Существует большое количество бесплатных современных систем мониторинга. В своём Telegram канале я написал небольшие обзоры на 20 наиболее известных и популярных в настоящее время систем мониторинга. Какие-то из них полностью бесплатные, а какие-то имеют как бесплатную версию, так и коммерческую. Я организовал список ТОП-20 систем мониторинга, который поможет вам сделать выбор и определиться, что имеет смысл внедрить у себя.
Архив метки: Prometheus
Как установить Grafana и Prometheus на Ubuntu 24.04
Grafana — это многоплатформенная платформа визуализации данных с открытым исходным кодом, разработанная Grafana Labs. Grafana представляет собой интерактивное веб-приложение для визуализации данных, включающее в себя графики, диаграммы и оповещения. С помощью Grafana вы можете запрашивать, визуализировать, настраивать оповещения и исследовать метрики, журналы и трассы TSDB. Это мощный инструмент, который превращает данные базы данных временных рядов (TSDB) в наглядные графики и визуализации. Читать
Настройка Alertmanager Prometheus
Системы мониторинга наподобие Prometheus устанавливаются не только для того чтобы иметь красивые графики состояния сервера в определённый момент, но чтобы вовремя узнавать о возможных проблемах. Для этого у таких систем существуют уведомления — алерты. Prometheus тоже умеет генерировать алерты на основе настраиваемых правил, однако если состояние сервера совпадает с правилом Prometheus будет генерировать алерт при каждом обновлении.
Это не очень удобное поведение, потому что если проблема будет сохранятся долго, вся почта будет заспамлена однообразными сообщениями. Поэтому существует Alertmanager. Это программа из того же пакета что и Prometheus, она позволяет сортировать алерты и отправлять сообщения только первый раз. В этой статье мы рассмотрим как выполняется настройка Alertmanager Prometheus на примере Ubuntu.
Метрики Qrator (Qrator Exporter)
В очередной раз пришлось настраивать сбор метрик с Qrator, прошлая моя заметка на этот счет жила в виде Issue в репозитории StupidScience/qrator-exporter (в проекте используются deprecated-методы), но там она пропала, поэтому опишу здесь, чтобы уж точно не потерялось.

Сбор данных будет осуществляться через telegraf и, с помощью него же, отдаваться в виде метрик формата Prometheus.
Prometheus: Recording Rules и теги – разделяем алерты в Slack
Необходимо создать отдельные каналы для backend, web, gaming, и их алерты вынести в разные каналы Slack. Тогда бекенд-девелоперы будут знать, что если в их канал Слака прилетел алерт – то на него таки стоит обратить внимание.
Как реализуем: используем Prometheus Recording Rules для правил, что бы создать отдельные алерты. Каждый алерт будет создаваться со своим набором тегов, используя которые мы в Opsgenie будем разруливать алерты через разные Slack-интергации по разным каналам.
Prometheus Recording Rules
Recording Rules позволяют формировать правила с expression, которые потом можно использовать в алертах.
К примеру, у нас есть такой алерт:
- name: Endpoint.rules
rules:
- record: blackbox_probe:http_probe
expr: probe_success{instance!~".*stage.*"}
- alert: EndpointProbeSuccess
expr: blackbox_probe:http_probe != 1
for: 2m
labels:
severity: warning
annotations:
summary: 'Endpoint down'
description: 'Cant access endpoint `{{ $labels.instance }}`'
tags: http
- alert: EndpointProbeSuccess
expr: blackbox_probe:http_probe != 1
for: 5m
labels:
severity: critical
annotations:
summary: 'Endpoint down'
description: 'Cant access endpoint `{{ $labels.instance }}`!'
tags: http
Тут используя общее правило blackbox_probe:http_probe мы создаём два алерта – один сработает с уровнем P3/warning через 2 минуты, а второй – с уровнем P1/critical через 5 минут, если первый не закрыли.
Prometheus Tags
Собственно говоря, тут теги – это просто дополнительное поле в аннотациях.
