Мониторинг — это сбор метрик и представление этих метрик в удобном виде (таблицы, графики, шкалы, уведомления, отчёты). Концептуально его можно изобразить в таком виде:

Метрики — это абстракция, с которой мы имеем дело, когда говорим о мониторинге. Это какие-то числа, описывающие состояние интересующей нас штуковины. Самый простой и понятный мониторинг следит за ресурсами компьютера: загрузкой процессора, памяти, диска, сети. Аналогично можно следить за чем-то более высокоуровневым, вроде количества посетителей на сайте или среднего времени ответа сервера. Для компьютера это один хрен безликие числа.
Мониторинг — это инструмент анализа того, что происходит/происходило в системе. Следовательно, без понимания смысла собранных данных мониторинг вам не особо поможет. И наоборот: в умелых руках это мощный инструмент.
Чем больше компонентов в вашей системе (микросервисов), чем больше нагрузка на неё, чем дороже время простоя, тем важнее иметь хорошую систему мониторинга.
То, что не метрики — то логи. Их тоже надо собирать и анализировать, но это отдельная история со своими инструментами.
Сейчас модно делать мониторинг на основе Prometheus. Так ли он хорош на самом деле? На мой взгляд это лучшее, что сейчас есть из мониторинга. Оговорюсь сразу для тех, кто хочет с этим поспорить: я понимаю, что разным задачам — разные инструменты и где-то больше подходит старый проверенный Nagios. Но в целом лидирует Prometheus.
Prometheus — это не готовое решение в духе “поставил и работает” (привет, Netdata). Это платформа, набор инструментов, позволяющий сделать себе такой мониторинг, какой надо. Фреймворк, если хотите.
Эта статья про знакомство с Prometheus’ом и установку. Потом будет интереснее — про настройку непосредственно мониторинга.
Архитектура Prometheus
Prometheus состоит из отдельных компонентов, которые общаются друг с другом по http. Всё модно-молодёжно, с веб-интерфейсами и настраивается в yaml-конфигах.
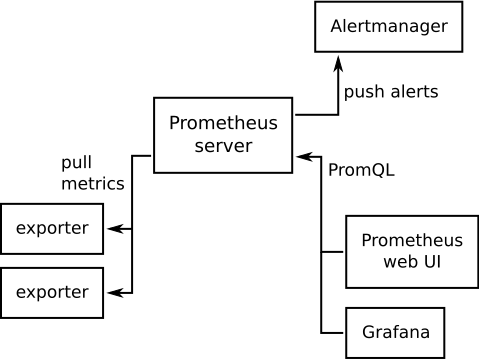
- Prometheus server — центральное звено. Здесь хранятся собранные метрики, плюс имеется простенький веб-интерфейс, чтобы на них смотреть (Prometheus web UI).
- Агенты, собирающие метрики и предоставляющие их в понятном для Prometheus’а виде. В зависимости от контекста называются экспортерами (exporter) или таргетами (target). Устанавливаются на целевые машины. Типичный представитель — node_exporter — собирает данные о вычислительных ресурсах: загрузку процессора, памяти, диска и т.п. Есть куча других экспортеров. Например, cadvisor собирает данные о контейнерах. Есть экспортеры для Postgres’а, для Nginx’а и т.д. С точки зрения самого Prometheus’а они ничем принципиально не отличаются друг от друга, просто каждый собирает какие-то свои метрики. Можно писать свои экспортеры, если ничего из готового вам не подходит.
- Alertmanager — уведомлятор. Это он отправит письмо вам на почту, если что-то сломается. Из коробки умеет в почту, Slack, Hipchat, Pagerduty. Сторонними средствами можно прикрутить Telegram и наверное что-то ещё.
