Шаблоны
В данном разделе напишем несколько готовых шаблонов, которые можно взять за основы при написании своего сценария. Читать
В данном разделе напишем несколько готовых шаблонов, которые можно взять за основы при написании своего сценария. Читать
Представьте, что у вас есть веб-сервер, работающий вне вашего кластера Kubernetes, который вы хотите интегрировать в свой контроллер ingress. Существует несколько причин, по которым вы можете захотеть это сделать:
Оказывается, на самом деле это довольно просто настроить.
В этом примере мы предполагаем, что внешний веб-сайт размещен на IP-адресе 10.20.30.40 и прослушивается через порт 8080. Обратите внимание, что для этого примера мы предполагаем, что порт 8080 обслуживает незашифрованный простой HTTP.
Также убедитесь, что вы правильно настроили свой брандмауэр и ограничили IP-адрес, по которому этот веб-сервер принимает подключения. Вы же не хотите открывать незашифрованный порт 8080 для всего мира.
Прежде всего, вам необходимо создать сервис с конечной точкой:
service.yaml
apiVersion: v1
kind: Service
metadata:
name: <my-external-service>
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
clusterIP: None
type: ClusterIP
---
apiVersion: v1
kind: Endpoints
metadata:
name: <my-external-service>
subsets:
- addresses:
- ip: 10.20.30.40
ports:
- name: http
port: 8080
protocol: TCP
По сути, мы сообщаем Kubernetes, что определяем службу, которая связана с внешним IP-адресом, прослушивающим определенный порт. Мы используем IP-адрес, чтобы избежать DNS-запросов, задействованных в этой настройке.
Загрузка его в кластер выполняется следующим образом:
$ kubectl apply -f service.yaml
Для завершения настройки мы добавляем сервис в определение ingress точно так же, как мы бы поступили с обычным сервисом:
ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress
annotations:
nginx.ingress.kubernetes.io/proxy-read-timeout: "3600"
nginx.ingress.kubernetes.io/proxy-send-timeout: "3600"
kubernetes.io/ingress.class: nginx
certmanager.k8s.io/cluster-issuer: letsencrypt-prod
spec:
tls:
- hosts:
- <my-domain-name.com>
secretName: letsencrypt-prod
rules:
- host: <my-domain-name.com>
http:
paths:
- backend:
serviceName: <my-external-service>
servicePort: 80
Примените это также, и все готово.
$ kubectl apply -f ingress.yaml
Если вы сейчас перейдете на https://my-domain-name.com, должно появиться правильное содержимое.
Источник: https://www.yellowduck.be/posts/k8s-proxy-an-external-site
Сначала необходимо убедиться, что в качестве источника пользователей выбрана внутренняя БД дженкинса.
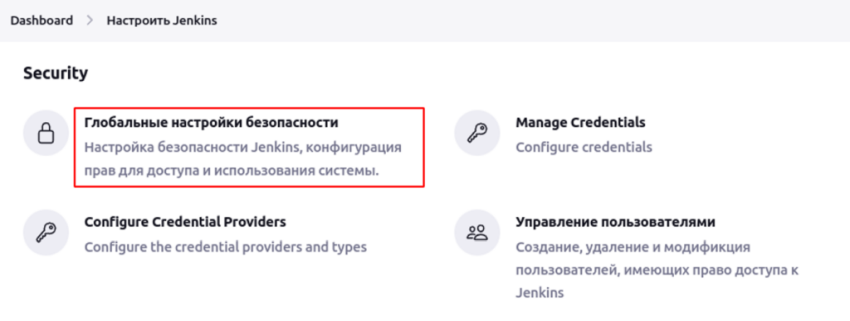
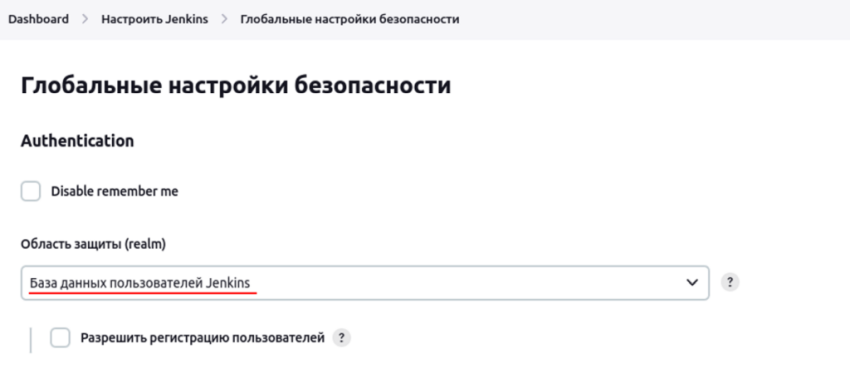
Далее идём в раздел Управление пользователями.
