ffmpeg — мощный инструмент для конвертирования файлов в большинстве известных видеоформатов. Программа ffmpeg не имеет графического интерфейса, однако позволяет выполнять задачи, перед которыми другие видеоконвертеры попросту бессильны.
Ниже рассмотрим, как установить ffmpeg в Ubuntu 20.04 из официальных репозиториев, а также с использованием snap-пакета. А затем поговорим о том, как с его помощью переконвертировать небольшое видео из одного формата в другой.
Zip — это один из самых распространенных и наиболее популярных способов создания сжатых архивных файлов. Это также один из самых старых форматов архивных файлов, он был создан в 1989 году. Поскольку он широко используется, вы будете регулярно сталкиваться с zip-файлами.
В одном из предыдущих уроков я показал, как заархивировать папку в Linux. В этом кратком руководстве для начинающих я покажу вам, как распаковывать файлы в Linux. Читать →
Мы рассмотрим процесс поднятия двух контейнеров с PostgreSQL и настройки репликации данных между ними. Использовать будем систему на базе Linux, однако, сам процесс настройки Docker и репликации не зависит от операционной системы.
Подготовка компьютера
На компьютере, где мы будем запускать наш кластер баз данных должен быть установлен Docker. Также мы сразу рассмотрим развертывание нужной нам инфраструктуры в docker-compose. Для установки необходимой одноименной платформы смотрим инструкцию Установка Docker на Linux.
После мы можем переходить к поднятию контейнеров.
Запуск контейнеров с СУБД
Как говорилось выше, мы будем поднимать наши контейнеры с помощью docker-compose.
postgresql_01/postgresql_02 — названия для сервисов, контейнеры для которых мы будем поднимать.
image — образ, из которого будут создаваться контейнеры. В данном примере мы берем официальный образ postgres.
container_name — имя, которое будет присвоено контейнеру после его запуска. В нашем примере это postgresql_01 и postgresql_02.
restart — режим перезапуска. Говорит, в каких случаях наш контейнер должен стартовать.
volumes — хорошим тоном для работы базы данных в контейнере является проброс каталога хостового компьютера внутрь контейнера. Таким образом, после удаления контейнера данные останутся на компьютере. В нашем примере в каталоге /data будут созданы каталоги postgresql_01 и postgresql_02, которые будут прокинуты в каталог /var/lib/postgresql/data контейнера.
environment — для первого запуска необходима инициализация базы данных. Без пароля системы выдает ошибку. Поэтому мы задаем переменную среды POSTGRES_PASSWORD.
Условимся, что первичный сервер или master будет в контейнере с названием postgresql_01. Вторичный — postgresql_02. Мы будем настраивать потоковую (streaming) асинхронную репликацию.
Настройка на мастере
Подключаемся к контейнеру docker:
docker exec -it postgresql_01 bash
Заходим под пользователем postgres:
su - postgres
Создаем пользователя, под которым будем подключаться со стороны вторичного сервера:
createuser --replication -P repluser
* в данном примере будет создаваться учетная запись repluser с правами репликации.
Система потребует ввода пароля. Придумываем его и набираем дважды.
Выходим из-под пользователя postgres:
exit
Выходим из контейнера:
exit
Открываем конфигурационный файл postgresql.conf:
vi /data/postgresql_01/postgresql.conf
Приводим к следующием виду некоторые параметры:
wal_level = replica
max_wal_senders = 2
max_replication_slots = 2
hot_standby = on
hot_standby_feedback = on
* где
wal_level указывает, сколько информации записывается в WAL (журнал операций, который используется для репликации). Значение replica указывает на необходимость записывать только данные для поддержки архивирования WAL и репликации.
max_wal_senders — количество планируемых слейвов;
max_replication_slots — максимальное число слотов репликации (данный параметр не нужен для postgresql 9.2 — с ним сервер не запустится);
hot_standby — определяет, можно или нет подключаться к postgresql для выполнения запросов в процессе восстановления;
hot_standby_feedback — определяет, будет или нет сервер slave сообщать мастеру о запросах, которые он выполняет.
Посмотрим подсеть, которая используется для контейнеров с postgresql:
И добавляем строку после остальных «host replication»:
host replication all 172.19.0.0/16 md5
* в данном примере мы разрешили подключение пользователю replication из подсети 172.19.0.0/16 с проверкой подлинности по паролю.
Перезапустим докер контейнер:
docker restart postgresql_01
Настройка на слейве
Выполним настройку вторичного сервера. Для начала, удалим содержимое рабочего каталога вторичной базы:
rm -r /data/postgresql_02/*
* в данном примере мы удалим все содержимое каталога /data/postgresql_02.
Мы должны быть уверены, что в базе нет ничего важного. Только после этого стоить удалять данные.
Заходим внутрь контейнера postgresql_02:
docker exec -it postgresql_02 bash
Выполняем команду:
su - postgres -c "pg_basebackup --host=postgresql_01 --username=repluser --pgdata=/var/lib/postgresql/data --wal-method=stream --write-recovery-conf"
* где postgresql_01 — наш мастер; /var/lib/postgresql/data — путь до каталога с данными слейва.
Система должна запросить пароль для пользователя repluser — вводим его. Начнется процесс репликации, продолжительность которого зависит от объема данных.
Проверка
Смотрим статус работы мастера:
docker exec -it postgresql_01 su - postgres -c "psql -c 'select * from pg_stat_replication;'"
Смотрим статус работы слейва:
docker exec -it postgresql_02 su - postgres -c "psql -c 'select * from pg_stat_wal_receiver;'"
Сервер Ansible: CentOS Linux release 7.9.2009 (Core).
Node 1: CentOS Linux release 7.9.2009 (Core).
