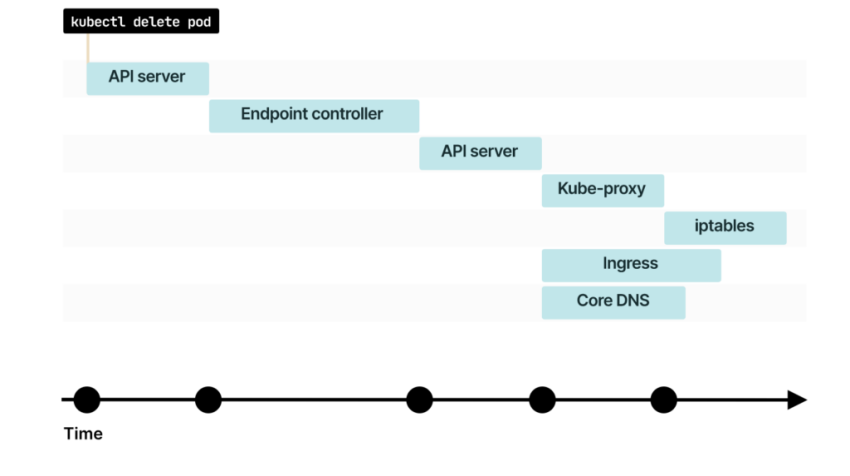
Тут всё логично – load-balancer отправил наш запрос к поду, под не ответил (вспомним curl: (52) Empty reply from server в наших первых тестах), и мы получили ответ 502 от балансировщика aka Ingress.
readinessProbe и livenessProbe
Теперь посмотрим, как изменение в readinessProbe и livenessProbe повлияют на ответы Ingress и работу самого пода.
readinessProbe
Документация – тут>>>.
readinessProbe используется для проверки того, готов ли под принимать трафик.
Сейчас наш под в статусе Ready:
kubectl get pod -l app=go-http
NAME READY STATUS RESTARTS AGE
go-http-8dc5b4779-7q4kw 1/1 Running 0 28m
Или так:
kubectl get pod -l app=go-http -o json | jq '.items[].status.containerStatuses[].ready'
true
И запрос к /ping возвращает нам ответ 200:
curl -I e172ad3e-default-gohttping-ec00-691779486.us-east-2.elb.amazonaws.com/ping
HTTP/1.1 200 OK
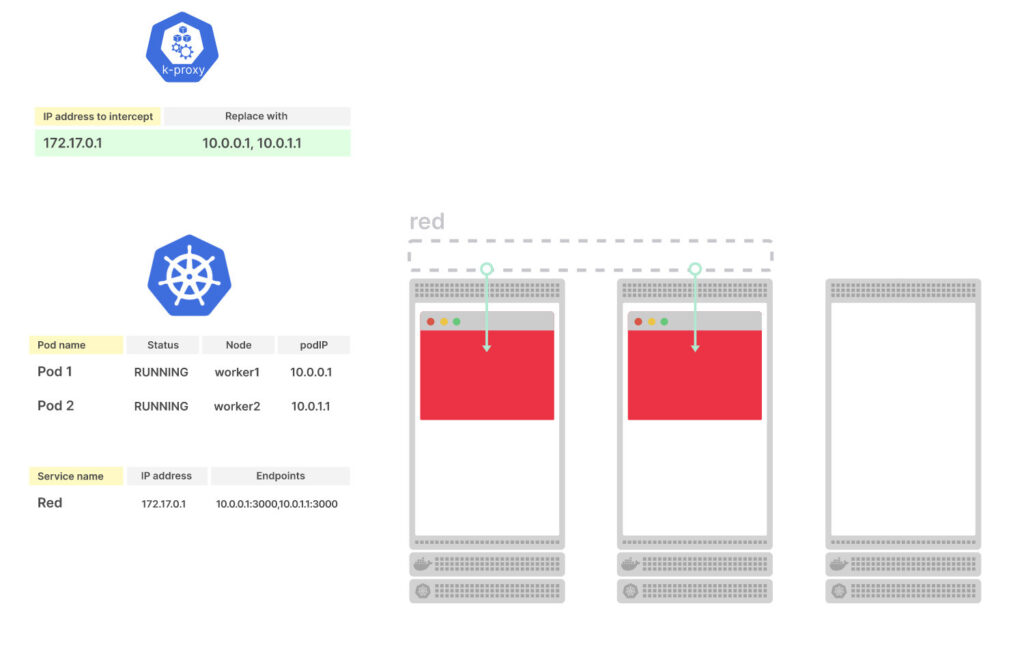
Меняем readinessProbe – задаём path=/err, что бы проверка постоянно фейлилась:
...
readinessProbe:
httpGet:
path: /err
...
