Apache Pinot — это распределенное хранилище данных OLAP, работающее в режиме реального времени.
Апач Пино Это решение для хранения данных OLAP. распределенная система реального времени, используемая для предоставления масштабируемой аналитики в реальном времени с низкой задержкой.
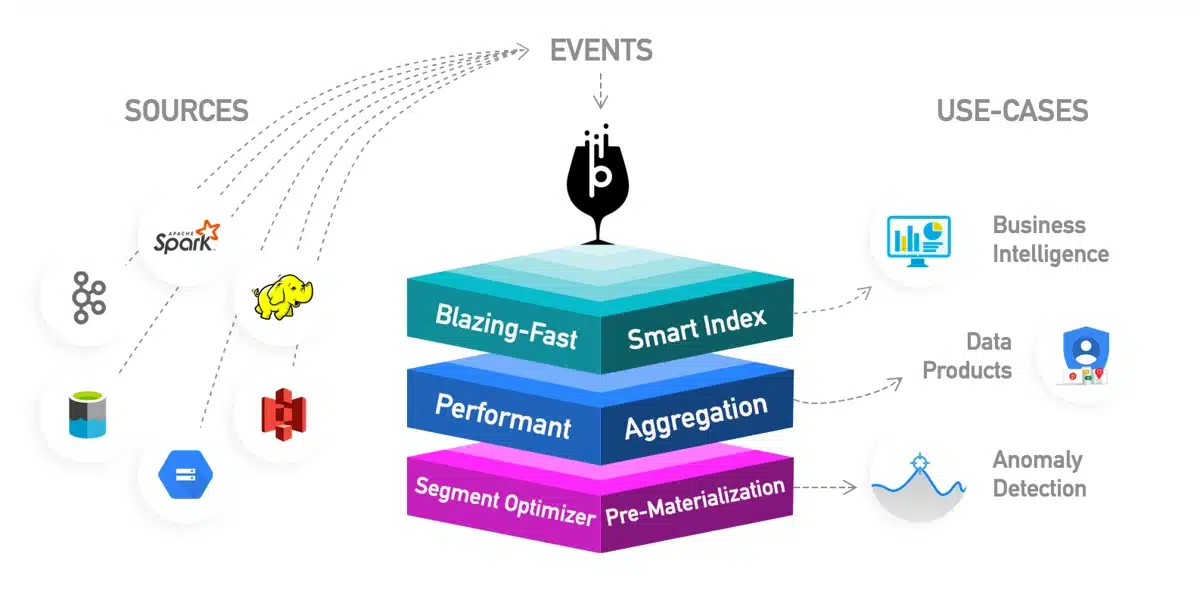
Может принимать данные из источников пакетных данных. (например, HDFS, S3, Azure Data Lake, Google Cloud Storage), а также из источников потоковой передачи (например, Kafka). Pinot предназначен для горизонтального масштабирования, поэтому при необходимости вы можете масштабироваться до более крупных наборов данных и более высокой частоты запросов.
Об Апаче Пино
Проект Пино изначально был разработан LinkedIn а в 2015 году он был передан Apache Foundation для дальнейшей совместной разработки. Хранилище предназначено для работы в среде, где постоянно добавляются новые данные, и обеспечивает минимальную и предсказуемую задержку, что позволяет использовать хранилище для обработки запросов в реальном времени.
Как и большинство других хранилищ данных и решений для хранения данных OLAP, Pinot поддерживает SQL-подобный язык запросов который поддерживает выбор, агрегацию, фильтрацию, группировку, сортировку и отдельные запросы данных.
Апач Пино обеспечивает горизонтальную масштабируемость и средства для достижения отказоустойчивости. и устойчивость к ошибкам программного и аппаратного обеспечения. Процессы репликации и резервного копирования интегрированы непосредственно в цикл обработки данных, добавляемых в хранилище. С одной стороны, такой подход позволяет существенно упростить архитектуру, но с другой – вызывает задержку между добавлением данных и их доступностью для запросов.
Данные хранятся в таблицах в базе данных, ориентированной на столбцы. Кроме того, поддерживается несколько схем сжатия и возможность размещения в поле нескольких значений. Pinot предоставляет подключаемую систему индексирования, которая может использовать различные технологии индексирования (отсортированный индекс, индекс растрового изображения, инвертированный индекс, индекс StarTree, фильтр Блума, индекс диапазона, индекс текстового поиска (Lucence/FST), индекс JSON, геопространственный индекс).
Из характеристик, которыми выделяется Апач Пино:
- Столбец-ориентированный– База данных, ориентированная на столбцы, с различными схемами сжатия, такими как длина серии и фиксированная длина в битах.
- Подключаемая индексация: Подключаемые технологии индексирования, Сортированный индекс, Растровый индекс, Инвертированный индекс.
- Оптимизация запросов— Возможность оптимизировать план запроса/выполнения на основе метаданных запроса и сегмента.
- Прием потоков и пакетов: Прием потоков Hadoop и пакетный прием практически в реальном времени.
- Консультация: Механизм выполнения запросов на основе SQL.
- Upsert во время приема в реальном времени: обновлять данные в масштабе и согласованно
- Несколько полей значений: поддержка полей с несколькими значениями, позволяющая запрашивать поля как значения, разделенные запятыми.
- Облачная нативность в Kubernetes: Helm Chart обеспечивает горизонтально масштабируемое отказоустойчивое кластерное развертывание, которым легко управлять с помощью Kubernetes.
Новая версия Апача Пино
Стоит отметить, что в последнее время Выпущена версия Apache Pinot 1.0., что в основном подведены итоги большой работы по стабилизации кодовой базы и учитывать пожелания сообщества (учтено более 300 комментариев).
Наряду с этим подчеркивается, чтоe новый механизм обработки многоэтапный запрос (Multi-Stage Query Engine) достиг своего полного потенциала, что позволяет реализовать поддержку объединения таблиц (JOIN). Использованный движок изначально отлично справлялся с простыми операциями фильтрации и агрегации, но для обеспечения предсказуемого времени выполнения запроса он не поддерживал операции соединения таблиц.
новый двигатель включает промежуточные этапы обработки сложных запросов, а семантика SQL близка к ANSI SQL.. Кроме того, новая версия предлагает встроенную поддержку обработки данных в формате JSON, обеспечивает поддержку значения «NULL», интегрируется с Apache Spark 3.x и улучшает реализацию таблиц в режиме Upsert (добавление сжатия сегментов и поддержка исключения операций). ).
Наконец, если вы интересно в возможности знать подробнее об этом, вы должны знать, что код проекта написан на Java и распространяется по лицензии Apache. Вы можете проверить детали новой версии в по следующей ссылке.