Файлы cookie являются жизненно важной частью Интернета. Без них веб-сайты не позволяли бы вам создавать учетные записи, входить в систему или запоминать свои интересы. Реклама также будет менее актуальной и даже более раздражающей. Однако файлы cookie также могут время от времени вызывать проблемы, поэтому время от времени их следует удалять. Когда это время придет, вы можете удалить отдельные файлы cookie или все файлы cookie сразу. Вот как это все работает в Google Chrome.
Самый быстрый способ удалить все файлы cookie из Google Chrome
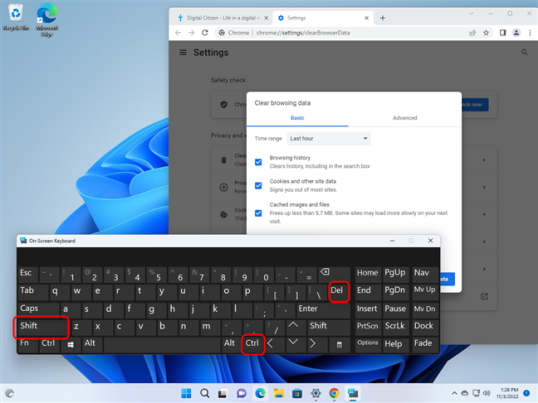
Чтобы удалить все файлы cookie, хранящиеся в Google Chrome, откройте браузер и используйте сочетание клавиш Ctrl+Shift+Delete. Это действие открывает новую вкладку «Настройки» с параметрами «Очистить данные просмотра», отображаемыми посередине.
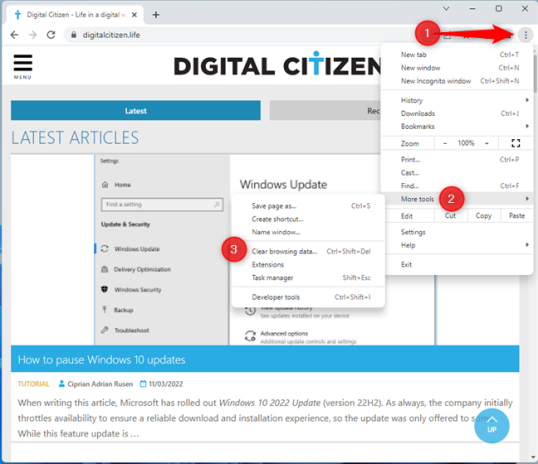
Вы также можете попасть в то же место с помощью мыши: нажмите на три точки в правом верхнем углу (Настройка и управление Google Chrome) и выберите Дополнительные инструменты > Очистить данные браузера.
На вкладке «Основные» всплывающего окна «Очистить данные просмотра» щелкните или коснитесь раскрывающегося списка «Временной диапазон» и выберите «Все время». Если вы хотите удалить только более свежие файлы cookie из Chrome, выберите период, который вам больше подходит.
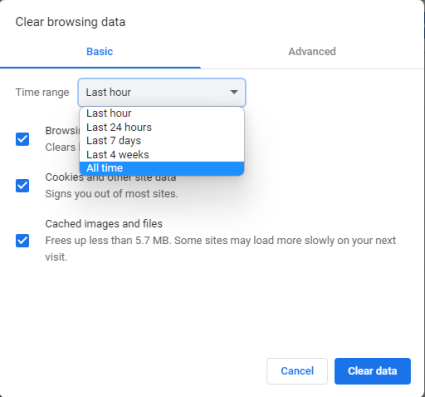
Затем проверьте типы данных просмотра, которые вы хотите удалить:
- История посещенных страниц — очищает все посещенные вами веб-сайты и ключевые слова, которые вы ввели в поле поиска Chrome.
- Файлы cookie и другие данные сайта — это необходимо проверить, если вы хотите удалить все файлы cookie из Chrome.
- Кэшированные изображения и файлы — изображения и другие файлы, загруженные Google Chrome с посещенных вами веб-сайтов. Если вы работаете над проектами веб-разработки и тестируете разрабатываемые веб-страницы, рекомендуется удалить кэшированные изображения и файлы вместе с файлами cookie.
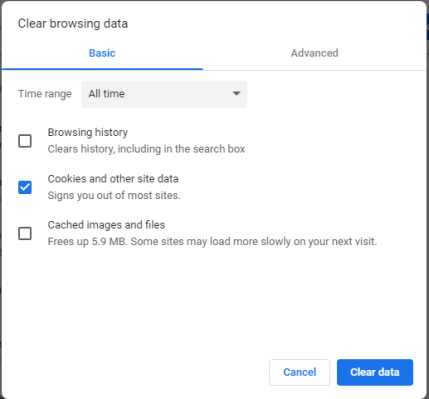
После выбора типа данных, которые вы хотите удалить, нажмите или нажмите «Очистить данные». Если вы хотите удалить другие данные браузера, а не только файлы cookie и основные сведения, которыми вы поделились ранее, нажмите или коснитесь вкладки «Дополнительно», а затем выберите элементы, которые вы хотите удалить, включая пароли и данные формы автозаполнения, прежде чем нажимать «Очистить данные».