- Grafana строго говоря не является частью Prometheus’а, но все её ставят и официальная документация рекомендует поступать именно так. Показывает красивые графики. Кучка графиков, собранных на одном экране, называется дашбордом (dashboard). Типа такого:
Установка
Все компоненты Prometheus’а написаны на Go и представляют собой статически скомпиленные бинари, не требующие никаких зависимостей кроме libc и готовые запускаться на любой платформе, будь то Debian, Arch или Centos. Установить их можно аж тремя способами:
- по-старинке через пакетный менеджер,
- взять готовые бинари с оф. сайта и засунуть их в систему в обход пакетного менеджера,
- развернуть всё в докер-контейнерах.
Разумеется, у каждого способа есть свои преимущества и недостатки.
Если ставить через пакетный менеджер, то через него же вы будете получать обновления и сможете всё удалить. Однако есть нюанс. У Prometheus’а нет своих собственных репозиториев для популярных дистрибутивов, а официальные репозитории Debian/Ubuntu как всегда отстают от апстрима. Например, сейчас в Debian доступна версия 2.7.1, когда Prometheus уже 2.11.1. Arch Linux — молодец, идёт в ногу со временем.
При установке вручную Prometheus не будет числиться в списках установленного софта и с точки зрения пакетного менеджера его в системе нет. Зато вы сможете обновлять Prometheus отдельно от пакетов. При ручной установке придётся немного побывать в роли установочного скрипта (который есть в пакете), поэтому, если у вас серьёзные намерения — автоматизируйте установку/обновление через какой-нибудь Ansible. Рекомендую взять за основу готовые роли для Prometheus, Alertmanager, Node exporter, Grafana.
Если ставить Prometheus в докере, то всё про мониторинг будет лежать в одном месте. Можно это хозяйство положить под Git и иметь возможность поднять мониторинг в две команды: git clone, docker-compose up. Но надо писать правильный docker-compose.yml, париться при возникновении сетевых проблем… Короче, вы от одних проблем избавляетесь, а взамен получаете другие. В зависимости от того, с какими вам больше нравится возиться, выбирайте тот или иной вариант установки. Вам понадобятся контейнеры prom/prometheus, prom/node_exporter, prom/alertmanager. За основу рекомендую взять docker-compose.yml из репозитория docprom.
В продакшене я бы поднимал мониторинг в докере как минимум в целях безопасности. Свой личный мониторинг я устанавливал по-старинке вручную.
Установка вручную
Расскажу про ручную установку, потому что в основе других способов установки лежат те же действия, только завёрнутые в дополнительную обёртку. Этот способ подойдёт для любых дистрибутивов Linux под управлением systemd (Ubuntu, Debian, Centos, Arch и т.д.)
Установка Prometheus server
Идём на https://github.com/prometheus/prometheus/releases, находим билд под свою платформу (скорее всего это будет linux-amd64). Копипастим ссылку, качаем:
$ wget https://github.com/.../prometheus-2.11.1.linux-amd64.tar.gz
$ tar xf prometheus-*.tar.gz
Раскидываем файлы по ФС, заводим пользователя:
# cd prometheus-*
# cp prometheus promtool /usr/local/bin
# mkdir /etc/prometheus /var/lib/prometheus
# cp prometheus.yml /etc/prometheus
# useradd --no-create-home --home-dir / --shell /bin/false prometheus
# chown -R prometheus:prometheus /var/lib/prometheus
В архиве будут два ненужных каталога: console_libraries/ и consoles/. Их не трогаем.
Создаём systemd-юнит:/etc/systemd/system/prometheus.service
[Unit]
Description=Prometheus
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Restart=on-failure
ExecStart=/usr/local/bin/prometheus
--config.file /etc/prometheus/prometheus.yml
--storage.tsdb.path /var/lib/prometheus/
ExecReload=/bin/kill -HUP $MAINPID
ProtectHome=true
ProtectSystem=full
[Install]
WantedBy=default.target
Запускаем Prometheus server:
# systemctl daemon-reload
# systemctl start prometheus
# systemctl status prometheus
В статусе должно быть написано “active (running)” — значит работает. Теперь можно сходить на http://localhost:9090 и полюбоваться на интерфейс Prometheus’а. Пока что он бесполезен, но уже можно потыкать.