В конфиге Alertmanager для reciever Opsgenie настроена передача этих тегов – tags: "{{ .CommonAnnotations.tags}}":
- name: 'warning'
opsgenie_configs:
- message: "{{ .CommonAnnotations.summary }}"
description: "{{ range .Alerts }}nn{{ .Annotations.description }}{{ end }}n*Source*: <{{ (index .Alerts 0).GeneratorURL }}|Prometheus alerts>"
source: "{{ (index .Alerts 0).GeneratorURL }}"
tags: "{{ .CommonAnnotations.tags}}"
priority: P3
И затем эти теги доступны в Opsgenie:
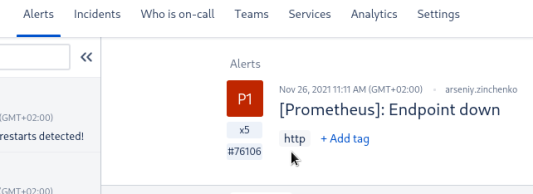
А значит – мы их сможем использовать в фильтрах Slack-интеграций.
AWS CloudWatch Tags?
А что делать с CloudWatch? В Opsgenie есть отдельные интеграции с AWS CloudWatch, которые триггерят свои алерты.
Увы – к CloudWatch Alarms теги прикрутить нельзя (пока что? не нашёл как?), поэтому делаем через теги в самой интеграции.
Например, для AWS Trusted Advisor заданы такие теги:
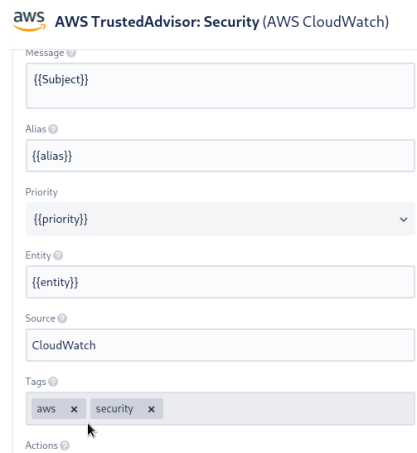
Позже можно будет разруливать между каналами типа #devops-alarms-aws и #devops-alarms-security.
Настройка Prometheus alerts
Настроим общий Recording Rule, и используя его – создадим два алерта, которые будут выбирать метрики, используя label namespace:
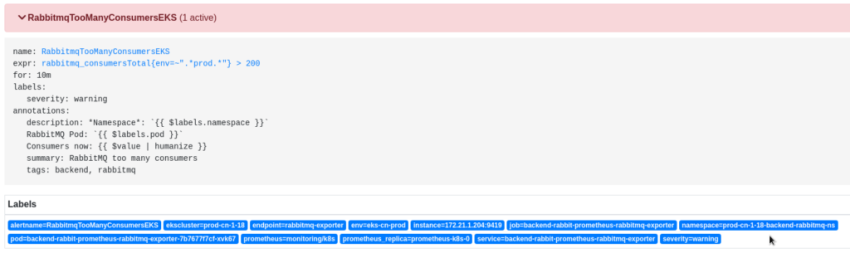
Тут очень пригодилось то, что мы изначально в имена неймспейсов Kubernetes включаем и кластер (dev, stage, prod), и команду, которая этот Namespace создавала.
Например, в имени namespace=prod-cn-1-18-backend-rabbitmq-ns мы видим, что это Prod-кластер в Китае (cn), версия Kubernetes в нём – 1.18, команда, которая использует этот сервис – backend, ну и имя самого сервиса – rabbitmq.
А затем к каждому алерту мы навесим свои теги – backend и web.
Итак, создаём Recording Rule с именем test:eks:pod_restarts:rate:
groups:
###############
### Testing ###
###############
- name: Test.rules
rules:
- record: test:eks:pod_restarts:rate
expr: rate(kube_pod_container_status_restarts_total{ekscluster=~"prod-.*"}[15m]) * 900
Само выражение нам сейчас не особо важно, тут просто скопировал правило из алерта рестартов подов.
Далее, используя этот rule описываем два алерта:
groups:
###############
### Testing ###
###############
- name: Test.rules
rules:
- record: test:eks:pod_restarts:rate
expr: rate(kube_pod_container_status_restarts_total{ekscluster=~"prod-.*"}[15m]) * 900
- alert: "TestingAlertBackend"
expr: test:eks:pod_restarts:rate{namespace=~".*backend.*"} < 2
for: 1s
labels:
severity: warning
annotations:
summary: "Testing alert: Backend"
description: "Ignore it: testing alerting system"
tags: backend, eks
- alert: "TestingAlertWeb"
expr: test:eks:pod_restarts:rate{namespace=~".*web.*"} < 2
for: 1s
labels:
severity: warning
annotations:
summary: "Testing alert: Web"
description: "Ignore it: testing alerting system"
tags: web, eks
Тут в алерте TestingAlertBackend используем правило test:eks:pod_restarts:rate, и выбираем все неймспейсы, которые содержат имя backend:
test:eks:pod_restarts:rate{namespace=~".*backend.*"}
А затем к этому алерту добавляем два тега – backend и eks.
