На этом уроке разберём создание разделов при установке операционной системы Debian 11. Каждый раздел будем использовать по разному.
Архив метки: Linux
Как проверить версию MySQL в Ubuntu Linux
Это краткое руководство показывает студентам и новым пользователям, как проверять версии MySQL/MariaDB в Ubuntu Linux.
Как узнать, какие версии MySQL или сервера базы данных MariaDB у вас установлены? Как узнать? Какую команду вы используете?
Ответ на все ваши вопросы подробно описан ниже.
В настоящее время, куда бы вы ни посмотрели, вы найдете сервер базы данных MariaDB, который используется во многих проектах с открытым исходным кодом. Несколько лет назад этого не было.
Тогда MySQL был, вероятно, единственным сервером баз данных, который использовался в большинстве проектов с открытым исходным кодом. Однако после изменений лицензирования, внесенных Oracle, новая материнская компания создала альтернативу MySQL под названием MariaDB.
MariaDB — это прямая замена MySQL. Это означает, что во многих случаях вы можете просто удалить MySQL и установить MariaDB, и все готово. Обычно нет необходимости конвертировать какие-либо файлы данных.
Какую бы базу данных вы ни использовали, приведенные ниже команды должны работать для определения версии MySQL или MariaDB.
Чтобы начать проверку версий базы данных MySQL или MariaDB, выполните следующие действия.
Проверить версию сервера MySQL
MySQL и MariaDB поставляются со встроенным инструментом, который позволяет вам проверять версии сервера. Просто запустите приведенные ниже команды с аргументом -d, чтобы отобразить текущую версию сервера.
mysqld --version
Выполнение приведенной выше команды покажет, какая версия работает на сервере.
MySQL output: /usr/sbin/mysqld Ver 8.0.23-0ubuntu0.20.04.1 for Linux on x86_64 ((Ubuntu)) MariaDB output: mysqld Ver 10.3.25-MariaDB-0ubuntu0.20.04.1 for debian-linux-gnu on x86_64 (Ubuntu 20.04)
Если вы запустите приведенные ниже команды, она также должна отобразить версию сервера.
mysqladmin -V
Вывод команды выше.
MySQL output: mysqladmin Ver 8.0.23-0ubuntu0.20.04.1 for Linux on x86_64 ((Ubuntu)) MariaDB output: mysqladmin Ver 9.1 Distrib 10.3.25-MariaDB, for debian-linux-gnu on x86_64
MySQL и MariaDB поставляются с клиентским инструментом, который также должен помочь вам найти версию сервера. Из командной строки вызовите клиентский инструмент, выполнив следующую команду:
sudo mysql
Это позволит вам войти в систему и отобразить сведения о сервере, включая номер версии.
Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 9 Server version: 8.0.23-0ubuntu0.20.04.1 (Ubuntu) Copyright (c) 2000, 2021, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or 'h' for help. Type 'c' to clear the current input statement. mysql>
Сервер MariaDB выдаст следующее сообщение:
Welcome to the MariaDB monitor. Commands end with ; or g. Your MariaDB connection id is 49 Server version: 10.3.25-MariaDB-0ubuntu0.20.04.1 Ubuntu 20.04 Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or 'h' for help. Type 'c' to clear the current input statement. MariaDB [(none)]>
Или запустите запрос STATUS, чтобы отобразить сведения о сервере, включая номер версии.
mysql> STATUS;
Это должно отобразить вывод ниже:
Connection id: 9 Current database: Current user: root@localhost SSL: Not in use Current pager: stdout Using outfile: '' Using delimiter: ; Server version: 8.0.23-0ubuntu0.20.04.1 (Ubuntu) Protocol version: 10 Connection: Localhost via UNIX socket Server characterset: utf8mb4 Db characterset: utf8mb4 Client characterset: utf8mb4 Conn. characterset: utf8mb4 UNIX socket: /var/run/mysqld/mysqld.sock Binary data as: Hexadecimal Uptime: 6 min 54 sec Threads: 2 Questions: 5 Slow queries: 0 Opens: 117 Flush tables: 3 Open tables: 36 Queries per second avg: 0.012
Этих методов немного, которые помогут вам определить серверную версию MySQL или MariaDB из консоли командной строки.
