Zabbix – это система мониторинга сетевого оборудования с широкими возможностями. Официальный сайт.
В описании ниже пример установки Zabbix-сервера в нашей организации. Информация поступает на сервер от различного сетевого оборудования внутри локальной сети. От Интернета сеть отделена сетевым экраном и считается условно безопасной. Вопросы информационной безопасности в описании не рассматриваются, но обязательны.
Сервер установлен на ПК со следующими параметрами:
Процессор: Intel Core I5-3450 3.1ГГцх4.
ОЗУ: 8Гб.
HDD: 2Tb.
Сетевая карта 1Гбит/сек.
Сервер подключен в сеть, ему раздается IP-адрес по DHCP с доступом к Интернету.
Этот же компьютер используется в нашей локальной сети как сервер сбора логов.
Скачиваем Ubuntu 20. Desktop image с графическим интерфейсом.
Создаем установочную флэшку с помощью ПО Rufus и переносим скачанный образ на нее.
Загружаемся с установочной флэшки.
Выбираем – Try or Install Ubuntu.
Далее откроется мастер установки.
Выбраны следующие параметры:
Install Ubuntu – установить Ubuntu.
English – язык системы.
Keyboard layout – English – язык клавиатуры.
Normal installation – тип установки – нормальная.
Download updates while installing Ubuntu – загрузить обновления вовремя установки (если подключен Интернет).
Erase disk and install Ubuntu – стереть диск и установить Ubuntu (все данные с диска удаляются!).
Where are you – выбираем часовой пояс.
Who are you – имя ПК, логин, пароль.
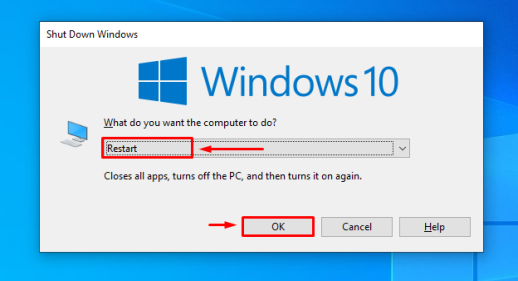
После установки вытаскиваем из ПК флэшку и нажимаем кнопку «Ввод» на клавиатуре.
Система установлена. Вводим указанный ранее логин и пароль и попадаем на рабочий стол.
Компьютер подключен в сеть. IP-адрес присвоился по DHCP.
Запускаем терминал Ctrl+Alt+T.
Входим от имени root.
|
1
| sudo su — root |
Вводим пароль учетной записи. Ввод пароля не отображается.
Далее все действия в терминале выполняются с правами root.
Обновляем систему.
|
1 2
| apt—get update apt—get upgrade —y |
Настройка удаленного доступа.
Подключение будет происходить от ПК с Windows 10 к ПК с Ubuntu 20.
Запускаем терминал. Вводим команды.
|
1
| apt install xrdp —y |
Выполнится установка.
Выходим из профиля.
Power Off >> Log Out.
(если не выйти, то по RDP не войти)
Подключаемся по RDP из Windows на IP-адрес ПК с Ubuntu.
Win+R >> mstsc.
Вводим IP-адрес.
Вводим логин-пароль (без указания домена).
Попадаем на рабочий стол Ubuntu.
Для работы Zabbix потребуются следующие компоненты:
Apache
PHP
MYSQL
Запускаем терминал Ctrl+Alt+T. Входим от имени root.
|
1
| sudo su — root |
Вводим пароль учетной записи. Ввод пароля не отображается.
Далее все действия в терминале выполняются с правами root.
Установка Apach2.
Устанавливаем apach2.
|
1
| apt—get install apache2 —y |
Включаем автозапуск.
|
1
| systemctl enable apache2 |
Запускаем службу
|
1
| systemctl start apache2 |
Проверяем статус
|
1
| systemctl status apache2 |
Active (running) – значит работает.
Можно посмотреть страницу приветствия перейдя в браузере по адресу:
|
1
| http://localhost |
Установка PHP.
Информация о пакете php.
|
1
| apt show php |
(текущая версия 7.4)
Можно посмотреть какие есть модули.
|
1
| apt—cache search php7.4 |
Установка.
|
1
| apt—get install php7.4 —y |
Установка дополнительных модулей.
Для работы, ускорения и прочих особенностей выбраны сл. модули.
|
1
| apt—get install libapache2—mod—php7.4 |
(работа с apache, возможно он уже установлен автоматически)
|
1
| apt—get install php7.4—mysql |
(работа с bd mysql)
|
1
| apt—get install php7.4—curl |
(библиотека для передачи через протоколы http https)
|
1
| apt—get install php7.4—xml |
(взаимодействие с xml)
|
1
| apt—get install php7.4—gd |
(работа с графикой)
Эти два модуля возможно уже присутствуют.
|
1
| apt—get install php7.4—json |
(сериализация объектов в текст )
|
1
| apt—get install php7.4—opcache |
(кэш кода php для ускорения обработки большого кол-ва запросов)
Проверка работы php.
В командной строке создаем файл info.php
|
1
| vi /var/www/html/info.php |
Вставляем в файл содержание.
|
1
| <?php phpinfo(); ?> |
Выходим из редактора vi
esc
|
1
| :wq |
(сохранить и закрыть)
В браузере проверяем ссылку
|
1
| http://localhost/info.php |
Должна открыться страница параметров php.
Установка MYSQL.
|
1
| apt—get install mysql—server —y |
Добавление в автозагрузку и старт
|
1 2
| systemctl enable mysql systemctl start mysql |
Проверка версии mysql
|
1
| mysqld —version |
Проверка статуса mysql
|
1
| systemctl status mysql |
Active (running) – работает.
После всех установок нужно перезапустить веб-сервер
|
1
| systemctl restart apache2 |
Установка Zabbix.
Переходим на официальный сайт и выбираем компоненты для установки.
Выбраны компоненты как на картинке.