Node 2: CentOS Linux release 7.9.2009 (Core).
Node 3: CentOS Linux release 7.9.2009 (Core).
Node 4: CentOS Linux release 7.9.2009 (Core).
1. Задача.
К примеру, нам требуется с помощью внедрения custom facts для Ansible организовать сбор версий контейнеров, запущенных на серверах, а так же сбор версий некоторого программного обеспечения на серверах, которое имеет файл с указанием версии в своём каталоге /ecp/po/version.txt.
Собранная информация должна формироваться в json-формат.
Дополнительно требуется рассмотреть средства визуализации информации в удобном виде (opensource web-приложения).
2. Решение задачи.
Решение будет состоять из нескольких этапов:
загрузка и выполнение скрипта на узлах с целью получить json файлы;
выгрузка файлов json с узлов;
склеивание узловых файлов json в один сводный файл;
просмотр сводного файла.
В системе Ansible есть возможность собирать системную информацию, которая собирается в виде фактов с помощью встроенного модуля setup.
Со сбором стандартных переменных по умолчанию всё предельно ясно, но что делать, если мы хотим сформировать наши собственные переменные на всех хостах, чтобы в дальнейшем использовать их в нашем коде?
Для этого существует возможность добавления Custom facts, что делается следующим образом:
на любом хосте, контролируемом Ansible, создаётся каталог /etc/ansible/facts.d;
внутри каталога размещаются один либо несколько файлов с расширением *.fact, например custom.fact;
файлы возвращают данные в формате json.
Создаем инвентарь test-servers.inventory на 4 тестовых сервера:
Создаем специальный custom.fact файл для загрузки на узлы, который, по сути, является скриптом для выполнения некоторого комплекса действий на удалённом узле.
По замыслу будут собираться некоторые переменные и заворачиваться в разметку json.
Создаём специальный playbookcustom-facts-fetch.yml, содержащий сценарий /ansible/files/custom.fact для узла, возвращающий некоторый файл json на Ansible master сервер с каждого узла:
После успешной отработки playbook на сервере Ansible master появится каталог /ansible/json с подкаталогами ‘имя_узла‘:
В каждом из которых будет находиться json файл вида имя_узла.json:
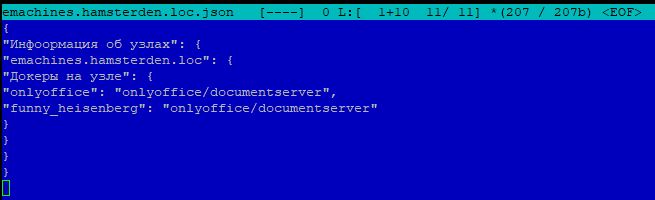
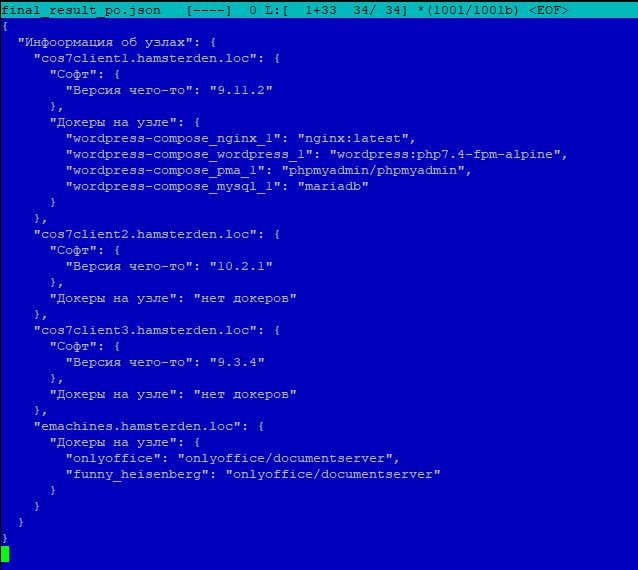
Содержимое json файла первого узла emachines:
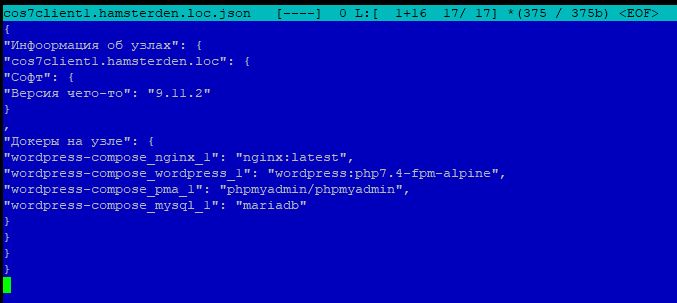
Содержимое json файла второго узла server1:
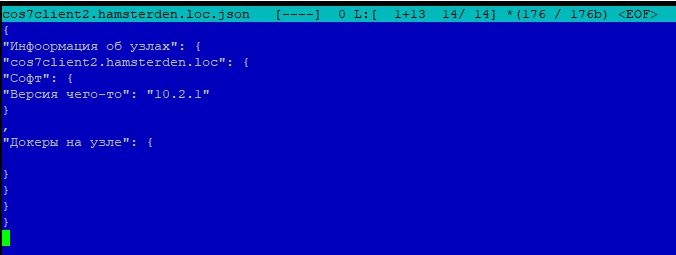
Содержимое json файла третьего узла server2:
Содержимое json файла четвертого узла server3:
Получилось несколько файлов json, по файлу с каждого целевого узла.
Сколько узлов мы задействовали для Ansible custom facts, столько и json файлов и будет.