Передеплоиваем:
kubectl apply -f go-http.yaml
deployment.apps/go-http configured
И проверяем:
kubectl get pod -l app=go-http
NAME READY STATUS RESTARTS AGE
go-http-5bd557544-2djcw 0/1 Running 0 4s
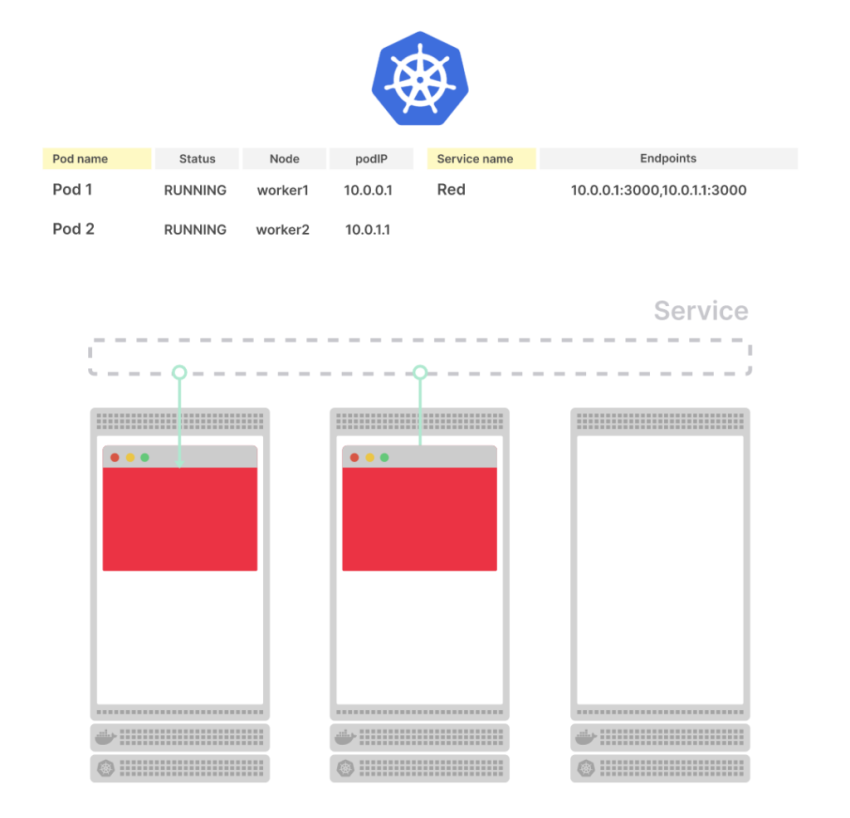
Если мы теперь отправим запрос даже на ендпоинт /ping – всё-равно получим 502, т.к. бекенд Сервиса, т.е. под, не принимает трафик, потому что не прошёл readinessProbe:
kubectl get pod -l app=go-http -o json | jq '.items[].status.containerStatuses[].ready'
false
Пробуем:
curl -I e172ad3e-default-gohttping-ec00-691779486.us-east-2.elb.amazonaws.com/ping
HTTP/1.1 502 Bad Gateway
livenessProbe
Документация – тут>>>.
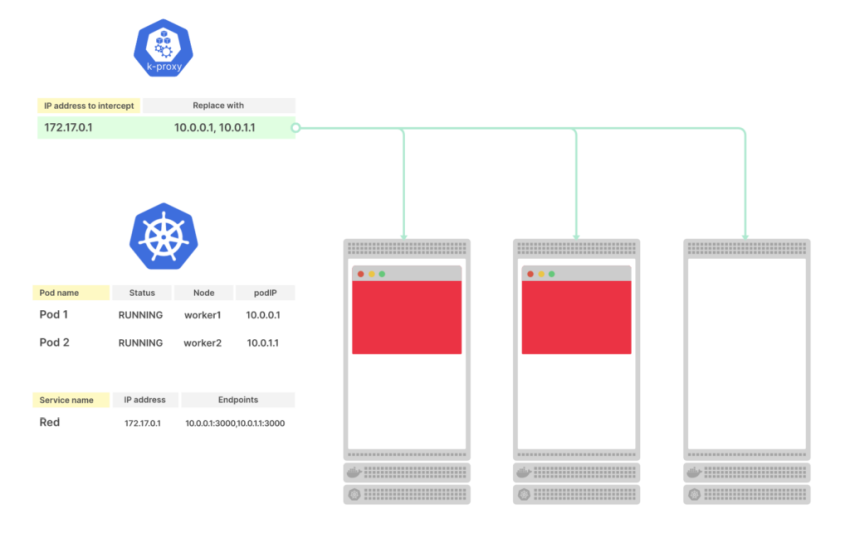
Вернём readinessProbe в /ping, что бы трафик на под пошёл, но изменим livenessProbe – зададим path в /err, а initialDelaySeconds и periodSeconds установим в 15 секунд, плюс добавим failureThreshold равным одной попытке:
...
livenessProbe:
httpGet:
path: /err
port: 8080
initialDelaySeconds: 15
periodSeconds: 15
failureThreshold: 1
readinessProbe:
httpGet:
path: /ping
...