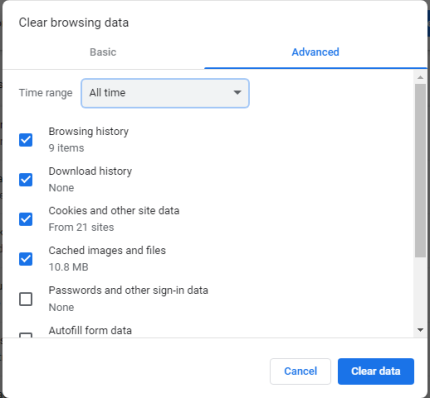
Это быстрый способ удалить все файлы cookie из Google Chrome. Если вы ищете определенный файл cookie для удаления или хотите сначала взглянуть на то, что вы удаляете, продолжайте читать.
Как просмотреть (и удалить или заблокировать) файлы cookie, хранящиеся на веб-сайте, который вы посещаете, в Google Chrome
Откройте Google Chrome и посетите веб-сайт, файлы cookie которого вы хотите просмотреть. В левой части адресной строки есть символ замка, сообщающий, безопасен ли веб-сайт, который вы посещаете. При наведении на него отображается всплывающая подсказка «Просмотреть информацию о сайте». Нажмите или коснитесь значка замка.
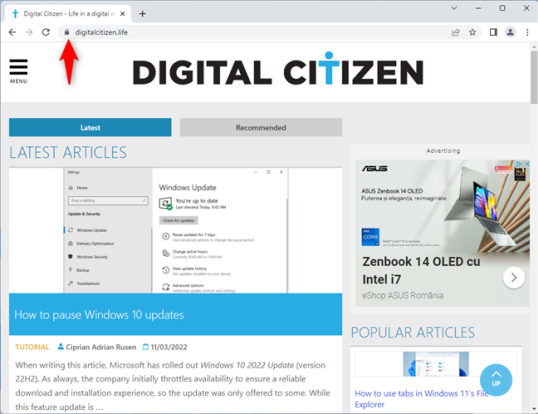
Появится всплывающее окно с несколькими вариантами:
- Соединение защищено — сообщает, использует ли веб-сайт безопасное соединение HTTPS и имеет ли он действующий сертификат шифрования.
- Файлы cookie — сообщает вам количество файлов cookie, хранящихся для посещаемого вами веб-сайта, и позволяет вам просматривать, блокировать или удалять их.
- Настройки сайта — переход на страницу настроек сайта, где вы можете настроить разрешения, которые вы предоставили этому веб-сайту, для доступа к таким вещам, как ваше местоположение, веб-камера или микрофон.
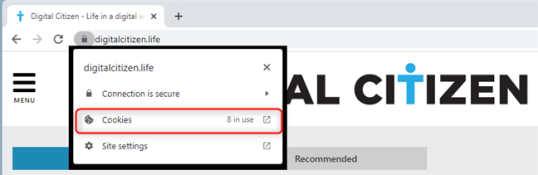
Во всплывающем окне отображаются папки со всеми файлами cookie, хранящимися на веб-сайте, который вы посещаете. Количество сохраненных файлов cookie зависит от каждого веб-сайта и способа доступа к нему. Например, когда вы посещаете наш веб-сайт — Digital Citizen — напрямую, вводя его адрес вручную, вы получаете меньше файлов cookie. Если вы получаете доступ к нему на основе поиска Google, вы получаете больше файлов cookie, некоторые из которых сохраняются Google, чтобы запомнить подробности о том, как вы попали на наш веб-сайт. То же самое верно для всех веб-сайтов. Несмотря на то, что мы ценим вашу конфиденциальность и стараемся максимально экономно использовать файлы cookie, другие веб-сайты могут хранить невероятно большое количество файлов cookie в вашем веб-браузере.
