Экран вашего ПК с Windows 10 черно-белый? Хотите вернуть нормальный цвет экрана? В Windows 10 есть несколько цветных фильтров, которые могли быть активированы по ошибке, или, возможно, кто-то, имеющий доступ к вашему компьютеру, решил вас разыграть. Неважно, как Window 10 должен быть черно-белым, вот как решить эту проблему.
Описание проблемы: Windows 10 черно-белая!
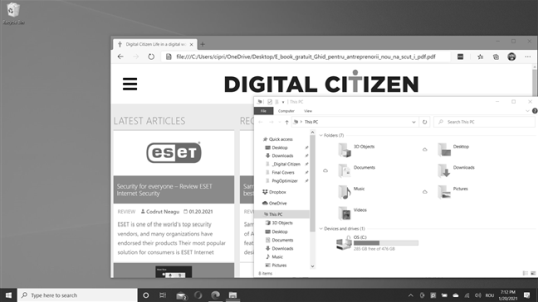
Во время работы на ПК с Windows 10 экран переключался с цветного на черно-белый или оттенки серого, как на скриншоте ниже? Вы не знаете, чем это вызвано, и перезапуск Windows 10 не решает проблему. Также, если вы обновите драйверы и настройки видеокарты, ничего не изменится. Все ваши приложения серые, и на экране отображаются только черный, белый и оттенки серого цвета.
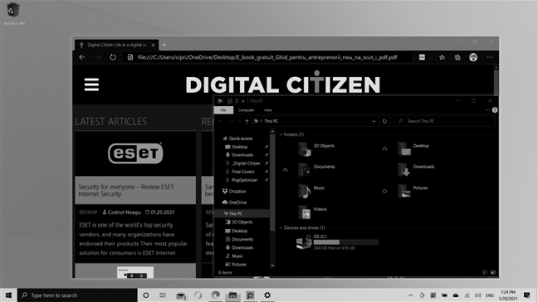
Или экран может выглядеть еще темнее, как на картинке ниже:
Если у вас установлена последняя версия Windows 10, например Windows 10 October 2020 Update, прочтите следующий раздел этого руководства. У нас есть решение, как вернуть нормальный цвет экрана. Если у вас старая версия Windows 10 от 2017 года или более ранняя, прокрутите вниз до последней главы. Если вы не знаете, какая у вас версия Windows 10, вы можете проверить версию Windows 10, сборку ОС, выпуск или тип.
Решение: отключите цветные фильтры Windows 10, чтобы вернуть нормальный цвет экрана
Если у вас более новая версия Windows 10, откройте «Настройки» (Windows + I на клавиатуре) и перейдите в «Легкость доступа».
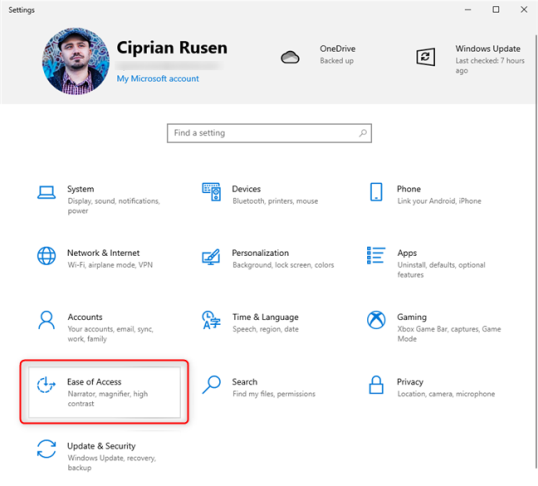
В левом столбце выберите Цветовые фильтры . Справа вы видите цветные фильтры, доступные в Windows 10:
- Инвертированный — меняет цвета и делает фон большинства приложений черным.
- Оттенки серого — серый становится доминирующим цветом для всех фонов приложений. Изображение на экране похоже на первый снимок экрана, которым мы поделились в этом руководстве.
- Инвертированная шкала серого: инвертирует цвета фильтра шкалы серого и делает фон большинства приложений черным, как показано на втором снимке экрана этого руководства.

