Ок, поставил частоту 61 гц. Вгружаю скетч. На екране (использую LCD Nokia 5110) вижу ненормальное поведение программы. Все «замерло». Оказывается — установленный мною делитель, действует также на системный таймер. Функции delay(), milis(), micros() и работает тоже с измененным делителем частоты. Delay(1000) — сделает задержку не на 1 секунду!!! Моя программа выполняется намного дольше, чем задумано. Пришлось ШИМ-у пересаживатся на 3-пин. Его делитель частоты не трогает ситемный таймер.
Автор: dim.medvedev
Дата публикации: 2015-03-11T00:05:00.000-07:00
Здравствуйте посетители и читатели. Перед тем как начну, хочу поздравить всех с наступившим новым 2015 годом и с прошедшими праздниками. Ну и всем удачи и успехов в поисках работы или же просто в работе… так как от нее будет зависеть — то, на сколько Вам сладко придется жить 🙂
Немного напомню, что в моих постах информации из замечательной книги… Сам я в питоне пока не шарю, так как я веб программист который в основном сталкивается с РНР,НТМЛ и т.д. — но в последнее время ЯваСкрипт начинает нравиться… думаю скоро выложить на своем втором блоге — про рнр информацию о том, на сколько нужно шарить, чтоб пройти хотяб на джуниора и немножко выше, а так же я постараюсь создать блог на yii с небольшим обьяснением. Ну и собственно ссылка на мой второй блог — http://phpekurs.blogspot.com/ надеюсь я не буду затягивать со временем выпуска материалов как это бывает с этим блогом. Ну что ж, теперь приступим к теме….
После ознакомления с модулями мы должны поближе рассмотреть понятие квалификации имен. В языке Pythonдля доступа к атрибутам любого объекта используется синтаксис квалификации имени object.attribute.
Квалификация имени в действительности является выражением, возвращаю-щим значение, присвоенное имени атрибута, ассоциированного с объектом.
Например, выражение module2.sys в предыдущем примере возвращает значение атрибута sys в объекте module2. Точно так же, если имеется встроенный объект списка L, выражение L.append вернет метод append, ассоциированный с этим списком.
Итак, какую роль играет квалификация имен атрибутов с точки зрения правил, рассмотренных нами в главе 17? В действительности – никакую: это совер-шенно независимые понятия. Когда вы обращаетесь к именам, квалифицируя их, вы явно указываете интерпретатору объект, атрибут которого требуется получить. Правило LEGB применяется только к кратким, неполным именам. Ниже приводятся принятые правила: Простые переменные Использование краткой формы имени, например X, означает, что будет про-изведен поиск этого имени в текущих областях видимости (следуя правилу LEGB).
Квалифицированные имена Имя X.Yозначает, что будет произведен поиск имени X в текущих областях видимости, а затем будет выполнен поиск атрибута Y в объекте X(не в областях видимости).
Квалифицированные пути Имя X.Y.Z означает, что будет произведен поиск имени Y в объекте X, а затем поиск имени Z в объекте X.Y.
Общий случай Квалификация имен применима ко всем объектам, имеющим атрибуты: модулям, классам, расширениям типов на языке Cи так далее.
На этом данный пост заканчивается… не забывайте кликать по рекламке, нужны бабосы на пивасик и немного на жизнь)
Автор: Няшный Человек
Дата публикации: 2015-01-13T21:11:00.000+02:00
В прошлый раз, мы рассмотрели пример одной задачи, которую можно решить методами оптимизации. Напомним, что для применения оптимизации должны выполняться два основных требования: наличие целевой функции и тот факт, что близкие параметры дают близкие решения. Не каждую задачу, удовлетворяющую этим требованиям, можно решить методами оптимизации, но есть неплохие шансы, что попытка применить эти методы даст интересные результаты, о которых вы даже не подозревали.
На этот раз, мы займемся другой задачей, для которой оптимизация просто напрашивается. Общая формулировка такова: распределить ограниченные ресурсы между людьми, у которых есть явно выраженные предпочтения, так чтобы все были максимально счастливы (или, в зависимости от склада характера, минимально недовольны))))
Оптимизация распределения студентов по комнатам
Сегодня мы решим задачу о распределении студентов по комнатам в общежитии с учетом их основного и альтернативного пожеланий. Хотя формулировка довольно специфична, ее можно легко обобщить на похожие задачи, – тот же самый код годится для распределения игроков по столам в онлайновой карточной игре, для распределения ошибок между разработчиками в большом программном проекте и даже для распределения работы по дому между прислугой. Как и раньше, наша цель – собрать информацию об отдельных людях и найти такое сочетание, которое приводит к оптимальному результату.