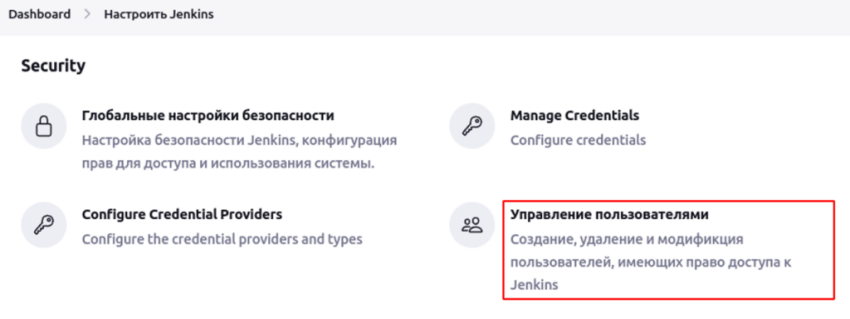
Там будет кнопка “Создать пользователя”
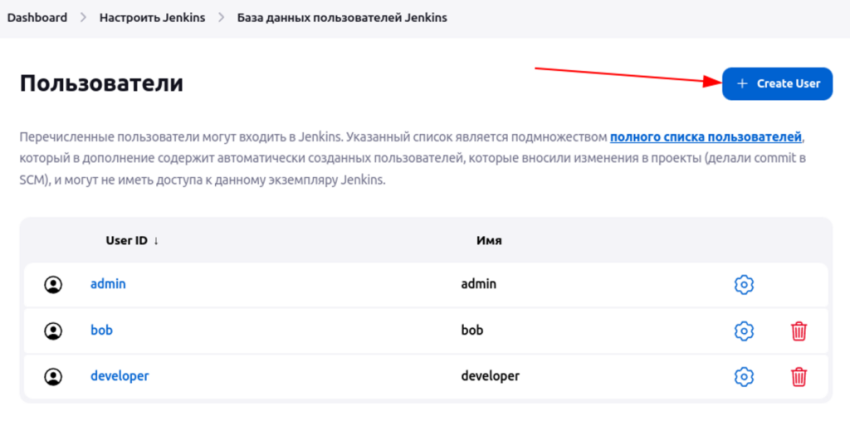
Должен быть установлен плагин Matrix Authorization Strategy. Он устанавливается в числе рекомендованных плагинов если вы выбрали этот путь в мастере установки дженкинса.
Этот плагин добавляет в разделе с настройками безопасности таблицу, где столбцы это права, а строки это пользователи.
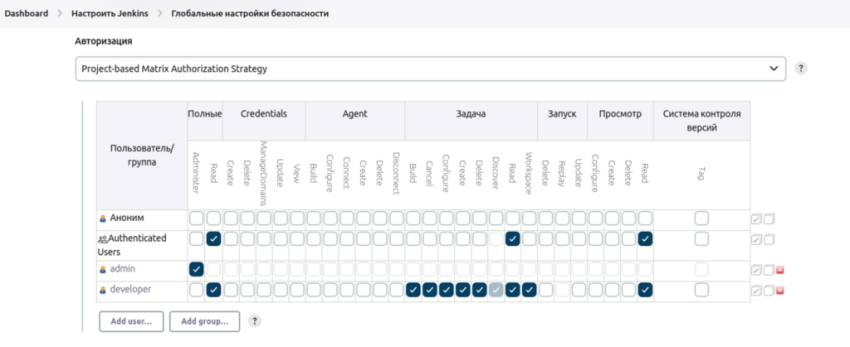
Важно: при выборе этого способа авторизации не забудьте сразу выдать пользователю admin полные права. Если всё же у вас пропал доступ к настройке системы, то его можно вернуть отредактировав файл /var/jenkins_home/config.xml. Необходимо в строчке <useSecurity>true</useSecurity> написать false и перезапустить дженкинс.