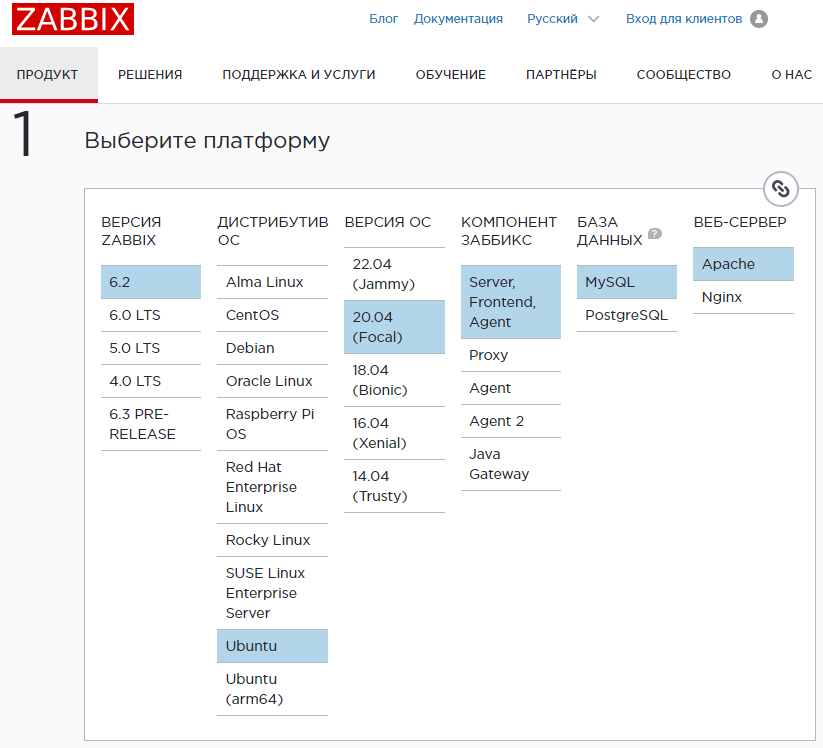
На основании выбранных компонентов ниже генерируется код для установки. Копируем его по шагам в терминал.
OS Distribution Ubuntu или Ubuntu (arm64) выбирается в зависимости от разрядности процессора.
Устанавливаем репозиторий Zabbix и выполняем обновление списка пакетов для установки.
Скачиваем.
|
1
| wget https://repo.zabbix.com/zabbix/6.2/ubuntu/pool/main/z/zabbix-release/zabbix-release_6.2-2%2Bubuntu20.04_all.deb |
Устанавливаем пакет zabbix
|
1
| dpkg —i zabbix—release_6.2—2+ubuntu20.04_all.deb |
Обновляем списки пакетов.
|
1
| apt update |
Устанавливаем компоненты Zabbix.
Сервер.
|
1
| apt install zabbix—server—mysql —y |
Веб-интерфейс
|
1
| apt install zabbix—frontend—php —y |
Настройка для apache.
|
1
| apt install zabbix—apache—conf —y |
Настройка-скрипт для импорта данных в базу sql.
|
1
| apt install zabbix—sql—scripts —y |
Агент.
|
1
| apt install zabbix—agent —y |
Создадим базу данных с названием zabbix, пользователя с паролем и назначим права.
Заходим в mysql с правами root.
|
1
| mysql —u root |
(пароля нет)
|
1
| create database zabbix character set utf8mb4 collate utf8mb4_bin; |
|
1
| create user zabbix@localhost identified by ‘password’; |
|
1
| grant all privileges on zabbix.* to zabbix@localhost; |
|
1
| set global log_bin_trust_function_creators = 1; |
|
1
| flush privileges; |
|
1
| exit; |
Импорт схемы.
|
1
| zcat /usr/share/zabbix—sql—scripts/mysql/server.sql.gz | mysql —default—character—set=utf8mb4 —uzabbix —p zabbix |
(вводим пароль password, ждем пару минут)
Отключение настройки log_bin_trust_function_creators
|
1
| mysql —root |
|
1
| set global log_bin_trust_function_creators = 0; |
|
1
| exit; |
Добавляем пароль БД в конфигурацию Zabbix.
Используем редактор vi.
|
1
| vi /etc/zabbix/zabbix_server.conf |
Вставляем в файл строку.
|
1
| DBPasswor=password |
Сохранить и выйти.
|
1
| :wq |
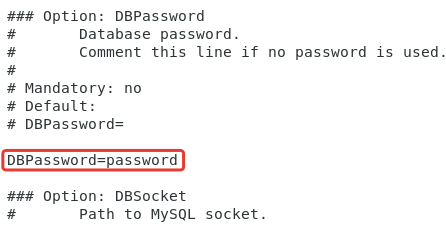
Пароль — password представлен для примера, в реальной ситуации нужно выбирать сложный пароль.
Перезапускаем программы
|
1
| systemctl restart zabbix—server apache2 |
Автозапуск при включении.
|
1
| systemctl enable zabbix—server zabbix—agent |
Статус сервера
|
1
| systemctl status zabbix—server |
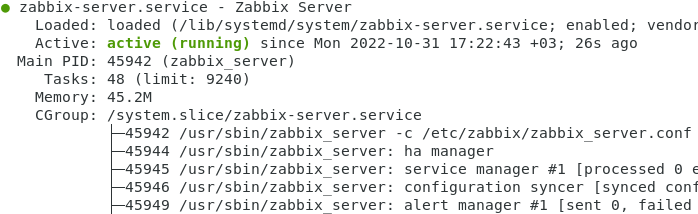
В браузере переходим по адресу.
|
1
| http://localhost/zabbix |
Нажимаем кнопку «Next step».