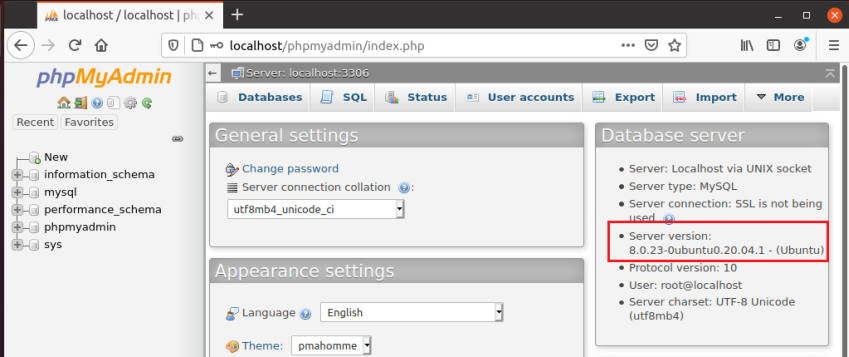
Использование phpMyAdmin
Если у вас установлен phpMyAdmin, вы также сможете увидеть версию сервера на портале. Войдите в систему и просмотрите сведения о сервере на панели управления.
Использование PHP
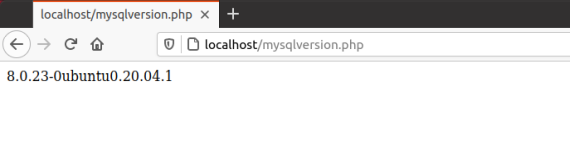
Если вы можете загрузить файл в корневой каталог Интернета, просто создайте локальный файл с именем mysqlversion.php . Затем скопируйте и вставьте приведенный ниже код в файл и загрузите его в корневую папку вашего сервера.
<?php
// Create a database connection.
$link = mysqli_connect("localhost", "root", "root_password");
// Print the MySQL version.
echo mysqli_get_server_info($link);
// Close the connection.
mysqli_close($link);
Это отобразит версию вашего сервера.
 Могут быть другие способы просмотреть номер версии вашего сервера базы данных в Ubuntu Linux. Однако несколько вышеперечисленных методов должны помочь вам начать работу.
Могут быть другие способы просмотреть номер версии вашего сервера базы данных в Ubuntu Linux. Однако несколько вышеперечисленных методов должны помочь вам начать работу.
Заключение
В этом посте показано, как узнать номер версии сервера базы данных MySQL или MariaDB в Ubuntu Linux. Если вы обнаружите какую-либо ошибку выше, пожалуйста, используйте форму комментария ниже, чтобы сообщить.
2021-05-12T12:00:25
Вопросы читателей
Как установить и настроить Perf в дистрибутивах Linux
Мониторинг системы Linux обычен для каждого пользователя. Если вы системный администратор, возможно, вам придется тщательно проверить свою систему. Вы не можете найти много инструментов, чтобы узнать общее состояние системы; найти приложение, которое может генерировать подробную информацию о состоянии системы в реальном времени, сложно.
Perf — это один из инструментов Linux, который вы можете использовать для получения подробной информации о проверке работоспособности и текущего положения в вашей системе. Perf — один из наиболее часто используемых и надежных инструментов системного мониторинга для сбора информации о ядре Linux, процессоре и оборудовании. Кроме того, он также может выполнять динамическую трассировку, проверять состояние оборудования и предоставлять отчеты о тестах производительности на машине Linux. Читать
Файловые системы поддерживаемые Linux
В этой статье познакомимся с тем, какие файловые системы могут быть использованы в операционной системе Linux: ext, btrfs, xfs и с другими.
Настройка сети в Proxmox
В первую очередь, на сервере виртуализации необходимо настроить сетевые подключения, которые в дальнейшем будут использоваться для доступа виртуальных машин в Интернет, обмена данными друг с другом, при необходимости распределить сети по VLAN. Для этого можно использовать реализованные в ядре Linux функции или установить Open vSwitch. В панели управления Proxmox VE реализован простой и понятный интерфейс управления сетями. Читать
Как установить и настроить браузер Tor в дистрибутивах Linux
Браузер Tor — самый надежный и зашифрованный веб-браузер для маршрутизации трафика и использования Интернета в частной сети. Большинство людей используют браузер Tor, чтобы скрыть свой цифровой след и личность. Tor может ввести вас на заблокированные или заблокированные веб-сайты вашим интернет-провайдером или правительством. Использование Tor полностью безопасно, и он не отправляет ваши личные данные о просмотре в орган. Браузер Tor совместим с телефонами Linux, Windows и Android. Установив Tor в свою систему, вы можете скрыть свой адрес, но поскольку IP-адрес проходит через множество неизвестных серверов Tor, прежде чем достигнет целевого сервера, это также может замедлить ваше соединение.