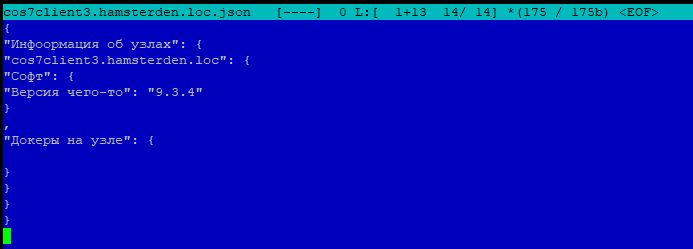
В первом файле emachines.hamsterden.loc.json не имеется фрагмент с названием «Версия чего-то‘, по втором файле cos7client1.hamsterden.loc.json такой фрагмент имеется, а так как в custom.fact реализована проверка на фактическое наличия файла /ecp/po/version.txt.
К примеру, наличие файла /ecp/po/version.txt бывает только у серверов типа «web-server». Так как скрипт «сам учитывает» тип сервера, то можно смело применять custom.fact на все целевые серверы и файл json всегда будет генерироваться корректно для каждого типа серверов.
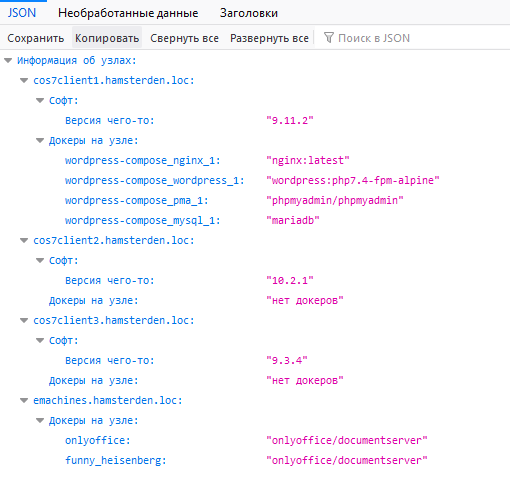
Для создание сводного json файла по всем файлам со всех узлам, воспользуемся утилитой jq.
2. Ansible Vault для хранения конфиденциальных данных.
Если ваши плейбуки Ansible содержат конфиденциальные данные, такие как пароли, ключи API и учетные данные, важно обеспечить их безопасность с помощью шифрования. Ansible предоставляет ansible-vault для шифрования файлов и переменных.
Несмотря на то, что любой файл данных Ansible, а также двоичные файлы, возможно зашифровать изначально, чаще для шифрования переменных файлов, содержащих конфиденциальные данные, используется ansible-vault. После шифрования файла с помощью этого инструмента вы сможете выполнять, редактировать или просматривать его, только предоставив соответствующий пароль, указанный при первом шифровании файла.
2.1. Создание нового зашифрованного файла.
Вы можете создать новый зашифрованный файл Ansible с помощью:
# ansible-vault create credentials.yml
Эта команда выполнит следующие действия:
Сначала вам будет предложено ввести новый пароль. Вам нужно будет указывать этот пароль при каждом доступе к содержимому файла, будь то редактирование, просмотр или просто запуск плейбука или команд с использованием его значений.
Затем откроется редактор командной строки по умолчанию, чтобы вы могли заполнить файл требуемым содержимым.
Наконец, когда вы закончите редактирование, ansible-vault сохранит файл как зашифрованный.
2.2. Шифрование существующего файла.
Чтобы зашифровать существующий файл Ansible, вы можете использовать следующую команду:
# ansible-vault encrypt credentials.yml
Эта команда запросит у вас пароль, который вам нужно будет вводить при каждом доступе к файлу credentials.yml.
2.3. Просмотр содержимого зашифрованного файла.
Если вы хотите просмотреть содержимое файла, который ранее был зашифрован с помощью ansible-vault, и вам не нужно изменять его содержимое, вы можете использовать команду:
# ansible-vault view credentials.yml
Она предложит вам указать пароль, который вы выбрали при первом шифровании файла с помощью ansible-vault.
2.4. Редактирование зашифрованного файла.
Чтобы изменить содержимое файла, который ранее был зашифрован с помощью ansible-vault, выполните:
# ansible-vault edit credentials.yml
Эта команда предложит вам указать пароль, который вы выбрали при первом шифровании файла credentials.yml. После проверки пароля откроется редактор командной строки по умолчанию с незашифрованным содержимым файла, что позволит вам внести нужные изменения. По завершении вы можете сохранить и закрыть файл, как обычно, и обновленное содержимое будет сохранено и зашифровано.
2.5. Расшифровка файлов.
Если вы хотите навсегда расшифровать файл, ранее зашифрованный с помощью ansible-vault, вы можете сделать это с помощью следующего синтаксиса:
# ansible-vault decrypt credentials.yml
Эта команда предложит вам ввести тот пароль, который использовался при первом шифровании файла. После проверки пароля содержимое файла будет сохранено на диск в виде незашифрованных данных.
3. Использование нескольких паролей.
Ansible поддерживает для хранилища несколько паролей, сгруппированных по разным идентификаторам. Это полезно, если вы хотите иметь выделенные пароли хранилища для различных сред – для разработки, тестирования и производства.
Чтобы создать новый зашифрованный файл с пользовательским идентификатором хранилища, включите параметр --vault-id вместе с меткой и расположением, где ansible-vault может найти пароль для этого хранилища. Метка может быть любой, а расположение может быть либо prompt (что означает, что команда должна предложить вам ввести пароль), либо путь к файлу паролей.
Это создаст новый идентификатор по имени dev, который использует prompt для получения пароля. Комбинируя этот метод с файлами переменных группы, вы сможете создать отдельные хранилища для каждой среды приложения:
Мы использовали dev и prod в качестве идентификаторов хранилищ, чтобы продемонстрировать, как вы можете создавать отдельные хранилища для каждой среды. Самостоятельно вы можете создать столько хранилищ, сколько захотите, и использовать любой ID.