В нашем примере будет пять двухместных комнат и десять претендующих на них студентов. У каждого студента есть основное и альтернативное пожелание.
# Люди и два пожелания у каждого (основное, второстепенное) prefs = [('Toby', ('Bacchus', 'Hercules')), ('Steve', ('Zeus', 'Pluto')), ('Karen', ('Athena', 'Zeus')), ('Sarah', ('Zeus', 'Pluto')), ('Dave', ('Athena', 'Bacchus')), ('Jeff', ('Hercules', 'Pluto')), ('Fred', ('Pluto', 'Athena')), ('Suzie', ('Bacchus', 'Hercules')), ('Laura', ('Bacchus', 'Hercules')), ('James', ('Hercules', 'Athena'))]
Сразу видно, что удовлетворить основное пожелание каждого человека не удастся, так как на два места в комнате Bacchus имеется три претендента. Поместить любого из этих трех в ту комнату, которую он указал в качестве альтернативы, тоже невозможно, так как в комнате Hercules всего два места.
В приведенном примере общее число вариантов порядка 100 000, то можно перебрать их все и найти оптимальный. Но если комнаты будут четырехместными, то количество вариантов будет исчислять триллионами.
Представление решения
В каждой комнате должно оказаться ровно два студента. Будем считать, что в каждой комнате есть два отсека, то есть всего их в нашем случае будет десять. Каждому студенту по очереди назначается один из незанятых отсеков; первого можно поместить в любой из десяти отсеков, второго – в любой из оставшихся девяти и т. д.
# [9, 8, 7, 6,..., 1] domain = [i for i in xrange(9, 0, -1)]
Целевая функция
Целевая функция работает следующим образом. Создается начальный список отсеков, и уже использованные отсеки из него удаляются. Стоимость вычисляется путем сравнения комнаты, в которую студент помещен, с двумя его пожеланиями. Стоимость не изменяется, если студенту досталась та комната, в которую он больше всего хотел поселиться; увеличивается на 1, если это второе из его пожеланий; и увеличивается на 3, если он вообще не хотел жить в этой комнате.
def dorm_cost(vec): cost=0
# Создаем список отсеков, т.е. первые 2 места - 0 отсек и т.д. slots = [0, 0, 1, 1, 2, 2, 3, 3, 4, 4]
# Цикл по студентам, i - порядковый номер студента for i in xrange(len(vec)): x = int(vec[i]) dorm = dorms[slots[x]] pref = prefs[i][1] print x, '->', slots[x],'->', prefs[i][0], pref, '->', dorm
# Стоимость основного пожелания равна 0, альтернативного – 1 # Если комната не входит в список пожеланий, стоимость увеличивается на 3 if pref[0] == dorm: cost += 0 elif pref[1] == dorm: cost += 1 else: cost += 3
# Удалить выбранны
й отсек # Это самое важное действие тут, # прошу особо обратить на него внимание и учесть, что элементы сдвигаются del slots[x]
return cost
При конструировании целевой функции полезно стремиться к тому, чтобы стоимость идеального решения (в данном случае каждый студент заселился в комнату, которую поставил на первое место в своем списке предпочтений) была равна нулю. В рассматриваемом примере мы уже убедились, что идеальное решение недостижимо, но, зная о том, что его стоимость равна нулю, можно оценить, насколько мы к нему приблизились. У этого правила есть еще одно достоинство – алгоритм оптимизации может прекратить поиск, если уже найдено идеальное решение.
Оптимизация
Всем кто не изучил методы оптимизации в предыдущей статье, бегом изучать!) Хорошим мальчикам и может даже девочкам, импортировать любой из методов и запустить!) Я, для примера, попробую на генетическом алгоритме.
Т.е. не устроило только Lauru и то, учтен был ее 2й вариант)
Вместо вывода
Итак, надеюсь, я показал, что используя одни алгоритмы, но меняя область определения и принцип расчета целевой функции, мы можем решить абсолютно разные оптимизационные задачи!)