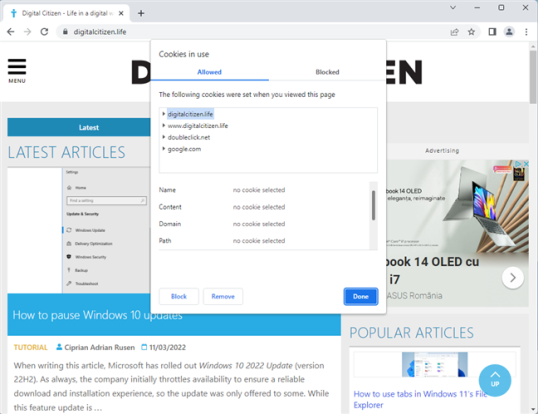
Файлы cookie разделены на папки в зависимости от их источника. Источником может быть веб-сайт, который вы посещаете, или используемые им службы. Дважды щелкните или дважды коснитесь каждой папки, чтобы расширить ее и просмотреть содержащиеся в ней файлы cookie. Вы также можете нажать на стрелку рядом с ним. Затем таким же образом откройте Cookies. При открытии файла cookie отображается информация о нем в нижней половине окна, например его имя, содержимое, домен и путь. На приведенном ниже снимке экрана вы видите файл cookie «_ga» с нашего веб-сайта, созданный для Google Analytics, службы, которую мы используем для анализа трафика на нашем сайте и того, что читают люди, что позволяет нам улучшать наш контент.
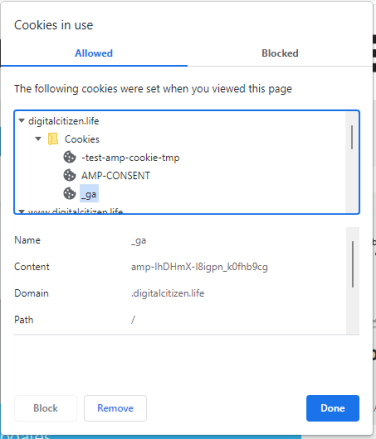
Для каждого файла cookie у вас есть кнопки «Блокировать» и «Удалить», которые делают именно то, что они говорят. Однако некоторые файлы cookie нельзя заблокировать, их можно только удалить. Когда вы закончите просмотр и удаление файлов cookie для посещаемого веб-сайта, нажмите или коснитесь «Готово», чтобы возобновить нормальную работу в Интернете.
Как просмотреть и удалить файлы cookie Chrome для посещенных вами веб-сайтов (chrome://settings/cookies)
Если вы хотите получить доступ ко всем файлам cookie, хранящимся в вашем браузере Google Chrome, а также ко всем данным и разрешениям сайта, нажмите или коснитесь трех точек в правом верхнем углу (Настройка и управление Google Chrome) и выберите «Настройки».
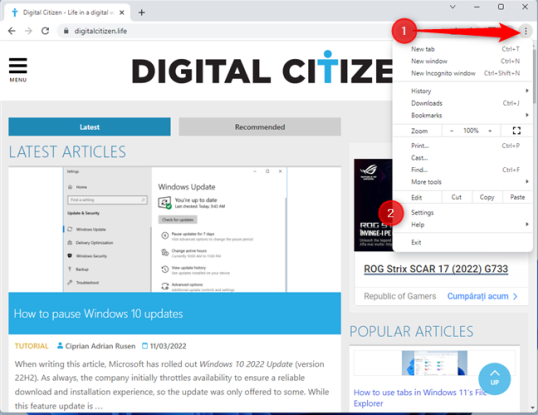
На открывшейся вкладке «Настройки» выберите «Конфиденциальность и безопасность» на левой боковой панели. Затем справа нажмите или коснитесь «Файлы cookie и все остальные данные сайта».
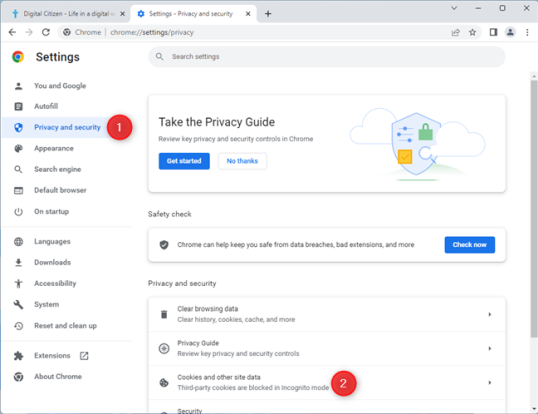
Это приведет вас к разделу «Файлы cookie и все другие данные сайта », к которым также можно получить доступ, скопировав и вставив этот путь в адресную строку Google Chrome:
chrome://settings/cookies
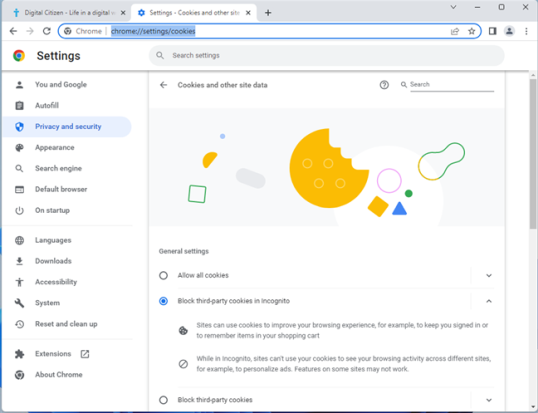
Прокрутите вниз, пока не найдете параметр «Просмотреть все данные и разрешения сайта», а затем нажмите или коснитесь его.