Теперь, чтобы просмотреть, отредактировать или расшифровать эти файлы, вам необходимо предоставить тот же ID хранилища и источник пароля вместе с командой ansible-vault:
Если вам нужно автоматизировать процесс инициализации серверов в Ansible с помощью стороннего инструмента, вам потребуется способ ввода пароля хранилища без его запроса. Вы можете сделать это, используя файл паролей через ansible-vault.
Файл паролей может быть простым текстовым файлом или исполняемым скриптом. Если файл является исполняемым, выходные данные, созданные ним, будут использоваться в качестве пароля хранилища. В противном случае в качестве пароля хранилища будет использоваться необработанное содержимое файла.
Чтобы применить файл паролей в ansible-vault, необходимо указать путь к файлу паролей при выполнении любой из команд vault:
Ansible не различает контент, который был зашифрован с помощью prompt, и простой файл пароля при условии, что входной пароль один и тот же. С практической точки зрения это означает, что файл можно зашифровать, используя prompt, а затем создать файл пароля для хранения того же пароля, который использовался в методе prompt. Также верно и обратное: вы можете зашифровать содержимое, используя файл паролей, а затем использовать метод prompt, предоставляя тот же пароль при запросе Ansible.
Для большей гибкости и безопасности, чтобы не хранить свой пароль в текстовом файле, вы можете использовать скрипт Python для получения пароля из других источников.
Официальный репозиторий Ansible содержит несколько примеров сценариев, которые вы можете использовать для справки при создании своего скрипта под потребности вашего проекта.
5. Запуск плейбука с зашифрованными данными.
Каждый раз, когда вы запускаете плейбук, в котором используются данные, ранее зашифрованные с помощью ansible-vault, вам нужно будет указывать пароль хранилища в команде playbook.
Если вы использовали параметры по умолчанию и prompt при шифровании данных плейбука, вы можете использовать опцию --ask-vault-pass, чтобы Ansible запрашивал пароль:
Если вы используете данные, зашифрованные с помощью ID, вам нужно указать тот же ID хранилища и источник пароля, который вы использовали при первом шифровании данных:
Сервер Ansible: CentOS Linux release 7.9.2009 (Core).
Node 1: CentOS Linux release 7.9.2009 (Core).
Node 2: CentOS Linux release 7.9.2009 (Core).
Node 3: CentOS Linux release 7.9.2009 (Core).
1. Введение.
Для тех, кто решит изучать Ansible, данный раздел будет крайне полезен. В данном разделе соберу некоторые полезные примеры из повседневной практики, чтобы вы могли понять как работает Ansible и научиться его использовать самостоятельно.