Установка node exporter
Node exporter надо раскатать на всех машинах, которые вы хотите мониторить. Устанавливается он аналогично серверу. Берём последний билд с https://github.com/prometheus/node_exporter/releases.
$ wget https://github.com/.../node_exporter-0.18.1.linux-amd64.tar.gz
$ tar xf node_exporter-*.tar.gz
# cd node_exporter-*
# cp node_exporter /usr/local/bin
# useradd --no-create-home --home-dir / --shell /bin/false node_exporter
/etc/systemd/system/node_exporter.service
[Unit]
Description=Prometheus Node Exporter
After=network.target
[Service]
Type=simple
User=node_exporter
Group=node_exporter
ExecStart=/usr/local/bin/node_exporter
SyslogIdentifier=node_exporter
Restart=always
PrivateTmp=yes
ProtectHome=yes
NoNewPrivileges=yes
ProtectSystem=strict
ProtectControlGroups=true
ProtectKernelModules=true
ProtectKernelTunables=yes
[Install]
WantedBy=multi-user.target
Важно! Если у вас /home вынесен на отдельный раздел, директиву ProtectHome=yes надо убрать, иначе node exporter будет неправильно показывать оставшееся место на разделе /home.
Запускаем node exporter:
# systemctl daemon-reload
# systemctl start node_exporter
# systemctl status node_exporter
Можно посмотреть как node exporter отдаёт метрики:
$ curl -s http://localhost:9100/metrics
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 7.9825e-05
go_gc_duration_seconds{quantile="0.25"} 7.9825e-05
go_gc_duration_seconds{quantile="0.5"} 7.9825e-05
go_gc_duration_seconds{quantile="0.75"} 7.9825e-05
go_gc_duration_seconds{quantile="1"} 7.9825e-05
go_gc_duration_seconds_sum 7.9825e-05
go_gc_duration_seconds_count 1
...
Пока не пытайтесь что-то понять в выводе. Отдаёт и ладно.
Установка alertmanager
Alertmanager — это про алерты. Первое время алертов у вас не будет, поэтому сейчас его можно не ставить. Но лучше всё-таки поставить, чтобы всё необходимое уже было подготовлено. Идём за дистрибутивом на https://github.com/prometheus/alertmanager/releases.
$ wget https://github.com/.../alertmanager-0.18.0.linux-amd64.tar.gz
$ tar xf alertmanager-*.tar.gz
# cd alertmanager-*
# cp alertmanager /usr/local/bin
# mkdir /etc/alertmanager /var/lib/alertmanager
# cp alertmanager.yml /etc/alertmanager
# useradd --no-create-home --home-dir / --shell /bin/false alertmanager
# chown -R alertmanager:alertmanager /var/lib/alertmanager
/etc/systemd/system/alertmanager.service
[Unit]
Description=Alertmanager for prometheus
After=network.target
[Service]
User=alertmanager
ExecStart=/usr/local/bin/alertmanager
--config.file=/etc/alertmanager/alertmanager.yml
--storage.path=/var/lib/alertmanager/
ExecReload=/bin/kill -HUP $MAINPID
NoNewPrivileges=true
ProtectHome=true
ProtectSystem=full
[Install]
WantedBy=multi-user.target
Запускаем alertmanager:
# systemctl daemon-reload
# systemctl start alertmanager
# systemctl status alertmanager
Веб-интерфейс alertmanager’а доступен на http://localhost:9093. Пока в нём нет ничего интересного.
Установка Grafana
Если у вас Debian/Ubuntu или Redhat/Centos, лучше установить Grafana из пакета. Ссылочки найдёте в описании под видео на https://grafana.com/grafana/download.
$ wget https://dl.grafana.com/oss/release/grafana_6.3.2_amd64.deb
# dpkg -i grafana_6.3.2_amd64.deb
Запускаем grafana:
# systemctl start grafana
# systemctl status grafana
Prometheus, Node exporter, Alertmanager и Grafana по умолчанию слушают на всех сетевых интерфейсах. При необходимости прикрывайтесь фаерволлом от посторонних глаз.