Давайте разберемся, как решать задачи со множеством участников, применяя технику стохастической оптимизации. По существу, оптимизация сводится к поиску наилучшего решения задачи путем апробирования различных решений и сравнения их между собой для оценки качества. Обычно оптимизация применяется в тех случаях, когда число решений слишком велико и перебрать их все невозможно.
У методов оптимизации весьма широкая область применения: в физике они используются для изучения молекулярной динамики, в биологии – для прогнозирования белковых структур, а в информатике – для определения времени работы алгоритма в худшем случае. В НАСА методы оптимизации применяют даже для проектирования антенн с наилучшими эксплуатационными характеристиками. Выглядят они так, как ни один человек не мог бы вообразить.
Мы же, для примера, возьмем классическую задачу группового путешествия!) Читать →
Сегодня мы рассмотрим систему полнотекстового поиска, она позволяют искать слова в большом наборе документов и сортируют результаты поиска по релевантности найденных документов запросу. Алгоритмы полнотекстового поиска относятся к числу важнейших среди алгоритмов коллективного разума. Новые идеи в этой области помогли сколотить целые состояния. Широко распространено мнение, что своей быстрой эволюцией от академического проекта к самой популярной поисковой машине в мире система Google обязана прежде всего алгоритму ранжирования страниц PageRank.
Что такое поисковая машина
Итак, давайте же создадим здоровую конкуренцию мировым поисковикам!) Статья так же будет полезна начинающим SEO специалистам, т.к. покажет некоторые величины, которые могут влиять на позиции вашего сайта в поиске.
Первый шаг при создании поисковой машины – разработать методику сбора документов. Иногда для этого применяется ползание (начинаем с небольшого набора документов и переходим по имеющимся в них ссылкам), а иногда отправной точкой служит фиксированный набор документов, быть может, хранящихся в корпоративной сети интранет.
Далее собранные документы необходимо проиндексировать. Обычно для этого строится большая таблица, содержащая список документов и вхождений различных слов. В зависимости от конкретного приложения сами документы могут и не храниться в базе данных; в индексе находится лишь ссылка (путь в файловой системе или URL) на их местонахождение
Ну и последний шаг – это, конечно, возврат ранжированного списка документов в ответ на запрос. Имея индекс, найти документы, содержащие заданные слова, сравнительно несложно; хитрость заключается в том, как отсортировать результаты. Можно придумать огромное количество метрик, и недостатков в них.
Итак, для данной задачи нам потребуется DB (PostgreSQL) и Python (библиотека Grab). А за источник индексирования, новостную ленту rambler’а.
Все функции, описаные ниже, у меня являются методами классов, с такой инициализацией:
self.cur = self.conn.cursor() self.cur.execute("set search_path to 'rambler_search'")
self.grab = Grab()
def __del__(self): self.conn.close()
def dbcommit(self): self.conn.commit()
Код паука
Для начала, рассмотрим код функции, которая будет забирать страницу статьи, разбивать ее на текст, вычленяя ссылки и передавать их индексирующим функциям. На вход подается список ссылок, являющихся вхождением для паука.
Эта функция в цикле обходит список страниц, вызывая для каждой функцию addtoindex. Далее она получает все ссылки на данной странице и добавляет их URL в список newpages. В конце цикла newpages присваивается pages, и процесс повторяется.
Эту функцию можно было бы определить рекурсивно, так что при обработке каждой ссылки она вызывала бы сама себя. Но, реализовав поиск в ширину, мы упростим модификацию кода в будущем, позволив пауку ползать непрерывно или сохранять список неиндексированных страниц для последующего индексирования. Кроме того, таким образом мы избегаем опасности переполнить стек.