Проверка предварительных требований. Нажимаем «Next step».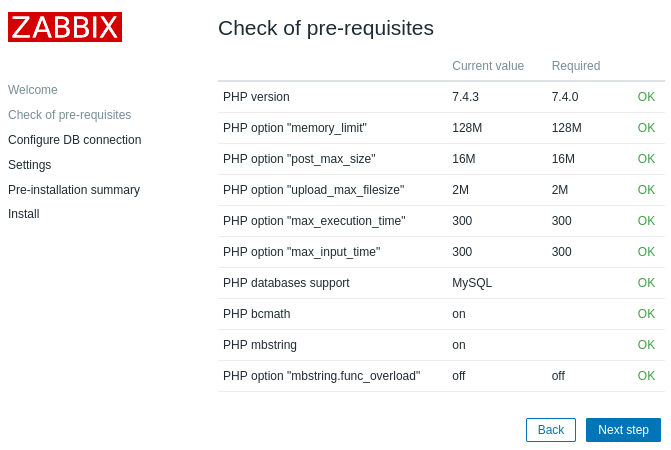
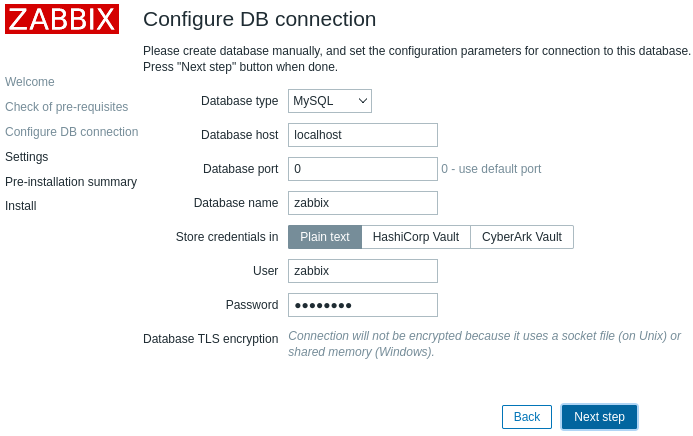
Следующий шаг – параметры базы данных.
Вводим пароль – password. Нажимаем кнопку «Next step».
На следующем шаге указываем имя сервера и часовой пояс. Нажимаем «Next step».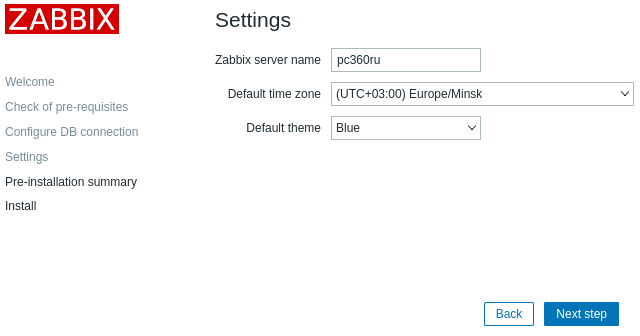
Проверяем всю введенную информацию. Нажимаем «Next step».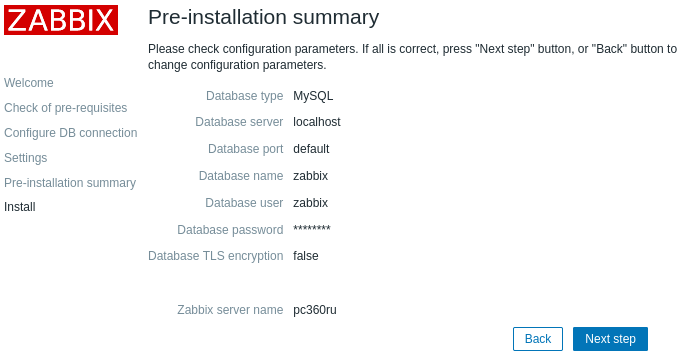
Завершаем настройку нажав «Finish».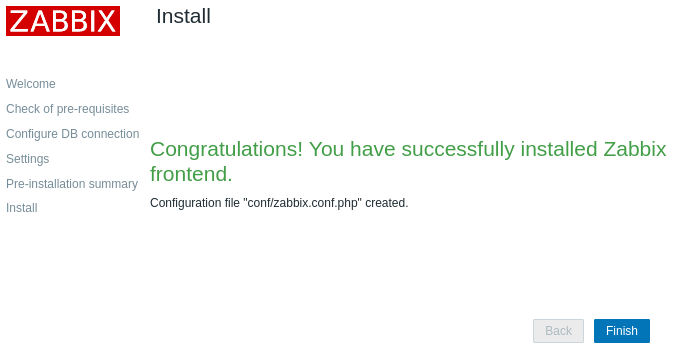
На странице авторизации вводим учетные данные Zabbix.
Логин: Admin.
Пароль: zabbix.
Установка завершена.
Русификация.
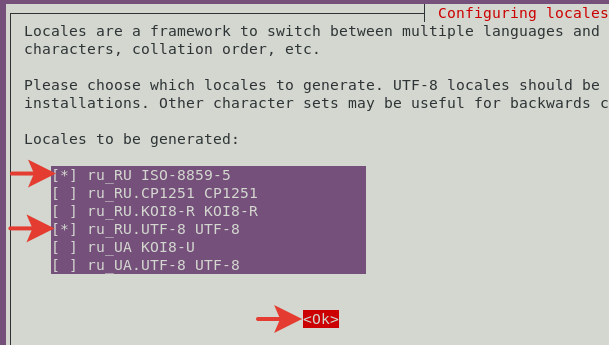
Выполняем команду для изменения локальных настроек.
|
1
| dpkg—reconfigure locales |
Выбираем стрелками вверх-вниз ru_RU.UTF-8 UTF-8 и ru_RU ISO-8859-5. Отмечаем на пробел. Нажимаем TAB, чтоб перейти на ОК. Нажимаем Ввод.
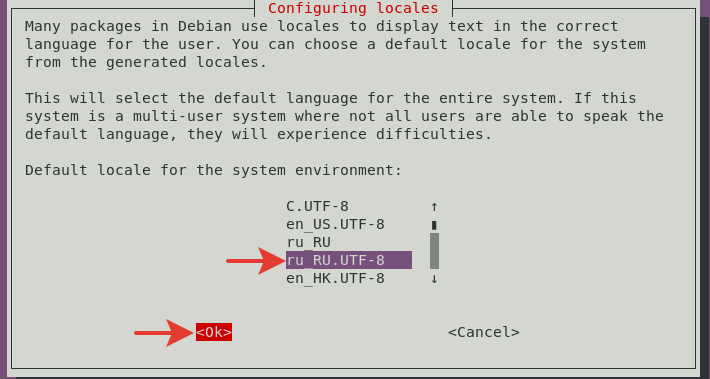
Перезапускаем apache и zabbix
|
1
| systemctl restart zabbix—server apache2 |
В настройках профиля выбираем русский язык.