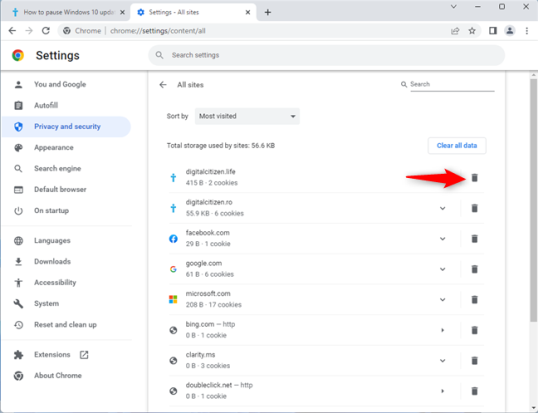
Вы видите список всех веб-сайтов, которые вы посетили и для которых Google Chrome сохранил файлы cookie и другие данные. Для каждого сайта вы видите его логотип, URL-адрес, количество файлов cookie и объем сохраненных данных. Вы можете развернуть, чтобы увидеть больше, нажав на название интересующего вас веб-сайта. Вы также можете очистить все его файлы cookie, данные сайта и разрешения, нажав кнопку «Удалить» рядом с веб-сайтом (он выглядит как мусорная корзина).
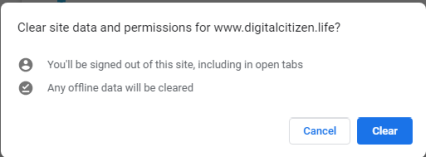
Подтвердите, что вы можете очистить данные и разрешения сайта, нажав «Очистить». Файлы cookie сайта и другие данные удаляются, и вы выходите из этого веб-сайта.
Если вы хотите удалить все файлы cookie и данные сайтов, хранящиеся в Chrome, для всех веб-сайтов в списке, нажмите или коснитесь кнопки «Очистить все данные» в правом верхнем углу, а затем подтвердите свой выбор, нажав «Очистить».
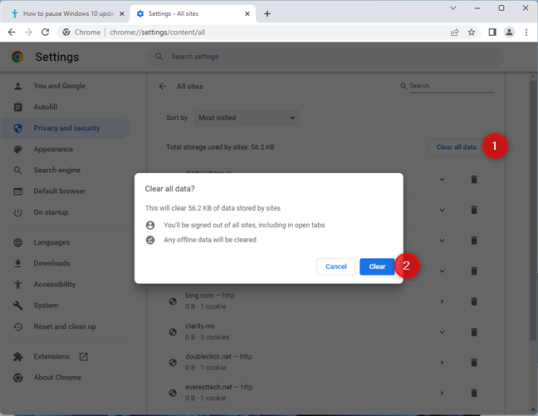
Все готово, и вы можете закрыть вкладку «Настройки» в Google Chrome.
Что произойдет, если я удалю все файлы cookie из Chrome?
Некоторые читатели задаются вопросом, стоит ли просто удалить все файлы cookie из Google Chrome, и спрашивают: что происходит, когда я удаляю файлы cookie?
Прежде всего, удаление файлов cookie означает, что вы покидаете сайты, на которых вы вошли в систему. Некоторые сайты используют постоянные файлы cookie, которые сохраняются в течение длительного периода времени. Избавление от них означает, что у них будет меньше данных о вас, и вы выиграете от некоторой конфиденциальности. Вы также можете увидеть меньше целевых объявлений. Однако главное преимущество удаления файлов cookie заключается в том, что вы получаете чистый лист. Затем вы можете начать заново и выбрать типы файлов cookie, которые вы хотите принимать на каждом веб-сайте в будущем.
Почему вы очищаете файлы cookie в Google Chrome?
Если у вас возникают проблемы с переключением между несколькими учетными записями на определенных сайтах, очистка файлов cookie в Chrome может избавить вас от головной боли. Вы удаляете файлы cookie по той же причине? Или это из соображений конфиденциальности или общего обслуживания и очистки компьютера? Оставьте свой ответ, используя варианты комментариев, доступные ниже.