Браузер Tor в дистрибутивах Linux
Tor браузер на основе веб — браузера Firefox, и он написан на Python и языка программирования C. Он построен в рамках проекта Tor и имеет лицензию BSD с тремя пунктами. Tor подключает сигнал вашего интернет-провайдера к сети tor, где никто не знает, какой узел подключен к какому узлу; поэтому в Tor практически невозможно установить личность. Tor доступен для Ubuntu и других дистрибутивов Linux. В этом посте будет рассказано, как установить и начать работу с браузером Tor в различных операционных системах Linux.
1. Установите Tor Browser в Ubuntu Linux.
Установить браузер Tor на Ubuntu / Debian Linux легко и несложно. Есть два разных метода, которые мы можем использовать для его установки в Linux на базе Debian. На этом этапе мы рассмотрим метод PPA и Aptitude для установки браузера Tor на машине Ubuntu.
Метод 1: установите Tor Browser через PPA
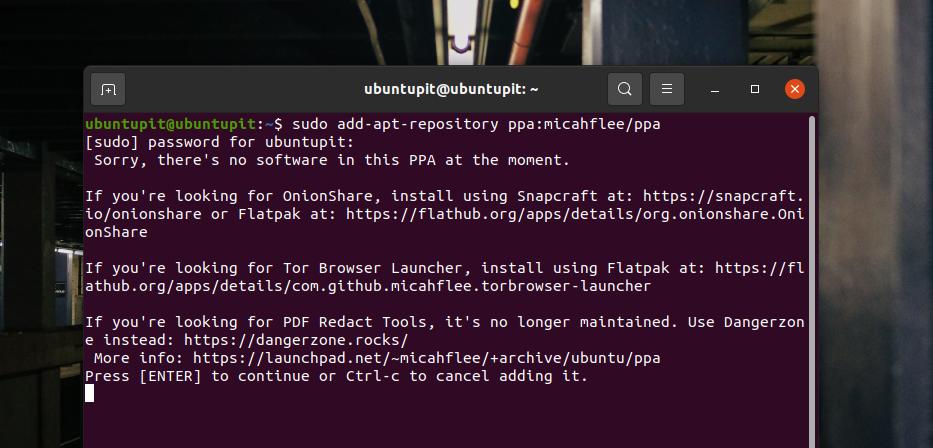
Есть способы установить браузер Tor на Ubuntu с помощью команд PPA. Если вы новичок в Ubuntu, начало работы с командами PPA может быть отличным. Сначала выполните следующую команду, чтобы добавить PPA в системный репозиторий.
sudo add-apt-repository ppa:micahflee/ppa
Затем выполните приведенные ниже команды, чтобы обновить репозиторий и установить Tor Browser на свой компьютер с Linux. Следующие команды требуют привилегий root; убедитесь, что он у вас есть.
sudo apt update sudo apt install torbrowser-launcher
Метод 2: установка браузера Tor через репозиторий Linux
Как пользователь Ubuntu / Debian Linux, вероятно, вы ищете способ установки браузера Tor с помощью команд aptitude. Tor имеет официальный репозиторий Linux, который позволяет вам установить его через интерфейс командной строки в Ubuntu. Вы можете использовать следующие команды, чтобы добавить репозиторий Universe, а затем установить программу запуска браузера Tor на свой компьютер.
sudo add-apt-repository universe && sudo apt update sudo apt install torbrowser-launcher
После завершения установки вы можете запустить следующую команду для первого запуска браузера Tor в вашей системе Linux.
torbrowser-launcher
2. Установите Tor в Fedora и openSUSE.
Здесь мы увидим, как установить браузер Tor в Fedora и SuSe Linux. Если вы следовали предыдущим шагам, то, возможно, уже заметили, что установка Tor в Linux не является сложной задачей. Если вы используете рабочую станцию Fedora на основе DNF, вы можете просто запустить следующую команду DNF с правами root в оболочке терминала, чтобы установить Tor в вашей системе.
$ sudo dnf install -y torbrowser-launcher
Tor также доступен в официальном репозитории SuSE Linux. Чтобы установить Tor в openSUSE и SuSE Linux, выполните следующую команду zypper с правами root в оболочке терминала.
sudo zypper install torbrowser-launcher
3. Установите Tor в Linux с помощью исходного кода.