Официальную документацию с официальными примерами всегда можно почитать на сайте разработчиков Ansible.
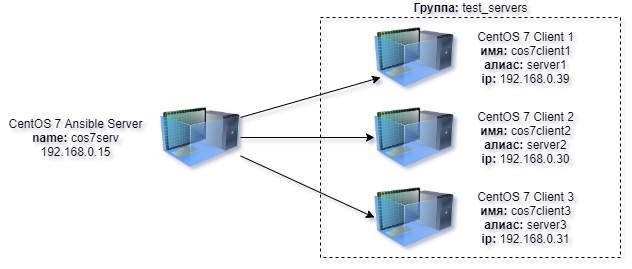
Пускай у нас будет вот такой стенд из 4х виртуальных машин под управлением CentOS 7:
Все сервера, в данном примере, имеют одинаковую операционную систему CentOS Linux release 7.9.2009 (Core), одинаковых пользователей root и одинаковые пароли на учетных записях root.
Задачи: для всех узлов.
отключить SELinux и перезагрузить узлы;
обновить операционную систему;
установить на всех узлах группу полезных программ Midnight Commander, wget, tar;
настроить межсетевой экран узлов на разрешение соединяться с 80 и 443 портами;
установить web-сервер Nginx и протестировать отдачу тестовой страницы, пробросить готовую композицию HTML5 на узлы;
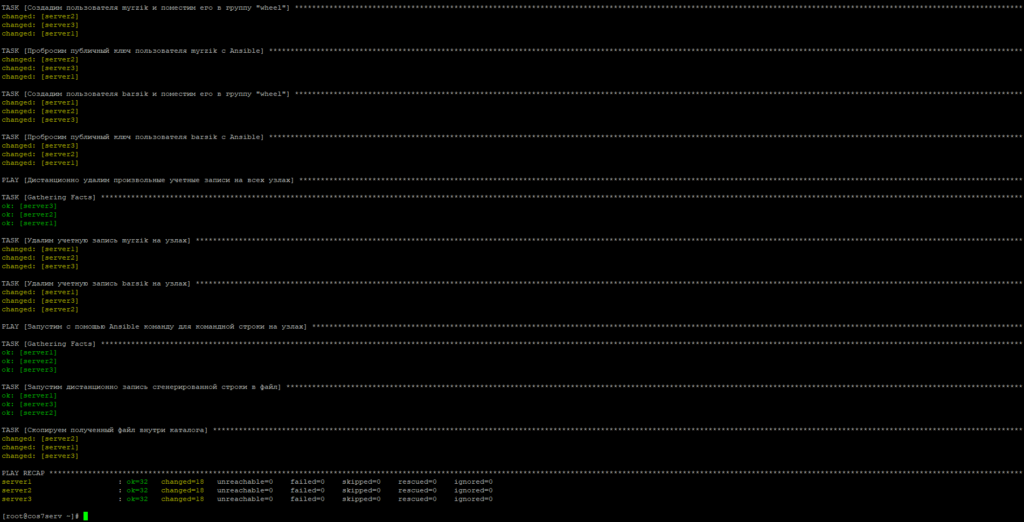
добавить пользователей myrzik и barsik и настроить режим sudo для них;
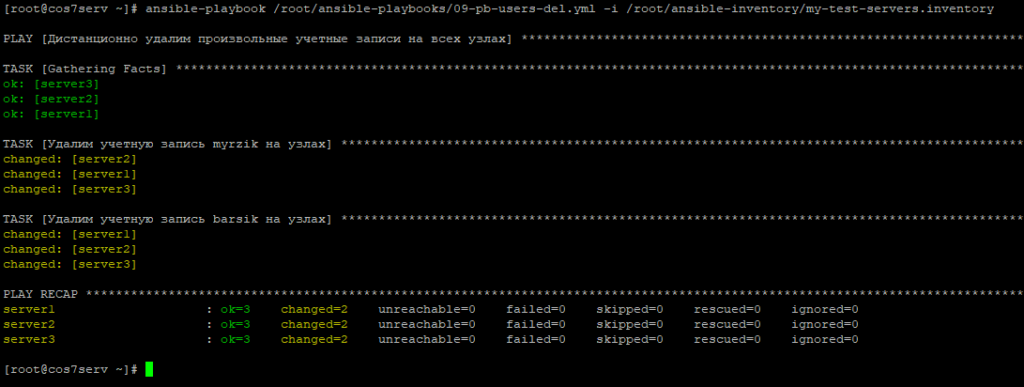
удалить пользователей myrzik и barsik;
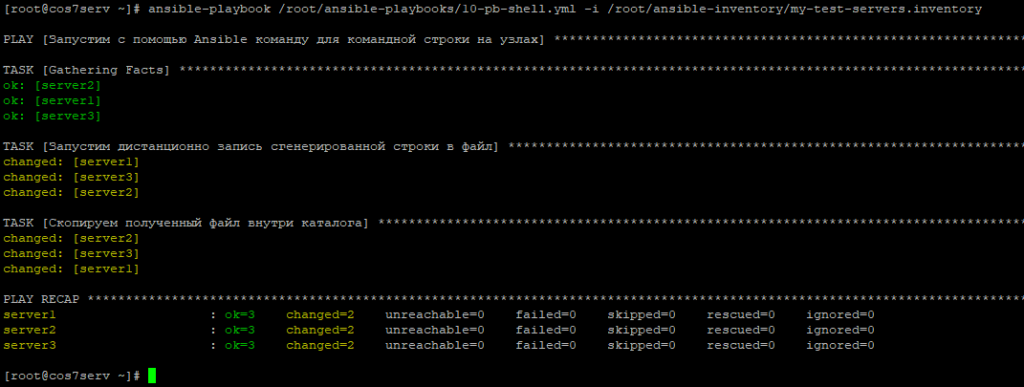
выполнить некоторые произвольные команды для консоли на всех узлах дистанционно.
Протестировать:
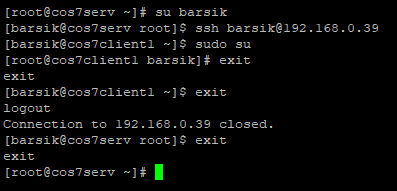
зайти на виртуальные машины под условными пользователями и переключиться в root;
зайти на каждую виртуальную машину по http и увидеть заставку Nginx.
Условие: удалённые виртуальные машины можно настраивать только системой Ansible.
Дополнительно: еще в эту инструкцию я буду добавлять разные новые и полезные примеры, но вверху в задачах, учитывать это не буду.
3. Подготовка сервера Ansible.
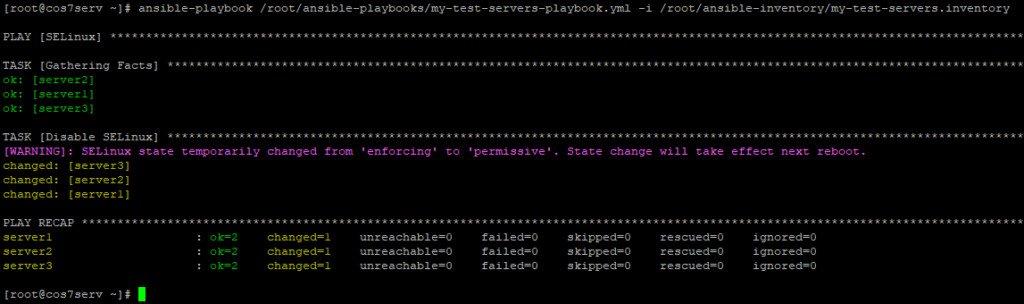
Первым делом отключим на Ansible Server систему SELinux. Рамках учебного стенда она нам не нужна.
Когда вы устанавливаете CentOS 7, функция SELinux включена по умолчанию, из-за этого некоторые приложения в вашей системе могут фактически не поддерживать этот механизм безопасности. Чтобы такие приложения функционировали нормально, вам необходимо отключить SELinux.
Конечно в интернете имеется много способов настройки и эксплуатации этой системы, но в данной инструкции я, пока что, настраивать SELinux не буду.
Пожалуй, это самый суровый способ, но тоже работает.
Вводим команду:
# yum -y remove selinux*
Перезапустим Ansible Server:
# shutdown -r now
3.2. Обновление системы.
Обновим полностью операционную систему сервера Ansible:
# yum -y update && yum -y upgrade
3.3. Установка Ansible.
По умолчанию Ansible нет в репозитории CentOS 7.