Nexus является популярным менеджером репозиториев (repository manager). Он используется для хранения артефактов или прокси, т.е. всё что выкачивается через него, сохраняется в нём.
yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel createrepo
wget http://download.sonatype.com/nexus/3/latest-unix.tar.gz
tar xvf latest-unix.tar.gz -C /opt/
ln -s /opt/nexus-*/ /opt/nexus
useradd -m -r -s /bin/false nexus
chown -R nexus:nexus /opt/nexus-* /opt/sonatype-work /opt/nexus
vim /opt/nexus/bin/nexus.rc
run_as_user="nexus"
vim /etc/systemd/system/nexus.service
[Unit]
Description=nexus service
After=network.target
[Service]
Type=forking
ExecStart=/opt/nexus/bin/nexus start
ExecStop=/opt/nexus/bin/nexus stop
User=nexus
Restart=on-abort
[Install]
WantedBy=multi-user.target
Уменьшить количество потребляемой оперативной памяти:
vim /var/nexus/nexus-3.19.1-01/bin/nexus.vmoptions
меняем
-Xms2703m
-Xmx2703m
на
-Xms512m
-Xmx512m
systemctl daemon-reload && systemctl enable nexus
systemctl start nexus && systemctl status nexus
WEB-интерфейс
http://<Nexus-server-ip-address>:8081
для авторизации в качестве логина используйте
admin
пароль можно посмотреть тут:
cat /opt/sonatype-work/nexus3/admin.password
также по умолчанию пароль может быть следующим:
Login: admin
Password: admin123
Настройка ротации логов Nexus
cat /etc/logrotate.d/nexus
/opt/sonatype-work/nexus3/log/*.log {
daily
dateext
copytruncate
missingok
rotate 3
compress
delaycompress
notifempty
}
отметим что в директории в которой установлен nexux должно быть не меньше 5Gb.
стартуем
systemctl start nexus
добавляем в автозапуск
systemctl enable nexus
логи хранятся тут:
/opt/sonatype-work/nexus3/log/
для удобства создадим симлинк
mkdir /var/log/nexus
ln -s /opt/sonatype-work/nexus3/log/ /var/log/nexus/
========================================================================
не забываем включить анонимный доступ чтоб реп работал:
Anonymous — > Allow anonymous users to access the server

Далее переходим к списку репозиториев:
Создаём новый proxy репозиторий (create reposytory — > yum(proxy))
Name: test-repo-epel
ProxyRemote storage: http://mirror.centos.org/centos-7/7/os/x86_64/
после чего нажимаем create reposytory
Создаём ещё один proxy репозиторий (create reposytory — > yum(proxy))
Name: yum-centos-7-repo_updates
Remote storage: http://mirror.centos.org/centos-7/7/updates/x86_64/
Создаём yum group
Name: yum-repo-group
добавляем в него 2 созданных нами прокси и сохраняем.
всё, репозиторий создан.
Теперь чтобы использовать его необходимо пройти в раздел:
reposytory -> Repositories -> yum-repo-group
получаем следующую ссылку:
http://192.168.1.171:8081/repository/yum-repo-group/
и на целевой тачке создаем репозиторий:
cat /etc/yum.repos.d/Centos-7-Nexus.repo
[Centos-7-Nexus]
baseurl = http://192.168.1.177:8081/repository/yum-repo-group/
gpgcheck = 1
enabled=1
gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
name = Centos-Nexus
сохраняем и проверяем.
=======================================================================
создаём docker(hosted):
repositories -> create repository -> docker(hosted)
Name: docker-private
type hosted
http: 8083
можно ещё добавить для https
Нажимаем save
создаём docker(proxy):
repositories -> create repository -> docker(proxy)
Name: docker-hub
type proxy
remote storage: https://registry-1.docker.io
docker index: выбирем Use Docker Hub
Нажимаем save
создаём docker(group):
repositories -> create repository -> docker(group)
Name: docker-group
http:8082
и добавляем в него docker-private docker-hub
Нажимаем save.
На целевой тачке добавляем:
cat /etc/docker/daemon.json
{
"insecure-registries": ["192.168.1.177:8081","192.168.1.177:8082","192.168.1.177:8083"],
"experimental": true
}
Далее необходимо залогиниться в nexus репозитории:
docker login http://192.168.1.177:8082/repository/docker-group
!!! ВАЖНО. Если вы используете прокси, то необходимо убрать его, перезапустить демон, и рестартануть docker(reload не хватит):
mv /etc/systemd/system/docker.service.d/http-proxy.conf /home/
systemctl daemon-reload
systemctl restart docker
проверить, что прокся не задействована вы можете с помощью команды:
docker info
в её выводе не должно быть прокси.