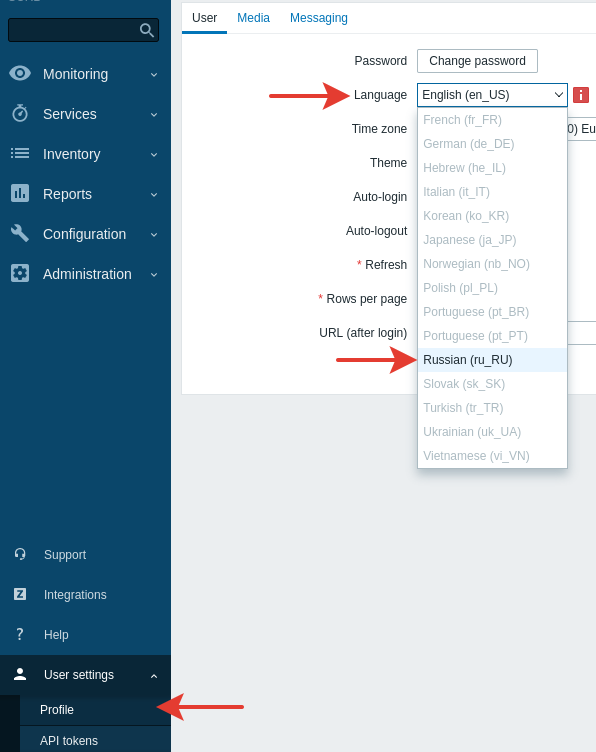
Интерфейс становится на русском.
Удаление Zabbix.
|
1
| apt—get purge zabbix* |
Удаление компонентов Zabbix.
|
1 2 3 4 5
| apt remove zabbix—server—mysql —y apt remove zabbix—frontend—php —y apt remove zabbix—apache—conf —y apt remove zabbix—sql—scripts —y apt remove zabbix—agent —y |
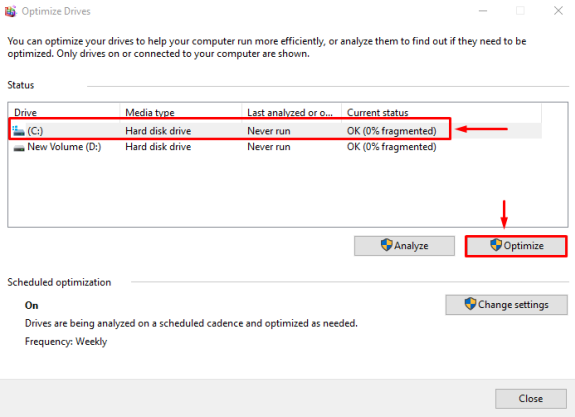
Мониторинг сетевых устройств с помощью Zabbix.
Мониторинг осуществляется через протокол SNMP — Simple Network Management Protocol или простой протокол управления сетью.
Настройка выполняется на MikroTik RB750GR3 с прошивкой v6.49 через WinBox в защищенной локальной сети.
Активация SNMP.
В боковом меню выбираем System >> SNMP.
Отмечаем галочкой Enabled для активации.
Trap Version: 2 – версия trap для SNMPv2.
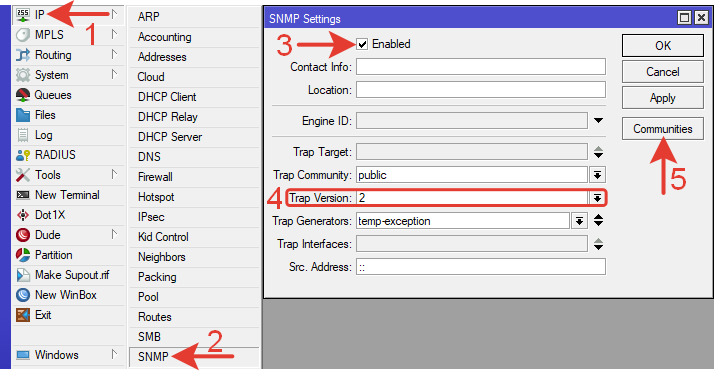
Настройка Community.
Выбираем сообщество «public» нажав кнопку «Communities» и настраиваем его. 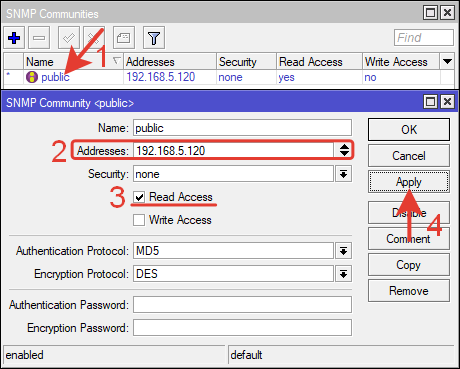
Addresses: 192.168.5.120 – IP-адрес с которого можно подключатся к микротику по SNMP (это IP-адресс сервера Zabbix).
Проверяем галочку Read Access – только чтение.
Сохраняем настройку.
Так же сохраняем настройку в окне SNMP Settings.
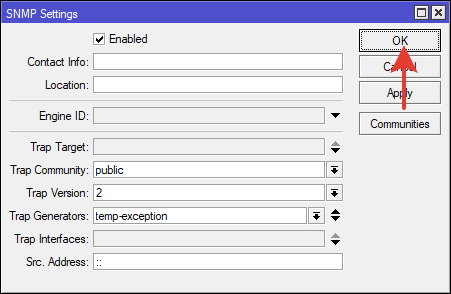
Через командную строку терминала:
|
1 2
| /snmp community set [ find default=yes ] addresses=192.168.5.120/32 /snmp set enabled=yes trap—version=2 |
Выполняем настройку в ZABBIX.
Добавляем новый хост.
Мониторинг >> Узлы сети >> Создать узел сети.