Подключим дополнительный репозиторий EPEL:
# yum -y install epel-release
После устанавливаем сам сервер управления Ansible:
# yum -y install ansible
Проверка версии установленной версии Ansible:
# rpm -qa | grep ansible
Ответ:
или вот так:
# ansible --version
Ответ:
Отлично! Теперь у нас есть сервер Ansible.
3.4. Создание файла инвентаря.
Установим файловый менеджер и текстовый редактор в одном лице — Midnight Commander:
# yum -y install mc
Файл инвентаря по умолчанию обычно находится в /etc/ansible/hosts, но вы можете использовать опцию -i для указания пользовательских файлов при запуске команд и плейбуков для Ansible.
Это удобный способ настройки индивидуального инвентаря для каждого проекта, который можно включить в системы контроля версий, такие как Git.
Создадим свой файл нашего инвентаря:
# cd ~
# mkdir -p ~/ansible-inventory
# cd ~/ansible-inventory
# touch my-test-servers.inventory
test_servers — это группа серверов, в которую добавлены три сервера с IP-адресами192.168.0.30, 192.168.0.31 и 192.168.0.39;
server 1-3 — это индивидуальные алиасы каждого из серверов группы test_servers в списке инвентаря;
ansible_ssh_host — это специальная переменная, которая содержит IP-адрес узла, к которому будет создаваться соединение;
ansible_ssh_user — это еще одна специальная переменная которая говорит Ansible‘у подключаться под указанным аккаунтом, то есть пользователем. По умолчанию Ansible использует ваш текущий аккаунт пользователя, или другое значение по умолчанию, указанное в ~/.ansible.cfg (remote_user).
3.5. Генерация ключей пользователя root.
Создаём пару RSA-ключей для пользователя root на Ansible сервере:
# ssh-keygen
На все вопросы жмём Enter. Нам не нужны никакие пароли на ключи и генерируем ключи мы в каталог по умолчанию.
Ответ:
3.6. Проброс root-ключей на узлы.
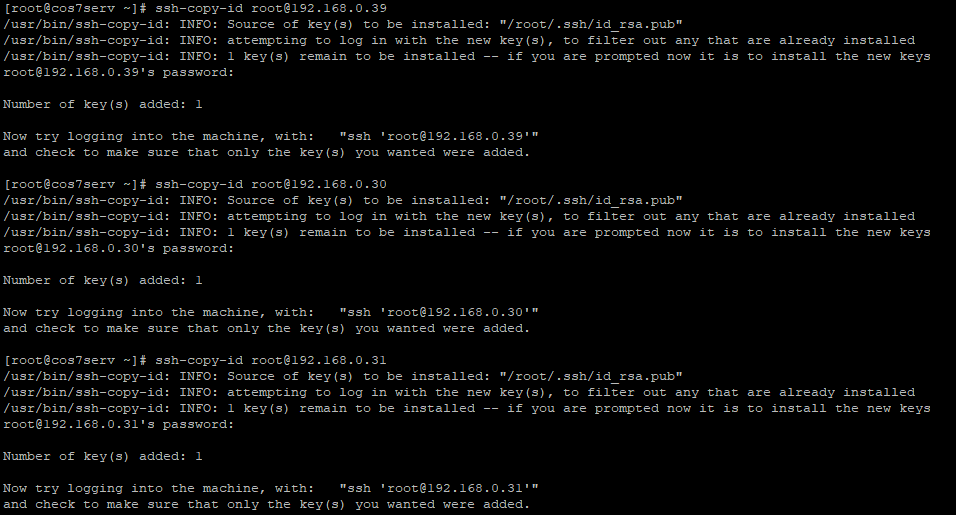
Копируем открытые ключи пользователя root на узлы, которыми планируем управлять с помощью Ansible.
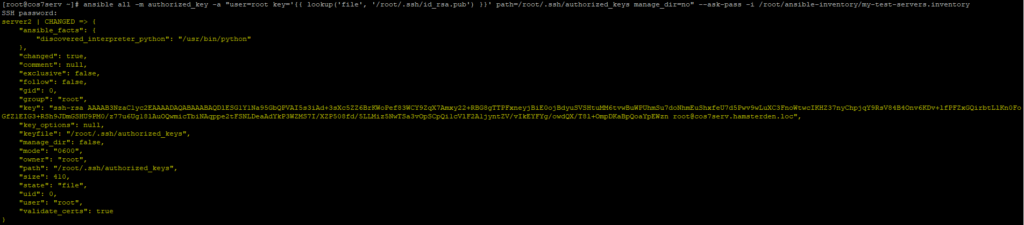
Выполним команду автоматической установки публичного ключа пользователя root на все узлы с авторизацией по паролю, до которых может дотянутся Ansible по списку инвентаря my-test-servers.inventory.
# ansible all -m authorized_key -a "user=root key='{{ lookup('file', '/root/.ssh/id_rsa.pub') }}' path=/root/.ssh/authorized_keys manage_dir=no" --ask-pass -i /root/ansible-inventory/my-test-servers.inventory
Ответ:длинный список изменений на каждом узле.
Конечно можно было и вручную всё распространить, у нас узлов 3 штуки, а представьте, если их было бы 10-20 штук:
Модуль ping проверит, есть ли у вас валидные учетные данные для подключения к нодам, определенным в файле инвентаря, и может ли Ansible запускать сценарии Python на удаленном сервере от имени root пользователя.
Ответ pong означает, что Ansible готов запускать команды и плейбуки на этом узле.
Ответ:
Выполним простую команду 'uptime' для проверки возможности управления узлами:
# ansible -a 'uptime' test_servers -i /root/ansible-inventory/my-test-servers.inventory
Ответ:
3.8. Настройка входа Ansible на самого себя.