Первичная настройка
Теперь, когда все компоненты установлены, надо подружить их друг с другом. Сперва минимально настроим Prometheus server:/etc/prometheus/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
scrape_configs:
- job_name: 'node'
static_configs:
- targets:
- localhost:9100
# - anotherhost:9100
Пока не буду вдаваться в подробности настройки, этим займёмся в следующих статьях. На текущем этапе надо получить пусть примитивный, но работающий мониторинг. Основное что сейчас стоит знать:
- Отступы в yml — два пробела. Всегда и везде.
scrape_interval— с какой периодичностью Prometheus server будет забирать (scrape) метрики с экспортеров.localhost:9093иlocalhost:9100— адреса alertmanager’а и node exporter’а соответственно. Если у вас другие, замените на правильные. Если у вас node exporter установлен на несколько машин, впишите их все.
Теперь попросим prometheus перечитать конфигурационный файл:
# systemctl reload prometheus
В веб-интерфейсе на странице http://localhost:9090/targets появился первый таргет. Он должен быть в состоянии “UP”.
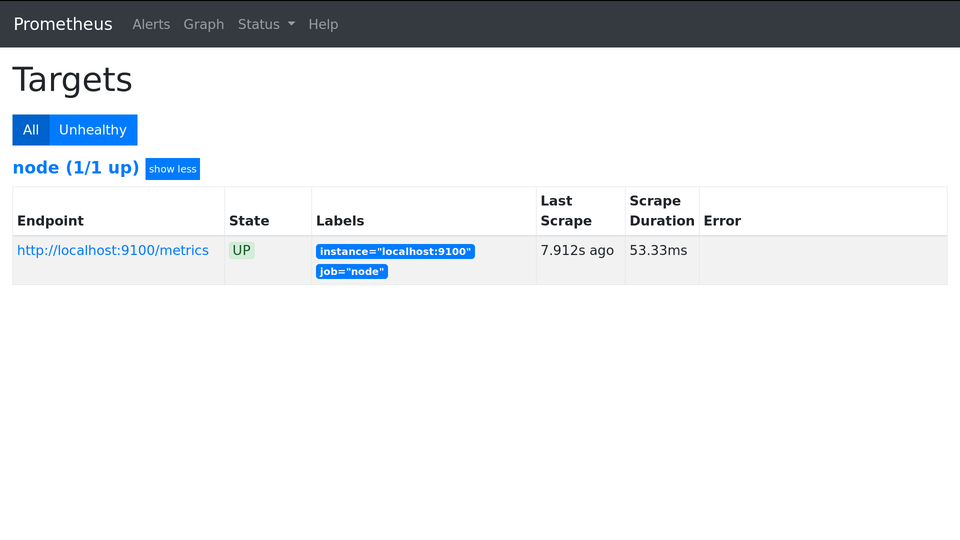
Поздравляю, мониторинг начал мониторить! Теперь можно пойти на вкладку Graph и запросить какую-нибудь метрику, например node_load1 — это одноминутный load average. Там же можно временной график посмотреть:
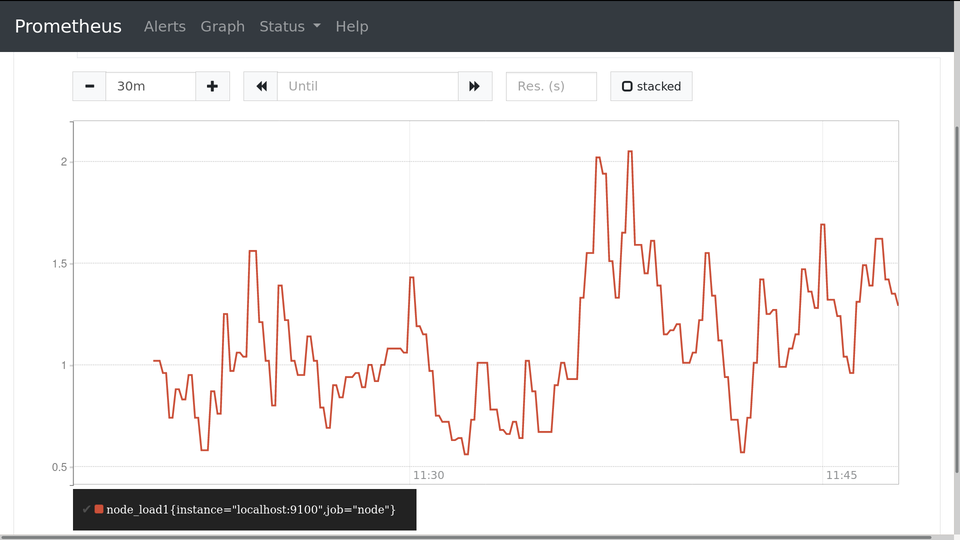
В повседневной жизни вы вряд ли будете смотреть графики в этом интерфейсе. Гораздо приятнее смотреть графики в Grafana.