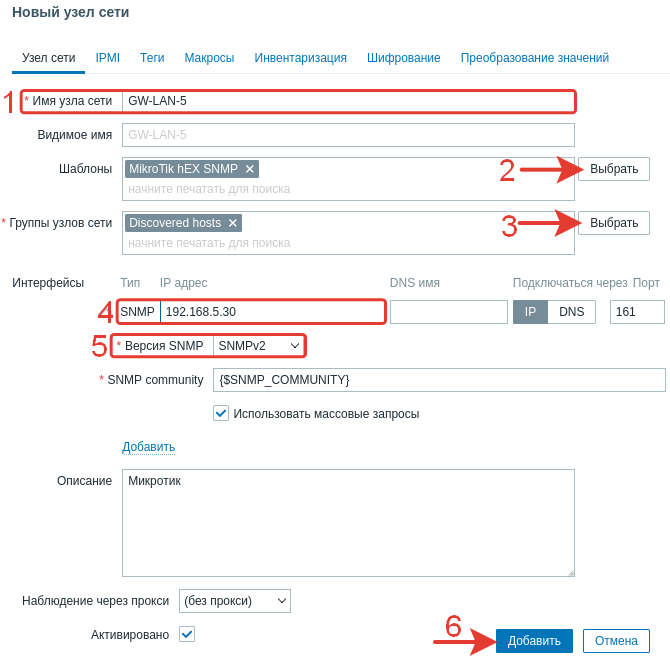
Имя узла сети – GW-LAN-5 – название роутера в локальной сети.
Шаблоны – выбираем MikroTik hEX SNMP – в соответствии с моделью роутера.
Группы узлов сети – Discovered hosts или своя любая группа.
Интерфейсы >> SNMP, IP-адрес 192.168.5.30 – адрес роутера в сети. Порт 161 без изменений.
Интерфейсы >> Версия SNMP – SNMPv2.
Нажимаем кнопку «Добавить».
В боковом меню выбираем «Узлы сети» и видим что статус роутера – «Доступен».

Можно посмотреть различную информацию по этому хосту, выбрав последние данные, это – температура, нагрузка на CPU, память и многое другое.
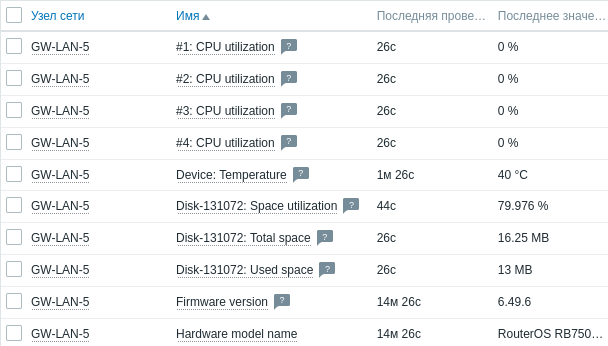
Если мониторинг не заработал, то нужно проверить доступность портов, проверить файервол в Ubuntu на котором установлен Zabbix, трассу между сервером и роутером на наличие дополнительных промежуточных роутеров с ограничивающими трафик правилами.
Удаление хоста из Zabbix.
Выбираем нужный хост и переходим в настройку.
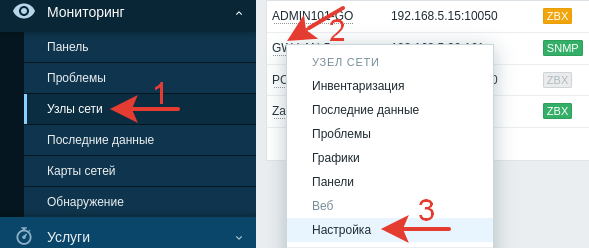
В нижней части экрана нажимаем «Удалить».

Скачиваем и устанавливаем агента Zabbix с официального сайта.
Выбираем параметры файла для загрузки под свою систему и скачиваем.

В данном случае выбран дистрибутив для ОС Windows под платформу c 64 разрядным процессором (не обязательно фирмы AMD) версия Zabbix 6.2 с шифрованием передачи данных между сервером и агентом, установочный пакет MSI.
Если выбрать PACKAGING >> Archive, то нужно будет выполнять установку через командную строку.
Устанавливаем скаченного агента.

Путь установки и содержание можно не менять.
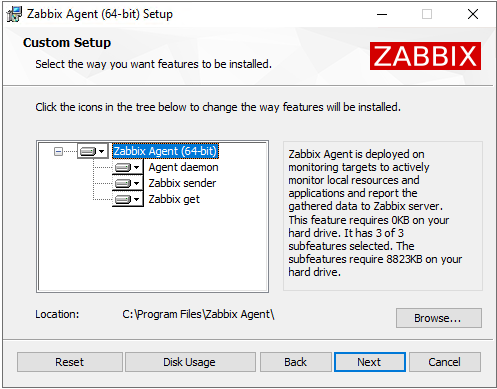
На следующем шаге указываем IP-адрес сервера Zabbix.
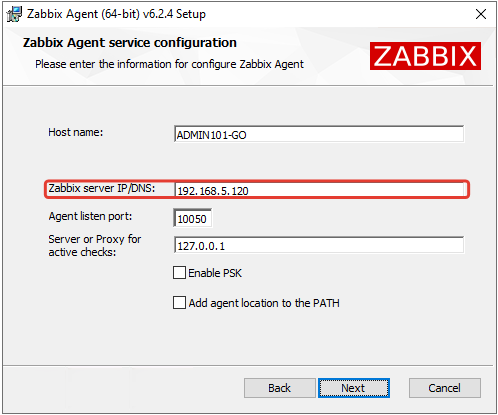
Завершаем установку.