Также настроим вход по ключу Ansible Server на самого себя:
Внимание! Почти все типовые действия, которые вам потребуются для работы с Ansible, имеются на официальном сайте с технической документацией по этой системе. Не тратьте на поиски в интернете готовых решений, сразу открывайте официальное руководство пользователя Ansible и ищите там.
Когда вы устанавливаете CentOS 7, функция SELinux включена по умолчанию, из-за этого некоторые приложения в вашей системе могут фактически не поддерживать этот механизм безопасности. Чтобы такие приложения функционировали нормально, вам необходимо отключить SELinux. Рамках учебного стенда она нам не нужна.
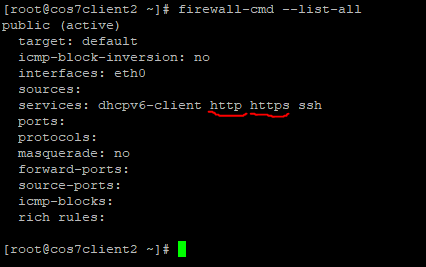
Примечание! После перезагрузки узлов я проверил состояние SELinux на узлах:
# sestatus
Ответ:
Как видно SELinux отключен на всех узлах дистанционно с помощью Ansible.
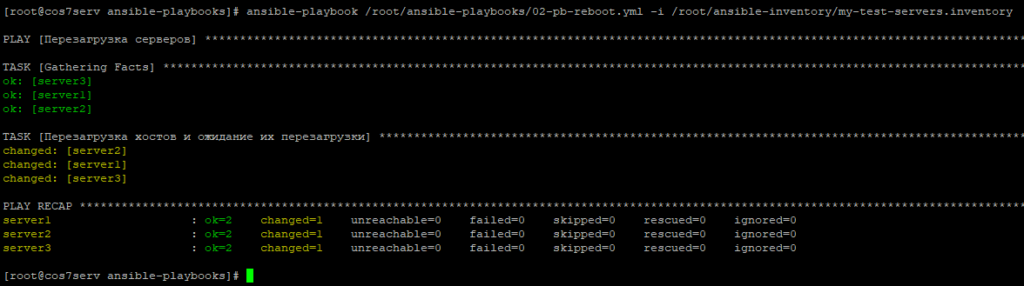
Примечание! В любой команде Ansible, которая требует перезагрузки после изменения узел будет перезагружен, когда playbook завершится, а затем Ansible будет ждать, пока узел не станет доступным, и ssh будет работать, прежде чем перейти к следующему плейбуку.
Примечание! Если вам нужно перезагрузиться на полпути через playbook вы можете заставить все задачи выполниться с помощью команды:
- name: Reboot if necessary
meta: flush_handlers
Иногда это можно сделать, чтобы что-то изменить, заставить сервер перезагрузиться, а затем проверить, что изменения вступили в силу и все в том же playbook.
4.2. Обновление операционных систем на узлах.
Перед выполнением других учебных задач, обновим операционные системы на узловых серверах с помощью Ansible.
Воспользуемся готовым решением ansible.builtin.yum от создателей Ansible по обновлению программного обеспечения на узлах.
Долго-долго ждём, особенно если это самое первое обновление после установки узловых систем и они ни разу еще не обновлялись до этого.
После некоторого всплеска активности CPU на узлах Ansible всё завершилось.
Ответ:
Все пакеты на узлах успешно обновлены до последнего актуального состояния из доступных узлам репозиториев.
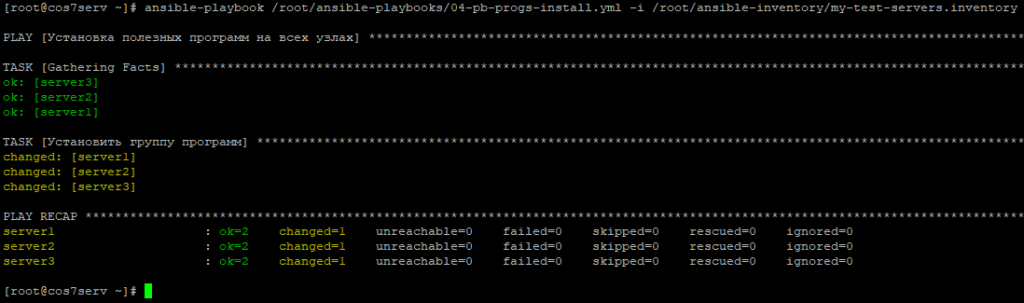
4.3. Установка группы полезных программ.
Про учебному сценарию требуется установить пакет программного обеспечения, который состоит из традиционного набора программ для многих серверов: mc, wget, tar.
Снова воспользуемся готовым решением ansible.builtin.yum от создателей Ansible по установке программного обеспечения mc, wget, tar на узлах.
---
- name: Установка полезных программ на всех узлах
hosts: test_servers
become_method: sudo
become_user: root
tasks:
- name: Установить группу программ
yum:
name: "{{ package }}"
vars:
package:
- mc
- wget
- tar
state: latest
Проверим синтаксис плейбука 04-pb-progs-install.yml специальной утилитой --syntax-check от Ansible:
Все пакеты на узлах успешно установлены программы mc, wget, tar из доступных узлам репозиториев.