# Начинаем со списка страниц для индексации # опускаемся в глубину на 2 уровня def crawl(self, pages, depth=2):
try: article_text = '' # текст статьи for paragraph in self.grab.tree.xpath("//p[contains(@class, 'b-article__paragraph')]"): article_text += paragraph.text_content()
self.addtoindex(page, article_text) # записываем в базу текст статьи с индексацией
links = self.grab.tree.xpath("//a") for link in links:
if ('href' in link.attrib): url = urljoin(page, link.attrib['href']).split('#')[0]# делаем полную ссылку и удаляем часть за # если она есть
match = rambler_news_href_pattern.findall(url) if match: url = match[0]
if url[0:4] == 'http' and not self.isindexed(url): newpages[url] = 1
linkText = link.text_content() # текст ссылки self.addlinkref(page, url, linkText) # записываем в базу текст ссылки с индексацией
self.dbcommit()
except Exception, e: print "Could not parse page %s" % page, e
pages = newpages
Построение индекса
Наш следующий шаг – подготовка базы данных для хранения полнотекстового индекса. Я уже говорил, что такой индекс представляет собой список слов, с каждым из которых ассоциировано множество документов, где это слово встречается, и место вхождения слова в документ. В данном примере мы анализируем только текст на странице, игнорируя все нетекстовые элементы. Кроме того, индексируются только сами слова, а все знаки препинания удаляются. Такой метод выделения слов несовершенен, но для построения простой поисковой машины сойдет.
Создание схемы
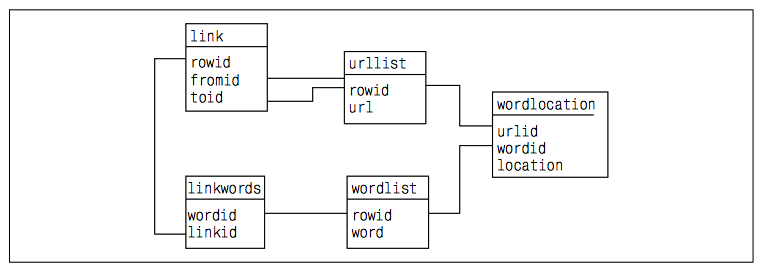
Подождите запускать программу – нужно сначала подготовить базу данных. Схема простого индекса состоит из пяти таблиц. Первая (url_list) – это список проиндексированных URL. Вторая (word_list) – список слов, а третья (word_location) – список мест вхождения слов в документы. В оставшихся двух таблицах хранятся ссылки между документами. В таблице link хранятся идентификаторы двух URL, связанных ссылкой, а в таблице link_words есть два столбца – word_id и link_id – для хранения слов, составляющих ссылку. Вся схема изображена на рисунке ниже. Код запросов приводить не буду, должны ведь и вы поработать)))
Выделение слов на странице
Для решения данной задачи, воспользуемся простейшей функцией. Мы не будем вводить стоп слова, которые не нужно индексировать, а просто введем ограничение на длину слова в 3 символа, тем самым убрав предлоги и другой мусор (хоть и пострадают всякие мелкие слова, типа «мир», «тир», «пир»).
def getwords(html): words = [] for split_str in html.split(): t = re.split("[s;:-_*".,?!()'&#«»]", split_str) words += [a.lower() for a in t if a != '' and len(a) > 3] return words
Добавление в индекс
Теперь мы готовы написать код метода addtoindex. Он вызывает две функции, написанные в предыдущем разделе, чтобы получить список слов на странице. Затем эта страница и все найденные на ней слова добавляются в индекс и создаются ссылки между словами и их вхождениями в документ. В нашем примере адресом вхождения будет считаться номер слова в списке слов.
def addtoindex(self, url, text):
if self.isindexed(url): return # если уже индексирована - пропускаем print 'Indexing %s' % url
# Получаем слова из текста words = getwords(text)
# Получаем id url'а url_id = self.getentryid('url_list', 'url', url)
# Связываем слова с этим урлом for i, word in enumerate(words): # пронумеруем слова word_id = self.getentryid('word_list', 'word', word) self.cur.execute("insert into word_location(url_id, word_id, location) values (%d, %d, %d)" % (url_id, word_id, i)) self.dbcommit()
Хорошо, теперь нужно описать функцию getentryid — возвращающую id записи из бд и isindexed — проверяющую, не индексировали ли мы эту страницу раньше.