Открываем интерфейс Grafana по адресу http://localhost:3000. Логинимся (admin:admin), при желании меняем пароль. Практически всё в Графане настраивается тут же, через веб-интерфейс. Нажимаем на боковой панели Configuration (шестерёнка) → Preferences:
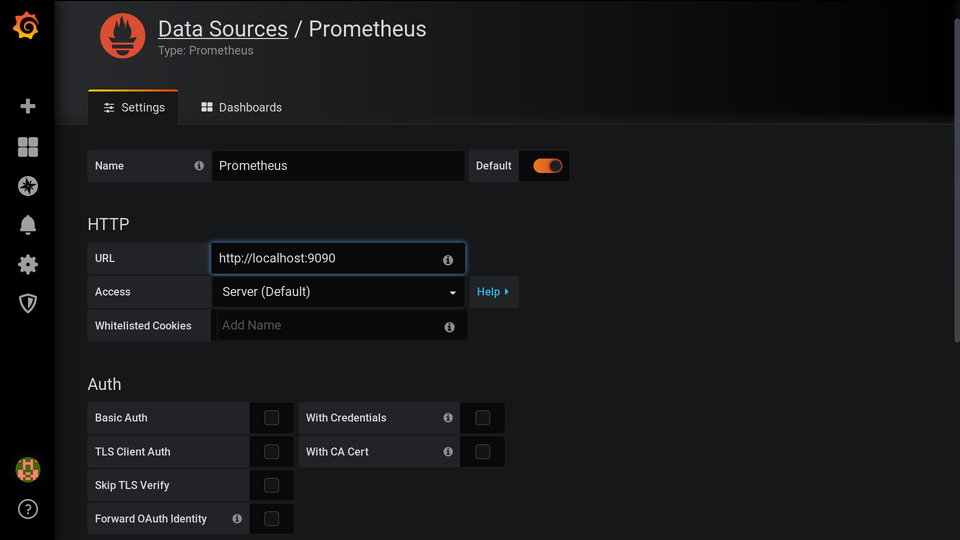
Идём на вкладку Data Sources, добавляем наш Prometheus:
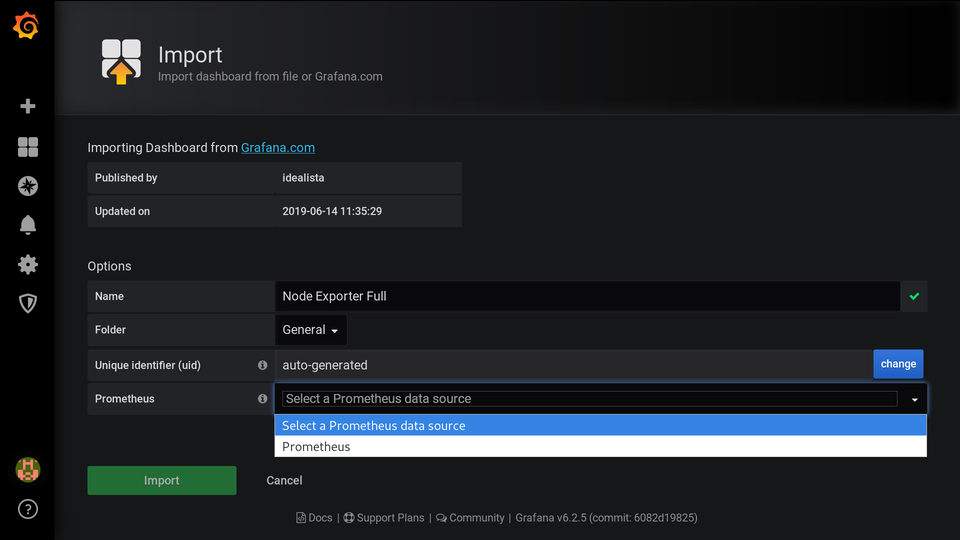
Теперь добавим готовый дашборд Node exporter full. Это лучший дашборд для старта из всех, что я пересмотрел. Идём Dashboards (квадрат) → Manage → Import.