При логине в 192.168.1.177:8082/repository/docker-group в качестве логина и пароля надо указывать или тех пользователей которые вы создали в nexus или главного пользователя с которым вы авторизовались в nexus admin admin123
чтобы выкачать образ необходимо указывать адрес источника, т.е.:
docker pull 192.168.1.177:8082/httpd
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
192.168.1.177:8082/nginx latest e445ab08b2be 37 hours ago 126MB
192.168.1.177:8082/httpd latest ee39f68eb241 12 days ago 154MB
переименуем наш образ и загрузим его в nexus:
docker tag 192.168.1.177:8082/nginx 192.168.1.177:8082/nginx33:3
docker push 192.168.1.177:8082/nginx33:3
========================================
чтобы использовать nexus как прокси для скачивания обновлений или докер образов надо пройти в:
System -> HTTP -> HTTP(s) Proxy
указываем ip и port нашего прокси, также можем задать список адресов которые исключаются из прокси(т.е. обращаясь к ним запрос не пойдёт через проксю)
Hosts to exclude from HTTP/HTTPS proxy
и нажимаем saveне забываем логиниться
docker login 192.168.1.177:8082
=========================================
чтобы использовать nexus как прокси для установки через pip
надо создать репозиторий:
Create repository — pypi (proxy) задаём имя (произвольное) в качестве remote storage указываем
https://pypi.org
сохраняем, далее создаём pypi(group) задаём имя (произвольное) добавляем в группу ранее созданый прокси репозиторий и сохраняем
получаем ссылку группы:
http://192.168.1.177:8082/repository/pypi-repo/
далее на целевой тачке создаём файл pip.conf
cat /etc/pip.conf
[global]
index = http://192.168.1.177:8082/repository/pypi-repo/pypi
index-url = http://192.168.1.177:8082/repository/pypi-repo/simple
и запускаем установку так:
pip install pypi-install --trusted-host 192.168.1.177
Источник: https://sidmid.ru/nexus-install-and-settings/
Docker Compose — это инструмент, который позволяет определить и запускать много-контейнерные приложения с помощью файла конфигурации в YAML-формате. Он упрощает и автоматизирует процесс разворачивания и управления множеством Docker-контейнеров.
Docker Compose представляет собой инструмент, разработанный Docker Inc. и используется для управления несколькими контейнерами Docker как единого приложения. Это позволяет легко запускать, масштабировать и обслуживать многоконтейнерные приложения в любой среде, где установлен Docker.
Одной из основных причин, по которой Docker Compose стал так популярен в сфере DevOps, является его способность создавать многоконтейнерные приложения в несколько строк кода. Например, вы можете определить все необходимые контейнеры в файле docker-compose.yml и запустить их одной командой.
Это позволяет разработчикам быстро и эффективно тестировать, разворачивать и масштабировать свои приложения.
Одной из главных особенностей Docker Compose является возможность использования переменных окружения, которые могут быть использованы в файле конфигурации. Это позволяет управлять настройками контейнеров извне, что облегчает настройку и поддержку много-контейнерных приложений.
Кроме того, Docker Compose позволяет определять зависимости между контейнерами, что обеспечивает правильный порядок запуска. Например, если ваше приложение требует базы данных, то вы можете определить эту зависимость в файле конфигурации, и Docker Compose автоматически запустит контейнер с базой данных перед запуском вашего приложения.
Подводя итог, Docker Compose является мощным инструментом для управления много-контейнерными приложениями.
Kubernetes позволяет автоматически масштабировать приложения (то есть Pod в развертывании или ReplicaSet) декларативным образом с использованием спецификации Horizontal Pod Autoscaler.
По умолчанию критерий для автоматического масштабирования — метрики использования CPU (метрики ресурсов), но можно интегрировать пользовательские метрики и метрики, предоставляемые извне.
Вместо горизонтального автомасштабирования подов, применяется Kubernetes Event Driven Autoscaling (KEDA) — оператор Kubernetes с открытым исходным кодом. Он изначально интегрируется с Horizontal Pod Autoscaler, чтобы обеспечить плавное автомасштабирование (в том числе до/от нуля) для управляемых событиями рабочих нагрузок. Код доступен на GitHub.