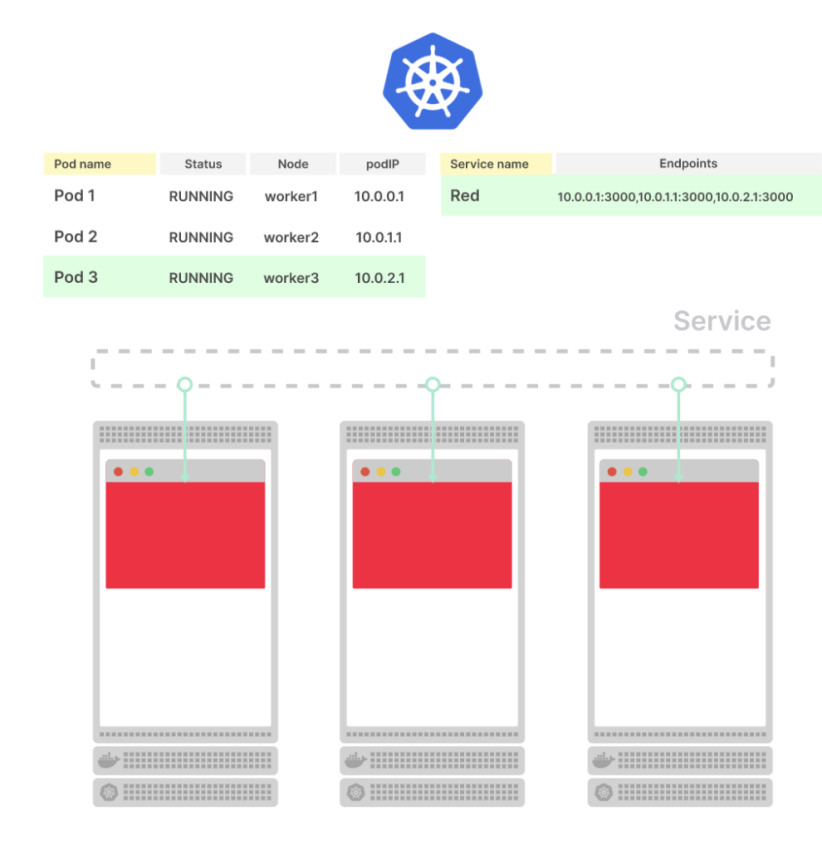
Теперь после запуска пода Kubernetes выждет 15 секунд, затем выполнит livenessProbe и будет повторять её каждые следующие 15 секунд.
Передеплоиваем, и проверяем:
kubectl get pod -l app=go-http
NAME READY STATUS RESTARTS AGE
go-http-78f6c66c8b-q6fkf 1/1 Running 0 6s
Проверяем запрос к ендпоинту /ping:
curl -I e172ad3e-default-gohttping-ec00-691779486.us-east-2.elb.amazonaws.com/ping
HTTP/1.1 200 OK
Всё хорошо.