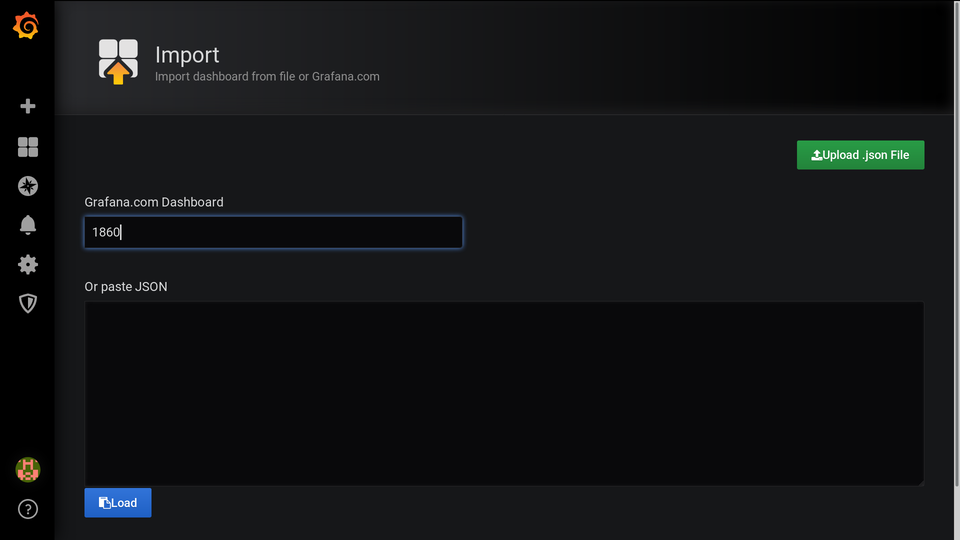
Вписываем 1860 и убираем курсор из поля ввода, иначе не начнёт импортировать. Дальше указываем data source и жмём import.
Поздравляю, самая скучная часть работы проделана! Теперь вы можете наблюдать за жизнью своих серверов в Графане.
Если у вас серьёзные намерения и вы хотите, чтобы все компоненты автоматически запускались после перезагрузки машины, не забудьте сообщить об этом systemd:
# systemctl enable prometheus
# systemctl enable grafana
# systemctl enable alertmanager
# systemctl enable node_exporter
И это всё?
У нас пока нет алертов, не заведены пользователи в Grafana, мы ничего не понимаем в настройке. Да, наш мониторинг пока очень сырой. Но надо же с чего-то начать! Позже я напишу про настройку, про алерты и многое другое. Всё будет, друзья. Всё будет.
Куда копать дальше?
- Официальная документация Prometheus. Да, она не супер-подробная, и лично мне многое было непонятно вначале, но заглянуть стоит.
- Блог Robust Perseption, который ведёт Brian Brazil — один из разработчиков Prometheus’а. Статьи короткие и, на мой взгляд, слишком лаконичные. Хочется больше подробностей, больше примеров.
- Книга Prometheus up and running за авторством всё того же Brian Brazil. Во многом повторяет статьи блога.
Источник: https://laurvas.ru/prometheus-p1/