# Узнаем id записи в БД, если нет # иначе записываем и возвращаем новый def getentryid(self, table, field, value, createnew=True):
self.cur.execute("select id from %s where %s = '%s'" % (table, field, value)) cur = self.cur.fetchone()
if not cur: # print (table, field, value) self.cur.execute("insert into %s (%s) values ('%s') returning %s.id" % (table, field, value, table)) cur = self.cur.fetchone() self.dbcommit()
return cur[0]
else: return cur[0]
# Возвращаем True, если посещали страницу def isindexed(self, url): self.cur.execute("select id from url_list where url = '%s'" % url) u = self.cur.fetchone()
if u: # Проверяем, что паук посещал страницу self.cur.execute("select count(1) from word_location where url_id = %d" % u[0]) v = self.cur.fetchone()
if v[0]: return True
return False
Последняя функция, необходимая нам для начала индексирования — это addlinkref. Как следует из ее названия, она заносит ссылки и слова из которых они состоят к нам в БД.
Ну что же, на этом этапе мы можем запустить паука и создать базу данных)
Запросы
Теперь, когда у нас есть материал, с которым можно работать, необходимо написать сам поисковик. Начнем мы с мал
ого, грубого поиска, по абсолютному вхождению фразы в новость.
Таблица word_location обеспечивает простой способ связать слова с документами, так что мы можем легко найти, какие страницы содержат данное слово. Однако поисковая машина была бы довольно слабой, если бы не позволяла задавать запросы с несколькими словами. Чтобы исправить это упущение, нам понадобится функция, которая принимает строку запроса, разбивает ее на слова и строит SQL-запрос для поиска URL тех документов, в которые входят все указанные слова.
Данная функция всего лишь создает строгий JOIN, типа такого:
SELECT wl0.url_id, wl0.location, wl1.location FROM word_location wl0 JOIN word_location wl1 ON wl0.url_id = wl1.url_id WHERE wl0.word_id = 2734 and wl1.word_id = 2698
В результате, получаем список кортежей и список с id слов. Каждый кортеж — это сто список вида (id новости, позиция 1го слова, позиция 2го слова…)
Ранжирование по содержимому
Итак, худо-бедно, но мы научились искать по индексу. Однаковозвращаем мы их в том порядке, в котором они посещались пауком. Чтобы решить эту проблему, необходимо как-то присвоить страницам ранг относительно данного запроса и уметь возвращать их в порядке убывания рангов.
В этом разделе мы рассмотрим несколько способов вычисления ранга на основе самого запроса и содержимого страницы, а именно:
Частота слов
Количество вхождений в документ слова, указанного в запросе, помогает определить степень релевантности документа.
Расположение в документе
Основная тема документа, скорее всего, раскрывается ближе к его началу.
Расстояние между словами
Если в запросе несколько слов, то они должны встречаться в документе рядом.
Самые первые поисковые машины (кстати rambler.ru) часто работали только с подобными метриками и тем не менее давали пристойные результаты. Давайте добавим следующие методы:
# Функция, которая взвешивает результаты def get_scored_list(self, rows, word_ids):
total_scores = {row[0]: 0 for row in rows}
if rows: # Список весовых функций weight_functions = [ ]
for (weight, scores) in weight_functions: for url in total_scores: total_scores[url] += weight * scores[url]
return total_scores
# Возвращает полный урл по id def get_url_name(self, url_id):
self.cur.execute("select url from url_list where id = %d" % url_id)
return self.cur.fetchone()[0]
# Основная функция поиска def search(self, search_sentence):
ranked_scores = [(score, url) for (url, score) in scores.items()] ranked_scores.sort() ranked_scores.reverse()
for (score, url_id) in ranked_scores[0:10]: print '%ft%s' % (score, self.get_url_name(url_id))
return word_ids, [r[1] for r in ranked_scores[0:10]]
Наиболее важна здесь функция get_scored_list, код которой мы будем постепенно уточнять. По мере добавления функций ранжирования мы будем вводить их в список weight_functions и начнем взвешивать полученные результаты.
Функция нормализации
Все рассматриваемые ниже функции ранжирования возвращают словарь, в котором ключом является идентификатор URL, а значением – числовой ранг. Иногда лучшим считается больший ранг, иногда – меньший. Чтобы сравнивать результаты, получаемые разными методами, необход
имо как-то нормализовать их, то есть привести к одному и тому же диапазону и направлению. Функция нормализации принимает на входе словарь идентификаторов и рангов и возвращает новый словарь, в котором идентификаторы те же самые, а ранг находится в диапазоне от 0 до 1. Ранги масштабируются по близости к наилучшему результату, которому всегда припи- сывается ранг 1. От вас требуется лишь передать функции список рангов и указать, какой ранг лучше – меньший или больший:
if smallIsBetter: minscore = min(scores.values()) return {u: float(minscore)/max(vsmall, l) for (u,l) in scores.items()}
else: maxscore = max(scores.values()) if maxscore == 0: maxscore = vsmall return {u: float(c)/maxscore for (u,c) in scores.items()}
return scores
Отлично! Пора заняться весовыми функциями, для которых мы и придумали эту нормализацию.