И /err нам ожидаемо вернёт 502:
curl -I e172ad3e-default-gohttping-ec00-691779486.us-east-2.elb.amazonaws.com/err
HTTP/1.1 502 Bad Gateway
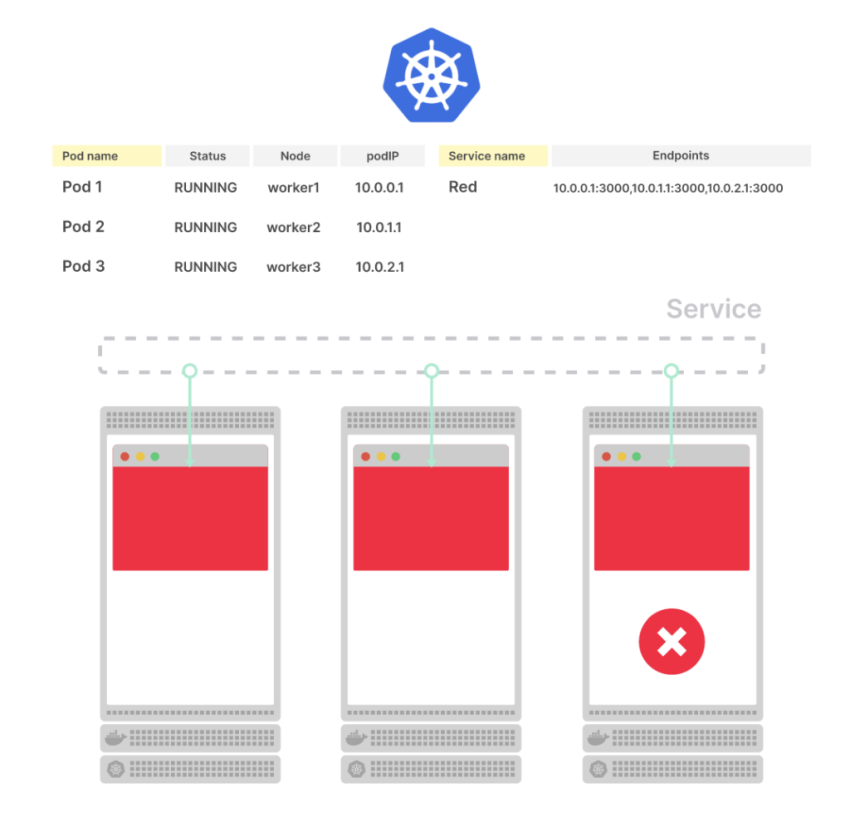
Через 15 секунд, после выполнения первой live проверки – под будет перезапущен:
kubectl get pod -l app=go-http
NAME READY STATUS RESTARTS AGE
go-http-668c674dcb-4db9x 0/1 Running 1 19s
Events этого пода:
kubectl describe pod -l app=go-http
...
Normal Created 6s (x4 over 81s) kubelet, ip-10-3-55-229.us-east-2.compute.internal Created container go-http
Warning Unhealthy 6s (x3 over 66s) kubelet, ip-10-3-55-229.us-east-2.compute.internal Liveness probe failed: Get http://10.3.53.103:8080/err: EOF
Normal Killing 6s (x3 over 66s) kubelet, ip-10-3-55-229.us-east-2.compute.internal Container go-http failed liveness probe, will be restarted
Normal Started 5s (x4 over 81s) kubelet, ip-10-3-55-229.us-east-2.compute.internal Started container go-http
Контейнер в поде не прошёл проверку livenessProbe, и Kubernetes перезапускает под в попытке “починить” его.
Если получится попасть на сам момент перезапуска контейнера – увидим стаус CrashLoopBackOff, а запрос к /ping снова вернёт нам 502:
kubectl get pod -l app=go-http
NAME READY STATUS RESTARTS AGE
go-http-668c674dcb-4db9x 0/1 CrashLoopBackOff 4 2m21s
Выводы
Используем readinessProbe для проверки того, что приложение запустилось, в данном случае – Go-бинарник начал прослушивать порт 8080, и на него можно направлять трафик, и используем livenessProbe во время работы пода для проверки того, что приложение в нём все ещё живо.
Если приложение начинает отдавать 502 на определённые запросы – то следует поискать проблему именно в запросах, т.к. если бы была проблема в настройках Ingress/Service – получали бы 502 постоянно.
Самое важное – понимать принципиальную разницу между readinessProbe и livenessProbe:
- если фейлится
readinessProbe– процесс aka контейнер в поде останется в том же состоянии, в котором был на момент сфейленой ready-проверки, но под будет отключен от трафика к нему - если фейлится
livenessProbe– трафик на под продолжает идти, но контейнер будет перезапущен
Итак, имеем ввиду, что:
- Если
readinessProbeне задана вообще –kubeletбудет считать, что под готов к работе, и направит к нему трафик сразу после старта пода. При этом если на запуск пода уходит минута – то клиенты, которые к нему были направлены после его запуска, будут ждать эту минуту, пока он ответит. - Если приложение ловит ошибку, которую не может обработать – оно должно завершить свой процесс, и Kubernetes сам перезапустит контейнер.
- Используем
livenessProbeдля проверки состояний, которые нельзя обработать в самом приложении, например – deadlock или бесконечный цикл, при которых контейнер не может ответить на ready-проверку. В таком случае если нетlivenessProbe, которая может перезапустить процесс, то под будет отключен от Service – но останется в статусе Running, продолжая потреблять реурсы WorkerNode.
Источник: https://rtfm.co.ua/ru/kubernetes-ingress-oshibka-502-readinessprobe-i-livenessprobe/