Установка любых пакетов из исходного кода — всегда удобный способ получить пакет. Если вы не можете найти способы установить браузер Tor в вашей системе Linux, вы всегда можете загрузить сжатый исходный код и установить Tor в своей системе. Следующий метод будет выполняться почти во всех основных дистрибутивах Linux.
Сначала загрузите исходный файл Tor отсюда. Когда загрузка завершится, откройте каталог загрузки и извлеките сжатый файл. После распаковки просмотрите файлы браузера tor и запустите каталог на терминале.
Теперь, когда в оболочке терминала открывается каталог Tor, запустите следующую команду с точкой и косой чертой (./) в своей оболочке, чтобы установить браузер Tor в вашей системе Linux. Весь процесс установки не займет много времени. Как только установка завершится, браузер Tor впервые автоматически откроется в вашей системе.
./start-tor-browser.desktop
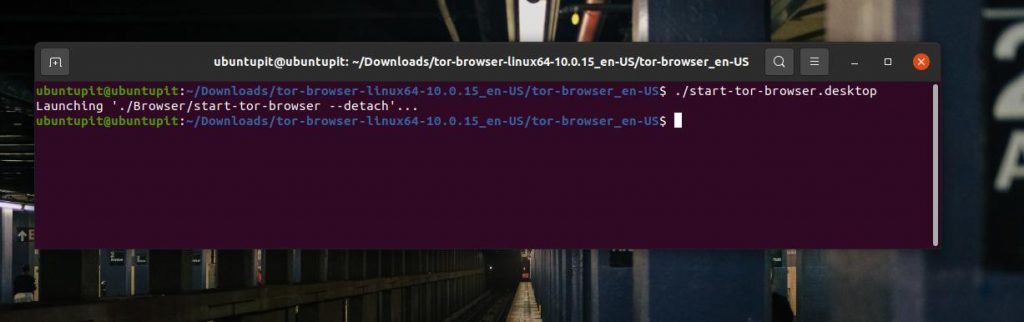
4. Начните работу с Tor Browser
До сих пор мы видели несколько основных методов установки браузера Tor в системе Linux. Пришло время запустить Tor в нашей системе. Независимо от того, какой дистрибутив Linux вы используете, следующие шаги будут одинаковыми для всех систем. Во-первых, чтобы открыть браузер Tor, вы можете запустить следующую команду в оболочке терминала.
$ torbrowser-launcher
Вы также можете найти значок лука в браузере Tor, чтобы запустить его на своем компьютере.
![]()
Когда браузер Tor открывается в первый раз, загрузка необходимых файлов может занять некоторое время. Наберитесь терпения и не закрывайте окно, пока загрузка не закончится. При загрузке всей системы Tor вы можете выбрать, откуда скачать. Если настройки по умолчанию вам не подходят, используйте зеркальный сервер.
Как только сервер будет выбран, он сразу же начнет загрузку файлов Tor. Вы увидите прогресс загрузки в строке состояния.
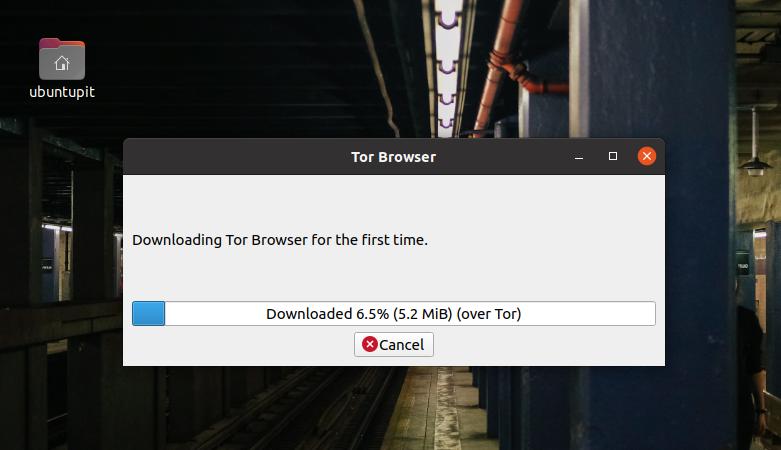
Когда загрузка завершится, автоматически откроется новое окно, чтобы соединить вас с цепью Tor. Если установить соединение не удалось, проверьте подключение к Интернету и повторите попытку.