Весовые функции
Частота слов
Метрика, основанная на частоте слов, ранжирует страницу исходя из того, сколько раз в ней встречаются слова, упомянутые в запросе. Если я выполняю поиск по слову python, то в начале списка скорее получу страницу, где это слово встречается много раз, а не страницу о музыканте, который где-то в конце упомянул, что у него дома живет питон.
def frequency_score(self, rows):
counts = {row[0]:0 for row in rows} for row in rows: counts[row[0]] += 1
return self.normalize_scores(counts)
Чтобы активировать ранжирование документов по частоте слов, измените строку функции get_scored_list, где определяется список weight_functions, следующим образом:
Еще одна простая метрика для определения релевантности страницы запросу – расположение поисковых слов на странице. Обычно, если страница релевантна поисковому слову, то это слово расположено близко к началу страницы, быть может, даже находится в заголовке.
def location_score(self, rows):
locations = {} for row in rows: loc = sum(row[1:]) if locations.has_key(row[0]): if loc < locations[row[0]]: locations[row[0]] = loc else: locations[row[0]] = loc
Если запрос содержит несколько слов, то часто бывает полезно ранжировать результаты в зависимости от того, насколько близко друг к другу встречаются поисковые слова. Как правило, вводя запрос из нескольких слов, человек хочет найти документы, в которых эти слова концептуально связаны. Рассматриваемая метрика допускает изменение порядка и наличие дополнительных слов между поисковыми.
def distance_score(self, rows):
mindistance = {}
# Если только 1 слово, любой документ выигрывает if len(rows[0]) <= 2: return {row[0]: 1.0 for row in rows}
mindistance = {}
for row in rows: dist = sum([abs(row[i]-row[i-1]) for i in xrange(2, len(row))])
if mindistance.has_key(row[0]): if dist < mindistance[row[0]]: mindistance[row[0]] = dist else: mindistance[row[0]] = dist
Все обсуждавшиеся до сих пор метрики ранжирования были основаны на содержимом страницы. Часто результаты можно улучшить, приняв во внимание, что говорят об этой странице другие, а точнее те сайты, на которых размещена ссылка на нее. Особенно это полезно при индексировании страниц сомнительного содержания или таких, которые могли быть созданы спамерами, поскольку маловероятно, что на такие страницы есть ссылки с настоящих сайтов.
Простой подсчет ссылок
Простейший способ работы с внешними ссылками заключается в том, чтобы подсчитать, сколько их ведет на каждую страницу, и использовать результат в качестве метрики. Так обычно оцениваются научные работы; считается, что их значимость тем выше, чем чаще их цитируют.
def inbound_link_score(self, rows):
unique_urls = {row[0]: 1 for row in rows} inbound_count = {}
for url_id in unique_urls: self.cur.execute('select count(*) from link where to_id = %d' % url_id) inbound_count[url_id] = self.cur.fetchone()[0]
return self.normalize_scores(inbound_count)
Описанный алгоритм трактует все внешние ссылки одинаково, но такой уравнительный подход открывает возможность для манипулирования, поскольку кто угодно может создать несколько сайтов, указывающих на страницу, ранг которой он хочет поднять. Также возможно, что людям более интерес
Модули будут, вероятно, более понятны, если представлять их, как простые пакеты имен, – то есть место, где определяются переменные, которые должны быть доступны остальной системе. С технической точки зрения каждому модулю соответствует отдельный файл, и интерпретатор создает объект модуля, содержащий все имена, которым присвоены какие-либо значения в файле модуля. Проще говоря, модули – это всего лишь пространства имен (места, где создаются имена), и имена, находящиеся в модуле, называются его атрибутами.В данной тематике мы разберем как работает этот механизм.
Файлы создают пространства имен
Итак, как же файлы трансформируются в пространства имен? Суть в том, что каждое имя, которому присваивается некоторое значение на верхнем уровне файла модуля (то есть не вложенное в функции или в классы), превращается в атрибут этого модуля.