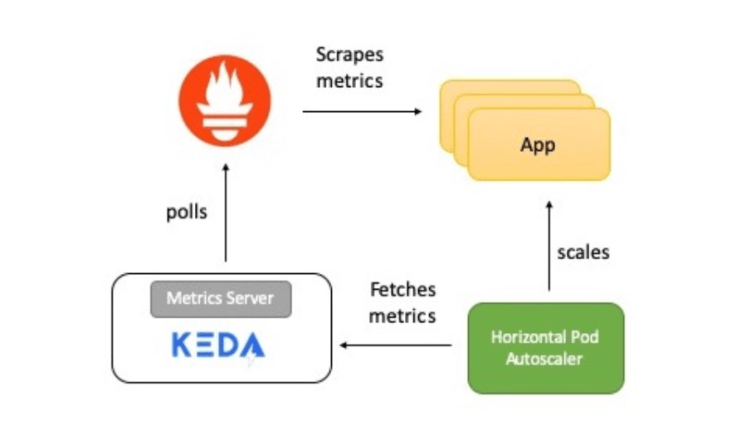
На схеме — краткое описание того, как все работает:
Теперь подробно расскажу о каждом элементе.
Prometheus — набор инструментов для мониторинга и оповещения систем с открытым исходным кодом, часть Cloud Native Computing Foundation. Собирает метрики из разных источников и сохраняет в виде данных временных рядов. Для визуализации данных можно использовать Grafana или другие инструменты визуализации, работающие с API Kubernetes.
KEDA поддерживает концепцию скейлера — он действует как мост между KEDA и внешней системой. Реализация скейлера специфична для каждой целевой системы и извлекает из нее данные. Затем KEDA использует их для управления автоматическим масштабированием.
Скейлеры поддерживают нескольких источников данных, например, Kafka, Redis, Prometheus. То есть KEDA можно применять для автоматического масштабирования развертываний Kubernetes, используя в качестве критериев метрики Prometheus.
Скейлер действует как мост между KEDA и внешней системой, из которой нужно получать метрики. ScaledObject — настраиваемый ресурс, его необходимо развернуть для синхронизации развертывания с источником событий, в данном случае с Prometheus.
ScaledObject содержит информацию о масштабировании развертывания, метаданные об источнике события (например, секреты для подключения, имя очереди), интервал опроса, период восстановления и другие данные. Он приводит к соответствующему ресурсу автомасштабирования (определение HPA) для масштабирования развертывания.
Когда объект ScaledObject удаляется, соответствующее ему определение HPA очищается.
Вот определение ScaledObject для нашего примера, в нем используется скейлер Prometheus:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: default
labels:
deploymentName: go-prom-app
spec:
scaleTargetRef:
deploymentName: go-prom-app
pollingInterval: 15
cooldownPeriod: 30
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: prometheus
metadata:
serverAddress:
http://prometheus-service.default.svc.cluster.local:9090
metricName: access_frequency
threshold: '3'
query: sum(rate(http_requests[2m]))
Учтите следующие моменты:
Можно установить minReplicaCount равным нулю. В этом случае KEDA активирует развертывание с нуля до единицы, а затем предоставляет HPA для дальнейшего автоматического масштабирования. Возможен и обратный порядок, то есть масштабирование от единицы до нуля. В примере мы не выбрали ноль, поскольку это HTTP-сервис, а не система по запросу.
Пороговое значение используют в качестве триггера для масштабирования развертывания. В нашем примере запрос PromQL sum(rate (http_requests [2m])) возвращает агрегированное значение скорости HTTP-запросов (количество запросов в секунду), ее измеряют за последние две минуты.
Поскольку пороговое значение равно трем, значит, будет один под, пока значение sum(rate (http_requests [2m])) меньше трех. Если же значение возрастает, добавляется дополнительный под каждый раз, когда sum(rate (http_requests [2m])) увеличивается на три. Например, если значение от 12 до 14, то количество подов — четыре.
Теперь давайте попробуем настроить!
Вы можете развернуть KEDA несколькими способами, они перечислены в документации. Я использую монолитный YAML:
[root@kub-master-1 ~]# wget https://github.com/kedacore/keda/releases/download/v2.1.0/keda-2.1.0.yaml
[root@kub-master-1 ~]# kubectl apply -f keda-2.1.0.yaml
ну или можно установить через helm
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
kubectl create namespace keda
helm install keda kedacore/keda —namespace keda
я ставил через монолитный файл.