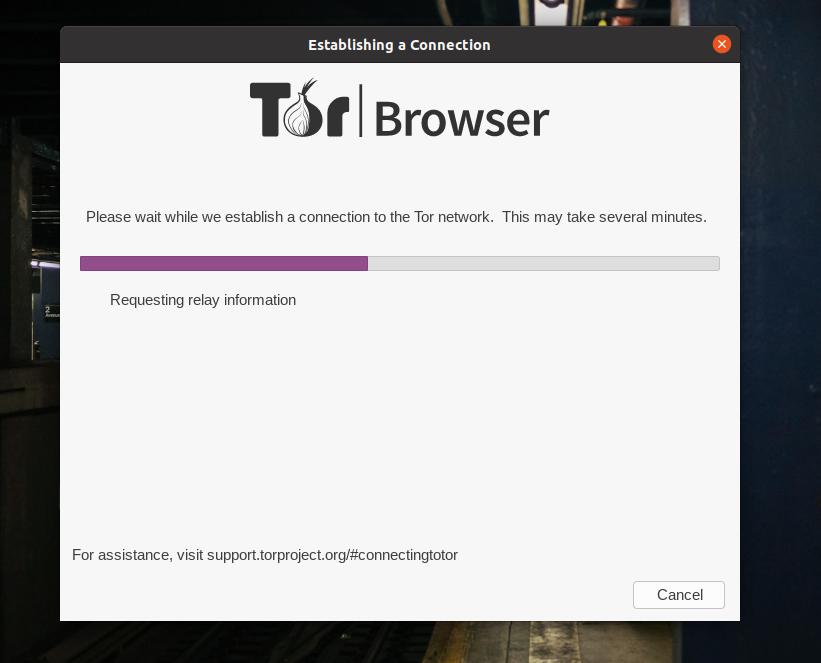
Наконец, когда загрузка и установка завершатся, в вашей системе откроется браузер Tor. В верхнем левом углу браузера вы можете изучить функции Tor.
В самом начале вы можете не забыть проверить уровень безопасности браузера Tor. Чтобы проверить это, нажмите на гамбургер-меню, расположенное в правом верхнем углу браузера. В меню выберите «Конфиденциальность и безопасность». Там вы увидите уровень безопасности браузера. Вы также можете быстро просмотреть уровень безопасности, нажав значок безопасности в области надстроек браузера.
Браузер Tor предлагает использовать HTTPS на каждом сайте, чтобы сделать соединение безопасным и безопасным. Убедитесь, что HTTPS Everywhere включен.
5. Удалить Tor из Linux
Tor — это не веб-браузер, требовательный к оперативной памяти и ресурсам. Но у Tor есть некоторые минусы, которые могут вынудить вас удалить его из вашей системы. Tor не позволяет скачивать большие файлы, а в некоторых странах использование Tor запрещено и незаконно. Если вам нужно удалить браузер Tor из вашей системы Linux, вы можете использовать следующие методы соответственно.
Удалите Tor, если вы установили через PPA
sudo apt remove torbrowser-launcher
Удалите Tor, если вы установили Tor с помощью команды Aptitude
sudo apt remove tor-browser rm -r ~/.tor-browser-en sudo apt purge torbrowser-launcher
Если вышеупомянутые методы к вам не подходят, вы всегда можете найти tor-browser_en-US каталог в файловой системе Linux и удалить весь каталог, чтобы удалить Tor из вашей системы.
Дополнительный совет: вас беспокоит конфиденциальность? Используйте ОС Tails
Если вы участвуете в секретном проекте или вообще не хотите раскрывать свою личность в Интернете, использование браузера Tor может быть не лучшим решением. Есть много других способов отследить ваш IP-адрес в Интернете. Чтобы решить эту проблему, вы можете установить на свой компьютер ОС Tails с открытым исходным кодом на основе ядра Linux . ОС Tails полностью бесплатна и безопасна в использовании. Конфиденциальность — это главный приоритет Tails OS. В Tails все входящие и исходящие соединения защищены, зашифрованы и проходят через сеть Tor.

Заключительные слова
Никто не может отрицать, что Tor — самый безопасный браузер для анонимной работы в Интернете. Если конфиденциальность — ваша самая большая проблема, то Tor для вас. Скрытие вашей личности с помощью луковой цепи, вероятно, является самым надежным методом в эпоху Интернета. Во всем посте я описал различные методы установки браузера Tor и начала работы с ним на машине Linux.
Пожалуйста, поделитесь им со своими друзьями и сообществом Linux, если вы найдете этот пост полезным и информативным. Вы также можете записать свое мнение об этом сообщении в разделе комментариев.
2021-05-10T11:32:07
Вопросы читателей