Например, операция присваивания, такая как X = 1, на верхнем уровне модуля M.py превращает имя X в атрибут модуля M, обратиться к которому из-за пределов модуля можно как M.X. Кроме того, имя X становится глобальной переменной для программного кода внутри M.py, но нам необходимо более формально объяснить понятия загрузки модуля и областей видимости, чтобы понять, почему:
• Инструкции модуля выполняются во время первой попытки импорта. Когда модуль импортируется в первый раз, интерпретатор Python создает пустой объект модуля и выполняет инструкции в модуле одну за другой, от начала файла до конца.
• Операции присваивания, выполняемые на верхнем уровне, создают атрибуты модуля. Во время импортирования инструкции присваивания, выполняемые на верхнем уровне файла и не вложенные в инструкции def или class (например, =, def), создают атрибуты объекта модуля – при присваивании имена сохраняются в пространстве имен модуля.
• Доступ к пространствам имен модулей можно получить через атрибут __dict__ или dir(M). Пространства имен модулей, создаваемые операцией импортирования, представляют собой словари – доступ к ним можно получить через встроенный атрибут __dict__, ассоциированный с модулем, и с помощью функции dir. Функция dir – это примерный эквивалент отсортированного списка ключей атрибута __dict__, но она включает унаследованные имена классов, может возвращать не полный список и часто изменяется от версии к версии.
• Модуль – это единая область видимости (локальная является глобальной). Как мы видели в главе 17, имена на верхнем уровне модуля подчиняются тем же правилам обращения/присваивания, что и имена в функциях, только в этом случае локальная область видимости совпадает с глобальной (точнее, они следуют тому же правилу LEGB поиска в областях видимости, с которым мы познакомились в главе 17, только без уровней поиска L и E).
Но в модулях область видимости модуля после загрузки модуля превращается в атрибут-словарь объекта модуля. В отличие от функций (где локальное пространство имен существует только во время выполнения функции), область видимости файла модуля превращается в область видимости атрибутов объекта модуля и никуда не исчезает после выполнения операции импортирования.
Ниже эти понятия демонстрируются в программном коде. Предположим, мы
создаем в текстовом редакторе следующий файл модуля с именем module2.py:
Print(‘starting to load…’)
import sys
name = 42
def func(): pass
class klass: pass
print(‘done loading.’)
Когда модуль будет импортироваться в первый раз (или будет запущен как программа), интерпретатор выполнит инструкции модуля от начала до конца. В ходе операции импортирования одни инструкции создают имена в пространстве имен модуля, а другие выполняют определенную работу. Например, две инструкции print в этом файле выполняются во время импортирования:
>>> imp
ort module2
starting to load…
done loading.
Но как только модуль будет загружен, его область видимости превратится в пространство имен атрибутов объекта модуля, который возвращает инструкция import. После этого можно обращаться к атрибутам в этом пространстве
имен, дополняя их именем вмещающего модуля:
>>> module2.sys
>>> module2.name
42
>>> module2.func
>
>>> module2.klass
Здесь именам sys, name, func и klass были присвоены значения во время выполнения инструкций модуля, поэтому они стали атрибутами после завершения операции импортирования. О классах мы будем говорить в шестой части книги, но обратите внимание на атрибут sys – инструкции import действительно присваивают объекты модулей именам, а любая операция присваивания на
верхнем уровне файла создает атрибут модуля.
Внутри интерпретатора пространства имен хранятся в виде объектов словарей. Это самые обычные объекты словарей с обычными методами. Обратиться к словарю пространства имен модуля можно через атрибут __dict__ модуля (не забудьте обернуть вызов этого метода вызовом функции list – в Python 3.0 он возвращает объект представления!):
Имена, которые были определены в файле модуля, становятся ключами внутри словаря, таким образом, большинство имен здесь отражают операции
присваивания на верхнем уровне в файле. Однако интерпретатор Python добавляет в пространство имен модуля еще несколько имен, например __file__ содержит имя файла, из которого был загружен модуль, а __name__ – это имя, под которым модуль известен импортерам (без расширения .py и без пути к каталогу).
Автор: Няшный Человек
Дата публикации: 2014-08-16T04:04:00.000+03:00