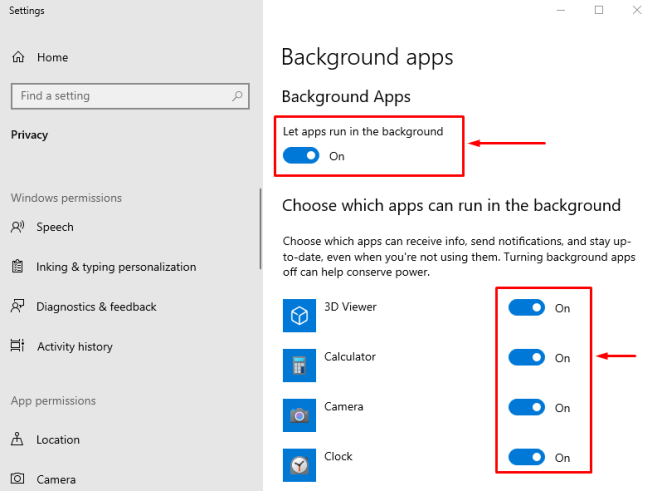
Агент будет работать в виде службы. Убедиться в этом можно перейдя в службы.
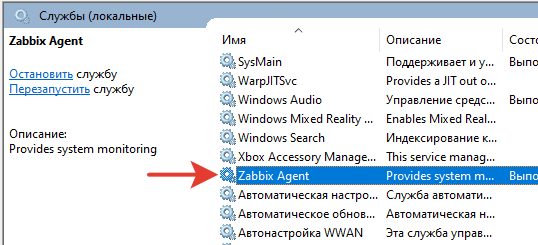
Далее переходим на сервер Zabbix.
В боковом меню выбираем «Узлы сети» (Hosts).
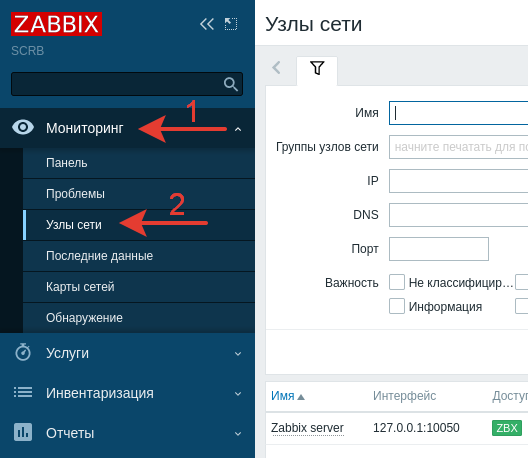
Создаем новый узел сети.
Указываем имя хоста. Оно должно соответствовать реальному имени ПК.

Добавляем несколько стандартных шаблонов Windows.

Выбираем их из списка.
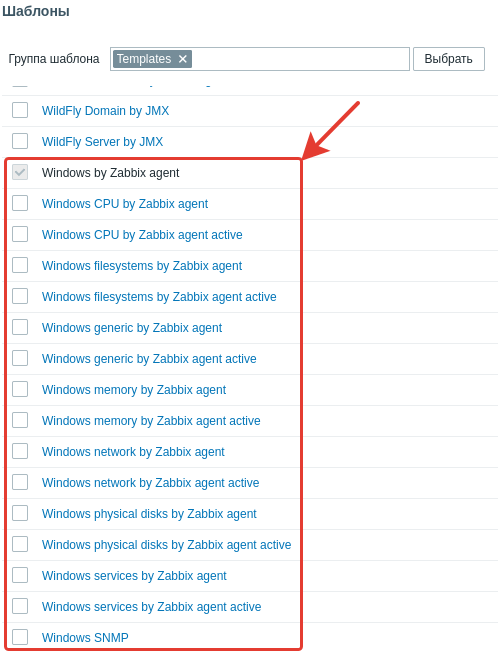
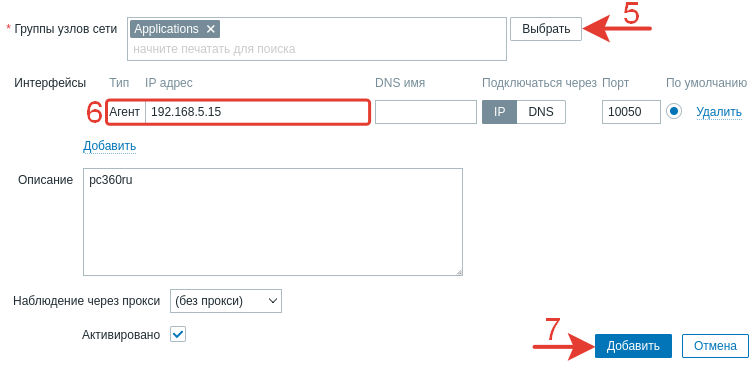
Добавляем группу и IP-адрес хоста с установленным агентом.
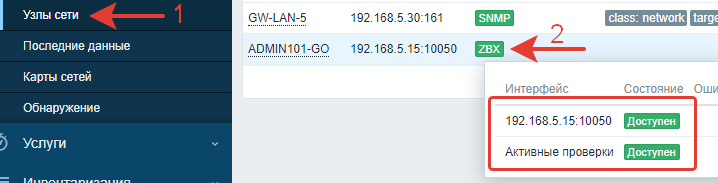
Через пару минут проверяем состояние хоста на сервере. Агент доступен.
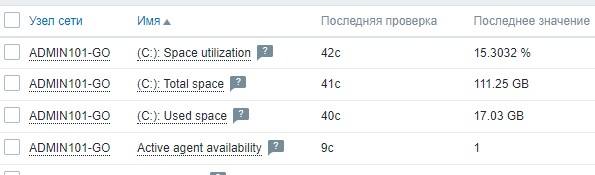
Можно посмотреть получаемые данные.
Если не заработало.
Проверяем файл конфигурации.
|
1
| C:Program FilesZabbix Agentconfzabbix_agentd.conf |
Смотрим активные строки.

Строки, начинающиеся знаком #, — это комментарии.
LogFile=C:Program FilesZabbix Agentzabbix_agentd.log – место сохранения лога.
Server=192.168.5.120 – IP-адрес Zabbix-сервера.
ServerActive=192.168.5.120:10051 IP-адрес Zabbix-сервера для активных проверок.
Hostname=ADMIN101-GO имя ПК, должно соответствовать написанному в Zabbix-сервере.
Проверяем файл логов и выясняем причины ошибок, если они есть.
Проверяем правило брандмауэра Windows.