проверим что всё поднялось:
[root@kub-master-1 ~]# kubectl get all -n keda
NAME READY STATUS RESTARTS AGE
pod/keda-metrics-apiserver-57cbdb849f-w7rfg 1/1 Running 0 70m
pod/keda-operator-58cb545446-5rblj 1/1 Running 0 70m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/keda-metrics-apiserver ClusterIP 10.100.134.31 <none> 443/TCP,80/TCP 70m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/keda-metrics-apiserver 1/1 1 1 70m
deployment.apps/keda-operator 1/1 1 1 70m
NAME DESIRED CURRENT READY AGE
replicaset.apps/keda-metrics-apiserver-57cbdb849f 1 1 1 70m
replicaset.apps/keda-operator-58cb545446 1 1 1 70m
создаём namespace
kubectl create ns my-site
запускаем обычное приложение например apache:
[root@kub-master-1 ~]# cat my-site.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment-apache
namespace: my-site
spec:
replicas: 1
selector:
matchLabels:
app: apache # по вот этому лейблу репликасет цепляет под
# тут описывается каким мокаром следует обновлять поды
strategy:
rollingUpdate:
maxSurge: 1 # указывает на какое количество реплик можно увеличить
maxUnavailable: 1 # указывает на какое количество реплик можно уменьшить
#т.е. в одно время при обновлении, будет увеличено на один (новый под) и уменьшено на один (старый под)
type: RollingUpdate
## тут начинается описание контейнера
template:
metadata:
labels:
app: apache # по вот этому лейблу репликасет цепляет под
spec:
containers:
- image: httpd:2.4.43
name: apache
ports:
- containerPort: 80
# тут начинаются проверки по доступности
readinessProbe: # проверка готово ли приложение
failureThreshold: 3 #указывает количество провалов при проверке
httpGet: # по сути дёргает курлом на 80 порт
path: /
port: 80
periodSeconds: 10 #как часто должна проходить проверка (в секундах)
successThreshold: 1 #сбрасывает счётчик неудач, т.е. при 3х проверках если 1 раз успешно прошло, то счётчик сбрасывается и всё ок
timeoutSeconds: 1 #таймаут на выполнение пробы 1 секунда
livenessProbe: #проверка на жизнь приложения, живо ли оно
failureThreshold: 3
httpGet:
path: /
port: 80
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
initialDelaySeconds: 10 #означает что первую проверку надо сделать только после 10 секунд
# тут начинается описание лимитов для пода
resources:
requests: #количество ресурсов которые резервируются для pod на ноде
cpu: 60m
memory: 200Mi
limits: #количество ресурсов которые pod может использовать(верхняя граница)
cpu: 120m
memory: 300Mi
[root@kub-master-1 ~]# cat my-site-service.yaml
---
apiVersion: v1
kind: Service
metadata:
name: my-service-apache # имя сервиса
namespace: my-site
spec:
ports:
- port: 80 # принимать на 80
targetPort: 80 # отправлять на 80
selector:
app: apache #отправлять на все поды с данным лейблом
type: ClusterIP
[root@kub-master-1 ~]# cat my-site-ingress.yaml
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: my-ingress
namespace: my-site
spec:
rules:
- host: test.ru #тут указывается наш домен
http:
paths: #список путей которые хотим обслуживать(он дефолтный и все запросы будут отпаврляться на бэкенд, т.е. на сервис my-service-apache)
- backend:
serviceName: my-service-apache #тут указывается наш сервис
servicePort: 80 #порт на котором сервис слушает
# path: / все запросы на корень '/' будут уходить на наш сервис
применяем:
[root@kub-master-1 ~]# kubectl apply -f my-site.yaml -f my-site-service.yaml -f my-site-ingress.yaml
проверяем:
[root@kub-worker-1 ~]# curl test.ru
<html><body><h1>It works!</h1></body></html>
[root@kub-master-1 ~]# kubectl get all -n my-site
NAME READY STATUS RESTARTS AGE
pod/my-deployment-apache-859486bd8c-k6bql 1/1 Running 0 20m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/my-service-apache ClusterIP 10.100.255.190 <none> 80/TCP 20m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/my-deployment-apache 1/1 1 1 20m
NAME DESIRED CURRENT READY AGE