Аналогично – с алертом для Web-team.
Alertmanager group_by
Кроме того, добавим в параметр group_by Алертменеджера группировку по тегам, что бы алерты Backend отделялись от алертов Web:
route:
group_by: ['alertname', 'tags']
repeat_interval: 15m
group_interval: 5m
Иначе, если группировать только по alertname, Alertmanager сгенерирует один алерт, который упадёт в первый попавшийся канал.
Переходим к Opsgenie.
Настройка Opsgenie и Slack
Создаём два канала в Slack – #devops-alarms-backend и #devops-alarms-web – будем их использовать в двух интеграциях Slack.
Далее, добавляем саму первую интеграцию Slack, для Backend-team, и в его Alert Filter выбираем алерты уровня P3 и с тегом backend:
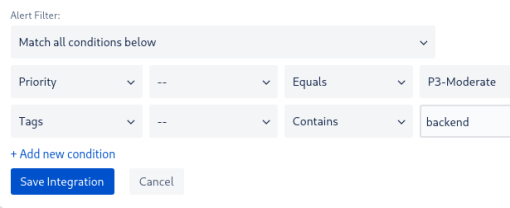
А в старой интеграции – #devops-alarms-warning – добавляем фильтр с NOT, что бы не дублировать алерты в старый канал:
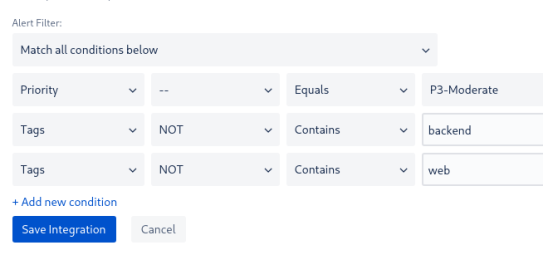
Проверяем – триггерим алерт, и получаем пачку алертов в оба канала.
Бекенд:
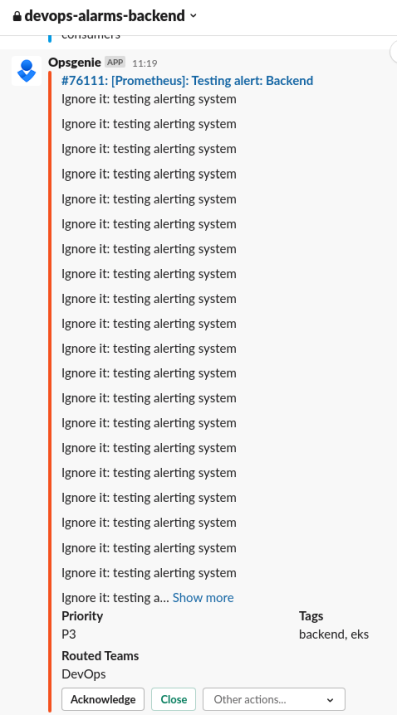
Тут Tags: backend, eks.
И аналогичная пачка прилетела от подов веб-команды:
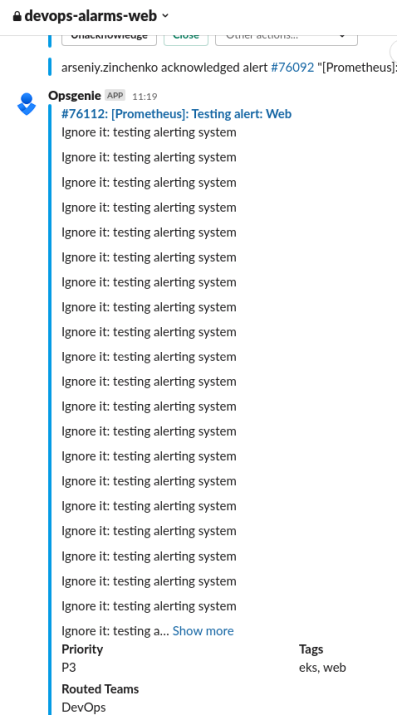
Готово
Источник: https://sidmid.ru/prometheus-recording-rules-и-теги-разделяем-алерты-в-slack/
2023-01-02T05:29:16
DevOps