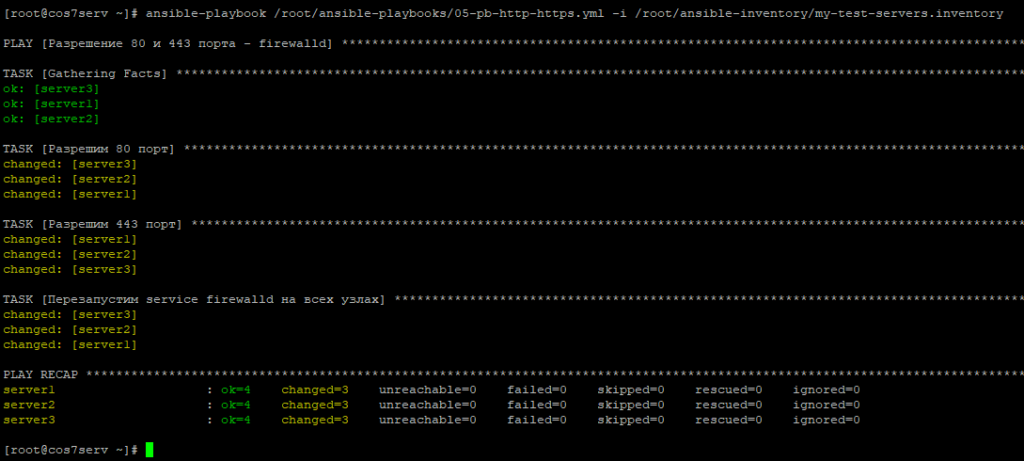
4.4. Настройка межсетевого экрана.
Для успешной и безопасной работы любого сервера первым делом требуется настраивать его сетевую безопасность. Настроим разрешение обращаться к узлам по 80 порту и 443 порту.
Воспользуемся готовым решением ansible.posix.firewalld от создателей Ansible по настройке межсетевого экрана firewalld на узлах.
Отдельно установим модуль ansible.posix.firewalld на Ansible сервер:
# ansible-galaxy collection install ansible.posix
Ответ:
Ansible поменяет настройки в файлах конфигурации firewalld. Для того, чтобы новые настройки были задействованы, требуется перезапустить firewalld на узлах.
В этом перезапуске службы межсетевого экрана нам поможет модуль ansible.builtin.service от создателей Ansible.
По умолчанию index.html — заставка Nginx, хранится в каталоге /usr/share/nginx/html на узлах, значит, если её принудительно заменить на что-то другое, то Nginx это будет добросовестно показывать.
В копировании содержимого Ansible каталога в другой каталог узлов, поможет модуль ansible.builtin.copy.
Заранее скачайте заставку на HTML5 и распакуйте её в каталог /root/ansible-files/nginx/ntml5/zastavka. Будем копировать содержимое этого каталога на узлы Ansible.
--
- name: Копирование каталогов Ansible в каталог узлов
hosts: test_servers
become_method: sudo
become_user: root
tasks:
# Копируйте дважды, так как иногда файлы пропускаются (в основном только один файл пропускается из папки, если папка не существует).
- name: Копирование из каталога в каталог
copy:
src: "/root/ansible-files/nginx/html5/zastavka/"
dest: "/usr/share/nginx/html/"
owner: root
group: root
mode: 0644
backup: yes
ignore_errors: true
Примечание: Если вы передаете несколько путей с помощью переменной, тогда:
src: "/ корень / {{элемент}}"
Примечание: Если вы передаете путь, используя переменную для разных элементов, тогда:
src: "/ root / {{item.source_path}}"
Проверим синтаксис плейбука 07-pb-nginx-html5.yml специальной утилитой --syntax-check от Ansible:
Проверим доступность новой демонстрационной страницы HTML web-сервера на узлах Ansible.
Наберем в браузере адрес какого-нибудь узла:
# http://192.168.0.39
Ответ на всех узлах одинаковый:
Web-сервер получил новую заглушку HTML5 и Nginx поменял страничку приветствия, которая была по умолчанию.
4.6. Добавить пользователей с sudo.
Для обслуживания тестовых серверов создадим пару учетных записей для самых трудолюбивых сотрудников, которые будут работать не покладая лапок. Учетный записи для пользователей: Мурзик и Барсик.
Создадим на самом сервере Ansible двух пользователей: myrzik и barsik. Генерируем для них ключи. Можно и готовые ключи использовать для установки на узлах, но у меня их нет. Барсик с Мурзиком не прислали ключи.
Создание:
# adduser myrzik
# adduser barsik
Установка паролей, чтобы они могли заходить на сервер Ansible:
# passwd myrzik
# passwd barsik
Генерируем для них ключи:
# su myrzik
# ssh-keygen
На все вопросы для myrzik просто жмём Enter.
# su barsik
# ssh-keygen
На все вопросы для barsik просто жмём Enter.
Теперь у нас на сервере Ansible появилось две учетные записи для наших пушистых коллег.
Добавим на узлы с помощью Ansible учетные записи пользователей myrzik и barsik вход по ключам, а так же режим sudo без пароля для них.
В работе Ansible с учетными записями пользователей поможет модуль ansible.builtin.user.
Команда для командной строки на узлах Ansible исполнена.
Есть еще способы запустить консольную команду:
---
- name: Установка zabbix-agent на узлах
hosts:
cos7client1
cos7client2
cos7client3
become_method: sudo
become_user: root
tasks:
- name: Установка репозитория docker и установка docker на узлы
ansible.builtin.shell: "curl -fsSL https://get.docker.com/ | sh"
- name: Поставим в автозапуск docker на узлах
ansible.builtin.service:
name: docker
enabled: yes
- name: Запустим docker на узлах
ansible.builtin.service:
name: docker
state: started
- name: Версия docker на узлах
ansible.builtin.shell: docker info
- name: Executing a Command Using Shell Module
shell: docker info
- name: Executing a command using command module
command: docker info
Для того, что бы увидеть что выводит команда в консоль узла, введите ключ -vvv:
Если ваши плейбуки должны работать в определённом порядке и если все они являются обязательными, то создайте Основную книгу и включите файлы с задачами с помощью операторов import_playbook.