
В прошлом посте мы с Вами разобрались, как ранжировать людей по вкусам и говорить кто на нас похож больше всех. Теперь займемся связанной задачей — рекомендацией фильмов!
Рекомендование предметов
Найти подходящего критика – это, конечно, неплохо, но в действительности-то я хочу, чтобы мне порекомендовали фильм. Можно было бы посмотреть, какие фильмы понравились человеку с похожими на мои вкусами, и выбрать из них те, что я еще не смотрел. Но при таком подходе можно было бы пропустить много классных фильмов. Или посмотреть фильм, который понравился только ему.
Чтобы разрешить эти проблемы, необходимо ранжировать сами фильмы, вычислив взвешенную сумму оценок критиков. Берем каждого из отобранных критиков и умножаем его оценку подобия со мной на оценку, которую он выставил каждому фильму. Вот пример из книжки, надеюсь будет понятно)

Смысл в том, чтобы мнение критика с похожими на мои вкусами вносило больший вклад в общую оценку, чем мнение критика, не похожего на меня. В строке «Итого» приведены суммы вычисленных таким образом величин.
select v1.film_id,
count(1),--количество людей тоже ставивших голоса фильму кроме меня
evkl.sum_koef -- сумма подобия людей(со мной) голосовавших за этот фильм
from votes v1
join votes v2 on v1.film_id=v2.film_id
join (
select sum(evkl.vote*evkl.koef)/sum(evkl.koef) sum_koef, evkl.film_id
from(
select
v1.user_id,
v1.vote,
v1.film_id,
1/(1+(|/sum((v1.vote-v2.vote)^2))) koef--евклидово не взвешенное расстояние
from votes v1
join votes v2 on v1.film_id=v2.film_id
where v1.user_id <> v2.user_id
and v2.user_id=4722023 -- мой id
group by v1.user_id, v1.film_id, v1.vote
) evkl
group by evkl.film_id
) evkl on v1.film_id=evkl.film_id
where v1.user_id <> v2.user_id
and v2.user_id=4722023 -- мой id
group by v1.film_id, evkl.sum_koef
order by evkl.sum_koef desc
Таким образом фильмы с одинаковыми оценками(которые поставил я), стали взвешенными и выстроились в порядке, которые по идее мне понравились чуточку больше)))
Ну что же — это уже, как минимум не плохо) Но и основная задача, рекомендации фильмов, решается не сложнее).
select
v1.film_id,
sum(v1.vote*evkl.koef)/sum(evkl.koef)
from votes v1
join (
select
v1.user_id,
1/(1+(|/sum((v1.vote-v2.vote)^2))) koef--евклидово не взвешенное расстояние
from votes v1
join votes v2 on v1.film_id=v2.film_id
where v1.user_id <> v2.user_id
and v2.user_id=4722023
group by v1.user_id
order by v1.user_id
) evkl on evkl.user_id=v1.user_id
--фильтруем, чтобы за фильм голосовало не менее 10 человек
join (
select film_id, count(1) from votes group by film_id having count(1)>10
) flms on flms.film_id=v1.film_id
group by v1.film_id
order by sum(v1.vote*evkl.koef)/sum(evkl.koef)
Вот и все!) Что нам нужно знать об этой ф-ии. Ну во первых мы ввели ограничение на минимальное кол-во голосов за фильм в 10, чтобы не вышло так, что кому-то понравился фильм, у вас с этим критиком коэффициент близкий у 1 и соответственно фильм имеет хороший вес.
И теперь про отличие этой цифры от той, что выставлена на самом сайте kinopoisk.ru. А отличие простое: там просто средне арифметическая по голосам и кол-ву голосовавших, а эта чисто ваша, рассчитанная исходя из сходства вкусов Вас и тех кто голо
совал. Поэтому при таком подходе, у разных людей у одного и того же фильма будут разные оценки, иногда абсолютно разные!)))
Фильтрация по схожести образцов
Техника, которую мы применяли до сих пор, называется коллаборативной фильтрацией по схожести пользователей. Альтернатива известна под названием «коллаборативная фильтрация по схожести образцов». Когда набор данных очень велик, коллаборативная фильтрация по схожести образцов может давать лучшие результаты, причем многие вычисления можно выполнить заранее, поэтому пользователь получит рекомендации быстрее.
Итак, создадим табличку, куда будем записывать коэффициенты схожести фильмов между собой.
CREATE TABLE movies_similarity
(
id serial NOT NULL,
film_id1 integer NOT NULL,
film_id2 integer NOT NULL,
pirson_koef double precision NOT NULL,
CONSTRAINT movies_similarity_pk PRIMARY KEY (id)
)
Туда при помощи запроса и конструкции INSERT INTO запишем данные фильмов, которые мы оценили уже на сайте.
Выдача рекомендаций
Теперь вы готовы выдавать рекомендации, пользуясь словарем данных о схожести образцов без обращения ко всему набору данных. Необходимо получить список всех образцов, которым пользователь выставлял оценки, найти похожие и взвесить их с учетом коэффициентов подобия. Давайте разберем пример:
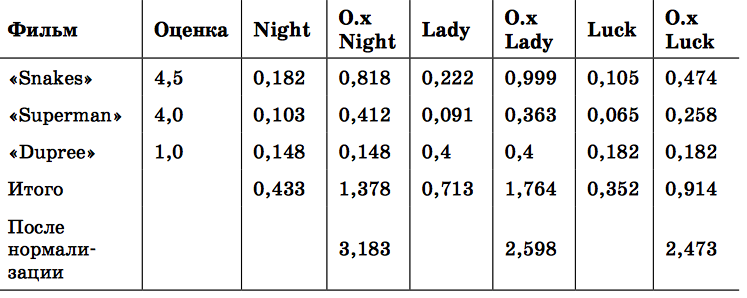
В каждой строке указан фильм, который я смотрел, и оценка, которую я ему выставил. Для каждого фильма, который я не смотрел, имеется столбец, где показано, насколько он похож на виденные мной фильмы. Например, коэффициент подобия между фильмами «Superman» и «The Night Listener» равен 0,103. В столбцах с названиями, начинающимися с О.x, показана моя оценка, умноженная на коэффициент подобия; поскольку я поставил фильму «Superman» оценку 4,0, то, умножая число на пересечении строки «Superman» и столбца «Night» на 4,0, получаем: 4,0 × 0,103 = 0,412.
В строке «Итого» просуммированы коэффициенты подобия и значения в столбцах «О.x» для каждого фильма. Чтобы предсказать мою оценку фильма, достаточно разделить итог для колонки «О.x» на суммарный коэффициент подобия. Так, для фильма «The Night Listener» прогноз моей оценки равен 1,378/0,433 = 3,183.
select
ms.film_id1,
case when sum(ms.pirson_koef)<>0
then
sum(v.vote*ms.pirson_koef)/sum(ms.pirson_koef)
else
0
end
from votes v
join movies_similarity ms on ms.film_id2=v.film_id
where v.user_id=4722023
group by ms.film_id1
order by case when sum(ms.pirson_koef)<>0
then
sum(v.vote*ms.pirson_koef)/sum(ms.pirson_koef)
else
0
end desc
В общем из тех 14 фильмов, что я лайкнул мне посоветовали посмотреть — «Голова-ластик»
Ну что же…думаю этим и займусь) А вы найдите себе фильм на вечер!)
![]()
Автор: Pavel Petropavlov