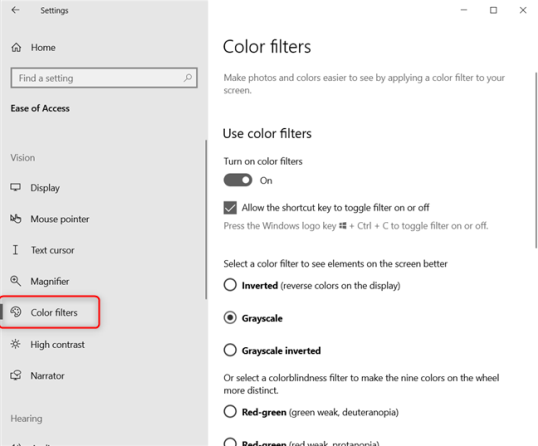
С правой стороны, установите «Включить цветовые фильтры» переключатель Выкл, а также убрав флажок , который говорит: «Разрешить сочетание клавиш для переключения фильтра или отключить.» Это гарантирует, что сочетание клавиш Windows + CTRL + C случайно не включит цветные фильтры, изменив изображение на экране, что могло быть случайностью, которая вызвала всю проблему.
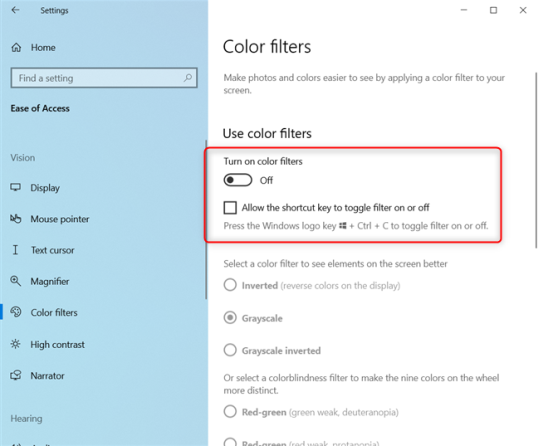
Цвет экрана вернулся к нормальному. Наслаждайтесь использованием Windows 10! 🙂
Если у вас старая версия Windows 10, следуйте этому решению
Microsoft впервые представила эту проблему с цветными фильтрами еще в 2017 году, в Windows 10 Fall Creators Update . Если у вас есть старая версия Windows 10 и настроек приложения не похож на скриншотах разделяемых в предыдущем разделе, попробуйте нажать следующую комбинацию клавиш: Windows + CTRL + C. Он должен немедленно отключить цветной фильтр, который делает вашу Windows 10 черно-белой.
Другой способ решить эту проблему — открыть Настройки и перейти в Легкость доступа.
Слева выберите «Цвет и высокая контрастность». Справа вы видите цветовой фильтр, выбранный по умолчанию: оттенки серого. Посмотрите на переключатель, который говорит «Применить цветовой фильтр» и включите Off.
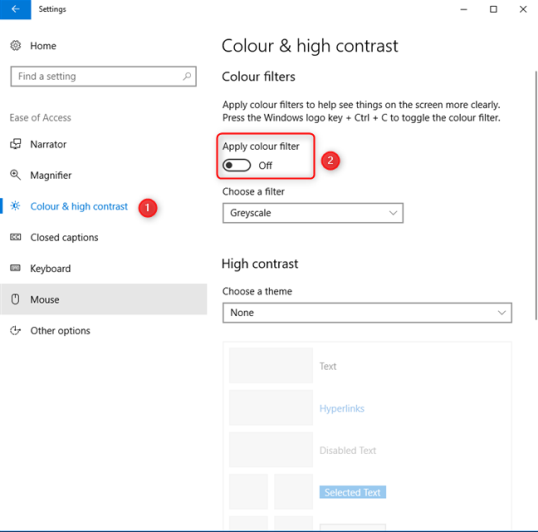
Ваш экран больше не черно-белый.
Почему произошло изменение цвета?
Эта проблема могла возникнуть без вашего осознания, потому что вы нажали сочетание клавиш Windows + CTRL + C и активировали цветной фильтр в градациях серого в Windows 10. Как видите, отключить этот фильтр быстро и легко, и вы можете настроить все так, чтобы эта проблема не повторяется. Перед тем как уйти, оставьте комментарий ниже и сообщите нам, удалось ли нам помочь вам исправить вашу черно-белую Windows 10.