При установке, программа сама создает правило, но оно какое-то странное, разрешает любую активность, поэтому решено его не использовать.
Создано правило разрешающее входящее соединение по порту 10050 только с IP-адреса Zabbix-сервера.
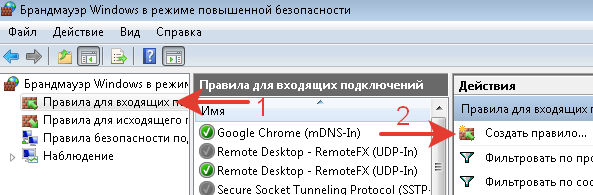
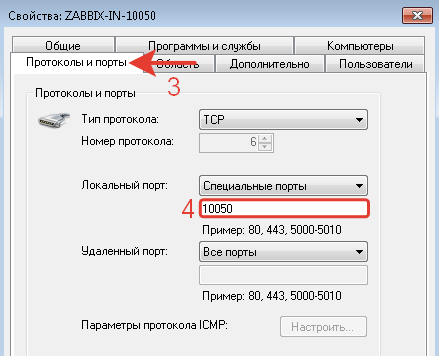
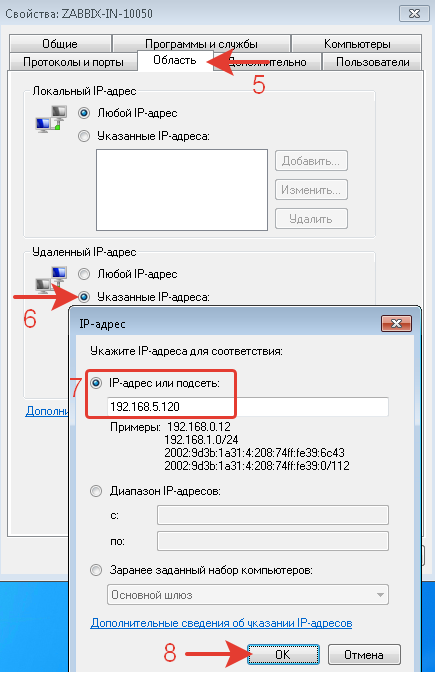
Порт 10050 используется для доступа сервер-агент.
Порт 10051 используется для доступа агент-сервер.
Можно открыть в файрволе Ubuntu временно для проверки доступ на входящие и исходящие соединения для портов 10050 и 10051 для любых источников.
Сперва лучше проверить связь от сервера до агента через telnet.
Подключаемся к серверу, открываем терминал, вводим команду.
|
1
| telnet 192.168.5.15 10050 |
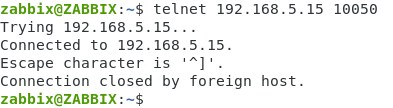
На картинке результат при нормально работающем агента.
Скачиваем и устанавливаем агента Zabbix с официального сайта.
Выбираем параметры файла для загрузки под свою систему и скачиваем.
КОМПОНЕТ ЗАББИКС – Agent (выбираем агента).
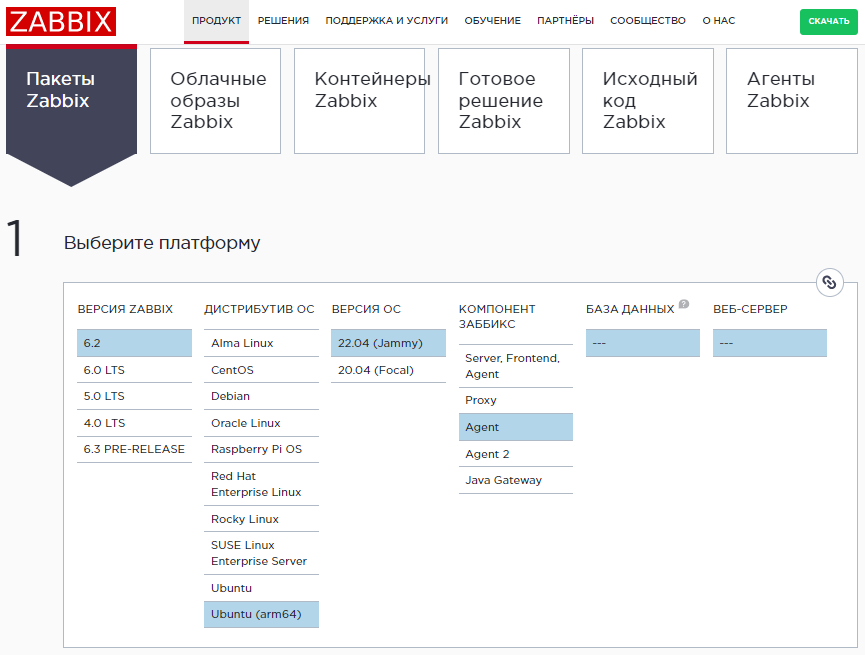
На основании выбранных компонентов ниже генерируется код для установки. Копируем его по шагам в терминал.
Скачиваем.
|
1
| wget https://repo.zabbix.com/zabbix/6.2/ubuntu-arm64/pool/main/z/zabbix-release/zabbix-release_6.2-3%2Bubuntu20.04_all.deb |
Устанавливаем пакет zabbix
|
1
| dpkg —i zabbix—release_6.2—3+ubuntu20.04_all.deb |
Обновляем списки пакетов.
|
1
| apt update |
Устанавливаем компонент zabbix-agent.
|
1
| apt install zabbix—agent —y |
Перезапускаем агент и включаем его запуск при старте системы.
|
1 2
| systemctl restart zabbix—agent systemctl enable zabbix—agent |
Проверяем статус агента.
|
1
| systemctl status zabbix—agent |
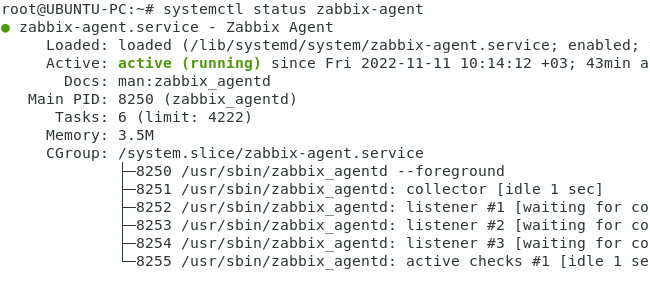
Active (running) – значит работает.
