В ознаменование Всемирного дня пароля, который был вчера, 5 мая, Apple, Google и Microsoft предпринимают «совместные усилия», чтобы расправиться с «паролем».
И это основные поставщики операционные системы хотят «расширить поддержку общего стандарта входа без пароля создан Альянсом FIDO и Консорциумом World Wide Web.
Java 18: установка и настройка Oracle JDK 18 в Debian 11
Несколько дней назад (22) организация Oracle объявила о доступности «Java 18». Последняя версия одного из наиболее часто используемых языков программирования и платформа для разработки номер один в мире. Новый пакет или программа, также известная как Оракл JDK 18, предлагает тысячи улучшений с точки зрения производительности, стабильности и безопасности. И, кроме того, включая девять предложений по улучшению платформы, что еще больше повышает производительность разработчиков.
Однако в этой публикации мы не будем углубляться в его новинки или улучшения, так как сделали это через несколько дней после (28) его запуска. Здесь мы углубимся в более практические и технические аспекты, то есть о его установка и настройка о текущем Дистрибутив GNU / Linux de Стабильный Debian.
Mozilla только что объявила о выпуске новая версия вашего веб-браузера Firefox и в то же время празднуя выпуск версии 100.
В 2004 году Mozilla объявила о выпуске Firefox 1.0 с помощью краудфандинговой рекламы в New York Times, в которой были перечислены имена всех, кто помог создать эту первую версию (сотни человек). Тогда целью ответственных лиц было предоставить Firefox 1.0 надежную, простую в использовании и надежную работу в Интернете.
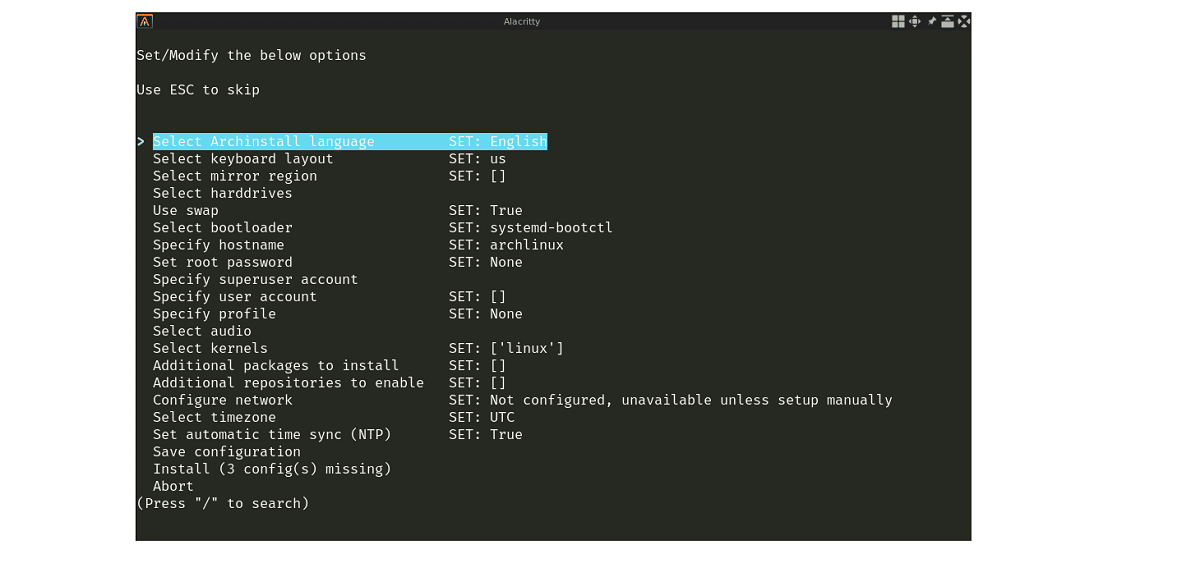
Недавно выпущена новая версия установщика «Archinstall 2.4», который по состоянию на апрель 2021 года в качестве опции включен в установочные iso-образы Arch Linux и отдельная реализация GUI для установки находится в разработке, но не входит в установочные образы Arch Linux и не обновлялся более двух лет .
Для тех, кто еще не знает об интеграции установщика Archinstall, вы должны знать, что этот установщик работает в консольном режиме и предлагается в качестве опции для автоматизации установки.. По умолчанию, как и раньше, предлагается ручной режим, предполагающий использование пошаговой инструкции по установке.
Последняя версия драйвера Game Ready обеспечивает наилучшие игровые возможности Dune: Spice Wars с первого дня. Кроме того, этот новый драйвер Game Ready предлагает поддержку последних выпусков и обновлений, включая введение Chernobylite трассировки лучей, добавление Nvidia DLSS к JX3 Online и запуск раннего доступа Vampire: The Masquerade — Bloodhunt.
Просматривая объемные примечания к выпуску (PDF), мы также обнаруживаем ряд исправлений, представленных в этом драйвере, в том числе:
Драйвер RTX 3050 может случайно истечь время ожидания и восстановиться при использовании Google Chrome [3567457]
MSI GT83VR 6RF/GT83VR 7RF/GT83 Titan 8RG] Внутренний ноутбук монитор показывает черный экран после обновления драйвера. [3508108]
Ошибка с кодом события 14 при входе в Windows, если настроен параметр Digital Vibrance [3544567]
Vulkan: производный TouchDesigner может аварийно завершить работу OpenColorIO [3575777].
Vulkan: Enscape может отображаться неправильно [3562578].
IntelliCAD может испытывать проблемы с нестабильностью [3529698].
Siemens Teamcenter / Siemens Tecnomatix: устранены проблемы с визуализацией при использовании более старых версий GLSL [3513350].
Adobe Premiere Pro: сбой, связанный с DirectX, с последним драйвером
Еще три дисплея были проверены для G-Sync, а именно Asus ROG XG259CM, Galaxy V1-01 и Samsung G95NA.
Хотите узнать больше о том, как Nvidia проходит процесс квалификации водителей? Шон Пеллетье, старший менеджер по продукту Game Ready Drivers, представляет интересный обзор.
Недавно выпуск новые версии программы Эмуляторы Box86 0.2.6 и Box64 0.1.8. Проекты разрабатываются синхронно одной и той же командой разработчиков.
Box86 ограничен запуском 86-битных приложений x32. (например, игры) в системах Linux, отличных от x86, таких как ARM (хост-система должна быть 32-разрядной с прямым порядком байтов). Поэтому для запуска и компиляции Box32 требуется 86-битная подсистема. Box86 бесполезен только на 64-битных системах. Кроме того, вам понадобится 32-битный набор инструментов для компиляции Box86.