replicaset.apps/my-deployment-apache-859486bd8c 1 1 1 20m
будем автоскейлить — для примера по метрике nginx nginx_ingress_controller_requests
запрос в prometheus будет следующий:
sum(irate( nginx_ingress_controller_requests{namespace=»my-site»}[3m] )) by (ingress)*10
т.е. считаем общее количество запросов в неймспейс my-site за 3 минуты
создаём keda сущность:
[root@kub-master-1 ~]# cat hpa-keda.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: my-site
spec:
scaleTargetRef:
name: my-deployment-apache
minReplicaCount: 1 # Optional. Default: 0
maxReplicaCount: 8 # Optional. Default: 100
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-kube-prometheus-prometheus.monitoring.svc.cluster.local:9090
metricName: nginx_ingress_controller_requests
threshold: '100'
query: sum(irate(nginx_ingress_controller_requests{namespace="my-site"}[3m])) by (ingress)*10
тут мы указываем в каком namespace нам запускаться:
namespace: my-site
указываем цель, т.е. наш deployment:
name: my-deployment-apache
задаём минимальное и максимальное количество реплик
minReplicaCount: 1 # значение по умолчанию: 0
maxReplicaCount: 8 # значение по умолчанию: 100
есть ещё 2 стандартные переменные отвечающие за то когда поды будут подыматься и убиваться:
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
указываем адрес нашего prometheus
serverAddress: http://prometheus-kube-prometheus-prometheus.monitoring.svc.cluster.local:9090
адрес идёт в виде сервис.неймспейс.svc.имя_кластера
указываем нашу метрику:
metricName: nginx_ingress_controller_requests
указываем пороговое значение при котором начнётся автоскейлинг:
threshold: ‘100’
и соответственно наш запрос в prometheus:
query:
всё можно применять:
[root@kub-master-1 ~]# kubectl apply -f hpa-keda.yaml
проверяем:
[root@kub-master-1 ~]# kubectl get horizontalpodautoscalers.autoscaling -n my-site
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-prometheus-scaledobject Deployment/my-deployment-apache 0/100 (avg) 1 8 1 68m
[root@kub-master-1 ~]# kubectl get pod -n my-site
NAME READY STATUS RESTARTS AGE
my-deployment-apache-859486bd8c-v59b8 1/1 Running 0 37m
а теперь накрутим запросов:
[root@kub-worker-1 ~]# for i in {1..5000}; do curl test.ru; done
проверяем:
[root@kub-master-1 ~]# kubectl get horizontalpodautoscalers.autoscaling -n my-site
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-prometheus-scaledobject Deployment/my-deployment-apache 34858m/100 (avg) 1 8 7 71m
как видим количество запросов превысило наш лимит и стали создаваться новые поды:
[root@kub-master-1 ~]# kubectl get pod -n my-site
NAME READY STATUS RESTARTS AGE
my-deployment-apache-859486bd8c-6885f 1/1 Running 0 49s
my-deployment-apache-859486bd8c-6mcq4 1/1 Running 0 64s
my-deployment-apache-859486bd8c-cdb6z 1/1 Running 0 64s
my-deployment-apache-859486bd8c-kpwb8 1/1 Running 0 64s
my-deployment-apache-859486bd8c-rmw8d 1/1 Running 0 49s
my-deployment-apache-859486bd8c-v59b8 1/1 Running 0 39m
my-deployment-apache-859486bd8c-xmv28 1/1 Running 0 49s
прекращаем запросы и спустя 5 минут, указанное в переменной cooldownPeriod ненужные поды будут убиты:
[root@kub-master-1 ~]# kubectl get pod -n my-site
NAME READY STATUS RESTARTS AGE
my-deployment-apache-859486bd8c-6885f 0/1 Terminating 0 6m35s
my-deployment-apache-859486bd8c-6mcq4 1/1 Running 0 6m50s
my-deployment-apache-859486bd8c-cdb6z 0/1 Terminating 0 6m50s
my-deployment-apache-859486bd8c-kpwb8 0/1 Terminating 0 6m50s
my-deployment-apache-859486bd8c-rmw8d 0/1 Terminating 0 6m35s
my-deployment-apache-859486bd8c-v59b8 0/1 Terminating 0 44m
my-deployment-apache-859486bd8c-xmv28 0/1 Terminating 0 6m35s
[root@kub-master-1 ~]# kubectl get pod -n my-site
NAME READY STATUS RESTARTS AGE
my-deployment-apache-859486bd8c-6mcq4 1/1 Running 0 7m48s
Источник: https://sidmid.ru/kubernetes-автоскейлинг-приложений-при-помощ/