Изменяем файл конфигурации Zabbix-агента через редактор vi.
|
1
| vi /etc/zabbix/zabbix_agentd.conf |
Находим строку Server=127.0.0.1 и вписываем IP-адрес Zabbix-сервера.
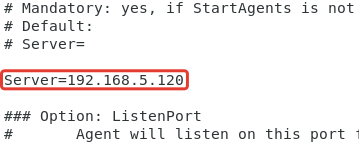
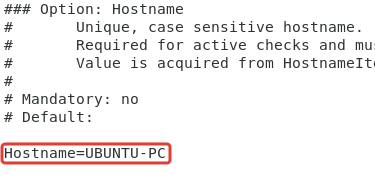
Находим строку #HostName= раскомментируем ее (убираем #) и указываем актуальное имя ПК на котором агент.
Находим строку # ListenPort и раскомментируем ее.
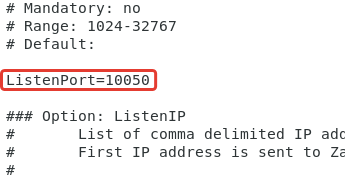
Порт 10050 используется для связи сервер-агент.
Для активных проверок так же можно указать адрес сервера Заббикс.
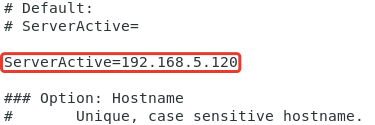
Сперва нужно определиться, какой режим мониторинга будет использоваться: активный или пассивный.
При пассивном – запрос приходит от сервера и агент ему отвечает.
При активном – агент сам отправляет серверу данные и не ждет от него запроса, сверяя только шаблон.
У нас в сети используется в основном пассивный мониторинг.
Выходим и сохраняем.
Esc
|
1
| :wq |
Перезапускаем агента.
|
1
| systemctl restart zabbix—agent |
Далее переходим на сервер Zabbix.
В боковом меню выбираем «Узлы сети» (Hosts).
Создаем новый узел сети.
Заполняем необходимые поля.
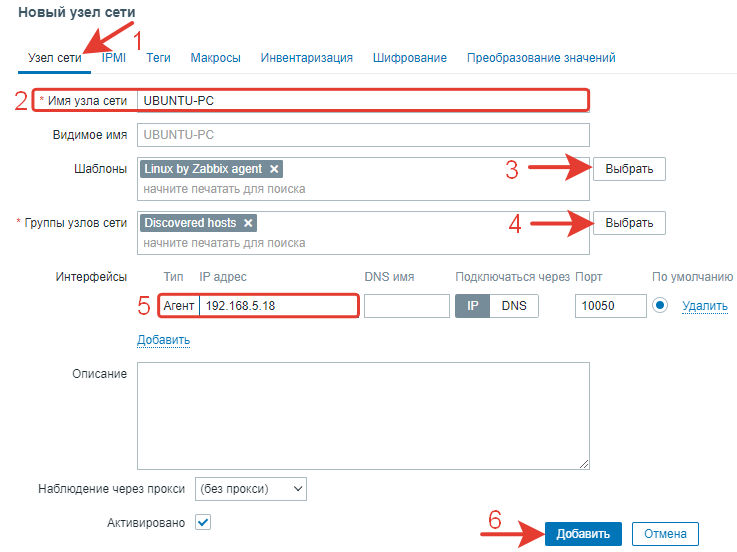
Имя узла сети должно соответствовать реальному имени ПК и тому, что написано в файле конфигурации агента.
Шаблон выбираем для Linux.
Группа узлов сети любая.
Интерфейс – указываем IP-адрес компьютера с установленным агентом. Порт 10050 остается без изменений.
Нажимаем кнопку «Добавить».
Через некоторое время смотрим на статус добавленного узла.

Статус – Доступен.
Если не заработало.
Проверяем связь от сервера до агента через telnet.
На сервере открываем терминал, вводим команду.
|
1
| telnet 192.168.5.18 10050 |
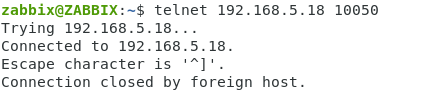
На картинке нормальный результат. Подключение и через некоторое время отключение.
Проверяем еще раз файл конфигурации.
|
1
| /etc/zabbix/zabbix_agentd.conf |
Минимально необходимыми в нем должны быть только такие строки.
|
1 2 3 4 5 6 7
| PidFile=/run/zabbix/zabbix_agentd.pid LogFile=/var/log/zabbix—agent/zabbix_agentd.log LogFileSize=0 Server=192.168.5.120 ListenPort=10050 ServerActive=192.168.5.120 Hostname=UBUNTU—PC |
Проверяем файл логов и выясняем причины ошибок, если они есть.
|
1
| /var/log/zabbix—agent/zabbix_agentd.log |
Проверяем состояние служб и портов.
Устанавливаем net-tool (если раньше не было установлено)
|
1
| apt install net—tools |
Просмотр работающих сервисов.
|
1
| netstat —pnltu |

Проверяем firewall Ubuntu.
Если на сервере закрыты все порты, то можно временно для проверки открыть порты 10050 и 10051 на все направления.
Подключаемся с правами root.
|
1
| sudo su — root |
(пароль)
Добавляем правила.
Для 10051.
|
1 2
| iptables —A INPUT —p tcp —dport 10051 —j ACCEPT iptables —A OUTPUT —p tcp —dport 10051 —j ACCEPT |
Для 10050.
|
1 2
| iptables —A OUTPUT —p tcp —dport 10050 —j ACCEPT iptables —A INPUT —p tcp —dport 10050 —j ACCEPT |

Просмотр созданных правил.
|
1
| iptables —L |
Если это помогло, то конкретизируем направления, указав IP-адреса источника и назначения (сервер-клиент).
Если не помогло, удаляем все правила.
|
1
| iptables —F |